计算机视觉算法——基于Transformer的目标检测(DN DETR / DINO)
- 计算机视觉算法——基于Transformer的目标检测(DN DETR / DINO)
- 1. DN DETR
- 1.1 Stablize Hungarian Matching
- 1.2 Denoising
- 1.3 Attention Mask
- 2. DINO
- 2.1 Contrastive Denoising
- 3.2 Mix Query
- 3.3 Look Forward Twice
- 3. Sparse DETR
- 3.1 Encoder Token Sparsification
- 3.2 Scoring Network
- 3.3 Encoder Auxiliary Loss and Top-K Decoder Queries
- 4. Lite DETR
- 4.1 Motivation and Analysis
- 4.2 Interleaved Update
- 4.3 Key-aware Deformable Attention
计算机视觉算法——基于Transformer的目标检测(DN DETR / DINO)
自DETR年提出来之后,许多Paper针对DETR中收敛速度慢、检测效果差等问题进行了针对性优化,在
计算机视觉算法——基于Transformer的目标检测(DETR / Deformable DETR / Dynamic DETR / DETR 3D)
计算机视觉算法——基于Transformer的目标检测(Efficient DETR / Anchor DETR / Conditional DETR / DAB DETR)
中我们对DETR以及其部分优化方法进行了总结,本篇博客我们针对这些优化方法进行进一步补充。
1. DN DETR
DN DETR发表于2022年CVPR,该论文的主要贡献是在训练过程中引入了去噪任务,进一步加速了训练收敛速度,仅用12个Epochs就可以得到不错的效果
1.1 Stablize Hungarian Matching
在Anchor DETR、Conditional DETR、DAB DETR等一系列工作中,研究方向多集中在如何修改网络结构或者给Learnable Query赋予先验以加速网络的收敛,而DN DETR则引入了一个新的思路,如何稳定匈牙利匹配的过程来加速收敛。
匈牙利匹配是基于全局最优的思想通过规则定义的Cost矩阵计算出匹配的结果,由于匹配的离散性和训练的随机性,这会使得Query和Ground Truth的匹配是一个非常不稳定的过程。
DN DETR提出的方法是取消匈牙利匹配过程,我们先验地告诉每一个Query它需要学习的GroundTruth是哪个,但是如果直接给Query提供对应GroundTruth的监督,会使得这个任务对于DN DETR过于简单。因此作者考虑到给GroundTruth加入噪声作为输入,然后使用GroundTruth来重建输出,让DN DETR去完成去噪任务。因为每个Query对应的GroundTruth是稳定不变的,也就避免了上上述不稳定匹配的过程。
下面我们来看看是DN DETR是如何添加噪声的:
1.2 Denoising
DN DETR带Denoising的训练过程如下图所示:

从图中我们可以看到,Denoising Part是一个完全增量的模块,原始基于匈牙利匹配的Matching Part并不会丢弃。DN DETR是基于DAB DETR进行开发的,在DAB DETR中,Query被分成了Content Query和Position Query两部分,因此对于真值的噪声添加我们也分为Content和Positoin两部分
Content Noise
Content Noise即对GT Label添加噪声,由于GT Label是一个数字,如果只是将这个数字修改另外一个数字肯定是不够的,我们需要将加噪的GT Label编码为Embedding向量,具体来说我们需要做如下操作:
- 在模型中设置一个Embedding Matrix,由其对加噪的GT Label进行编码得到对应的Class Embedding;
- 考虑到对Matching Part的友好性,在Class Embedding部分拼接了指示向量Indicator,用来甄别Query到底是做Denoising任务还是Matching任务;
- 在原始的DETR中,Query的Content部分是初始化为零向量,在这里我们需要对Query的Content部分进行改造,对于左Denosing任务Content Query初始化为‘Non Object’类别,这个值应该不小于GT Label的类别数Num_Classes并且通过Embedding Matrix进行编码。对于做Denoising任务的Content Query则初始化为0到Num_Classes-1,同样通过Embedding Matrix进行编码。
Position Noise
Position Noise即对4D Anchor Box部分添加噪声。这部分噪声可以概括为中心点位移和尺度缩放:
- 中心点位移:首先从均匀分布中采样一个扰动参数 λ 1 ∈ ( 0 , 1 ) \lambda_1 \in(0,1) λ1∈(0,1),然后分别计算中心点 x , y x,y x,y对应偏移量为 ∣ Δ x ∣ = λ 1 x , ∣ Δ y ∣ = λ 1 y |\Delta x|=\lambda _1 x,| \Delta y \mid=\lambda_1 y ∣Δx∣=λ1x,∣Δy∣=λ1y由于 x = w 2 x=w_2 x=w2, y = h 2 y=h_2 y=h2,于是扰动后中心点 ( x ± Δ x , y ± Δ y ) ({x} \pm \Delta {x}, {y} \pm \Delta {y}) (x±Δx,y±Δy)还位于原框内
- 尺度缩放:同样从均匀分布中采集一个扰动参数 λ 2 ∈ ( 0 , 1 ) \lambda_2 \in(0,1) λ2∈(0,1),然后也是分别计算宽高对应的偏移量 ∣ Δ w ∣ = λ 2 w , ∣ Δ h ∣ = λ 2 h |\Delta w|=\lambda_2 w,| \Delta h \mid=\lambda_2 h ∣Δw∣=λ2w,∣Δh∣=λ2h,最终得到缩放后的宽高 ( 1 ± λ 2 ) w , ( 1 ± λ 2 ) h (1 \pm \lambda_2) w,(1 \pm \lambda_2) h (1±λ2)w,(1±λ2)h,也就是说,宽高会缩放至原来的 0 0 0到 2 2 2倍
对于不同噪声影响的大小,作者在实验部分进行的对比:

Denoising Groups
为了更充分地利用Denosing任务去提升模型的学习效率,我们可以让模型堆每个Ground Truth在不同程度的噪声下都拥有纠错能力,作者设置了Denoising Groups,即多个去噪组,每个Ground Truth在每组内都会有一个Noised Query负责去预测。
在每组内Ground Truth和Query是One-to-One的关系,但是总和每组来看Ground Truth和Query就是One-to-Many的关系。在CNN的目标检测方法中经常使用到这种One-to-Many的关系,即由多个Anchor去预测同一个Ground Truth,这种训练监督方式会导致这些方法避免不了使用NMS进行后处理,但是在DN DETR中,这种One-to-Many的关系仅在训练的时候起到加速收敛的作用,但是在实际推理时仍然是使用Matching Part的二分匹配的结果,因此可以避免NMS

从上图的实验对比结果可以看出来,适当增加Denosing Group可以提高模型AP。
1.3 Attention Mask
在Transformer的构建中,如果没有特殊处理,Denosing Part的Query和Matching Part的Query是会进行Attention交互的。Denosing Part的Query中包含大量Ground Truth信息的,如果Matching Part的Query通过Attention获取到了这些Ground Truth的信息,学习的效果肯定会大打折扣。因此作者在训练过程中添加了Attention Mask来组织Ground Truth的信息泄露。
如何设置Attention Mask呢?
- Matching Part的Queries不能看到Denoising Part的Query,原因上面已经分析过。
- 不同Denoising Group的Queries不能相互看到,原因是每个Denoising Group中必定有一个Query拥有当前Query负责预测的Ground Truth的信息,如果拿当前Query和其他Denosing Group的Queries进行Attention势必会导致信息泄露。
- 相同Denoising Group的Queries可以相互看到,原因是对于同组的Queries各自负责的Ground Truth都是不相同的,因此相互Attention不会存在信息泄露。
从下面实验结果看,Attention Mask在训练过程中起到了至关重要的作用:

下面我们通过代码看看上述各个要点是如何实现的:
DN DETR的代码主要是基于DAB DETR的工程实现的,主要代码实现在dn_component.py脚本中,首先是构建Noise和Attention Mask的部分:
def prepare_for_dn(dn_args, embedweight, batch_size, training, num_queries, num_classes, hidden_dim, label_enc):
"""
prepare for dn components in forward function
Args:
dn_args: (targets, args.scalar, args.label_noise_scale, args.box_noise_scale, args.num_patterns) from engine input
embedweight: positional queries as anchor
training: whether it is training or inference
num_queries: number of queries
num_classes: number of classes
hidden_dim: transformer hidden dimenstion
label_enc: label encoding embedding
Returns: input_query_label, input_query_bbox, attn_mask, mask_dict
"""
if training:
# targets是list[dict],每个dict中存储的一张图片上ground truth的所有目标框的label和boxes,一个target就是一个batch
# scalar代表的去噪的组数,默认是5
targets, scalar, label_noise_scale, box_noise_scale, num_patterns = dn_args
else:
num_patterns = dn_args
if num_patterns == 0:
num_patterns = 1
# 用于指示匹配的任务的向量,全部初始化为0
indicator0 = torch.zeros([num_queries * num_patterns, 1]).cuda()
# label_enc = nn.Embedding(num_classes + 1, hidden_dim - 1), num_class+1的原因是tgt的初始值为num_classes,代表non object,hidden_dim-1的原因是需要concate indicator0,在原detr中tgt初始化为零向量
tgt = label_enc(torch.tensor(num_classes).cuda()).repeat(num_queries * num_patterns, 1)
# content部分:(num_queries*num_patterns,hidden_dim)
tgt = torch.cat([tgt, indicator0], dim=1)
# position部分:(num_queries,4)->(num_query*num_patterns,4)
refpoint_emb = embedweight.repeat(num_patterns, 1)
if training:
# 每张图片上所有ground truth的数量是不一样的
known = [(torch.ones_like(t['labels'])).cuda() for t in targets]
# know_idx中元素是shape为(num_gt_img, 1),值为1的tensor, 后序用于记录每个目标框的索引
know_idx = [torch.nonzero(t) for t in known]
# 记录batch中图片的ground truth的数量
known_num = [sum(k) for k in known]
# you can uncomment this to use fix number of dn queries
# if int(max(known_num))>0:
# scalar=scalar//int(max(known_num))
# can be modified to selectively denosie some label or boxes; also known label prediction
# torch.cat是把batch中所有的ground truth的索引排成一排
unmask_bbox = unmask_label = torch.cat(known)
labels = torch.cat([t['labels'] for t in targets])
boxes = torch.cat([t['boxes'] for t in targets])
# 记录每个ground truth的图片在在整个batch中是第几张图片
batch_idx = torch.cat([torch.full_like(t['labels'].long(), i) for i, t in enumerate(targets)])
# 记录每个ground truth在整个batch中的位置,
known_indice = torch.nonzero(unmask_label + unmask_bbox)
known_indice = known_indice.view(-1)
# add noise
# 将indice,labels,batch_id,bounding box复制到所有去噪组中去
known_indice = known_indice.repeat(scalar, 1).view(-1)
known_labels = labels.repeat(scalar, 1).view(-1)
known_bid = batch_idx.repeat(scalar, 1).view(-1)
known_bboxs = boxes.repeat(scalar, 1)
# 用于在label上添加噪声
known_labels_expaned = known_labels.clone()
# 用于在boxes上添加噪声
known_bbox_expand = known_bboxs.clone()
# noise on the label
if label_noise_scale > 0:
# (scalar*num_gts_batch,) 从均匀分布中采样
p = torch.rand_like(known_labels_expaned.float())
# 选择一半的label进行添加噪声
chosen_indice = torch.nonzero(p < (label_noise_scale)).view(-1) # usually half of bbox noise
# 论文中的flip操作,随机选择任意的类别作为噪声
new_label = torch.randint_like(chosen_indice, 0, num_classes) # randomly put a new one here
known_labels_expaned.scatter_(0, chosen_indice, new_label)
# noise on the box
if box_noise_scale > 0:
diff = torch.zeros_like(known_bbox_expand)
# bounding box的中心点坐标
diff[:, :2] = known_bbox_expand[:, 2:] / 2
# bounding box的猖狂
diff[:, 2:] = known_bbox_expand[:, 2:]
# 在原来ground truth的boxes上加上偏移量,并且保证添加噪声后框的中心点在原来的框内
known_bbox_expand += torch.mul((torch.rand_like(known_bbox_expand) * 2 - 1.0),
diff).cuda() * box_noise_scale
known_bbox_expand = known_bbox_expand.clamp(min=0.0, max=1.0)
m = known_labels_expaned.long().to('cuda')
input_label_embed = label_enc(m) # 对添加噪声的ground truth进行编码
# add dn part indicator
indicator1 = torch.ones([input_label_embed.shape[0], 1]).cuda()
input_label_embed = torch.cat([input_label_embed, indicator1], dim=1)
input_bbox_embed = inverse_sigmoid(known_bbox_expand)
single_pad = int(max(known_num)) # 整个batch中一张图片最多的ground truth的数量
pad_size = int(single_pad * scalar) # 相当于将同一个ground truth的不同噪声组拼接成一行,然后repeate成batch size行
padding_label = torch.zeros(pad_size, hidden_dim).cuda()
padding_bbox = torch.zeros(pad_size, 4).cuda()
# 将去噪任务和匹配任务的query拼接在一起
input_query_label = torch.cat([padding_label, tgt], dim=0).repeat(batch_size, 1, 1)
input_query_bbox = torch.cat([padding_bbox, refpoint_emb], dim=0).repeat(batch_size, 1, 1)
# 由于上面input_query_label和input_query_box是padded的并且初始化为0,因此需要将每张图片真实有效的noised label和noisd boxes放到正确的位置上
# map in order
map_known_indice = torch.tensor([]).to('cuda')
if len(known_num):
# 得到每个ground truth在每张图片上的独立索引
map_known_indice = torch.cat([torch.tensor(range(num)) for num in known_num]) # [1,2, 1,2,3]
# 计算每个ground truth在每张图片生成的所有去噪组上的索引
map_known_indice = torch.cat([map_known_indice + single_pad * i for i in range(scalar)]).long()
if len(known_bid):
# 将去噪任务中的noised labels和noises boxes放到对应的位置上
input_query_label[(known_bid.long(), map_known_indice)] = input_label_embed # 属于那张图片,是这张图片上的第几个噪声组的第几个label
input_query_bbox[(known_bid.long(), map_known_indice)] = input_bbox_embed
tgt_size = pad_size + num_queries * num_patterns
attn_mask = torch.ones(tgt_size, tgt_size).to('cuda') < 0
# match query cannot see the reconstruct
attn_mask[pad_size:, :pad_size] = True
# reconstruct cannot see each other
for i in range(scalar): # 按照制定的规则设置attention mask
if i == 0:
attn_mask[single_pad * i:single_pad * (i + 1), single_pad * (i + 1):pad_size] = True
if i == scalar - 1:
attn_mask[single_pad * i:single_pad * (i + 1), :single_pad * i] = True
else:
attn_mask[single_pad * i:single_pad * (i + 1), single_pad * (i + 1):pad_size] = True
attn_mask[single_pad * i:single_pad * (i + 1), :single_pad * i] = True
mask_dict = {
'known_indice': torch.as_tensor(known_indice).long(), # (scalar*num_gts_batch,) 每个 gt 在整个 batch 中的索引
'batch_idx': torch.as_tensor(batch_idx).long(), # (num_gts_batch,) 每个 gt 所在图片的 batch 索引
'map_known_indice': torch.as_tensor(map_known_indice).long(), # (num_gts_batch*scalar,) 噪声 queries(非 padding 的) 的索引
'known_lbs_bboxes': (known_labels, known_bboxs), # (scalar*num_gts_batch,), (scalar*num_gts_batch,4)
'know_idx': know_idx, # List[Tensor]: 其中每个 Tensor 的 shape 是 (num_gt_img,1) 每个 gt 在其图片中的索引
'pad_size': pad_size # 该 batch 中噪声 queries 的数量(包括 padding 的)
}
else: # no dn for inference
input_query_label = tgt.repeat(batch_size, 1, 1)# (num_queries*num_patterns,hidden_dim)->(batch_size,num_queries*num_patterns,hidden_dim)
input_query_bbox = refpoint_emb.repeat(batch_size, 1, 1)# (num_query*num_patterns,4)->(batch_size,num_query*num_patterns,4)
attn_mask = None
mask_dict = None
# 將 batch 的维度置换到第二維(dim1),以适配 transformer 的輸入
input_query_label = input_query_label.transpose(0, 1)
input_query_bbox = input_query_bbox.transpose(0, 1)
return input_query_label, input_query_bbox, attn_mask, mask_dict
其次从输出中分离去噪任务和匹配任务的部分:
def dn_post_process(outputs_class, outputs_coord, mask_dict):
"""
post process of dn after output from the transformer
put the dn part in the mask_dict
"""
if mask_dict and mask_dict['pad_size'] > 0:
# 取出去噪任务的结果
# (num_layers,batch,pad_size,num_classes)
output_known_class = outputs_class[:, :, :mask_dict['pad_size'], :]
# (num_layers,batch,pad_size,4)
output_known_coord = outputs_coord[:, :, :mask_dict['pad_size'], :]
# 让 outputs_class & outputs_coord 保持为原始 DETR 匹配任务的预测结果,与原始DETR架构兼容
outputs_class = outputs_class[:, :, mask_dict['pad_size']:, :]
outputs_coord = outputs_coord[:, :, mask_dict['pad_size']:, :]
# 將去噪任务的预测結果记录到 mask_dict
mask_dict['output_known_lbs_bboxes']=(output_known_class,output_known_coord)
return outputs_class, outputs_coord
然后是Loss计算前进行的预处理部分,主要对去噪任务的Query去Padding,仅对真实有效的Query计算Loss:
def prepare_for_loss(mask_dict):
"""
prepare dn components to calculate loss
Args:
mask_dict: a dict that contains dn information
"""
# (num_layers,batch,pad_size,num_classes), (num_layers,batch,pad_size,4)
output_known_class, output_known_coord = mask_dict['output_known_lbs_bboxes']
# (num_dn_groups*num_gts_batch,), (num_dn_groups*num_gts_batch,4)
known_labels, known_bboxs = mask_dict['known_lbs_bboxes']
# (num_dn_groups*num_gts_batch,) 非 Padding 部分的 Queries 索引
map_known_indice = mask_dict['map_known_indice']
# (num_dn_groups*num_gts_batch,) 將所有 GT 在 Batch 中排序的索引
known_indice = mask_dict['known_indice']
# (num_gts_batch,) 每个 GT 所在图片的 Batch 索引(即是该 batch 中的第几张图)
batch_idx = mask_dict['batch_idx']
# (num_dn_groups*num_gts_batch,) 所有去噪組每个 GT/Queries 所在图片的 Batch 索引
bid = batch_idx[known_indice]
# 过滤,仅保留非 Padding 部分的 Quries 对应的预测结果
if len(output_known_class) > 0:
output_known_class = output_known_class.permute(1, 2, 0, 3)[(bid, map_known_indice)].permute(1, 0, 2)
output_known_coord = output_known_coord.permute(1, 2, 0, 3)[(bid, map_known_indice)].permute(1, 0, 2)
num_tgt = known_indice.numel()
return known_labels, known_bboxs, output_known_class, output_known_coord, num_tgt
最后是Loss计算部分:
def compute_dn_loss(mask_dict, training, aux_num, focal_alpha):
"""
compute dn loss in criterion
Args:
mask_dict: a dict for dn information
training: training or inference flag
aux_num: aux loss number
focal_alpha: for focal loss
"""
losses = {}
# 先计算Transformer最后一层的预测结果对应的Loss
if training and 'output_known_lbs_bboxes' in mask_dict:
# 过滤掉Padding部分的Queries的预测记过,使得GT与Query的预测结果一一对应
known_labels, known_bboxs, output_known_class, output_known_coord, \
num_tgt = prepare_for_loss(mask_dict)
losses.update(tgt_loss_labels(output_known_class[-1], known_labels, num_tgt, focal_alpha))
losses.update(tgt_loss_boxes(output_known_coord[-1], known_bboxs, num_tgt))
else:
losses['tgt_loss_bbox'] = torch.as_tensor(0.).to('cuda')
losses['tgt_loss_giou'] = torch.as_tensor(0.).to('cuda')
losses['tgt_loss_ce'] = torch.as_tensor(0.).to('cuda')
losses['tgt_class_error'] = torch.as_tensor(0.).to('cuda')
# 计算Transformer除最后一层外其余每层预测结果对应的Loss
if aux_num:
for i in range(aux_num):
# dn aux loss
if training and 'output_known_lbs_bboxes' in mask_dict:
l_dict = tgt_loss_labels(output_known_class[i], known_labels, num_tgt, focal_alpha)
l_dict = {k + f'_{i}': v for k, v in l_dict.items()}
losses.update(l_dict)
l_dict = tgt_loss_boxes(output_known_coord[i], known_bboxs, num_tgt)
l_dict = {k + f'_{i}': v for k, v in l_dict.items()}
losses.update(l_dict)
else:
l_dict = dict()
l_dict['tgt_loss_bbox'] = torch.as_tensor(0.).to('cuda')
l_dict['tgt_class_error'] = torch.as_tensor(0.).to('cuda')
l_dict['tgt_loss_giou'] = torch.as_tensor(0.).to('cuda')
l_dict['tgt_loss_ce'] = torch.as_tensor(0.).to('cuda')
l_dict = {k + f'_{i}': v for k, v in l_dict.items()}
losses.update(l_dict)
return losses
def tgt_loss_boxes(src_boxes, tgt_boxes, num_tgt,):
"""Compute the losses related to the bounding boxes, the L1 regression loss and the GIoU loss
targets dicts must contain the key "boxes" containing a tensor of dim [nb_target_boxes, 4]
The target boxes are expected in format (center_x, center_y, w, h), normalized by the image size.
"""
if len(tgt_boxes) == 0:
return {
'tgt_loss_bbox': torch.as_tensor(0.).to('cuda'),
'tgt_loss_giou': torch.as_tensor(0.).to('cuda'),
}
# 计算 L1 Loss
loss_bbox = F.l1_loss(src_boxes, tgt_boxes, reduction='none')
losses = {}
losses['tgt_loss_bbox'] = loss_bbox.sum() / num_tgt
# 计算 GIOU Loss
loss_giou = 1 - torch.diag(box_ops.generalized_box_iou(
box_ops.box_cxcywh_to_xyxy(src_boxes),
box_ops.box_cxcywh_to_xyxy(tgt_boxes)))
losses['tgt_loss_giou'] = loss_giou.sum() / num_tgt
return losses
def tgt_loss_labels(src_logits_, tgt_labels_, num_tgt, focal_alpha, log=True):
"""Classification loss (NLL)
targets dicts must contain the key "labels" containing a tensor of dim [nb_target_boxes]
"""
if len(tgt_labels_) == 0:
return {
'tgt_loss_ce': torch.as_tensor(0.).to('cuda'),
'tgt_class_error': torch.as_tensor(0.).to('cuda'),
}
# 增加Batch的维度
src_logits, tgt_labels= src_logits_.unsqueeze(0), tgt_labels_.unsqueeze(0)
# 制作One Hot类别标签,类别为(1,num_dn_groups*num_gts_batch,num_classes+1)
target_classes_onehot = torch.zeros([src_logits.shape[0], src_logits.shape[1], src_logits.shape[2] + 1],
dtype=src_logits.dtype, layout=src_logits.layout, device=src_logits.device)
target_classes_onehot.scatter_(2, tgt_labels.unsqueeze(-1), 1)
target_classes_onehot = target_classes_onehot[:, :, :-1]
# 计算Focal Loss
loss_ce = sigmoid_focal_loss(src_logits, target_classes_onehot, num_tgt, alpha=focal_alpha, gamma=2) * src_logits.shape[1]
losses = {'tgt_loss_ce': loss_ce}
losses['tgt_class_error'] = 100 - accuracy(src_logits_, tgt_labels_)[0]
return losses
def sigmoid_focal_loss(inputs, targets, num_boxes, alpha: float = 0.25, gamma: float = 2):
"""
Loss used in RetinaNet for dense detection: https://arxiv.org/abs/1708.02002.
Args:
inputs: A float tensor of arbitrary shape.
The predictions for each example.
targets: A float tensor with the same shape as inputs. Stores the binary
classification label for each element in inputs
(0 for the negative class and 1 for the positive class).
alpha: (optional) Weighting factor in range (0,1) to balance
positive vs negative examples. Default = -1 (no weighting).
gamma: Exponent of the modulating factor (1 - p_t) to
balance easy vs hard examples.
Returns:
Loss tensor
"""
# 將原始输出转换为 0~1 概率
prob = inputs.sigmoid()
# 计算二元交叉熵损失
# (1,num_dn_groups*num_gts_batch,num_classes)
ce_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduction="none")
# focal loss 的套路:降低置信度高的样本(包括正負樣本)的权重,对原始 BCE Loss 加权
p_t = prob * targets + (1 - prob) * (1 - targets)
loss = ce_loss * ((1 - p_t) ** gamma)
# 对正负样本加权
if alpha >= 0:
alpha_t = alpha * targets + (1 - alpha) * (1 - targets)
loss = alpha_t * loss
return loss.mean(1).sum() / num_boxes
以上就是DN DETR的主要代码,总而言之,一方面去噪任务中Query与GT是确定性关系,避免了匈牙利匹配带来的不稳定;另外一方面,多个去噪Groups的设置,相当于引入了One-to-Many的学习方式,使得模型学习更加充分。优化有网络的收敛速度和精度都有明显提升:

2. DINO
DINO发表于2023年3月份,该模型的主要从Contrastive Denosing、Mix Query Slection和Look Forward Twice三个方面进行优化,第一次让DETR系列的检测器取得了目标检测SOTA性能。下面我们从这三个方面依次展开学习下细节:
2.1 Contrastive Denoising
在DN DETR中的去噪部分,我们为每一个真值都分配了一组带不同噪声的Query,作者认为这样会导致所有和去噪相关的Query只会学习正样本,而缺少了对负样本的学习。因此对于噪声较大的Query,我们就应该认为其为负样本,在去噪任务中监督‘No Object’类别,如下图所示:

如上右图所示,训练过程中会设置两个超参
λ
1
\lambda_1
λ1和
λ
2
\lambda_2
λ2,当噪声水平小于
λ
1
\lambda_1
λ1时,我们就认为其是正样本,当噪声水平大于
λ
1
\lambda_1
λ1并且小于
λ
2
\lambda_2
λ2时,我们就认为其是负样本,负责预测‘No Object’类别。并且作者在论文中提到,
λ
2
\lambda_2
λ2也会设置得比较小,这样可以使得Query去学会区分位于真值附近的负样本难例,进一步抑制模型对同一目标输出重复框,如下图所示,左图是DN DETR的检测结果,在箭头所指的小男孩区域网络输出了三个重叠的检测框,但是在右侧DINO的检测结果中这个问题得到了改善:

在训练过程中,每个去噪Group会有
2
×
n
2\times n
2×n个Queries,对于正样本的监督对Box回归仍然是采用L1和GIOU Loss,分类仍然是采用Focal Loss,对于负样本则仅使用Focal Loss对分类进行监督。
3.2 Mix Query

在原始DETR和DN DETR中,在训练和推理的过程中Decoder Content Queries都是初始化为全0的Tensor并不会从Encoder Features里面获取任何信息,而Positional Queries则是一个通过nn.Embedding初始化并且可学习的Tensor;Deformable DETR的Decoder中Content Quires和Positional Queries均是可学习的,为了进一步提高性能,Deformable DETR可以执行一个二阶段的筛选,从Encoder输出的Feature中选择得分Top K的特征Tensor来作为Decoder Quries的先验。
在DINO DETR将上述两种方式进行了混合,Positional Quires从Encoder的Top K的特征中进行初始化,而Content Queries仍然初始化为全为0的Tensor,作者认为,Encoder输出的特征还没有进过Decoder的Refinement,作为Content先验会导致混淆,比如一个选择的Feature可能包括多个物体或者一个物体的一部分,但是作为Positional Queris先验是可以帮助更好地去从Encoder中获取信息的。
3.3 Look Forward Twice

在Deformable DETR中,为了稳定训练过程在Iterative Box Refinement在会进行Gradient Detached,上图虚线表示的就是Gradient Detached的位置,在Look Forward Once模式中,第
i
i
i层的参数只会被第
i
i
i层的Auxiliary Loss所更新,但是作者认为,结合上一层的Refinement信息来对当前层的Box进行预测会更有帮助,因此在Look Forward Twice模式中,第
i
i
i层的参数会同时被第
i
i
i层和第
i
+
1
i+1
i+1层的Auxiliary Loss所影响,具体影响方式如下:
对于每一层的预测 b i ( p r e d ) b_i^{(pred)} bi(pred)的精度主要由当前层的初值 b i − 1 b_{i-1} bi−1(即上一层的预测值)和当前层的预测偏移 Δ b i \Delta b_i Δbi两部分决定,对于Look Forward Once,第 i i i层的Auxiliary Loss产生的梯度仅更新预测偏移 Δ b i \Delta b_i Δbi,梯度信息会在第 i i i层到第 i − 1 i-1 i−1层中被Detach掉;但是对于Look Forward Twice,则同时更新当前层的初值 b i − 1 b_{i-1} bi−1和当前层的预测偏移 Δ b i \Delta b_i Δbi两部分,如何更新初值 b i − 1 b_{i-1} bi−1呢?最简单的办法就是直接将 b i − 1 b_{i-1} bi−1 Gradient Detach前的 b i − 1 ′ b_{i-1}^{\prime} bi−1′和 Δ b i \Delta b_{i} Δbi相加作为第 i i i层的输出,如下步骤所示: Δ b i = Layer i ( b i − 1 ) \Delta b_i=\operatorname{Layer}_{\mathrm{i}}\left(b_{i-1}\right) Δbi=Layeri(bi−1) b i ′ = Update ( b i − 1 , Δ b i ) b_i^{\prime}=\operatorname{Update}\left(b_{i-1}, \Delta b_i\right) bi′=Update(bi−1,Δbi) b i = Detach ( b i ′ ) b_i=\operatorname{Detach}\left(b_i^{\prime}\right) bi=Detach(bi′) b i (pred) = Update ( b i − 1 ′ , Δ b i ) b_i^{\text {(pred) }}=\operatorname{Update}\left(b_{i-1}^{\prime}, \Delta b_i\right) bi(pred) =Update(bi−1′,Δbi)其中 Update ( ⋅ , ⋅ ) \operatorname{Update}(\cdot, \cdot) Update(⋅,⋅)是通过预测的偏移 Δ b i \Delta b_i Δbi更新 b i − 1 b_{i-1} bi−1。
如下是各个模块带来的收益,可以看到Mixed Query Selection、Contrastive Denoising,Look Forward Twice分别带来了0.5,0.5和0.4的提高
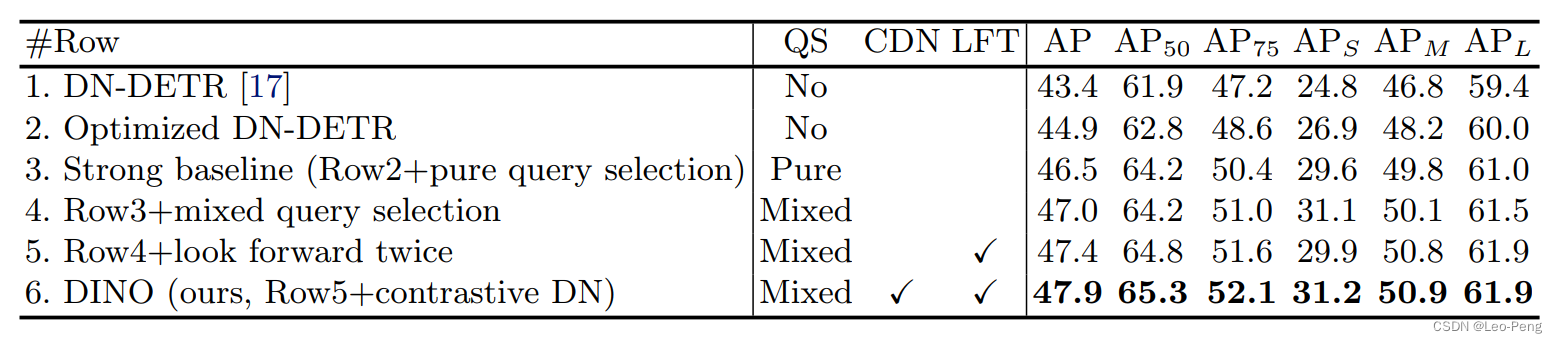
最终,DINO的和其他SOTA方法的对比如下:
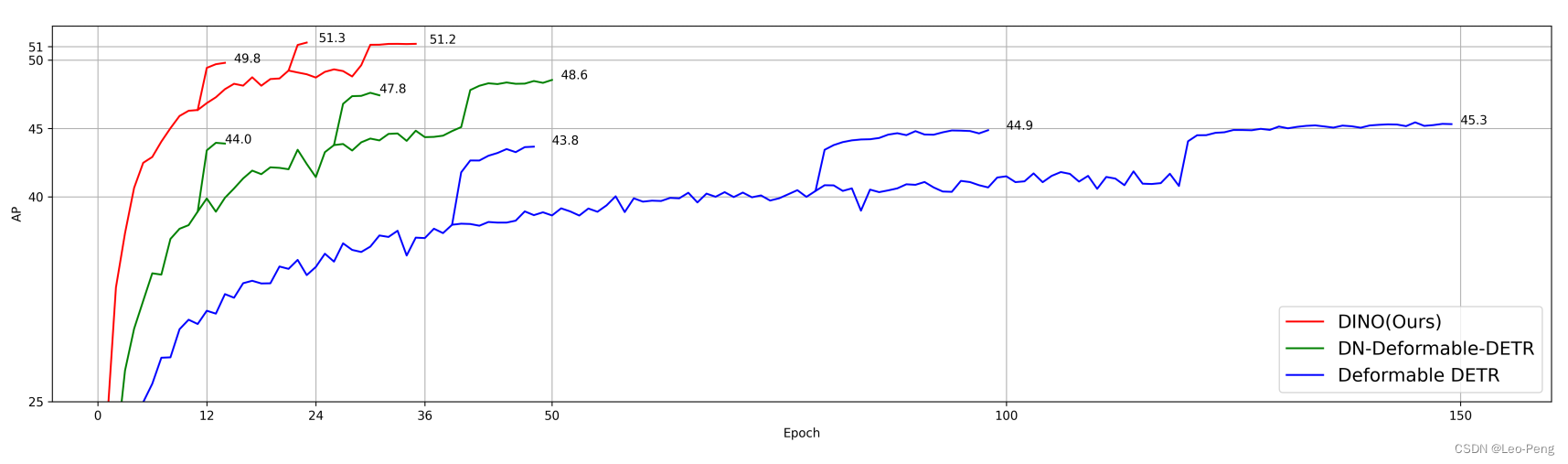
3. Sparse DETR
Sparser DETR发表于ICLR 2022,前面的文章优化的角度主要是如何加快DETR训练的收敛速度和收敛精度,而本文考虑的主要是如何优化推理速度,主要贡献是通过Sparse Query的方式降低Encoder复杂度,从而在Deformable DETR的基础上将推理速度提高了38%
3.1 Encoder Token Sparsification
作者在文章中首先分析到Deformable DETR使用多尺度特征虽然提高了检测器的性能,但是同时也增加了更多的Query,导致Deformable DETR的推理速度实际上比原始DETR还要慢。而实际上我们检测的图像通常包含大量的背景区域,背景区域的Query和前景区域的Query被同等对待会造成大量的冗余计算,在Deformable DETR中使用Two Stage模式证明了仅使用前景区域的Query可以实现更好的检测性能,在本文中,作者通过实验发现:
- 在COCO数据集上对一个完全收敛的Deformable DETR进行推理,发现Decoder相关的Encoder中的Token数量仅占总数量的45%
- 从头重新训练一个新的检测器,但是只更新部分Encoder Token,这些Encoder Token是根据另外一个已经充分训练好的检测器的Decoder挑选的,新训练的检测器大约只有0.1AP的性能损失。
由此可见对Encoder Token进行稀疏化是一个可行的优化方向,那么如何进行稀疏化呢?本文Sparse DETR,主要网络结构如下:

Sparse DETR中核心的三个模块分别是Scoring Network,Encoder Auxiliary Loss和Top-K Decoder Queries,下面分别介绍
3.2 Scoring Network
Scoring Network的作用是输入一个Encoder的特征 x feat \mathbf{x}_{\text {feat }} xfeat 和保留比例 ρ \rho ρ,输出的是特征 x feat \mathbf{x}_{\text {feat }} xfeat 中每个Token的显著度,其中满足前 ρ % \rho \% ρ%显著度的区域定义为 Ω s ρ \Omega_s^\rho Ωsρ,对于第 i i i层的Layer更新第 i − 1 i-1 i−1层特征 x i − 1 \mathbf{x}_{i-1} xi−1的方式如下: x i j = { x i − 1 j j ∉ Ω s ρ LN ( FFN ( z i j ) + z i j ) j ∈ Ω s ρ , where z i j = LN ( DefAttn ( x i − 1 j , x i − 1 ) + x i − 1 j ) , \mathbf{x}_i^j= \begin{cases}\mathbf{x}_{i-1}^j & j \notin \Omega_s^\rho \\ \operatorname{LN}\left(\operatorname{FFN}\left(\mathbf{z}_i^j\right)+\mathbf{z}_i^j\right) & j \in \Omega_s^\rho, \text { where } \mathbf{z}_i^j=\operatorname{LN}\left(\operatorname{DefAttn}\left(\mathbf{x}_{i-1}^j, \mathbf{x}_{i-1}\right)+\mathbf{x}_{i-1}^j\right),\end{cases} xij={xi−1jLN(FFN(zij)+zij)j∈/Ωsρj∈Ωsρ, where zij=LN(DefAttn(xi−1j,xi−1)+xi−1j),即属于高显著度区域的Token通过Deformable Attention进行Refine,而属于低显著度区域的Token则直接透传。
那么如何训练Scoring Network或者说如何定义显著度这个指标呢?
在介绍最终的方法前,论文中首先提到了一种使用Objectness Score的方法,Objectness Score指的是在Backbone的Feature上直接接一个和最终检测头相同的结构的检测头,并同样使用匈牙利计算损失,这个检测头输出的前 ρ % \rho \% ρ%得分的检测结果就可以作为高显著度区域 Ω s ρ \Omega_s^\rho Ωsρ,这个方法是简单有效的,但是问题也很明显,其计算高显著度区域的过程中完全没有考虑到Decoder
在本文中是使用Transfomer中的Decoder Cross Attention Map(DAM)进行定义的,使用DAM的原因是在训练过程中Decoder的Attention就是逐步集中到到Encoder输出Token的部分子集上的,这和我们想要的显著度的定义一脉相承。在Dense Attention中,DAM可以直接通过将各层Decoder Layer中的Attention Map相加,在Deformable Attention中,DAM可以将Offsets和Encoder Tokens相关的Object Queries的Attention Weights进行累加。 然后我们将这些累加获得的DAM作为伪真值建立一个BCE损失来训练一个Scoring Network:
L
dam
=
−
1
N
∑
i
=
1
N
BCE
(
g
(
x
feat
)
i
,
D
A
M
i
b
i
n
)
\mathcal{L}_{\text {dam }}=-\frac{1}{N} \sum_{i=1}^N \operatorname{BCE}\left(g\left(\mathbf{x}_{\text {feat }}\right)_i, \mathrm{DAM}_i^{\mathrm{bin}}\right)
Ldam =−N1i=1∑NBCE(g(xfeat )i,DAMibin)上述流程可以通过下图进行总结:

论文中提到,可能有的同学会觉得在训练前期,Decoder收敛效果不好可能会影响到DAM的准确性,但是通过实验就是证明使用DAM会比Objectness Score效果要好,如下图所示:

3.3 Encoder Auxiliary Loss and Top-K Decoder Queries
在DETR中,Auxilary Loss通常是加载Decoder Layer上,在Encoder中由于Encoder Token的数量太多,Encoder Auxiliary Loss将会带来巨大的计算量,但是在Sparse DETR中,由于Encoder Token已经被稀疏化,因此添加Auxiliary Loss并不会造成过大的负担,因此在Spase DETR中添加了Encoder Auxiliary Loss帮助区分Encoder中的混淆特征,进一步提高模型的最终检测性能,如下左图就体现了添加了Auxiliary Loss的收益:

在Deformable DETR的Two Stage模式中,是通过Decoder的检测头对Encoder的Feature进行打分,然后选取部分Feature进行Object Query的初始化,在Sparser DETR中,由于我们加了Auxiliary Loss,因为我们可以通过Auxiliary Detection Head对Encoder输出的特征进行打分,然后选取部分作为Decoder Queries的初始化。
综上所述是Sparse DETR的主要内容,如下是精度和效率对比:

可以看到,Sparse DETR在FPS提高的基础上,AP相对于Deformable DETR并没有下降。总而言之,Sparse DETR主要是通过添加一个Scoring Network输出一个Deformable Attention Map来对Encoder Token进行稀疏化,正式由于稀疏化带来的好处,进一步引入了Encoder Auxiliary Loss和Top-K Decoder Queries来提升网络性能。
4. Lite DETR
Lite DETR发表于CVPR 2023,通Sparse DETR一样,Lite DETR考虑的主要是如何优化推理速度,在本文中通过Interleaved Update和Key-aware Deformable Attention使得在降低60%的GFLOPS的基础上保持了99%的检测精度
4.1 Motivation and Analysis
Multi Scale Features对于DETR的精度提升是重要的,但是高分辨率特征的Token的数量是低分辨率的4倍,在DINO中,如果去掉 1 / 8 1/8 1/8分辨率(高分辨率)Feature上的Token的话将在GLOPS上减少48%,但是AP也会损失4.9%,在小目标AP上的损失甚至会达到10.2%。作者认为**,高分辨率特征只拥有的是局部信息更容易收敛,并且在多尺度特征训练的过程中,这些局部信息是会有冗余的**,因此作者考虑是否有办法在训练过程中更加关注与低分辨率特征的更新,减少高分辨率特征更新计算同时保持整个网络的性能。
4.2 Interleaved Update
论文将多尺度特征
S
S
S划分为低层级特征(高分辨率)
F
L
∈
R
N
L
×
d
model
F_L \in \mathbb{R}^{N_L \times d_{\text {model }}}
FL∈RNL×dmodel 和高层级特征(低分辨率)
F
H
∈
R
N
H
×
d
model
F_H \in \mathbb{R}^{N_H \times d_{\text {model }}}
FH∈RNH×dmodel ,
N
H
N_H
NH和
N
L
N_L
NL分辨是两者的Token数量,其中
N
H
≈
6
%
∼
33
%
N
L
N_H \approx 6 \% \sim 33 \% N_L
NH≈6%∼33%NL,在Lite DETR的网络结构中,会在更新
A
A
A次高层级特征
F
H
F_H
FH后只更新
1
1
1次低层级特征
F
L
F_L
FL,这种更新方式就被定义为Interleaved Update。

对于高层级特征的更新方式如下: Q = F H , K = V = Concat ( F H , F L ) \mathbf{Q}=F_H, \mathbf{K}=\mathbf{V}=\operatorname{Concat}\left(F_H, F_L\right) Q=FH,K=V=Concat(FH,FL) F H ′ = K D A ( Q , K , V ) F_H^{\prime}=K D A(\mathbf{Q}, \mathbf{K}, \mathbf{V}) FH′=KDA(Q,K,V) Output = Concat ( F H ′ , F L ) \text { Output }=\text { Concat }\left(F_H^{\prime}, F_L\right) Output = Concat (FH′,FL)其中 K A D KAD KAD为Key-aware Deformable Attention,下文将介绍。 Q \mathbf{Q} Q是高层级特征, K \mathbf{K} K和 V \mathbf{V} V为高低层级特征,输出则是将更新后的高层级特征 F H ′ F_H^{\prime} FH′和未更新的低层级特征 F H ′ F_H^{\prime} FH′Concate结果,在这个过程中,高层级特征和高层级特征进行Attention时类似于Self Attention,在和低层级特征进行Attention时类似于Cross Attention。
对于低层级特征的更新方式如下: Q = F L , K = V = Concat ( F H ′ , F L ) \mathbf{Q}=F_L, \mathbf{K}=\mathbf{V}=\operatorname{Concat}\left(F_H^{\prime}, F_L\right) Q=FL,K=V=Concat(FH′,FL) F L ′ = K D A ( Q , K , V ) F_L^{\prime}=K D A(\mathbf{Q}, \mathbf{K}, \mathbf{V}) FL′=KDA(Q,K,V) Output = Concat ( F L ′ , F H ′ ) \text { Output }=\text { Concat }\left(F_L^{\prime}, F_H^{\prime}\right) Output = Concat (FL′,FH′)其中 F H ′ F_H^{\prime} FH′和 F L ′ F_L^{\prime} FL′分别为更新后的高层级特征和低层级特征。为了进一步减小计算量,在Deformable Attention计算时使用的Feed Forward的隐藏层通道数也进行了适当的减小。
4.3 Key-aware Deformable Attention
在原始的Deformable DETR中,Query
Q
Q
Q将会被划分为
M
M
M个Head,每个Head将在
L
L
L层特征上分别生成
K
K
K个点作为Value,因此每个Query的采样点总数为
N
v
=
M
×
L
×
K
N_v=M \times L \times K
Nv=M×L×K,其Sample的Offset
Δ
p
\Delta p
Δp和对应的Attention Weights都是直接从Query通过两个线性映射层
W
p
∈
R
d
model
×
N
v
∈
R
d
model
×
d
model
W^p\in \mathbb{R}^{d_{\text {model }} \times N_v}\in \mathbb{R}^{d_{\text {model }} \times d_{\text {model }}}
Wp∈Rdmodel ×Nv∈Rdmodel ×dmodel 和
W
A
W^A
WA生成的:
Δ
p
=
Q
W
p
\Delta p=\mathbf{Q} W^p
Δp=QWp
V
=
Samp
(
S
,
p
+
Δ
p
)
W
V
\mathbf{V}=\operatorname{Samp}(S, p+\Delta p) W^V
V=Samp(S,p+Δp)WV
DeformAttn
(
Q
,
V
)
=
Softmax
(
Q
W
A
)
V
\operatorname{DeformAttn}(\mathbf{Q}, \mathbf{V})=\operatorname{Softmax}\left(\mathbf{Q} W^A\right) \mathbf{V}
DeformAttn(Q,V)=Softmax(QWA)V这个过程中,Query在不与Key进行交互的前提下就决定了每个采样点的重要性,这是因为在原始的Deformable DETR中,在Encoder中,因为所有的Multi-Scale Features都会作为Queries参与Self Attention,因此能快速地知道每个采样的重要性。但是在Lite DETR中,由于每次更新只有部分尺度的Feature参与,因此很难同时决定采样点以及每个采样点的重要性,因此本文还提出了一个Key-aware Deformable Attention,如下:
V
=
S
a
m
p
(
S
,
p
+
Δ
p
)
W
V
\mathbf{V}=S a m p(S, p+\Delta p) W^V
V=Samp(S,p+Δp)WV
K
=
Samp
(
S
,
p
+
Δ
p
)
W
K
\mathbf{K}=\operatorname{Samp}(S, p+\Delta p) W^K
K=Samp(S,p+Δp)WK
K
D
A
(
Q
,
K
,
V
)
=
Softmax
(
Q
K
T
d
k
)
V
K D A(\mathbf{Q}, \mathbf{K}, \mathbf{V})=\operatorname{Softmax}\left(\frac{\mathbf{Q K}^T}{\sqrt{d_k}}\right) \mathbf{V}
KDA(Q,K,V)=Softmax(dkQKT)V这个其实就普通的Cross Attention保持一致,这样有Key参与能更好地帮助不同尺度特征进行更新。

以上就是Lite DETR的主要内容,在论文中作者还和Sparse DETR进行了对比,Sparse DETR的三个缺点如下:
- 难以在不同模型中进行泛化;
- 由于优先并且隐式监督,Scoring Network的输出不一定是最优的;
- 需要引入诸如Auxiliary Encoder Detection Loss类的其他的结构;
相比之下,Sparse DETR的改动确实要少些,Sparse DETR和其他SOTA方法对比如下:
总而言之,Lite DETR是通过实现高层级特征和低层级特征的迭代更新来减少冗余的特征更新,为了保证更新的准确性而引入了Key-aware Deformable Attention,进而减小计算量。