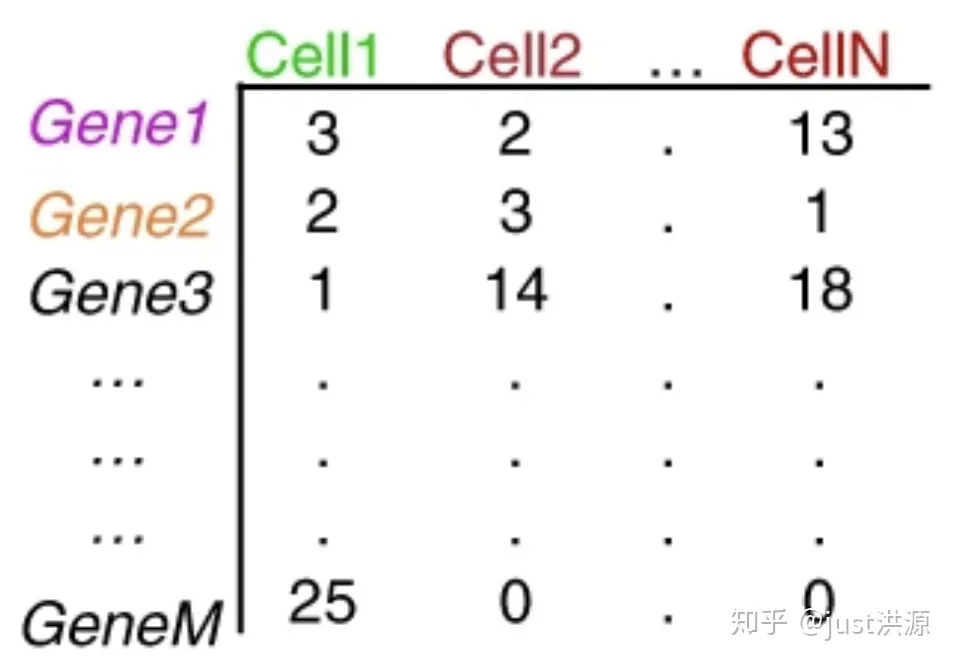
作此篇的原因是17年19题:

本题选A,做的时候总感觉不够通透,因此把这题涉及到的内容全部看了一遍,顿时没有那种朦胧感了
零、五段式流水线:
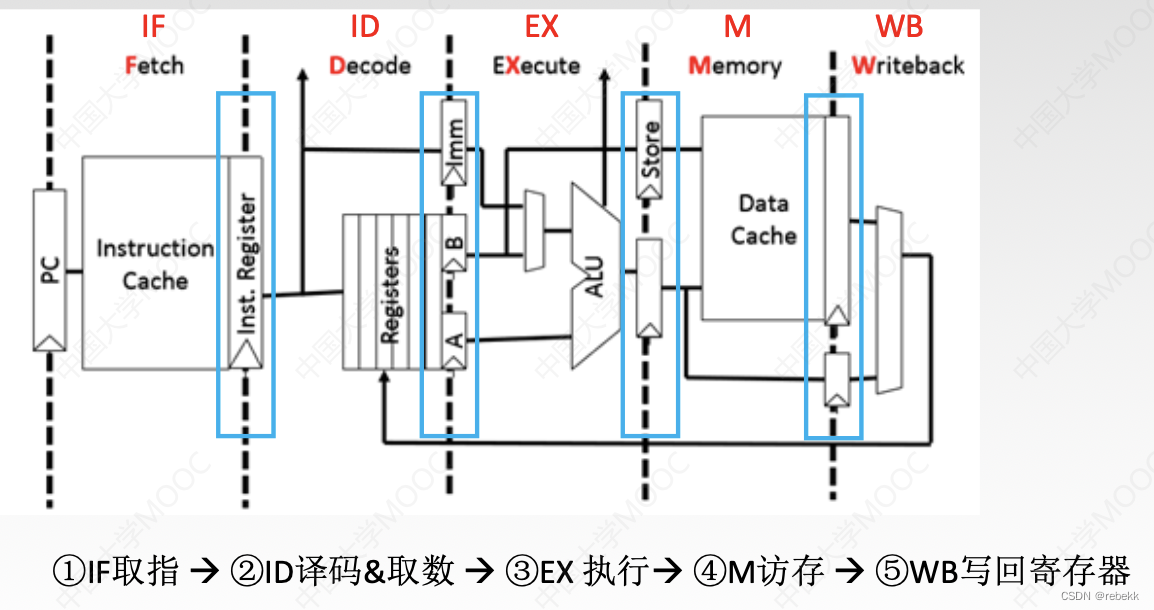
以下均为MIPS设定:指令长度为32位,主存按字节编址(所以指令地址总是4的倍数,即最后两位是00),因此PC中只需存放前32位地址,即PC<31:2>(0,1,2,…,31中的2~31)
取下条指令=整个地址+4=PC<31:2>+1
一、运算类指令
- 运算类指令类型:
- 加法指令(两个寄存器相加):
add rd, rs, rt:R[rs]+R[rt]->R[rd] - 加法指令(寄存器与立即数相加):
addiu rt, rs, imm16:R[rs]+SEXT(imm16)->R[rt] - 算数左移指令:
SHL Rd:(Rd)<<<2->Rd
- 加法指令(两个寄存器相加):
- R型指令(即类型1)的执行过程
- IF阶段:根据PC从指令Cache取指令到IF段的寄存器
- ID阶段:取出操作数至ID段寄存器
- EX阶段:运算,将结果存入EX段寄存器
- M阶段:空段
- WB:将运算结果写回指定寄存器
- R型指令的数据通路:
R[rs]+R[rt]->R[rd]
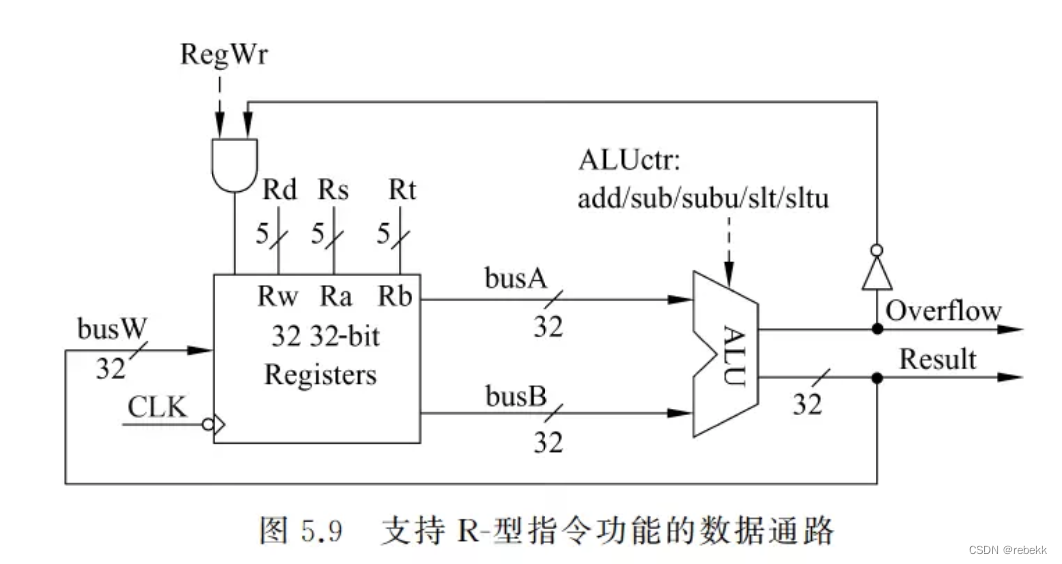
- Rs和Rt是两个源操作数寄存器编号,Rd是目的寄存器编号。因此寄存器堆的两个读地址端Ra和Rb分别与Rs与Rt相连,写地址端Rw与Rd相连。
- ALU运算结果连到寄存器堆的写数据端busW
- 控制信号RegWr为“写使能”信号,只有在RegWr信号为1且不溢出的情况下,运算结果才写入寄存器堆,显然R型指令执行时,RegWr信号应该为1
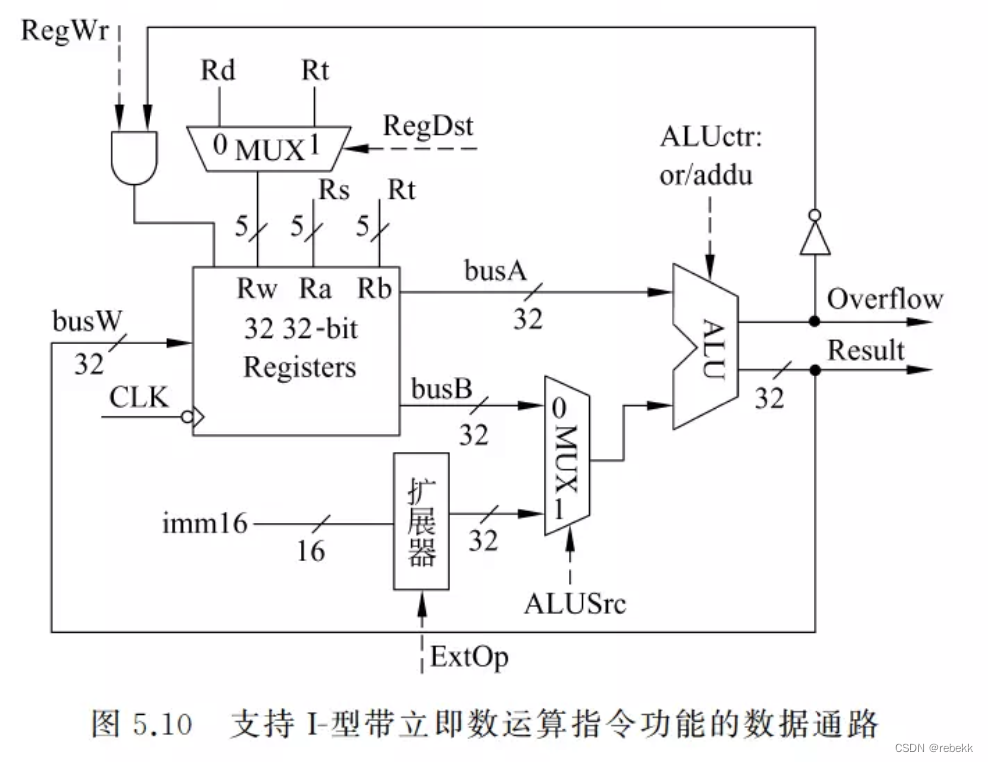
- I型指令的数据通路(即类型2)
R[rs]+SEXT(imm16)->R[rt],在R型指令数据通路的基础上,改动如下:- 因为R型指令和I型指令的目的寄存器不同,所以在寄存器堆的写地址端Rw处,增加了一个多路选择器,由控制信号RegDst控制选择Rd为目的寄存器还是Rt为目的寄存器
- 因为I型指令的立即数只有16位,需要对其扩展为32位才能送到32位ALU运算。对于按位逻辑运算,应采用零扩展,对于算术运算,应采用符号扩展。因此在数据通路中应增加一个扩展器,由控制信号ExtOp控制进行符号扩展还是零扩展
- 因为R型指令和I型指令在ALU的B口的操作数来源不同,所以在ALU的B输入端增加了一个多路选择器,由控制信号ALUSrc控制选择busB还是扩展器输出作为ALU的B口操作数
二、LOAD指令
lw rt, rs, imm16:R[rs]+SEXT(imm16)->Addr;M[Addr]->R[rt]
- 执行过程:
- IF阶段:根据PC从指令Cache取指令到IF段的寄存器
- ID阶段:将基址寄存器的值放到寄存器A,将偏移量的值放到Imm
- EX阶段:运算得到有效地址,将结果存入EX段寄存器
- M阶段:从数据Cache种取数并放入寄存器
- WB:将取出的数写回指定寄存器
三、STORE指令
sw rt, rs, imm16:R[rs]+SEXT(imm16)->Addr;R[rt]->M[Addr]
- 执行过程:
- IF阶段:根据PC从指令Cache取指令到IF段的寄存器
- ID阶段:将基址寄存器的值放到寄存器A,将偏移量的值放到Imm,将要存的数放到B
- EX阶段:运算得到有效地址,将地址存入EX段寄存器,并将寄存器B的内容放到寄存器Store
- M阶段:写入数据Cache
- WB:空段
- 数据通路:
- 流程:load指令和store指令的地址计算过程一样,都要先对立即数进行符号扩展,然后和基址寄存器的内容相加,得到访存地址。load指令是从该地址中读取一个数送到寄存器,store指令则相反
- 支持load/store指令功能的数据通路图:
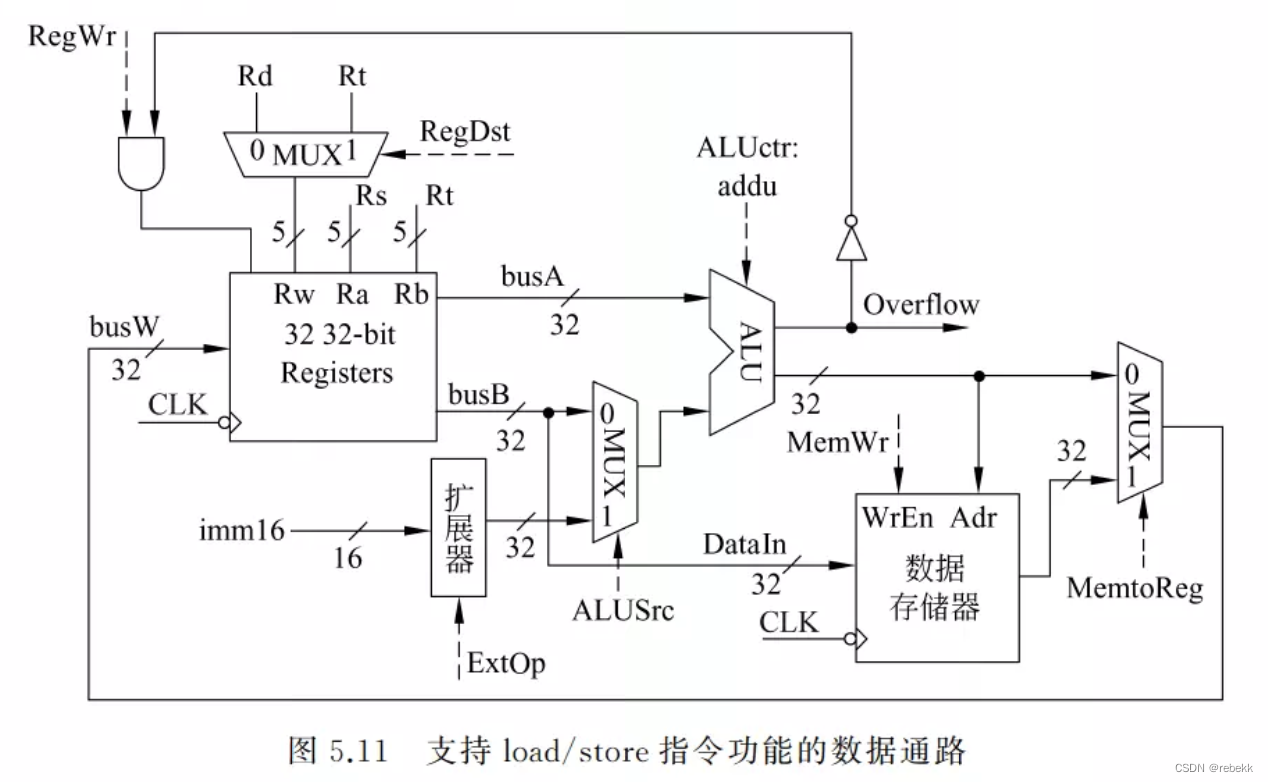
在I型指令数据通路的基础上,改动如下:- 因为运算类指令和load指令写入目的寄存器的结果的来源不同,所以在寄存器堆的写数据端busW处增加了一个多路选择器,由控制信号MemtoReg控制选择将ALU结果还是存储器读出数据写入目的寄存器
- 因为load/store指令需要读写数据存储器,故增加了数据存储器。访存地址在ALU中计算,因此数据存储器的地址端Adr连到ALU的输出。store指令将Rt内容送存储器,所以直接将busB连到数据存储器的DataIn输入端,而将输出端连到busW端的多路选择器上。控制信号MemWr用作“写使能”信号。load/store指令的地址运算对立即数进行符号扩展,ALUctr输入端的操作类型是不判溢出的加法addu
四、分支指令(条件转移指令)
beq rs, rt, imm16:R[rs]-R[rt]->Cond;if (Cond eq 0) PC+(SEXT(imm16)x4)->PC
- 执行过程:
- IF阶段:根据PC从指令Cache取指令到IF段的寄存器
- ID阶段:将进行比较的两个数放入寄存器A、B,偏移量放入Imm
- EX阶段:运算,比较两个数
- M阶段:将目标PC值写回PC(很多教材把写回PC的功能段称为“WrPC段”,因其耗时比M段更短,因此可安排在M段时间内完成)
- WB:空段
- 取指令部件的设计:
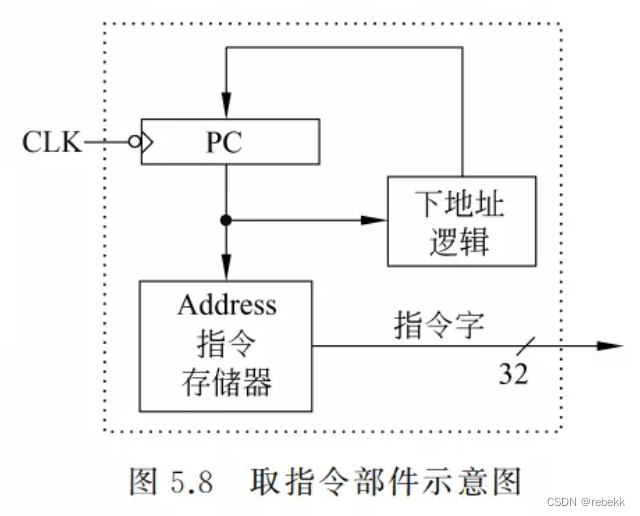
- 指令专门存放在指令存储器中,只有读操作。只需给出指令地址,经过一定的“取数时间”后,指令被送出。因为讨论的前提是单周期处理器(一个时钟周期完成一条指令),所以每来一个时钟,PC的值都会被更新一次,因而PC无需“写使能”信号控制
- 指令的地址来自PC,有专门的下地址逻辑来计算下条指令的地址,然后送PC。下地址逻辑中,要区分是顺序执行还是转移执行:若是顺序执行,则执行PC+4,若是转移执行,则要根据当前指令是分支指令还是跳转指令来计算转移目标地址
- 顺序执行时:PC<31:2>+1->PC<31:2>
- 跳转执行时:PC<31:2>+1+SEXT[imm16]->PC<31:2>
- 取指令时:指令地址=PC<31:2>||00
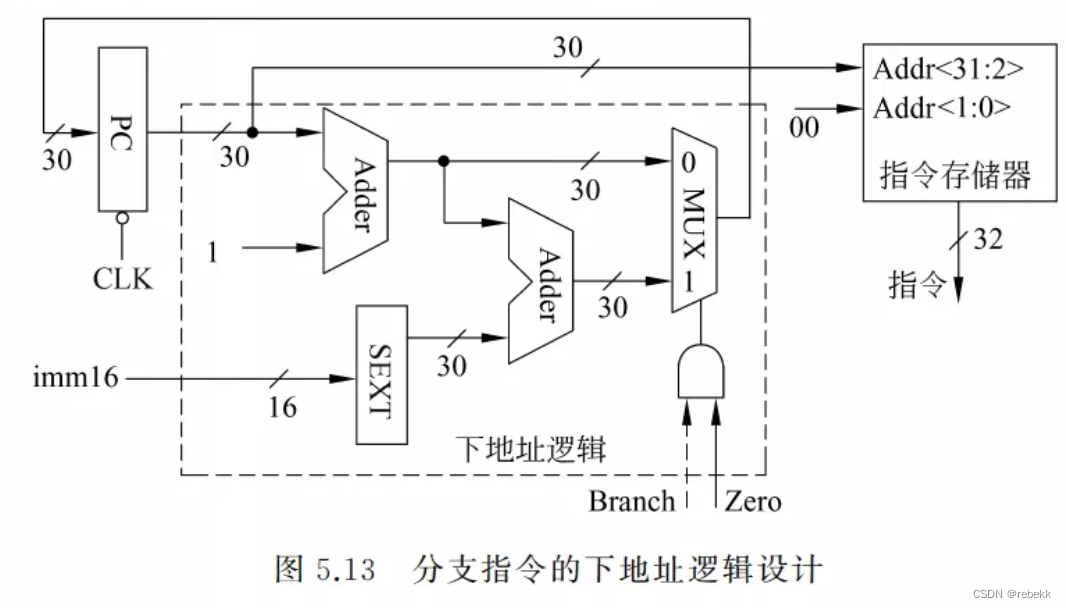
- 数据通路:

在load/store型指令数据通路的基础上,增加beq指令功能:- (与图5.11相比)主要增加了取指令部件,转移目标地址的计算在下地址逻辑中实现,在ALU中执行的是不判溢出的减法操作subu
- 下地址逻辑的输出是下条指令地址,4个输入是PC、Zero标志、立即数imm16、控制信号Branch
- Zero标志:在ALU中对R[Rs]和R[Rt]做减法得到一个Zero标志,根据Zero标志可判断是否转移
- 目标地址的计算:先对立即数imm16进行符号扩展再乘4,然后和基准地址PC+4相加
- 控制信号Branch:表示当前指令是否是分支指令,也应送到下地址逻辑,以决定是否按分支指令方式计算下条指令地址
- 下图是分支指令的下地址逻辑设计,可看出,每来一个时钟CLK,当前PC作为指令地址被送到指令存储器去取指令的同时,下地址逻辑计算下条指令地址并送PC的输入端,在下个时钟到来后写入PC
五、无条件转移指令(J型指令)
j target:PC<31:28>||target<25:0>->PC<31:2>
这类指令寻址方式只有直接寻址。将当前PC的高4位拼接26位直接地址最后再补充两个0就是跳转的目标地址(因为MIPS是32位定长指令字,所以指令地址一定是4的倍数,即地址最后两位总是0,无需在指令中显式给出)
- 执行过程:
- IF阶段:根据PC从指令Cache取指令到IF段的寄存器
- ID阶段:偏移量放入Imm
- EX阶段:将目标PC值写回PC(很多教材把写回PC的功能段称为“WrPC段”,因其耗时比EX段更短,因此可安排在EX段时间内完成)
- M阶段:
- WB:空段
- 完整的取指令部件(在图5.13分支指令下地址逻辑的基础上)
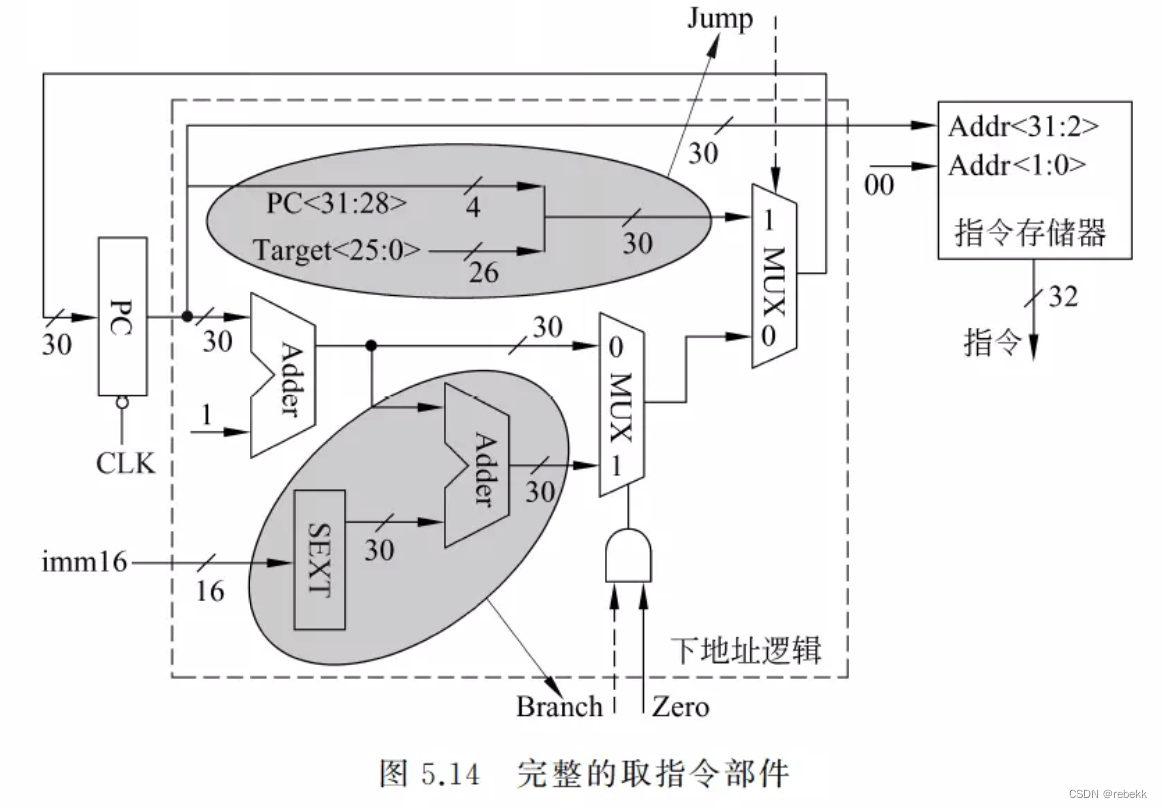
- 跳转目标地址的计算方法:PC<31:28>||target<25:0>->PC<31:2>
- 取指令阶段开始时,新指令还未被取出和译码,因此取指令部件中的控制信号的值还是上条指令产生的旧值,此外新指令还未被执行,因而标志(Zero)也为旧值。不过由这些旧控制信号值确定的地址只被送到PC输入端,并不会写入PC,因此不会影响取指令功能。只要保证在下个时钟CLK到来之前能产生正确的下条指令地址即可
- 取指令部件的输出是指令,输入是标志Zero、控制信号Branch和Jump。下地址逻辑中的立即数imm16和目标地址target<25:0>都直接来自取出的指令。
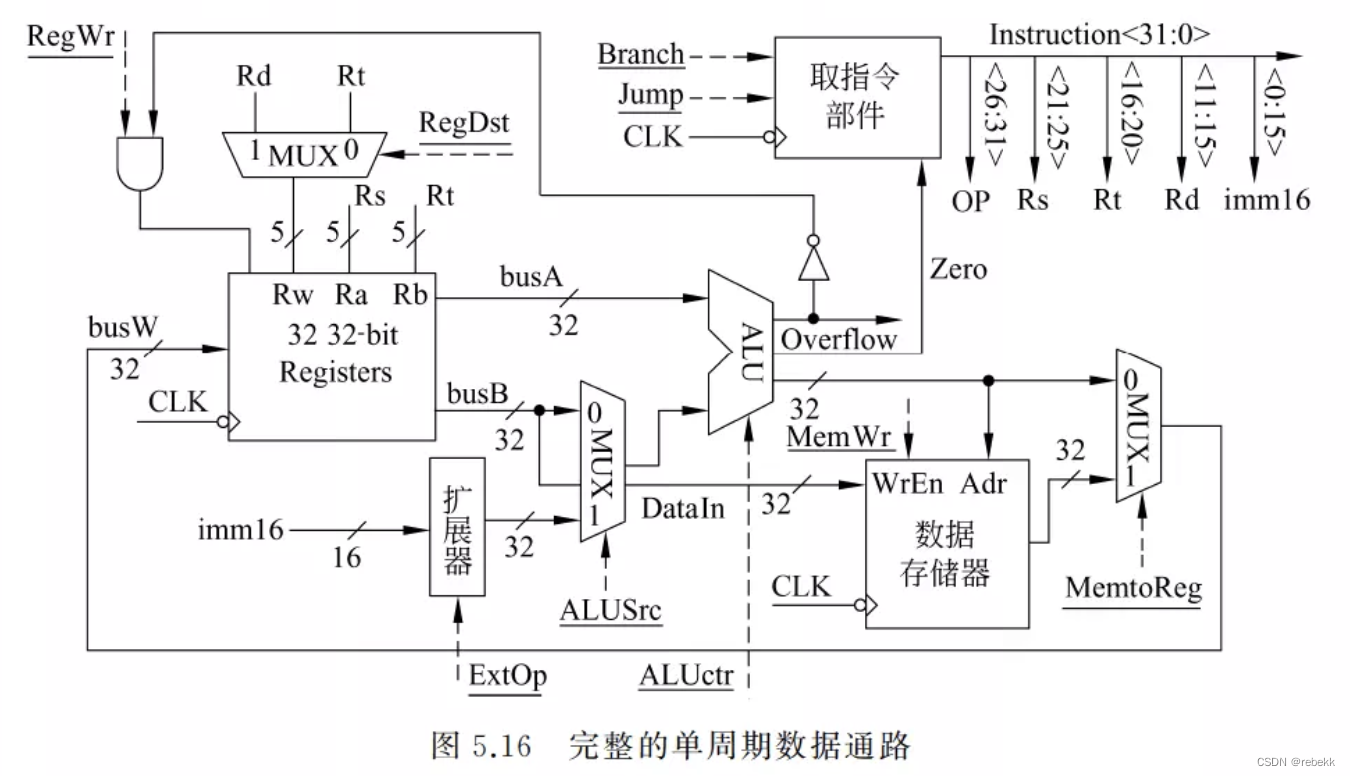
六、综合上述指令的完整数据通路
综合考虑上述所有数据通路的结构,可得到如下图所示的完整单周期数据通路。图中所有加下划线的都是控制信号,用虚线表示。指令执行结果总是在下个时钟到来时开始保存在寄存器、数据存储器或PC中





![[LaTex]arXiv投稿攻略——jpg/png转pdf](https://img-blog.csdnimg.cn/8ef9f1bc654a487db1e8190abe63c82f.png)