这篇文章是港科大团队在PLDI 2021会议上发表的文章。在这之前,作者在PLDI 2018发表Pinpoint。这篇文章在Pinpoint上改进。在Pinpoint的设计中,存储摘要的时候仍然需要缓存大量的路径条件,以及在应用摘要时进行大量的克隆,导致逻辑公式大小进行指数级的增长。
而在PLDI 2021中,作者进一步提出,我们可以不用构建Value Flow Graph了!直接在程序依赖图(Program Dependence Graph)上就可以达到相同的路径敏感检测效果。相比PLDI’18
-
该方法不需要缓存摘要中的路径条件。因为可以在遍历程序依赖图的时候直接将其转换成逻辑公式,即
程序依赖图就已经编码了路径条件。 -
该方法
克隆数比较少。程序依赖图的结构,能够在转换逻辑公式的时候进行大量的优化,降低函数克隆数,加速SMT的预处理。
实验效果:
-
能够在个人PC机上跑百万行代码规模的路径敏感分析。
12GB的内存,半小时内完成百万行分析。 -
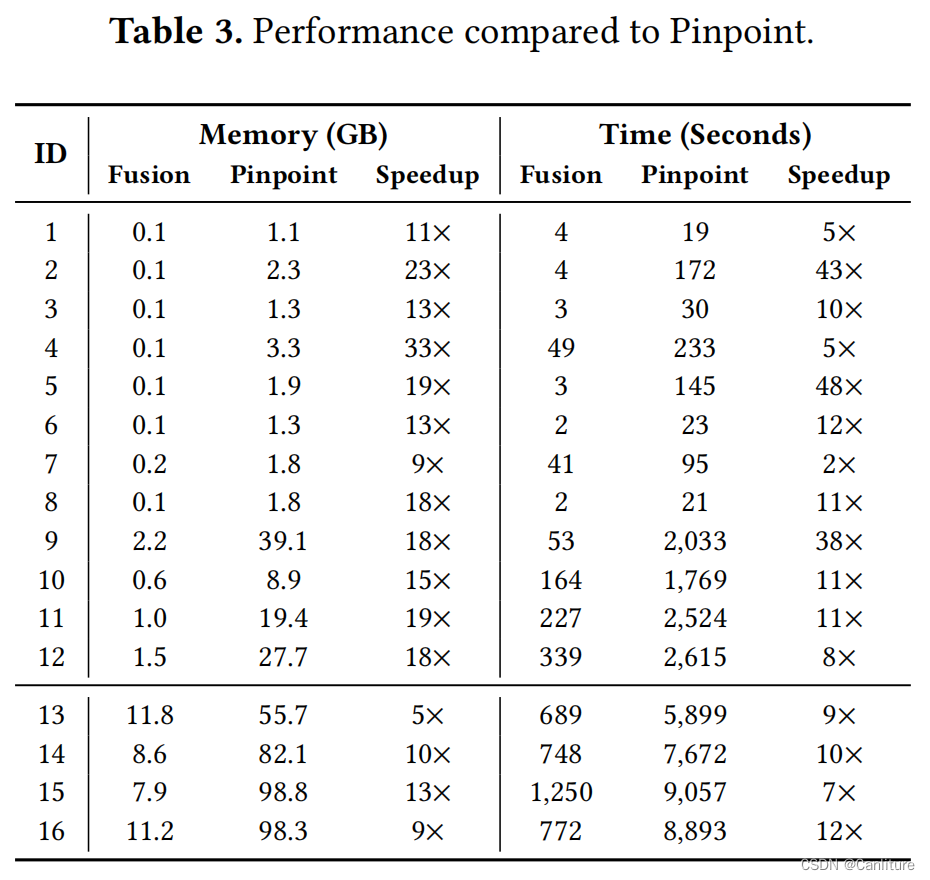
作者对比了两款工具(Pinpoint和Infer),消耗的内存只有他们的10%,但是能够提升10倍的速度。
1. 与Pinpoint对比
(1). 计算路径条件 (Computing)
(2). 求解路径条件 (Solving)
(3). 缓存路径条件 (Caching)
以如下代码为例子,对比Pinpoint三项指标的性能开销时

作者的方法(fusion)和Pinpoint(conventional)的对比如下:

作者在程序依赖图上能够有效地编码相当多的信息:
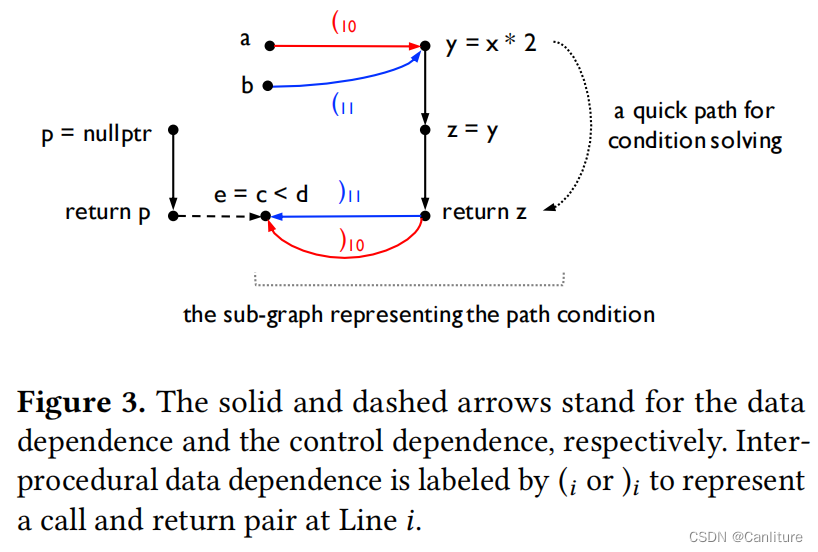
2. 程序依赖图
作者论文中以一个简单语言作为叙述对象,如下所示,比较简单。唯一需要注意的是identity,return,if-then-else。
-
if-then-else语句。表示这个程序是
Gated Single Assignment形式的。Gated Single Assignment公众号前几篇文章有讨论,它被应用在许多缺陷检测工具中,例如:FSE’10 利用符号分析检测缓冲区溢出,ICSE’08 - 路径敏感bug-finding工具Calysto -
identity和return语句。将单个函数内对非局部变量的
修改与使用(MOD/REF)显示化到程序中。 -
作者将代码中循环展开,所以不存在循环语句

程序依赖图用于模块化地表示单个函数内的数据依赖关系,控制依赖关系,程序依赖图的的定义如下:
- G = (V, Ed, Ec)
- V表示程序依赖图上节点的集合。每个节点根据讨论的上下文,可以表示为
一个语句,也可以表示为这个语句定义的变量。 - Ed表示节点间的数据依赖边。source
定义了某个变量,target是使用该变量的语句 - Ec表示节点间的控制依赖边。source为一条语句,target为if语句,表示source的执行依赖于if语句。
构建控制依赖边,现成的算法比较多,这里不介绍。下面是PDG上构建数据依赖边的规则:

这些规则比较简单,唯一需要注意的是左下角的规则,它是用来对未定义的库函数构建默认的数据依赖边。
3. 传统的稀疏分析算法
作者先介绍了传统的稀疏分析算法(即Pinpoint中的算法),然后提出PLDI 2021中作者提出的方法,一对比,就能看出很明显的差异。
下面是Pinpoint中提出的稀疏分析算法:

该算法用于分析一条感兴趣的控制流路径,该路径由语句列表所组成。
- 对每条语句进行遍历,
第4行就是对语句执行transfer function - 然后根据当前语句的数据依赖后继边,将数据传播到后继节点。(
第6行) - 第7-8行是用于保存路径用的,可以进行trace
- 第9行,由于有新的后记节点引入,所以需要把当前语句和后续语句之间的数据依赖条件也进行逻辑与
- 第11行实际上是路径收集的初始化步骤:当行没有前缀路径存在的时候,初始化一条2个节点组成的路径
- 第12行,对所有路径的约束进行逻辑与,并进行约束求解
下面是Pinpoint的函数间分析算法:

- S1表示的是值流摘要 (Value Flow Summary)。具体可参考Pinpoint论文。值流摘要是3元组:

- 有如下4类值流摘要:

- S2表示Pinpoint中提到的Return Value Summary。
- 对于函数间的Value Flow Path,第6行判断是否存在某段Value Flow Summary
- 如果存在,那么直接应用摘要中存储的Summary Tranfer Function,传递数据即可。
- 主要关注的就是
instantiate这个函数,它用于克隆摘要中的路径条件。
4. 基于程序依赖图的稀疏分析算法
Pinpoint中提到的方法需要缓存大量的路径条件,进行大量的条件克隆。作者的方法在这两方面进行了改进。
作者可以在程序依赖图上遍历感兴趣的控制流路径之后,直接生成逻辑公式。下面是函数内逻辑公式生成规则:

看起来比较直观。规则(1)(2)(3)用于切片,实际上就是求数据依赖和控制依赖的传递闭包,其中Xd用于切掉没必要的节点。(4)(5)(6)就是将程序语句转换为逻辑公式,看起来也比较容易理解。这里不细展开。
下面是函数间逻辑公式生成的规则,也比较简单,就是将形参-实参,返回值和reciever作逻辑相等。
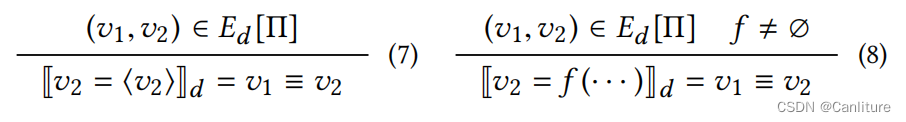
优化后的算法如下,可以看到,Value Flow Summary不再需要缓存大量的路径条件,因为可以直接遍历得到。Return Value Summary也可以直接去掉。同时,不需要再进行大量的路径条件克隆。

下面是整个算法大的执行框架,它由于直接在程序依赖图上进行SMT求解,可以进行很多求解前的预处理优化,具体相关的优化,这里不详细展开,论文也没有细讲。

5. 实验
实验环境
- Intel Xeon CPU E5-2698 v4 @ 2.20GHz
- 256GB, Ubuntu-16.04
- 每个静态分析器15个线程
- SMT求解10秒超时
- 每次分析时,设置阈值:100GB内存,12小时超时时间
Trade-Off:
- 数组联合体的所有成员互为别名
- 不处理全局变量
- 不处理异常, long jump, 内联汇编
- 不处理C式函数指针,C++利用CHA构造调用图
- 调用图与控制流图上的环都展开2次
测试集如下:
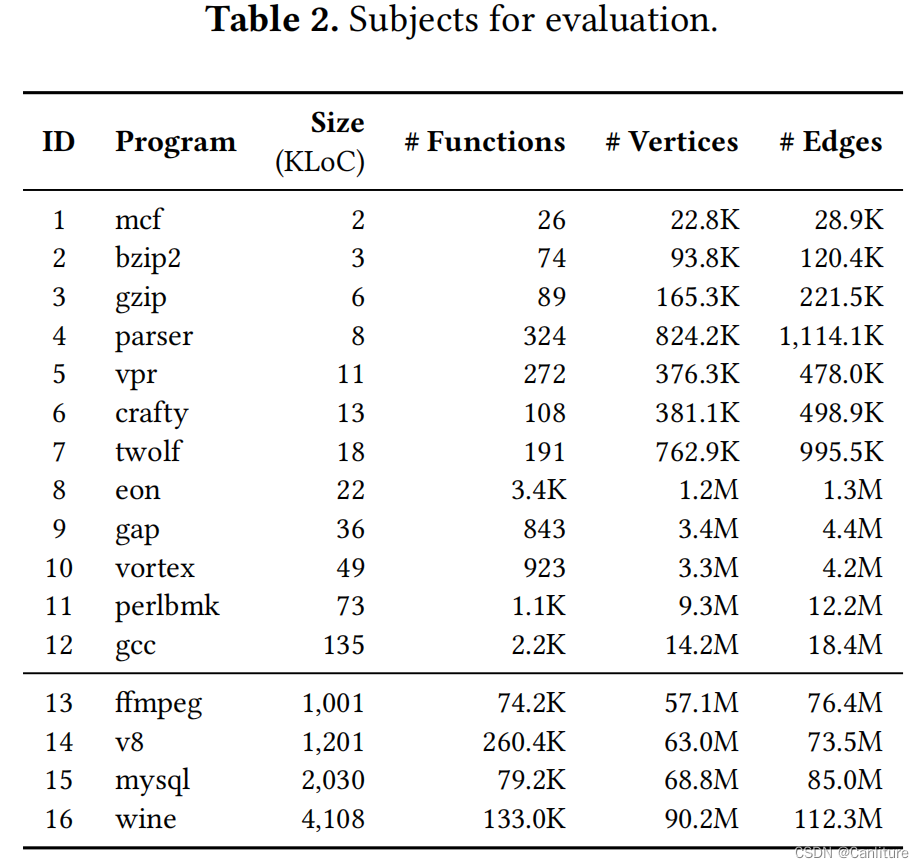
相比Pinpoint的性能:
对比分析能力:
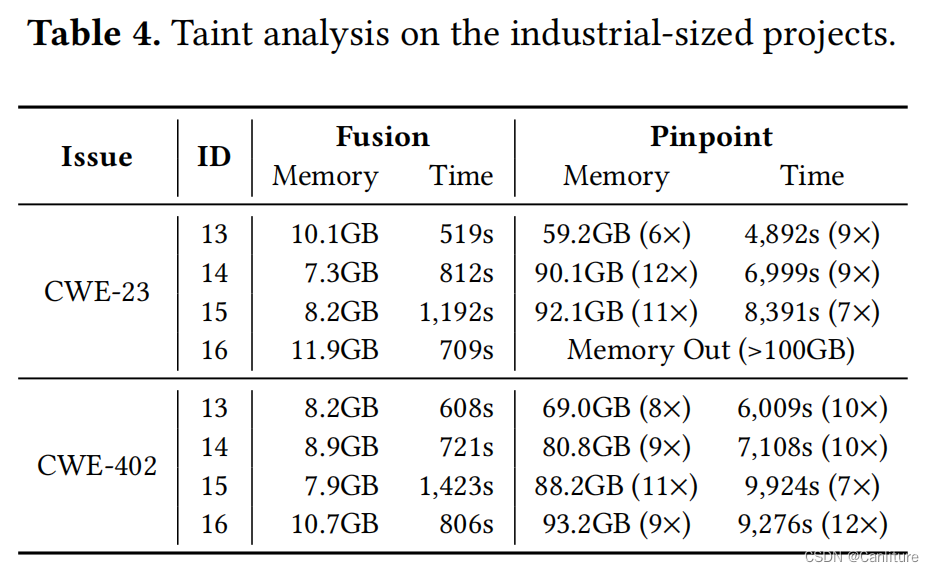
相比Infer的实验数据:
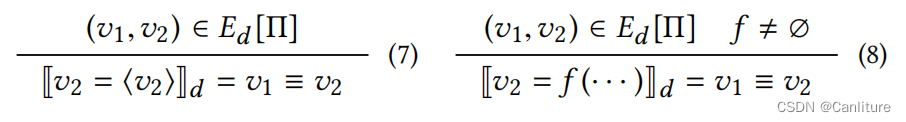
具体还有很多细节可以参考PLDI 2018 Pinpoint与PLDI 2021。