不同于传统的关键词搜索,你不需要给每个视频素材人为地打上标签。使用开源产品 CLIP-as-service,输入画面的描述文本,直接搜索到对应的视频片段。
CLIP 是一个强大的模型,能够很好地判别文本和图片是否相关,但将其集成到现有系统中需要大量时间精力,以及机器学习知识。
CLIP-as-service 是一种易于使用的服务,具有低延迟和高度可扩展性,可以作为微服务轻松集成到现有解决方案中。也就是说,想要实现视频中的效果,不需要 GPU,不需要安装复杂依赖,只需要使用几个 Python 函数,CLIP-as-service 将完成所有工作。
本项目通过提取出视频的关键帧,分割视频的关键片段,巧妙地将 文字搜索视频 的任务转化成为 文字搜索图片 的任务。在完成关键帧抽取后,通过将查询文本和关键帧图集传给 CLIP-as-service,即可返回与查询文本匹配的视频片段。
项目仓库:https://github.com/jemmyshin/Video-CLIP-Indexer
预备工作
首先,在新的 Python 3 虚拟环境中,安装 docarray 和 clip_client。
pip install clip_client "docarray[full]>=0.20.0同时,你还需要一个用于 CLIP-as-service 的 Token,👉 获取路径请参考:CLIP-as-service 新升级!
获取数据
DocArray 是一个用于处理、传输和存储多模态数据的 Python 工具包,提供了非常便捷的多模态数据处理功能。使用 DocArray 加载 MP4 视频只需两行代码:
from docarray import Document
video_data = Document(uri='89757.mp4')
video_data.load_uri_to_video_tensor()print(video_data.tensor.shape)
(12116, 720, 480, 3)对于视频数据来说,.tensor 是一个四维数组。本示例视频有 12,116 帧,视频尺寸为 720x480,每个像素具有 3 个颜色维度。使用 DocArray 你可以按照帧的编号逐一查看各个帧,也可以提供开始和结束的帧编号提取剪辑。例如:
# 显示第 1400 帧
Document(tensor=numpy.rot90(video_data.tensor[1400], -1)).display()
# 显示从 3100 帧到 3500 帧
clip_data = video_data.tensor[3100:3500]
Document(tensor=clip_data).save_video_tensor_to_file("clip.mp4")
Document(uri="clip.mp4").display()提取关键帧
关键帧指角色或物体运动变化时关键动作所处的那一帧。

在加载视频时,DocArray 使用Document.load_uri_to_video_tensor()方法,自动收集关键帧,并存储在 Document.tagskey 字典的 keyframe_indices。
比如在本示例视频中,关键帧有:
print(video_data.tags['keyframe_indices'])
[0, 150, 300, 450, 600, 750, 900, 1050, 1200, 1350, 1500, 1650, 1800, 1950, 2100, 2250, 2400, 2550, 2700, 2850, 3000, 3150, 3300, 3450, 3600, 3750, 3900, 4050, 4200, 4350, 4500, 4650, 4800, 4950, 5100, 5250, 5400, 5550, 5700, 5850, 6000, 6150, 6300, 6450, 6600, 6750, 6900, 7050, 7200, 7350, 7500, 7650, 7800, 7950, 8100, 8250, 8400, 8550, 8700, 8850, 9000, 9150, 9300, 9450, 9600, 9750, 9900, 10050, 10200, 10350, 10500, 10650, 10800, 10950, 11100, 11250, 11400, 11550, 11700, 11850, 12000]接着就可以根据关键帧,把文字视频搜索的任务转化成为图片搜索的任务。
执行搜索
首先,我们将所有关键帧提取成图像,并将每个关键帧放入自己的 Document,然后将所有帧编译成一个 DocumentArray 对象:
from docarray import Document, DocumentArray
from numpy import rot90
keyframe_indices = video_data.tags['keyframe_indices']
keyframes = DocumentArray()
for idx in range(0, len(keyframe_indices) - 1):
keyframe_number = keyframe_indices[idx]
keyframe_tensor = rot90(video_data.tensor[keyframe_number], -1)
clip_indices = {
'start': str(keyframe_number),
'end': str(keyframe_indices[idx + 1]),
}
keyframe = Document(tags=clip_indices, tensor=keyframe_tensor)
keyframes.append(keyframe)上面的代码使用 Document.tags 字典来存储开头和结束的关键帧编号,以便提取对应的视频剪辑。
接着我们使用 CLIP-as-service,将查询文本(在示例中为“戴着白色礼帽的汤姆猫”)和关键帧图像集合传输给它,它将返回和查询文本相似的图像:
from docarray import Document, DocumentArray
from clip_client import Client
server_url = "grpcs://api.clip.jina.ai:2096"
# substitute your own token in the line below!
jina_auth_token = "54f0f0ef5d514ca1908698fc6d9555a5"
client = Client(server_url,
credential={"Authorization": jina_auth_token})
query = Document(text="Tom cat wearing a white bowler hat", matches=keyframes)
ranked_result = client.rank([query])[0]我们将查询和关键帧图像传输到 Jina AI Cloud,CLIP-as-service 为文本查询和每个关键帧计算嵌入向量。然后,我们测量关键帧向量和文本查询向量之间的距离。我们返回一个关键帧列表,这些关键帧按它们与嵌入空间中的文本查询的接近程度排序。
将查询和关键帧图像传输到 Jina AI Cloud,然后 CLIP-as-service 就会为查询文本和每个关键帧计算 embedding。计算完成关键帧向量和查询文本向量之间的距离后,CLIP-as-service 就会返回在嵌入空间中与文本查询的按照相似程度排序的关键帧列表。
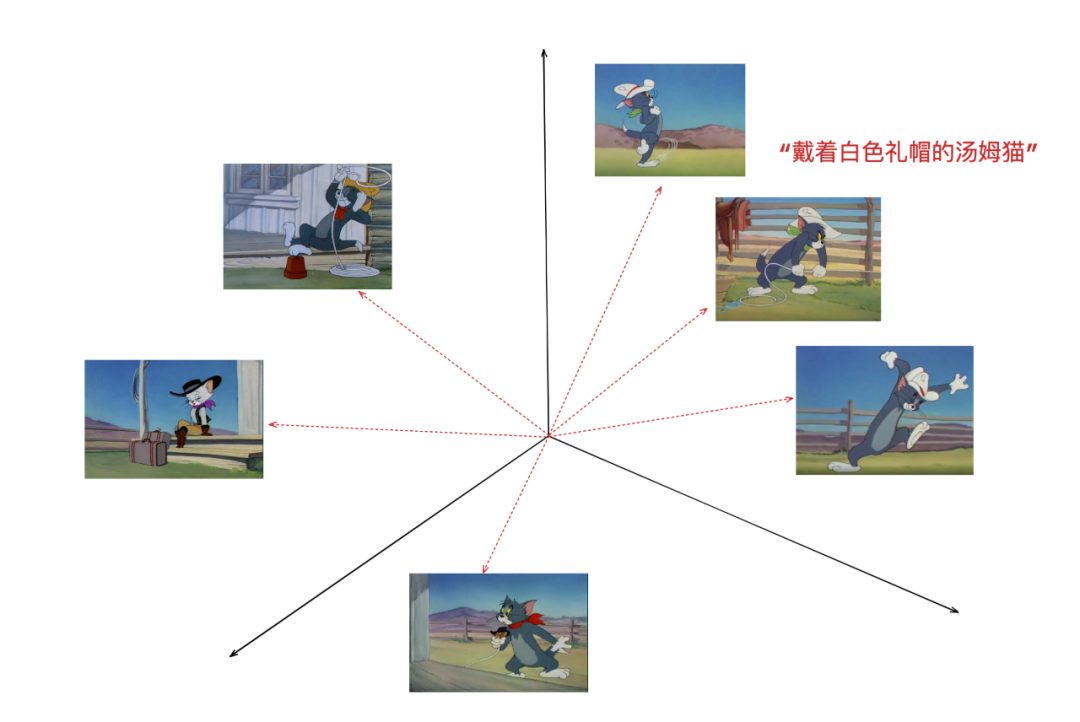
CLIP 将文本和图像转换为公共嵌入空间中的向量,其中它们之间的距离反映了它们的语义相似性。与其他图像相比,戴着礼帽的汤姆图像的嵌入向量比其他图像更接近文本“戴着白色礼帽的汤姆猫”的向量。
查询按照最佳匹配到最差匹配的顺序重新排列 Document.matches 中的关键帧图像。
print(ranked_result.matches[0].tags)
{'start': '2105', 'end': '2184'}你可以在 Document.tags 看到,我们保留了关于此关键帧的信息:它从第 2105 帧到第 2184 帧。有了这些信息,我们就可以获取与之匹配的视频片段:
match = ranked_result.matches[0]
start_frame = int(match.tags['start'])
end_frame = int(match.tags['end'])
clip_data = video_data.tensor[start_frame:end_frame]
Document(tensor=clip_data).save_video_tensor_to_file("match.mp4")
Document(uri="match.mp4").display()作者简介
付杰,Jina AI 机器学习工程师
Scott,Jina AI 高级布道师
原文链接
https://jina.ai/news/want-search-inside-videos-like-pro-clip-service-can-help/
更多资料
[1]
文档: https://clip-as-service.jina.ai/
[2]GitHub: https://github.com/jina-ai/clip-as-service
[3]获取 Token: https://console.clip.jina.ai/get_started
更多技术文章
📖 Jina AI创始人肖涵博士解读多模态AI的范式变革
🎨 语音生成图像任务|🚀 模型微调神器Finetuner
💨 DocArray + Redis:快到飞起来的推荐系统
😎 Jina AI正式将DocArray捐赠给Linux基金会
🧬 搜索是过拟合的生成;生成是欠拟合的搜索

点击“阅读原文”,即刻了解 Jina
![【LeetCode】验证二叉搜索树 [M]](https://img-blog.csdnimg.cn/img_convert/a7488a34e4b7e3b7fda2f1e8aff17a99.jpeg)









![【GO】K8s 管理系统项目[API部分--Pv]](https://img-blog.csdnimg.cn/d31bda7771094ff9ad9f62c7311f485f.png)

