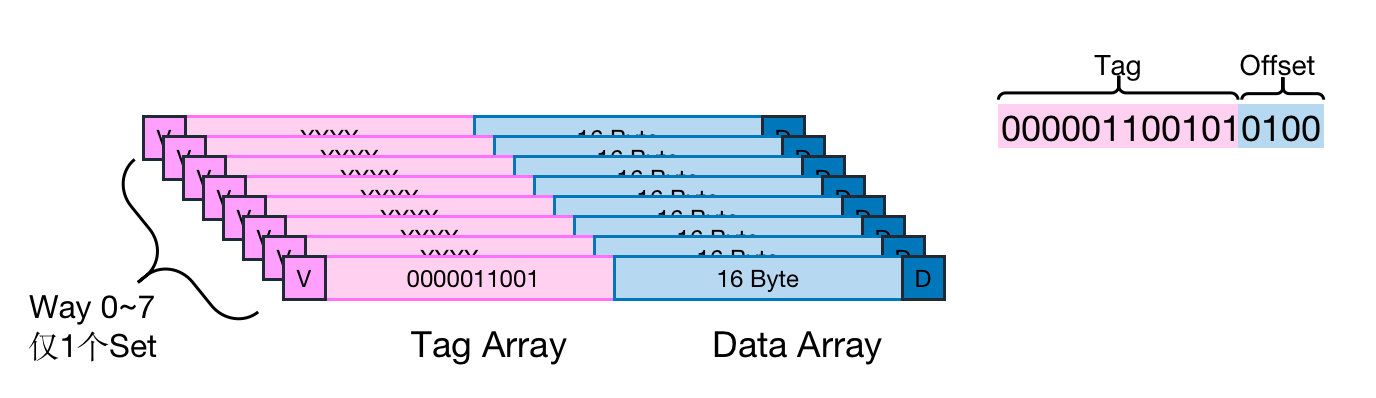
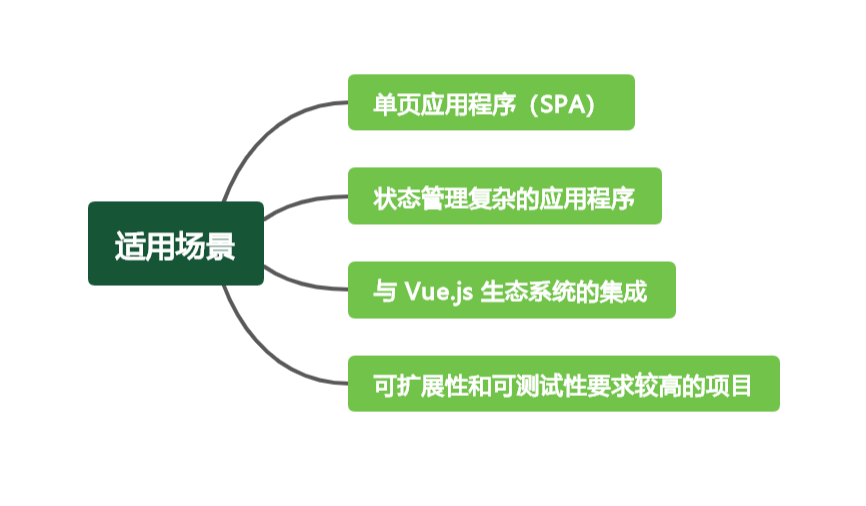
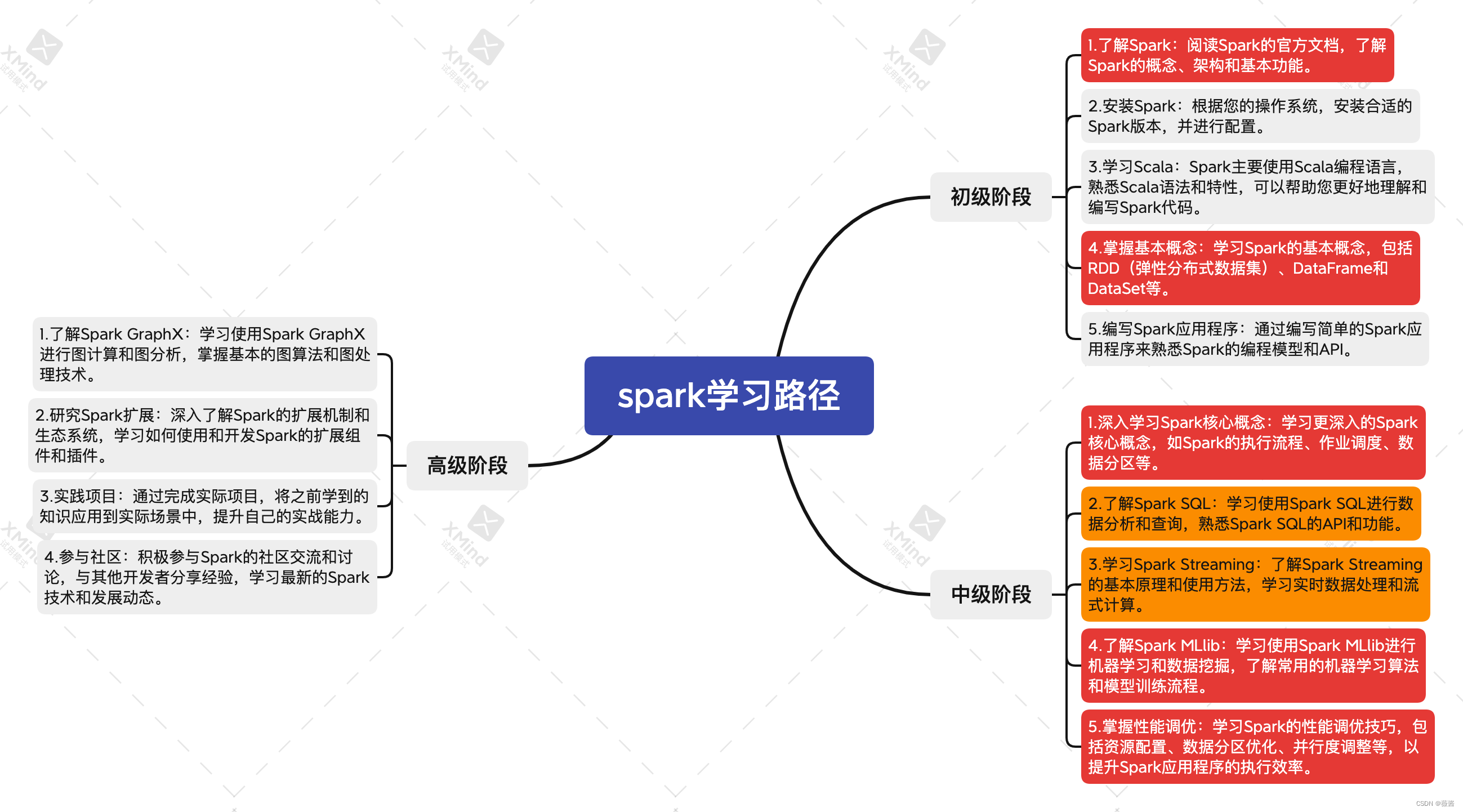
首先先让chatgpt帮我规划学习路径,使用Markdown格式返回,并转成思维导图的形式
目录
目录
1. 了解spark
1.1 Spark的概念
1.2 Spark的架构
1.3 Spark的基本功能
2.spark中的数据抽象和操作方式
2.1.RDD(弹性分布式数据集)
2.2 DataFrame
2.3 DataSet
1. 了解spark
1.1 Spark的概念
-
弹性分布式数据集(RDD)
是Spark的核心抽象,代表分布式内存中的不可变的对象集合。RDD可以跨多个节点并行操作,是Spark实现高性能的基础。 -
DataFrame和DataSet
Spark提供了结构化数据处理的API,可以使用DataFrame和DataSet进行高效的数据操作和分析。 -
Spark SQL
用于处理结构化数据的模块,提供了SQL查询和数据集操作的API。 -
Spark Streaming
用于实时数据处理和流式计算的模块,能够对数据流进行实时处理和分析。 - Spark MLlib
是Spark提供的机器学习库,包含了常见的机器学习算法和工具,用于数据挖掘和模型训练。
-
Spark GraphX
用于图计算和图分析的模块,提供了图处理和图算法的API。
1.2 Spark的架构
-
Cluster Manager(集群管理器)
集群管理器负责在集群中启动和管理Spark应用程序的执行。常见的集群管理器包括Hadoop YARN、Apache Mesos和Kubernetes。为Spark应用程序分配Executor的资源,并监控各个Executor的状态 -
Driver(驱动器)
驱动器是Spark应用程序的主要控制节点,运行用户编写的Spark应用程序的main函数。驱动器负责解析用户程序,将任务分配给各个Executor,并协调各个组件之间的交互。驱动器负责创建和维护SparkContext对象,SparkContext是与Spark集群进行交互的主要入口点 -
Executor(执行器)
执行器是运行在集群节点上的工作进程,负责执行具体的任务。每个应用程序都有自己的一组执行器,它们在启动时由集群管理器分配。执行器负责执行驱动器分配给它们的任务,并将计算结果返回给驱动器。执行器还负责将数据存储在内存中,并提供对数据的读写能力。在执行器中,每个任务都会被分配到一个线程上执行,可以并行执行多个任务。
三者的关系如下:
- driver和executor是通过cluster manager进行通信的,cluster manager负责将driver和executor连接起来,并协调它们之间的任务调度和资源分配。
- driver通过SparkContext对象与cluster manager通信,并将任务分发给executor执行。driver还负责监控和处理executor的状态和计算结果。
- executor接收来自driver的任务,并在本地执行。executor将计算结果返回给driver,并及时向driver汇报任务的状态。
总结起来,Cluster Manager负责资源的分配和任务调度,Driver负责解析用户程序并协调任务的执行,而Executor负责实际执行任务并返回计算结果。它们三者一起协作,实现了Spark应用程序的分布式计算。
1.3 Spark的基本功能
-
分布式数据处理
Spark可以处理大规模数据集,并支持在分布式环境中进行并行计算。它通过将数据加载到内存中并在集群中进行分布式计算,提供高性能的数据处理能力。 -
数据抽象和操作
Spark提供了弹性分布式数据集(RDD)的抽象,可以以类似于本地集合的方式对数据进行处理。Spark的API支持各种数据操作,如映射、过滤、聚合和排序等。 -
批处理和交互式查询
Spark提供了Spark SQL模块,支持使用SQL语言进行数据查询和操作。它可以处理结构化数据,并提供了高级API(如DataFrame和DataSet),使得批处理和交互式查询更加方便和高效。 -
流处理和实时分析
Spark Streaming模块使得实时数据处理和流式分析成为可能。它支持将连续数据流以微批处理的方式进行处理,并提供了窗口操作、状态管理和实时计算等功能。 -
机器学习和数据挖掘
Spark提供了Spark MLlib机器学习库,包含了常见的机器学习算法和工具。它支持分类、回归、聚类、推荐等机器学习任务,并提供了特征处理、模型评估和模型调优等功能。 -
图计算和图分析
Spark GraphX模块提供了图处理和图算法的功能。它支持构建和处理大规模图数据,并提供了图遍历、图算法和图分析等功能。 -
分布式文件系统和数据源支持
Spark支持多种分布式文件系统和数据源,如Hadoop HDFS、Amazon S3、Apache Cassandra等。这使得Spark可以方便地与各种数据存储和数据处理平台集成。
2.spark中的数据抽象和操作方式
2.1.RDD(弹性分布式数据集)
- 分布式内存中不可变对象集合
- 分区的数据集,可以跨节点并行操作
- 特性
- 容错性
- 不可变性
- 对RDD进行转换操作会生成一个新的RDD
- 可分区性
- 根据数据的键或哈希值进行分区,以便在集群中进行并行处理
- 可持久化
- 可以将数据存储在内存中,以便进行高速计算
2.2 DataFrame
- Spark SQL中的数据抽象
- 是具有命名列和逻辑模式的分布式数据集
- 特性
- 结构化数据
- 优化执行
- 使用Spark的优化器,将查询转为更高效的物理执行计划
- 支持SQL查询
2.3 DataSet
- Spark1.6后引入的数据抽象,是DataFrame的扩展
- 提供类型安全的分布式数据集
- 特性
- 类型安全
支持编译时类型检查 - 面向对象
可以使用面向对象的方式进行数据操作,同时也支持SQL查询 - 高性能
可以和DataFrame共享相同的执行计划和优化器,提供高性能的数据处理能力
- 类型安全