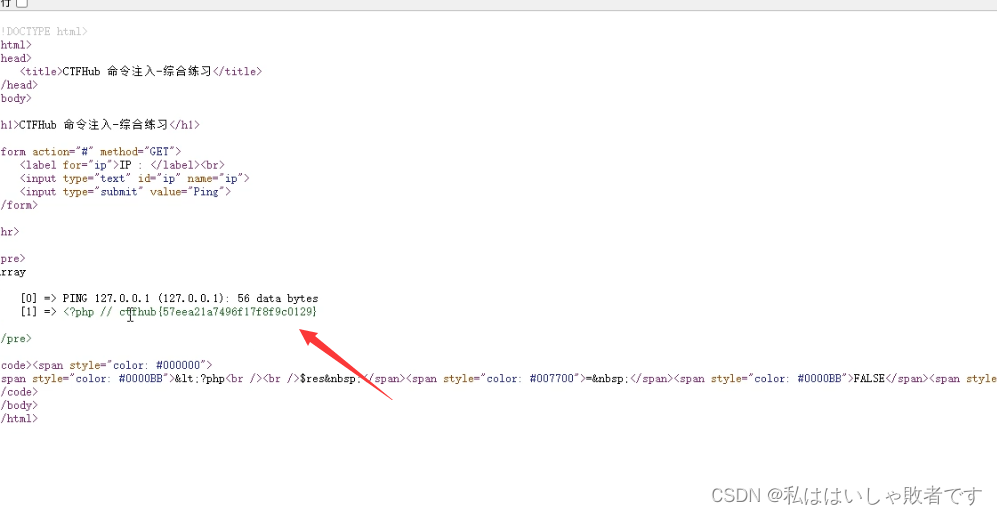
文章目录
- 传送门
- 系统级IO
- Unix输入和输出
- Unix文件
- Unix文件操作
- Unix管理打开文件
- 打开文件流程
- 文件共享
- 重定向文件
- 标准IO
- 标准IO流
- 标准IO的缓冲机制
- RIO(Robust IO)
- 对比与总结
- 网络编程
- 历史
- 从头构建互联网
- 网络层次
- 以太网段
- 网桥连接的以太网段
- 互联网
- 网络协议
- 互联网应用的软硬件组织
- 互联网的程序员视图
- IP地址
- 域名系统(DNS,Domain Naming System)
- 互联网通信
- 基础
- 连接过程
- 套接字
- 套接字编程——回声服务器架构
- 套接字地址结构
- 并发编程
传送门
此系列文章分为三篇,本文对应CSAPP的第三卷:程序间的交流与通信。现代程序不再是单纯的独立执行,而是要进行协作,这其中就涉及到了系统内通信,系统间通信,并发控制
第一卷:程序结构与执行——信息表示、指令、处理器、性能优化、储存层次
第二卷:在系统上运行程序——链接、异常控制流、虚拟内存
第三卷:程序间的交流与通信——系统级IO、网络编程、并发编程
系统级IO
Unix输入和输出
Unix系统中,接口分为三类:
- 基础:Unix系统级IO函数,只能通过系统调用访问
- C语言标准IO:是系统IO的封装
- RIO函数:是特殊封装的,具有健壮性的IO函数

Unix文件
Unix中文件具有高度的统一性:
- 文件:字节序列
- 普通文件:分为文本文件和二进制文件。注意,内核不会区分这两种文件,需要程序员手动调用相对应的IO函数。
- 文本文件以ASCII形式储存,以换行符分割
- 二进制文件的字节不一定是ASCII,可以存放任何信息,包括文本
- 目录:索引一组文件
- 记录文件的索引。分软链接和硬链接
- 目录至少有两个文件,分别是.和…
- 套接字:用于网络通信
- 普通文件:分为文本文件和二进制文件。注意,内核不会区分这两种文件,需要程序员手动调用相对应的IO函数。
- 所有的IO,全部变成文件映像
- 甚至内核也可以是文件
文件的目录按照树状结构组织,通过路径名逐层访问。每个进程有一个cwd,即工作目录。
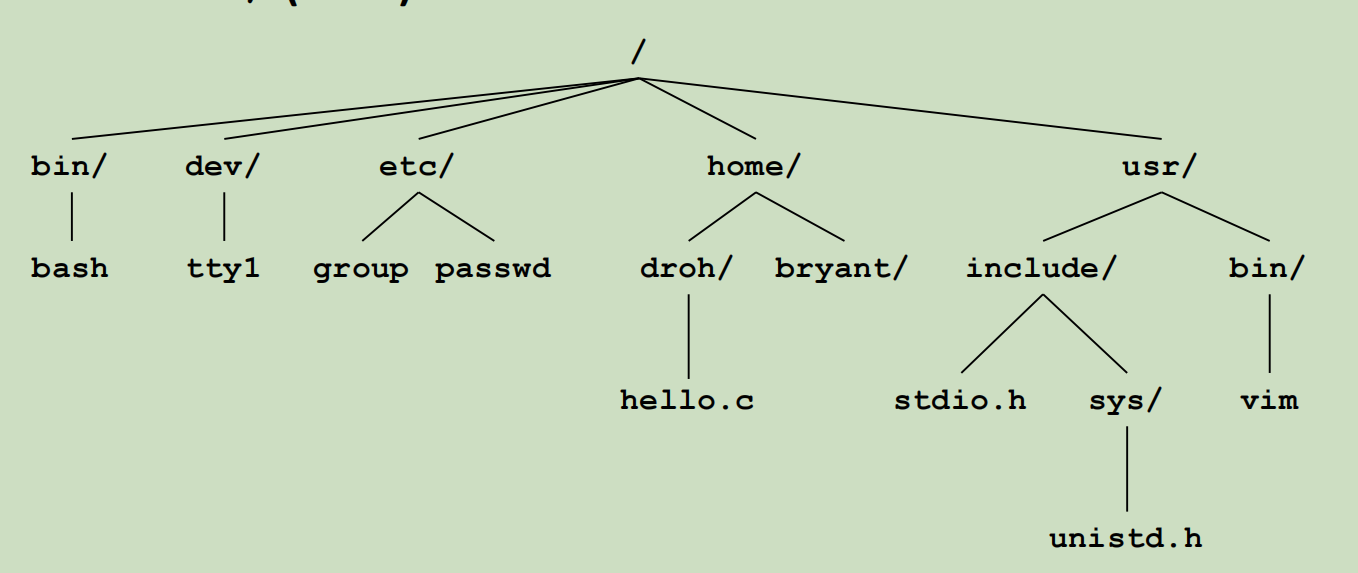
Unix文件操作
注意,Unix的文件操作都是系统调用。
- 打开open
- 返回文件标识符
- Linux shell打开的进程默认有三个打开文件,0,1,2对应stdin,stdout,stderr
- 关闭close
- 重复关闭文件会在线程化的程序中导致灾难
- 读read
- 读取若干字节到buf数组中
- 没有自动处理不足值(比如EOF)的机制,不会报错,要小心使用
- 写write
不足值发生的情况:
- EOF
- 从中断读文本行
- 读写网络套接字
Unix管理打开文件
打开文件流程
Unix打开文件的流程如下:
- 每个进程都有一打开的文件表
- 文件表里默认有0,1,2三个文件
- 文件表描述符指向打开的文件。
- 文件描述符。
- 文件描述符指向元数据。
- 每一次open都可以生成一个打开的文件,但是多次打开一个文件,打开的文件都是指向同一个元数据的,元数据只能有一个。
- 元数据。文件都有元数据,元数据与文件一一对应,由内核维护。用户用stat和fstat函数访问。
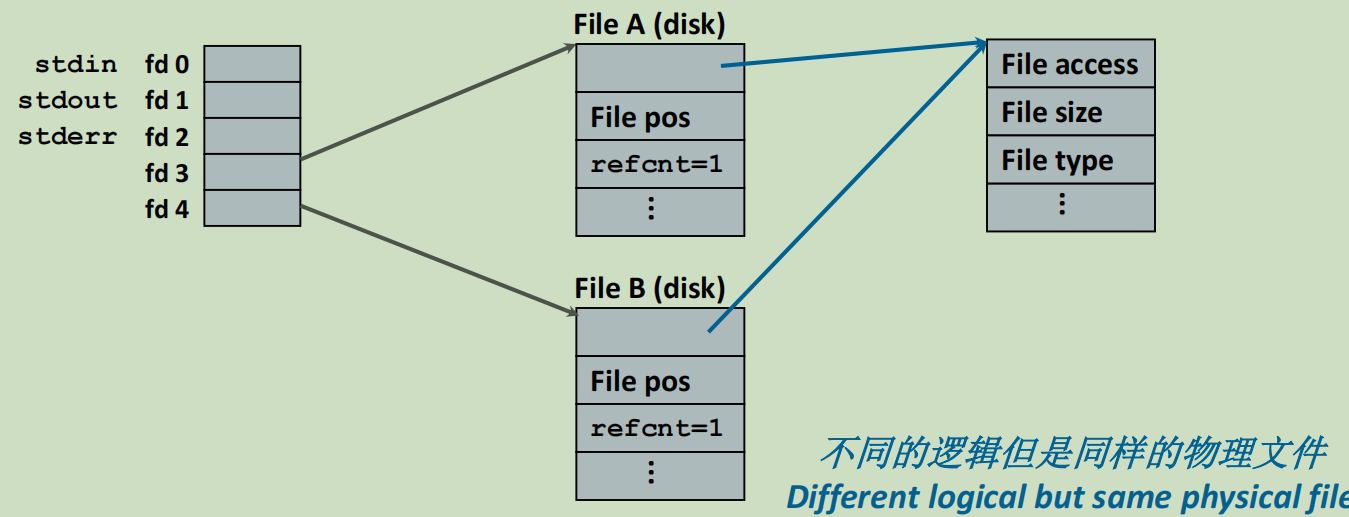
文件共享
共享文件有两种方式:
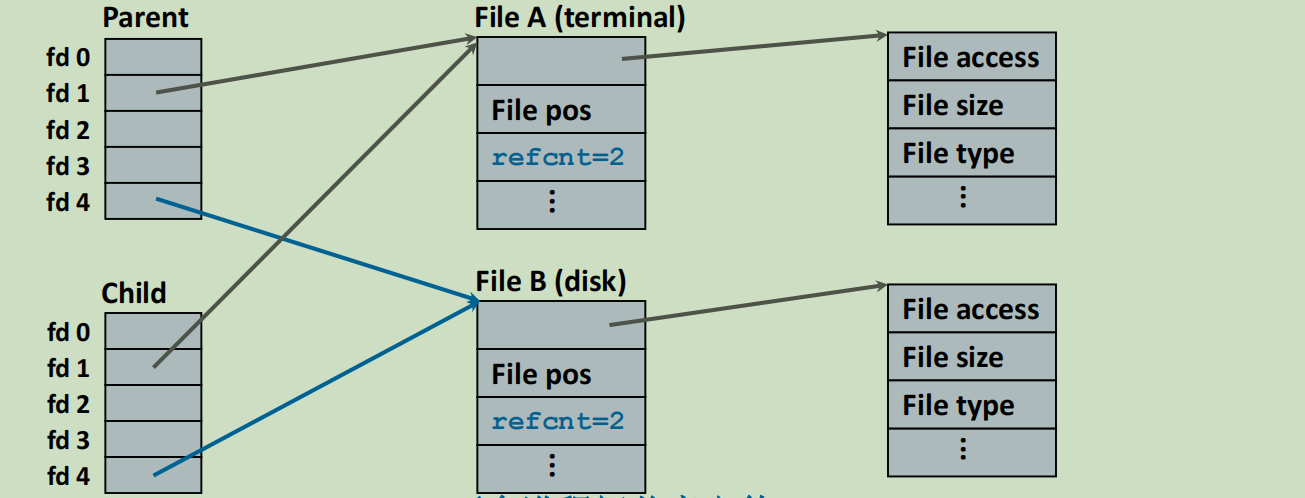
- 平等进程之间共享:各自有一个打开的文件,指向同一个元数据。(上图)
- 父子进程之间共享:描述符表指向同一个打开的文件。(下图)
父子进程这种共享很合理,而且和父子进程资源独立并不冲突。虽然子进程复制了一份文件描述符表,但是指向的确是同样的位置,所以子进程其实只是复制了一份指针表,指向的空间还是共享的。
重定向文件
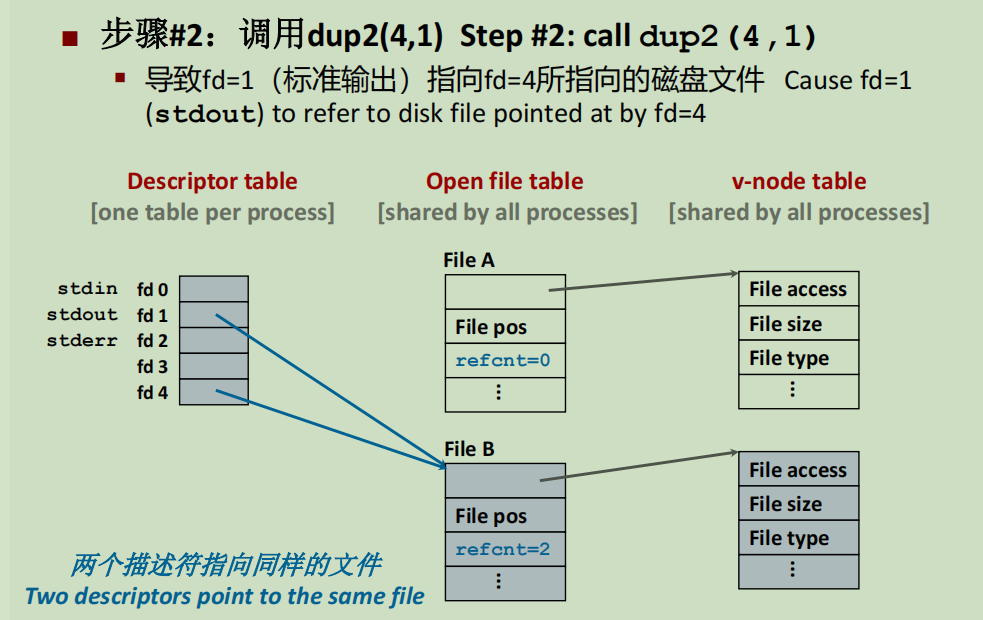
C编程中,常用freopen将txt文件的内容重定向到stdin里,取代手工输入。Linux中,通过dup函数实现重定向。
dup函数修改文件描述符表,dup(a,b)是将a写入到b中。
下图,调用dup(4,1)后,原来的1就被4覆盖。
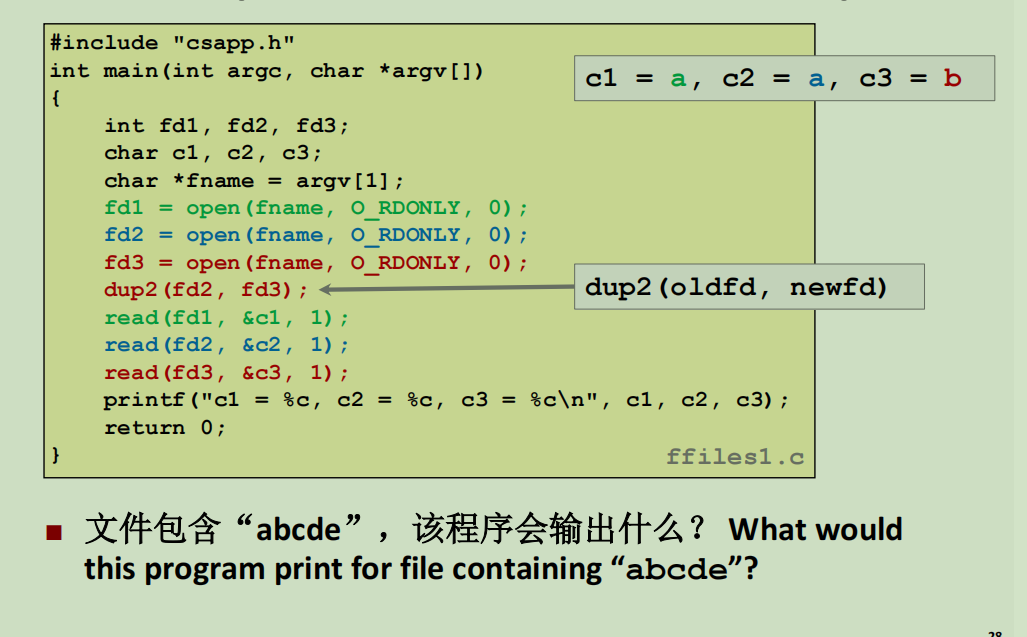
举个例子。下图中,进程打开了三次文件,生成三个打开文件,此时三个文件指针都指向文件开头互不干扰。之后,使用dup(fd2,fd3),则将fd3覆盖为fd2,此时,原来的fd3和fd2同时指向一个打开文件,相当于公用一个文件指针了。
读取fd1,输出a
读取fd2,fd3,其实都是在读取fd2,所以输出ab。
下图展示了父子进程的文件共享。可以看到,父子进程指向的空间是公用的。s的不同会导致父子进程其中一个休眠。
- 如果s=1,则子进程先读,父进程后读取
- 如果s=0,则父进程先读,子进程后读取。
因为两个进程是共享文件的,所以三次读取,一定是abc。

标准IO

标准IO流
标准IO打开的文件都称作流(stream)。这是文件描述符和内存缓冲区的抽象。
(此处是我的个人理解:IO流和Unix有什么区别呢?Unix读取是读取到char数组中的,而C语言IO流默认输入就是字节的形式,不去管你怎么编码的,就顺着读。那怎么知道要读多少呢,读的又是什么东西?通过fscanf和fprintf的格式控制符来实现即可。所以,流读写比Unix的IO更加方便,形式多样)
同Unix一样,C程序也会有默认的打开文件,分别是stdin,stdout,stderr,但是这三个文件已经是流了。
标准IO的缓冲机制
标准IO的基础是Unix的IO,也就是说,即使你只用一个getc函数读取一个字符,你也是进行了一次系统调用。系统调用要消耗1w个时钟周期,是非常费时的。反而是系统调用以后的IO比较快。所以,为了加速,应该尽可能减少系统调用的次数。
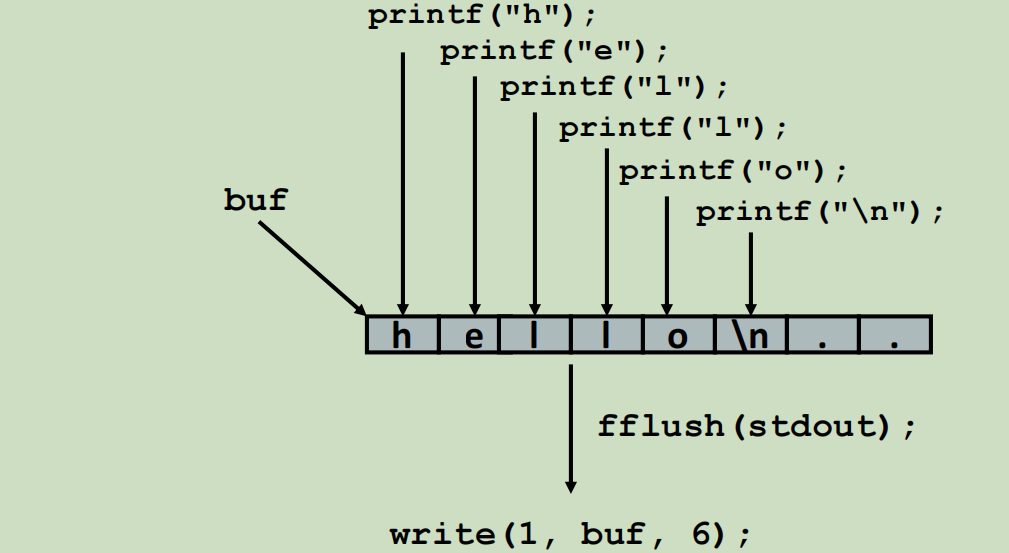
标准IO采用缓冲机制,读的时候,先一次性读取一个比较大的字节块到IO缓冲区,然后用户输入再从缓冲区读你想要的东西。当缓冲区没有的时候,再进行Unix系统调用读取一个字节块。

写的时候,也是先写到IO缓冲区,最后一次性输出。可以使用fflush手动刷新缓冲区,当然,在碰到"\n"的时候也会自动刷新。
在大一的时候,写C语言会碰到各种读写的问题,很多都是缓冲区在作祟,比如缓冲区里剩下一个换行符,你得手动刷新才不影响下次读取。
RIO(Robust IO)
RIO是一组特殊封装的IO函数。与Unix的读写类似,但是具有高度的健壮性,特别适合从网络套接字读取文本行。
对比与总结
Unix IO:
- 优点:
- 通用,额外开销最低
- 是其他IO的基础
- 底层:可以访问元数据
- 安全:可以用于异步信号处理
- 缺点:
- 太原始,没有自动处理不足值的机制,也没有自动缓冲的机制
标准IO:
- 优点:
- 高效:通过缓冲区技术减少系统调用次数
- 省心:自动处理不足值
- 缺点:
- 封装:不能访问元数据
- 危险:异步情况下不安全,不能用于信号处理程序
三种IO各有千秋,要根据情况进行选自:
- 一般情况:标准IO,但是要理解标准IO的底层原理,比如IO缓冲区
- Unix IO
- 信号处理程序
- 需要极限的性能
- RIO
- 网络套接字(注意,标准IO不适用于网络套接字,其流格式与网络套接字冲突)
网络编程
历史
最开始是ARPA,这是互联网的前身。ARPA中有IMP,通过简单的网络协议通信。后来发展到了大学之间的组网。此后发展非常迅速,很快遍布全球。
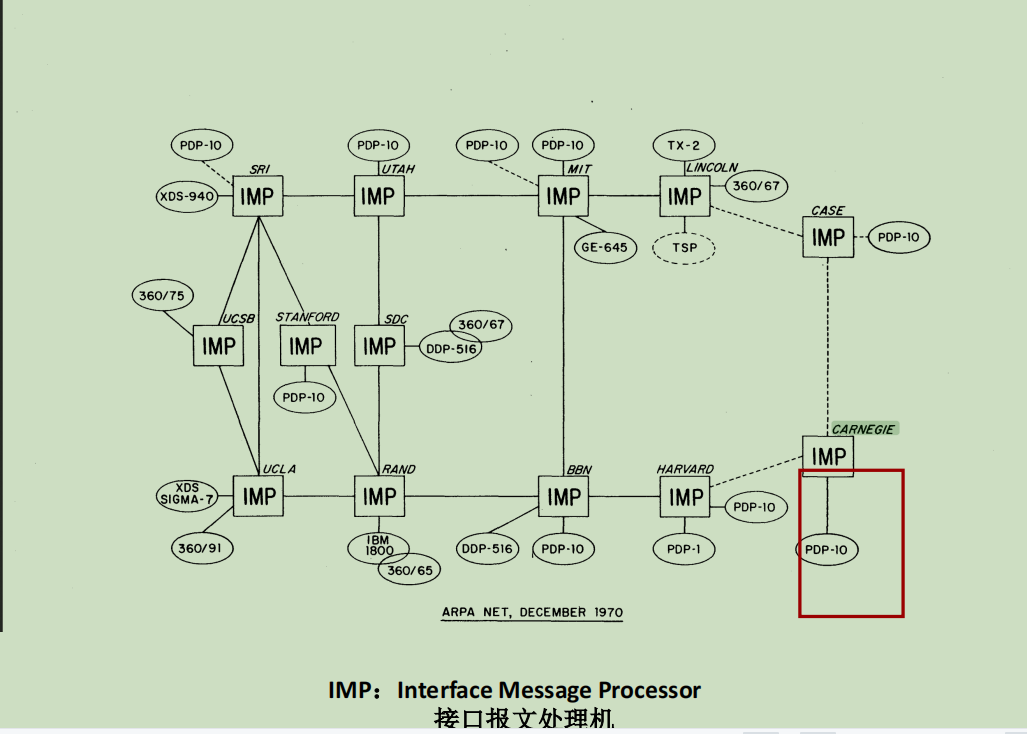
当节点数量够多的时候,僵尸网络就出现了。有人被不知不觉中控制,成为肉鸡,用于实行ddos攻击。
网络不是凭空传递的,无论是最开始还是现在,通过线缆是最稳定的方法,所以现在世界上有大量的海底线缆。
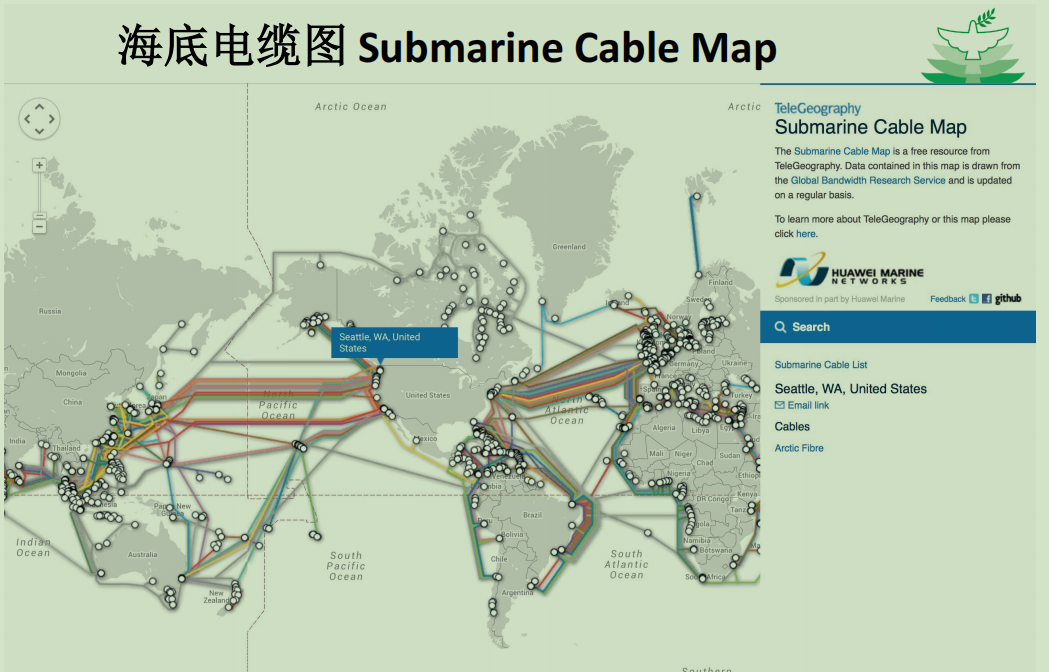
客户-服务器事务。
这个就是我们当时写C++大作业,做简化版QQ的时候,用的通讯模型。
主机和客户可以在一台电脑上。
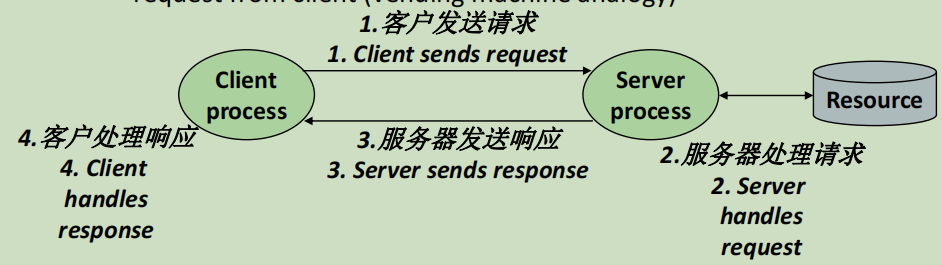
硬件是网络的基础,而网络还是依附于原有的计算机架构的。
注意,适配器其实就是网卡,挂在计算机总线上。(我自己装的台式机,主板上用PCIE-x1总线就可以接网卡)
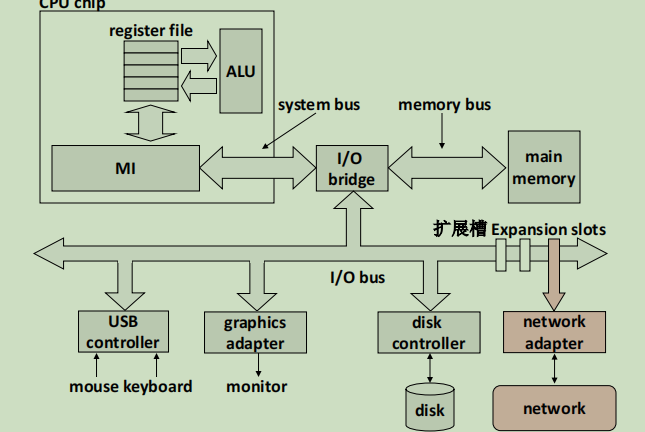
网络,本质上就是若干节点之间通过电线链接。这种链接是分层的,比如我家里几台设备连到一个路由器上,然后这个路由器挂到网线上,我家里的设备就是更底层的。按照层次来说,有如下级别:
- LAN(局域网,local area network),这种网络可以跨越建筑物,校园
- 以太网(Ethernet)是经典的网络,校园网就是以太网
- WAN(广域网,wide area network),遍布全国,全世界
- 通常是高速点对点链路(光纤)
在LAN和WAN之间,其实还有不同的层级,但是都类似。
从头构建互联网
网络层次
以太网段
以太网是房间,楼层级别的。
多个主机,通过集线器,链接到一个hub上,一个hub用一个port标识。
线缆速度不高,但是对一台机器来说够用,也有100Mb/s了。
每一个以太网适配器(对应一台主机上的网卡)都有一个唯一的mac地址。
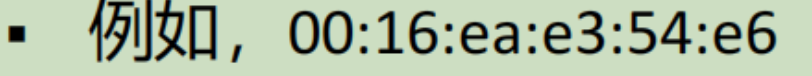
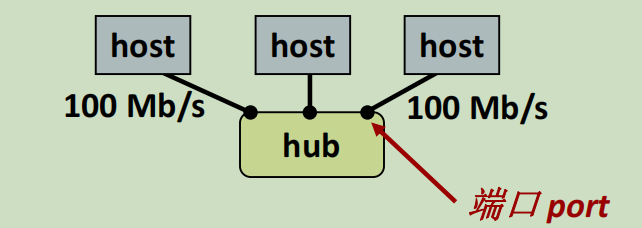
主机以帧为单位向其他主机发送bit,一个主机向集线器发送,其他所有主机都可以看到。
集线器是过时的东西。现在是通过网桥(交换机、路由器)来链接的。
网桥连接的以太网段
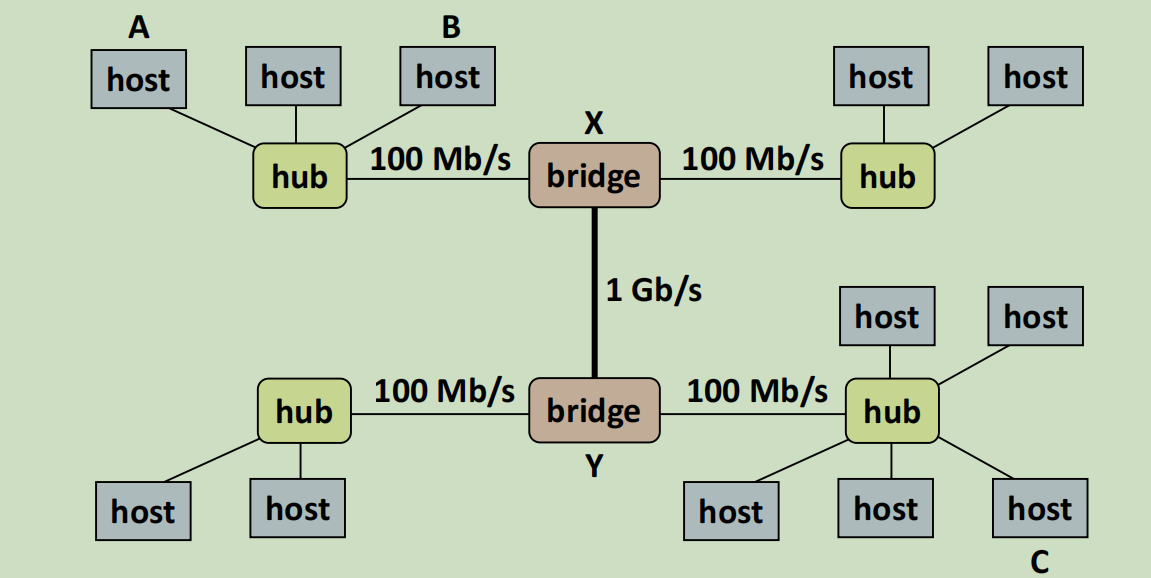
hub可以覆盖的距离非常短,通常就是一个房间。后面出现了网桥连接(此时是交换机),就可以跨越房间,楼层,建筑物了。
集线器不具有选择性,发出去都可以收到。而网桥具有选择性:
- 在发送的时候,网桥会网信息中打上标记,表明是从哪里来,到哪里去
- 另一个网桥接收的时候,解析出到哪里去的信息,发送给某个hub
互联网
前面的以太网和桥接网络都是局域网,为了便于描述,局域网都用下面这种模式描述:一根线上面搭了若干主机。
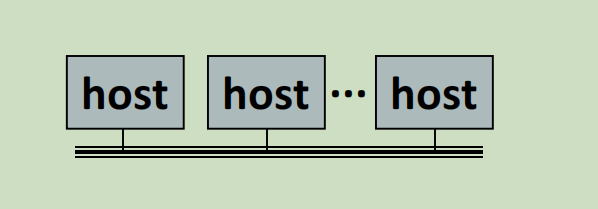
局域网之间通过广域网链接。
不同的局域网,往往并不兼容,所以在局域网之间的交换设备要更加复杂,即路由器:
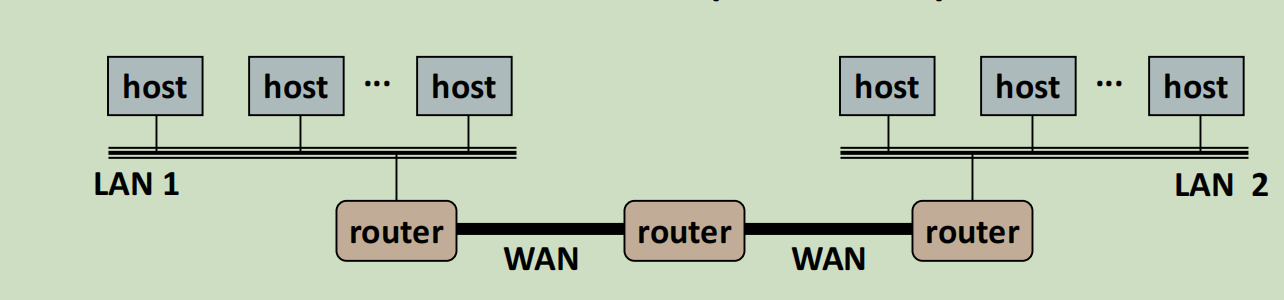
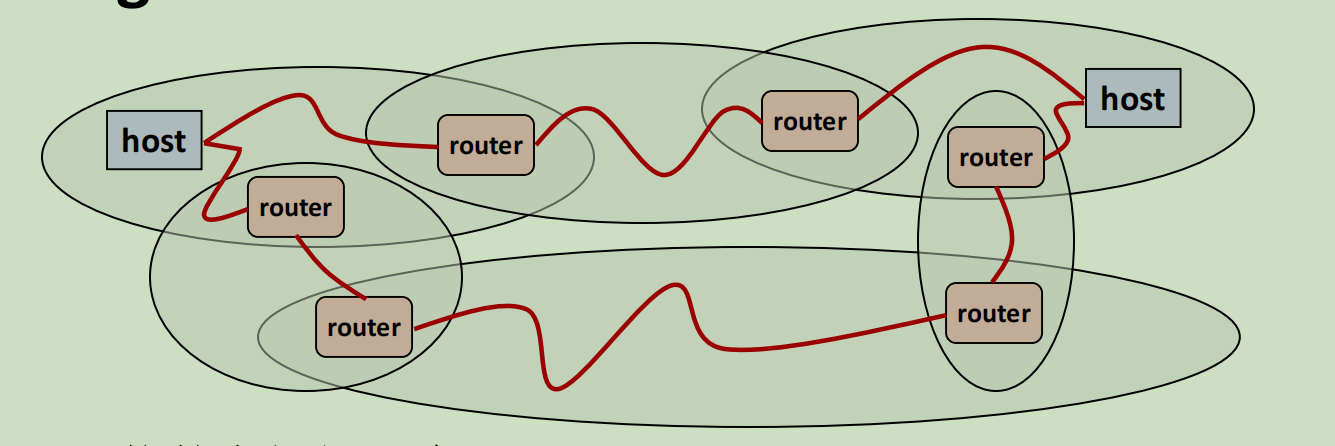
到了路由这一层,网络的链接关系就比较混乱了,也就是所谓的自组织互联,实际上就是没有固定的拓扑结构,广域网通信要通过若干个节点多次跳转。
因此,从一个局域网通过广域网发送到另一个局域网的路径是多种多样的,如何选择最优的道路(路由),是很多人研究的课题。
网络协议
局域网和广域网之间互不兼容,如何发送信息,就需要制定一个统一的标准,这就是网络协议。协议由软硬件协作构成,主要解决两个问题:
- 命名方案
- 网络协议使用地址区分主机,地址有统一的标准(IP地址)
- 每个主机和路由器都会有一个唯一地址
- 传递规则。一条网络信息称为一组信息,由元数据和数据组成。
- 分组头部。有分组大小,源地址,目标地址
- 有效信息载荷。储存了信息本身
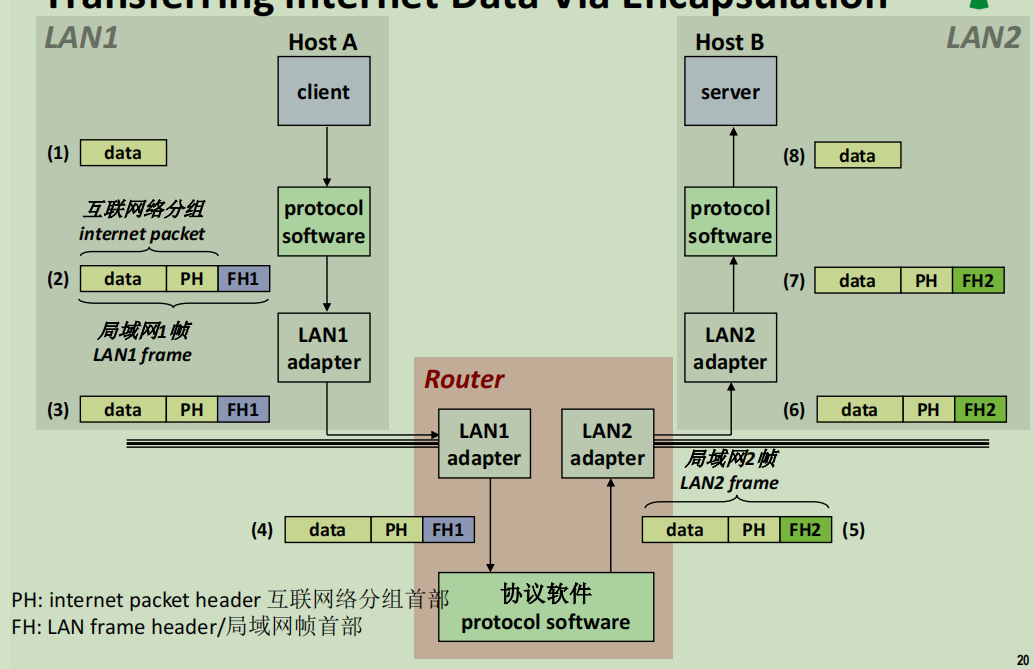
举个例子:
- client发出信息
- 局域网网络协议包装:
- 给信息加装分组头部PH,组成一组数据
- 给一组数据加局域网帧头部FH1
- 广域网网络协议转换。将一个局域网的FH1头部转换成另一个局域网的FH2头部
- 局域网网络协议解包:
- 解析FH2
- 解析PH
- 收到信息。
现在的网络协议是TCP/IP协议族:
- IP:网络协议。提供了基本命名方案和主机之间的基本传输能力
- 传输协议
- UDP:传输协议。IP之间不可靠的数据报文传输
- TCP:传输协议。IP之间可靠的通讯字节流
以上的传输,在软件上要通过混合Unix文件IO和套接字接口函数来访问。
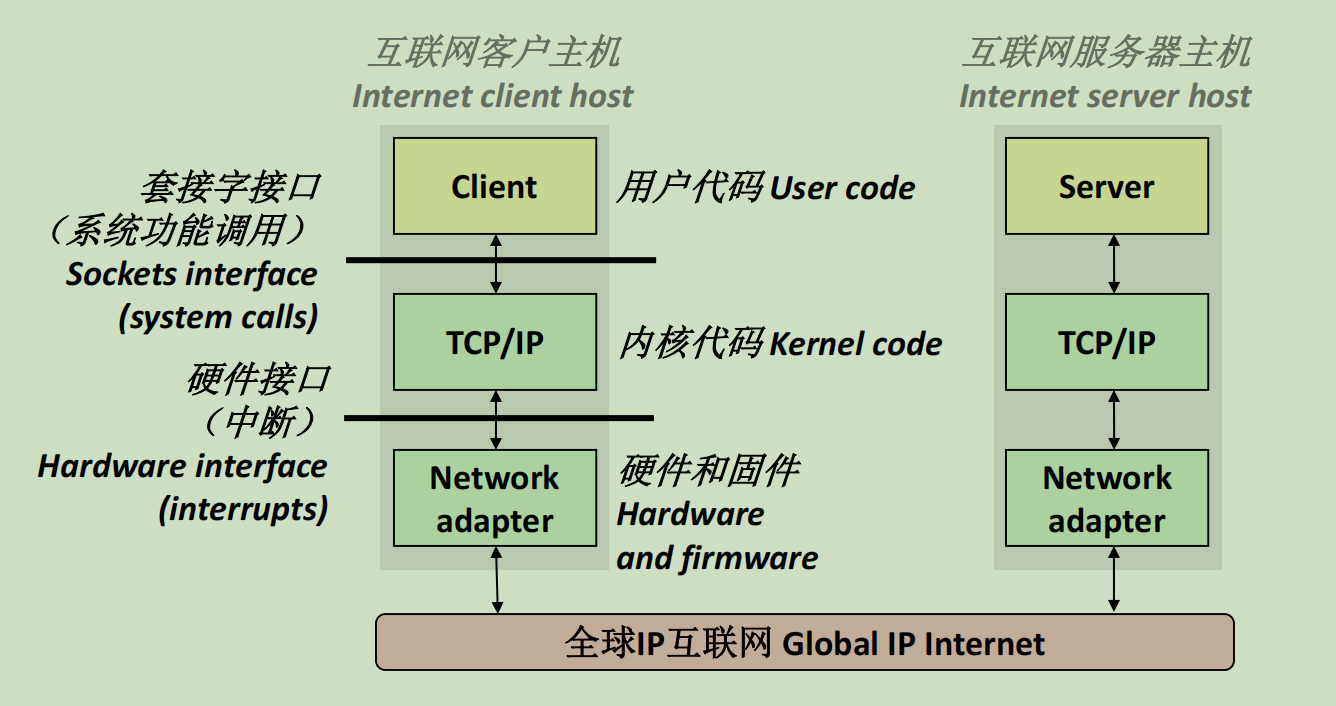
互联网应用的软硬件组织
从宏观的角度来说,互联网应用有三层组织:
- Client用户层。通过套接字调用系统功能
- TCP/IP内核层。系统级的协议层
- 硬件和固件层。网络通信的硬件。硬件平台通过全球IP互联网互联
互联网的程序员视图
一组:内网ip,外网ip
域名解析:字符解析成IP
进程可以通过网络通信
IP地址
IPV4,分层,所以还没有爆满
32位4字节,以大端法储存在内存中。
常用点分十进制记法。
分层结构:
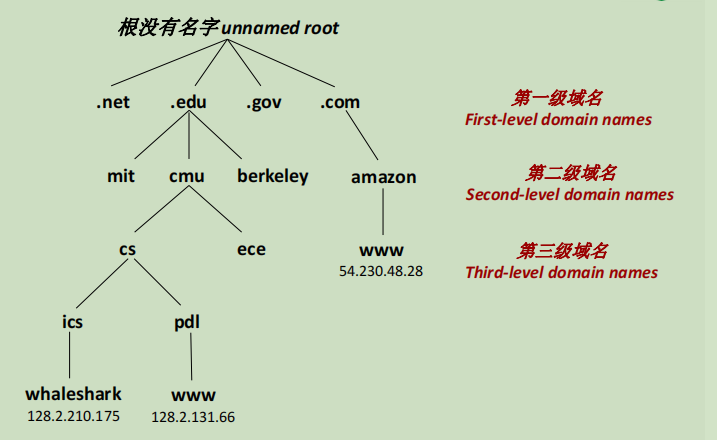
一级域名都是公益的,往下分支。有一个公益组织,维护三级域名。
北京的局域网出口是清华。比如北理工校园网,先要连到清华,之后清华才连接到第三级域名上。VPN软件是跳过了清华,直接连到了第三级别域名上。
IPV6,128位,未来要替代。
域名系统(DNS,Domain Naming System)
DNS可以将字符串映射为IP,DNS只是为了方便实用,所以实际使用其实不一定要DNS,比如校园网的10.0.0.55。
这个映射,物理上基于一个巨大的全球分布式DNS数据库。从逻辑上说,DNS可以简单理解为一张表,里面有上百万个主机字符串与IP的映射条目。
通过工具可以查看IP和域名之间的映射关系:
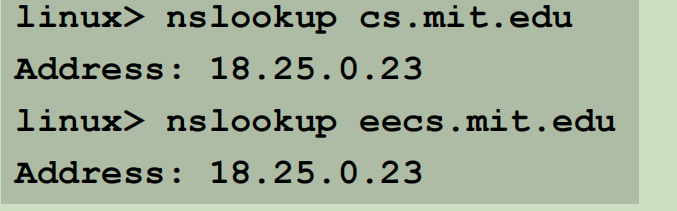

可以看到,多个域名可以映射到同一个IP。更加复杂的情况下,可以把一个域名池映射到一个IP池中,用于负载均衡,在解析的时候,优先解析负载比较轻的IP,让系统均摊流量。
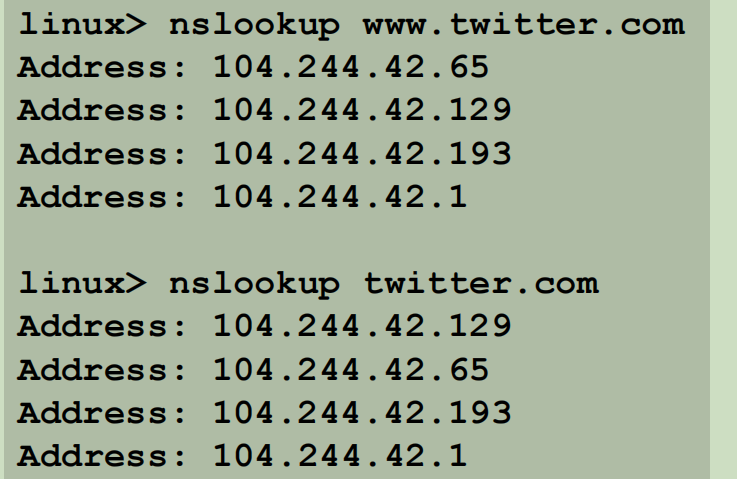
还有一种是,有合法域名但是没有IP映射。可能是预留的域名,也可能是隐藏了。

互联网通信
基础
通常是用TCP进行客户端和服务器链接。TCP的特点:
- 点对点。一对一的链接
- 全双工。可以同时双向传输
- 可靠。只要不断掉,就一定可以被接收
使用TCP协议编程的时候,要构建对应于某个IP的套接字,套接字格式为IP:port对。
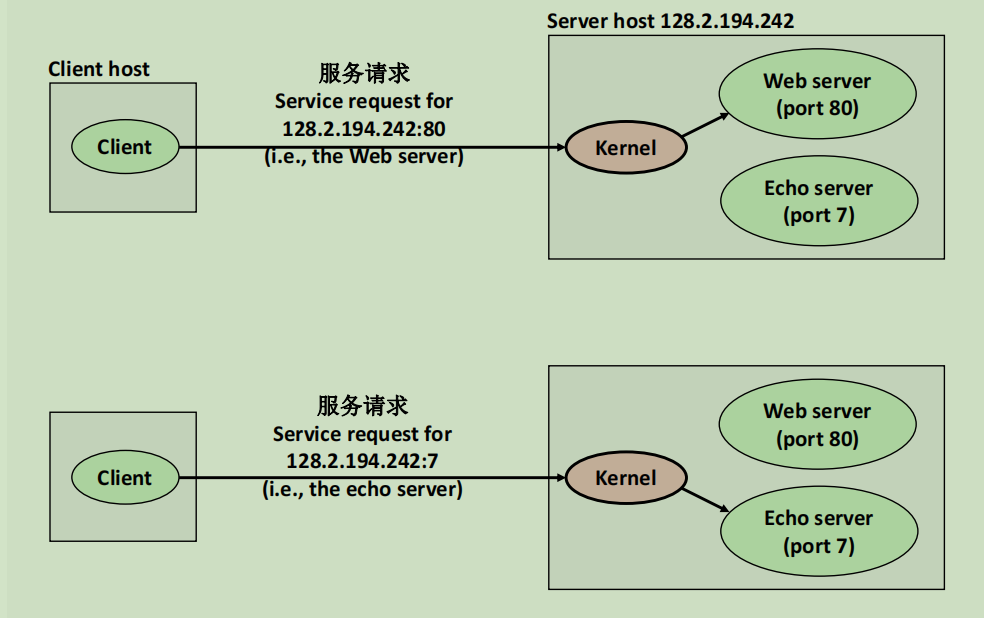
在网络通信中,端口是16位整数,用于表示进程。
有的是临时端口,用于普通的通信,内核自动分配。有的是预留端口,与特定服务有关,比如80端口是web服务器端口,22是SSH端口,21是ftp文件传输端口。
连接过程
套接字这个名字取得很形象。客户端有一个ip:port对,服务器也有ip:port对,就像是两方各给一个接口,两个接口可以套在一起,形成一个套接字对。

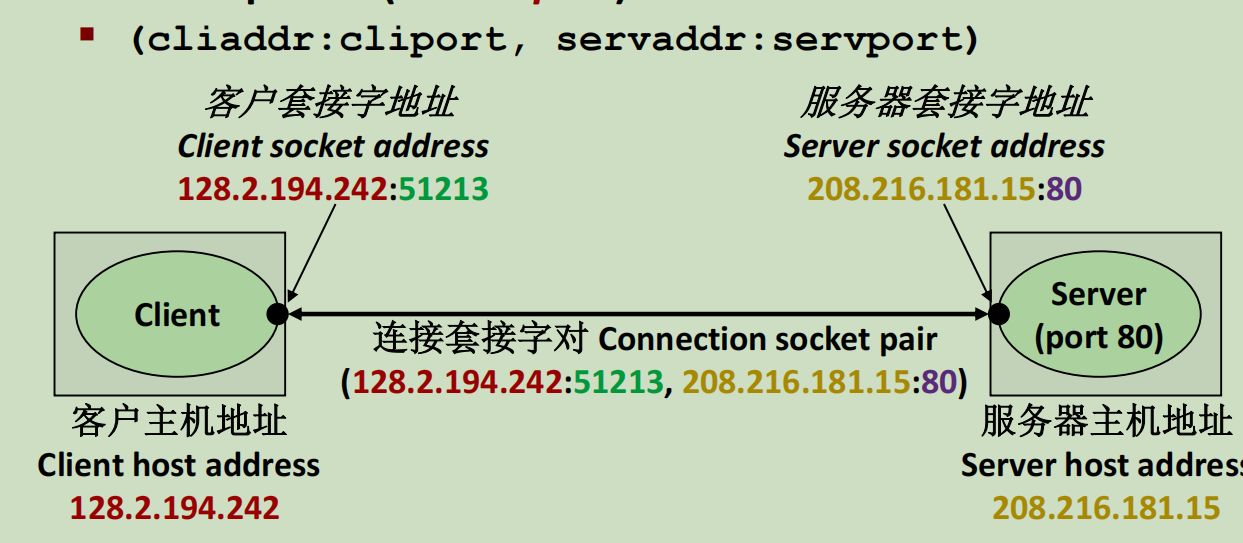
下图说明了,端口与进程一一对应。切换不同的端口可以访问一台主机上的不同任务。
套接字
套接字是一组与Unix IO结合的系统级函数,用于在Client级别编写通信程序。套接字起源很早,适用于现在所有系统。
- 从系统来看:套接字可以看做是系统对外通信的点,两个系统的点之间形成套接字对进行连接
- 从应用来看:套接字可以看做文件,通过对套接字文件的读写实现远程网络的通信
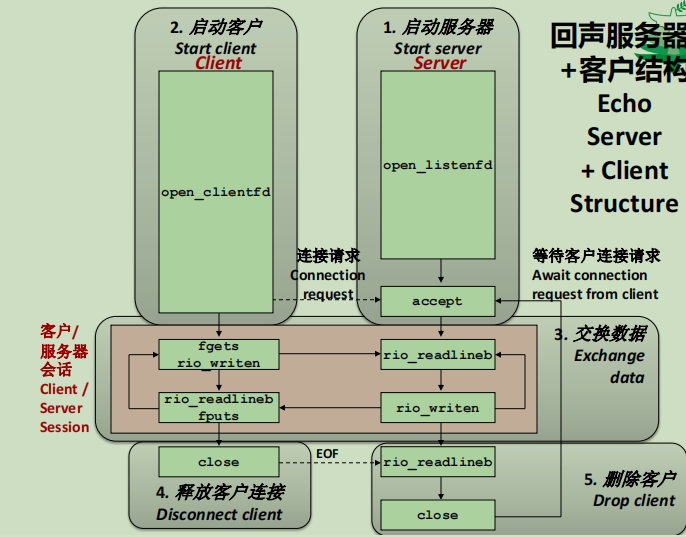
套接字编程——回声服务器架构
具体编程基本就是下面的流程,思想很朴素,代码就不帖了,到时候学计网自然会学:
- 先建立TCP连接
- 再执行套接字双向通信
- 客户端发送请求
- 服务器接收请求,解析,做处理,返回响应
- 客户端收到响应
- 最后再关闭套接字连接

逻辑上的视图如下:
套接字地址结构
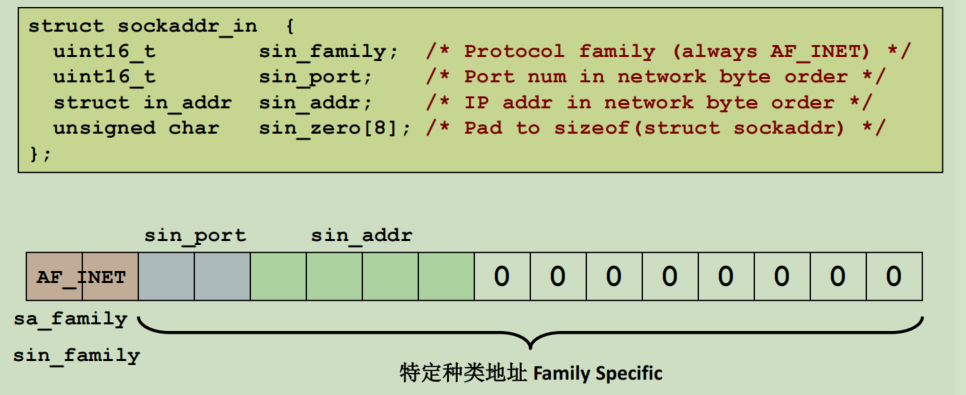
前面是套接字的宏观逻辑,这里讲更精细的。套接字有两种,底层的数据是一样的,只不过是两种不同的视图,所以可以互相强制转换:
- 通用套接字地址。是一个结构体,family表示协议类型,14字节储存了地址的数据

- IPv4套接字地址。这一层是给用户用的,分为协议类型(2字节),ip(4字节)和port(2字节)
并发编程
这章不学了,就看懂几个公式,猜出来是什么意思就行:
- 并行加速后的时间=串行时间比例+并行部分比例/加速因子
- 加速比:1/加速后的时间
- 并行效率:加速比/处理器数量*100%

在2022年12月28日的晚上23:48分,明天考试。但是,该睡觉了,也学不完了,后面也没必要学了。
故本章略。
明早起来看看例题,就准备考试了。