作者:刘凡
KNN算法介绍
KNN算法是有监督学习中的分类算法,它是一种非参的,惰性的算法模型。非参的意思并不是说这个算法不需要参数,而是意味着这个模型不会对数据做出任何的假设,与之相对的是线性回归(我们总会假设线性回归是一条直线)。也就是说KNN建立的模型结构是根据数据来决定的,这也比较符合现实的情况,毕竟在现实中的情况往往与理论上的假设是不相符的。惰性的意思是指模型在使用前不会被训练,只有当使用的时候才会被训练。
KNN算法优点: 简单易用,相比其他算法,KNN算是比较简洁明了的算法。即使没有很高的数学基础也能搞清楚它的原理。可以处理多分类问题;还可以处理回归问题。
KNN算法缺点: 对内存要求较高,因为该算法存储了所有训练数据,预测阶段可能很慢;对训练数据依赖度特别大,虽然所有机器学习的算法对数据的依赖度很高,但是KNN尤其严重,因为如果我们的训练数据集中,有一两个数据是错误的,刚刚好又在我们需要分类的数值的旁边,这样就会直接导致预测的数据的不准确,对训练数据的容错性太差;维数灾难。
自编函数实现
#欧氏距离
def distance(a,b):
return np.sqrt(np.sum((a-b)**2,axis=1))
# 分类器实现
class kNN(object):
# 定义初始化方法,初始化kNN需要的参数
def __init__(self,n_neighbors = 1,dist_func = distance):
self.n_neighbors = n_neighbors
self.dist_func = dist_func
# 训练模型方法
def fit(self,x,y):
# 将x,y传进来即可
self.x = x
self.y = y
# 模型预测方法
def predict(self,x):
# 初始化预测分类数组
y_pred = np.zeros((x.shape[0],1),dtype = self.y.dtype)
# 遍历输入的x数据点,取出每一个数据点的i和数据x_test
for i,x_test in enumerate(x):
# x_test跟所有的训练数据计算距离
distances = self.dist_func(self.x,x_test)
# 得到的距离按照由近到远排序
nn_index = np.argsort(distances)
# 选取最近的k个点,保存其类别
nn_y = self.y[nn_index[:self.n_neighbors]].ravel()
# 统计类别中频率最高的那个,赋给y_pred[i]
y_pred[i] = np.argmax(np.bincount(nn_y))
return y_pred
测试
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
iris = load_iris()
# 划分训练集和测试集
x = iris.data
y = iris.target.reshape(-1,1)#将iris.target 行向量,转换成列
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3)
knn = kNN(n_neighbors = 3)
knn.fit(x_train,y_train)
# 传入测试数据,做预测
y_pred = knn.predict(x_test)
# 求准确率
accuracy = accuracy_score(y_test,y_pred)
print('预测准确率:',accuracy)
'''预测准确率: 0.9777777777777777'''
调参
knn = kNN()
# 训练模型
knn.fit(x_train,y_train)
# 创建一个列表保存不同的准确率
result_list = []
knn.dist_func = distance
# 考虑不同的k值
for k in range(1,10,1):
knn.n_neighbors = k
# 传入测试数据,做预测
y_pred = knn.predict(x_test)
# 求出预测准确率
accuracy = accuracy_score(y_test,y_pred)
result_list.append([k,accuracy])
df = pd.DataFrame(result_list,columns = ['k','预测准确率'])
df

sklearn模块的实现
参数介绍
sklearn.neighbors 模块中的KNeighborsClassifier类可以实现KNN算法。
KNeighborsClassifier(n_neighbors=5, *, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=None)
-
n_neighbors: int, 可选参数(默认为 5)用于kneighbors查询的默认邻居的数量
-
weights(权重): str or callable(自定义类型), 可选参数(默认为 ‘uniform’)用于预测的权重函数。可选参数如下:
- ‘uniform’ : 统一的权重. 在每一个邻居区域里的点的权重都是一样的。
- ‘distance’ : 权重点等于他们距离的倒数。使用此函数,更近的邻居对于所预测的点的影响更大。
- ‘callable’ : 一个用户自定义的方法,此方法接收一个距离的数组,然后返回一个相同形状并且包含权重的数组。
-
algorithm(算法): {‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, 可选参数(默认为 ‘auto’)
计算最近邻居用的算法:- ‘ball_tree’是为了克服kd树高纬失效而发明的,其构造过程是以质心C和半径r分割样本空间,每个节点是一个超球体。 ball-tree按超球面进行划分。球树:找到一个中心点,使所有样本点到这个中心点的距离最短。对于每一个节点的子节点的选择,方式如下:选择当前超球体区域离中心最远的点作为左子节点选择距离左子节点距离最远的点作为右子节点对于其他的样本点,计算到左子节点和右子节点对应样本点的欧式距离,并分配到距离较近的那一个对所有子节点做相同的操作
- ‘kd_tree’ 构造kd树存储数据以便对其进行快速检索的树形数据结构,kd树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高。
- Kd-tree按维度逐次划分kd 树是一个二叉树,每一个内部的节点都代表了一个超矩形空间,并且它的子树包含在这个超矩形空间内部的所有样本点。但是 kd 树对于一些样本分布情况而言效率并不高,比如当大量样本落在一个超矩形的角落的情况,此时使用球树的效率会更高
- ‘brute’ 使用暴力搜索.也就是线性扫描,当训练集很大时,计算非常耗时
- ‘auto’ 会基于传入fit方法的内容,选择最合适的算法。
-
leaf_size(叶子数量): int, 可选参数(默认为 30)。传入BallTree或者KDTree算法的叶子数量。此参数会影响构建、查询BallTree或者KDTree的速度,以及存储BallTree或者KDTree所需要的内存大小。 此可选参数根据是否是问题所需选择性使用
-
p: integer, 可选参数(默认为 2)。 用于Minkowski metric(闵可夫斯基空间)的超参数。p = 1, 相当于使用曼哈顿距离 (l1),p = 2, 相当于使用欧几里得距离(l2) 对于任何 p ,使用的是闵可夫斯基空间(l_p)
-
metric(矩阵): string or callable, 默认为 ‘minkowski’用于树的距离矩阵。默认为闵可夫斯基空间,如果和p=2一块使用相当于使用标准欧几里得矩阵. 所有可用的矩阵列表请查询 DistanceMetric 的文档。
-
metric_params(矩阵参数): dict, 可选参数(默认为 None)给矩阵方法使用的其他的关键词参数。
-
n_jobs: int, 可选参数(默认为 1), 用于搜索邻居的,可并行运行的任务数量。设定工作的core数量,如果为-1, 任务数量设置为CPU核的数量。不会影响fit方法。
测试
#测试
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.neighbors import KNeighborsClassifier
iris = load_iris()
# 划分训练集和测试集
x = iris.data
y = iris.target.reshape(-1,1)#将iris.target 行向量,转换成列
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3)
knn = KNeighborsClassifier(n_neighbors=3,weights='uniform',algorithm='auto')
knn.fit(x_train,y_train)
# 传入测试数据,做预测
y_pred = knn.predict(x_test)
# 求准确率
accuracy = accuracy_score(y_test,y_pred)
print('预测准确率:',accuracy)
'''预测准确率: 0.9555555555555556'''
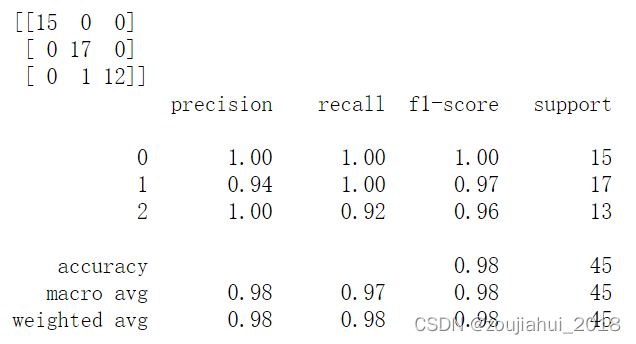
计算混淆矩阵
sklearn.metrics模块中的confusion_matrix和classification_report 函数可以计算出混淆矩阵和预测正确率等指标。
from sklearn.metrics import confusion_matrix,classification_report
print(confusion_matrix(y_test, y_pre))
print(classification_report(y_test, y_pre))