从一则用户案例说起
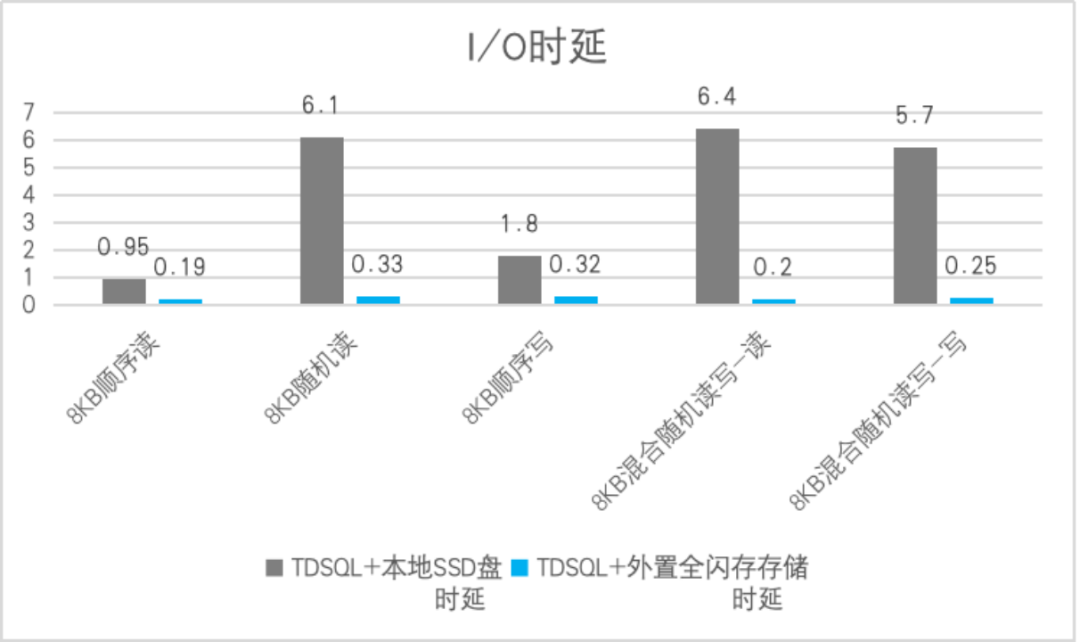
某金融用户问,数据库用服务器本地盘性能好还是外置存储好?直觉上,本地盘路径短性能应该更好。然而测试结果却出乎意料:同等中等并发压力,混合随机读写模型,服务器本地SSD盘合计4万 IOPS水平,时延竟然高达6ms,回退到机械磁盘时代的水平,而外置存储同样并发压力下30万IOPS,稳定时延在0.2ms。
I/O模型 | TDSQL+本地SSD盘时延 | TDSQL+外置全闪存存储时延 |
8KB顺序读 | 0.95 | 0.19 |
8KB随机读 | 6.1 | 0.33 |
8KB顺序写 | 1.8 | 0.32 |
8KB混合随机读写-读 | 6.4 | 0.2 |
8KB混合随机读写-写 | 5.7 | 0.25 |
可以看到,单靠先天物理路径上的优势或者硬件资源堆叠,并不能代表一定高效,更先进架构和算法才是决定性的竞争力。实际上,存算一体和存算分离在数据库发展史上多次反复,每一次变化都由技术进步推动而来。
第一次存算分离
初期的IT系统体量小,以存算一体为主
通用电气公司1961年开发的第一款数据库管理系统,叫做IDS(Integrated Data Store,集成数据存储),只能运行在通用电气的主机上,且只有一个文件存储在本地盘上,由本机的CPU、内存依据手工编码的指令来读写。总而言之,早期的数据库系统以存算一体的方式部署在本地盘上,有以下两点主要原因:
当时的数据库属于高端应用,和各种大型机、中型机紧密绑定在一起。如当时经典的 IBM 大型机System/360,后来被熟知的数据库 DB2 最早就是运行在这个平台上,凭借在当时强大的算力和本地化存储能力,在全球各大金融机构和科研实验室占据领导地位。
数据量小。以当时的银行信贷管理系统为例,这个系统的数据量在当时只有10GB左右,使用大型机的本地存储空间绰绰有余。
IT系统数据体量爆发式上涨,计算和存储开始走向分离
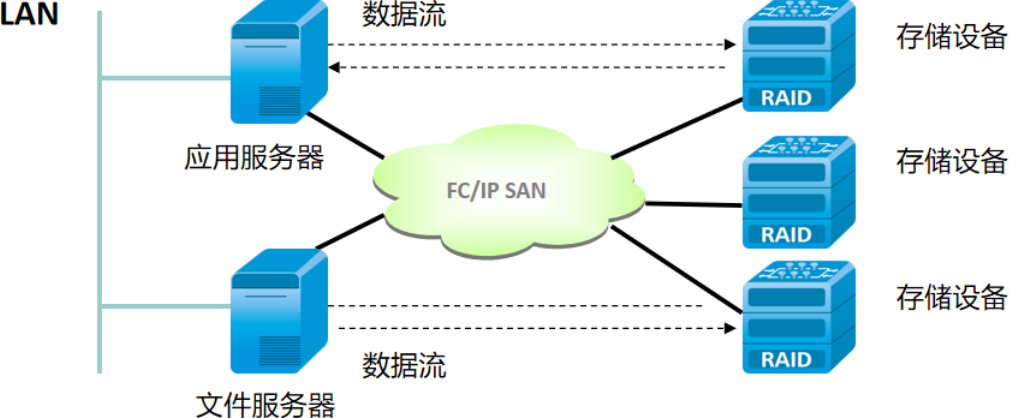
此后,随着互联网技术的兴起,数据库系统的数据量开始激增,传统的单机数据库服务器无法满足不断增长的大量数据的存储和访问,UNIX 系统也开始大行其道,而几乎所有的 UNIX 主机都具备了连接独立存储服务器的能力,在这一时期,面向块设备应用的存储区域网络(SAN)和面向网络文件系统的网络附加存储(NAS)方案开始占据主导,此时主要的架构方案选择由存算一体转向了存算分离架构,外置集中式共享存储设备开始流行。
商业数据库巨头 Oralce 从9i版本开始,推出了基于共享存储的RAC,RAC的各计算节点与共享存储分离,解决了数据库算力横向扩展问题和容错性问题,同时利用1000Mbps网络的普及,将缓存也以共享的概念构建了Cache Fusion,也就是被业界津津乐道的缓存融合技术,效率上的提升让 Oracle 的并发处理性能得到了质的提升。
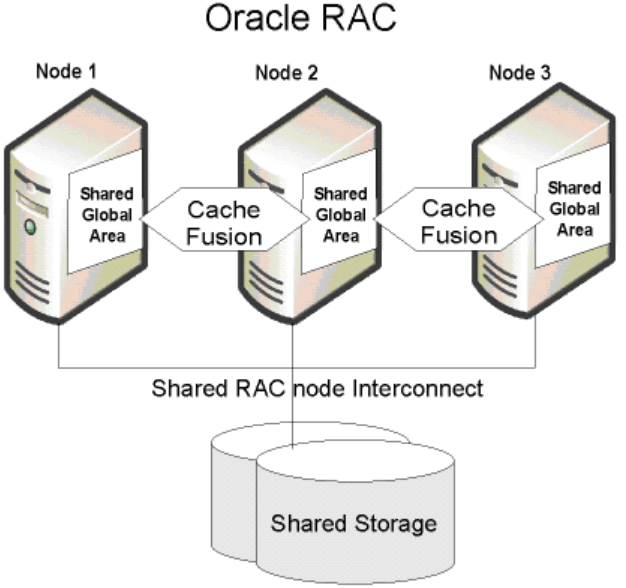
毫无疑问,在当时RAC的问世是革命性的,也一举奠定了 Oracle 在核心级数据库系统领域的霸主地位。在这次的存算分离当中, 最重要的支撑技术主要包括成熟的网络组网技术,以及成熟的存储网络技术,当然 Oracle 自己的杀手级技术缓存融合,也起到很大的作用。
海量数据催生的存算一体
时间来到21世纪的10、20年代,伴随着web2.0、3.0的飞速发展,越来越多的业务成为互联网业务,业务访问并发量的升级带来了数据量指数级激增。人们开始意识到,不仅仅需要获取业务生产所必须的数据,还需要获取海量数据加工之后的价值数据。于是各行业都开始在原业务基础上搭建自己的商业智能系统,来构建新型的核心业务系统,这时客户面临的最大挑战一是成本,二是吞吐量。

因为传统小型机和高端存储阵列价格居高不下,想搭建一套自有的分析系统,在硬件和license上是一笔不小的投资,而且即便花巨资建好,数据库跑数据分析也可能很慢,找厂家定位后被告知:磁盘转速不够、网络带宽不够、CPU处理不够……总之,还得继续砸钱把硬件堆上去。
究其原因,主要是在基于传统集中式共享存储的存算分离架构下,IO有瓶颈:主机端只处理数据而不存数据,因此要去共享存储端取数据,这时从网络走一道加一层延迟,而存储端读HDD机械盘又加一层,层层加码造成了读写效率的大大降低。
Apache 基金会开发的 Hadoop 分布式基础架构利用多节点并发和本地化计算突破了IO的瓶颈,它一出生就是奔着存算一体设计的,通过将计算任务分发到存储数据所在的位置解决了在当时困扰已久的网络瓶颈问题。
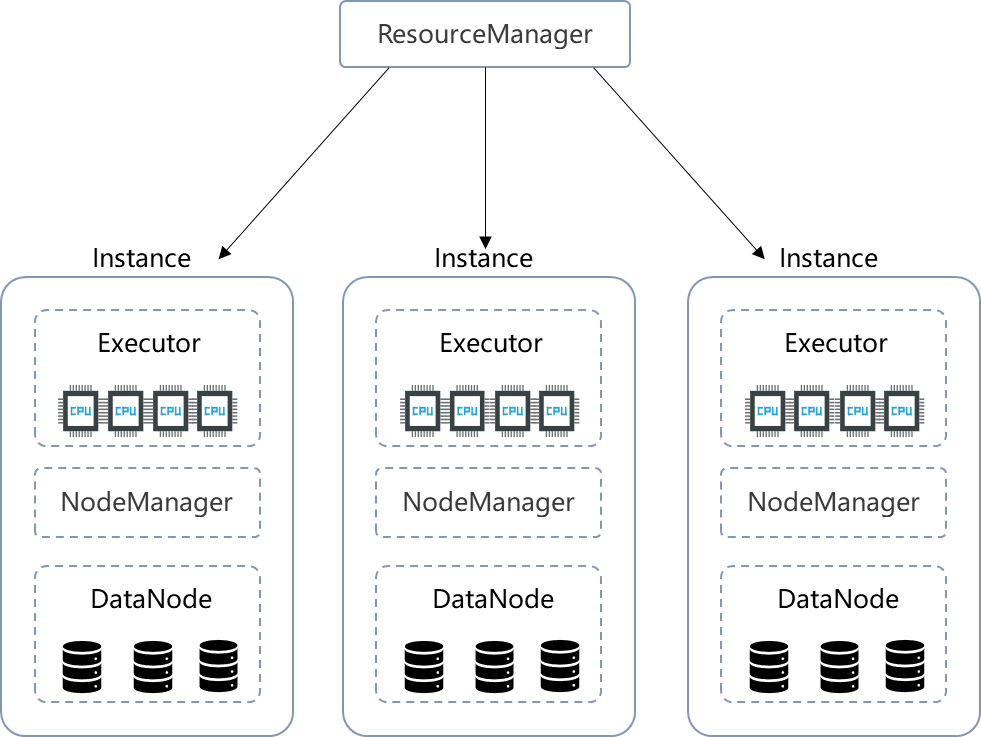
Hadoop 的特别之处在于存算一体化架构下的数据本地性:
集群中每个实例(Instance)既负责存储数据(DataNode),也负责处理计算任务(Executor)。
调度时会把计算任务尽最大可能发到要处理数据所在的实例上。
Hadoop 的第一代技术框架,用分布式解决了并发数和带宽的问题,用本地化计算解决了网络瓶颈问题,同时其包括HDFS分布式存储在内的多个 Hadoop 核心组件可以被广泛部署在低价的硬件设备之上,提升了用户的使用性价比。
云计算时代带来新一代的存算分离
随着云计算的快速发展,按需付费的概念开始深入人心,即使对于本地化部署的核心系统资源也要求能做到按需供给,那么存算一体的紧耦合架构在这时就无法满足用户需求了。而数据库技术也在往资源服务化的方向发展,把基于独立计算和共享存储的松耦合架构向前推进了一大步。
Google 在2014年的发布会上公布的开源项目 Kubernetes,使得云计算弹性扩展的优势得到充分的发挥,它是一种基于容器技术的云原生应用部署和管理的架构体系,Kubernetes 部署的应用往往被拆分成多个不同的子模块,封装在一个个容器中,被称之为“微服务”,同时各应用模块又按照是否存在持久化数据为标准,区分为有状态和无状态。当应用需要对外提供服务时,可以先利用存储接口组件连接起外置存储,构建出一个有状态的持久化数据库资源池,在此之上再根据上层业务的服务需要动态的加载各种无状态的微服务,其过程就好比集装箱在装卸货箱一样:每个货箱都是标准化的规则单位体积,可以根据车头的动力不同而选择装卸不同数量的货箱,保证每一趟车都可以拉够力所能及的箱子,同时货箱在不同的车头之间还能很方便的调换。Kubernetes 的问世,使得云基础设施中存算解耦的实现具备了技术基础。
数据库也在云原生理念潮流的推动下,演进出了能适应多变和不确定业务需求的Serverless数据库方案。传统的云数据库只是将数据库部署在云基础设施上而未对数据库做改进优化,局限于其存算一体的架构,存和算的资源比率被限制在一个范围内,其弹性范围、资源利用率都受到较大的限制。另一方面,由于节点间的Share-Nothing,新增节点必定触发跨节点的数据全量复制,性能至少下降20%。阿里云推出的 PolarDB 是典型的Serverless数据库,它能根据业务实际情况自动调整数据库的资源规模,下图是 PolarDB 技术架构:
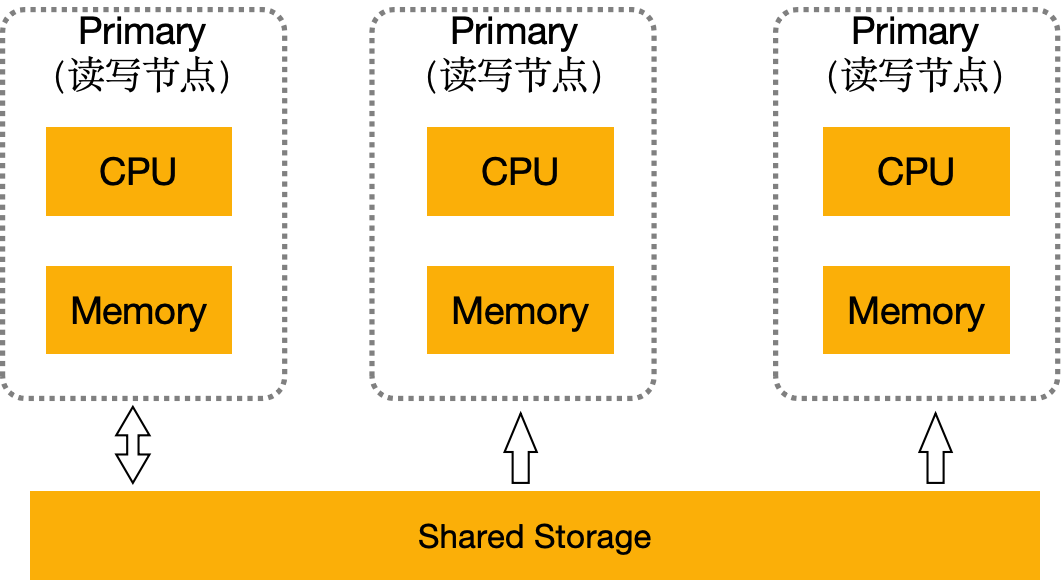
它首先将计算和存储资源进行解耦分离,存算分离的架构是Serverless能力的基础。分离后的数据统一存储在资源池中,故 PolarDB 用户在每个计算节点上都能看到所有数据,拥有着单机数据库体验感的同时,资源得到了很好的利用:存储空间支持以Serverless的方式按需自动伸缩,而计算节点不管扩展到多少个,数据也始终只有一份。
而 AWS 推出的云数据库 Aurora 则在存算分离的基础上将分布式的优势发挥得更加彻底,它将存储端由集中式资源池改为分布式集群卷,使得数据的可靠性和容错性有了更进一步的保障。下面再来简单看一看 Aurora 技术架构:
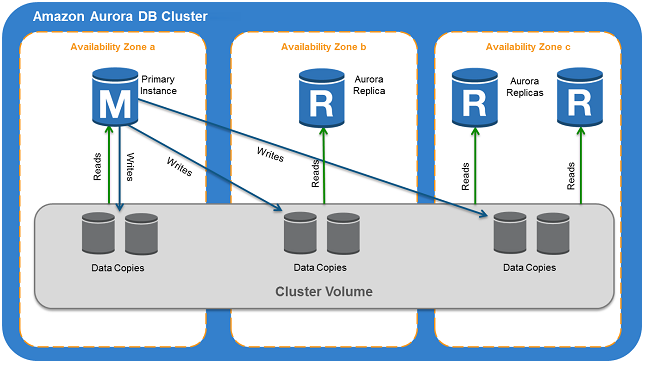
Aurora 的架构有以下几个突出的特点:
将存储层作为一个跨数据中心分布式服务体系,相对于计算层而独立构建,可以灵活自由的按需扩展;
计算和存储端操作分离,互不影响。计算端将包含redo log在内的数据处理逻辑全部下推到存储端来异步执行;
计算层和存储层都使用的现有的ECS实例,并没有特殊的底层设施。也就是说,Aurora 是基于 AWS 现有的服务打造出来的,是符合云计算服务化标准的。
存算分离架构提供了充分利用云计算红利的基础,不同应用场景、不同压力下的用户业务可以随时根据需求,灵活的增加或减少对应的服务资源。同时因为存储资源也与计算资源解耦,所以也可以按需进行横向扩展,大大提高了资源利用率。
存算分离是多元数据库时代基础设施架构的最优解
可以看到,在新的技术水平下,IT栈分层解耦,专业的事通过专业的解决方案实现,存算分离架构重新成为技术演进趋势上的选择。AWS Aurora、华为云 GaussDB、阿里云 PolarDB 等都不约而同采用了共享存储的方式,通过“存算分离”架构,去提升数据库的整体能力。
存算分离架构应用于数据库基础设施场景中时,可以带来以下价值:
可靠性提升:外置的共享存储可靠性结合数据库集群本身的故障切换能力,解决了一体化方案可靠性只能依赖上层集群实现的短板。
能力复用:使用共享专业分布式存储成熟的快照克隆、数据校验、亚健康检测等能力,快速提升数据库整体解决方案能力。
架构开放:基于开放生态的存储底座,可快速支撑起多种不同类型数据库的运行,有利于数据库应用的平滑落地。
快速迭代:软硬解耦的SDS软件定义存储架构,易于通过软件版本的更新迭代,实现存储能力的不断提升,与各种不同技术流派数据库的发展路线很好的匹配,同步演进。
云和恩墨 zData X 数据库一体机和 zStorage 高性能分布式存储软件:为数据库撑起“核心”之名
云和恩墨 zData X 数据库一体机,基于自研高性能分布式存储软件 zStorage,采用存算分离架构,是融合高性能计算、分布式全闪存存储、RoCE网络、和数据库管理服务的数据库一体化运行平台。
zData X 支持多种类型的商业、开源和国产数据库,包括 Oracle、MySQL、PostgreSQL、MogDB、达梦、人大金仓、openGauss 等。zData X 可按需配置,满足不同规模数据库的性能、可靠性和扩展性要求,提升数据库管理效率。适用于核心数据库性能加速和多元异构数据库存储资源池化部署等场景。
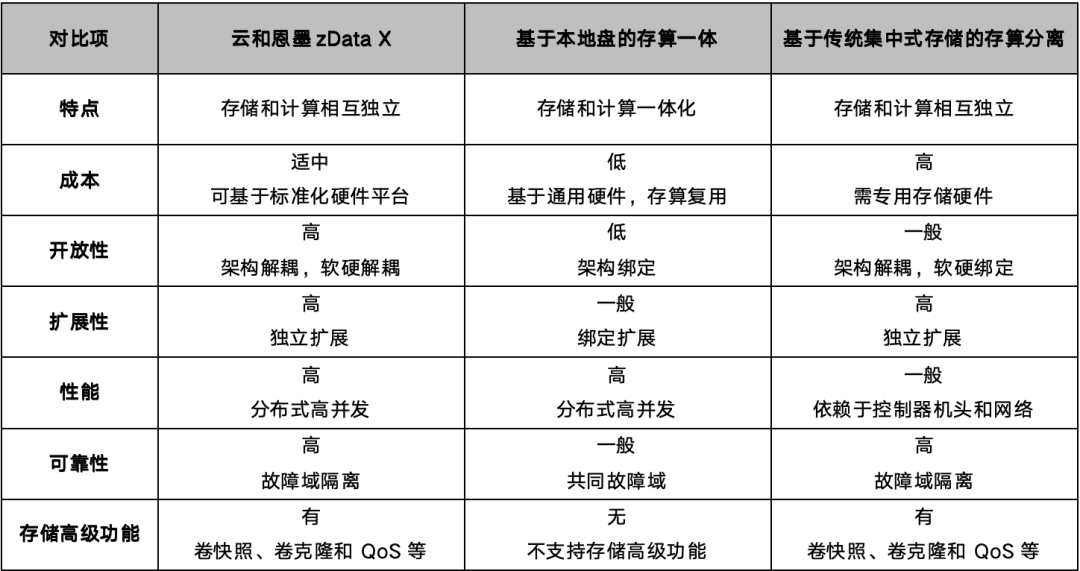
zData X 架构上的两个特点:
存算分离,计算和存储均可以按需弹性扩展。
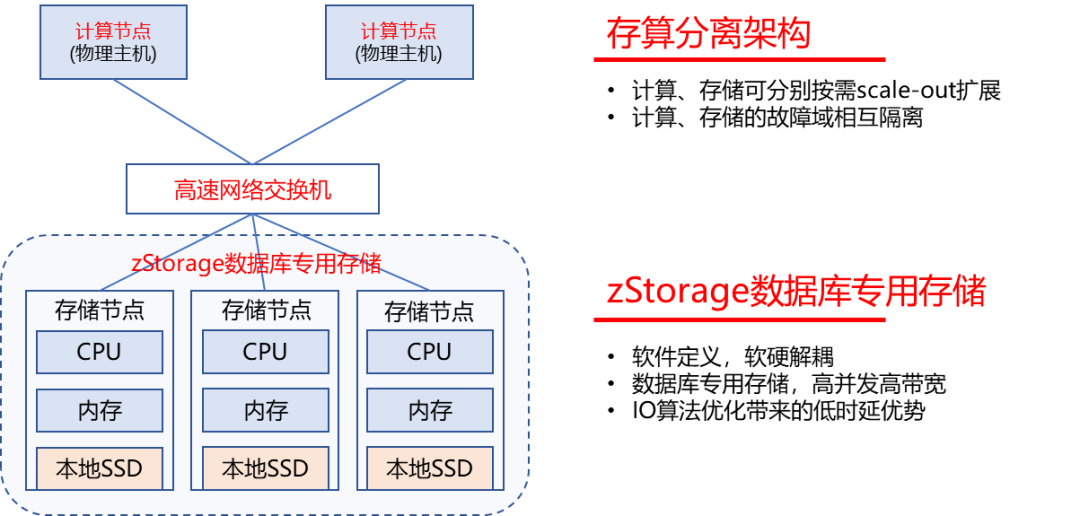
存储端采用高性能分布式存储软件 zStorage 取代了传统架构中的集中式存储。zStorage 兼具分布式存储的高扩展性、软件定义云化能力与集中式存储的低时延、丰富的数据保护特性,为数据库提供云化的高性能、高可靠性、高扩展性数据底座。zData X 无论相对于存算一体化,还是相对基于传统集中式存储的存算分离架构,都有明显的优势。

数据驱动,成就未来,云和恩墨,不负所托!
云和恩墨创立于2011年,以“数据驱动,成就未来”为使命,是智能的数据技术提供商。我们致力于将数据技术带给每个行业、每个组织、每个人,构建数据驱动的智能未来。
云和恩墨在数据承载(分布式存储、数据持续保护)、管理(数据库基础软件、数据库云管平台、数据技术服务)、加工(应用开发质量管控、数据模型管控、数字化转型咨询)和应用(数据服务化管理平台、数据智能分析处理、隐私计算)等领域为各个组织提供可信赖的产品、服务和解决方案,围绕用户需求,持续为客户创造价值,激发数据潜能,为成就未来敏捷高效的数字世界而不懈努力。