
☁️主页 Nowl
🔥专栏《机器学习实战》 《机器学习》
📑君子坐而论道,少年起而行之

文章目录
一.任务描述
二.数据集描述
三.主要代码
(1)主要代码库的说明与导入方法
(2)数据预处理
(3)模型训练
(4)模型预测与性能评估
(5)除数据预处理外的完整代码
四.本章总结
一.任务描述
在泰坦尼克号灾难中,了解乘客生存状况是一个重要而挑战性的任务。这个任务的目标是通过分析乘客的各种特征,构建预测模型,以预测一个乘客在沉船事件中是否幸存。数据集提供了关于每位乘客的多个方面的信息,如性别、年龄、客舱等级等。
通过利用这些特征,机器学习算法可以学习模式,从而推断出哪些因素对于乘客生存的影响最为显著。例如,可能发现女性、儿童或者在更高等级客舱的乘客更有可能幸存。通过对模型进行训练和优化,可以得到一个能够根据新的乘客信息进行幸存预测的工具。
这个任务的重要性不仅在于还原历史事件,更在于提供了一个实际应用背景下的机器学习问题。通过探索这个问题,可以深入了解特征之间的关系、模型选择以及优化方法,从而拓展对机器学习在实际场景中应用的认识。

二.数据集描述
获取数据集: 幸存者预测训练集
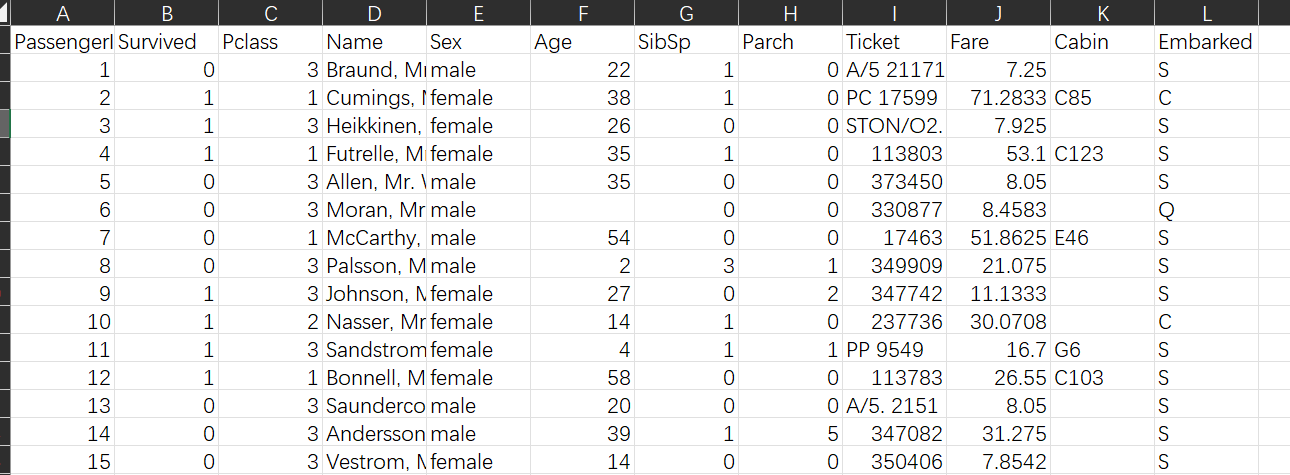
以下是对数据集中的特征的描述
- PassengerId(乘客ID): 每个乘客的唯一标识符。
- Survived(生存情况): 乘客是否存活,通常是二进制值,1表示存活,0表示未存活。
- Pclass(客舱等级): 乘客所在的客舱等级,通常分为1、2、3等级,反映了社会经济地位。
- Name(姓名): 乘客的姓名。
- Sex(性别): 乘客的性别,可能是"male"(男性)或"female"(女性)。
- Age(年龄): 乘客的年龄。
- SibSp(同伴/兄弟姐妹的数量): 乘客在船上有多少兄弟姐妹或配偶。
- Parch(父母/子女的数量): 乘客在船上有多少父母或子女。
- Ticket(船票号码): 乘客的船票号码。
- Fare(票价): 乘客支付的票价。
- Cabin(客舱号码): 乘客所在的客舱号码。
- Embarked(登船港口): 乘客登船的港口,可能是"C"(Cherbourg)、"Q"(Queenstown)或"S"(Southampton)。
这些特征提供了关于每位乘客的各种信息,可以用于分析和预测乘客在泰坦尼克号上的生存情况。通过构建机器学习模型来预测某位乘客是否在沉船事件中幸存下来。
三.主要代码
为了精简说明,(2)-(4)仅为主要部分,请自行导入库
(1)主要代码库的说明与导入方法

pandas (
Pandas是一个用于数据处理和分析的强大库,提供了数据结构(如DataFrame和Series)和数据操作工具,使得在Python中进行数据清理、转换和分析变得更加方便。import pandas as pd):matplotlib.pyplot (
Matplotlib是一个用于绘制图表和可视化数据的2D绘图库。import matplotlib.pyplot as plt):pyplot是Matplotlib的子模块,提供了类似于MATLAB的绘图接口,用于创建图表、直方图、散点图等。sklearn.model_selection (
from sklearn.model_selection import train_test_split):train_test_split是scikit-learn中用于划分数据集为训练集和测试集的函数。它能够随机将数据划分为两个子集,是机器学习中常用的数据准备步骤之一。RandomForestClassifier (
from sklearn.ensemble importRandomForestClassifier): RandomForestClassifier是 scikit-learn 中的随机森林分类器,是一种基于集成学习的算法。它通过构建多个决策树并综合它们的预测结果来提高模型的性能和鲁棒性。随机森林广泛用于分类和回归问题。它在处理大量数据、高维特征和复杂模式时表现良好,通常被用于构建强健的预测模型。sklearn.metrics (
from sklearn import metrics):metrics模块包含了许多用于评估模型性能的指标,例如准确性、精确度、召回率、F1分数等。这些指标可用于评估分类、回归和聚类等任务的模型性能。
(2)数据预处理
1.查看数据基本信息
注意这里的文件地址要改成你自己的,不然运行不了
# 导入文件
survive = pd.read_csv("datasets/titanic/train.csv")
# 查看数据列名称
print(survive.columns)
# 查看数据集格式
print(survive.shape)2.通过数据集的描述,我们可以剔除一些无关的特征,例如乘客的姓名,登船的港口,船票号码,客舱号码这些看起来与是否能存活下来无关的特征
# 删除无关特征
survive = survive.drop(columns=["Name", "Ticket", "Embarked", "Cabin", "PassengersId"])3.查看数据是否有空值
# 打印所有特征的空值数量
print(survive.isnull().sum())
# 删除含有空值的行
survive = survive.dropna() 
可以看到Age列有177个空值,我们将这些有缺失的行删除
4.将字符特征转化为数字特征
字符数据是无法被我们的机器学习模型学习的,我们必须将它们转化为数字特征,本数据中性别只有两类,所以我们将它们变为0和1
survive["Sex"] = survive["Sex"].replace({"male": 1, "female": 0})5.划分训练集与测试集
将数据分为训练集与测试集,测试集规模为20%,训练数据删除"Survived"列,将结果设置为"Survived"列
划分训练集与测试集
train, test = train_test_split(survive, test_size=0.2)
train_x = train.drop(columns="Survived")
train_y = train.Survived
test_x = test.drop(columns="Survived")
test_y = test.Survived(3)模型训练
使用随机森林模型进行训练,每次抽样100给样本,每棵树最大深度设置为10
# 构建随机森林模型
model = RandomForestClassifier(n_estimators=100, max_depth=10)
model.fit(train_x, train_y)(4)模型预测与性能评估
使用metric的准确率作为模型指标
prediction = model.predict(test_x)
print('The accuracy of the RandomForest is:', metrics.accuracy_score(prediction, test_y))
准确率大概为82%,还不错!
(5)除特征工程外的完整代码
这里是舍弃了一些寻找特征等工作的完整模型训练代码
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
survive = pd.read_csv("datasets/titanic/train.csv")
survive = survive.drop(columns=["Name", "Ticket", "Embarked", "Cabin", "PassengerId"])
survive = survive.dropna()
survive["Sex"] = survive["Sex"].replace({"male": 1, "female": 0})
train, test = train_test_split(survive, test_size=0.2)
train_x = train.drop(columns="Survived")
train_y = train.Survived
test_x = test.drop(columns="Survived")
test_y = test.Survived
model = RandomForestClassifier(n_estimators=100, max_depth=10, random_state=42)
model.fit(train_x, train_y)
prediction = model.predict(test_x)
print('The accuracy of the RandomForest is:', metrics.accuracy_score(prediction, test_y))
四.本章总结
- 根据任务特点挖掘重要特征
- 如何去除无用的特征
- 数据中有空缺值如何处理
- 如何将字符特征转化为数字
- 随机森林模型的应用
当然,也可以自己处理特征,自己选择模型,调整参数,看看会不会获得更好的结果






![[蓝桥杯训练]———高精度乘法、除法](https://img-blog.csdnimg.cn/07efda7a53e744a28dca1cd116898023.jpeg#pic_center)
