Sand alone 架构
Standalone模式是Spark自带的一种集群模式,不同于前面本地模式启动多个进程来模拟集群的环境,Standalone模式是真实地在多个机器之间搭建Spark集群的环境,完全可以利用该模式搭建多机器集群,用于实际的大数据处理。
Stand alone 是完整的spark运行环境,其中 Master 角色以Master进程存在,worker角色以worker进程存在,
Driver角色在运行时存在于Master进程内,Executor运行于Worker进程内
StandAlone集群在进程上主要有3类进程:
- 主节点Master进程:
Master角色, 管理整个集群资源,并托管运行各个任务的Driver - 从节点Workers:
Worker角色, 管理每个机器的资源,分配对应的资源来运行Executor(Task);
每个从节点分配资源信息给Worker管理,资源信息包含内存Memory和CPU Cores核数 - 历史服务器HistoryServer(可选):
Spark Application运行完成以后,保存事件日志数据至HDFS,启动HistoryServer可以查看应用运行相关信息。
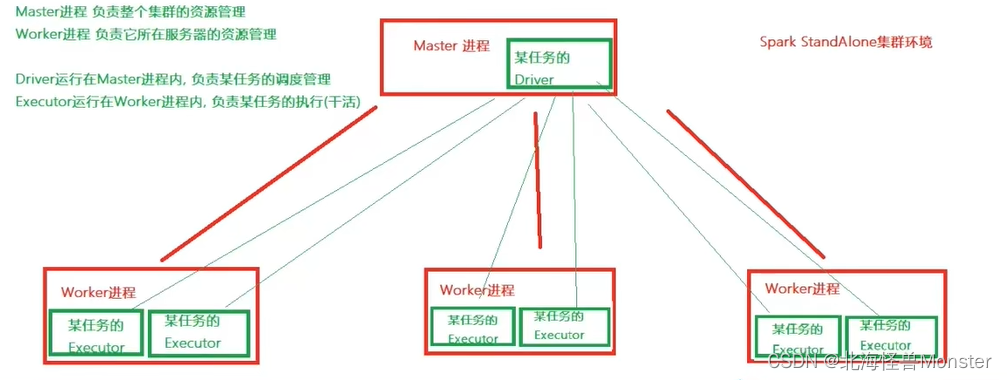
对于上图有一个地方需要注意:
在 standalone 模式下, master进程和 worker进程是固定的。
开启一个任务,就会在master进程中开启一个对应的 Driver,然后在worker中开启一个或者多个 Executor
开启两个任务,就会在master进程中开启两个对应的 Driver,对应的Executor各自汇报给对应的Driver,Executor数量根据你任务情况而定。
stand alone 环境安装
node1运行: Spark的Master进程 和 1个Worker进程
node2运行: spark的1个worker进程
node3运行: spark的1个worker进程
整个集群提供: 1个master进程 和 3个worker进程
前提:在所有机器安装Python(Anaconda)
参照 单机模式下的 Anaconda安装即可,除了不解压
https://blog.csdn.net/m0_48639280/article/details/128459471
记得配置 /etc/profile /root/.bashrc
更改国内源
进入到spark的安装目录,进入conf文件夹
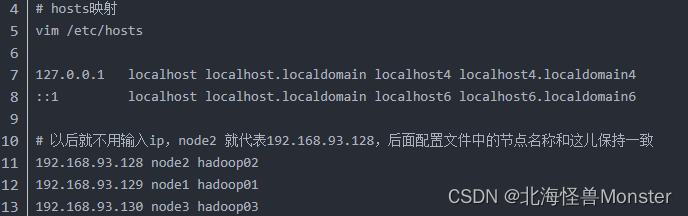
配置workers文件,这儿有一个前提,你/etc/hosts 文件有路由映射,要是你没有映射worker文件设置不生效
# 改名, 去掉后面的.template后缀
mv workers.template workers
# 编辑worker文件
vim workers
# 将里面的localhost删除, 追加
node1
node2
node3
到workers文件内
# 功能: 这个文件就是指示了 当前SparkStandAlone环境下, 有哪些worker
配置spark-env.sh文件
# 1. 改名
mv spark-env.sh.template spark-env.sh
# 2. 编辑spark-env.sh, 在底部追加如下内容
## 设置JAVA安装目录
JAVA_HOME=/export/server/jdk
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
## 指定spark老大Master的IP和提交任务的通信端口
# 告知Spark的master运行在哪个机器上
export SPARK_MASTER_HOST=node1
# 告知sparkmaster的通讯端口
export SPARK_MASTER_PORT=7077
# 告知spark master的 webui端口
SPARK_MASTER_WEBUI_PORT=8080
# worker cpu可用核数
SPARK_WORKER_CORES=1
# worker可用内存
SPARK_WORKER_MEMORY=1g
# worker的工作通讯地址
SPARK_WORKER_PORT=7078
# worker的 webui地址
SPARK_WORKER_WEBUI_PORT=8081
## 设置历史服务器
# 配置的意思是 将spark程序运行的历史日志 存到hdfs的/sparklog文件夹中
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
在HDFS上创建程序运行历史记录存放的文件夹:
hadoop fs -mkdir /sparklog
hadoop fs -chmod 777 /sparklog 修改权限方便后续操作
配置spark-defaults.conf文件
# 1. 改名
mv spark-defaults.conf.template spark-defaults.conf
# 2. 修改内容, 追加如下内容
# 开启spark的日期记录功能
spark.eventLog.enabled true
# 设置spark日志记录的路径
spark.eventLog.dir hdfs://node1:8020/sparklog/
# 设置spark日志是否启动压缩
spark.eventLog.compress true
配置log4j.properties 文件 [可选配置]
# 1. 改名
mv log4j.properties.template log4j.properties
# 2. 修改内容 参考下图

将Spark安装文件夹 分发到其它的服务器上
目前这些配置只在 node1上。
scp -r spark-3.1.2-bin-hadoop3.2 node2:/export/server/
scp -r spark-3.1.2-bin-hadoop3.2 node3:/export/server/
准备步骤完成了,最后检查每台机器的:
JAVA_HOME
SPARK_HOME
PYSPARK_PYTHON
等等 环境变量是否正常指向正确的目录
启动历史服务器,在spark安装目录下的sbin目录
start-history-server.sh 执行该脚本即可
如下图,则启动成功

还是这个sbin目录
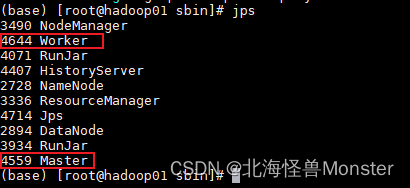
通过 start-all.sh脚本启动集群 stop-all.sh 脚本关闭集群
start-master.sh start-work.sh 启动当前机器上的 master 和 worker
如下图,则启动成功

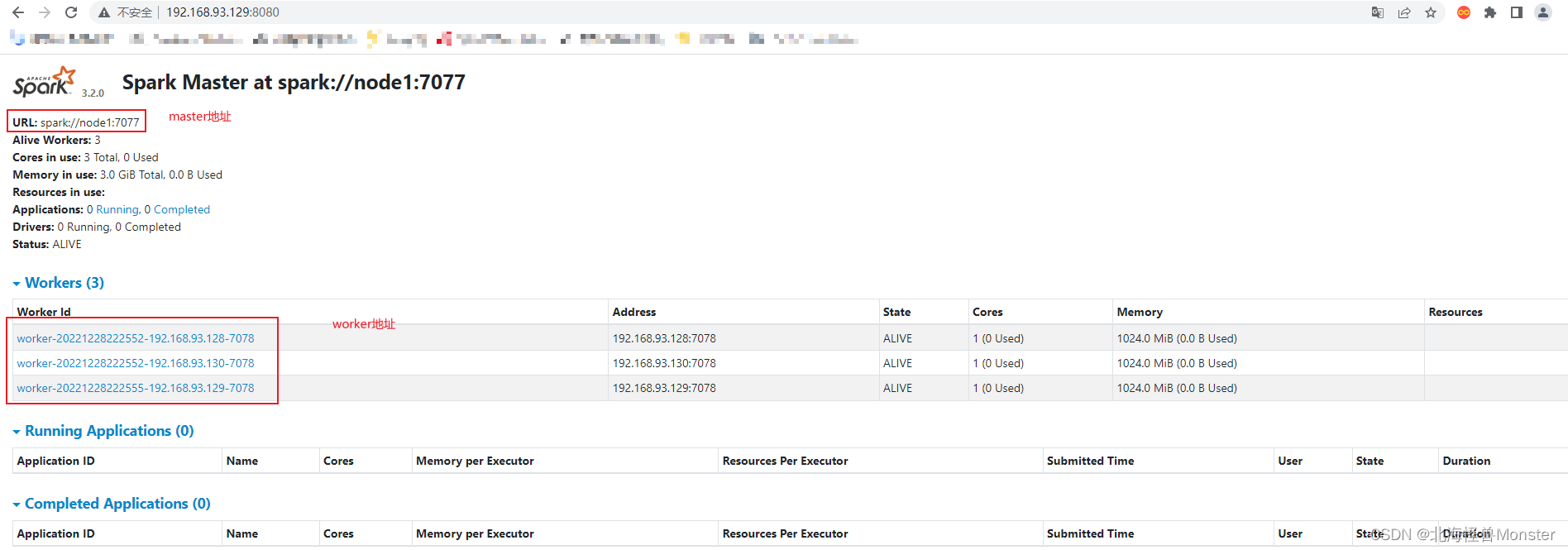
查看Master的WEB UI
默认端口master我们设置到了8080
如果端口被占用, 会顺延到8081 …;8082… 8083… 直到申请到端口为止
可以在日志中查看, 具体顺延到哪个端口上:
Service 'MasterUI' could not bind on port 8080. Attempting port 8081.