前言
嗨喽,大家好呀~这里是爱看美女的茜茜呐
又到了学Python时刻~

环境使用:
-
Python 3.8
-
Pycharm
-
专业版是付费的 <激活码可以免费用>
-
社区版是免费的
-
模块使用:
第三方模块 需要安装的
-
requests >>> pip install requests
-
parsel >>> pip install parsel
-
csv
安装python第三方模块:
-
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
-
在pycharm中点击Terminal(终端) 输入安装命令
爬虫基本流程:
一. 数据来源分析
-
明确需求:
-
明确采集网站是什么?
-
明确采集数据是什么?
车辆基本信息
-
-
分析 车辆基本信息数据, 具体是请求那个网址可以得到
通过开发者工具, 进行抓包分析:
-
打开开发者工具: F12 / 鼠标右键点击检查选择network
-
刷新网页: 让本网页数据内容重新加载一遍 <方便分析数据出处>
-
搜索数据来源: 复制你想要的内容, 进行搜索即可
车辆信息数据
-
二. 代码实现步骤
-
发送请求, 模拟浏览器对于url地址发送请求
-
获取数据, 获取服务器返回响应数据
开发者工具: response <网页源代码>
-
解析数据, 提取我们想要的数据内容
- 车辆信息
-
保存数据, 把车辆信息保存csv表格里面
代码展示
PS:本篇完整源码如有需要的小伙伴可以加下方的群去找管理员免费领取

采集数据
导入模块
# 导入数据请求模块 --> 第三方模块 需要安装 pip install requests
import requests
# 导入数据解析模块 --> 第三方模块 需要安装 pip install parsel
import parsel
# 导入csv模块 --> 内置模块 不需要安装
import csv
创建文件
f = open('data.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'标题',
'年份',
'里程',
'城市',
'价格',
'标签',
'是否保修',
'详情页',
])
写入表头
csv_writer.writeheader()
“”"
- 发送请求, 模拟浏览器对于url地址发送请求
-
安装模块: win + R 输入cmd
输入安装命令: pip install requests -
导入模块是灰色, 不是报错, 而是导入模块没有使用
-
伪装模拟 headers 请求头
- 字典数据类型, 要构建完整键值对 <引号位置一定要加对>
- 可以直接复制
-
<Response [200]> 响应对象
200 状态码 表示请求成功 -
批量替换
- 选择替换内容
- ctrl + R 输入正则命令即可
:.*
,
-
“”"
for page in range(1, 51):
print(f'======================正在采集第{page}页的数据内容======================')
确定请求链接

# 伪装模拟
headers = {
# User-Agent 用户代理 表示浏览器基本身份信息
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 发送请求
response = requests.get(url=url, headers=headers)
print(response)
“”"
-
获取数据, 获取服务器返回响应数据
开发者工具: response <网页源代码>
response.text 获取响应文本数据 <网页源代码>
html字符串数据 --> re正则 -
解析数据, 提取我们想要的数据内容
- 车辆信息css选择器: 根据标签属性提取内容
选择器对象
“”"
# 把获取下来 response.text 转成 可解析对象
selector = parsel.Selector(response.text)
# 第一次提取, 获取所有li标签 ---> 获取所有车辆信息所在标签
lis = selector.css('.Content_left .gongge_ul li')
# for循环遍历, 把列表里面元素一个一个提取出来
for li in lis:
"""
提取每一个车辆信息具体的数据内容
.title --> 定位class类名为title的标签
attr(title) --> 提取标签里面title属性
get() --> 提取第一个标签数据, 获取一个, 返回字符串
getall() --> 提取所有的标签数据, 获取多个, 返回列表
strip() --> 去除字符串左右两端空格
replace() --> 字符串替换方法
"""
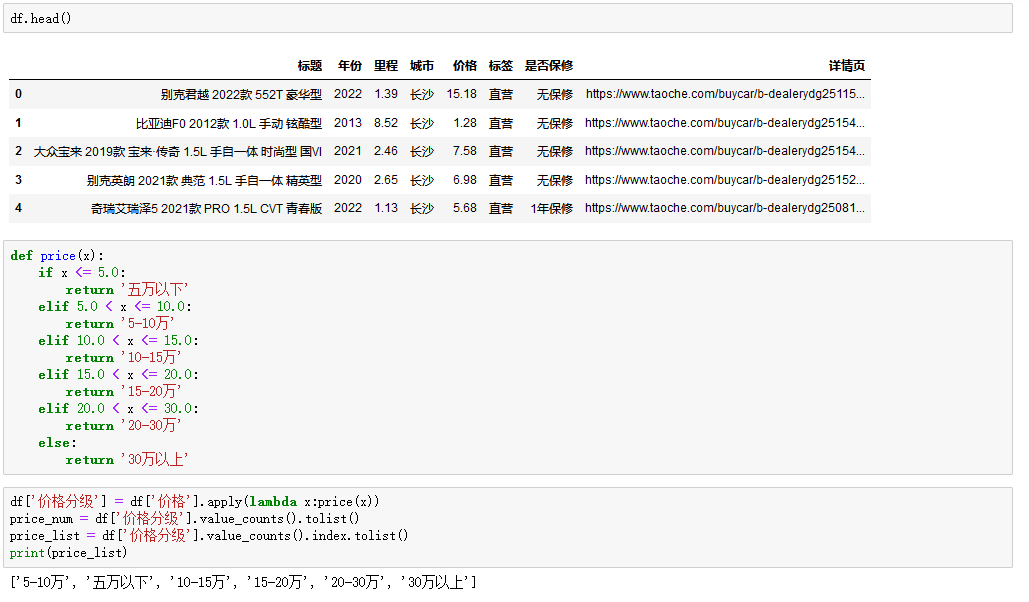
title = li.css('.title::attr(title)').get() # 标题
car_info = li.css('.gongge_main p i::text').getall() # 基本信息
year = car_info[0].replace('年', '') # 年份
mileage = car_info[1].replace('万公里', '') # 里程
city = car_info[2].strip() # 城市
label = li.css('.car_tag em::text').get().strip() # 标签
tag = li.css('.tc_label::text').get() # 保修
price = li.css('.Total::text').get() # 价格
href = li.css('.title::attr(href)').get() # 详情页
# 解析出来的数据保存字典里面
dit = {
'标题': title,
'年份': year,
'里程': mileage,
'城市': city,
'价格': price,
'标签': label,
'是否保修': tag,
'详情页': href,
}
# 写入数据
csv_writer.writerow(dit)
print(title, year, mileage, city, price, label, tag, href)
数据分析

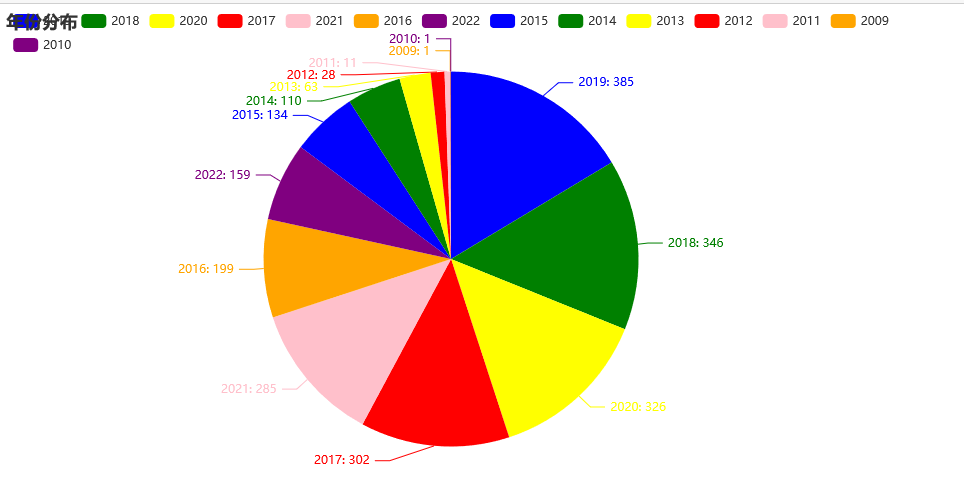
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
c = (
Pie()
.add("", [list(z) for z in zip(year_type, year_num)])
.set_colors(["blue", "green", "yellow", "red", "pink", "orange", "purple"])
.set_global_opts(title_opts=opts.TitleOpts(title="年份分布"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# .render("pie_set_color.html")
)
c.render_notebook()
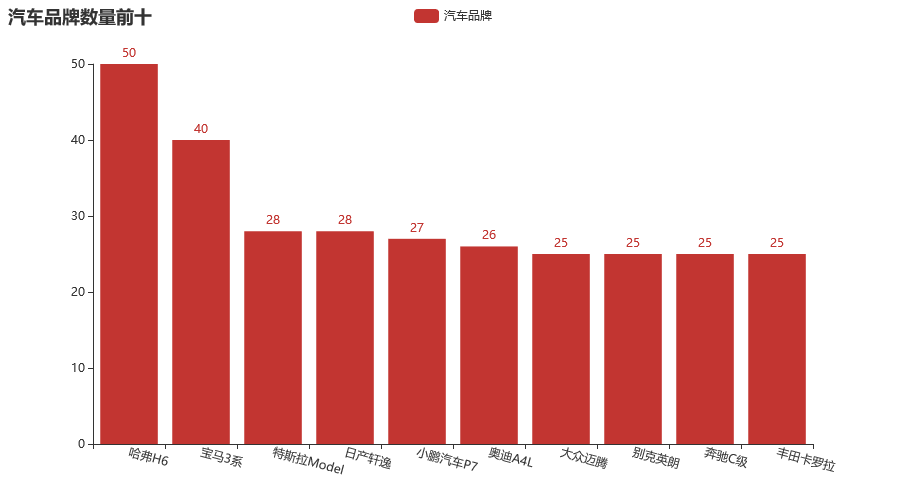
df_title = df.apply(lambda x:x['标题'].split(' ')[0], axis=1)
title_list = df_title.value_counts().index.tolist()[:10]
title_num = df_title.value_counts().tolist()[:10]
from pyecharts import options as opts
from pyecharts.charts import Bar
c = (
Bar()
.add_xaxis(title_list)
.add_yaxis("汽车品牌", title_num)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
title_opts=opts.TitleOpts(title="汽车品牌数量前十"),
)
)
c.render_notebook()
from pyecharts import options as opts
from pyecharts.charts import Liquid
c = (
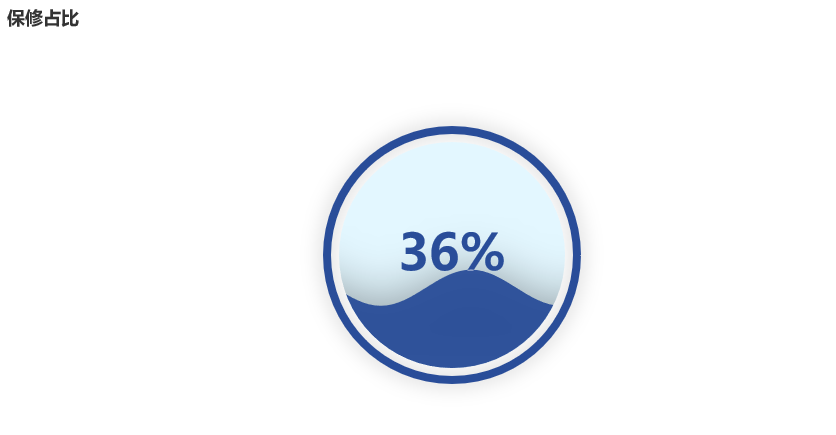
Liquid()
.add("lq", [1-per])
.set_global_opts(title_opts=opts.TitleOpts(title="保修占比"))
)
c.render_notebook()
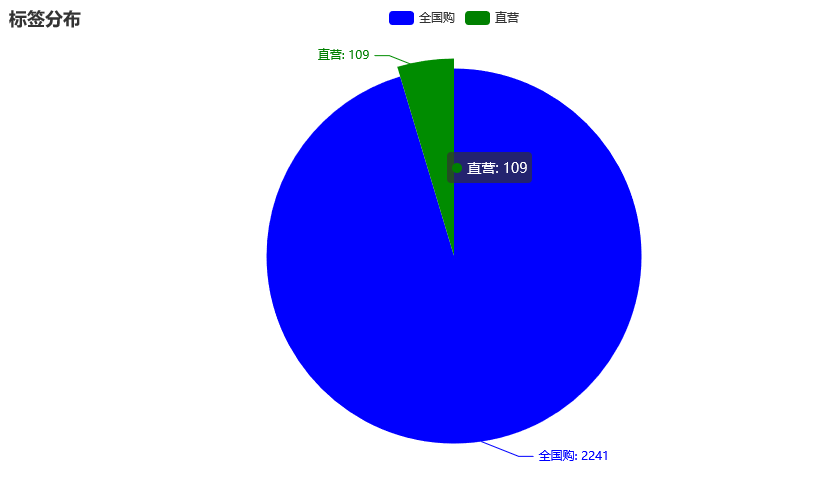
lable_num = df['标签'].value_counts().tolist()
lable_type = df['标签'].value_counts().index.tolist()
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
c = (
Pie()
.add("", [list(z) for z in zip(lable_type, lable_num)])
.set_colors(["blue", "green", "yellow", "red", "pink", "orange", "purple"])
.set_global_opts(title_opts=opts.TitleOpts(title="标签分布"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# .render("pie_set_color.html")
)
c.render_notebook()
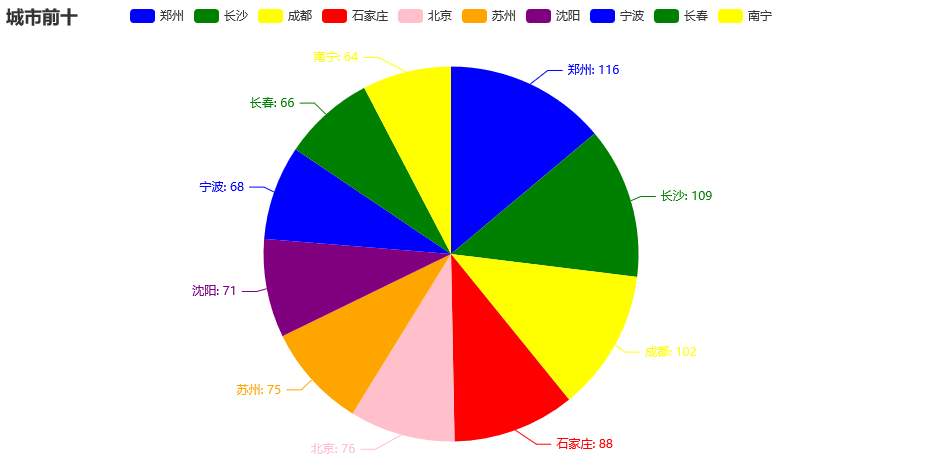
city_num = df['城市'].value_counts().tolist()[:10]
city_type = df['城市'].value_counts().index.tolist()[:10]
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
c = (
Pie()
.add("", [list(z) for z in zip(city_type, city_num)])
.set_colors(["blue", "green", "yellow", "red", "pink", "orange", "purple"])
.set_global_opts(title_opts=opts.TitleOpts(title="城市前十"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# .render("pie_set_color.html")
)
c.render_notebook()
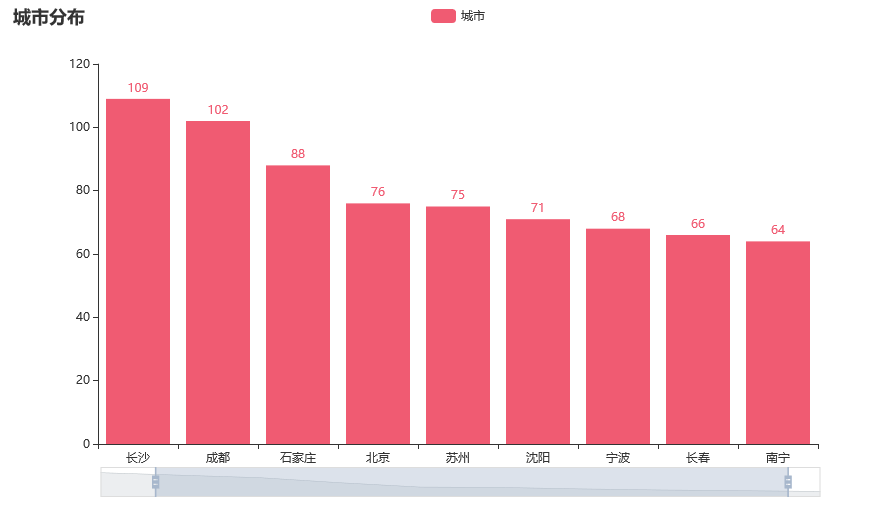
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.faker import Faker
c = (
Bar()
.add_xaxis(city_type)
.add_yaxis("城市", city_num, color=Faker.rand_color())
.set_global_opts(
title_opts=opts.TitleOpts(title="城市分布"),
datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts(type_="inside")],
)
)
c.render_notebook()
# print(Faker.days_attrs)
# print(Faker.days_values)
# print(Faker.rand_color())
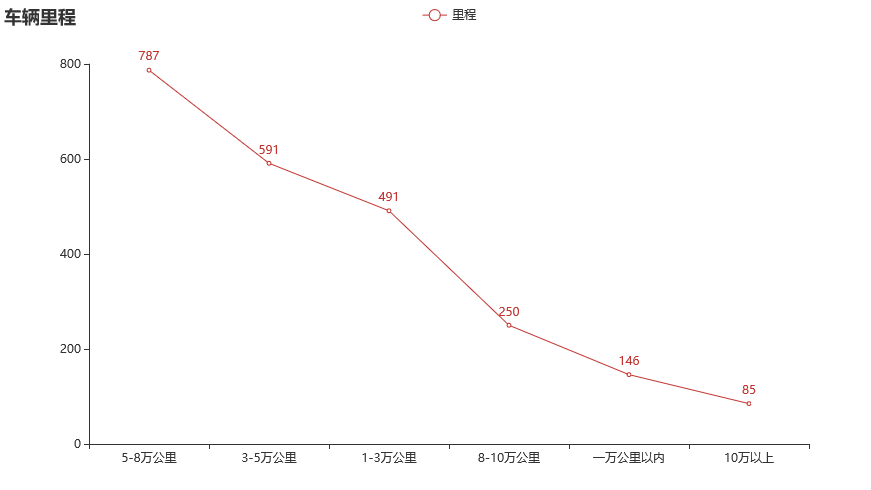
import pyecharts.options as opts
from pyecharts.charts import Line
from pyecharts.faker import Faker
c = (
Line()
.add_xaxis(price_list)
.add_yaxis("价格", price_num)
.set_global_opts(title_opts=opts.TitleOpts(title="车辆价格"))
)
c.render_notebook()


尾语
感谢你观看我的文章呐~本次航班到这里就结束啦 🛬
希望本篇文章有对你带来帮助 🎉,有学习到一点知识~
躲起来的星星🍥也在努力发光,你也要努力加油(让我们一起努力叭)。
最后,博主要一下你们的三连呀(点赞、评论、收藏),不要钱的还是可以搞一搞的嘛~
不知道评论啥的,即使扣个6666也是对博主的鼓舞吖 💞 感谢 💐





![【GO】 K8s 管理系统项目[API部分--Namespace]](https://img-blog.csdnimg.cn/5791e0ae3bf64221a96e3a0febbb4f4f.png)