本文相关内容只记录看论文过程中一些难点问题,内容间逻辑性不强,甚至有点混乱,因此只作为本人“备忘”,不建议其他人阅读。
DENOISING DIFFUSION IMPLICIT MODELS: https://arxiv.org/abs/2010.02502
前序知识 DDPM:https://blog.csdn.net/a40850273/article/details/134601881
DDIM
一、DDIM 没有独立的训练过程,可以直接复用 DDPM 的训练过程以及训练好的模型就可以直接采样。
具体原因是 DDPM 的具体推导过程中是要求边缘分布服从
的高斯分布,而对于联合分布
没有具体要求。虽然 DDPM 中假定了扩散过程服从马尔科夫特性,但是即使不满足依然可以使用 DDPM 的训练过程进行求解。因此 DDIM 就设计了一个不服从马尔科夫特性的扩散过程,从而加速采样。
二、非马尔科夫扩散过程设计
具体设计如下,只要满足如下定义,边缘分布就满足 。因此,就可以使用如下非马尔科夫分布对反向扩散过程进行采样。DDIM 的分布与 DDPM 的分布之间的差别主要是将
引入的均值部分,如果
与 DDPM 中的
相同时,那 DDIM 将退化为 DDPM。
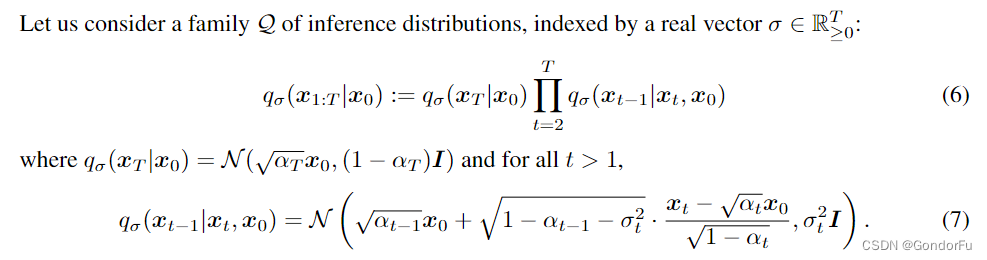
具体证明过程:
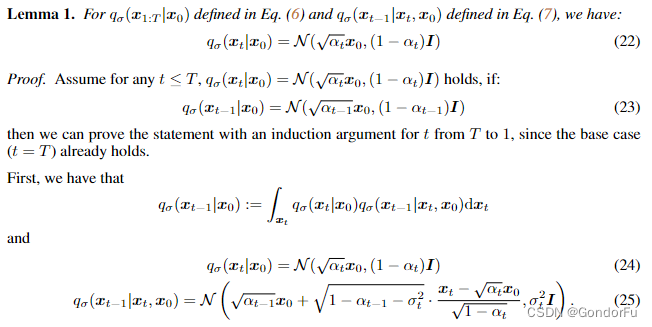
且
,则
—— Bishop (2006) (2.115)

三、DDIM 采样过程
二 中给出了逆向扩散过程概率分布,不过具体进行采样时,由于 未知,因此需要先基于
对
进行估计。
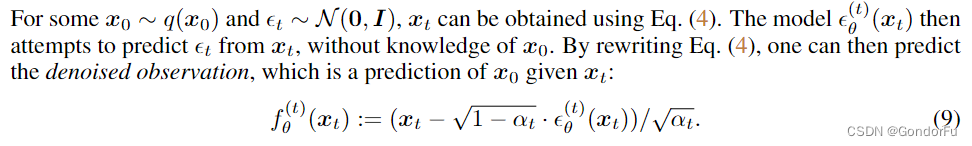
然后将 作为
的估计代入 二 中的逆向扩散分布中得到具体的递归采样公式。

进一步,可以设置 为零,那么整个反向过程中将不存在任何随机性,变成一个确定性过程。对应最终生成的样本由初始
的随机高斯采样结果直接确定,
的差异最终导致生成样本的多样性。
# https://github.com/CompVis/stable-diffusion/blob/main/ldm/models/diffusion/ddim.py L165
# 以下采样过程涉及条件生成内容,核心代码计算就是前面的公式,为标注 core code 的部分
@torch.no_grad()
def p_sample_ddim(self, x, c, t, index, repeat_noise=False, use_original_steps=False, quantize_denoised=False,
temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None,
unconditional_guidance_scale=1., unconditional_conditioning=None):
b, *_, device = *x.shape, x.device
if unconditional_conditioning is None or unconditional_guidance_scale == 1.:
e_t = self.model.apply_model(x, t, c)
else:
x_in = torch.cat([x] * 2)
t_in = torch.cat([t] * 2)
c_in = torch.cat([unconditional_conditioning, c])
e_t_uncond, e_t = self.model.apply_model(x_in, t_in, c_in).chunk(2)
e_t = e_t_uncond + unconditional_guidance_scale * (e_t - e_t_uncond)
if score_corrector is not None:
assert self.model.parameterization == "eps"
e_t = score_corrector.modify_score(self.model, e_t, x, t, c, **corrector_kwargs)
alphas = self.model.alphas_cumprod if use_original_steps else self.ddim_alphas
alphas_prev = self.model.alphas_cumprod_prev if use_original_steps else self.ddim_alphas_prev
sqrt_one_minus_alphas = self.model.sqrt_one_minus_alphas_cumprod if use_original_steps else self.ddim_sqrt_one_minus_alphas
sigmas = self.model.ddim_sigmas_for_original_num_steps if use_original_steps else self.ddim_sigmas
# select parameters corresponding to the currently considered timestep
a_t = torch.full((b, 1, 1, 1), alphas[index], device=device)
a_prev = torch.full((b, 1, 1, 1), alphas_prev[index], device=device)
sigma_t = torch.full((b, 1, 1, 1), sigmas[index], device=device)
sqrt_one_minus_at = torch.full((b, 1, 1, 1), sqrt_one_minus_alphas[index],device=device)
# >>>>>>>>>>>>>>>>> core code >>>>>>>>>>>>>>>>>>>>>>
# current prediction for x_0
pred_x0 = (x - sqrt_one_minus_at * e_t) / a_t.sqrt()
if quantize_denoised:
pred_x0, _, *_ = self.model.first_stage_model.quantize(pred_x0)
# direction pointing to x_t
dir_xt = (1. - a_prev - sigma_t**2).sqrt() * e_t
noise = sigma_t * noise_like(x.shape, device, repeat_noise) * temperature
if noise_dropout > 0.:
noise = torch.nn.functional.dropout(noise, p=noise_dropout)
x_prev = a_prev.sqrt() * pred_x0 + dir_xt + noise
return x_prev, pred_x0四、DDIM 加速采样过程 —— respacing









![[数据结构]-红黑树](https://img-blog.csdnimg.cn/af890bb3c539409294654bf1f0d9fda5.png)
