文章目录
- 一、前言
- 二、数据采集、处理和入库
- 2.1 获取神策 token
- 2.2 请求神策数据
- 2.3 数据处理-面向数组
- 2.4 测试阿里云 DataFrame 入库
- 2.5 调度设计与配置
- 2.6 项目代码整合
- 三、小结
- 四、花絮-避坑指南
- 第一坑:阿里云仅深圳节点支持神策数据
- 第二坑:神策 Token
- 第三坑:阿里云 RestAPI 只成功了一半!
- 第四坑:PyODPS 引用参数
- 第五坑:project 'for_analysis' is protected
一、前言
最近接到一个需求,查看用户在某个网站的访问情况,网站的访问数据通过神策进行埋点,用于用户标识(用户ID)的一些限制,数据被孤立了,不能直接通过神策直接解决该需求,需要先将神策数据入库,然后再和数据库其他用户数据打通,再获取一个更完整的用户画像信息。
本文主要介绍将神策数据入库的相关操作。
目标:将神策数据入库到 MaxCompute 数仓。
二、数据采集、处理和入库
基本逻辑就是请求神策数据->处理数据->转为 MaxCompute 数组并入库。
请求神策数据涉及 Token 获取、神策 API 的获取(官方文档)、 API 调试等内容;处理数据涉及面向数组的思想,还有处理时区问题、字典没有 Key 的取值方式等;转为 MaxCompute 数组并入库涉及 MaxCompute 建表、数据写入、调度参数使用、调度配置等问题。下面逐一来解决。
2.1 获取神策 token
这里的 Token 是 API secret 的 token,需要管理员获取。
2.2 请求神策数据
此处使用 Postman 进行调试工作。
根据文档介绍,导出事件 events 的数据的接口信息如下:
相关的神策数据导出 API 文档参考:https://manual.sensorsdata.cn/sa/latest/zh_cn/tech_export_transfer-150668708.html
curl 'https://saasdemo.cloud.sensorsdata.cn/api/sql/query?token=******&project=default' \
-X POST \
--data-urlencode "q=SELECT * FROM events where date = '2017-01-01' /*MAX_QUERY_EXECUTION_TIME=1800*/" \
--data-urlencode "format=event_json" \
>> event.json
需要改动的内容:
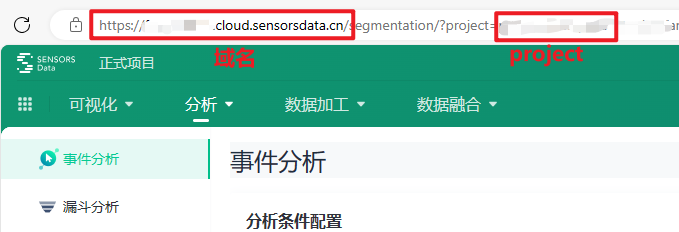
域名:https://saasdemo.cloud.sensorsdata.cn 需要改为自己的域名,登录神策正式项目之后,地址栏的前面那一串(如下图)
token:参考【2.1 获取神策 token】
project:链接参数可查看(如下图)
当你通过 Postman 请求成功之后,点击右边的【</>】标识,可以找到源代码,这是一个数据请求的 demo,支持很多语言,根据需要获取。
本次使用 Python 实现,所以取 Python 的 demo。
import requests
url = "https://【你的域名】/api/sql/query?token=【你的API Secret】&project=【你的项目】"
payload = {'q': 'SELECT * FROM events where date = \'2023-11-20\' limit 20 /*MAX_QUERY_EXECUTION_TIME=1800*/',
'format': 'event_json'}
files=[
]
headers = {
'Content-Type': 'application/x-www-form-urlencoded',
}
response = requests.request("POST", url, headers=headers, data=payload, files=files)
print(response.text)
发起请求之后,神策返回的数据结构大致如下,以下数据经过脱敏处理仅保留:type、event、time_free、time、distinct_id、properties共 6 个键,其中properties字段下还包含了$os、$os_version、$province、$city、$browser、$is_first_time共 5 个子键。
{"type":"track","event":"$pageview","time_free":true,"time":1700448379460,"distinct_id":"483855yhbjafigngduef1","properties":{"$os_version":"16.6.1","$city":"成都","$os":"iOS","$is_first_time":false,"$browser":"Mobile Safari","$country":"中国","$province":"四川"}}
{"type":"track","event":"$pageview","time_free":true,"time":1700448381061,"distinct_id":"483855yhbjafigngduef1","properties":{"$os_version":"16.6.1","$city":"株洲","$os":"iOS","$is_first_time":false,"$browser":"Mobile Safari","$country":"中国,"$province":"湖南"}}
{"type":"track","event":"$pageview","time_free":true,"time":1700466642669,"distinct_id":"483855yhbjafigngduef1","properties":{"$os_version":"16.6.1","$city":"长沙","$os":"iOS","$is_first_time":false,"$browser":"Mobile Safari","$country":"中国","$province":"湖南"}}
{"type":"track","event":"$pageview","time_free":true,"time":1700466642906,"distinct_id":"483855yhbjafigngduef1","properties":{"$os_version":"16.6.1","$city":"温州","$os":"iOS","$is_first_time":false,"$browser":"Mobile Safari","$country":"中国","$province":"浙江"}}
{"type":"track","event":"$pageview","time_free":true,"time":1700466644391,"distinct_id":"483855yhbjafigngduef1","properties":{"$os_version":"16.6.1","$city":"济南","$os":"iOS","$is_first_time":false, "$browser":"Mobile Safari","$country":"中国","$province":"山东"}}
{"type":"track","event":"$pageview","time_free":true,"time":1700485319088,"distinct_id":"483855yh1jafigngdue3d","properties":{"$browser_version":"7.0.20.1781","$os_version":"10","$city":"北京","$os":"Windows","$is_first_time":false,"$browser":"WeChat","$country":"中国","$province":"北京"}}
{"type":"track","event":"$pageview","time_free":true,"time":1700493761576,"distinct_id":"483855yh1jafigngdue3d","properties":{"$browser_version":"7.0.20.1781","$os_version":"10","$city":"上海","$os":"Windows","$is_first_time":false,"$browser":"WeChat","$country":"中国","$province":"上海"}}
{"type":"track","event":"$pageview","time_free":true,"time":1700493779926,"distinct_id":"483855yh1jafigngdue3d","properties":{"$browser_version":"7.0.20.1781","$os_version":"10","$city":"深圳","$os":"Windows","$is_first_time":false,"$browser":"WeChat","$country":"中国","$province":"广东"}}
{"type":"track","event":"$pageview","time_free":true,"time":1700493823995,"distinct_id":"483855yh1jafigngdue3d","properties":{"$browser_version":"7.0.20.1781","$os_version":"10","$city":"北京","$os":"Windows","$is_first_time":false,"$browser":"WeChat","$country":"中国","$province":"北京"}}
{"type":"track","event":"$pageview","time_free":true,"time":1700493863222,"distinct_id":"483855yh1jafigngdue3d","properties":{"$browser_version":"7.0.20.1781","$os_version":"10","$city":"广州","$os":"Windows","$is_first_time":false,"$browser":"WeChat","$country":"中国","$province":"广东"}}
2.3 数据处理-面向数组
通过数据处理,最终将数据处理为以下格式: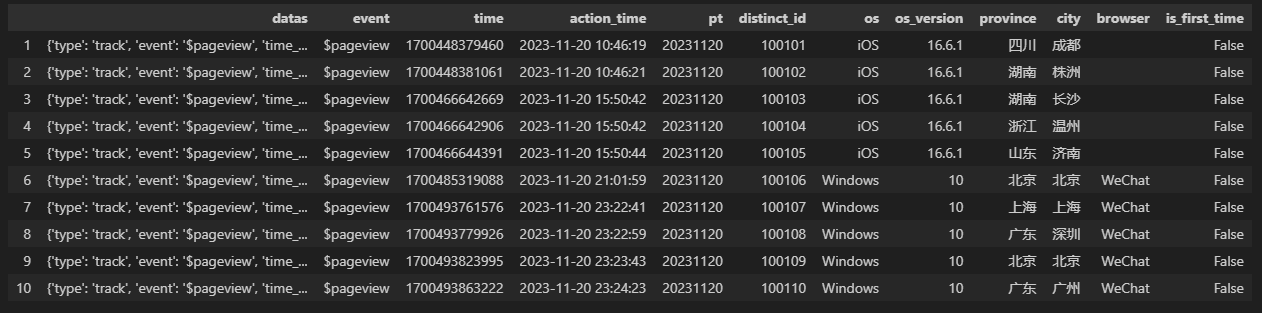
数据之间的关系映射如下:
| pandas 列 | 响应数据的键 |
|---|---|
| event | event |
| time | time |
| action_time | 由 time 时间 |
| pt | 由 time 格式化 |
| distinct_id | distinct_id |
| os | $os |
| os_version | $os_version |
| province | $province |
| city | $city |
| browser | $browser |
| is_first_time | $is_first_time |
这里舍弃了两个键:type、time_free,然后将其他的 8 个键分别处理为独立的一列,并对字段 time 进行处理,变成人眼易读的时间格式(‘年-月-日 时:分:秒’),同时格式化为日期格式(‘年月日’),便于后续入库作为表分区使用。特别注意:Pandas 的时期默认是 0 时区,所以将时间戳**time**转为北京时间的时候,注意加上 8 小时。
明确处理逻辑之后,开始进行数据处理。数据处理方式有多种,这里采用面向数组的方式进行处理,大概逻辑就是将请求到的数据直接转化为数组,然后用数组进行处理。即:
# 按行切割响应数据
res_datas = text.split('\n')
# 转为 json 数据(字符串),并转换为 DataFrame
datas_df = pd.read_json(json.dumps(res_datas))
# 将列数据转为字典,并修改列名为 datas
datas_df = pd.DataFrame(datas_df[0][datas_df[0] !=''].apply(lambda x:json.loads(x)))
datas_df.columns = ['datas']
神策返回的这个数据的处理难点在于:时区问题、子字段拆解(重点是部分记录key不完整)。
可以暂停思考下:如果是你,会怎么处理呢?
【时区问题】Pandas 处理数据默认使用 0 时区在时间戳和时间格式之间进行转换,如果不涉及转换问题,比如直接对时间戳或时间进行加减乘除不会出现问题,一旦涉及二者转换就需要进行时区处理。
这里提供一个转换方案是直接加 8 小时,即对datetime64[ns]类型的列,直接加上pd.Timedelta(hours=8))。参考如下:
#注意时区问题!!!
datas_df['action_time'] = pd.to_datetime((pd.to_datetime(datas_df.time,unit='ms')+ pd.Timedelta(hours=8)).dt.strftime('%Y-%m-%d %H:%M:%S')) #用于记录时间
datas_df['pt'] = (pd.to_datetime(datas_df.time,unit='ms')+ pd.Timedelta(hours=8)).dt.strftime('%Y%m%d') #用于分区
【子字段问题】子字段的拆解本身不难,难点是部分记录的 key 缺失,在字典对象里有一个很好的解决方法,就是采用get('[字段名]', '')来处理。
#有的key没有,使用:dict.get('[字段名]', '')
datas_df['os'] = datas_df.datas.apply(lambda x:x['properties'].get('$os', ''))
datas_df['os_version'] = datas_df.datas.apply(lambda x:x['properties'].get('$os_version', ''))
datas_df['province'] = datas_df.datas.apply(lambda x:x['properties'].get('$province', ''))
datas_df['city'] = datas_df.datas.apply(lambda x:x['properties'].get('$city', ''))
datas_df['browser'] = datas_df.datas.apply(lambda x:x['properties'].get('$browser', ''))
datas_df['is_first_time'] = datas_df.datas.apply(lambda x:x['properties'].get('$is_first_time', ''))
最终面向数组的处理方法的完整代码如下(可直接跑):
def dates_processing(text):
"""处理响应的数据"""
import pandas as pd
import json
# 按行切割响应数据
res_datas = text.split('\n')
# 转为 json 数据(字符串),并转换为 DataFrame
datas_df = pd.read_json(json.dumps(res_datas))
# 将列数据转为字典,并修改列名为 datas
datas_df = pd.DataFrame(datas_df[0][datas_df[0] !=''].apply(lambda x:json.loads(x)))
datas_df.columns = ['datas']
# 展开 datas,将数据取出,作为新列
datas_df['event'] = datas_df.datas.apply(lambda x:x['event'])
datas_df['time'] = datas_df.datas.apply(lambda x:x['time'])
#注意时区问题!!!
datas_df['action_time'] = pd.to_datetime((pd.to_datetime(datas_df.time,unit='ms')+ pd.Timedelta(hours=8)).dt.strftime('%Y-%m-%d %H:%M:%S')) #用于记录时间
datas_df['pt'] = (pd.to_datetime(datas_df.time,unit='ms')+ pd.Timedelta(hours=8)).dt.strftime('%Y%m%d') #用于分区
datas_df['distinct_id'] = datas_df.datas.apply(lambda x:x['distinct_id'])
#有的key没有,使用:dict.get('[字段名]', '')
datas_df['os'] = datas_df.datas.apply(lambda x:x['properties'].get('$os', ''))
datas_df['os_version'] = datas_df.datas.apply(lambda x:x['properties'].get('$os_version', ''))
datas_df['province'] = datas_df.datas.apply(lambda x:x['properties'].get('$province', ''))
datas_df['city'] = datas_df.datas.apply(lambda x:x['properties'].get('$city', ''))
datas_df['browser'] = datas_df.datas.apply(lambda x:x['properties'].get('$browser', ''))
datas_df['is_first_time'] = datas_df.datas.apply(lambda x:x['properties'].get('$is_first_time', ''))
return datas_df
response_text = '''
{"type":"track","event":"$pageview","time_free":true,"time":1700448379460,"distinct_id":"100101","properties":{"$os_version":"16.6.1","$city":"成都","$os":"iOS","$is_first_time":false,"$province":"四川"}}
{"type":"track","event":"$pageview","time_free":true,"time":1700448381061,"distinct_id":"100102","properties":{"$os_version":"16.6.1","$city":"株洲","$os":"iOS","$is_first_time":false,"$province":"湖南"}}
{"type":"track","event":"$pageview","time_free":true,"time":1700466642669,"distinct_id":"100103","properties":{"$os_version":"16.6.1","$city":"长沙","$os":"iOS","$is_first_time":false,"$province":"湖南"}}
{"type":"track","event":"$pageview","time_free":true,"time":1700466642906,"distinct_id":"100104","properties":{"$os_version":"16.6.1","$city":"温州","$os":"iOS","$is_first_time":false,"$province":"浙江"}}
{"type":"track","event":"$pageview","time_free":true,"time":1700466644391,"distinct_id":"100105","properties":{"$os_version":"16.6.1","$city":"济南","$os":"iOS","$is_first_time":false,"$province":"山东"}}
{"type":"track","event":"$pageview","time_free":true,"time":1700485319088,"distinct_id":"100106","properties":{"$os_version":"10","$city":"北京","$os":"Windows","$is_first_time":false,"$browser":"WeChat","$province":"北京"}}
{"type":"track","event":"$pageview","time_free":true,"time":1700493761576,"distinct_id":"100107","properties":{"$os_version":"10","$city":"上海","$os":"Windows","$is_first_time":false,"$browser":"WeChat","$province":"上海"}}
{"type":"track","event":"$pageview","time_free":true,"time":1700493779926,"distinct_id":"100108","properties":{"$os_version":"10","$city":"深圳","$os":"Windows","$is_first_time":false,"$browser":"WeChat","$province":"广东"}}
{"type":"track","event":"$pageview","time_free":true,"time":1700493823995,"distinct_id":"100109","properties":{"$os_version":"10","$city":"北京","$os":"Windows","$is_first_time":false,"$browser":"WeChat","$province":"北京"}}
{"type":"track","event":"$pageview","time_free":true,"time":1700493863222,"distinct_id":"100110","properties":{"$os_version":"10","$city":"广州","$os":"Windows","$is_first_time":false,"$browser":"WeChat","$province":"广东"}}
'''
dates_processing(response_text)
2.4 测试阿里云 DataFrame 入库
首先明白两个概念:PyODPS 自带的 DataFrame 和 Pandas 的 DataFrame,二者是不同的。
PyODPS 提供的 DataFrame API,有类似 Pandas 的接口,不过在处理数据的能力上没有 Pandas 提供 的 DataFrame 强。PyODPS 自带的 DataFrame 更能充分利用 MaxCompute 的计算能力。
本测试的数据流转是 字典dict_test->Pandas Dataframedatas_df->PyODPS Dataframepyodps_df->MaxCompute 表单project.my_new_table。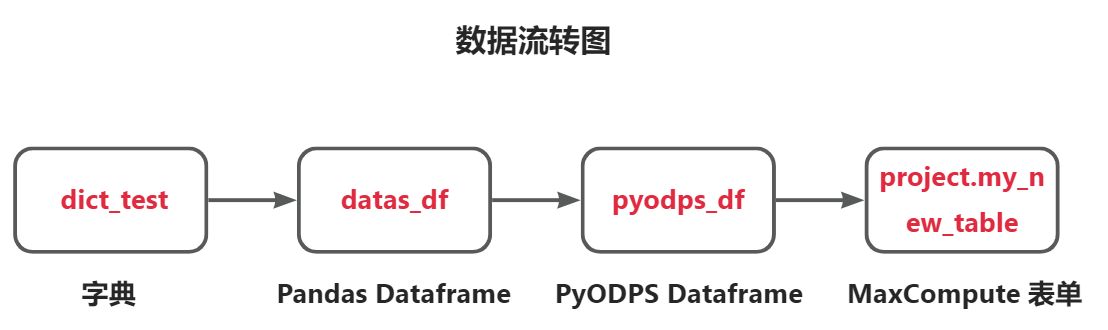
首先使用上面处理好的数据以字典的格式返回 3 条,然后将结果复制,然后赋值给dict_test,单独用于测试。
datas_df[:3].to_dict()
变量dict_test用来构建datas_df,datas_df是一个 Pandas 的 DataFrame 类型的表单,它和实际从神策请求的数据处理之后的结果是一致的,而且使用相同的变量名,所以在本测试通过之后可以直接将小块代码注释掉。datas_df用来创建 PyODPS 的 DataFrame 数组pyodps_df。
dic = {'datas': {1: {'type': 'track','event': '$pageview','time_free': True,'time': 1700448379460,'distinct_id': '100101','properties': {'$os_version': '16.6.1','$city': '成都','$os': 'iOS','$is_first_time': False,'$province': '四川'}},
2: {'type': 'track','event': '$pageview','time_free': True,'time': 1700448381061,'distinct_id': '100102','properties': {'$os_version': '16.6.1','$city': '株洲','$os': 'iOS','$is_first_time': False,'$province': '湖南'}},
3: {'type': 'track','event': '$pageview','time_free': True,'time': 1700466642669,'distinct_id': '100103','properties': {'$os_version': '16.6.1','$city': '长沙','$os': 'iOS','$is_first_time': False,'$province': '湖南'}}},
'event': {1: '$pageview', 2: '$pageview', 3: '$pageview'},
'time': {1: 1700448379460, 2: 1700448381061, 3: 1700466642669},
'action_time': {1: '2023-11-20 10:46:19',2: '2023-11-20 10:46:21',3: '2023-11-20 15:50:42'},
'pt': {1: '20231120', 2: '20231120', 3: '20231120'},
'distinct_id': {1: '100101', 2: '100102', 3: '100103'},
'os': {1: 'iOS', 2: 'iOS', 3: 'iOS'},
'os_version': {1: '16.6.1', 2: '16.6.1', 3: '16.6.1'},
'province': {1: '四川', 2: '湖南', 3: '湖南'},
'city': {1: '成都', 2: '株洲', 3: '长沙'},
'browser': {1: '', 2: '', 3: ''},
'is_first_time': {1: False, 2: False, 3: False}
}
datas_df = pd.DataFrame(dic)
变量pyodps_df是 PyODPS 自带的 DataFrame 类型,为了避免出现报错,需要指定数据类型,将列名和对应的数据类型传递给as_type参数。
pyodps_df = DataFrame(datas_df,as_type={
"event" : "string"
,"time" : "int64"
,"time_free" : "boolean"
,"distinct_id" : "string"
,"os" : "string"
,"os_version" : "string"
,"province" : "string"
,"city" : "string"
,"browser" : "string"
,"is_first_time" : "boolean"
,'pt' : "string"
})
变量args是调度配置的参数,测试时根据情况做取舍,如果是在 dataworks 中调试,可以直接在参数板块配置,然后注释掉该变量,发布调度之后一定要注释掉,避免出 bug。
DataWorks 的 PyODPS 节点中,将会包含一个全局变量 odps 或者 o,即为ODPS入口。所以可以直接使用o.create_table()来创建一个表单,注意其参数([表名],('字段1 数据类型,字段2 数据类型','分区字段 数据类型'),if_not_exists=True)中,第二个参数是一个元组,普通字段通过空格拼接在一起作为元组的第一个值,分区字段作为第二个值。
#创建分区表my_new_table,(表字段列表,分区字段列表)。
table = o.create_table(out_table, ('event string,time bigint,time_free boolean,distinct_id string,os string,os_version string,province string,city string,browser string,is_first_time boolean', 'pt string'), if_not_exists=True)
# 注意:该写入方式要求 DataFrame 的每个字段的类型都必须相同
在建表的时候还需要注意数据类型和 DataFrame 的数据类型可转换,否则会报错。参考 DataFrame 列类型和 ODPS SQL 字段类型的映射表:https://help.aliyun.com/zh/maxcompute/user-guide/sequence#section-avk-4s4-cfb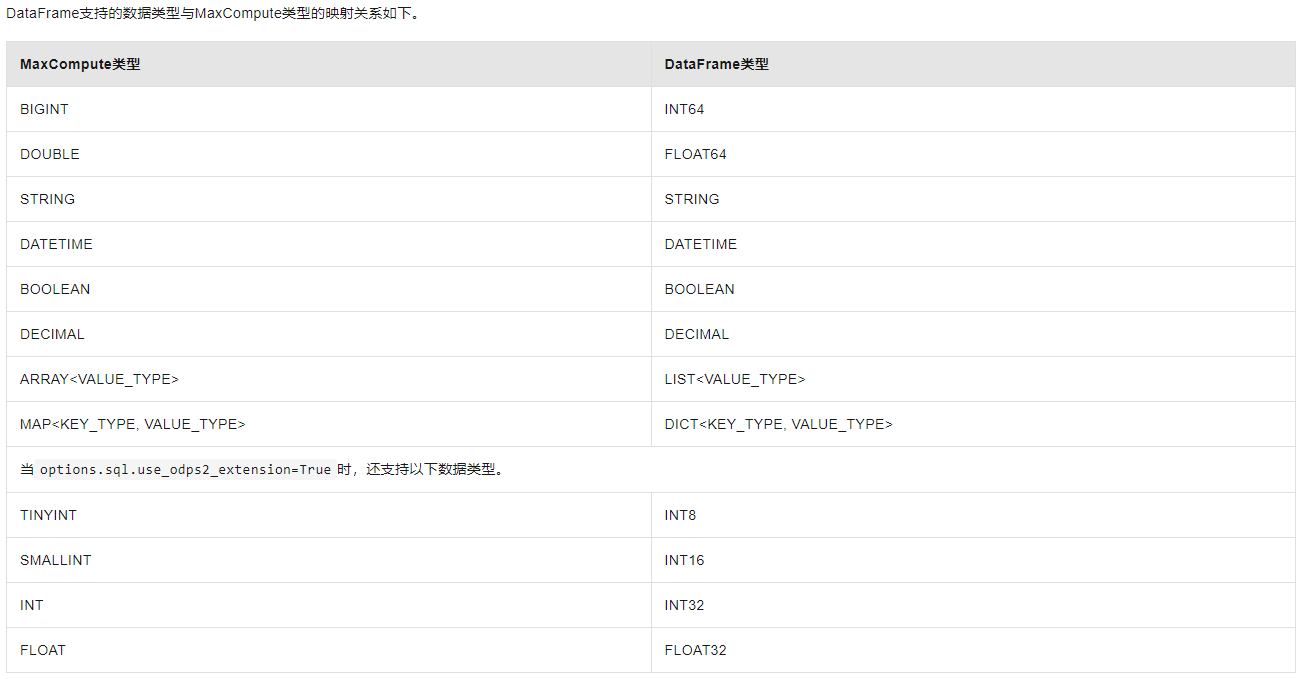
建好表之后,使用o.exist_table(out_table)判断表单是否存在,存在则返回True。当表存在时,才将执行结果报错到 Maxcompute 表中。
保存到 Maxcompute 表有两种写入方法,一个是指定 DataFrame 中某列为分区字段,注意参数名为 partitions;另外一个是指定分区,使用参数 partition,两个参数相差一个后缀 s。
第二种方式可以加上参数create_partition=True,即当分区不存在的时候新建分区。
if o.exist_table(out_table):
# 向表插入数据方式一:指定DataFrame的列为分区字段
# pyodps_df.persist(out_table, partitions=['pt']) #指定某个字段就是分区字段
# 向表插入数据方式二:指定分区
pyodps_df.persist(out_table, partition="pt=%s"% args['pt'], create_partition=True) #如果不存在则创建分区
print('完成写入!')
# 将执行结果保存为MaxCompute表文档链接:https://help.aliyun.com/zh/maxcompute/user-guide/execution#section-jwh-1y4-cfb
else:
print(f'表单{out_table}不存在。')
这两种方式的应用思考:如果你跑全量数据,基本上就第一种,因为可以指定前面处理好的pt字段按照每天一个分区的形式写入数据。如果是跑增量数据,两种方式都可以。不管是全量还是增量,有一个关键点,请求数据的时候需要设置日期取值,跑全量根据自己需要的时间段进行设置,跑增量可以考虑按天进行请求数据。在【2.5 调度设计与配置】有进一步的说明。
完整测试入库的代码如下(可直接跑):
from odps.df import DataFrame
dic = {'datas': {1: {'type': 'track','event': '$pageview','time_free': True,'time': 1700448379460,'distinct_id': '100101','properties': {'$os_version': '16.6.1','$city': '成都','$os': 'iOS','$is_first_time': False,'$province': '四川'}},
2: {'type': 'track','event': '$pageview','time_free': True,'time': 1700448381061,'distinct_id': '100102','properties': {'$os_version': '16.6.1','$city': '株洲','$os': 'iOS','$is_first_time': False,'$province': '湖南'}},
3: {'type': 'track','event': '$pageview','time_free': True,'time': 1700466642669,'distinct_id': '100103','properties': {'$os_version': '16.6.1','$city': '长沙','$os': 'iOS','$is_first_time': False,'$province': '湖南'}}},
'event': {1: '$pageview', 2: '$pageview', 3: '$pageview'},
'time': {1: 1700448379460, 2: 1700448381061, 3: 1700466642669},
'action_time': {1: '2023-11-20 10:46:19',2: '2023-11-20 10:46:21',3: '2023-11-20 15:50:42'},
'pt': {1: '20231120', 2: '20231120', 3: '20231120'},
'distinct_id': {1: '100101', 2: '100102', 3: '100103'},
'os': {1: 'iOS', 2: 'iOS', 3: 'iOS'},
'os_version': {1: '16.6.1', 2: '16.6.1', 3: '16.6.1'},
'province': {1: '四川', 2: '湖南', 3: '湖南'},
'city': {1: '成都', 2: '株洲', 3: '长沙'},
'browser': {1: '', 2: '', 3: ''},
'is_first_time': {1: False, 2: False, 3: False}
}
datas_df = pd.DataFrame(dic)
pyodps_df = DataFrame(datas_df,as_type={
"event" : "string"
,"time" : "int64"
,"time_free" : "boolean"
,"distinct_id" : "string"
,"os" : "string"
,"os_version" : "string"
,"province" : "string"
,"city" : "string"
,"browser" : "string"
,"is_first_time" : "boolean"
,'pt' : "string"
})
out_table = 'project.my_new_table'
# 调度配置的参数,发布调度之后需要注释掉
args = {'pt':'20231120'}
# DataWorks的PyODPS节点中,将会包含一个全局变量odps或者o,即为ODPS入口。
# ODPS入口相关文档链接:https://help.aliyun.com/zh/maxcompute/user-guide/use-pyodps-in-dataworks
#创建分区表my_new_table,(表字段列表,分区字段列表)。
table = o.create_table(out_table, ('event string,time bigint,time_free boolean,distinct_id string,os string,os_version string,province string,city string,browser string,is_first_time boolean', 'pt string'), if_not_exists=True)
# 注意:该写入方式要求 DataFrame 的每个字段的类型都必须相同
# DataFrame 列类型和 ODPS SQL 字段类型映射表:https://help.aliyun.com/zh/maxcompute/user-guide/sequence#section-avk-4s4-cfb
if o.exist_table(out_table):
# 向表插入数据方式一:指定DataFrame的列为分区字段
# pyodps_df.persist(out_table, partitions=['pt']) #指定某个字段就是分区字段
# 向表插入数据方式二:指定分区
pyodps_df.persist(out_table, partition="pt=%s"% args['pt'], create_partition=True) #如果不存在则创建分区
print('完成写入!')
# 将执行结果保存为MaxCompute表文档链接:https://help.aliyun.com/zh/maxcompute/user-guide/execution#section-jwh-1y4-cfb
else:
print(f'表单{out_table}不存在。')
2.5 调度设计与配置
这个虽然放在了最后讲,但事实上这个是贯穿整个过程的,因为需要处理相关的字段并参与全程测试。
如果能前置想清楚怎么入库可以更好的在处理的过程中减少测试,一次性通过测试,而不会出现这样的情况:处理数据和入库都测试跑通了,最后上调度跑生产发现需要加字段,然后全部再测试验证一遍。
调度的设计一般和需求相关,根据需求配置调度频率,比如 T+1 更新、一小时更新一次、5分钟更新一次等。
本实践项目的需求不高,调度频率设置 T+1 更新。
所以配置参数:pt=$[yyyymmdd-1],每天跑一次数据,并写入指定分区即可。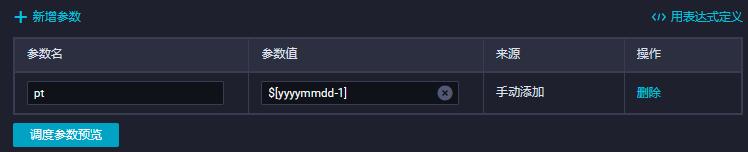
这里还有一个细节点:在请求神策数据的时候,输入的 SQL 中有一个where条件,用来限定请求日期的范围,目前是配置固定的参数:2023-11-20。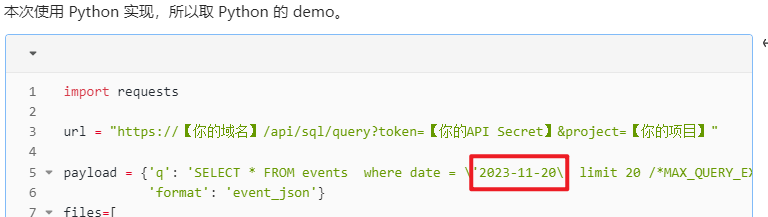
这个参数需要做调整,改为能够动态变化的参数。修改方式有两种:
第一种是直接用 SQL 获取 T-1 的日期:CURRENT_DATE() - INTERVAL '1' day
神策函数参考文档链接:https://manual.sensorsdata.cn/sa/latest/zh_cn/page-137920660.html
另一种是新增一个调度参数:y_m_d=$[yyyy-mm-dd-1]替换它。
到底采取哪一种策略呢?都可以。不过我选择第二种方法,也推荐使用第二种,原因很简单,如果哪一天出故障了,需要补数据的话,方便操作,直接通过参数日期便可控制,而不需要先修改代码,单独跑数,跑完再改回去,然后提交、发布。
新增调度参数如下:
注意:分区字段格式是年月日,没有-关联日期值,而代码里的日期格式要求年-月-日,所以需要新建不同的参数,当然,你也可以使用年-月-日格式作为分区字段,这样子就不用配置两个参数,不过需要特别注意,前面的分区字段pt都是处理为年月日格式,如果要更换,需要整体修改,保证格式统一。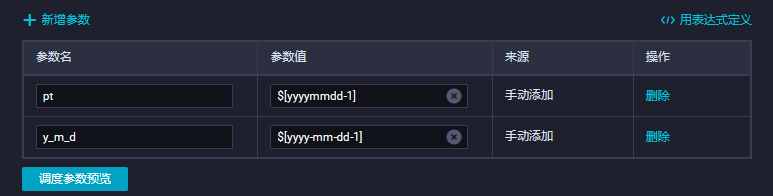
调度参数格式化参考文档:https://help.aliyun.com/zh/dataworks/user-guide/supported-formats-of-scheduling-parameters
2.6 项目代码整合
配置调度参数:
完整代码:
import requests
import pandas as pd
import json
from odps.df import DataFrame
def request_datas():
"""请求数据"""
url = "https://【你的域名】/api/sql/query?token=【你的API Secret】&project=【你的项目】"
sql = """select * from events where date = '%s' """
payload = {'q': f'{sql} /*MAX_QUERY_EXECUTION_TIME=1800*/' % args['y_m_d'],
'format': 'event_json'}
headers = {'Content-Type': 'application/x-www-form-urlencoded',}
response = requests.request("POST", url, headers=headers, data=payload)
print('完成读取!')
if response.status_code == 200:
print('数据正常获取!')
return response.text
else:
print('数据获取异常!')
return None
def dates_processing(text):
"""处理响应的数据"""
# 按行切割响应数据
res_datas = text.split('\n')
# 转为 json 数据(字符串),并转换为 DataFrame
datas_df = pd.read_json(json.dumps(res_datas))
# 将列数据转为字典,并修改列名为 datas
datas_df = pd.DataFrame(datas_df[0][datas_df[0] !=''].apply(lambda x:json.loads(x)))
datas_df.columns = ['datas']
# 展开 datas,将数据取出,作为新列
datas_df['event'] = datas_df.datas.apply(lambda x:x['event'])
datas_df['time'] = datas_df.datas.apply(lambda x:x['time'])
#注意时区问题!!!
datas_df['action_time'] = pd.to_datetime((pd.to_datetime(datas_df.time,unit='ms')+ pd.Timedelta(hours=8)).dt.strftime('%Y-%m-%d %H:%M:%S')) #用于记录时间
datas_df['pt'] = (pd.to_datetime(datas_df.time,unit='ms')+ pd.Timedelta(hours=8)).dt.strftime('%Y%m%d') #用于分区
datas_df['distinct_id'] = datas_df.datas.apply(lambda x:x['distinct_id'])
#有的key没有,使用:dict.get('[字段名]', '')
datas_df['os'] = datas_df.datas.apply(lambda x:x['properties'].get('$os', ''))
datas_df['os_version'] = datas_df.datas.apply(lambda x:x['properties'].get('$os_version', ''))
datas_df['province'] = datas_df.datas.apply(lambda x:x['properties'].get('$province', ''))
datas_df['city'] = datas_df.datas.apply(lambda x:x['properties'].get('$city', ''))
datas_df['browser'] = datas_df.datas.apply(lambda x:x['properties'].get('$browser', ''))
datas_df['is_first_time'] = datas_df.datas.apply(lambda x:x['properties'].get('$is_first_time', ''))
return datas_df
if __name__ == '__main__':
response_datas = request_datas()
if response_datas is not None:
datas_df = data_preprocessing(response_datas)
size = datas_df.shape[0]
pyodps_df = DataFrame(datas_df,as_type={
"event" : "string"
,"time" : "int64"
,"time_free" : "boolean"
,"distinct_id" : "string"
,"os" : "string"
,"os_version" : "string"
,"province" : "string"
,"city" : "string"
,"browser" : "string"
,"is_first_time" : "boolean"
,'pt' : "string"
})
out_table = '【修改为你的项目和表单,示例:project.my_new_table】'
# 调度配置的参数,发布调度之后需要注释掉
# args = {'pt':'20231120', 'y_m_d':'2023-11-20'}
# DataWorks的PyODPS节点中,将会包含一个全局变量odps或者o,即为ODPS入口。
# ODPS入口相关文档链接:https://help.aliyun.com/zh/maxcompute/user-guide/use-pyodps-in-dataworks
# 创建分区表my_new_table,(表字段列表,分区字段列表)。
table = o.create_table(out_table, ('event string,time bigint,time_free boolean,distinct_id string,os string,os_version string,province string,city string,browser string,is_first_time boolean', 'pt string'), if_not_exists=True)
# 注意:该写入方式要求 DataFrame 的每个字段的类型都必须相同
# DataFrame 列类型和 ODPS SQL 字段类型映射表:https://help.aliyun.com/zh/maxcompute/user-guide/sequence#section-avk-4s4-cfb
if o.exist_table(out_table):
# 向表插入数据方式一:指定DataFrame的列为分区字段
# pyodps_df.persist(out_table, partitions=['pt']) #指定某个字段就是分区字段
# 向表插入数据方式二:指定分区
pyodps_df.persist(out_table, partition="pt=%s"% args['pt'], create_partition=True) #如果不存在则创建分区
print(f'完成写入!共 {size} 条数据。')
# 将执行结果保存为MaxCompute表文档链接:https://help.aliyun.com/zh/maxcompute/user-guide/execution#section-jwh-1y4-cfb
else:
print(f'表单{out_table}不存在。')
else:
print('退出程序!')
注意点:
1、必须修改【】中的内容,改为自己的,否则报错。
2、目前处理的都是比较基础的字段,如果需要新增其他字段,可根据datas_df['os'] = datas_df.datas.apply(lambda x:x['properties'].get('$os', ''))的格式进行新增,比如:datas_df['browser_version'] = datas_df.datas.apply(lambda x:x['properties'].get('$browser_version', ''))。
3、MaxCompute 项目需要关闭数据保护策略,否则无法引入外部数据,提示的报错信息是:project ‘xxx’ is protected。参考解决方案:https://help.aliyun.com/zh/maxcompute/user-guide/odps-0130013
三、小结
这篇文章写了好几天,一直拿捏不好。本身做的时候就经历了三四天的时间,然后过程感受到很多坑,加之还有其他的任务,做做停停,不断踩坑,出坑。好在最终出坑并且写完了。
最终的解决方案的整个流程梳理下来其实就是:请求神策数据->Pandas 处理数据->转为 MaxCompute 数组并入库。
- 请求神策数据节点内容包括
- Token 获取;
- 神策 API 的获取;
- 使用 Postman 调试 API 并获取代码 demo;
- Pandas 处理数据节点内容包括
- 使用面向数组的思想处理数据;
- 处理时区问题;
- 字典没有 Key 的取值方式;
- 配置分区参数,用于数据入库;
- 转为 MaxCompute 数组并入库节点内容包括
- 理解不同 Dataframe 的异同;
- MaxCompute 建表;
- PyODPS Dataframe 数据写入(persist())
- 调度参数配置和使用。
流程结构图如下: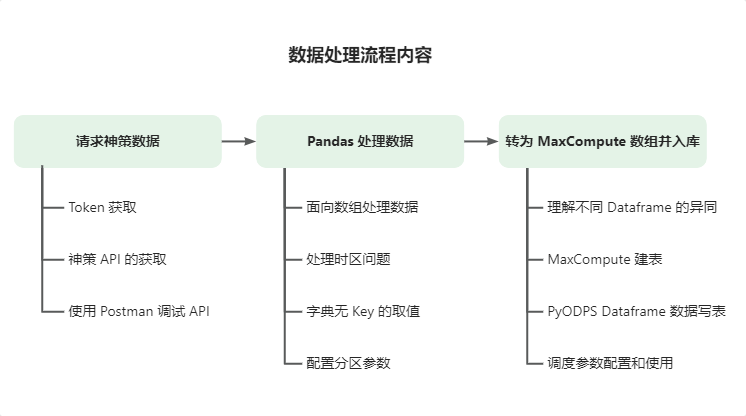
虽然整理的流程很简单,但是过程需要参考大量的官方文档,了解各个组件的逻辑,本文所涉及的文档整理如下:
1、神策数据导出 API 文档参考:https://manual.sensorsdata.cn/sa/latest/zh_cn/tech_export_transfer-150668708.html
2、DataFrame 列类型和 ODPS SQL 字段类型映射表:https://help.aliyun.com/zh/maxcompute/user-guide/sequence#section-avk-4s4-cfb
3、将执行结果保存为MaxCompute表文档链接:https://help.aliyun.com/zh/maxcompute/user-guide/execution#section-jwh-1y4-cfb
4、ODPS入口相关文档链接:https://help.aliyun.com/zh/maxcompute/user-guide/use-pyodps-in-dataworks
5、将执行结果保存为MaxCompute表文档链接:https://help.aliyun.com/zh/maxcompute/user-guide/execution#section-jwh-1y4-cfb
6、神策函数参考文档链接:https://manual.sensorsdata.cn/sa/latest/zh_cn/page-137920660.html
7、调度参数格式化参考文档:https://help.aliyun.com/zh/dataworks/user-guide/supported-formats-of-scheduling-parameters
8、project ‘xxx’ is protected 解决方案:https://help.aliyun.com/zh/maxcompute/user-guide/odps-0130013
9、Sensors Data(神策)数据源参考文档:https://help.aliyun.com/zh/dataworks/user-guide/sensors-data-data-source
10、各种类型调度节点参数说明文档:https://help.aliyun.com/zh/dataworks/user-guide/configure-scheduling-parameters-for-different-types-of-nodes
四、花絮-避坑指南
捋顺完最终的解决方案之后,再讲点花絮吧,也算是避坑指南。
第一坑:阿里云仅深圳节点支持神策数据
在 dataworks 工作空间新增数据源的时候可以看到,可以直接引入神策数据。
要求很简单,只要有神策数据接收地址即可。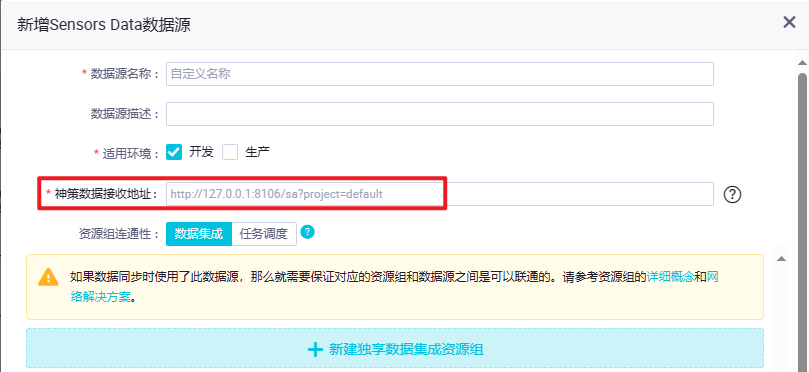
神策数据接收地址:在神策界面,数据融合栏目下的数据接入引导就可以获取到该信息。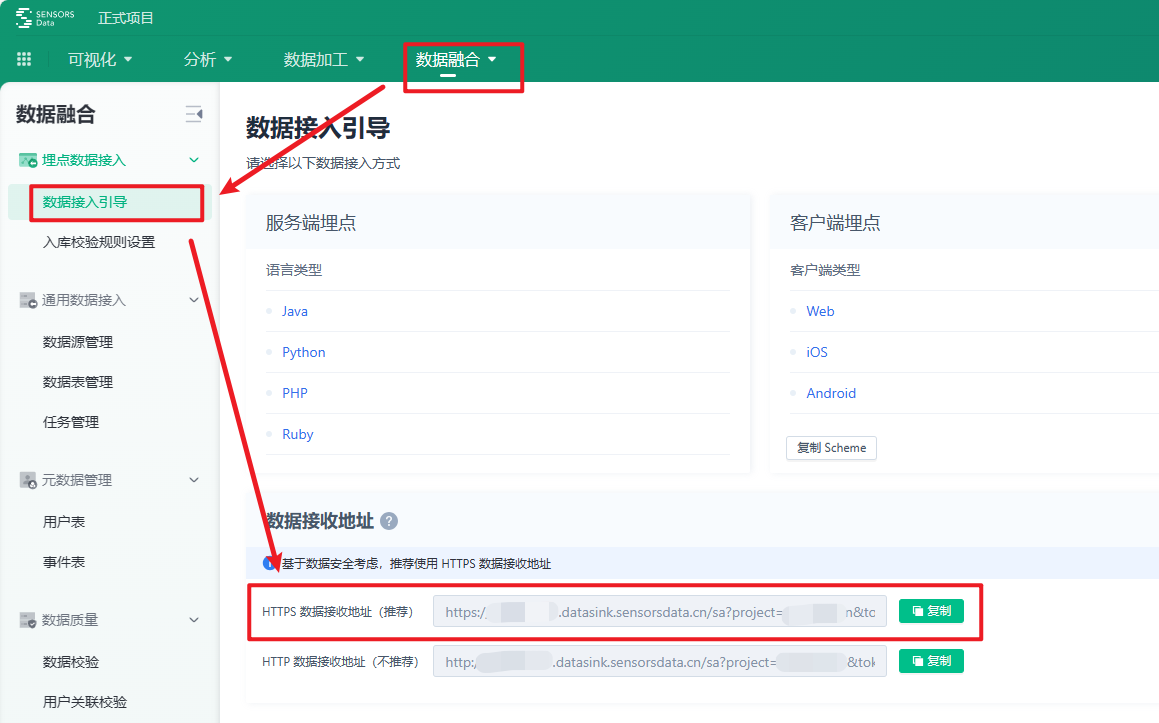
引入数据源之后,新建一个离线同步节点,结果发现,在数据来源找不到神策的标识!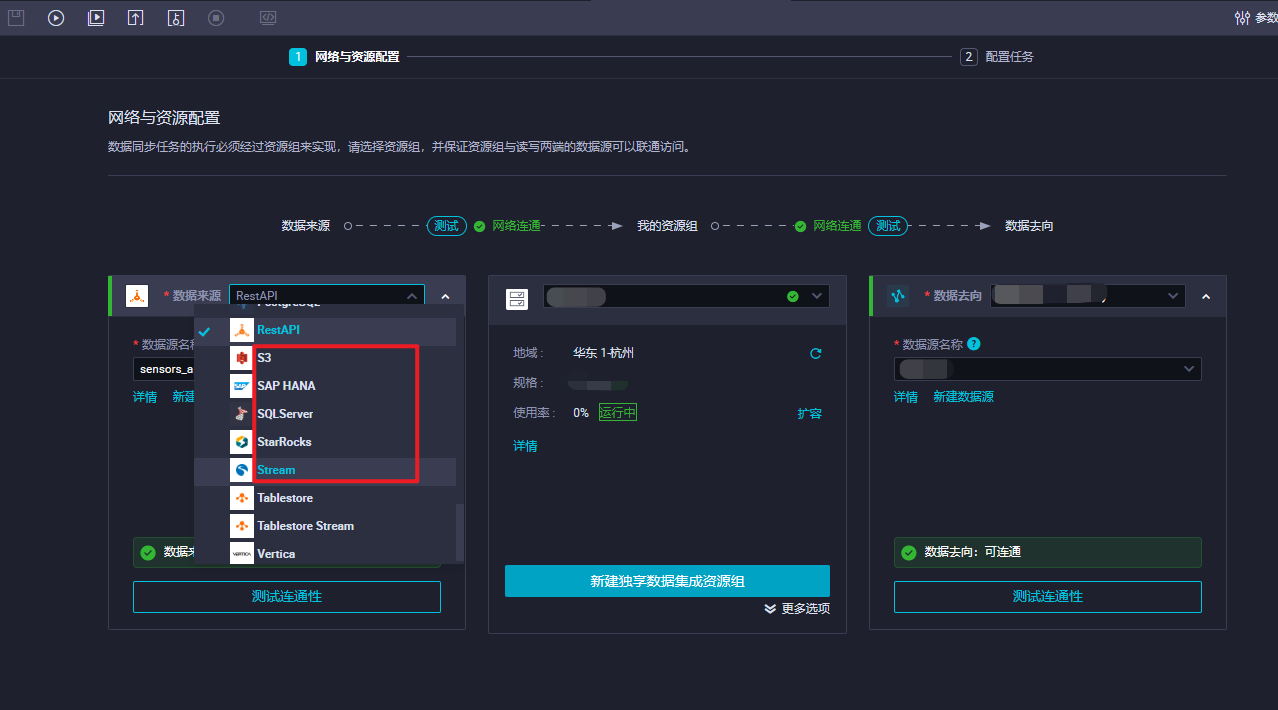
帮助文档找神策,发现:仅华南1(深圳)地域支持绑定Sensors Data数据源。
参考文档:https://help.aliyun.com/zh/dataworks/user-guide/sensors-data-data-source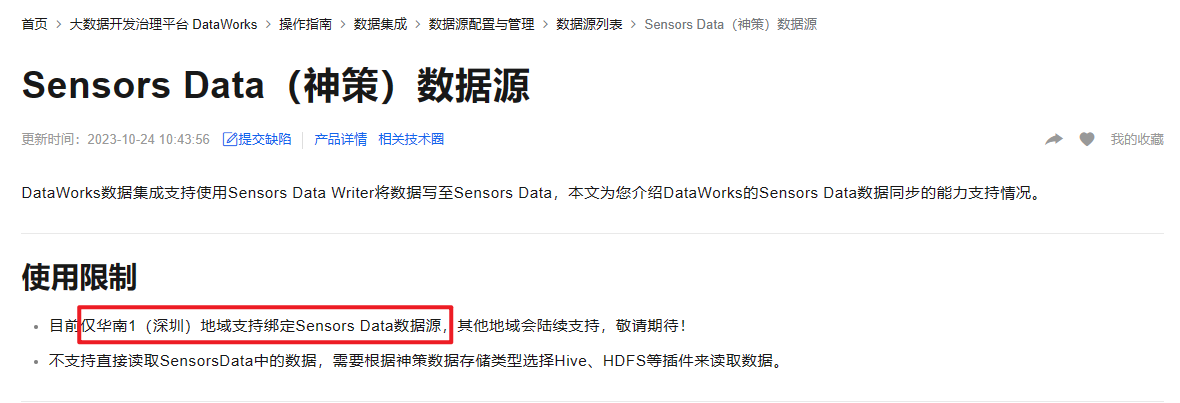
阿里云总能给我一些“惊喜”,一会喜,一会忧。
第二坑:神策 Token
直接使用神策跑不通,尝试获取神策数据的 API,通过其他方式接入。
前面介绍到在神策的数据融合栏目下的数据接入引导可以复制一个数据接收地址,里面就有一个 Token,不过当我拿着它,结合神策 API 文档,然后在 postman 尝试发起请求时,又给我返回失败:没有访问权限?
神策数据导出参考:https://manual.sensorsdata.cn/sa/latest/zh_cn/tech_export_transfer-150668708.html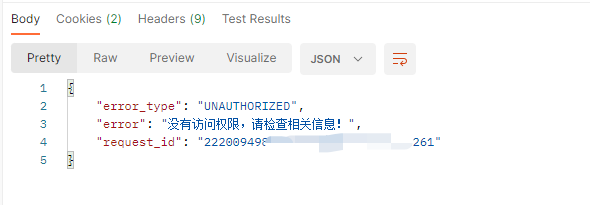
几个 API 文档,挨个试一遍,结果都不行。
由于使用的 Token 是正确的,但是无权限,猜测可能是账号问题,也可能是 Token 本身的问题:如果是账号的问题,可能是每个账号都有独立的 Token,然后和账号权限绑定;如果同一个主体一个 Token,那么就是 Token 问题。
找运维同学帮忙测试下,一样的 Token,一样的结果。那就是 Token 问题。
后来找神策服务人员询问,了解到要通过一个 Admin 获取一个 API Secret 的 Token。
又找运维同学拿到 API Secret 的 Token,终于请求数据成功!
第三坑:阿里云 RestAPI 只成功了一半!
直接使用神策跑不通,尝试使用阿里云 RestAPI。
在 dataworks 工作空间新增数据源,通过 RestAPI 将神策的接口再次引入。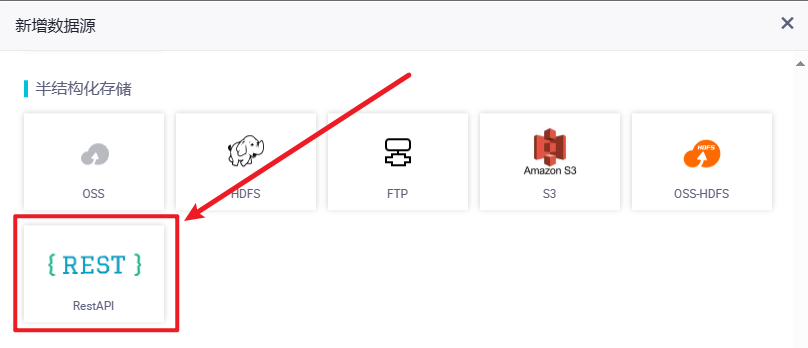
这次找到数据源了。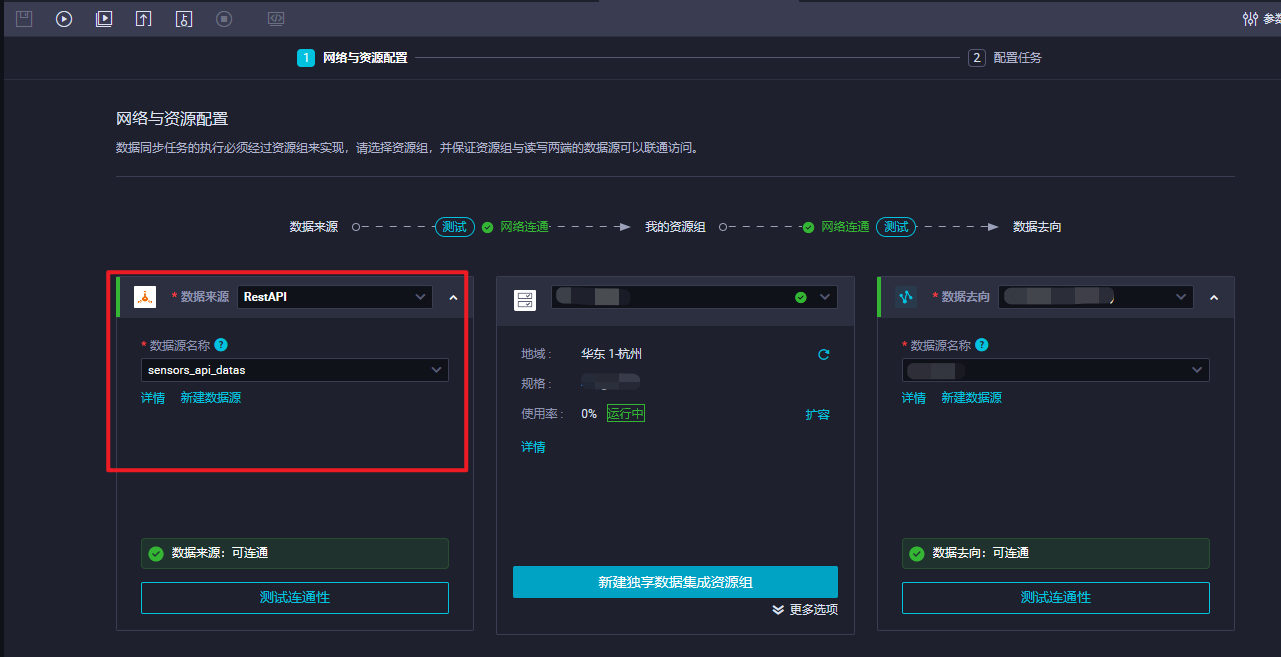
但是在下一步预览数据时空空如也……似乎只成功了一半,还有一半没有结果。
第四坑:PyODPS 引用参数
在 SQL 中,引用参数使用'${参数名}',但是在 PyODPS 中并非如此!起初使用'${参数名}'测试入库,一直没有写入数据,一度还怀疑是阿里云相关配置隐藏某些东西,后来变换方式测试了好些方法,开始报错,仔细查看报错,逐渐看出了一些“猫腻”,似乎是系统不知道我给它的东西是什么。
最后通过print('${参数名}')打印参数,结果原封不动给我打印出来了。
这才发现,原来这么引用是错误的!!!
正确的引用方式是:**args['参数名']**。
这是通过通义千问解决的~~~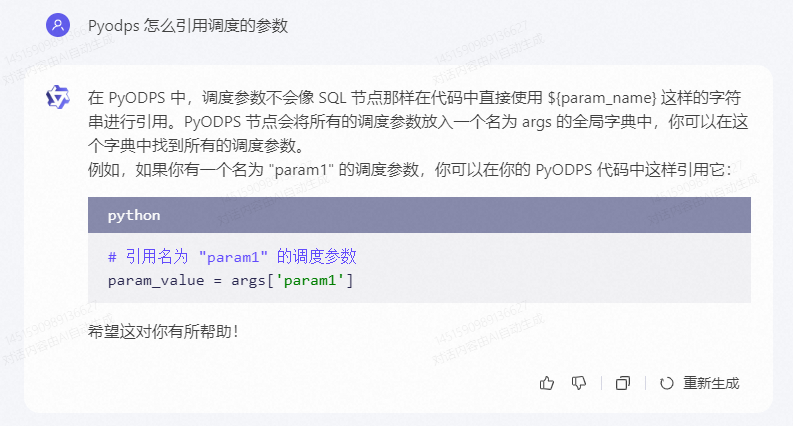
后来找到了相关的文档:各种类型调度节点参数说明:https://help.aliyun.com/zh/dataworks/user-guide/configure-scheduling-parameters-for-different-types-of-nodes
第五坑:project ‘for_analysis’ is protected
报错内容如下:
odps.errors.ODPSError: ODPS-0130013: InstanceId: 2023112107222501384g
Catalog Service Failed, ErrorCode: 50, Error Message: ODPS-0130013:Authorization exception - Authorization Failed [4022], You have NO privilege ‘odps:Alter’ on {acs:odps::projects/xxx/tables/xxxxxx}. project ‘xxx’ is protected. Context ID:343ac503-5031-af8-7b221256e4d5. —>Tips: CurrentProject:xxx; Pricipal:ALIYUN$xxxxxx@xxx.com; No permission ‘odps:Alter’ on resource acs:odps::projects/xxx/tables/xxxxxx
报错原因是当前project开启数据保护策略,不允许外部项目发起的数据访问。
解决方案是本项目的所有者关闭数据保护策略。
set ProjectProtection=false;
参考文档:https://help.aliyun.com/zh/maxcompute/user-guide/odps-0130013
当然,如果数仓架构设置多个项目,各个项目有各自的职责,也可以考虑更换项目,在允许该操作的项目下进行操作。


![[数据结构]-红黑树](https://img-blog.csdnimg.cn/af890bb3c539409294654bf1f0d9fda5.png)


![[架构之路-250]:目标系统 - 设计方法 - 软件工程 - 需求工程 - 需求开发:如何用图形表达需求,面向对象需求分析OOA与UML视图](https://img-blog.csdnimg.cn/922e3986a3514983884582d09de54bf9.png)