作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
枚举简介
枚举是一种特殊的类,和class、interface等是一个级别的(其实就是一个类),一般用于表示多种固定的状态。
《阿里巴巴开发手册》对枚举的介绍:

我们在设计山寨枚举中用WeekDay表示周一到周日,但正版枚举的格式要精简很多:
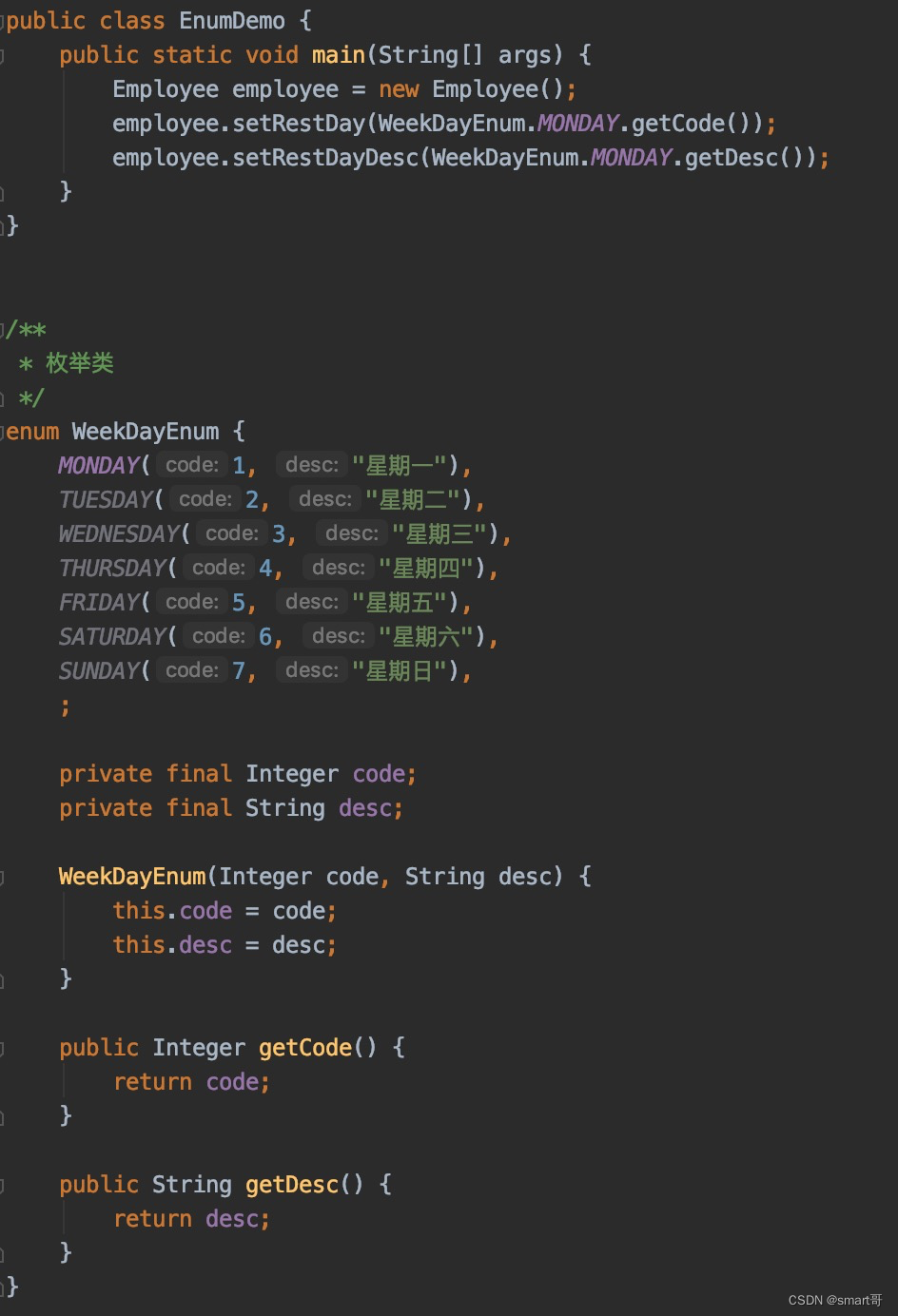
注意,WeekDayEnum命名规则并不是固定的,但推荐以Enum结尾,方便见名知意。当一个类声明为enum时,表示这是一个枚举类,比如enum WeekDayEnum。
对于枚举为何出现,你可以理解为JDK1.5以前很多人和我们之前一样都采用自定义山寨枚举的办法制作枚举类,所以JDK干脆提供了官方版,而且JDK枚举的底层原理正是“抄袭”了我们的山寨枚举。
枚举类底层原理
我们对上面的WeekDayEnum反编译:

是不是和我们山寨"枚举"很相似?
区别在于:
- enum关键字修饰的WeekDayEnum,在编译后会自动继承Enum类,且声明为final
- 比山寨版枚举多了valueOf()方法,传入名称返回对应的枚举实例
- values()并不是直接返回WeekDay[],而是$VALUES.clone()
特别是最后一点,我们来对比下。山寨版枚举:

正版枚举反编译:

为什么正版的枚举要$VALUES.clone()呢?
因为如果像山寨版枚举这样返回整个实际数组,外部调用者就可以随意增删枚举对象!
另外,我们可以尝试分别打印正版枚举和我们的山寨枚举:
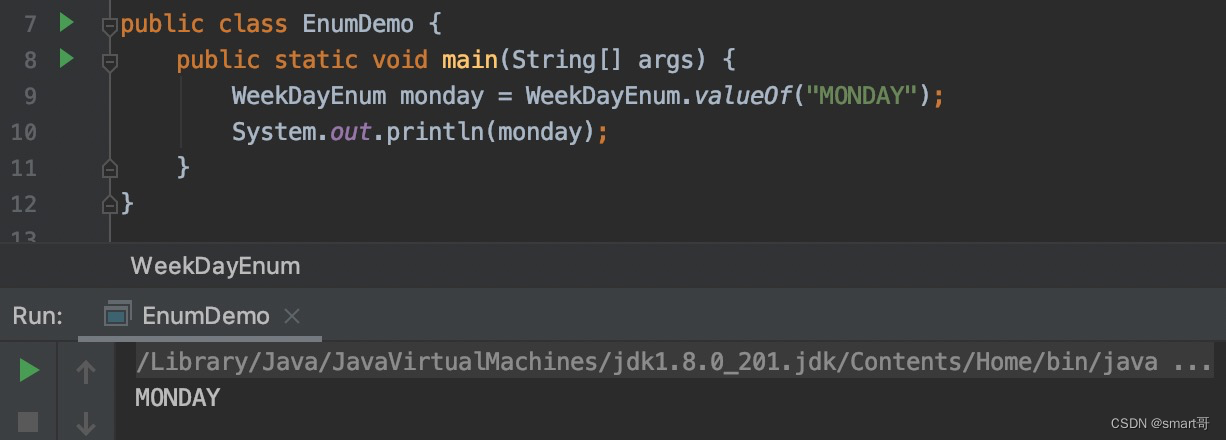

说明正版枚举重写了toString()方法。
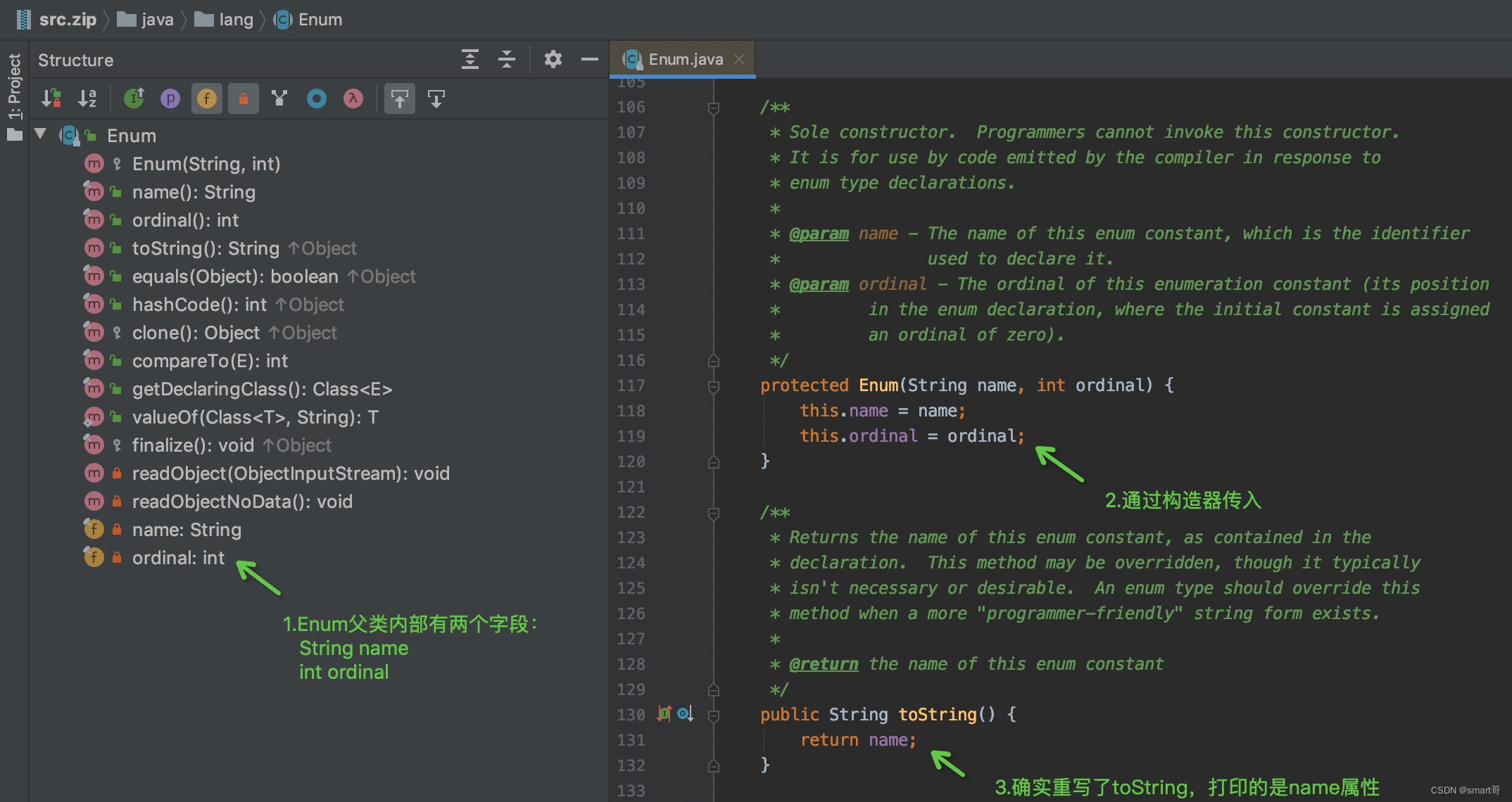
光看WeekDayEnum的代码好像看不出来哪里重写了toString(),于是推测肯定是它的父类Enum重写了:
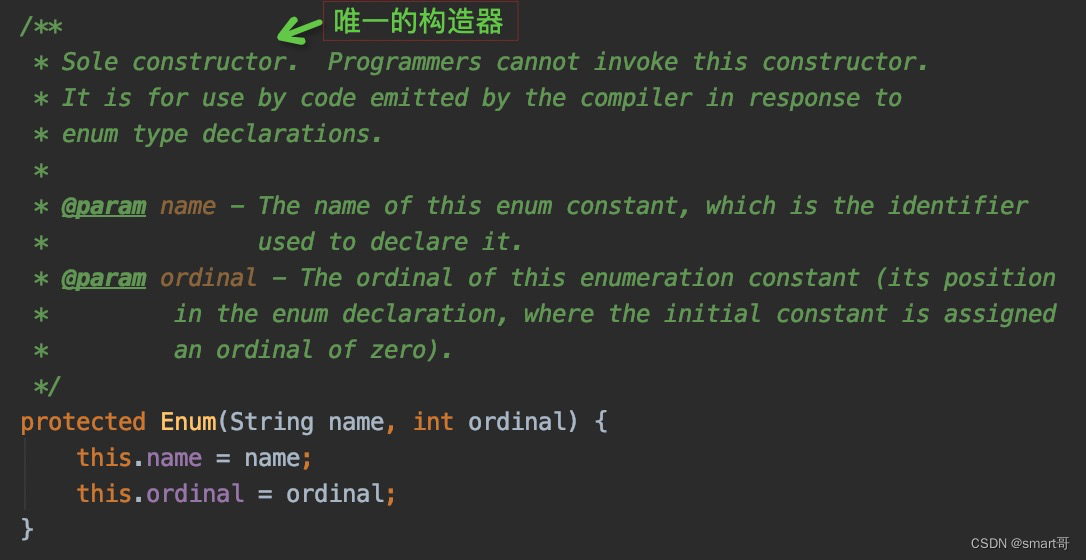
在Enum这里,有且仅有一个构造器:
而我们都知道子类在new的时候,会调用父类的构造器。
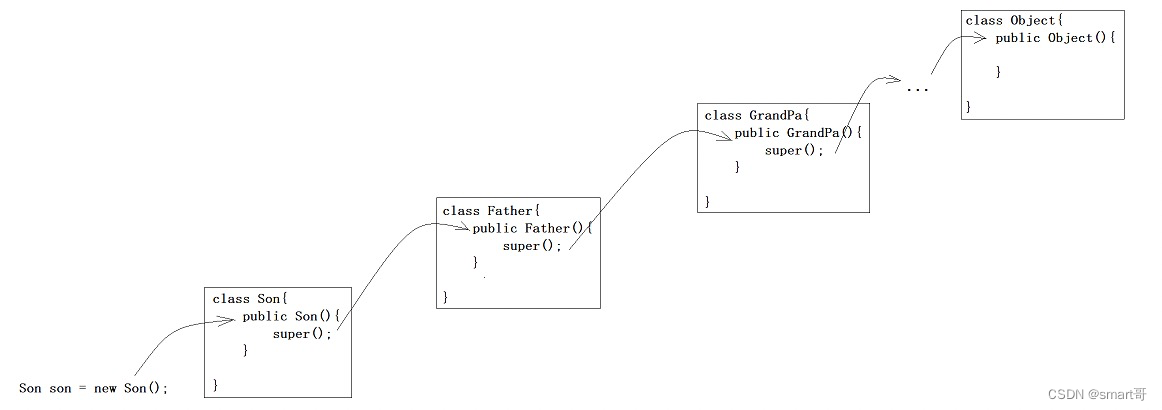
所以子类WeekDayEnum在哪里调了这个构造器、又往它里面传入了什么呢?


我们发现,虽然当初编写WeekDayEnum时,构造器只传入了两个参数,但编译器却给我们额外加了两个(见图一),用来为父类Enum中的name和ordinal赋值(见图二)。name来自MONDAY、TUESDAY等枚举名称,而ordinal则是编写序号。
特别注意,name并不是MONDAY(1, "星期一")里的desc,而是MONDAY字符串。这很好理解,因为不是所有枚举都有desc字段,它是我们自己定义的字段。如果你愿意,完全可以这样定义枚举:

枚举中的每个对象都有默认的name,就是你看到的通常意义上的枚举名称,而默认toString()会打印name。
name和ordinal
勇敢面对内心的疑问吧:为什么编译器要给构造器额外添加参数name、ordinal?
这个问题其实我们在设计山寨版枚举时讨论过了:

总的来说,就是为了区分枚举对象。因为在编写枚举时,极有可能会这样写:

这个是无参的,反编译后如果不额外添加name、ordinal,就会变成这样:
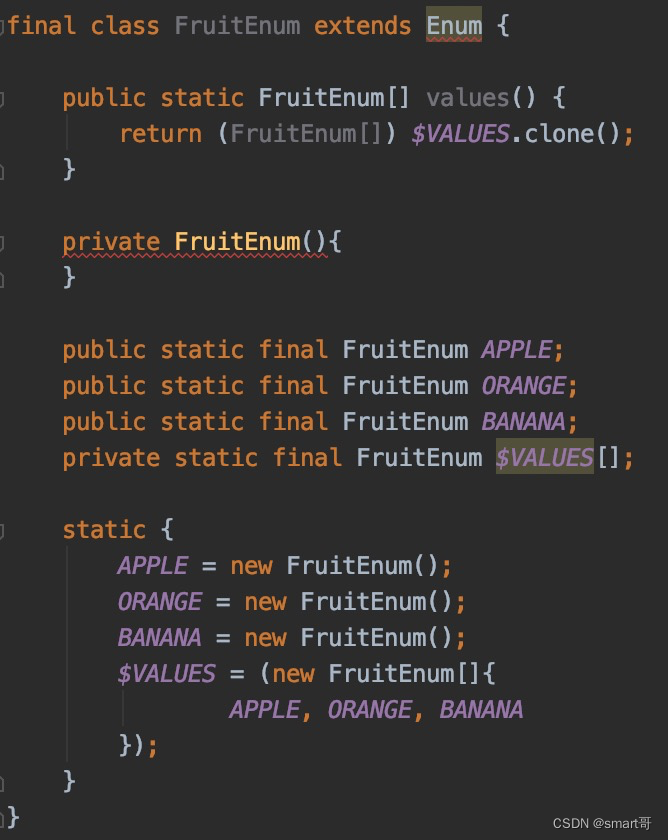
此时如果你把整个枚举存入数据库,就会都变成"{}",那么下次取出来就没什么特征性了。
另一个原因是,新增的参数是为了满足valueOf()方法,调用者可以传入字符串,匹配对应的枚举类型。比如
FruitEnum BANANA = FruitEnum.valueOf("BANANA")
这样就可以根据name得到BANANA枚举(对象)。
枚举 VS 常量类
枚举和常量类有什么区别呢?
我想起了另一个经常会被问到的问题:
Dubbo和SpringCloud什么区别?
Dubbo只是一个RPC框架,而SpringCloud几乎代表了一整个微服务解决方案,从网关、注册中心到配置中心一应俱全,完全不是一个概念。
同样的,枚举本质是一个对象,可以设置对象该有的一切,而常量类往往只有字段(public static final),枚举对象和常量类的字段是没有可比性的。比如枚举可以自定义方法,常量可以吗?
总之,应该把枚举看成特殊的对象,而不是仅仅将其等同于常量。
作为常量使用时,区别不大
如果实际编码时传递的是枚举的字段而不是枚举本身,比如WeekDayEnum.TUESDAY.getCode(),此时枚举和常量类的用法差别不大。

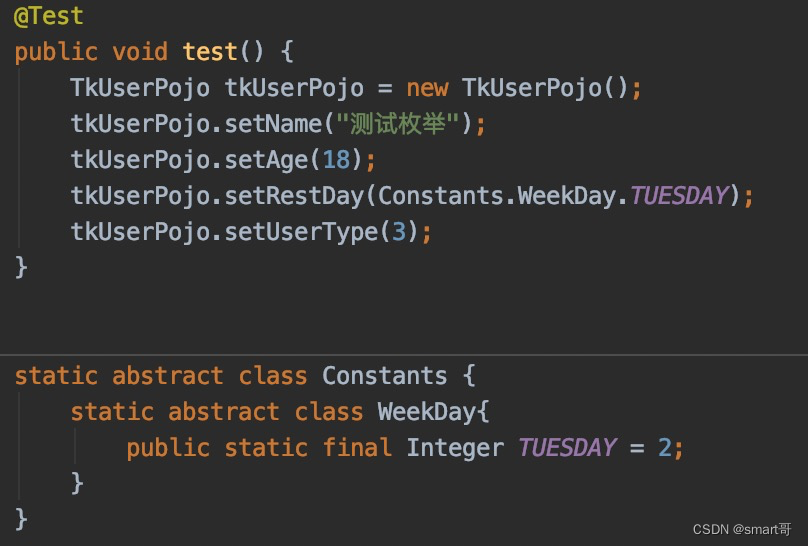
甚至单纯作为常量用的话,常量类似乎更容易理解且方便。
枚举优点一:限制重复定义常量
枚举作为常量使用时,编译器会自动限制取值不能相同,而常量类做不到,有可能会重复
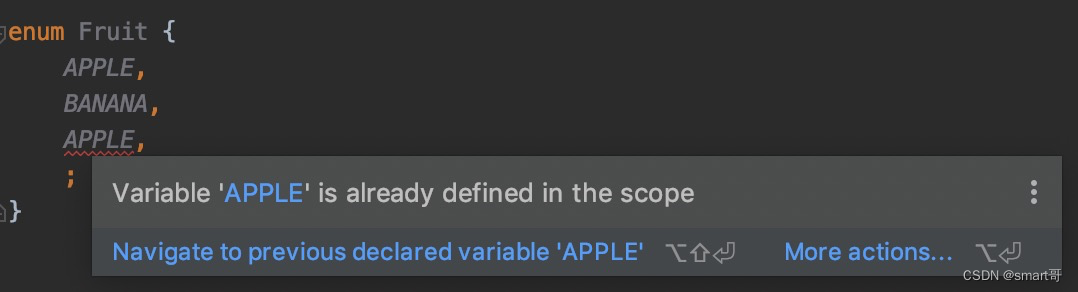
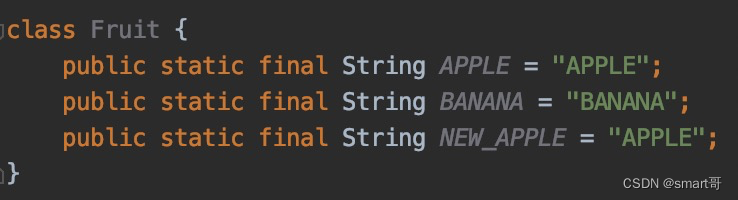
其实这个优点没什么卵用,凑数。
枚举优点二:包含更多维度的信息
枚举毕竟是对象,可以包含更多的信息
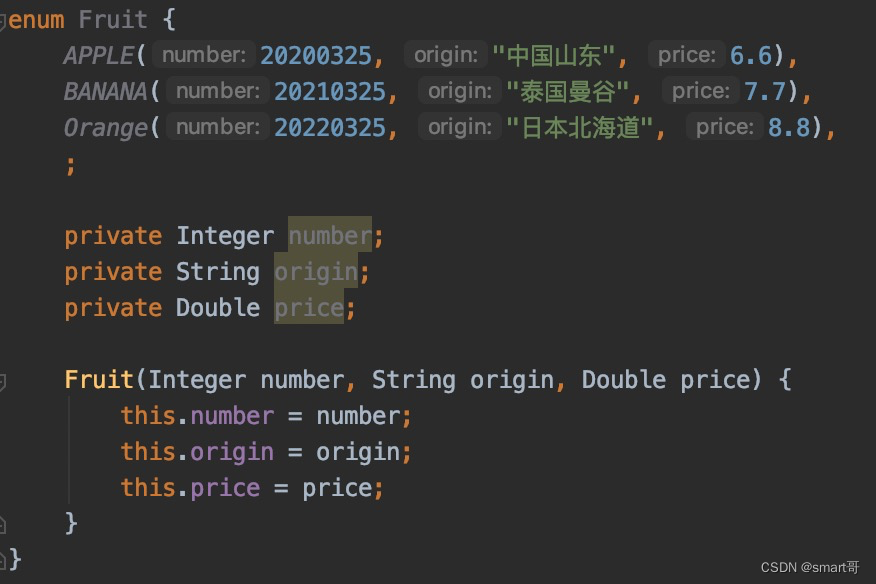
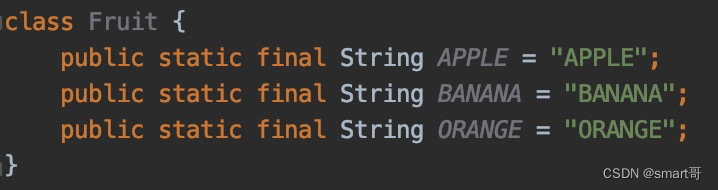
枚举优点三:枚举+Switch比常量+if/else简洁
枚举可以直接用于Switch判断,代码通常会比常量+if/else简洁一些:
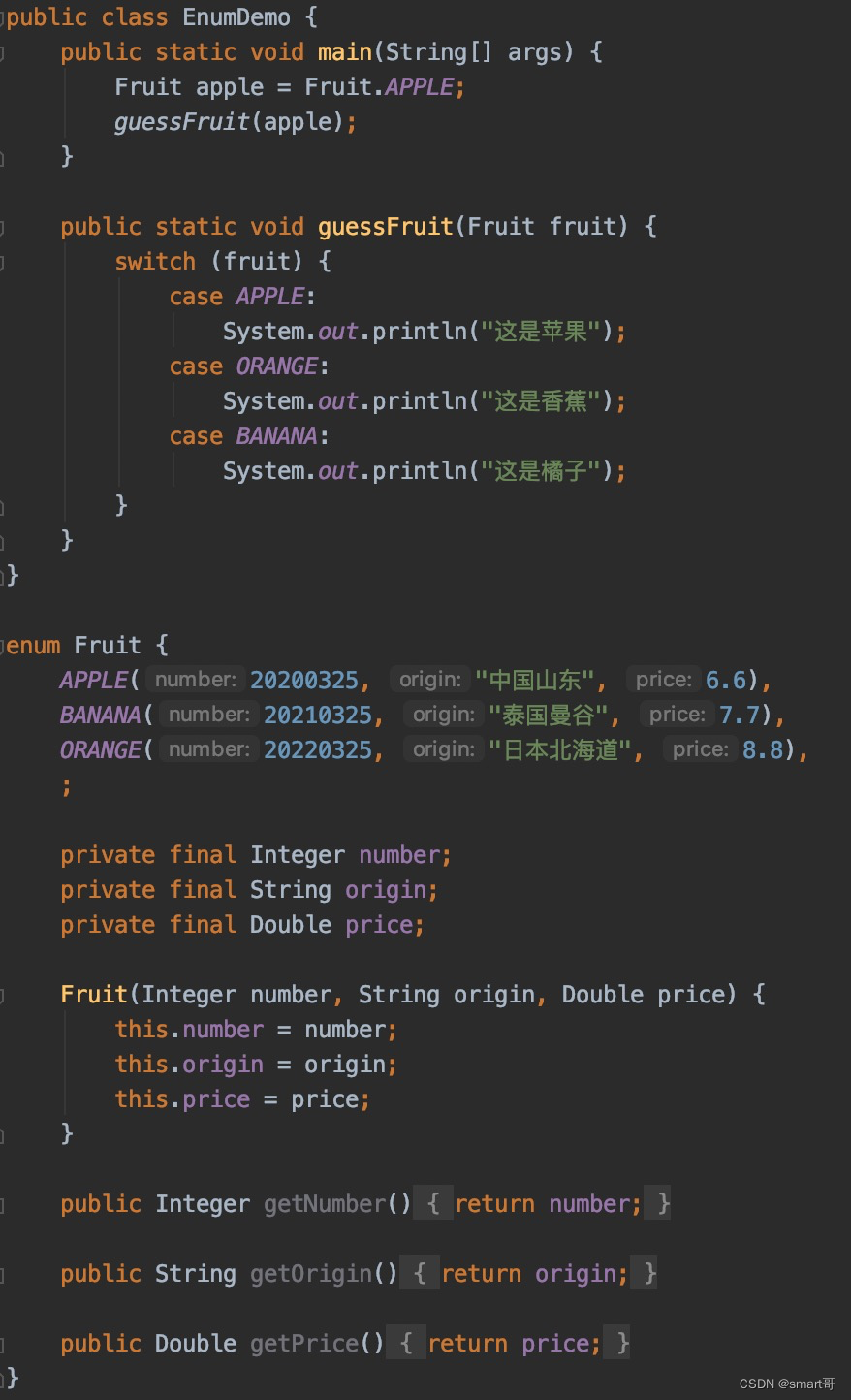
至此终于把上面三个“优点”讲完,这也是网上抄来抄去的一些内容。实话实说,我不觉得if/else就怎么了。我的想法是,上面的优点好像都是强行凑数,用来捧枚举,然后踩一脚常量类,个人认为没什么卵用。
枚举真要谈优点,一定要从它作为对象的角度来说,而不是强行把它限定为“特殊的常量类”。
利用枚举完善状态码
枚举做统一返回结果,可以有效规范错误码及错误信息。我们在山寨版枚举中演示过了。
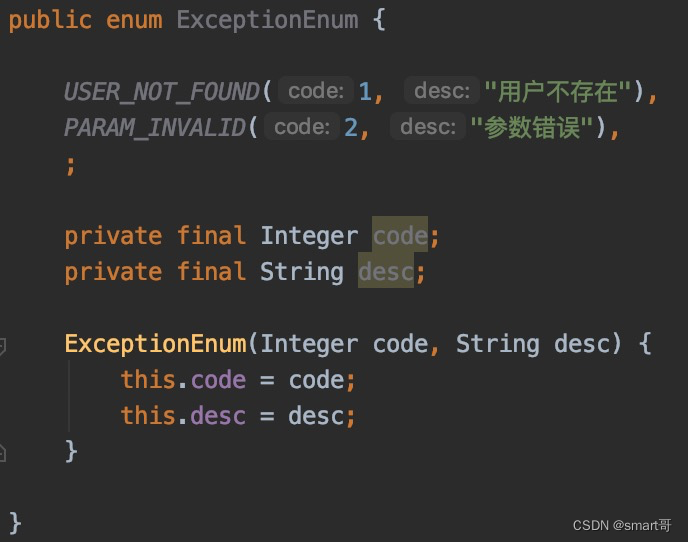
如果不用枚举,code和desc做不到绑定,用户传入1的同时可以传入"参数错误",这样状态码和信息就错乱了。

所以最好不要这样设计:
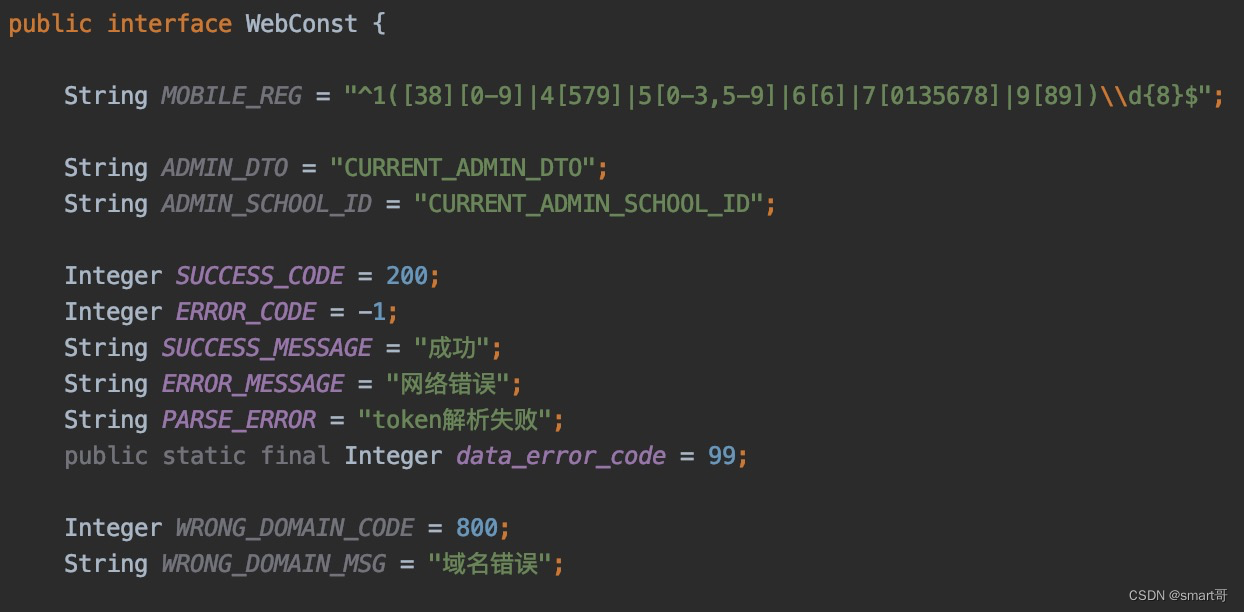
状态码和状态描述之间没有必然联系,是散乱的。
枚举策略
再讲一个利用枚举消除if/else的案例,具体这是什么设计模式其实不重要,不管黑猫白猫,能抓老鼠就是好猫。
比如一个网上商城有会员制度:
- 黄金会员:6折
- 白银会员:7折
- 青铜会员:8折
无论在商城里买什么,都会按照会员的折扣优惠。
用常量类实现:
public class MemberDemo {
public static void main(String[] args) {
User user = new User(1L, "bravo", Constants.GOLD_MEMBER);
BigDecimal productPrice = new BigDecimal("1000");
BigDecimal discountedPrice = calculateFinalPrice(productPrice, user.getMemberType());
System.out.println(discountedPrice);
}
/**
* 根据会员身份返回折扣后的商品价格
*
* @param originPrice
* @param user
* @return
*/
public static BigDecimal calculateFinalPrice(BigDecimal originPrice, Integer type) {
if (Constants.GOLD_MEMBER.equals(type)) {
return originPrice.multiply(new BigDecimal("0.6"));
} else if (Constants.SILVER_MEMBER.equals(type)) {
return originPrice.multiply(new BigDecimal("0.7"));
} else if (Constants.BRONZE_MEMBER.equals(type)) {
return originPrice.multiply(new BigDecimal("0.8"));
} else {
return originPrice;
}
}
}
@Data
@AllArgsConstructor
class User {
private Long id;
private String name;
/**
* 会员身份
* 1:黄金会员,6折优惠
* 2:白银会员,7折优惠
* 3:青铜会员,8折优惠
*/
private Integer memberType;
}
class Constants {
/**
* 黄金会员
*/
public static final Integer GOLD_MEMBER = 1;
/**
* 白银会员
*/
public static final Integer SILVER_MEMBER = 2;
/**
* 青铜会员
*/
public static final Integer BRONZE_MEMBER = 3;
}上面的代码有两个缺点:
- if/else过多,如果会员制度再复杂些,语句会更长,阅读性不佳
- 不利于扩展。如果后期和百度一样不要脸地在vip基础上新增svip,需要修改逻辑判断的代码,这很容易出错
用枚举实现(在枚举类中定义抽象方法,强制子类实现):
/**
* @author mx
* @date 2023-11-25 14:57
*/
public class MemberDemo {
public static void main(String[] args) {
User user = new User(1L, "bravo", MemberEnum.GOLD_MEMBER.getType());
BigDecimal productPrice = new BigDecimal("1000");
BigDecimal discountedPrice = calculateFinalPrice(productPrice, user.getMemberType());
System.out.println(discountedPrice);
}
/**
* 根据会员身份返回折扣后的商品价格
*
* @param originPrice
* @param user
* @return
*/
public static BigDecimal calculateFinalPrice(BigDecimal originPrice, Integer type) {
return MemberEnum.getEnumByType(type).calculateFinalPrice(originPrice);
}
}
@Data
@AllArgsConstructor
class User {
private Long id;
private String name;
/**
* 会员身份
* 1:黄金会员,6折优惠
* 2:白银会员,7折优惠
* 3:青铜会员,8折优惠
*/
private Integer memberType;
}
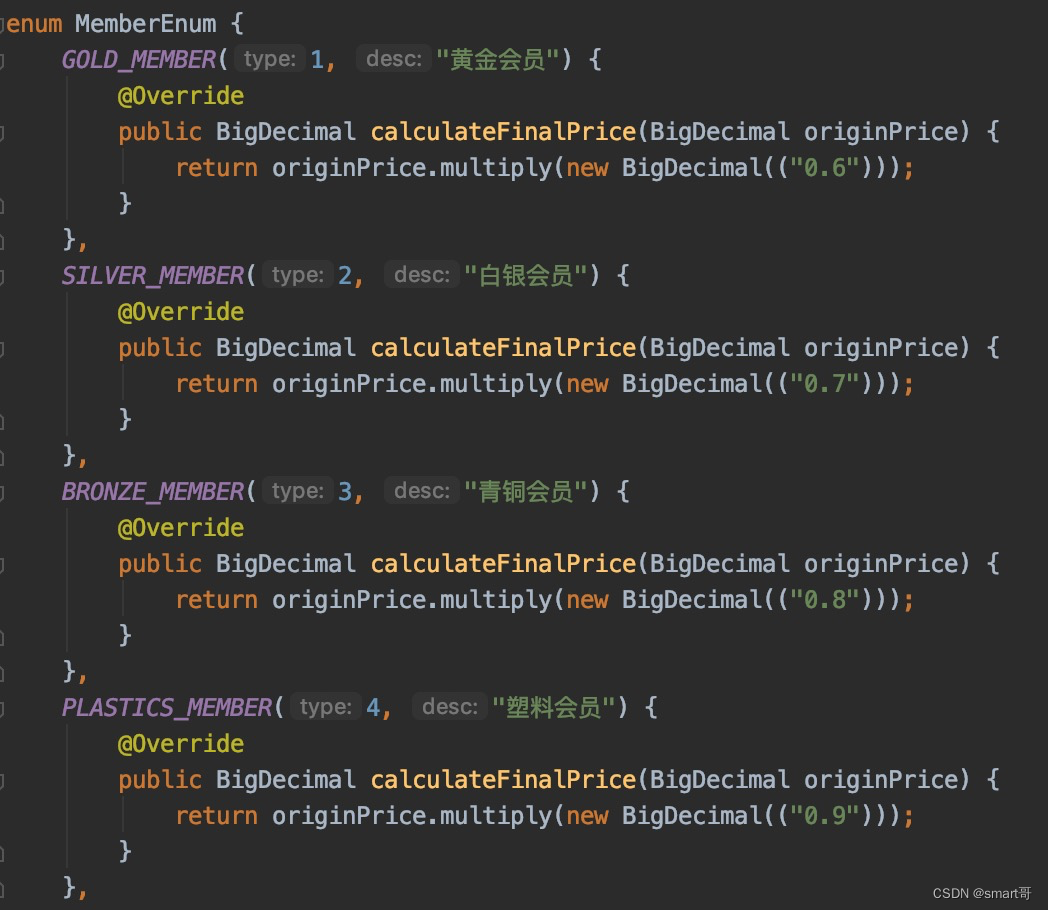
enum MemberEnum {
// ---------- 把这几个枚举当做本应该在外面实现的MemberEnum子类,不要看成MemberEnum内部的 ----------
GOLD_MEMBER(1, "黄金会员") {
@Override
public BigDecimal calculateFinalPrice(BigDecimal originPrice) {
return originPrice.multiply(new BigDecimal(("0.6")));
}
},
SILVER_MEMBER(2, "白银会员") {
@Override
public BigDecimal calculateFinalPrice(BigDecimal originPrice) {
return originPrice.multiply(new BigDecimal(("0.7")));
}
},
BRONZE_MEMBER(3, "青铜会员") {
@Override
public BigDecimal calculateFinalPrice(BigDecimal originPrice) {
return originPrice.multiply(new BigDecimal(("0.8")));
}
},
;
// ---------- 下面才是MemberEnum类的定义 ---------
private final Integer type;
private final String desc;
MemberEnum(Integer type, String desc) {
this.type = type;
this.desc = desc;
}
/**
* 定义抽象方法,留个子类实现
*
* @param originPrice
* @return
*/
protected abstract BigDecimal calculateFinalPrice(BigDecimal originPrice);
public Integer getType() {
return type;
}
public String getDesc() {
return desc;
}
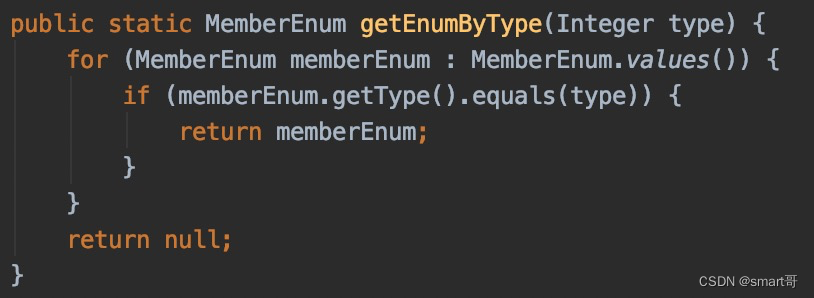
public static MemberEnum getEnumByType(Integer type) {
MemberEnum[] values = MemberEnum.values();
for (MemberEnum memberEnum : values) {
if (memberEnum.getType().equals(type)) {
return memberEnum;
}
}
throw new IllegalArgumentException("Invalid Enum type:" + type);
}
}枚举类本身比较抽象,上面的代码可能一部分人会一时转不过弯。那你就想象着把三个枚举抽出来:

当然,你也可以新增一个接口,在接口内部定义calculateFinalPrice(),让MemberEnum实现该接口
我敢肯定,必然有部分同学觉得我在故弄玄虚,搞了一大堆,但看起来反而更麻烦。
大家不要光看当前的代码量,而要考虑扩展。如果此时需要新增会员类型,那么使用常量的版本需要改动两处:
- 常量类
- if/else所在的类

而枚举版本只要在枚举类中新增一个类型:
而修改if/else的犯错概率一般远大于新增枚举类。这其实也体现了设计模式的思想:用增量代替修改。
还是觉得枚举麻烦?
此时应该给代码加上一根时间轴,动态地看待问题。比如,假设随着时间推移,不可避免地需要在很多地方对用户的身份进行判断,于是你的同事把你写的if/else拷贝到项目的各个角落。

而产品的需求改到第二版时才发现漏算了星耀会员,于是你需要找到所有相关的if/else进行修改...你必须细致,只要有一处忘了改就会出错,增加了测试和维护的成本。
但如果采用策略枚举的方式,把易变动的逻辑抽取出来共同维护就会方便很多。
设计模式中有个说法:越抽象越稳定,越具体越不稳定,所以提倡面向抽象编程。设计模式的目的不是消除变化,而是隔离变化。在软件工程中,变化的代码就像房间里一只活蹦乱跳的兔子,你并不能让它绝对安静(不要奢望需求永不变更),但可以准备一个笼子把它隔离起来,从而达到整体的稳定。
上面的代码中,if/else是兔子,而MemberEnum则扮演着笼子的角色。如果不用MemberEnum把兔子关在一起,那么兔子就会在整个项目蹦跶,很难管理。
上面案例充分说明作为对象的枚举比作为字段的常量可玩性高很多。
枚举代码优化
优化1:尽量使用foreach
举个例子,对于普通的for循环:
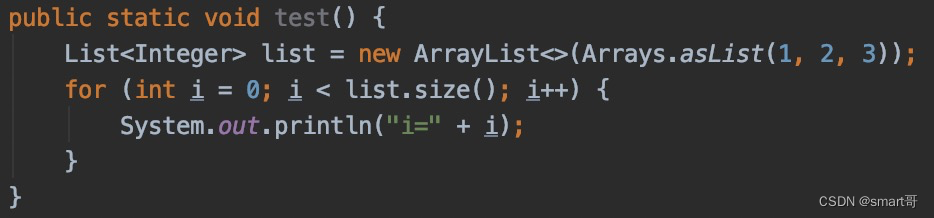
每次循环其实都会判断i<list.size(),每次都会调用size()获取大小,而foreach则会进行优化:

其他写法:

如果你学过Java8的Stream,还可以这样写:
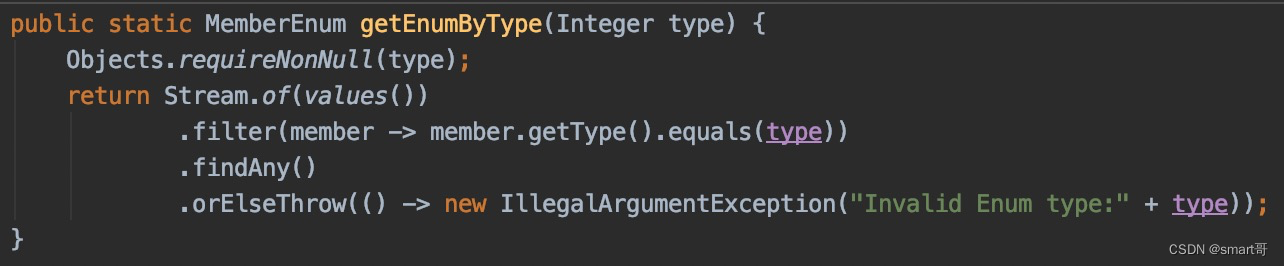
抛不抛异常看业务,个人觉得返回null意义也不大,反正要么空指针要么插入不可预计的值。
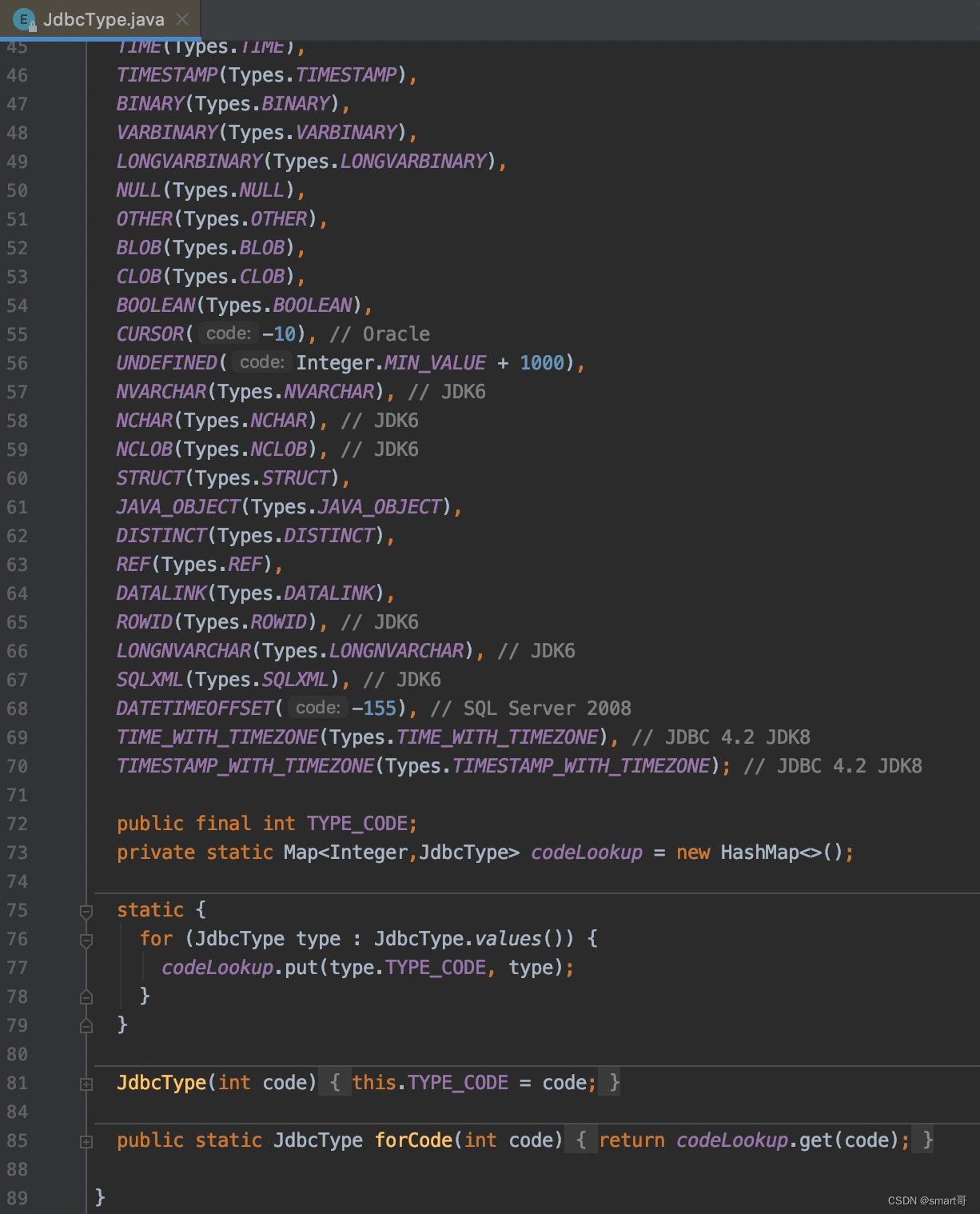
优化2:用Map替代For,缓存枚举值,利用key提高检索速度(实用小算法)
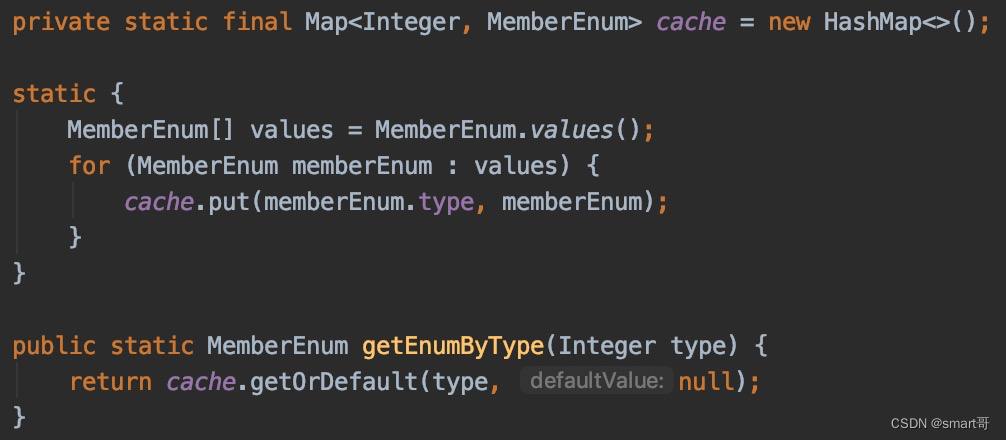
或
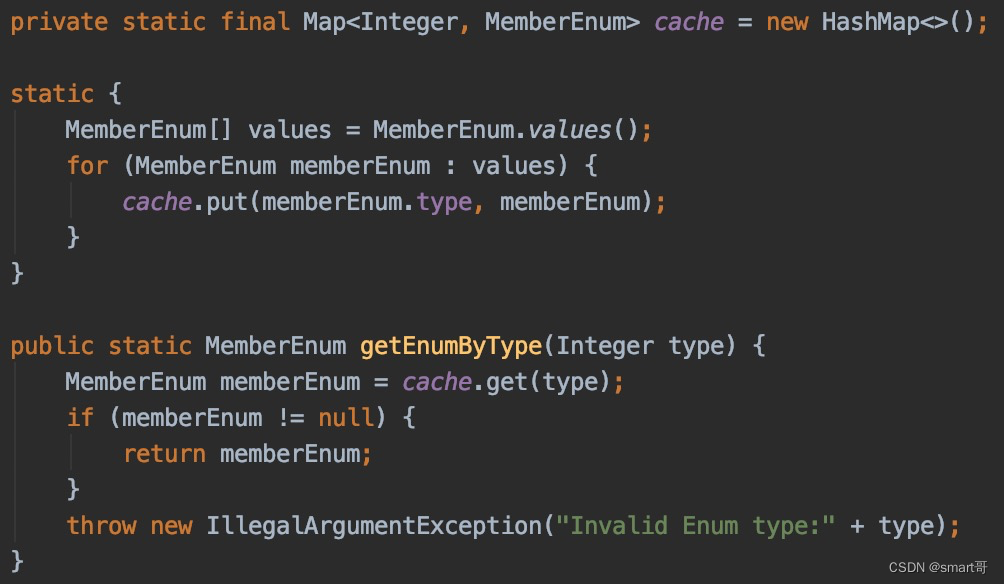
这种写法是我在研究MyBatis枚举转换器时看源码发现的:
优化3:静态导入简化代码(看个人喜好,不是很好用)
一般都是这样写:

但有时代码会看起来很长,此时可以使用静态导入:


优化4:结合Lombok简化代码
@Getter
@AllArgsConstructor
public enum PlatformEnum {
TAOBAO(1, "淘宝", "taobao", "http://xxx"),
PDD(2, "拼多多", "pdd", "http://xxx");
private final Integer code;
private final String sourceKey;
private final String iconUrl;
public static PlatformEnum getByCode(Integer code) {
for (PlatformEnum platformEnum : PlatformEnum.values()) {
if (platformEnum.getCode().equals(code)) {
return platformEnum;
}
}
return null;
}
}枚举与常量类的取舍
最后说一下个人平时对枚举和常量类的取舍:
- 错误码的定义用枚举
- 字段状态用枚举或常量类都可以,个人更倾向于使用枚举,可玩性会比常量类高
- 一些全局变量的定义可以使用常量类,比如USER_INFO、SESSION_KEY
一点小建议
大部分人设计枚举时都是使用以下格式:
MONDAY(1, "星期一")
这种格式在当前情境下是合理的,但如果是其他场景:
WAIT_FOR_DEAL(1, "等待处理")
SUITABLE(2, "合适")
UNSUITABLE(3, "不合适")
INVITE(4, "邀请面试")
...
随着状态越来越多,前端同学会变得很痛苦。所以如果你的项目允许,可以使用MONDAY("MONDAY", "星期一")这种形式,也就是存字符串。
这个时候其实没必要考虑索引键长问题,你就当它是一个普通字段。退一步想,如果这是name字段,难道你会因为索引的原因而使用int类型吗...考虑前后端对接及维护,代码的可读性有时比一丁点所谓的性能还重要。
扩展内容
在网上看到的写法,但个人觉得不是很好。他的出发点是每个枚举类都要写getEnumByType()方法,太麻烦了,希望把各个类中的getEnumByXxx()方法抽取到工具类中:
public class EnumUtil {
private static final Map<Object, Object> key2EnumMap = new ConcurrentHashMap<>();
private static final Set<Class<?>> enumSet = ConcurrentHashMap.newKeySet();
/**
* 获取枚举(带缓存)
*
* @param enumType 枚举Class类型
* @param enumToValueMapper 抽取字段(按哪个字段搜索)
* @param key 待匹配的字段值
* @param <T>
* @return
*/
public static <T extends Enum<T>, R> Optional<T> getEnumWithCache(Class<T> enumType, Function<T, R> enumToValueMapper, Object key) {
if (!enumSet.contains(enumType)) {
// 不同的枚举类型互相不影响
synchronized (enumType) {
if (!enumSet.contains(enumType)) {
// 添加枚举
enumSet.add(enumType);
// 缓存枚举键值对
for (T enumConstant : enumType.getEnumConstants()) {
// enumToValueMapper.apply()表示从枚举中获得value。但不同枚举可能value相同,因此getKe()进一步加工,为value拼接路径做前缀
String mapKey = getKey(enumType, enumToValueMapper.apply(enumConstant));
key2EnumMap.put(mapKey, enumConstant);
}
}
}
}
return Optional.ofNullable((T) key2EnumMap.get(getKey(enumType, key)));
}
/**
* 获取key
* 注:带上枚举类名作为前缀,避免不同枚举的Key重复
*
* @param enumType
* @param key
* @param <T>
* @return
*/
public static <T extends Enum<T>, R> String getKey(Class<T> enumType, R key) {
return enumType.getName().concat(key.toString());
}
/**
* 获取枚举(不缓存)
*
* @param enumType
* @param enumToValueMapper
* @param key
* @param <T>
* @param <R>
* @return
*/
public static <T extends Enum<T>, R> Optional<T> getEnum(Class<T> enumType, Function<T, R> enumToValueMapper, Object key) {
for (T enumThis : enumType.getEnumConstants()) {
if (enumToValueMapper.apply(enumThis).equals(key)) {
return Optional.of(enumThis);
}
}
return Optional.empty();
}
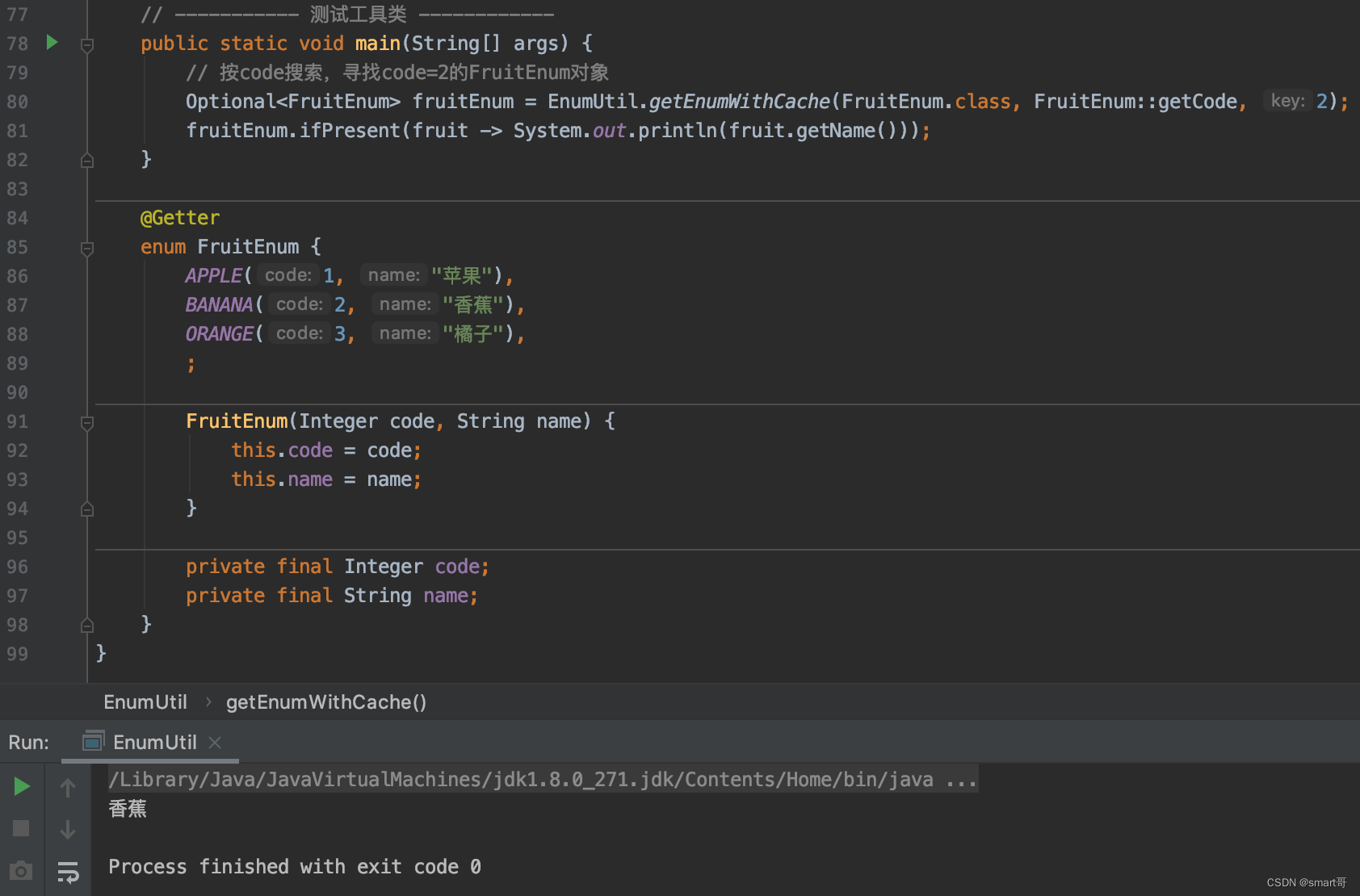
// ----------- 测试工具类 ------------
public static void main(String[] args) {
// 按code搜索,寻找code=2的FruitEnum对象
Optional<FruitEnum> fruitEnum = EnumUtil.getEnumWithCache(FruitEnum.class, FruitEnum::getCode, 2);
fruitEnum.ifPresent(fruit -> System.out.println(fruit.getName()));
}
@Getter
enum FruitEnum {
APPLE(1, "苹果"),
BANANA(2, "香蕉"),
ORANGE(3, "橘子"),
;
FruitEnum(Integer code, String name) {
this.code = code;
this.name = name;
}
private final Integer code;
private final String name;
}
}
为什么我认为上面的Util工具不好呢?
- 首先,getEnumWithCache()最后返回值需要强转,IDEA提示看着很难受。但似乎无法解决,因为key2EnumMap只能用Object,所以注定了需要强转。
- 其次,也是最重要的,没有对Function enumToValueMapper做限制。也就是说用户可以随意传入映射参数,有些人把枚举映射为name,有些人把枚举映射为oridnal,还有其他属性。也就说,很乱。到时取出时,你都不知道自己当初存的key是什么。
当然,如果你实在需要一个EnumUtil简化操作,那么下面这个简化版的可能更适合你(其实hutool这类第三方工具都有提供类似的功能):
@Slf4j
public class EnumUtil {
/**
* 获取枚举类型的枚举值,通过属性值
*
* @param clazz 枚举类
* @param fieldFunction 属性值获取函数
* @param fieldValue 属性值
* @param <E> 枚举类
* @param <V> 属性值
* @return 匹配的枚举值,可能为null
*/
public static <E extends Enum<E>, V> E getEnum(Class<E> clazz, Function<E, V> fieldFunction, V fieldValue) {
Assert.notNull(clazz);
E[] es = clazz.getEnumConstants();
for (E e : es) {
if (Objects.equals(fieldFunction.apply(e), fieldValue)) {
return e;
}
}
return null;
}
/**
* 获取枚举类型的枚举值,通过属性值
*
* @param clazz 枚举类
* @param fieldFunction 属性值获取函数
* @param fieldValue 属性值
* @param <E> 枚举类
* @param <V> 属性值
* @return 匹配的枚举值,Optional类型
*/
public static <E extends Enum<E>, V> Optional<E> getEnumOptional(Class<E> clazz, Function<E, V> fieldFunction, V fieldValue) {
Assert.notNull(clazz);
E[] es = clazz.getEnumConstants();
for (E e : es) {
if (Objects.equals(fieldFunction.apply(e), fieldValue)) {
return Optional.of(e);
}
}
return Optional.empty();
}
}补充:解答读者疑惑
在本文评论区看到一个提问,觉得也是很多人的疑问。这里特别补充一下。
为什么枚举类内部可以定义抽象方法?
关于这个问题,可以先去看看JDK的Enum是什么样的:

Enum本身就是一个抽象类,却没有定义抽象方法。按之前小册讲过的:一个类,没有抽象方法,却被定义为抽象类,主要是为了不被new。同理 UserStatusEnum extends Enum后,自己也是一个抽象类,也没有任何抽象方法。
OK,回到问题本身。
我们通常说的 枚举,一般是指枚举对象,而不是枚举类。
@Getter
@AllArgsConstructor
public enum UserStatusEnum { // 这个才是枚举类
// 这两个看起来是“字段”的玩意儿,其实是对象(枚举对象)
DELETE(-1, "删除"),
DEFAULT(0, "默认");
private final Integer status;
private final String desc;
}
所以,我在一个抽象类UserStatusEnum中定义一个抽象方法有什么问题呢?再者,既然我在UserStatusEnum中既然定义了抽象方法,那么DELETE、DEFAULT两个枚举对象就必须实现这个方法。
@Getter
@AllArgsConstructor
public enum UserStatusEnum {
DELETE(-1 "删除"){
// 实现UserStatusEnum定义的抽象方法
@Override
public void test() {
}
},
DEFAULT(0, "默认") {
@Override
public void test() {
}
};
private final Integer status;
private final String desc;
// 定义一个抽象方法
public abstract void test();
}枚举最令人困惑的地方在于,枚举类的定义和枚举对象是混在一个文件中的,再加上一些后期的自动编译处理,让初学者看起来觉得很抽象。但你如果把DELETE、DEFAULT单独拎出去,想象成一个独立的对象或实现类,会更容易接受。
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
进群,大家一起学习,一起进步,一起对抗互联网寒冬