论文:https://arxiv.org/abs/2207.10666
GitHub:https://github.com/microsoft/Cream/tree/main/TinyViT
摘要
在计算机视觉任务中,视觉ViT由于其优秀的模型能力已经引起了极大关注。但是,由于大多数ViT模型的参数量巨大,使得其无法在资源受限的设备上运行。为了解决这个问题,本文提出了TinyViT,基于提出的快速蒸馏方案在大规模数据集上进行预训练的一系列小且高效的模型。核心思想是将大的预训练模型蒸馏给一个小的,同时能获取海量预训练数据的红利。具体来说,在预训练阶段进行蒸馏流程完成知识迁移,教师模型的输出被稀疏化并存储在硬盘中来节省内存消耗和计算负担。大量实验证明TinyViT的有效性,其参数量为21M,在ImageNet-1K数据集上取得84.8%的top-1精度,与Swin-B相比,同样的精度下参数量少了4.2倍。此外,通过增大网络输入分辨率,TinyViT可以去的86.5%的精度,比Swin-L稍微好点,但参数量仅为其11%。最后,实验验证了其在下游任务上具有较好的迁移能力。
模型结构
快速预训练蒸馏
如上图所示,作者观察到,使用大规模数据预训练小模型并不会带来性能的增益,尤其是迁移到下游任务上。为了解决这个问题,作者借助知识蒸馏进一步释放小模型的预训练潜力。不同于之前的工作关注微调阶段的蒸馏工作,本文关注预训练阶段的蒸馏,这样不仅小模型可以从大模型中学习到知识,同时提高了它们对下游任务的迁移能力。
直接进行预训练蒸馏是低效且昂贵的,因为大部分的计算资源消耗在教师模型的前向传播中,而不是训练学生模型上。为了解决这个问题,作者提出了一个快速预训练蒸馏框架。如下图所示,首先将数据增强方式和教师模型的预测结果保存下来,在训练阶段,重用存储的信息来精确地复制前向传播过程,成功地省略了教师模型的前向传播过程和内存占用。
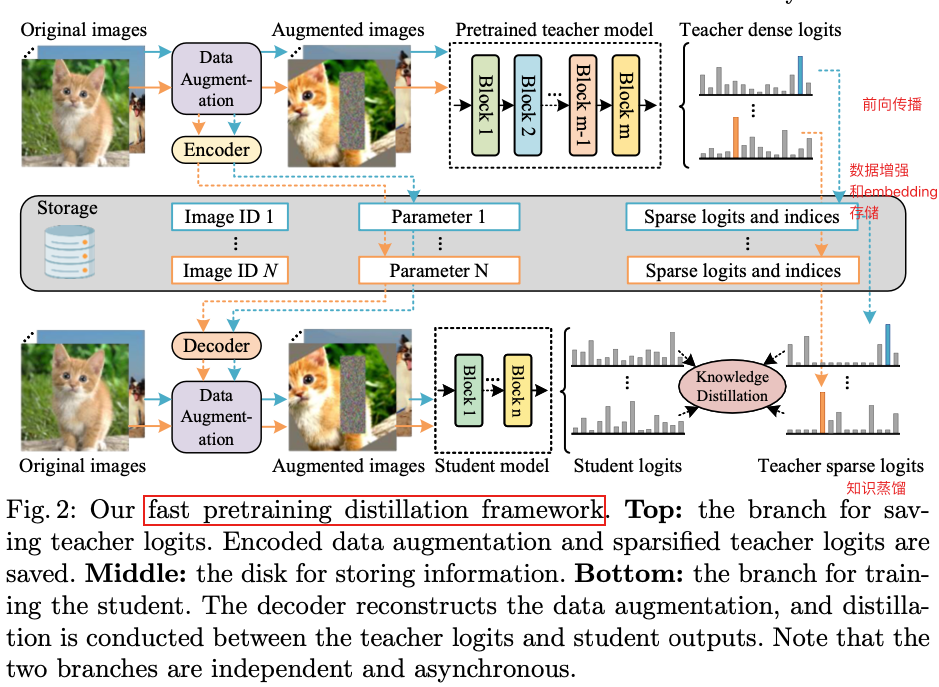
假设输入图像为
x
x
x,数据增强方式为
A
A
A,例如randaugment和cutmix,教师模型用
T
T
T表示。数据增强方式
A
A
A和教师模型预测结果
y
^
=
T
(
A
(
x
)
)
\hat{y}=T(A(x))
y^=T(A(x))将会被保存下来。需要注意的是,由于数据增强具有随机性,因此对于同一张图片多次通过同样的数据增强策略会得到不同的结果,所以每次迭代
(
A
,
y
^
)
(A, \hat{y})
(A,y^)都需要存储。
在训练阶段,只需要重用
(
A
,
y
^
)
(A, \hat{y})
(A,y^),并优化下面的目标函数即可:
L
=
C
E
(
y
^
,
S
(
A
(
x
)
)
L=CE(\hat{y}, S(A(x))
L=CE(y^,S(A(x))
其中,
S
(
.
)
S(.)
S(.)和
C
E
(
.
)
CE(.)
CE(.)分别表示学生模型和交叉墒损失函数。这个训练框架是不需要真实标签,因为只使用了教师模型生成的软标签进行训练。这种无标签策略在实际中是可行的,因为软标签足够正确,同时携带大量用于分类的信息,例如类别关系。此外,当使用真实标签进行蒸馏会带来轻微的性能下降,原因在于IN-21K中并不是所有的标签都是互斥的。
此外,作者的蒸馏框架中应用了稀疏软标签和数据增强编码,可以极大减少存储压力同时提高内存利用率。
稀疏软标签
考虑到教师模型输出
C
C
C维度(类别数)的向量,如果
C
C
C非常大,则保存全部的向量内容需要更多的存储空间,例如,对于IN-21K而言
C
=
21841
C=21841
C=21841。因此,只保存
y
^
\hat{y}
y^中最重要的
t
o
p
−
K
top-K
top−K个值即可。在训练过程中,只对稀疏标签进行标签平滑:
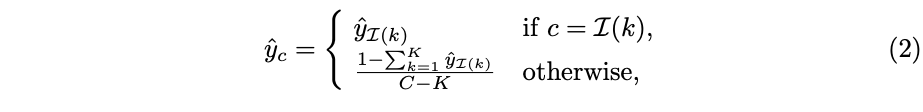
当稀疏稀疏
K
K
K远小于
C
C
C时,可以将逻辑值的存储量减少几个数量级。而且实验结果表明,这中稀疏标签可以实现与密集标签相当的知识蒸馏性能。
数据增强编码
数据增强涉及到一组参数 d d d,例如旋转角度和裁剪坐标。由于每次迭代中每个图像的 d d d是不同的,直接保存它会降低内存的效率。为了解决这个问题,作者通过标量参数 d 0 = ξ ( d ) d_0=\xi(d) d0=ξ(d)来编码 d d d,其中 ξ \xi ξ表示编码器。在训练阶段,从存储文件中加载 d 0 d_0 d0然后还原 d = ξ − 1 ( d 0 ) d=\xi^{-1}(d_0) d=ξ−1(d0),其中 ξ − 1 \xi^{-1} ξ−1表示解码器。解码器的常见选择是PCG,它将单个参数作为输入,并生成一系列参数。
模型结构
作者通过一个逐步模型缩减方法(a progressive model contraction approach)来得到一族微小视觉transformer模型。具体而言,从一个大模型开始定义一些基本的缩放因子,每一次迭代通过调整缩放因子来得到一个更小的模型。选择那些既满足参数数量约束又满足吞吐量约束的模型,在下一步中,具有最佳精度的模型将被进一步缩减,直到达成目标。
为了方便用于多尺度特征的密集预测下游任务,作者采用了分层视觉transformer作为基本架构。更具体来说,基础模型由分辨率逐渐降低的四个阶段组成,类似Swin和LeViT。patch embedding模块由两个卷积组成,卷积核大小为3,步长为2,padding为1。在第一阶段,使用轻量且高效的MBConvs来下采样,因为在开始阶段由于卷积较强的归纳偏差使用卷积层可以有效地学习低级表示。后3个阶段由transformer block组成,使用窗口注意力来降低计算成本。注意力偏差和注意力与MLP之间的3✖️3深度卷积被引入来获取局部信息。所有的激活函数都是GeLU,卷积层和线性层的归一化方法为BatchNorm和LayerNorm。
构建模型过程中,作者考虑了如下的缩放因子:
- γ D 1 − 4 \gamma_{D_{1-4}} γD1−4:4个stage的嵌入维度;决定网络的宽度
- γ N 1 − 4 \gamma_{N_{1-4}} γN1−4:4个stage中block的个数;决定网络的深度
- γ W 2 − 4 \gamma_{W_{2-4}} γW2−4:最后3个stage的宽口大小
- γ R \gamma_{R} γR:MBConv block的channel expansion ratio;
- γ M \gamma_{M} γM:transformer blocks中MLP的expansion ratio;
- γ E \gamma_{E} γE:multi- head attention中每个head的维度
所有模型中相同的缩放因子为: γ N 1 , γ N 2 , γ N 3 , γ N 4 = 2 , 2 , 6 , 2 {\gamma_{N_1},\gamma_{N_{2}},\gamma_{N_{3}},\gamma_{N_{4}}}={2,2,6,2} γN1,γN2,γN3,γN4=2,2,6,2, γ W 2 , γ W 3 , γ W 4 = 7 , 14 , 7 {\gamma_{W_{2}},\gamma_{W{3}},\gamma_{W_{4}}}={7,14,7} γW2,γW3,γW4=7,14,7和 γ R , γ M , γ E , = 4 , 4 , 32 {\gamma_{R},\gamma_{M},\gamma_{E},}={4,4,32} γR,γM,γE,=4,4,32。对于嵌入向量 γ D 1 , γ D 2 , γ D 3 , γ D 4 {\gamma_{D_1},\gamma_{D_{2}},\gamma_{D_{3}},\gamma_{D_{4}}} γD1,γD2,γD3,γD4,TinyViT-21M为{96, 192, 384, 576} ,TinyViT-11M为{64, 128, 256, 448}, TinyViT-5M为{64, 128, 160, 320}。
效果分析
在本节中,作者对两个关键问题进行分析和讨论:
- 限制小模型适应大规模数据的潜在原因是什么?
- 为什么蒸馏可以帮助小模型释放大规模数据的潜力?
为了回答上述问题,作者在ImageNet-21K上进行了实验,该数据集包含14M图像和21841个类别。
限制小模型适应大规模数据的潜在原因是什么?
作者发现在IN-21K中存在很多困难样本,例如图像对应标签错误,相似图像有不同标签等。众所周知,IN-21K中大约有10%的样本是困难样本。小模型难以适应这些困难样本,导致与大模型相比训练精度较低(TinyVit-21M: 53.2%和Swin-L-197M: 57.1%),同时在IN-1K上的可迁移性有限(TinyViT-21M w/ pretraining: 83.8% 和 w/o pretraining: 83.1%)。

如上图所示,为了验证困难样本的影响,作者使用如下两种技术:
- 使用IN-21K微调预训练模型Florence,然后推理IN-21K,对于预测结果不在top-5之内的那些图像,定义为困难样本。通过这种方式,从IN-21K中移除了大约2M图像,约14%。然后在清理后的数据集上预训练TinyViT-21M和Swin-T。
- 使用Florence作为教师模型来执行预训练蒸馏训练TinyViT-21M和Swin-T,使用其生成软标签来代替IN-21K中被污染的GT标签,得到在IN-1K上进行微调的结果。
从上图的结果可以得出如下结论:
- 在原始的IN-21K上预训练小模型在IN-1K上微调的增益微乎其微;
- 当移除部分困难样本之后,小模型可以更好的利用大数据并实现更高的性能增益;
- 知识蒸馏方案可以避免检测困难样本,因为它不使用GT标签,,而GT标签的不合适才是样本属于困难样本的主要原因,因此它可以获得更高的性能提升。
为什么蒸馏可以帮助小模型释放大规模数据的潜力?
答案是学生模型可以直接从教师模型那里学习到高级知识。具体来说,教师在训练学生时注入类之间的关系,同时过滤学生模型的噪声标签。
为了分析教师模型预测的类别关系,作者从总共21841个类别的IN-21K中为每个类别选择8张图像。这些图像被送入到Florence来的道预测逻辑值,并画出预测逻辑上勒见Pearson相关稀疏的热力图。
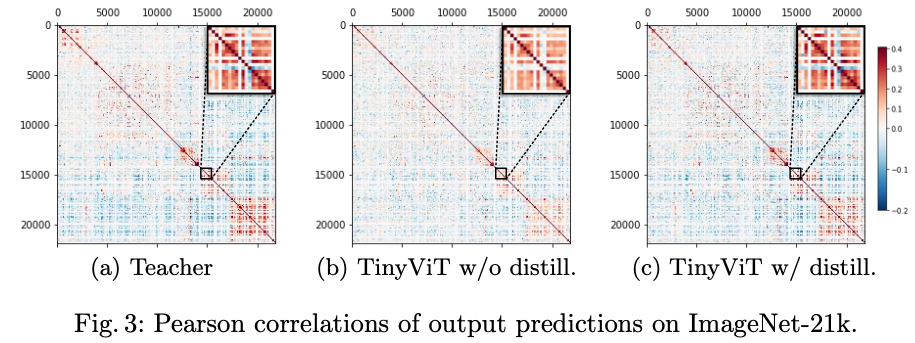
如上图1(a)所示,相似或者相关类别之间有高相关性,不同类别可以被区分,表明教师模型的预测结果确实包含类别关系。在(b)和©中比较了是否采用蒸馏法的Pearson相关性。分析对角线结构,作者发现当不使用蒸馏技术时候,对角线的结构会更不明显,说明小模型更难捕获类间关系。但是,蒸馏可以引导学生模型模仿教师模型的行为,从而更好地从大数据中挖掘知识。
实验结果
实验细节
ImageNet-21K的预训练:TinyViT在ImageNet-21K上预训练90个epoch,具体参数设置如下:
- 优化器:AdamW,权重衰减系数0.01
- 学习率:初始学习率为0.002,warmup 5个epoch,余弦衰减方案,batch size为4096,梯度裁剪设置为最大norm=5
- 随机深度:TinyViT/11M为0,21M为0.1
从上一步预训练模型进行ImageNet-1K微调:将预训练模型在ImageNet-1K上进行微调
ImageNet-1K高分辨率微调:进一步提高输入分辨率,微调TinyViT
知识蒸馏:预先保存教师模型在ImageNet-1K上的top-100预测值,包括Swin-L, BEiT-L, CLIP-ViT-L/14和Florence。
消融实验
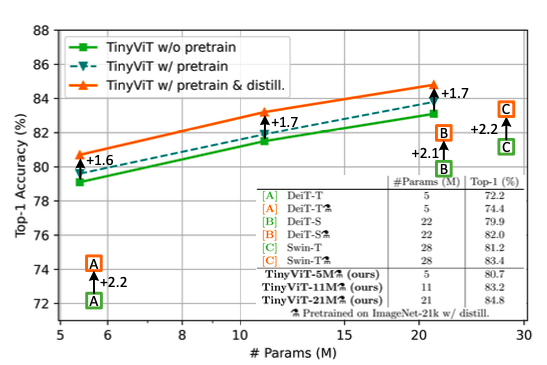
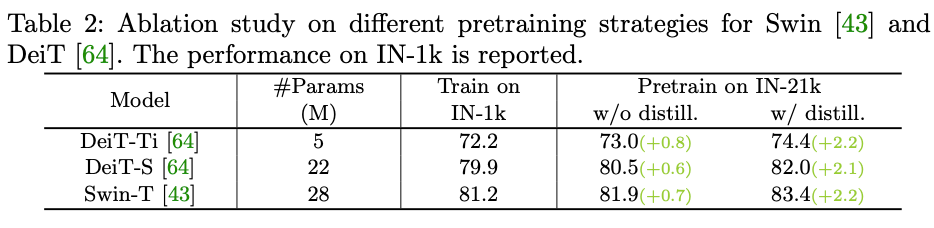
预训练蒸馏方案的影响:如下图所示,相比于从头开始训练,进行预训练但不做蒸馏,取得的增益十分有限,如0.8%/0.6%/0.7% for DeiT-Ti/DeiT-S/Swin-T。使用快速蒸馏方案,分别可以提高2.2%/2.1%/2.2%。结果表明预训练蒸馏方案可以使得小模型可以从大规模数据中获利更多。
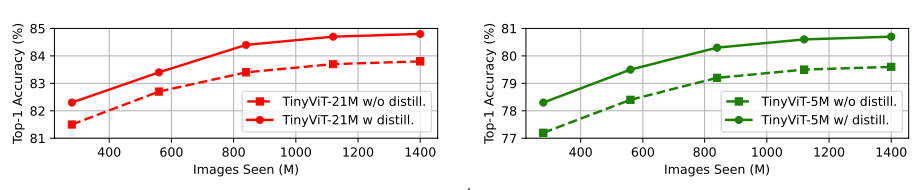
预训练数据规模的影响:如下图所示,TinyVIT-5M/21M在不同预训练数据规模上结果的影响。使用IN-21K的数据进行预训练,CLIP- ViT- L/14作为教师模型,最后在IN-1K上进行微调,可以得出预训练蒸馏方案在不同的数据大小上都能带来性能增益。
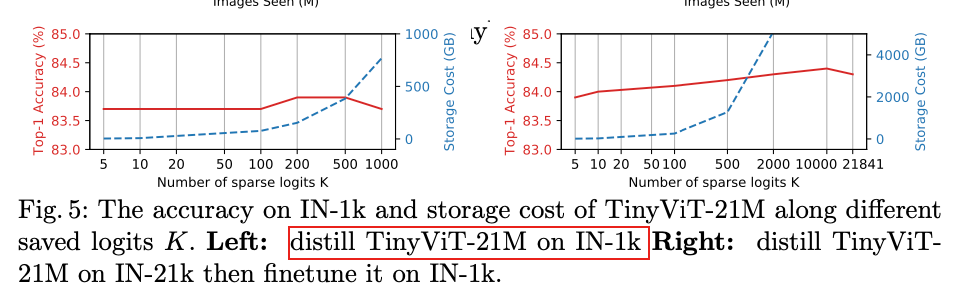
稀疏化大小的影响:使用Swin- L作为教师模型,TinyViT-21M作为学生模型,在IN-1K和IN-21K上都观察到精度随着稀疏逻辑值K的数增加而提高,直到饱和。这个观察符合现有工作对知识蒸馏的认知,教师模型的输出中除了有类别关系还包含噪声。为了在有限的空间下获得相当的精度,作者选择稍大的K,在IN-1K中K=10(1% logits),在IN-21K上K=100(0.46% logits),分别需要16GB/48GB的存储空间。
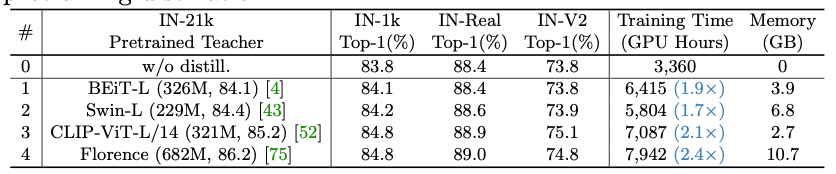
教师模型的影响:作者同时评估了教师模型对预训练蒸馏的影响。如下图所示,更好的教师可以产生更好的学习模型。但是,较好的教师模型通常模型尺寸较大,导致GPU内存消耗高且时间长。
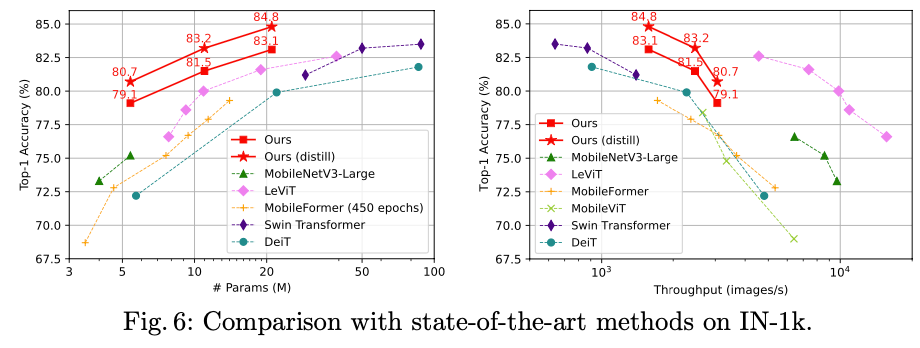
图像分类结果

下游任务
线性探测
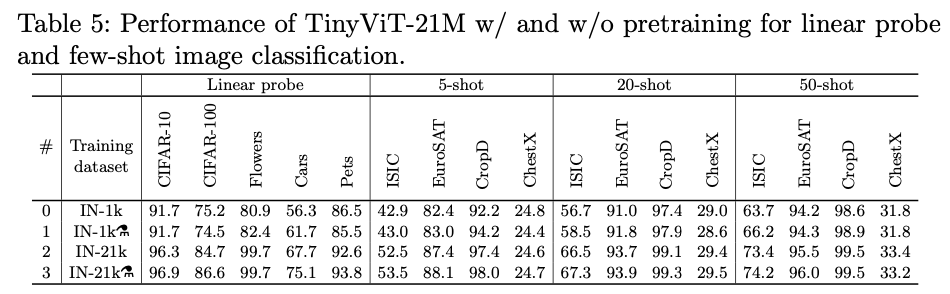
如下图所示,测试了4种不同训练设计下性能对比,可以发现预训练蒸馏可以提升TinyViT线性探测的能力。此外,当在更大规模的数据上训练时,有更好的表现。
少样本学习
如上图所示,同样可以观察到预训练蒸馏下TinyViT能取得更好的效果,除了ChestX数据集,因为它是一个灰度医学图像与自然图像存在较大差距。
目标检测
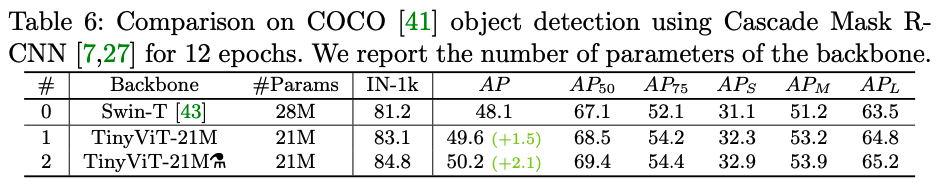
以Swin-T的Cascade R-CNN作为基准,在相同的训练策略下,TinyViT取得更好的成绩,高1.5%,当应用预训练蒸馏法后,还能额外取得0.6%的增益。结果表明,预训练蒸馏方案对于小模型在下游任务上的迁移能力也是有效的。
结论
本文基于提出的预训练蒸馏方案发布了一个小且有效的视觉ViT模型,TinyViT。大量的实验表明TinyViT在ImageNet-1K上的高效性,以及在下游任务上的迁移能力。在接下来的工作中,将考虑使用更多数据和更好的教师模型来解锁小模型的能力。设计一个高效的模型缩放方法来生成具有较好性能的小模型是另外一个有趣的研究方向。
Vision Transformer 超详细解读 (原理分析+代码解读) (二十八)