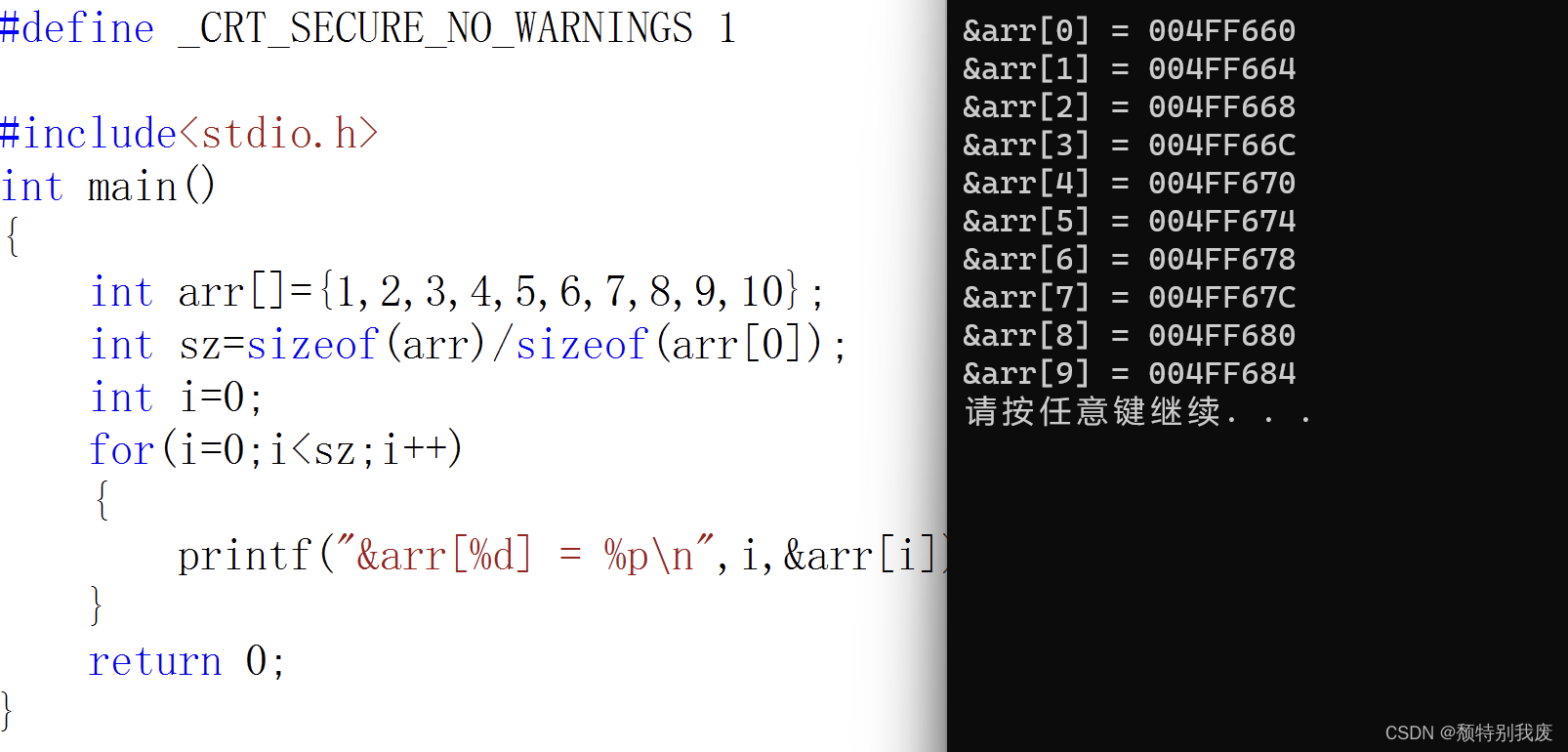
1、拉取flink镜像,创建网络
docker pull flink
docker network create flink-network
2、创建 jobmanager
# 创建 JobManager
docker run \
-itd \
--name=jobmanager \
--publish 8081:8081 \
--network flink-network \
--env FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager" \
flink:latest jobmanager
3、创建 taskmanager
# 创建 TaskManager
docker run \
-itd \
--name=taskmanager \
--network flink-network \
--env FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager" \
flink:latest taskmanager
4、访问 http://localhost:8081/
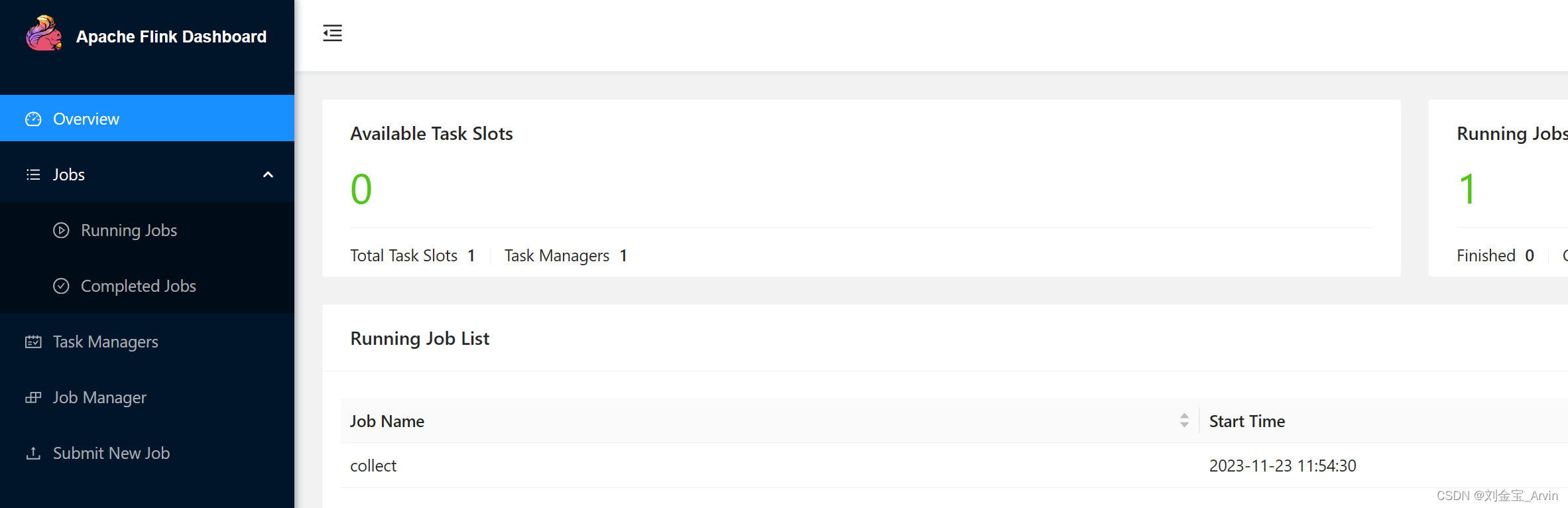
4.1 修改Task Slots
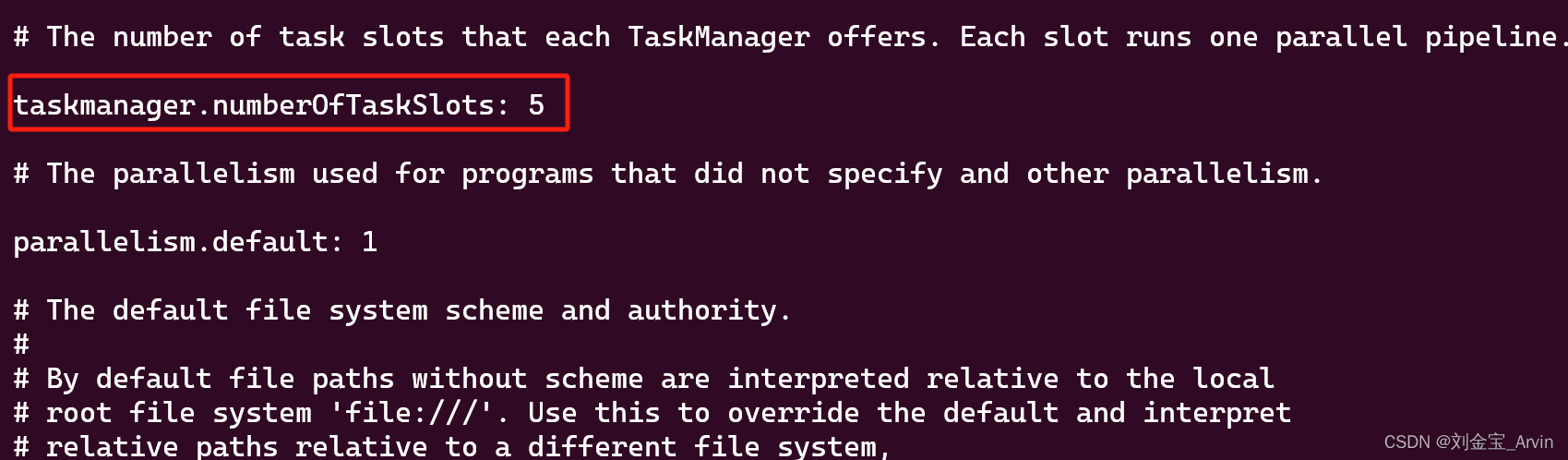
默认的Slots num是1,我们可以修改为5:
修改的目录是jobmanager和taskmanager的/opt/flink/conf的flink-conf.yaml文件:

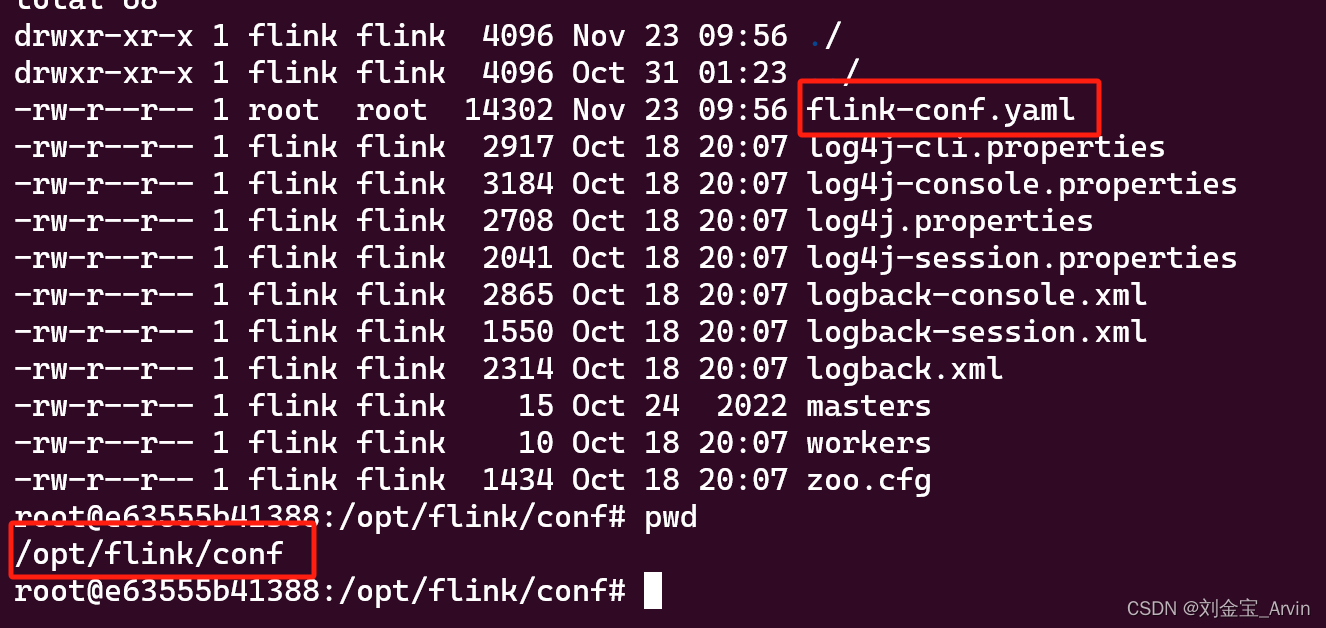
修改taskmanager.numberOfTaskSlots:即可。
注意:默认的docker容器中没有vi/vim命令,可以使用docker cp命令,复制出来修改,然后在复制回去,如下:
docker cp taskmanager:/opt/flink/conf/flink-conf.yaml .
docker cp flink-conf.yaml taskmanager:/opt/flink/conf/
5、通过flinksql消费Kafka
确保有一个可用的kafka,如果没有,可以五分钟内,Docker搭建一个
Docker安装kafka 3.5
并且通过python,简单写一个生产者
Python生产、消费Kafka
5.1 导入flink-sql-connector-kafka jar包
顾名思义,用于连接flinksql和kafka。
进入flink
docker exec -it jobmanager /bin/bash
进入 flink的bin目录
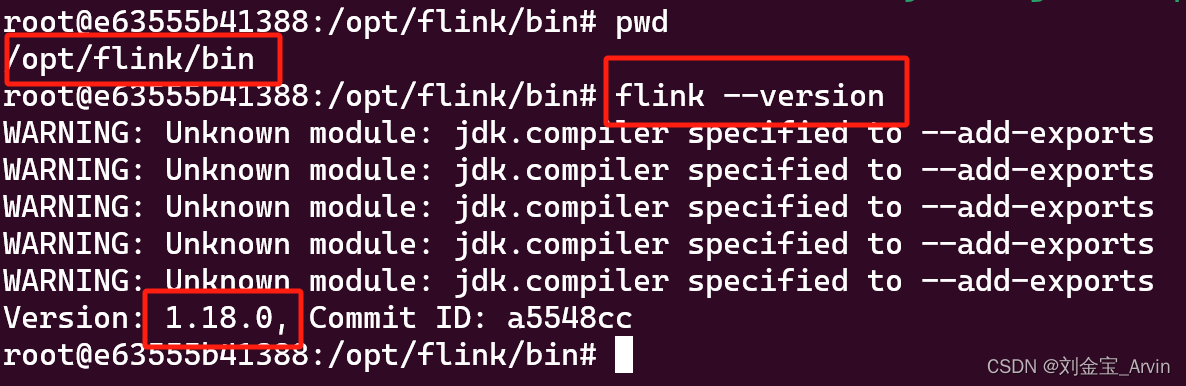
cd /opt/flink/bin
查看flink版本:
flink --version
可以看出,我的版本是1.18.0
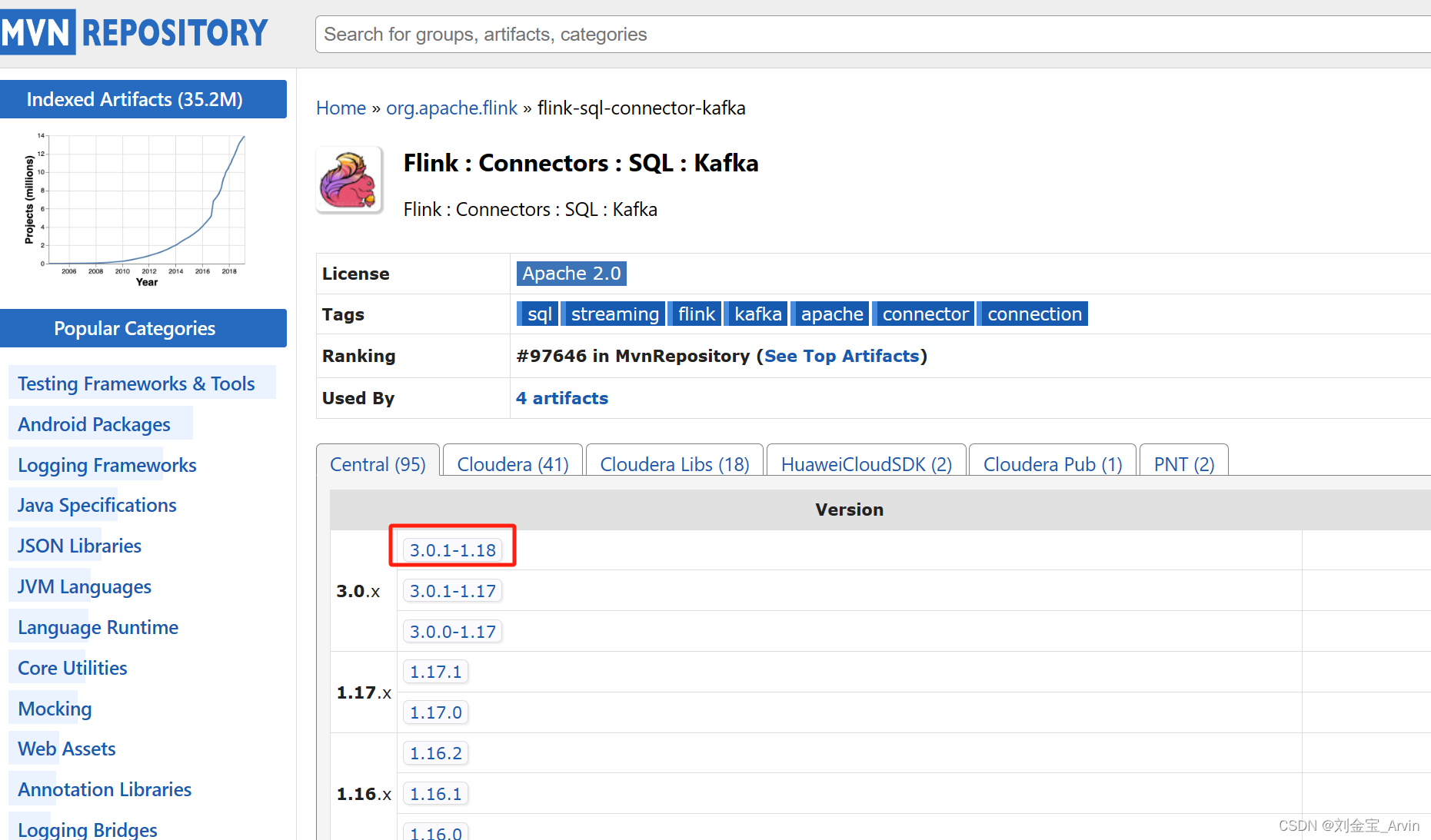
根据自己的flink版本,下载对应的 flink-sql-connector-kafka jar包
https://mvnrepository.com/artifact/org.apache.flink/flink-sql-connector-kafka
因为我是1.18.0,所以选择下图的版本包:
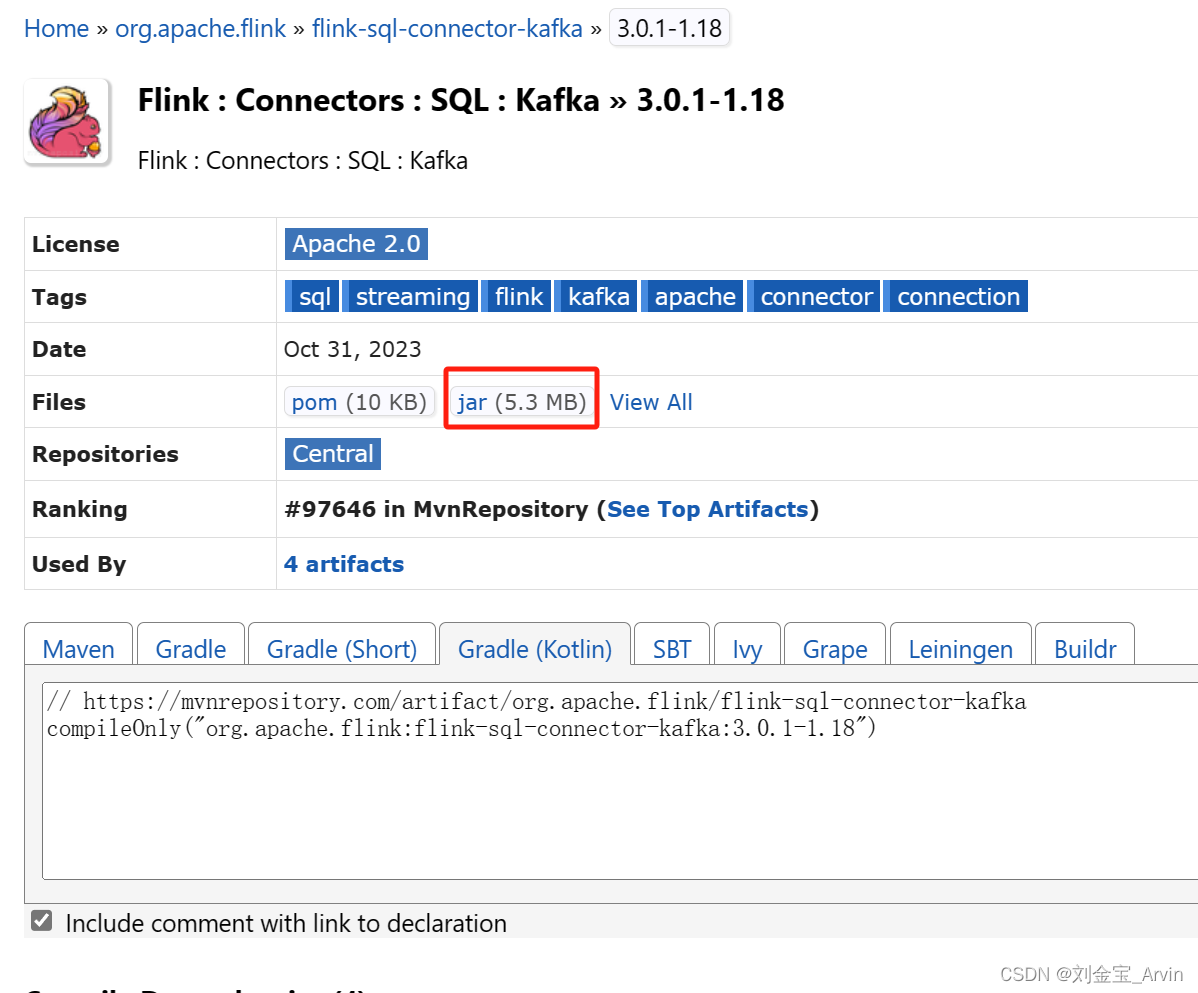
点进去进行下载:
将下载的jar包,分别在jobmanager,taskmanager /opt/flink/lib目录下,注意,是两个都要放,如下图:
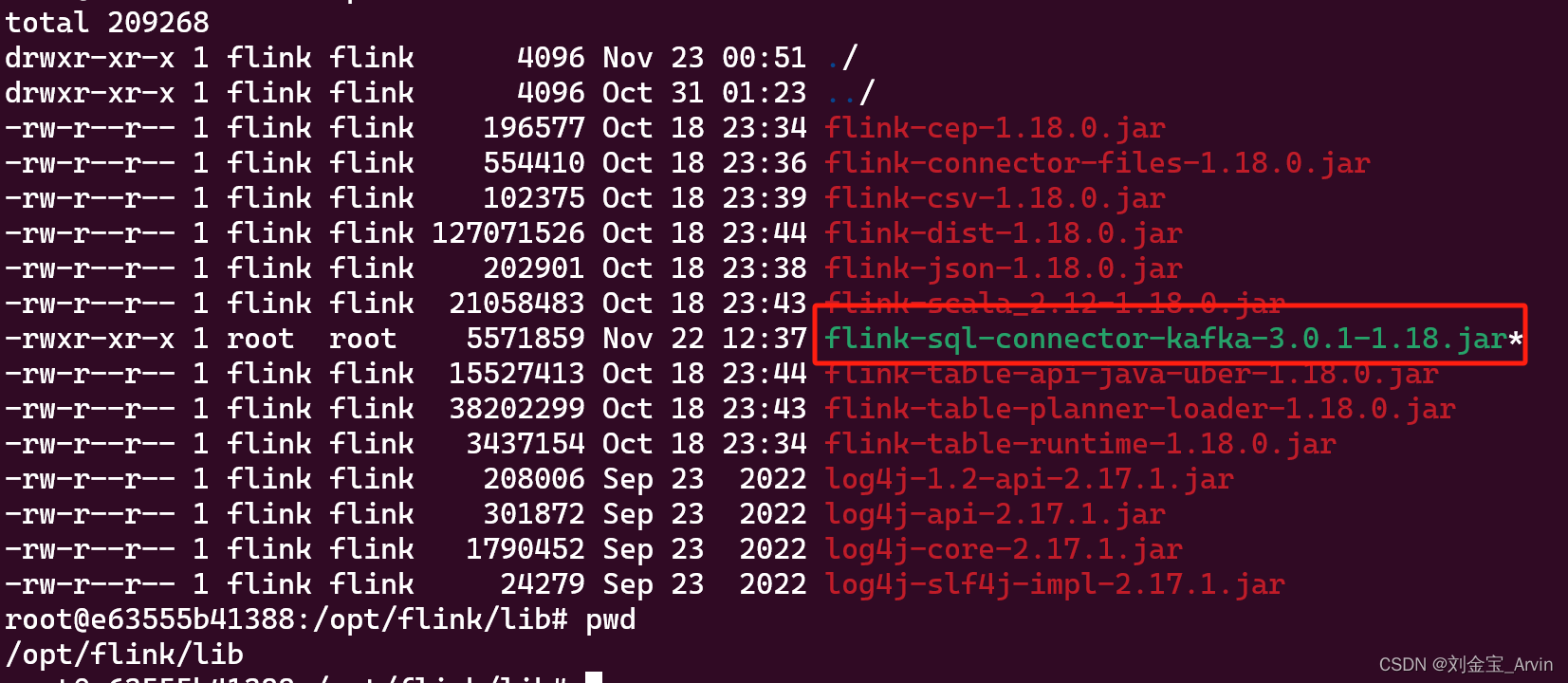
可以使用docker cp test.txt jobmanager:/opt/flink/lib命令,用户宿主机和docker容器文件传输。把test.txt换成对应的jar包即可
5.2 flinksql消费kafka
进入jobmanager中,执行
cd /opt/flink/bin
sql-client.sh
Flink SQL执行以下语句:
CREATE TABLE KafkaTable (
`count_num` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'kafka_demo',
'properties.bootstrap.servers' = '192.168.10.15:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
show tables;
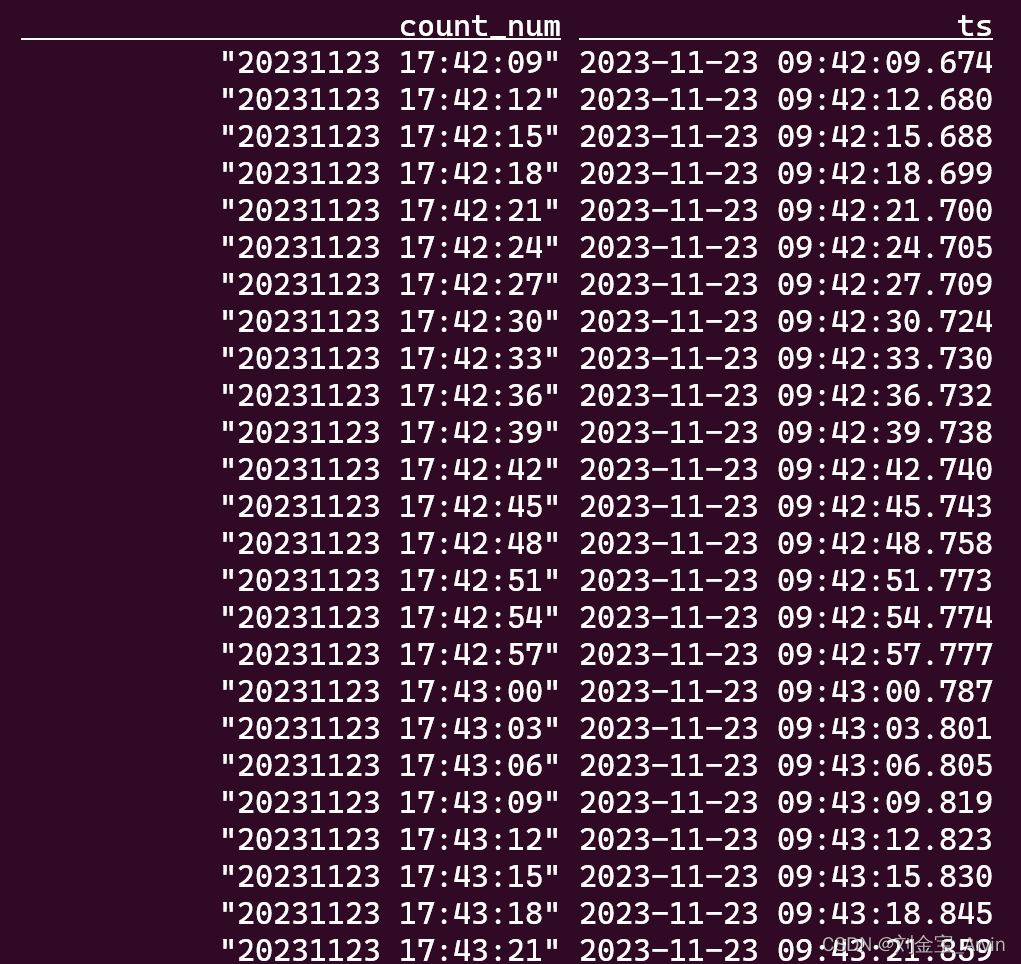
select * from KafkaTable;
可以看到Flink在消费kafka数据,如下图: