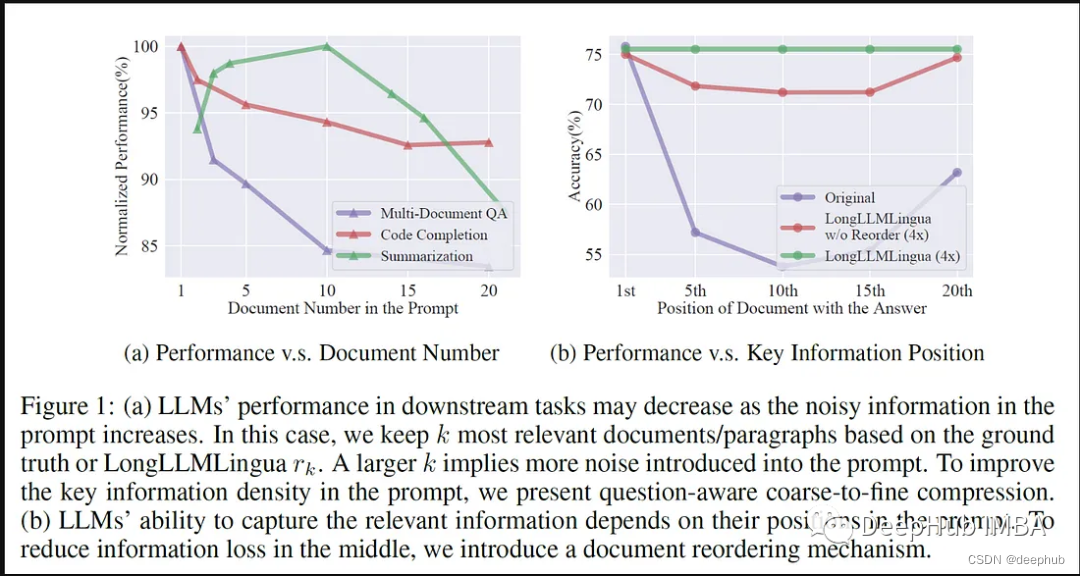
大型语言模型(llm)的出现刺激了多个领域的创新。但是在思维链(CoT)提示和情境学习(ICL)等策略的驱动下,提示的复杂性不断增加,这给计算带来了挑战。这些冗长的提示需要大量的资源来进行推理,因此需要高效的解决方案,本文将介绍LLMLingua与专有的LlamaIndex的进行集成执行高效推理。

LLMLingua是微软的研究人员发布在EMNLP 2023的一篇论文,LongLLMLingua是一种通过快速压缩增强llm在长上下文场景中感知关键信息的能力的方法。
LLMLingua与llamindex的协同工作
LLMLingua作为解决LLM应用程序中冗长提示的开创性解决方案而出现。该方法侧重于压缩冗长提示,同时保证语义完整性和提高推理速度。它结合了各种压缩策略,提供了一种微妙的方法来平衡提示长度和计算效率。
以下是LLMLingua与LlamaIndex集成的优势:
LLMLingua与LlamaIndex的集成标志着llm在快速优化方面迈出了重要的一步。LlamaIndex是一个包含为各种LLM应用程序量身定制的预优化提示的专门的存储库,通过这种集成LLMLingua可以访问丰富的特定于领域的、经过微调的提示,从而增强其提示压缩能力。
LLMLingua的提示压缩技术和LlamaIndex的优化提示库之间的协同作用提高了LLM应用程序的效率。利用LLAMA的专门提示,LLMLingua可以微调其压缩策略,确保保留特定于领域的上下文,同时减少提示长度。这种协作极大地加快了推理速度,同时保留了关键领域的细微差别。
LLMLingua与LlamaIndex的集成扩展了其对大规模LLM应用程序的影响。通过利用LLAMA的专业提示,LLMLingua优化了其压缩技术,减轻了处理冗长提示的计算负担。这种集成不仅加速了推理,而且确保了关键领域特定信息的保留。
LLMLingua与LlamaIndex的工作流程
使用LlamaIndex实现LLMLingua涉及到一个结构化的过程,该过程利用专门的提示库来实现高效的提示压缩和增强的推理速度。
- 框架集成
首先需要在LLMLingua和LlamaIndex之间建立连接。这包括访问权限、API配置和建立连接,以便及时检索。
- 预先优化提示的检索
LlamaIndex充当专门的存储库,包含为各种LLM应用程序量身定制的预优化提示。LLMLingua访问这个存储库,检索特定于域的提示,并利用它们进行提示压缩。
- 提示压缩技术
LLMLingua使用它的提示压缩方法来简化检索到的提示。这些技术专注于压缩冗长的提示,同时确保语义一致性,从而在不影响上下文或相关性的情况下提高推理速度。
- 微调压缩策略
LLMLingua基于从LlamaIndex获得的专门提示来微调其压缩策略。这种细化过程确保保留特定于领域的细微差别,同时有效地减少提示长度。
- 执行与推理
一旦使用LLMLingua的定制策略与LlamaIndex的预优化提示进行压缩,压缩后的提示就可以用于LLM推理任务。此阶段涉及在LLM框架内执行压缩提示,以实现高效的上下文感知推理。
- 迭代改进和增强
代码实现不断地经历迭代的细化。这个过程包括改进压缩算法,优化从LlamaIndex中检索提示,微调集成,确保压缩后的提示和LLM推理的一致性和增强的性能。
- 测试和验证
如果需要还可以进行测试和验证,这样可以评估LLMLingua与LlamaIndex集成的效率和有效性。评估性能指标以确保压缩提示保持语义完整性并在不影响准确性的情况下提高推理速度。
代码实现
下面我们将开始深入研究LLMLingua与LlamaIndex的代码实现
安装程序包:
# Install dependency.
!pip install llmlingua llama-index openai tiktoken -q
# Using the OAI
import openai
openai.api_key = "<insert_openai_key>"
获取数据:
!wget "https://www.dropbox.com/s/f6bmb19xdg0xedm/paul_graham_essay.txt?dl=1" -O paul_graham_essay.txt
加载模型:
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
load_index_from_storage,
StorageContext,
)
# load documents
documents = SimpleDirectoryReader(
input_files=["paul_graham_essay.txt"]
).load_data()
向量存储:
index = VectorStoreIndex.from_documents(documents)
retriever = index.as_retriever(similarity_top_k=10)
question = "Where did the author go for art school?"
# Ground-truth Answer
answer = "RISD"
contexts = retriever.retrieve(question)
contexts = retriever.retrieve(question)
context_list = [n.get_content() for n in contexts]
len(context_list)
#Output
#10
原始提示和返回
# The response from original prompt
from llama_index.llms import OpenAI
llm = OpenAI(model="gpt-3.5-turbo-16k")
prompt = "\n\n".join(context_list + [question])
response = llm.complete(prompt)
print(str(response))
#Output
The author went to the Rhode Island School of Design (RISD) for art school.
设置 LLMLingua
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.response_synthesizers import CompactAndRefine
from llama_index.indices.postprocessor import LongLLMLinguaPostprocessor
node_postprocessor = LongLLMLinguaPostprocessor(
instruction_str="Given the context, please answer the final question",
target_token=300,
rank_method="longllmlingua",
additional_compress_kwargs={
"condition_compare": True,
"condition_in_question": "after",
"context_budget": "+100",
"reorder_context": "sort", # enable document reorder,
"dynamic_context_compression_ratio": 0.3,
},
)
通过LLMLingua进行压缩
retrieved_nodes = retriever.retrieve(question)
synthesizer = CompactAndRefine()
from llama_index.indices.query.schema import QueryBundle
# postprocess (compress), synthesize
new_retrieved_nodes = node_postprocessor.postprocess_nodes(
retrieved_nodes, query_bundle=QueryBundle(query_str=question)
)
original_contexts = "\n\n".join([n.get_content() for n in retrieved_nodes])
compressed_contexts = "\n\n".join([n.get_content() for n in new_retrieved_nodes])
original_tokens = node_postprocessor._llm_lingua.get_token_length(original_contexts)
compressed_tokens = node_postprocessor._llm_lingua.get_token_length(compressed_contexts)
打印2个结果对比:
print(compressed_contexts)
print()
print("Original Tokens:", original_tokens)
print("Compressed Tokens:", compressed_tokens)
print("Comressed Ratio:", f"{original_tokens/(compressed_tokens + 1e-5):.2f}x")
打印的结果如下:
next Rtm's advice hadn' included anything that. I wanted to do something completely different, so I decided I'd paint. I wanted to how good I could get if I focused on it. the day after stopped on YC, I painting. I was rusty and it took a while to get back into shape, but it was at least completely engaging.1]
I wanted to back RISD, was now broke and RISD was very expensive so decided job for a year and return RISD the fall. I got one at Interleaf, which made software for creating documents. You like Microsoft Word? Exactly That was I low end software tends to high. Interleaf still had a few years to live yet. []
the Accademia wasn't, and my money was running out, end year back to the
lot the color class I tookD, but otherwise I was basically myself to do that for in993 I dropped I aroundidence bit then my friend Par did me a big A rent-partment building New York. Did I want it Itt more my place, and York be where the artists. wanted [For when you that ofs you big painting of this type hanging in the apartment of a hedge fund manager, you know he paid millions of dollars for it. That's not always why artists have a signature style, but it's usually why buyers pay a lot for such work. [6]
Original Tokens: 10719
Compressed Tokens: 308
Comressed Ratio: 34.80x
验证输出:
response = synthesizer.synthesize(question, new_retrieved_nodes)
print(str(response))
#Output
#The author went to RISD for art school.
总结
LLMLingua与LlamaIndex的集成证明了协作关系在优化大型语言模型(LLM)应用程序方面的变革潜力。这种协作彻底改变了即时压缩方法和推理效率,为上下文感知、简化的LLM应用程序铺平了道路。
这种集成不仅加快了推理速度,而且确保了在压缩提示中保持语义完整性。基于LlamaIndex特定领域提示的压缩策略微调在提示长度减少和基本上下文保留之间取得了平衡,从而提高了LLM推理的准确性。
从本质上讲,LLMLingua与LlamaIndex的集成超越了传统的提示压缩方法,为未来大型语言模型应用程序的优化、上下文准确和有效地针对不同领域进行定制奠定了基础。这种协作集成预示着大型语言模型应用程序领域中效率和精细化的新时代的到来。
如果你对LLMLingua感兴趣,在线的DMEO,还有论文,源代码等都在可以在这里找到:
https://avoid.overfit.cn/post/0fb3b50283c541d78e4d40c9083b88d9