本文介绍了Depthwise Convolution 的Int8算子在移动端CPU上的性能优化方案。ARM架构的升级和相应指令集的更新不断提高移动端各算子的性能上限,结合数据重排和Sdot指令能给DepthwiseConv量化算子的性能带来较大提升。

背景
MNN对ConvolutionDepthwise Int8量化算子在ARM V8(64位)和ARM V8.2上的性能做了较大的优化,主要优化方法包括改变数据的排列方式以及使用Sdot指令。为了方便叙述,后文统一用DepthwiseConvInt8来表示ConvolutionDepthwiseInt8量化算子。在优化前在安卓手机上测得该量化算子的耗时比使用FP16推理多三倍,严重影响量化模型在端侧的性能。本文从ARM汇编算子的角度出发讲解DepthwiseConvInt8算子的优化方案。

性能瓶颈定位及优化方案
▐ ARM V8 优化数据排列方式
方案介绍
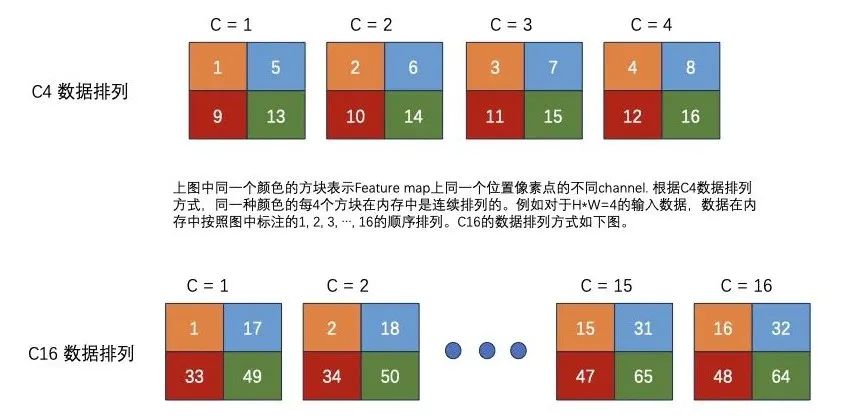
MNN中DepthwiseConvInt8的输入数据格式是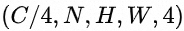 ,后文简称这种数据排列数据方式为C4),即每4个Channel的数据排列在一起。同理,我们用C16表示每16个Channel的数据连续排列的数据排布方式。下图直观地描述了C4的数据排列方式,假设
,后文简称这种数据排列数据方式为C4),即每4个Channel的数据排列在一起。同理,我们用C16表示每16个Channel的数据连续排列的数据排布方式。下图直观地描述了C4的数据排列方式,假设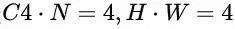 ,图中每一个小正方形代表一个数据,四种颜色分别代表feature map上四个坐标点,正方形内的数字编号
,图中每一个小正方形代表一个数据,四种颜色分别代表feature map上四个坐标点,正方形内的数字编号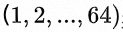 表示它们在内存中的排列次序。
表示它们在内存中的排列次序。
一般地,我们会对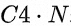 采取多线程计算,对
采取多线程计算,对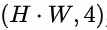 采取ARM汇编并行计算。本文关注单线程时对
采取ARM汇编并行计算。本文关注单线程时对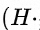 维度做性能优化。在ARM汇编中通常会同时计算输出的特征图上多个点的结果,这要求我们尽量能够同时读取输入特征图上的点数据。例如当Depthwise层的Stride参数等于1时,同时计算输出特征图中4个点坐标的数据(一共4(坐标点)*4(channel)=16个数据),我们需要读取上图中编号为
维度做性能优化。在ARM汇编中通常会同时计算输出的特征图上多个点的结果,这要求我们尽量能够同时读取输入特征图上的点数据。例如当Depthwise层的Stride参数等于1时,同时计算输出特征图中4个点坐标的数据(一共4(坐标点)*4(channel)=16个数据),我们需要读取上图中编号为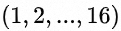 的正方形数据。当每个数据占4个字节(32位)时,4个输入数据正好填满一个向量寄存器。但是在Int8量化算子中,每个输入数据占8位(1个字节),如果仍然采取C4的数据排列,则4个数据填不满一个向量寄存器。特别地,当Depthwise层的Stride参数不是1时,采用C4的数据排列方式会导致feature map上多个数据时不能连续读取,进而导致性能损失。所以对于Int8类型的输入数据,在ARM平台上我们首先考虑将C4的数据排列方式改为C16的排列,这样保证可以连续地读取16个Int8类型数据来填满一个向量寄存器。我们用汇编代码来表示这两种数据读取方式的差异。
的正方形数据。当每个数据占4个字节(32位)时,4个输入数据正好填满一个向量寄存器。但是在Int8量化算子中,每个输入数据占8位(1个字节),如果仍然采取C4的数据排列,则4个数据填不满一个向量寄存器。特别地,当Depthwise层的Stride参数不是1时,采用C4的数据排列方式会导致feature map上多个数据时不能连续读取,进而导致性能损失。所以对于Int8类型的输入数据,在ARM平台上我们首先考虑将C4的数据排列方式改为C16的排列,这样保证可以连续地读取16个Int8类型数据来填满一个向量寄存器。我们用汇编代码来表示这两种数据读取方式的差异。
/* x0: source address, 读取feature map上的4个点 */
/* pack=4, stridex = 2, sizeof(inputData)=1 */
ld1 {v0.s}[0], [x0], #8
ld1 {v1.s}[0], [x0], #8
ld1 {v2.s}[0], [x0], #8
ld1 {v3.s}[0], [x0], #8
/* pack=16, stridex = 2, sizeof(inputData)=1 */
ld1 {v0.4s}, [x0], #32
ld1 {v1.4s}, [x0], #32
ld1 {v2.4s}, [x0], #32
ld1 {v3.4s}, [x0], #32从代码中可以看到同样是使用4条指令读取数据,C16比C4多读取3倍的数据。所以对于ARM V8平台,我们将pack=4更改为pack=16,虽然该方案额外增加了推理时数据排布的转换时间,但是在ARM汇编内部更好地并行化带来的收益更大。
ARM V8 性能提升结果
本文中所有的性能数据均来源于美颜模型在华为Mate40 Pro上的测试结果。美颜模型中一共含有23个Convolution Depthwise算子,所有算子都是3x3 kernel,其中19个算子的stride=1,4个算子的stride=2. 表格中记录的算子耗时是美颜模型中所有23个convolution depthwise算子在一次推理中的耗时总和,单位:ms.
华为 Mate40 Pro ARM V8 | 优化前 C4数据排列 | 优化后 C16数据排列 |
Convolution Depthwise Int8 量化算子 | 4.46 ms | 2.78 ms |
改变数据排列方式的方案性能加速比是1.6.
▐ ARM V8.2 使用sdot指令提高性能
为什么sdot指令能提高算子性能?
虽然在ARM V8平台上DepthwiseConvInt8算子的性能加速已经有明显效果,但ARM V8.2指令集为ARM平台上CPU算子的性能加速提供了更大的空间。与此同时,随着ARM V8.2指令集在旗舰型手机上的普及,浮点模型使用fp16推理极大地提高了移动端性能,量化模型想要保持竞争力也需要进一步优化。在DepthwiseConvInt8算子含有大量乘加计算,以3x3kernel为例,先进行9次乘法再进行1次加法,此时需要9条指令才能得到一个输出数据。ARM V8.2平台提供的sdot指令能实现3条指令即可得到1个输入数据。汇编代码能够直观展示两者差异:
// 3x3kernel 不使用sdot指令,进行9次循环
Loop_Kernel_H3:
Loop_Kernel_W3:
smlal v0.4s, v1.4h, v2.4s // 累加结果存储在v0中
// 3x3kernel 使用sdot指令
sdot v0.4s, v1.16b, v3.16b
sdot v0.4s, v2.16b, v4.16b
smlal v0.4s, v5.4h, v6.4h使用sdot指令会带来额外开销吗?
我们先关注sdot指令是如何加速若干个元素乘加操作的,下面的代码展示了sdot指令计算原理。
// v0.16b : [0,1,2,3, 4,5,6,7, 8,9,10,11, 12,13,14,15]
// v1.16b : [0,1,2,3, 4,5,6,7, 8,9,10,11, 12,13,14,15]
// v2.s[0]=v0.b[0]*v1.b[0]+v0.b[1]*v1.b[1]
// +v0.b[2]*v1.b[2]+v0.b[3]*v1.b[3]
sdot v2.4s, v0.16b, v1.16b // v2.4s: [14,126,366,734]由代码示例得知,进行累加的4个元素在内存中是连续排列的。上文中已经介绍了算子的输入数据排列是C4,同一个Kernel中的所有元素在内存中肯定不能连续读取。
sdot指令的使用之前需要重排数据才能得到正确的结果,注意此时的数据重排和ARM V8优化中的数据重排完全不同。上文中我们提到的ARM V8上的数据重排仅仅是在Channel维度将C4修改为C16,而ARM V8.2上sdot 指令之前的数据重排需要将一个kernel中的9个元素每4个连续排列在一起。我们用一张图来解释重排规则。不妨假设kernel size是3x3,后文中均采取此假设。
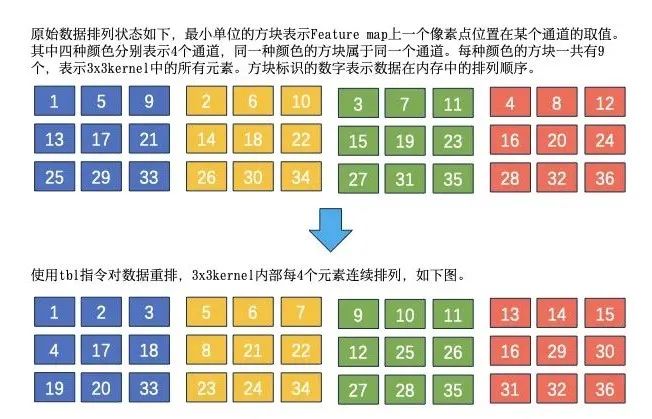
显然数据重排的时间会极大影响算子性能,高效地进行数据重排是ARM V8.2 DepthwiseConvInt8性能优化的关键步骤。
ARM V8.2 如何进行数据重排
思考重排问题时我们将问题简化,不需要写代码就能得到最高效的解决方案(前提是足够熟悉ARM汇编指令,因为指令集了解地越多,解决方法就越多)。我们把问题抽象为如何高效重排一个向量寄存器中的16个int8_t数据。重排前后的数据排列对比图如下:
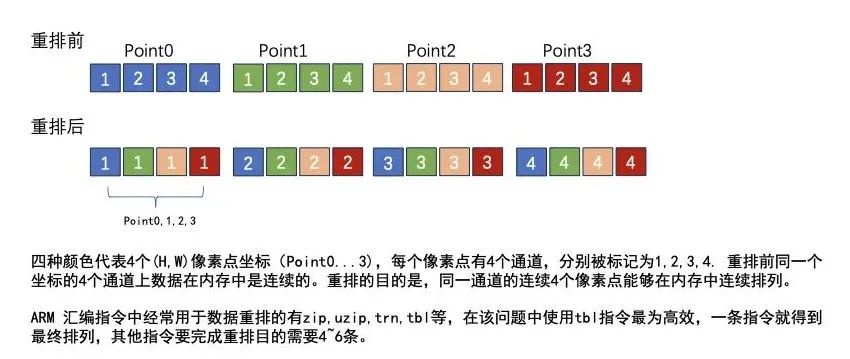
从抽象问题回到对3x3 kernel中的数据进行重排,我们最终需要9个元素相乘再累加,所以我们对kernel中的每4个元素进行重排,剩下的1个再使用smlal指令累加结果即可。当然我们推理前就可以对权值矩阵进行对应元素的重排,不占用推理时间。跟ARM V8上的优化不同的是,ARM V8.2的重排是基于C4进行的而不是C16. 无论是C8还是C16都会给数据重排带来更多的开销,具体来说就是需要的重排指令条数更多,这里就不详细讲解C8和C16场景下的最优重排方案了。
因为数据重排这一步是必不可少的,所以在该算子中使用sdot指令的前提是kernel size是已知的。当前MNN对于DepthwiseConvInt8 在ARM V8.2平台上的优化仅支持3x3 kernel.
ARM V8.2 性能提升结果
华为 Mate40 Pro ARM V8 | 优化前 C4数据排列 | ARM V8使用C16优化后 | ARM V8 使用sdot指令优化后 |
Convolution Depthwise Int8 量化算子 | 4.46 ms | 2.78 ms | 1.75 ms |
通过使用sdot 指令,算子性能加速比达到了2.55.
▐ ARM V8.2和ARM V8的优化方案差异总结
在ARM V8.2 上优化DepthwiseConvInt8算子性能的核心是重排输入数据以方便使用sdot指令进行累加。因为Depthwise算子的计算复杂度比Convolution低,所以数据重排的耗时对算子性能影响更大。经过稿纸推演和实际测试,我们确定了耗时最低的数据重排方案,即在输入数据是NC4HW4时,用tbl指令将与3x3kernel中9个数据分成3组,第一组和第二组分别有4个数据连续排列,最后一个数据单独排列。在ARM V8上的优化受限于指令种类数量,目前仅从减少数据读取时间角度优化算子性能。
▐ 总结
ARM架构的升级和相应指令集的更新不断提高移动端各算子的性能上限,目前在ARM V8.2上对于Convolution depthwise Int8量化算子的性能已经接近最优,但受限于数据重排带来的额外负载,Int8量化算子的性能仍然无法超越半浮点精度推理性能。

团队介绍
大淘宝技术Meta Team,负责面向消费场景的3D/XR基础技术建设和创新应用探索,通过技术和应用创新找到以手机及XR 新设备为载体的消费购物3D/XR新体验。团队在端智能、商品三维重建、3D引擎、XR引擎等方面有深厚的技术积累。先后发布端侧推理引擎MNN,端侧实时视觉算法库PixelAI,商品三维重建工具Object Drawer等技术。团队在OSDI、MLSys、CVPR、ICCV、NeurIPS、TPAMI等顶级学术会议和期刊上发表多篇论文。
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法