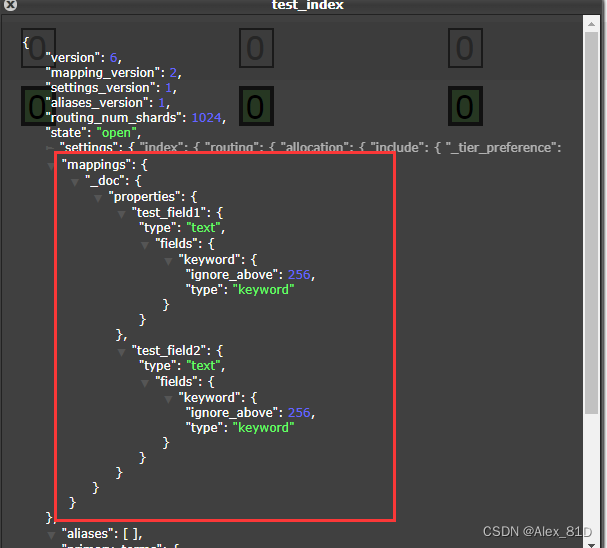
mglru与原lru算法的兼容
旧的lru算法有active与inactive两代lru,可参考linux 内存回收代码注释(未实现多代lru版本)-CSDN博客
新的算法在引入4代lru的同时,还引入了tier的概念。
新旧算法的切换的实现在lru_gen_change_state,当开启mglru时,调用fill_evictable,将active list 与 inactive list 的folio迁移到 mglru上(mglru的组织方式是:lruvec[gen][type][zone]),如果是关闭mglru,则调用drain_evictable,将mglru的folio迁移回active/inactive list两代的情况。
当开启mglru时,原有shrink_node与shrink_lruvec的路径会短路,主要体现在两个地方,对于全局的回收直接调用lru_gen_shrink_node,对于某个memory group 的回收会间接调用lru_gen_shrink_lruvec:
shrink_node
if (lru_gen_enabled() && root_reclaim(sc)) {
lru_gen_shrink_node(pgdat, sc);
return;
}
shrink_lruvec
if (lru_gen_enabled() && !root_reclaim(sc)) {
lru_gen_shrink_lruvec(lruvec, sc);
return;
}真正做页的回收的逻辑还是在shrink_folio_list。
mglru与原lru算法的差别
与旧的lru算法区别,主要有三个方面:1、修改了一次扫描要扫的数量计算逻辑。2、修改了代与代之间转换的逻辑。3、添加了refault页的延迟回收机制
mglru的组织
每个numa node 有一个 pgdat 结构,上面绑定了为每个memory group准备了两代bin list,分别为young bin list和old bin list,第个bin list 上有8个bin,新加入的memory group会随机找一个 bin list 加入(lru_gen_online_memcg)。回收总是在old代上做,找一个bin list,从头扫描到尾。memory group 会随着它分配的内存大小和是否做了回收,在old与young的bin list 头尾上游走。(lru_gen_rotate_memcg),具体而言:
1、memory group 的内存超过 soft limit 时,将它移至同代的开头,下次可能回收它(lru_gen_soft_reclaim,MEMCG_LRU_HEAD)
2、新加入的memory group会放在新代的结尾处,第一次扫描发现页数少于2^priority或是第一次扫描发现页数在low水位线以下时,会放在新代的结尾处(MEMCG_LRU_TAIL)
3、当第一次扫描发现内存在min水位以下,或第二次扫描发现上次扫描是小于2^priority的,或是每次扫描完足够页数时会把最后一个扫描的memory group 移至新代(MEMCG_LRU_YOUNG)。
4、在移除一个memory group时,需要回收全部内存,会把它放在old代(lru_gen_offline_memcg,MEMCG_LRU_OLD)
bin list 中每一项是memory group的lruvec指针。
lruvec内部分成了4代,每代有两个type:文件or匿名,每个type又维护了每个zone上的页框,如下:
// 找一个 group 对应在某个 node 上的lru
lruvec = &memcg->nodeinfo[pgdat->node_id]->lruvec.lrugen;
// 遍历一个 node 上某个 binlist 的 lru
lrugen = pgdat->memcg_lru.fifo[gen][bin];
// lru 内的页框
lrugen->folios[gen][type][zone]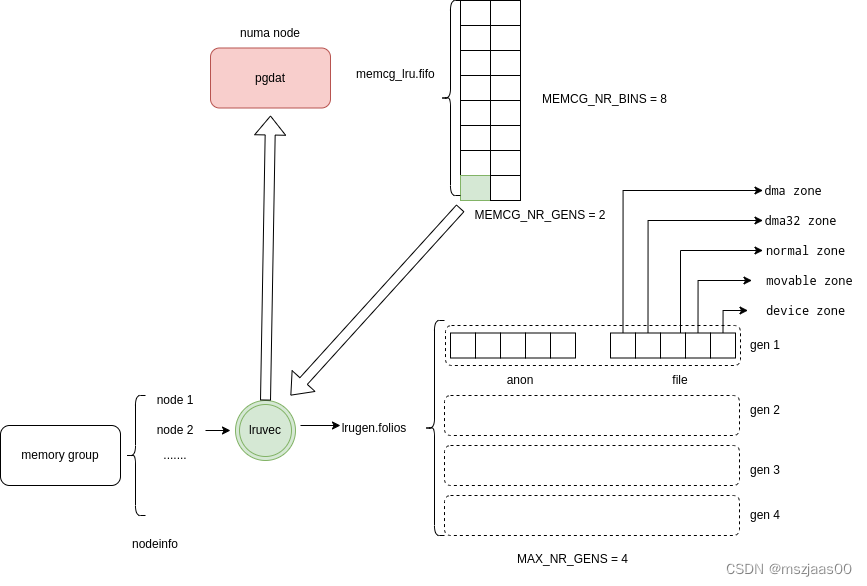
扫描数量
原有的swappiness表示回收匿名页与文件页的加权,取值1~200,值越小越支持从匿名页回收。新算法计算扫描数量的方法变了,只根据swappiness有无赋值来决定要不要计算扫描匿名页的数量,文件页一定会扫描回收。计算的方式也比较粗暴:total >> sc->priority;具体计算逻辑在get_nr_to_scan->should_run_aging。
代际转换
如果在should_run_aging计算时发现最新一代的页框数已经是总页框数的一半,或第三代的页框数小于总页框数的四分之一,就触发一次代际迭换,尝试发现young 页,把它们提升至最新代。代际迭换的代码在try_to_inc_max_seq。
try_to_inc_max_seq():
// 硬件不支持自动标记access flag
if (!should_walk_mmu()) {
iterate_mm_list_nowalk(lruvec, max_seq);
return;
}
// 尝试扫描 hot pmd 中的 young 页。
do {
is_last = iterate_mm_list(lruvec, walk, &mm);
if (mm)
walk_mm(lruvec, mm, walk);
} while (mm);
// 这一代扫描结束,更新代际
if (is_last)
inc_max_seq(lruvec, can_swap, force_scan);如果硬件支持自动在页表记录访问标记,则扫描一遍(扫描的实现在try_to_inc_max_seq->walk_mm->walk_pgd_range->walk_pud_range->walk_pmd_range->walk_pte_range),通过检查bloom filter,找到标记为hot的pmd,访问pmd中全部pte,将标记脏的pte对应页框标记为脏,并更新至最新代。这里说的bloom filter标记了平均每个cacheline中young页数大于1的pmd,只需要对这些pmd的全部pte中young 页的扫描,并标记脏和更新代数,因为这个pmd范围的young页多,是个热点区,意味着后面可能还会产生hot页。如果硬件不支持自动设置访问标记,就不能在这个地方扫了,而要等到建立rmap时,folio_referenced_one->lru_gen_look_around
bloom filter的设置有两个途径,一个是在上面说的扫描全部pte之后,计算young页数/total页数大于cacheline中能装下的pte数(或者说是不是平均每个cacheline都有一个pte项对应了young页,实现在suitable_to_scan);另一个是在shrink_folio_list时,会找一个页框映射的次数(folio_referenced),会调一次lru_gen_look_around,尝试看下这个pte对应的pmd中全部pte,同样是在标记完脏页、统计完young页数时,计算young页数/total页数大于cacheline中能装下的pte数,并把young 标记清掉。
这个过程大概代码如下:
walk_pmd_range():
{
restart:
for pmd_i in start_addr.. end_addr:
// 检查是不是hot pmd
if (!test_bloom_filter(max_seq, pmd_i))
continue;
// 检查hot pmd的所有pte中的脏页,并统计young的页数和清空young标记(young 指最近有访问),计算它还是不是hot pmd
is_still_hot = walk_pte_range(addr, pmd_end_addr);
// 如果是hot的pmd,则在bloom filter 标记一下,下一轮(代)扫描时再检查一次这个pmd
if (is_still_hot)
update_bloom_filter(max_seq + 1, pmd + i);
}
if (i < PTRS_PER_PMD && get_next_vma(PUD_MASK, PMD_SIZE, args, &start, &end))
goto restart;
}
walk_pte_range():
new_gen = lru_gen_from_seq(walk->max_seq);
restart:
for pte_i in start_addr.. end_addr:
{
// 硬件标记pte脏的,但页框没有标记脏,且这是文件页或未换出的匿名页,则在页框上标记下脏
if (pte_dirty(ptent) && !folio_test_dirty(folio) &&
!(folio_test_anon(folio) && folio_test_swapbacked(folio) &&
!folio_test_swapcache(folio)))
folio_mark_dirty(folio);
// 将这一页框更新到最新代
old_gen = folio_update_gen(folio, new_gen);
// 更新统计walk->nr_pages[old_gen][type][zone] 和 walk->nr_pages[new_gen][type][zone]
if (old_gen >= 0 && old_gen != new_gen)
update_batch_size(walk, folio, old_gen, new_gen);
}
if (i < PTRS_PER_PTE && get_next_vma(PMD_MASK, PAGE_SIZE, args, &start, &end))
goto restart;
// 计算young页数/total页数大于cacheline中能装下的pte数(或者说是不是平均每个cacheline都有一个pte项对应了young页)
return suitable_to_scan(total, young);
}Refault页的延迟回收
refault指缺页读入后又换出又读入。mglru引入tier概念,组织形式为lrugen->refaulted[hist][type][tier]。为file 和anon类型的页,维护了4代统计直方图(hist),每个直方图中有4个范围(tier),分别统计了本轮回收中访问了1次,2次,4次,8次的页数。
当触发refault时,会统计累加本轮回收中,已经refault这么多次的页数。(lru_gen_refault)
lru_gen_refault():
// recent 指refault与上次回收在同一代内
recent = lru_gen_test_recent(shadow, type, &lruvec, &token, &workingset);
// 总共有4代histogram,根据当前代数算出它在那个histogram中
hist = lru_hist_from_seq(READ_ONCE(lrugen->min_seq[type]));
// 每代有4个tier,tier的index = log2(本轮扫描中这页的 access 数),即分别为访问1次,2次,4次,8次的tier。
tier = lru_tier_from_refs(refs);
// 统计累加本轮扫描过程中发生 2^tier 次 refault 的页数。
atomic_long_add(delta, &lrugen->refaulted[hist][type][tier]);在决定是否回收页时,evict_folios->isolate_folios,会平衡本轮发生refault 的页数与回收+延时回收页数的比值,计算一个控制值(refaulted/(evicted+protected)),可以理解为发生refault的频繁程度。如果发生n次refault的频繁程度达到了发生1次refault频繁程度的2倍,则发生n次以上refault的页都不再回收。
isolate_folios():
// 计算refault次数超过多少后不再释放
tier_idx = get_tier_idx(lruvec, type);
isolate_folios->scan_folios->sort_folio():
// 本轮扫描中 refault 次数超过2^tier_idx 次的页不再释放,而是推到下一代
if (tier > tier_idx) {
// 将页放在下一次lru尾(回收是从本代的头开始的)
gen = folio_inc_gen(lruvec, folio, false);
list_move_tail(&folio->lru, &lrugen->folios[gen][type][zone]);
// 累加本代中不释放页的页数
int hist = lru_hist_from_seq(lrugen->min_seq[type]);
WRITE_ONCE(lrugen->protected[hist][type][tier - 1],
lrugen->protected[hist][type][tier - 1] + delta);
return true;
}在回收过程中,每完成一次分离出回收页的计算后(isolate_folios),会将这一代的统计值更新为新值与历史值的滑动平均值。
在一轮回收结束时,会调inc_max_seq将下一轮回收的代统计值清空,为最新代的统计留出位置。