非专业任务医生在审查X光片时受益于正确的可解释人工智能建议
01****文献速递介绍
本文主要探讨了人工智能(AI)在放射学中的应用,特别是在胸部X光片的诊断中AI临床决策支持系统(AI-CDSS)的作用。研究发现,尽管AI模型在放射学任务中表现出色,但关于这些产品在实际临床环境中的影响(如医生的诊断性能和患者结果)的研究却很少。研究还指出,用户如何解释和应用AI生成的建议的研究也有限。
为了深入研究,本研究探讨了使AI模型的内部工作和决策标准更透明的方法,比如通过在X光片上提供视觉注释,这可能有助于减轻过度依赖并鼓励适当的信任。此外,研究还比较了在使用AI支持和不使用AI支持的情况下检查图像时的诊断性能。
研究结果表明,对于非专业的IM/EM医生,提供带注释的建议可以提高他们的诊断准确率,而专业的放射科医生则表现得更好。研究还发现,接受AI建议的医生在诊断准确性上表现更好。然而,对于建议的质量评价,无论是AI生成的建议还是来自同事的建议,其影响都不显著。
此外,该研究还探讨了建议的解释性(带注释与不带注释)和建议的来源(AI与人类)对医生信心的影响。结果显示,接收到AI建议的放射科医生在最终诊断上的信心更高,尽管这种信心并没有在诊断准确性上表现出显著差异。
最后,研究指出,AI-CDSS在放射学领域及更广泛的应用中具有潜力,尤其是对于非放射科专家在审查医学图像和做出及时临床决策时,AI-CDSS的应用可能对改善工作流程、临床结果和患者安全具有重要意义。
Title
题目
CheckList for EvaluAtion of Radiomics*
research (CLEAR): a step-by-step reporting
guideline for authors and reviewers endorsed
by ESR and EuSoMII
审阅X光片时,非任务专家的医生从准确可解释的人工智能建议中获益。
Results Analysis.
结果 分析
We calculated three mixed-efects regression models, one for each dependent variable:
(1) diagnostic accuracy, (2) advice quality ratings, and (3) confdence in the diagnosis. Te equations corresponding to the statistical model outputs can be found in the online supplements (https://osf.io/h7aj3/). Te diagnostic accuracy was assessed using a logistic regression model because it was measured as a binary variable (accurate/inaccurate). Linear regression models were applied for the advice quality and the confdence ratings. Each dependent variable was regressed on the explainability of the advice (annotated vs. non-annotated), the source of the advice (AI vs. human), the task expertise (radiologists vs. IM/EM physicians), the interaction between explainability (annotated vs. non-annotated) and source (AI vs. human), and the control variables (professional identifcation, belief in professional autonomy, self-reported AI knowledge, attitude toward AI technology, and years of professional experience). All models included fxed efects for all variables mentioned above and a random efect for the participants to account for non-independence of observations and diferences in their skills, as well as a random efect for the patient cases to account for their diferent difculty levels. Further, we chose mixed-efects regression models because they are particularly useful for analyzing experiments with a repeated measures design. One of the eight cases, which had been taken from the previous study without changes, had no clinical abnormalities (diagnosis: normal) and, consequently, no annotations on the image. A second case was shown without annotations due to a technical issue. Tese two cases had to be excluded from the analysis because the explainability condition could not be unambiguously assigned.
我们计算了三个混合效应回归模型,每个依赖变量一个:
(1)诊断准确性,(2)建议质量评级,(3)对诊断的信心。相应的统计模型输出的方程式可以在在线补充材料中找到(https://osf.io/h7aj3/)。诊断准确性使用逻辑回归模型进行评估,因为它被测量为二元变量(准确/不准确)。对建议质量和信心评级使用线性回归模型。每个依赖变量根据建议的可解释性(带注释vs不带注释)、建议来源(AI vs人类)、任务专业水平(放射科医生vs内科/急诊医生)、可解释性(带注释vs不带注释)和来源(AI vs人类)的交互作用,以及控制变量(专业认同、对专业自主性的信念、自报的AI知识、对AI技术的态度和职业经验年数)进行回归。所有模型都包括上述所有变量的固定效应,以及为了考虑观察结果的非独立性和参与者技能差异而设置的参与者随机效应,以及为了考虑患者病例不同难度水平而设置的病例随机效应。此外,我们选择混合效应回归模型是因为它们特别适用于分析重复测量设计的实验。八个病例中的一个,之前的研究未做更改地采用,没有临床异常(诊断:正常),因此图像上没有注释。由于技术问题,第二个病例未显示注释。由于无法明确分配可解释性条件,这两个病例必须从分析中排除。
Figure
图

Figure 1. Exponential increase in artificial intelligence (AI)-related publications in healthcare.34 A real-time dashboard using natural language pFigure 1. Experimental setup. Every participant reviewed all eight cases. Each case consisted of a brief patient vignette, a chest X-ray, and diagnostic advice (radiologic fndings and primary diagnoses). Te advice came either with or without annotations on the X-ray. Additionally, the advice was labeled as coming either from an AI system or an experienced radiologist. Physicians were asked to give a fnal diagnosis, rate the quality of the advice, and judge how confdent they were with their diagnosis.
图1. 实验设置。每位参与者都审查了所有八个病例。每个病例包括一个简短的病人小结、一张胸部X光片和诊断建议(放射学发现和初步诊断)。建议要么附有X光片上的注释,要么没有。此外,建议被标记为来自AI系统或经验丰富的放射科医生。医生被要求给出最终诊断,评估建议的质量,并判断他们对自己的诊断有多自信。
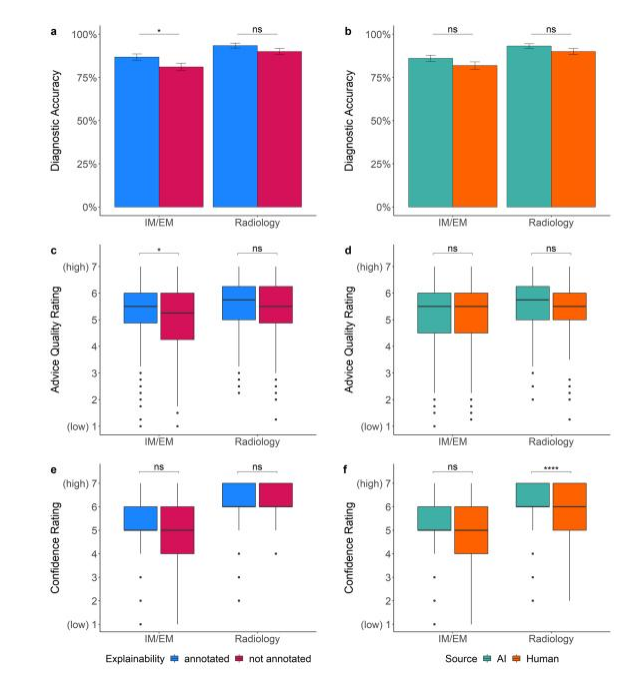
*Figure 2. Dependent variables across the advice manipulations. Te plots show how the advice manipulations afected non-task experts (i.e., IM/EM physicians) and task experts (i.e., radiologists). Plot (a) shows that explainable advice helped non-task experts to be more accurate on average (p(pIM/EM =0.042, pRadiology=0.120). Chart (b) indicates that the source of advice had only statistically non-signifcant efects on diagnostic accuracy (p(pIM/EM =0.129, pRadiology=0.155). Plot © displays that non-task experts rated the quality of annotated advice higher than non-annotated advice (p(pIM/EM =0.011, pRadiology=0.195). In (d), it is shown that there was no evidence that the source of advice had an efect on the quality rating (p(pIM/EM =0.645, pRadiology=0.812).Plot(e) indicates that explainability had little efect on the confdence ratings (p(pIM/EM =0.280, pRadiology=0.202). Finally, (f) f) shows that task experts reported higher confdence in their decision when receiving AI advice while non-task experts’ confdence was unafected by the source (p(pIM/EM =0.497, pRadiology<0.0001). Te boxplots show 25th to 75th percentiles and the median as the central line; the whiskers extend to a maximum of 1.5×interquartile range. Te error bars represent standarderrors.*p≤0.05,**p≤0.01,***p≤0.001,***p≤0.0001,nsstatistically nonsignifcant.
图2. 建议操纵对依赖变量的影响。这些图表展示了建议操纵如何影响非任务专家(即内科/急诊医生)和任务专家(即放射科医生)。图表(a)显示,可解释的建议帮助非任务专家平均更准确(p内科/急诊 = 0.042,p放射科 = 0.120)。图表(b)表明,建议来源对诊断准确性仅有统计上不显著的影响(p内科/急诊 = 0.129,p放射科 = 0.155)。图表(c)显示,非任务专家对带注释建议的质量评级高于不带注释的建议(p内科/急诊 = 0.011,p放射科 = 0.195)。在图表(d)中,显示没有证据表明建议来源对质量评级有影响(p内科/急诊 = 0.645,p放射科 = 0.812)。图表(e)表明,可解释性对信心评级的影响不大(p内科/急诊 = 0.280,p放射科 = 0.202)。最后,图表(f)显示,当接收AI建议时,任务专家在决策中报告更高的信心,而非任务专家的信心不受来源影响(p内科/急诊 = 0.497,p放射科 < 0.0001)。箱形图展示了25至75百分位数,中间线为中位数;胡须最多延伸至1.5×四分位距。误差条表示标准误差。*p ≤ 0.05,**p ≤ 0.01,***p ≤ 0.001,****p ≤ 0.0001,ns 统计上不显著。
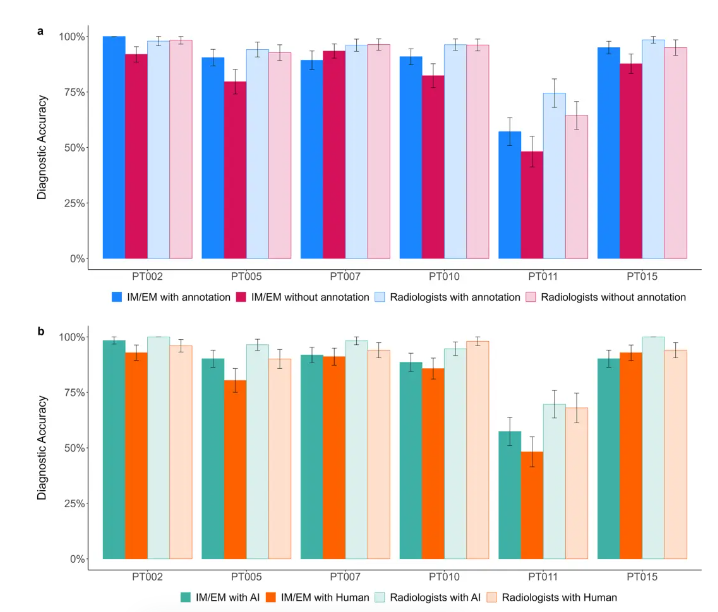
Figure 3. Diagnostic accuracy by clinical case. Case-dependent performance amongst non-task experts (i.e.,IM/EM physicians) and task experts (i.e., radiologists) across the two advice manipulations (a) explainability ofthe advice and (b) source of the advice. Te x-axis labels are the case ID numbers (see online supplements pages2–4 for further information about the cases). Te error bars represent standard errors.
图3. 按临床案例的诊断准确性。非任务专家(即内科/急诊医生)和任务专家(即放射科医生)在两种建议操作(a)建议的可解释性和(b)建议的来源之间的案例依赖性表现。x轴标签是案例ID号(有关案例的更多信息,请参见在线补充材料第2-4页)。误差线代表标准误差。
Table
表
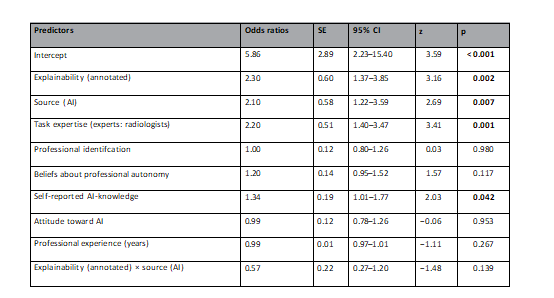
Table 1. Logistic mixed multilevel regression models for participants’ diagnostic accuracy. Random efects: σ2=3.29, τ00 ID =0.60, τ00 PATIENTID =1.10, ICC=0.34, NINID =222, NPNPATIENTID =6, observations=1332, marginal R2=0.086/conditional R2=0.397; OR>1 variable associated with higher odds for correct diagnosis; OR<1 variable associated with lower odds for correct diagnosis, OR=1 variable does not afect odds of outcome. Te intercept indicates that the probability of an accurate diagnosis was 0.85 when all predictors are zero. Predictors without a natural zero point (i.e., professional identifcation, beliefs about professional autonomy, self-reported AI-knowledge, attitude toward AI) were mean-centered. SEstandard error, pprobability of committing a type I error. Statistically signifcant values are in bold.
表1. 参与者诊断准确性的逻辑混合多层回归模型。随机效应:σ2 = 3.29,τ00 ID = 0.60,τ00 PATIENTID = 1.10,ICC = 0.34,NID = 222,NPATIENTID = 6,观察次数 = 1332,边际R2 = 0.086/条件R2 = 0.397;OR > 1的变量与更高的正确诊断概率相关;OR < 1的变量与较低的正确诊断概率相关,OR = 1的变量不影响结果的概率。截距指出,当所有预测因子为零时,准确诊断的概率为0.85。
没有自然零点的预测因子(即专业认同、关于专业自主性的信念、自我报告的AI知识、对AI的态度)进行了均值中心化处理。SE标准误差,p为犯一类错误的概率。统计上显著的值以粗体表示。
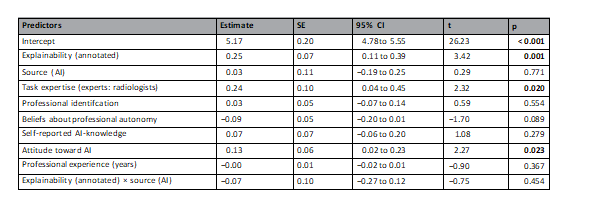
Table 2. Linear mixed multilevel regression models for advice quality rating. Random efects: σ2=0.79, τ00 ID =0.42, τ00 PATIENTID =0.16, ICC=0.42, NINID =222, NPNPATIENTID =6, observations=1332, marginal R2=0.042/conditional R2=0.449. Te regression estimate indicates how much the mean quality rating changes given a one-unit shif in the predictor while holding other predictors in the model constant. Te intercept represents the mean value of the advice quality rating when all predictor variables are zero. Predictors without a natural zero point (i.e., professional identifcation, beliefs about professional autonomy, self-reported AI-knowledge, attitude toward AI) were mean-centered. SEstandard error, pprobability of committing a type I error. Statistically signifcant values are in bold.
表2. 建议质量评级的线性混合多层回归模型。随机效应:σ2 = 0.79,τ00 ID = 0.42,τ00 PATIENTID = 0.16,ICC = 0.42,NID = 222,NPATIENTID = 6,观察次数 = 1332,边际R2 = 0.042/条件R2 = 0.449。回归估计值表示在其他预测因子保持不变的情况下,预测因子每变化一个单位时,平均质量评级的变化量。截距代表了所有预测变量为零时建议质量评级的平均值。没有自然零点的预测因子(即专业认同、关于专业自主性的信念、自我报告的AI知识、对AI的态度)进行了均值中心化处理。SE标准误差,p为犯一类错误的概率。统计上显著的值以粗体表示。
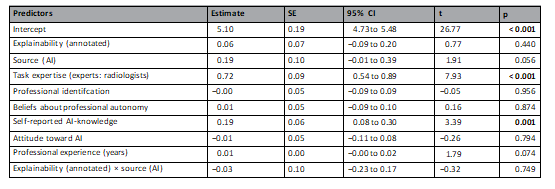
Table 3. Linear mixed multilevel regression models for confdence in the diagnosis. Random efects: σ2=0.85, τ00 ID =0.27, τ00 PATIENTID =0.16, ICC=0.34, N ID =222, N PATIENTID =6, observations=1332, marginal R2=0.130/conditional R2=0.424. Te regression estimate indicates how much the mean confdence rating changes given a one-unit shif in the predictor while holding other predictors in the model constant. Te intercept represents the mean value of the confdence in the diagnosis when all predictor variables are zero. Predictors without a natural zero point (i.e., professional identifcation, beliefs about professional autonomy, self-reported AI-knowledge, attitude toward AI) were mean-centered. SEstandard error, pprobability of committing a type I error. Statistically signifcant values are in bold.
表3. 诊断信心的线性混合多层回归模型。随机效应:σ² = 0.85,τ00 ID = 0.27,τ00 PATIENTID = 0.16,ICC = 0.34,N ID = 222,N PATIENTID = 6,观察数 = 1332,边际 R² = 0.130 / 条件 R² = 0.424。回归估计指出在控制模型中其他预测变量不变的情况下,每增加一个单位预测变量,平均信心评分的变化量。截距表示当所有预测变量为零时,对诊断信心的平均值。没有自然零点的预测变量(例如,专业认同、对专业自主性的看法、自报的人工智能知识、对人工智能的态度)进行了均值中心化。SE 指标准误差,p 指犯第一类错误的概率。统计上显著的数值以粗体显示。
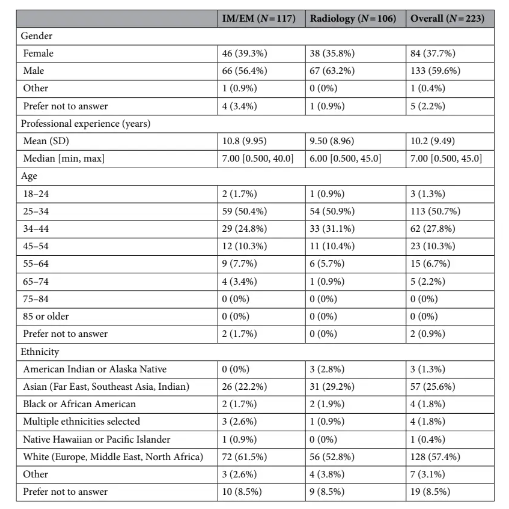
Table4. Participant demographics. IMinternal medicine, EMemergency medicine, Nnumbers of participants.
Table4. Participant demographics. IMinternal medicine, EMemergency medicine, Nnumbers of participants.
表4. 参与者人口统计数据。IM内科,EM急诊医学,N参与者人数。