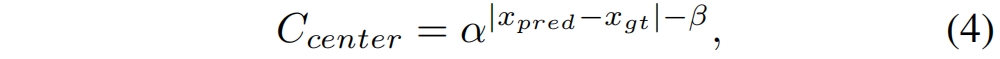NVIDIA在9月20日发布的NVIDIA DRIVE Thor 新一代集中式车载计算平台,可在单个安全、可靠的系统上运行高级驾驶员辅助应用和车载信息娱乐应用。提供 2000 万亿次浮点运算性能(2000 万亿次8位浮点运算)。NVIDIA当代产品是Orin,算力是256 TOPS。再后面是已发布的Altan,算力是1000TFLOPS,这次的Thor算力是2000 TOPS强大的着实让人震惊(但是芯片2025才出来,是时间好像有些远的PPT产品)。
产生一个疑问,这个算力是什么算力?如何计算/标定?
先看三个名词解释:
TFLOPS(teraFLOPS)等于每秒一万亿(=10^12)次的浮点运算。FLOPS(Floating-point operations per second的缩写),即每秒浮点运算次数。
TOPS(Tera Operations Per Second的缩写),1TOPS代表处理器每秒钟可进行一万亿次(10^12)操作。
DMIPS:Dhrystone Million Instructions executed Per Second,每秒执行百万条指令,用来计算同一秒内系统的处理能力,即每秒执行了多少百万条指令。
鉴于NVIDIA的Thor还是个PPT,还没有确切产品资料情况下,我们先看下现有芯片的此种算力。特斯拉FSD(自动驾驶的芯片/区别于智能座舱SOC)。
===============================================
NPU算力
NPU算力。TOPS仅指处理器每秒万亿次操作,需要结合具体数据类型精度才可以于FLOPS转换。8位精度下的MAC(乘积累加运算,MAC/ Multiply Accumulate)数量在FP16(半浮点数/16位浮点数)精度下等于减少了一半。 PS:NVIDIA、Intel和Arm携手合作,共同撰写FP8 Formats for Deep Learning白皮书。目前业界已由32位元降至16位元,如今甚至已转向8位元(FP8精度: 8 位元浮点运算规格),这也是NVIDIA使用FP8来表征算力的原因。NVIDIA上面Thor 2000TOPS也说的是这个东东。
在NPU中,芯片都用MAC阵列(乘积累加运算,MAC/ Multiply Accumulate)作为NPU给神经网络加速,许多运算(如卷积运算、点积运算、矩阵运算、数字滤波器运算、乃至多项式的求值运算)都可以分解为数个MAC指令,因此可以提高上述运算的效率。MAC矩阵是AI芯片的核心,是很成熟的架构。英伟达也在示例中使用3维的立方体计算单元完成矩阵乘加运算。TOPS是MAC在1秒内操作的数,计算公式为:
TOPS = MAC矩阵行 * MAC矩阵列 * 2 * 主频;
PS:公式中的 2 可理解为一个MACC(乘加运算)为一次乘法和一次加法为2次运算操作。下面以特斯拉自动驾驶FSD芯片为例。
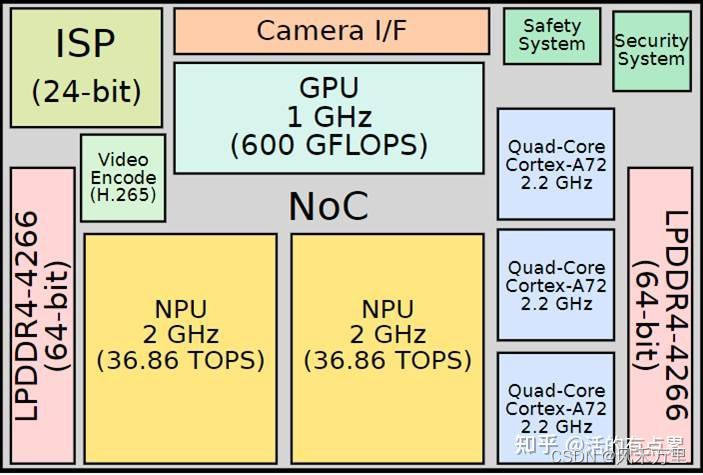
特斯拉资料中,该芯片的目标是自主4级和5级。FSD芯片采用三星(德克萨斯州奥斯汀的工厂)的14纳米工艺技术制造,集成了3个四核Cortex-A72集群,共有12个CPU,工作频率为2.2GHz,1个(ARM的)Mali G71 MP12 GPU,2个NPU工作频率为2GHz,还有其他各种硬件加速器。FSD最多支持128位LPDDR4-4266内存。
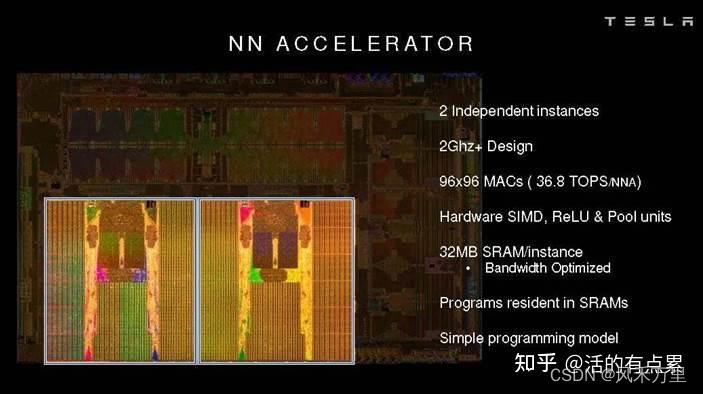
上图右侧第三行清楚的描述到:“ 96*96 MACs(单核)(36.8 TOPS/NNA)”,我们根据最上面计算公式:
TOPS = MAC矩阵行 * MAC矩阵列 * 2 * 主频 = 96 * 96 * 2 * 2G = 36.864 TOPS(单核)
上面结果和如上图片中算力数字匹配,是NPU单核算力。特斯拉FSD(Full Self-Driving) IC 中有2个NPU:每个周期,从SRAM读取256byte字节的激活数据和另外128byte的权重数据到MAC阵列中。每个NPU拥有96x96 MAC,另外在精度方面,乘法为8x8bit,加法为32bit,两种数据类型的选择很大程度上取决于他们降功耗的努力(例如32bitFP加法器的功耗大约是32bit整数加法器的9倍)。如上图,在2GHz的工作频率下,每个NPU的算力为36.86TOPS,FSD芯片峰值算力为73.7TOPS(两个单核NPU算力的累加)。
=====================================================
CPU的算力(ARM内核)
移远通信推出SA8155P平台的SIP模块AG855G,移远官网介绍中描述“AG855G的 AI 综合算力能够达到 8 TOPS”。那CPU算力呢?
高通官网及产品摘要中没有找到对其产品CPU算力的直接数字描述,但是在移远通信描述SA8155P “八核 64 位处理器,1+3+4三丛集架构,算力高达100K DMIPS”(有其他新闻媒体描述其算力为 95 KDMIPS)。加之之前找到的SA8155P 数据如下:
高通2019年发布的智能座舱芯片SA8155P,7nm工艺。CPU架构是Kryo 435(高通自己的命名)8个64位核心,3个丛集(Gold代表大核心,Silver代表小核心)
第1丛集:1×Kryo 435 Gold@2.419GHz
第2丛集:3×Kryo 435 Gold@2.131GHz
第3丛集:4×Kryo 435 Silver@1.785GHz
PS:前两个丛集是基于ARM Cortex-A76架构定制的,第三个丛集是Cortex-A55核心定制。
Graphics: Adreno 640 700MHz
Memory:4x16,2092.8MHz,LPDDR4X with ECC
NPU:NPU130 with ECC 908 MHz
Compute DSP:Q6 V66G (4 threads/2 clusters, 1024KB L2, 4x HVX) with ECC 1.4592 GHz
……
算力数据描述:
GPU计算性能:1.1 TFLOPS
AI(NPU)算力:8 TOPS(每秒运算8万亿次)
CPU算力:100K DMIPS (也有说95K DMIPS的)
这个CPU算力是怎么来的,如下正题:CPU算力计算方式描述(DMIPS:主要测整数计算能力)
以ARM核为主查询,ARM官网中描述,在“The Cortex-M3 RTL is delivered to licensees together with an "example" system testbench for simulation of a simple Cortex-M3 system, and a number of test programs including a Dhrystone test called "dhry". ”描述了DMIPS/MHz的计算方式:
DMIPS/MHz = 10^6 / (1757 * Number of processor clock cycles per Dhrystone loop)
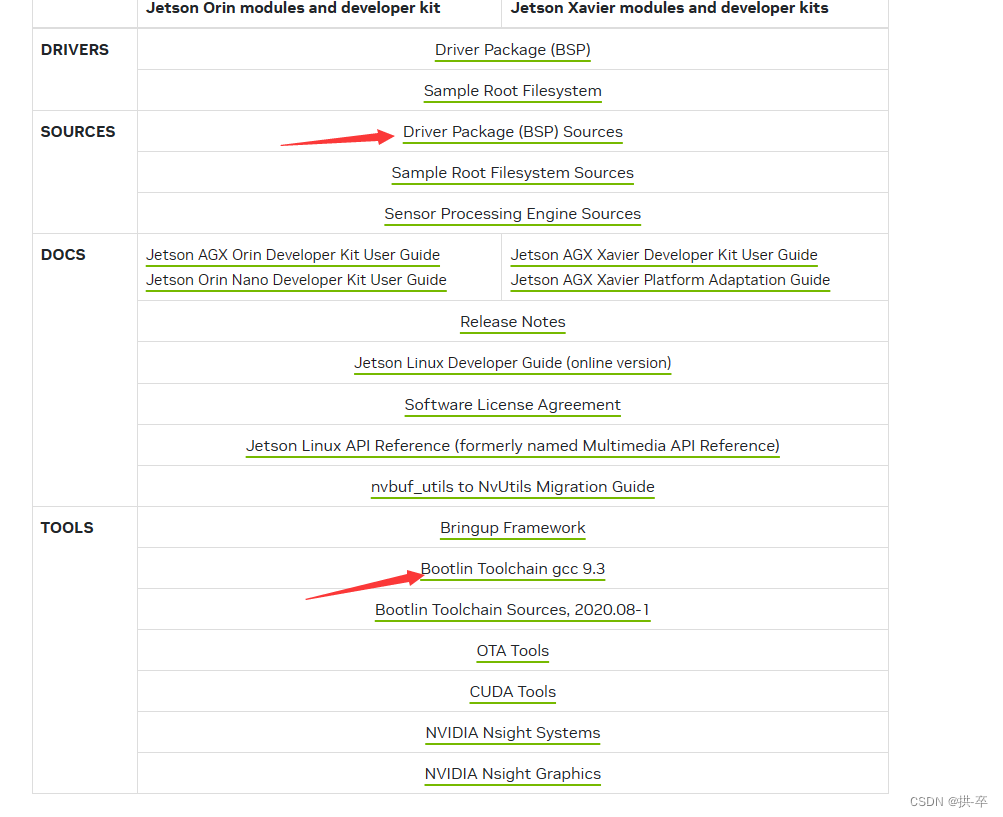
ARM官网中有Cortex-M3和M4的数据(如下截图)

ARM官网网页资料截图
我们可以计算Cortex-M3在Wait-states 0中的DMIPS/MHz是:
DMIPS/MHz = 10^6 / (1757 * 460.2)= 1.2367 ≈ 1.24 DMIPS/MHz
上面计算结果和图片数据对应。在ARM官网未查到有Cortex-A76的DMIPS/MHz数值描述,但查询到在发布Cortex-A76时,ARM首席架构师Filippo强调Cortex-A76架构较上一代(A75)性能至少提升35%,在一些数学运行任务上,新架构处理器可以有 50%—70% 的提升。
网上资料基本都是到Cortex-A75就完了,查询到如下架构的DMIPS/MHz如下:
Arm Cortex-A75 5.2 DMIPS/MHz
Arm Cortex-A73 4.8 DMIPS/MHz
Arm Cortex-A72 4.7 DMIPS/MHz
Arm Cortex-A57 4.1 DMIPS/MHz
Arm Cortex-A55 2.7 DMIPS/MHz
Arm Cortex-A53 2.3 DMIPS/MHz
虽然高通官网及产品摘要中没有找到对其产品CPU算力的直接数字描述,但是结合如上各网络资料,我们视图计算下高通这个SA8155P的真实CPU算力。
SA8155P的CPU算力计算如下(按照A75性能提升50%来计算,即 5.2 * 1.5 = 7.8 DMIPS/MHz )
SA8155P算力 = 2.419GHz * 1核 * 7.8 DMIPS/MHz + 2.131GHz * 3核 * 7.8 DMIPS/MHz + 1.785GHz * 4核 * 2.7 DMIPS/MHz = 18868.2 + 49865.4 + 19278 = 88011.6 DMIPS ≈ 88 KDMIPS
此数值和移远通信公布的100 KDMIPS算力有约12%的误差,但这其实是用ARM的方法计算了下三星的处理器。三星将ARM Cortex-A76内核优化后叫Kryo内核,还有硬件加速器等,猜想是三星对A76的性能优化已超50%性能提升,已到达ARM架构师Filippo(上面说的)所描述的50%-70%性能提升的中位数。另外,存储器读写速度、硬件加速引擎等也都可能直接影响CPU算力表现。
当然,也有可能是如上某些数据、信息或计算还不确切。大家有资料或深入研究的也请指出。
=================================================
GPU算力
…………..后面再写了,下面把NVIDIA的Thor发布的芯片构成信息整理:
在自动驾驶领域,提高驾驶安全性,传感器在数量和分辨率上都面临同步增长。同时也引入了更复杂的AI模型(NVIDIA大致每2年的产品都会有一个质的提升)。安全性是机器人开发的首要准则,要求传感器和算法具备多样性和冗余性。这些都需要更高的数据处理能力。
NVIDIA为实现这个应用了Grace、Hopper和Ada Lovelace。
1. Hopper有令人惊叹的Transformer引擎以及Vision Transformer的快速变革。
2. 在Ada中多实例GPU的发明有助于车载计算资源的集中化,同时也降低了成本。
3. Grace是NVIDIA数据中心处理器。通常所有的并行处理算法都是由GPU卸载和加速的,因此其余的工作负载往往收到单线程的限制,而Grace正好拥有出色的单线程性能。
Thor内部Arm Poseidon AE内核(汽车增强版本)。Thor支持通过NVLink-C2C芯片互联技术连接两个芯片运行单个操作系统(现有很多兴能源汽车厂家将2~4颗Orin处理器集合起来应用来满足算力需求)。
Thor可以配置为多种模式,Thor可以将其 2000 TOPS和 2000 TFLOPs全部用于自动驾驶工作流中,也可以将其配置为一部分用于驾驶舱AI和信息娱乐,一部分用于辅助驾驶。Thor有多计算域隔离,允许并发、对时间敏感的多进程无中断运行。可以在一台计算机上同时运行Linux、QNX和Android。Thor集中了众多计算资源,不仅降低了成本和功耗,同时功能也实现了质的飞跃。

NVIDIA Thor PCBA板卡
提前3年发布,也真是难为NVIDIA了,给一众跟随的 IC 厂商指明了前进的方向。