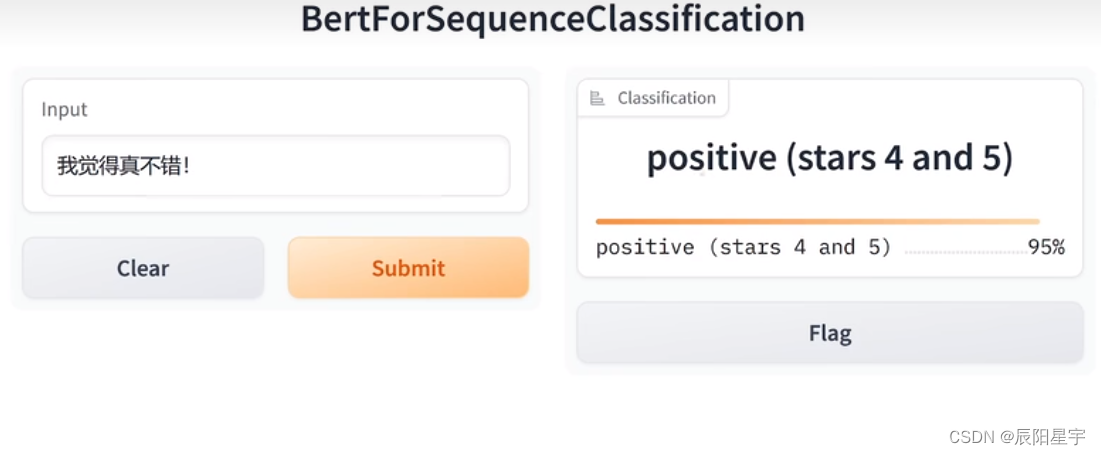
一、Transformer基础知识




pip install transformers datasets evaluate peft accelerate gradio optimum sentencepiece
pip install jupyterlab scikit-learn pandas matplotlib tensorboard nltk rouge
在host文件里添加途中信息,可以避免运行代码下载模型时候报错。

Transformers测试
#导入gradio
import gradio as gr
#导入transformersi相关包
from transformers import *
#通过Interface)加载pipeline并启动文本分类服务
gr.Interface.from_pipeline(pipeline("text-classification", model="uer/roberta-base-finetuned-dianping-chinese")).launch()
1、基础组件——pipeline
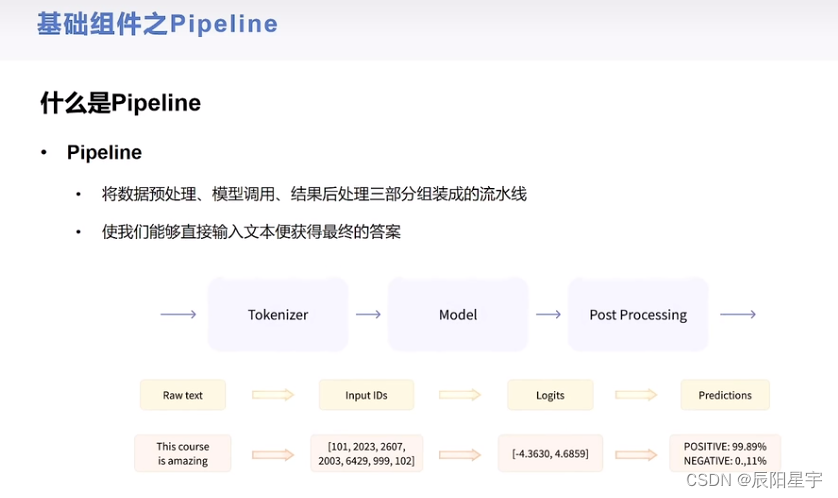

导入包
from transformers.pipelines import SUPPORTED_TASKS
查看pipeline支持的任务类型
# 查看SUPPORTED_TASK所有可支持的任务
print(SUPPORTED_TASKS.items())
dict_items([('audio-classification', {'impl': <class 'transformers.pipelines.audio_classification.AudioClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForAudioClassification'>,), 'default': {'model': {'pt': ('superb/wav2vec2-base-superb-ks', '372e048')}}, 'type': 'audio'}), ('automatic-speech-recognition', {'impl': <class 'transformers.pipelines.automatic_speech_recognition.AutomaticSpeechRecognitionPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForCTC'>, <class 'transformers.models.auto.modeling_auto.AutoModelForSpeechSeq2Seq'>), 'default': {'model': {'pt': ('facebook/wav2vec2-base-960h', '55bb623')}}, 'type': 'multimodal'}), ('text-to-audio', {'impl': <class 'transformers.pipelines.text_to_audio.TextToAudioPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForTextToWaveform'>, <class 'transformers.models.auto.modeling_auto.AutoModelForTextToSpectrogram'>), 'default': {'model': {'pt': ('suno/bark-small', '645cfba')}}, 'type': 'text'}), ('feature-extraction', {'impl': <class 'transformers.pipelines.feature_extraction.FeatureExtractionPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModel'>,), 'default': {'model': {'pt': ('distilbert-base-cased', '935ac13'), 'tf': ('distilbert-base-cased', '935ac13')}}, 'type': 'multimodal'}), ('text-classification', {'impl': <class 'transformers.pipelines.text_classification.TextClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForSequenceClassification'>,), 'default': {'model': {'pt': ('distilbert-base-uncased-finetuned-sst-2-english', 'af0f99b'), 'tf': ('distilbert-base-uncased-finetuned-sst-2-english', 'af0f99b')}}, 'type': 'text'}), ('token-classification', {'impl': <class 'transformers.pipelines.token_classification.TokenClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForTokenClassification'>,), 'default': {'model': {'pt': ('dbmdz/bert-large-cased-finetuned-conll03-english', 'f2482bf'), 'tf': ('dbmdz/bert-large-cased-finetuned-conll03-english', 'f2482bf')}}, 'type': 'text'}), ('question-answering', {'impl': <class 'transformers.pipelines.question_answering.QuestionAnsweringPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForQuestionAnswering'>,), 'default': {'model': {'pt': ('distilbert-base-cased-distilled-squad', '626af31'), 'tf': ('distilbert-base-cased-distilled-squad', '626af31')}}, 'type': 'text'}), ('table-question-answering', {'impl': <class 'transformers.pipelines.table_question_answering.TableQuestionAnsweringPipeline'>, 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForTableQuestionAnswering'>,), 'tf': (), 'default': {'model': {'pt': ('google/tapas-base-finetuned-wtq', '69ceee2'), 'tf': ('google/tapas-base-finetuned-wtq', '69ceee2')}}, 'type': 'text'}), ('visual-question-answering', {'impl': <class 'transformers.pipelines.visual_question_answering.VisualQuestionAnsweringPipeline'>, 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForVisualQuestionAnswering'>,), 'tf': (), 'default': {'model': {'pt': ('dandelin/vilt-b32-finetuned-vqa', '4355f59')}}, 'type': 'multimodal'}), ('document-question-answering', {'impl': <class 'transformers.pipelines.document_question_answering.DocumentQuestionAnsweringPipeline'>, 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForDocumentQuestionAnswering'>,), 'tf': (), 'default': {'model': {'pt': ('impira/layoutlm-document-qa', '52e01b3')}}, 'type': 'multimodal'}), ('fill-mask', {'impl': <class 'transformers.pipelines.fill_mask.FillMaskPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForMaskedLM'>,), 'default': {'model': {'pt': ('distilroberta-base', 'ec58a5b'), 'tf': ('distilroberta-base', 'ec58a5b')}}, 'type': 'text'}), ('summarization', {'impl': <class 'transformers.pipelines.text2text_generation.SummarizationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForSeq2SeqLM'>,), 'default': {'model': {'pt': ('sshleifer/distilbart-cnn-12-6', 'a4f8f3e'), 'tf': ('t5-small', 'd769bba')}}, 'type': 'text'}), ('translation', {'impl': <class 'transformers.pipelines.text2text_generation.TranslationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForSeq2SeqLM'>,), 'default': {('en', 'fr'): {'model': {'pt': ('t5-base', '686f1db'), 'tf': ('t5-base', '686f1db')}}, ('en', 'de'): {'model': {'pt': ('t5-base', '686f1db'), 'tf': ('t5-base', '686f1db')}}, ('en', 'ro'): {'model': {'pt': ('t5-base', '686f1db'), 'tf': ('t5-base', '686f1db')}}}, 'type': 'text'}), ('text2text-generation', {'impl': <class 'transformers.pipelines.text2text_generation.Text2TextGenerationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForSeq2SeqLM'>,), 'default': {'model': {'pt': ('t5-base', '686f1db'), 'tf': ('t5-base', '686f1db')}}, 'type': 'text'}), ('text-generation', {'impl': <class 'transformers.pipelines.text_generation.TextGenerationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForCausalLM'>,), 'default': {'model': {'pt': ('gpt2', '6c0e608'), 'tf': ('gpt2', '6c0e608')}}, 'type': 'text'}), ('zero-shot-classification', {'impl': <class 'transformers.pipelines.zero_shot_classification.ZeroShotClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForSequenceClassification'>,), 'default': {'model': {'pt': ('facebook/bart-large-mnli', 'c626438'), 'tf': ('roberta-large-mnli', '130fb28')}, 'config': {'pt': ('facebook/bart-large-mnli', 'c626438'), 'tf': ('roberta-large-mnli', '130fb28')}}, 'type': 'text'}), ('zero-shot-image-classification', {'impl': <class 'transformers.pipelines.zero_shot_image_classification.ZeroShotImageClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForZeroShotImageClassification'>,), 'default': {'model': {'pt': ('openai/clip-vit-base-patch32', 'f4881ba'), 'tf': ('openai/clip-vit-base-patch32', 'f4881ba')}}, 'type': 'multimodal'}), ('zero-shot-audio-classification', {'impl': <class 'transformers.pipelines.zero_shot_audio_classification.ZeroShotAudioClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModel'>,), 'default': {'model': {'pt': ('laion/clap-htsat-fused', '973b6e5')}}, 'type': 'multimodal'}), ('conversational', {'impl': <class 'transformers.pipelines.conversational.ConversationalPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForSeq2SeqLM'>, <class 'transformers.models.auto.modeling_auto.AutoModelForCausalLM'>), 'default': {'model': {'pt': ('microsoft/DialoGPT-medium', '8bada3b'), 'tf': ('microsoft/DialoGPT-medium', '8bada3b')}}, 'type': 'text'}), ('image-classification', {'impl': <class 'transformers.pipelines.image_classification.ImageClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForImageClassification'>,), 'default': {'model': {'pt': ('google/vit-base-patch16-224', '5dca96d'), 'tf': ('google/vit-base-patch16-224', '5dca96d')}}, 'type': 'image'}), ('image-segmentation', {'impl': <class 'transformers.pipelines.image_segmentation.ImageSegmentationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForImageSegmentation'>, <class 'transformers.models.auto.modeling_auto.AutoModelForSemanticSegmentation'>), 'default': {'model': {'pt': ('facebook/detr-resnet-50-panoptic', 'fc15262')}}, 'type': 'multimodal'}), ('image-to-text', {'impl': <class 'transformers.pipelines.image_to_text.ImageToTextPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForVision2Seq'>,), 'default': {'model': {'pt': ('ydshieh/vit-gpt2-coco-en', '65636df'), 'tf': ('ydshieh/vit-gpt2-coco-en', '65636df')}}, 'type': 'multimodal'}), ('object-detection', {'impl': <class 'transformers.pipelines.object_detection.ObjectDetectionPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForObjectDetection'>,), 'default': {'model': {'pt': ('facebook/detr-resnet-50', '2729413')}}, 'type': 'multimodal'}), ('zero-shot-object-detection', {'impl': <class 'transformers.pipelines.zero_shot_object_detection.ZeroShotObjectDetectionPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForZeroShotObjectDetection'>,), 'default': {'model': {'pt': ('google/owlvit-base-patch32', '17740e1')}}, 'type': 'multimodal'}), ('depth-estimation', {'impl': <class 'transformers.pipelines.depth_estimation.DepthEstimationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForDepthEstimation'>,), 'default': {'model': {'pt': ('Intel/dpt-large', 'e93beec')}}, 'type': 'image'}), ('video-classification', {'impl': <class 'transformers.pipelines.video_classification.VideoClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForVideoClassification'>,), 'default': {'model': {'pt': ('MCG-NJU/videomae-base-finetuned-kinetics', '4800870')}}, 'type': 'video'}), ('mask-generation', {'impl': <class 'transformers.pipelines.mask_generation.MaskGenerationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForMaskGeneration'>,), 'default': {'model': {'pt': ('facebook/sam-vit-huge', '997b15')}}, 'type': 'multimodal'}), ('image-to-image', {'impl': <class 'transformers.pipelines.image_to_image.ImageToImagePipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForImageToImage'>,), 'default': {'model': {'pt': ('caidas/swin2SR-classical-sr-x2-64', '4aaedcb')}}, 'type': 'image'})])
查看pipeline都支持哪些任务和实现
for k, v in SUPPORTED_TASKS.items():
print(k, v) # k:任务名称,v:任务的实现。tf:tensorflow模型,pt:pytorch模型
audio-classification {'impl': <class 'transformers.pipelines.audio_classification.AudioClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForAudioClassification'>,), 'default': {'model': {'pt': ('superb/wav2vec2-base-superb-ks', '372e048')}}, 'type': 'audio'}
automatic-speech-recognition {'impl': <class 'transformers.pipelines.automatic_speech_recognition.AutomaticSpeechRecognitionPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForCTC'>, <class 'transformers.models.auto.modeling_auto.AutoModelForSpeechSeq2Seq'>), 'default': {'model': {'pt': ('facebook/wav2vec2-base-960h', '55bb623')}}, 'type': 'multimodal'}
text-to-audio {'impl': <class 'transformers.pipelines.text_to_audio.TextToAudioPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForTextToWaveform'>, <class 'transformers.models.auto.modeling_auto.AutoModelForTextToSpectrogram'>), 'default': {'model': {'pt': ('suno/bark-small', '645cfba')}}, 'type': 'text'}
feature-extraction {'impl': <class 'transformers.pipelines.feature_extraction.FeatureExtractionPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModel'>,), 'default': {'model': {'pt': ('distilbert-base-cased', '935ac13'), 'tf': ('distilbert-base-cased', '935ac13')}}, 'type': 'multimodal'}
text-classification {'impl': <class 'transformers.pipelines.text_classification.TextClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForSequenceClassification'>,), 'default': {'model': {'pt': ('distilbert-base-uncased-finetuned-sst-2-english', 'af0f99b'), 'tf': ('distilbert-base-uncased-finetuned-sst-2-english', 'af0f99b')}}, 'type': 'text'}
token-classification {'impl': <class 'transformers.pipelines.token_classification.TokenClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForTokenClassification'>,), 'default': {'model': {'pt': ('dbmdz/bert-large-cased-finetuned-conll03-english', 'f2482bf'), 'tf': ('dbmdz/bert-large-cased-finetuned-conll03-english', 'f2482bf')}}, 'type': 'text'}
question-answering {'impl': <class 'transformers.pipelines.question_answering.QuestionAnsweringPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForQuestionAnswering'>,), 'default': {'model': {'pt': ('distilbert-base-cased-distilled-squad', '626af31'), 'tf': ('distilbert-base-cased-distilled-squad', '626af31')}}, 'type': 'text'}
table-question-answering {'impl': <class 'transformers.pipelines.table_question_answering.TableQuestionAnsweringPipeline'>, 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForTableQuestionAnswering'>,), 'tf': (), 'default': {'model': {'pt': ('google/tapas-base-finetuned-wtq', '69ceee2'), 'tf': ('google/tapas-base-finetuned-wtq', '69ceee2')}}, 'type': 'text'}
visual-question-answering {'impl': <class 'transformers.pipelines.visual_question_answering.VisualQuestionAnsweringPipeline'>, 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForVisualQuestionAnswering'>,), 'tf': (), 'default': {'model': {'pt': ('dandelin/vilt-b32-finetuned-vqa', '4355f59')}}, 'type': 'multimodal'}
document-question-answering {'impl': <class 'transformers.pipelines.document_question_answering.DocumentQuestionAnsweringPipeline'>, 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForDocumentQuestionAnswering'>,), 'tf': (), 'default': {'model': {'pt': ('impira/layoutlm-document-qa', '52e01b3')}}, 'type': 'multimodal'}
fill-mask {'impl': <class 'transformers.pipelines.fill_mask.FillMaskPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForMaskedLM'>,), 'default': {'model': {'pt': ('distilroberta-base', 'ec58a5b'), 'tf': ('distilroberta-base', 'ec58a5b')}}, 'type': 'text'}
summarization {'impl': <class 'transformers.pipelines.text2text_generation.SummarizationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForSeq2SeqLM'>,), 'default': {'model': {'pt': ('sshleifer/distilbart-cnn-12-6', 'a4f8f3e'), 'tf': ('t5-small', 'd769bba')}}, 'type': 'text'}
translation {'impl': <class 'transformers.pipelines.text2text_generation.TranslationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForSeq2SeqLM'>,), 'default': {('en', 'fr'): {'model': {'pt': ('t5-base', '686f1db'), 'tf': ('t5-base', '686f1db')}}, ('en', 'de'): {'model': {'pt': ('t5-base', '686f1db'), 'tf': ('t5-base', '686f1db')}}, ('en', 'ro'): {'model': {'pt': ('t5-base', '686f1db'), 'tf': ('t5-base', '686f1db')}}}, 'type': 'text'}
text2text-generation {'impl': <class 'transformers.pipelines.text2text_generation.Text2TextGenerationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForSeq2SeqLM'>,), 'default': {'model': {'pt': ('t5-base', '686f1db'), 'tf': ('t5-base', '686f1db')}}, 'type': 'text'}
text-generation {'impl': <class 'transformers.pipelines.text_generation.TextGenerationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForCausalLM'>,), 'default': {'model': {'pt': ('gpt2', '6c0e608'), 'tf': ('gpt2', '6c0e608')}}, 'type': 'text'}
zero-shot-classification {'impl': <class 'transformers.pipelines.zero_shot_classification.ZeroShotClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForSequenceClassification'>,), 'default': {'model': {'pt': ('facebook/bart-large-mnli', 'c626438'), 'tf': ('roberta-large-mnli', '130fb28')}, 'config': {'pt': ('facebook/bart-large-mnli', 'c626438'), 'tf': ('roberta-large-mnli', '130fb28')}}, 'type': 'text'}
zero-shot-image-classification {'impl': <class 'transformers.pipelines.zero_shot_image_classification.ZeroShotImageClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForZeroShotImageClassification'>,), 'default': {'model': {'pt': ('openai/clip-vit-base-patch32', 'f4881ba'), 'tf': ('openai/clip-vit-base-patch32', 'f4881ba')}}, 'type': 'multimodal'}
zero-shot-audio-classification {'impl': <class 'transformers.pipelines.zero_shot_audio_classification.ZeroShotAudioClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModel'>,), 'default': {'model': {'pt': ('laion/clap-htsat-fused', '973b6e5')}}, 'type': 'multimodal'}
conversational {'impl': <class 'transformers.pipelines.conversational.ConversationalPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForSeq2SeqLM'>, <class 'transformers.models.auto.modeling_auto.AutoModelForCausalLM'>), 'default': {'model': {'pt': ('microsoft/DialoGPT-medium', '8bada3b'), 'tf': ('microsoft/DialoGPT-medium', '8bada3b')}}, 'type': 'text'}
image-classification {'impl': <class 'transformers.pipelines.image_classification.ImageClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForImageClassification'>,), 'default': {'model': {'pt': ('google/vit-base-patch16-224', '5dca96d'), 'tf': ('google/vit-base-patch16-224', '5dca96d')}}, 'type': 'image'}
image-segmentation {'impl': <class 'transformers.pipelines.image_segmentation.ImageSegmentationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForImageSegmentation'>, <class 'transformers.models.auto.modeling_auto.AutoModelForSemanticSegmentation'>), 'default': {'model': {'pt': ('facebook/detr-resnet-50-panoptic', 'fc15262')}}, 'type': 'multimodal'}
image-to-text {'impl': <class 'transformers.pipelines.image_to_text.ImageToTextPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForVision2Seq'>,), 'default': {'model': {'pt': ('ydshieh/vit-gpt2-coco-en', '65636df'), 'tf': ('ydshieh/vit-gpt2-coco-en', '65636df')}}, 'type': 'multimodal'}
object-detection {'impl': <class 'transformers.pipelines.object_detection.ObjectDetectionPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForObjectDetection'>,), 'default': {'model': {'pt': ('facebook/detr-resnet-50', '2729413')}}, 'type': 'multimodal'}
zero-shot-object-detection {'impl': <class 'transformers.pipelines.zero_shot_object_detection.ZeroShotObjectDetectionPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForZeroShotObjectDetection'>,), 'default': {'model': {'pt': ('google/owlvit-base-patch32', '17740e1')}}, 'type': 'multimodal'}
depth-estimation {'impl': <class 'transformers.pipelines.depth_estimation.DepthEstimationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForDepthEstimation'>,), 'default': {'model': {'pt': ('Intel/dpt-large', 'e93beec')}}, 'type': 'image'}
video-classification {'impl': <class 'transformers.pipelines.video_classification.VideoClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForVideoClassification'>,), 'default': {'model': {'pt': ('MCG-NJU/videomae-base-finetuned-kinetics', '4800870')}}, 'type': 'video'}
mask-generation {'impl': <class 'transformers.pipelines.mask_generation.MaskGenerationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForMaskGeneration'>,), 'default': {'model': {'pt': ('facebook/sam-vit-huge', '997b15')}}, 'type': 'multimodal'}
image-to-image {'impl': <class 'transformers.pipelines.image_to_image.ImageToImagePipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForImageToImage'>,), 'default': {'model': {'pt': ('caidas/swin2SR-classical-sr-x2-64', '4aaedcb')}}, 'type': 'image'}

导入包
from transformers import pipeline
根据任务类型直接创建pipeline,默认都是英文模型
加载模型
pipe = pipeline("text-classification", model="./model/distilbert-base-uncased-finetuned-sst-2-english")
测试分类效果
pipe(["very good!", "vary bad!", "not bad", "just so so", "oh, damn!"])
[{'label': 'POSITIVE', 'score': 0.9998525381088257},
{'label': 'NEGATIVE', 'score': 0.9991207718849182},
{'label': 'POSITIVE', 'score': 0.9995881915092468},
{'label': 'POSITIVE', 'score': 0.9887603521347046},
{'label': 'NEGATIVE', 'score': 0.5632225871086121}]

推理测试
from transformers import *
# 这种方式,必须同时指定model和tokenizer
model = AutoModelForSequenceClassification.from_pretrained("uer/roberta-base-finetuned-dianping-chinese")
tokenizer = AutoTokenizer.from_pretrained("uer/roberta-base-finetuned-dianping-chinese")
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer, device_map="auto") # GPU自动分配
Model config DistilBertConfig {
"_name_or_path": "model/roberta-base-finetuned-dianping-chinese",
"activation": "gelu",
"architectures": [
"DistilBertForSequenceClassification"
],
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"finetuning_task": "sst-2",
"hidden_dim": 3072,
"id2label": {
"0": "NEGATIVE",
"1": "POSITIVE"
},
"initializer_range": 0.02,
"label2id": {
"NEGATIVE": 0,
"POSITIVE": 1
},
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
...
"transformers_version": "4.35.2",
"vocab_size": 30522
}
测试效果
pipe(["我觉得不太行!", "一般般", "还凑合吧", "太强了!"])
[{'label': 'NEGATIVE', 'score': 0.5539911389350891},
{'label': 'POSITIVE', 'score': 0.5317790508270264},
{'label': 'NEGATIVE', 'score': 0.5028885006904602},
{'label': 'POSITIVE', 'score': 0.8547790050506592}]
速度测试
import torch
import time
times = []
for i in range(100):
torch.cuda.synchronize()
start = time.time()
pipe("我觉得不太行!")
torch.cuda.synchronize()
end = time.time()
times.append(end - start)
print(sum(times) / 100)
0.01336388111114502
当想用知道怎么使用某个库时候,可以先实例化这个库,然后再查看对应信息去查找。
例如
qa_pipe = pipeline("question-answering", model="model/robert-base-chinese-extractive-qa")
输入qa_pipe查看pipline
qa_pipe
<transformers.pipelines.question_answering.QuestionAnsweringPipeline at 0x7f40c65a75e0>
再在代码界面上输入QuestionAnsweringPipeline,按住Ctrl进去查看示例,查看__call___方法
QuestionAnsweringPipeline
测试
# question是问题,context是让模型根据context内容抽取可以回答问题的答案
qa_pipe(question="中国的首都是哪里?", context="北京是中国的政治和文化中心,上海是中国的经济中心")
{'score': 0.00011347973486408591, 'start': 0, 'end': 2, 'answer': '北京'}
设置输出答案字长度
qa_pipe(question="中国的首都是哪里?", context="中国的首都是北京", max_answer_len=1)
{'score': 0.0022874099668115377, 'start': 6, 'end': 7, 'answer': '北'}
解析pipline背后的实现过程
先初始化tokenizer和model
from transformers import *
import torch
tokenizer = AutoTokenizer.from_pretrained("model/roberta-base-finetuned-dianping-chinese")
model = AutoModelForSequenceClassification.from_pretrained("model/roberta-base-finetuned-dianping-chinese")
Model config DistilBertConfig {
"_name_or_path": "model/roberta-base-finetuned-dianping-chinese",
"activation": "gelu",
"architectures": [
"DistilBertForSequenceClassification"
],
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"finetuning_task": "sst-2",
"hidden_dim": 3072,
"id2label": {
"0": "NEGATIVE",
"1": "POSITIVE"
},
"initializer_range": 0.02,
"label2id": {
"NEGATIVE": 0,
"POSITIVE": 1
},
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
...
All model checkpoint weights were used when initializing DistilBertForSequenceClassification.
输入文本并进行token化
input_text = "我觉得不太行!"
inputs = tokenizer(input_text, return_tensors="pt")
inputs
{'input_ids': tensor([[ 101, 1855, 100, 100, 1744, 1812, 1945, 1986, 102]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1]])}
将inputs输入model
res = model(**inputs)
res
SequenceClassifierOutput(loss=None, logits=tensor([[2.1696e-01, 1.5108e-04]], grad_fn=<AddmmBackward0>), hidden_states=None, attentions=None)
模型训练后,对最终全连接层的输出(logits)的最后一个维度进行归一化
logits = res.logits
logits = torch.softmax(logits, dim=-1) # 对最后一个维度进行归一化
logits
tensor([[0.5540, 0.4460]], grad_fn=<SoftmaxBackward0>)
根据最后一层的输出结果,找到概率最大的类别作为最终输出
pred = torch.argmax(logits).item() # 通过取概率最大值对应类的下表,取对应的类别
pred
0
查看一下0索引对应的类别
model.config.id2label # model config里的id2label有的对应的类别信息
{0: 'NEGATIVE', 1: 'POSITIVE'}
输出最终结果
result = model.config.id2label.get(pred)
result