文章来源:公众号ID-布博士(擎创科技资深产品专家)
哈喽~上期内容我们分享了传统调用链系统与CMDB系统的缺陷、服务所有权模型是什么、服务所有权模型分类。这期我们来说一说如何落地服务所有权模型,以及好用的模型推荐,希望对正在阅读的你有所帮助。
新来的朋友看这里,一键回看上期精彩内容
应急处置中排障的降本增效方法探索(上)
话不多说,我们继续往下看
一、如何逐步落地服务所有权模型?
1.构建原则
-
需从实际应用的视角来构建服务所有权模型,而不需要等待调用链和cmdb全部构建完善再应用。
-
鼓励运维工程师在变更完成之后自行更新服务所有权模型,边应用边治理。
-
每个服务所有者构建自己的服务模型。
-
构建者必须弄清楚服务模型所支持和依赖的服务是什么,而无需知道整个依赖关系的全貌。(如库存API的服务构建者必须知道自己所依赖的“mysql - 库存”和“Redis - 缓存“服务,支持”订单API“服务,但不必知道谁支撑订单API和依赖谁。)
-
每个服务所有者都构建完成自己的上下游依赖关系之后,则会构建完成整个服务所有权模型。
-
针对有错或缺失的部分,可以边应用边调整。
-
无须一次性完美构建,持续优化即可。

2.构建步骤
(1):明确业务服务和技术服务以及他们之间的依赖关系
首先要定义清晰的业务服务和技术服务边界,以及自己所运维的技术服务支持哪些业务服务。
●业务服务:直接面向最终客户的服务,如,网上购物商城服务,这是直接面向最终消费者的。
●技术服务:是为支持某项业务服务而搭建的应用系统或微服务(现代的微服务架构),如web服务向用户提供了商品目录浏览、下单等能力,基于tomcat的应用服务为web服务提供了业务处理的能力,而数据库服务为应用服务提供了数据持久会存储的能力。
●依赖关系:是指服务(包括业务服务和技术技术)之间的相互依赖关系,通过依赖关系的构建可以形成完整的服务所有权模型。
通常建议服务所有者先在纸上构建一个草图,明确自己所管理的服务边界以及所依赖和支持的服务有哪些,然后再着手构建服务所有权模型。

(2):确认服务所有权
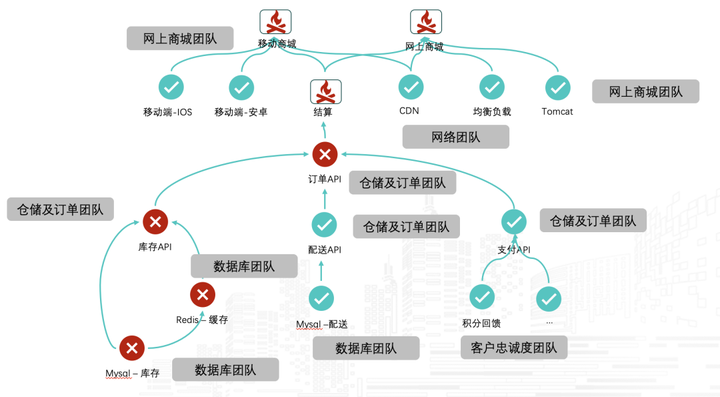
如上图所示,确保每一个服务都有具体的管理团队为其提供开发、运维,这样当发生事件或应急时可以有将的将告警路由到不同的团队进行处理,并可以促进团队之间的相互协作。
传统的应用系统是以应用为视角来进行管理的,为了更好地了解应用的架构,以及出现故障时,可以有效地构建应用系统的可视化架构拓扑,建议对整个应用系统进行架构上的拆分。建议如下:
①.应用系统所支持的业务,拆分为业务服务,这样当系统或相应的组件发生问题时,可以清晰的感知对潜在业务的影响。
②.构成应用系统的各组件,拆分为技术服务,如一套应用系统包括web集群、应用集群、数据库集群、数据库依赖存储等,可以拆分为web服务、应用服务、数据库服务、存储服务,这样可以有效的构建系统的可视化架构拓扑,而无须依赖cmdb完善之后才能构建。

(3):构建服务拓扑以及依赖关系
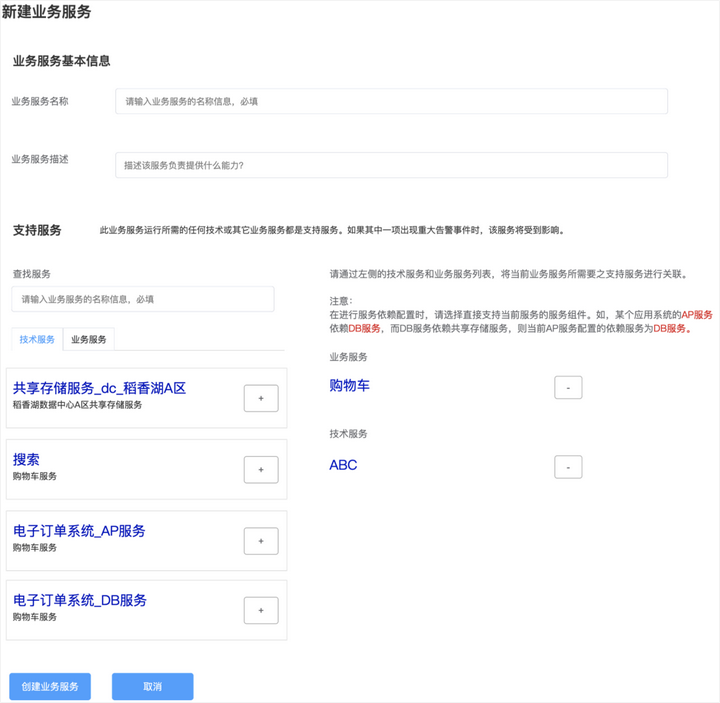
针对以上 1、2 步中手绘的服务拓扑关系,可以着手构建服务,如上图所示。一个业务服务创建过程,需要输入业务服务的基本信息,然后再从已有的服务列表中选择支持该业务服务的技术服务或业务服务。
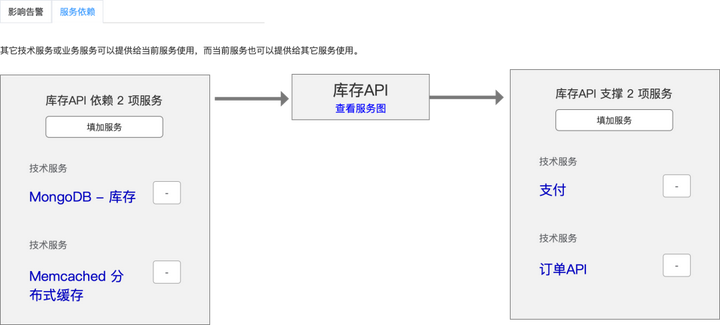
服务配置完成之后,后续也可以对服务进行依赖关系的修改,如下图所示,可以对库存API所依赖的服务和所支撑的服务进行修改。
(4):告警绑定服务
要在服务拓扑上清晰地展示每个服务状态以及是否发生故障,就需要将告警绑定到服务上,实践中可以有两种绑定方式:
1.对告警进行服务规则路由:针对这种方式在告警进入系统时要么通过丰富策略丰富对应的服务信息,要么根据其它辅助字段,如所属业务系统、告警对象类型(db主机、应用服务器等)关键字段,建立基于规则的路由策略。
2.事前构建服务依赖资源表:当服务创建时,运维人员清晰地知道该服务所使用的资源列表,如上图所示的电子商务平台中”redis-缓存“集群,使用了192.168.1.1和192.168.1.2两个主机,这样当告警对象名称为192.168.1.1和192.168.1.2时,会自动路由到该服务上。
在日常运维处理中,方式2在我看来会更合理。只是对系统进行扩缩容时,运维管理团队要主动维护这些变更内容,则后续的告警才会进行有效的服务绑定。
(5):持续优化和改进
服务所有权模型及拓扑依赖关系的构建不是一次性的,是一个长期治理和更正的过程,在使用的过程中会越来越趋近完善。使用的人越多,从服务所有权模型中所得到的回馈也就越多。更重要的是它仅仅通过简单管理的手段即可完美替代调用链、cmdb两套系统的价值。

二、好用的模型存储推荐及计算方案
建议用关系数据库和图数据库两种存储方案:关系数据库做服务节点、节点之间关系的存储。
进行可视化展示、根因分析推荐、相似故障识别算法、服务节点链接关系推荐、影响分析等这些建议采用图数据库来完成,因为其提供了比关系数据库更好的图查找、遍历、计算的方法,主要包括:
1.图搜索算法
包括广度优先搜索(BFS)和深度优先搜索(DFS),用于在图中查找特定的节点或路径。
2.最短路径算法
例如Dijkstra算法和Floyd-Warshall算法,用于找到两个节点之间的最短路径。
3.最小生成树算法
例如Prim算法和Kruskal算法,用于找到连接所有节点的最小生成树。

4.图聚类算法
如K-means算法和谱聚类算法,用于将图中的节点划分为不同的聚类。
5.PageRank算法
用于评估网页的重要性,并根据链接关系进行排名。
6.社区发现算法
例如Louvain算法和标签传播算法,用于识别图中的社区结构。
7.图神经网络
一种基于深度学习的方法,用于处理图数据的节点分类、链接预测等问题。
请注意,这只是一些常见的图计算方法,还有许多其他方法和算法可用于处理不同类型的图数据。

三、总结
本次内容主要跟大家分享了下如何在事件及应急场景下低成本且高效地构建排障拓扑,加速排障过程。通过服务所有权模型,可以清晰地了解业务服务和技术服务之间的依赖关系,促进团队协作,加速排障过程,并实现可视化根因分析。
在一步步落地服务所有权模型的构建过程,包括明确业务服务和技术服务之间的依赖关系、确认服务所有权、构建服务拓扑以及依赖关系、告警绑定服务的过程中,我们对服务模型有了进一步了解,明白持续优化和改进的重要性。

希望本次对构建服务所有权模型知识点的分享,可以让大家更好地管理和理解服务的架构,从而提高团队的协作效率和快速响应能力。
最后再次感谢大家阅读,觉得有用的话可以顺手赞一下,收到鼓励的楼主会很开心的~
![]()

擎创科技,Gartner连续推荐的AIOps领域标杆供应商。公司专注于通过提升企业客户对运维数据的洞见能力,为运维降本增效,充分体现科技运维对业务运营的影响力。
行业龙头客户的共同选择

了解更多运维干货与行业前沿动态
可以右上角一键关注
我们是深耕智能运维领域近十年的
连续多年获Gartner推荐的AIOps标杆供应商
下期我们不见不散~