LangChain系列文章
- LangChain 实现给动物取名字,
- LangChain 2模块化prompt template并用streamlit生成网站 实现给动物取名字
- LangChain 3使用Agent访问Wikipedia和llm-math计算狗的平均年龄
- LangChain 4用向量数据库Faiss存储,读取YouTube的视频文本搜索Indexes for information retrieve
- LangChain 5易速鲜花内部问答系统
- LangChain 6根据图片生成推广文案HuggingFace中的image-caption模型
- LangChain 7 文本模型TextLangChain和聊天模型ChatLangChain
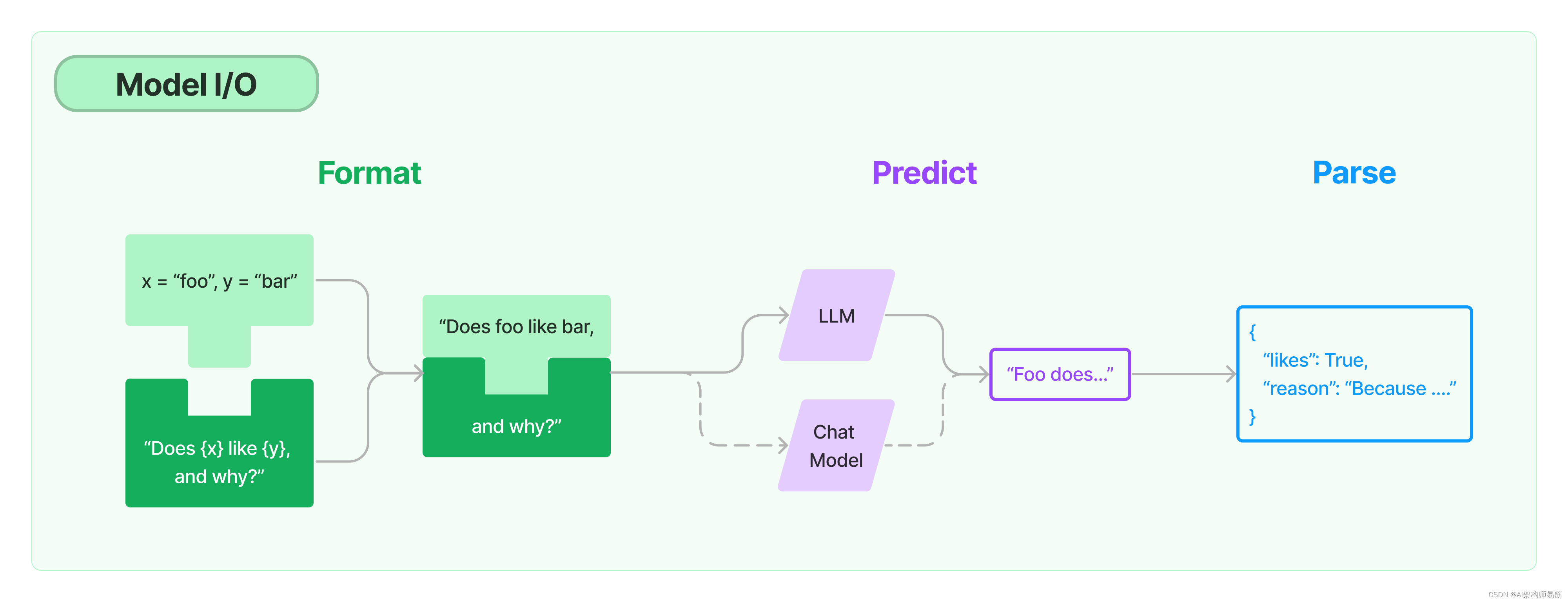
任何语言模型应用的核心要素是…模型。LangChain为您提供了与任何语言模型进行接口的构建块。
- Prompts提示:模板化,动态选择和管理模型输入
- Chat models聊天模型:由语言模型支持,但接受聊天消息列表作为输入并返回聊天消息的模型
- LLMs:接受文本字符串作为输入并返回文本字符串的模型
- Output parsers输出解析器:从模型输出中提取信息
1. Model I/O 的template以及批量运用
这段代码演示了如何使用一个预定义的文案模板,结合OpenAI的GPT-3模型,为不同的水果和它们的价格生成吸引人的描述。以下是对代码的逐行注释和解释model_io_for_loop.py:
(代码为黄佳老师的课程Demo,如需要知道代码细节请读原文)
# 导入Langchain库中的OpenAI模块,该模块提供了与OpenAI语言模型交互的功能
from langchain.llms import OpenAI
# 导入Langchain库中的PromptTemplate模块,用于创建和管理提示模板
from langchain.prompts import PromptTemplate
# 导入Langchain库中的LLMChain模块,它允许构建基于大型语言模型的处理链
from langchain.chains import LLMChain
# 导入dotenv库,用于从.env文件加载环境变量,这对于管理敏感数据如API密钥很有用
from dotenv import load_dotenv
# 调用load_dotenv函数来加载.env文件中的环境变量
load_dotenv()
# 定义一个文案模板,用于生成关于水果的描述。
# {price} 和 {fruit_name} 是占位符,稍后将被具体的价格和水果名称替换。
template = """您是一位专业的水果店文案撰写员。\n
对于售价为 {price} 元的 {fruit_name} ,您能提供一个吸引人的简短描述吗?
"""
# 使用PromptTemplate类的from_template方法创建一个基于上述模板的prompt对象。
# 这个对象可以用来格式化具体的水果名称和价格。
prompt = PromptTemplate.from_template(template)
print(prompt)
# 使用OpenAI类创建一个名为llm的实例。
# 这个实例配置了用于生成文本的模型参数:"text-davinci-003"是一个高级的GPT-3模型。
# temperature设置为0.5,用于控制生成文本的随机性和创造性。
# max_tokens设置为60,用于限制生成文本的最大长度。
llm = OpenAI(
model="text-davinci-003",
temperature=0.5,
max_tokens=60
)
# 定义两个列表:fruits包含不同的水果名称,prices包含相应的价格。
fruits = ["葡萄", "草莓", "樱桃"]
prices = ["10", "20", "30"]
# 使用zip函数将fruits和prices中的元素配对,并在每一对元素上迭代。
for fruit, price in zip(fruits, prices):
# 使用format方法和prompt模板生成具体的输入文本。
# 这里将占位符替换为具体的水果名称和价格。
input_prompt = prompt.format(price=price, fruit_name=fruit)
# 使用llm实例生成文案描述。
response = llm(input_prompt)
# 打印生成的文案描述。
print(response)
这里LLM也可以替换为别的,比如HuggingFaceHub
os.environ['HUGGINGFACEHUB_API_TOKEN'] = 'HUGGINGFACEHUB API Token'
# 导入LangChain中的OpenAI模型接口
from langchain import HuggingFaceHub
# 创建模型实例
llm= HuggingFaceHub(repo_id="google/flan-t5-large")
运行结果
zgpeaces-MBP at ~/Workspace/LLM/langchain-llm-app ±(feature/textAndChat) ✗ ❯ python model_io_for_loop.py
input_variables=['fruit_name', 'price'] template='您是一位专业的水果店文案撰写员。\n\n对于售价为 {price} 元的 {fruit_name} ,您能提供一个吸引人的简短描述吗?\n'
「精选葡萄,香甜多汁,仅 10 元,让你尝遍天下美味!」
草莓:甜美多汁,满口芬芳,令人回味无穷,20元即可
精选樱桃,甜蜜爽口,香甜可口,仅售30元!
2. Model I/O 输出解析
这段代码展示了如何使用Langchain库和OpenAI的GPT-3模型来生成关于水果的描述文案,并将生成的结果结构化存储在一个Pandas DataFrame中。下面是对代码的详细注释和解释:
# 导入Langchain库中的OpenAI模块,该模块提供了与OpenAI语言模型交互的功能
from langchain.llms import OpenAI
# 导入Langchain库中的PromptTemplate模块,用于创建和管理提示模板
from langchain.prompts import PromptTemplate
# 导入Langchain库中的LLMChain模块,它允许构建基于大型语言模型的处理链
from langchain.chains import LLMChain
# 导入dotenv库,用于从.env文件加载环境变量,这对于管理敏感数据如API密钥很有用
from dotenv import load_dotenv
# 调用load_dotenv函数来加载.env文件中的环境变量
load_dotenv()
# 定义一个文案模板,用于生成关于水果的描述。
# {price} 和 {fruit_name} 是占位符,稍后将被具体的价格和水果名称替换。
# {format_instructions} 是用于结构化输出的指令。
template = """您是一位专业的水果店文案撰写员。
对于售价为 {price} 元的 {fruit_name} ,您能提供一个吸引人的简短描述吗?
{format_instructions}
"""
# 使用PromptTemplate类的from_template方法创建一个基于上述模板的prompt对象。
# 这个对象可以用来格式化具体的水果名称和价格。
prompt = PromptTemplate.from_template(template)
print(prompt)
# 使用OpenAI类创建一个名为llm的实例。
# 配置使用"text-davinci-003"模型,设置温度为0.5,最大令牌数为120。
llm = OpenAI(
model="text-davinci-003",
temperature=0.5,
max_tokens=120
)
# 定义水果名称和对应价格的列表。
fruits = ["葡萄", "草莓", "樱桃"]
prices = ["10", "20", "30"]
# 导入Langchain库中的StructuredOutputParser和ResponseSchema,
# 用于解析和结构化AI模型的输出。
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
response_schemas = [
ResponseSchema(name="description", description="水果的描述文案"),
ResponseSchema(name="reason", description="为什么要这样写这个文案")
]
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
prompt = PromptTemplate.from_template(template, partial_variables={"format_instructions": format_instructions})
# 创建一个Pandas DataFrame来存储结果。
import pandas as pd
df = pd.DataFrame(columns=["fruit", "price", "description", "reason"])
# 使用zip函数将水果名称和价格配对,并迭代每一对元素。
for fruit, price in zip(fruits, prices):
# 使用format方法和prompt模板生成输入文本,替换占位符。
input_prompt = prompt.format(price=price, fruit_name=fruit)
# 使用llm实例生成文案描述。
response = llm(input_prompt)
# 解析输出并添加到DataFrame。
parsed_output = output_parser.parse(response)
parsed_output['fruit'] = fruit
parsed_output['price'] = price
df.loc[len(df)] = parsed_output
# 打印DataFrame的内容。
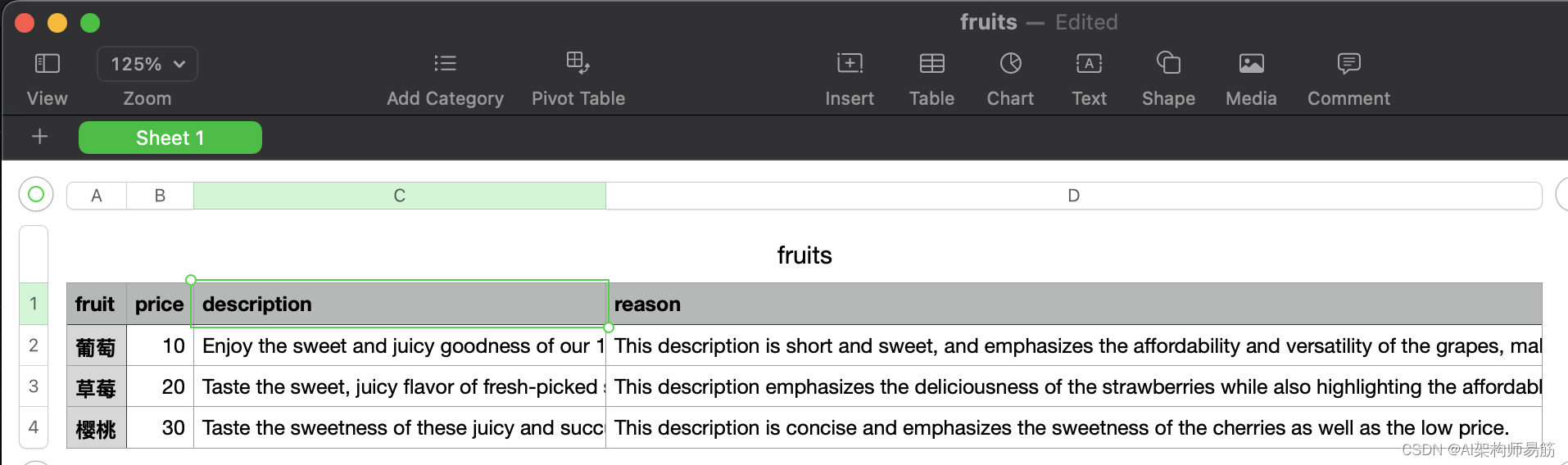
print(df.to_dict(orient="records"))
# 将DataFrame保存到CSV文件。
df.to_csv("fruits.csv", index=False)
运行结果
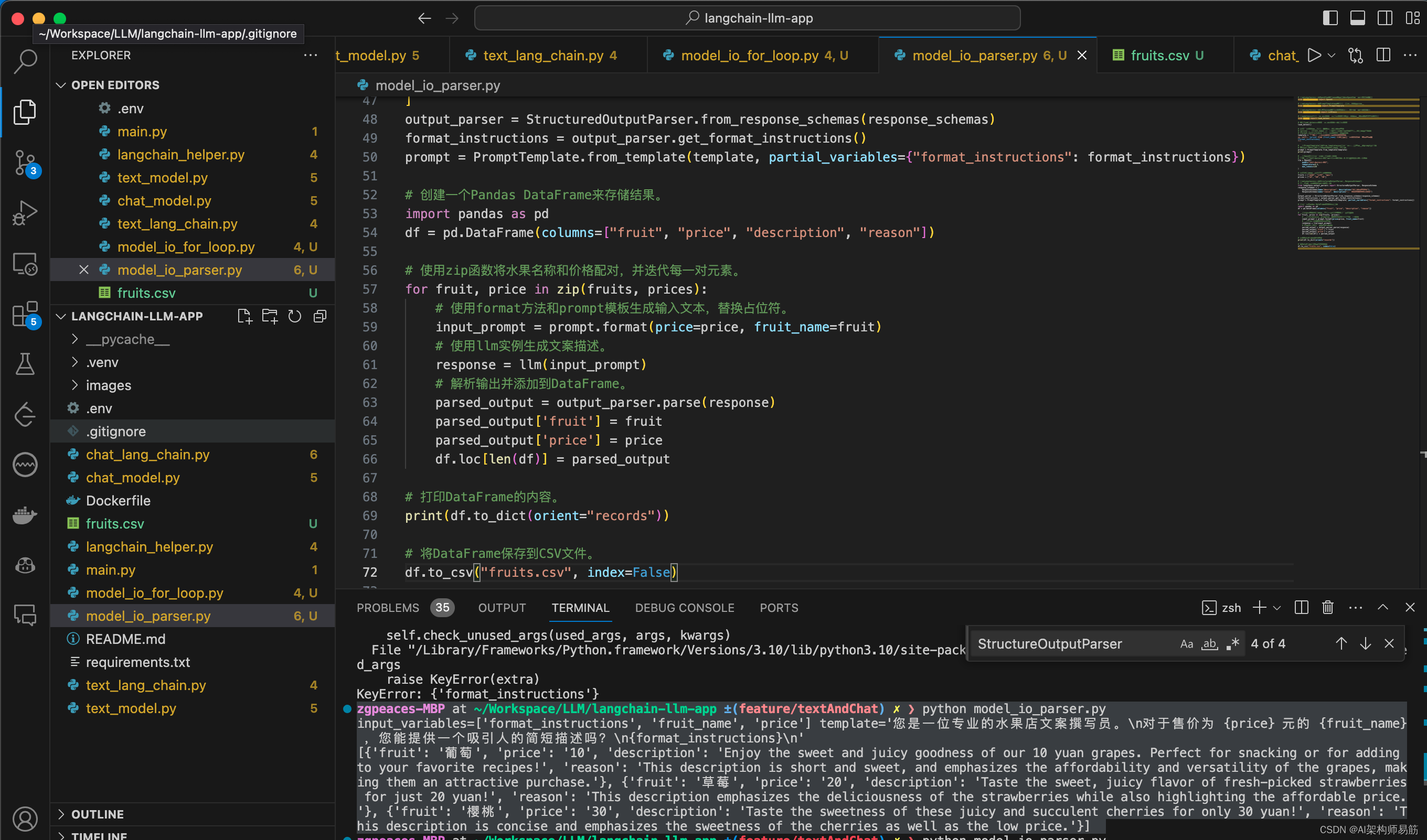
zgpeaces-MBP at ~/Workspace/LLM/langchain-llm-app ±(feature/textAndChat) ✗ ❯ python model_io_parser.py
input_variables=['format_instructions', 'fruit_name', 'price'] template='您是一位专业的水果店文案撰写员。\n对于售价为 {price} 元的 {fruit_name} ,您能提供一个吸引人的简短描述吗?\n{format_instructions}\n'
[{'fruit': '葡萄', 'price': '10', 'description': 'Enjoy the sweet and juicy goodness of our 10 yuan grapes. Perfect for snacking or for adding to your favorite recipes!', 'reason': 'This description is short and sweet, and emphasizes the affordability and versatility of the grapes, making them an attractive purchase.'}, {'fruit': '草莓', 'price': '20', 'description': 'Taste the sweet, juicy flavor of fresh-picked strawberries for just 20 yuan!', 'reason': 'This description emphasizes the deliciousness of the strawberries while also highlighting the affordable price.'}, {'fruit': '樱桃', 'price': '30', 'description': 'Taste the sweetness of these juicy and succulent cherries for only 30 yuan!', 'reason': 'This description is concise and emphasizes the sweetness of the cherries as well as the low price.'}]

代码
- https://github.com/zgpeace/pets-name-langchain/tree/feature/textAndChat
- https://github.com/huangjia2019/langchain/tree/main/03_%E6%A8%A1%E5%9E%8BIO
参考
https://python.langchain.com/docs/modules/model_io/