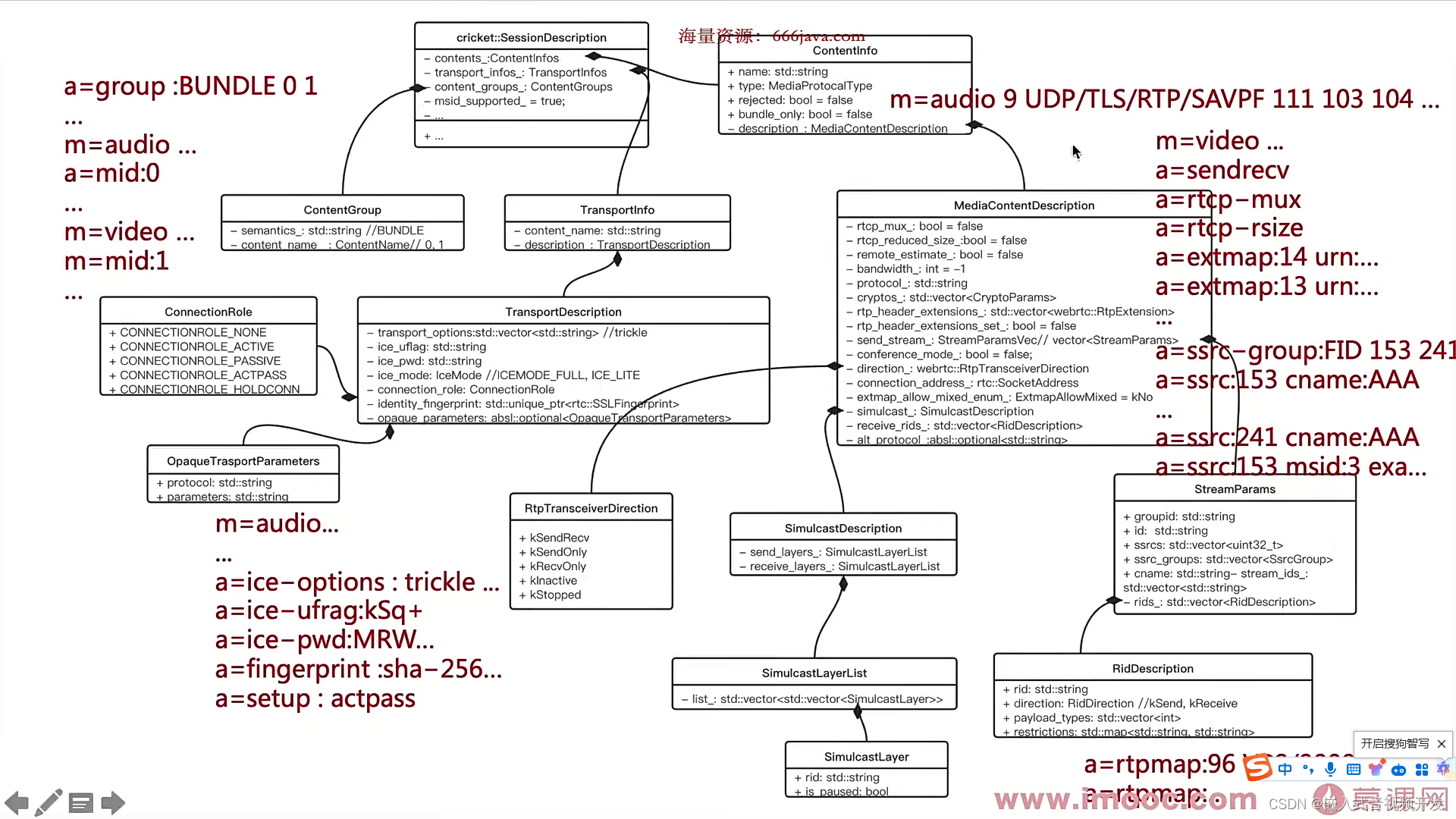
Web后端开发_02

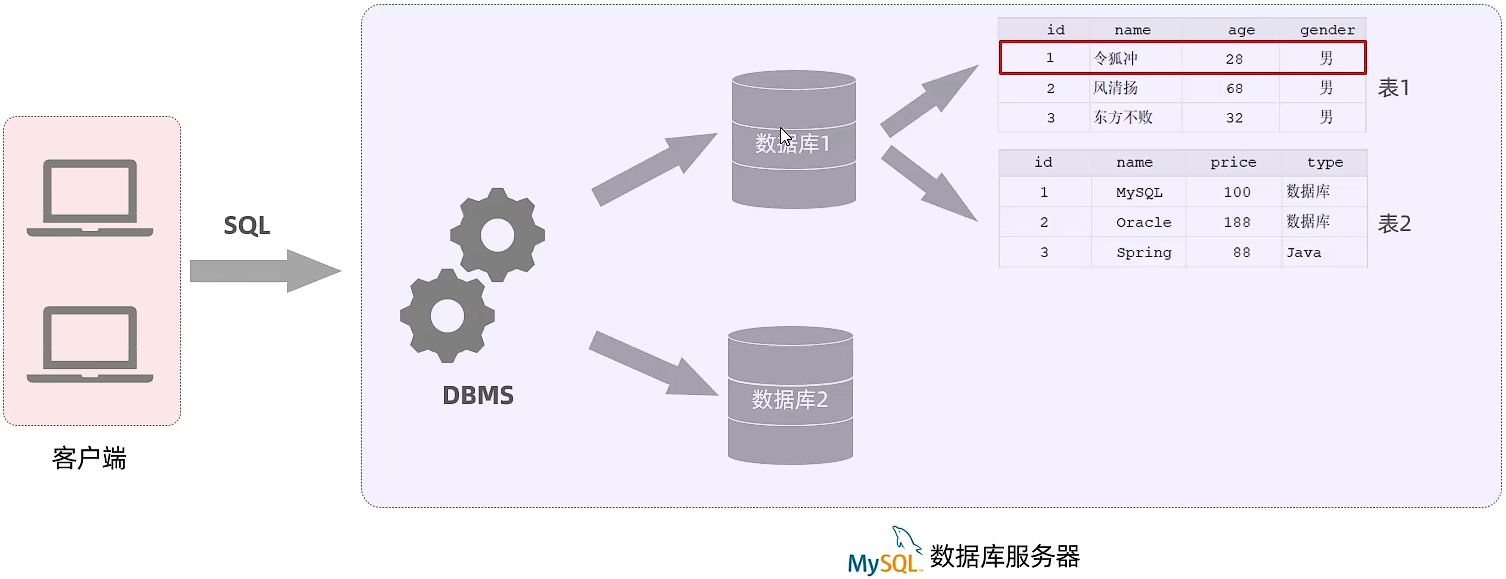
数据库介绍
什么是数据库?
- 数据库:DataBase(DB),是存储和管理数据的仓库
- 数据库管理系统:DataBase Management System (DBMS),操纵和管理数据库的大型软件。
- SQL:Structured Query Language,操作关系型数据库的编程语言,定义了一套操作关系型数据库统一标准。
数据库产品
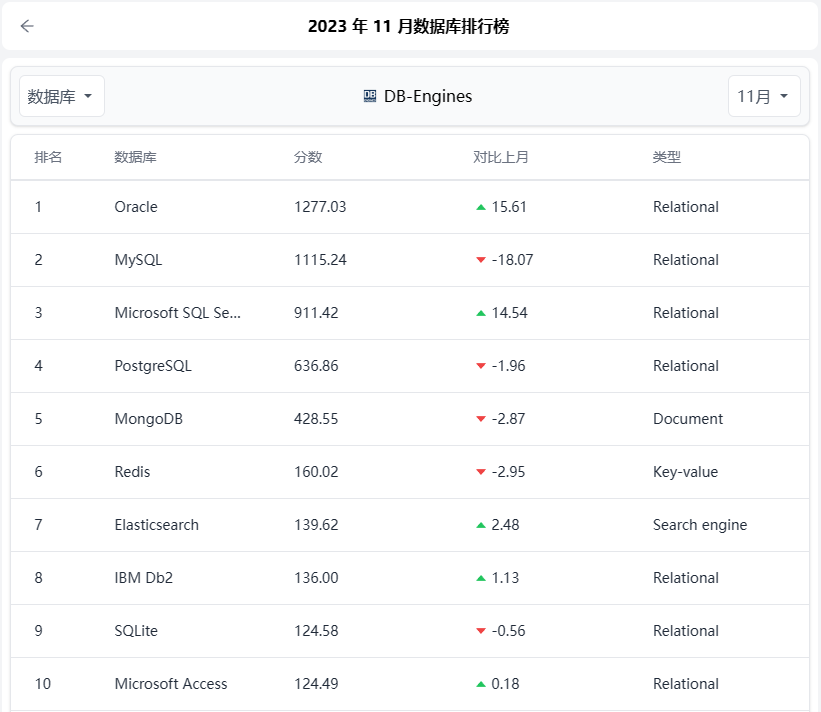
HelloGitHub|数据库排名
https://hellogithub.com/report/db-engines/
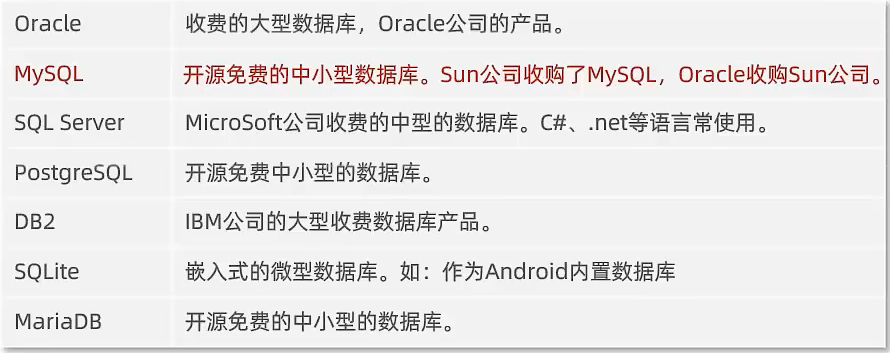
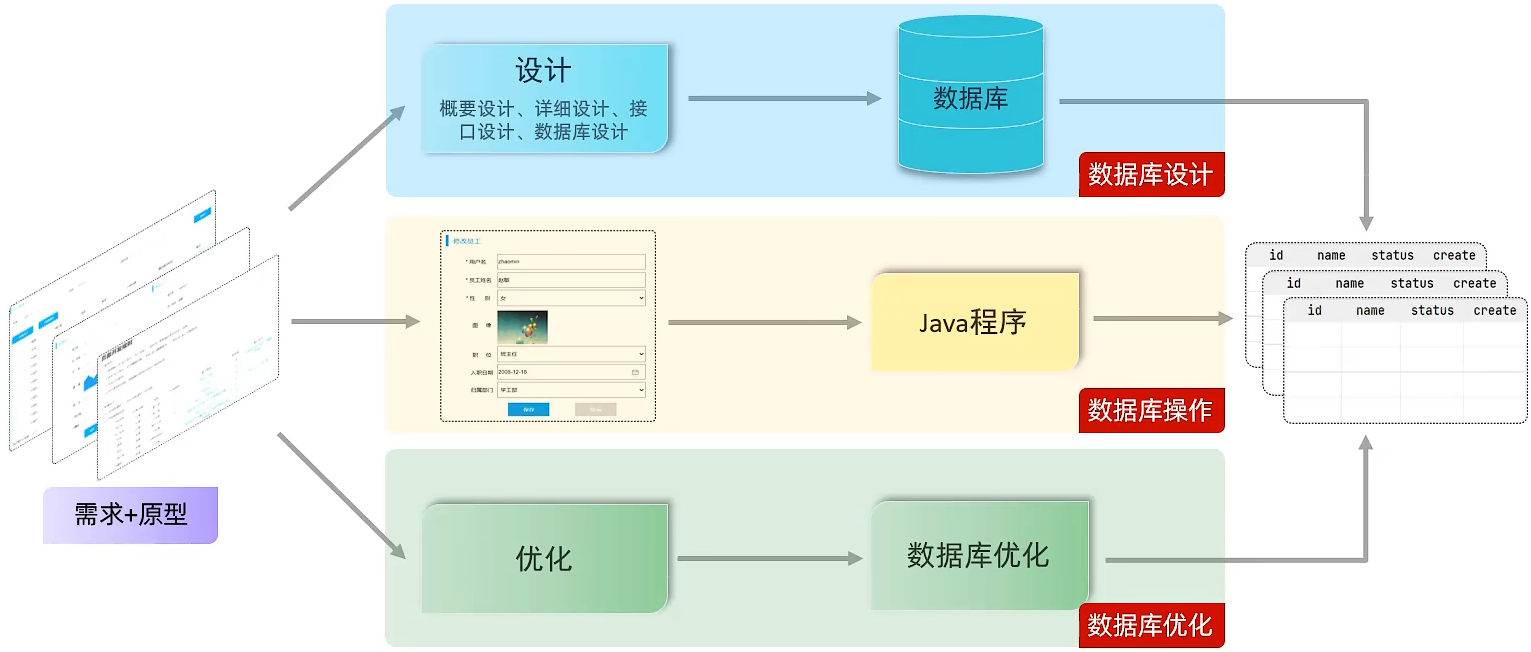
数据库设计
MySQL概述
安装、配置
MySQL安装:
MySQL官方提供了两个不同的版本:

我下载安装的是MySQL社区版(MySQL Community Server 8.0.28)
黑马给的有(MySQL Community Server 8.0.31)的安装配置方法,这里不在赘述。
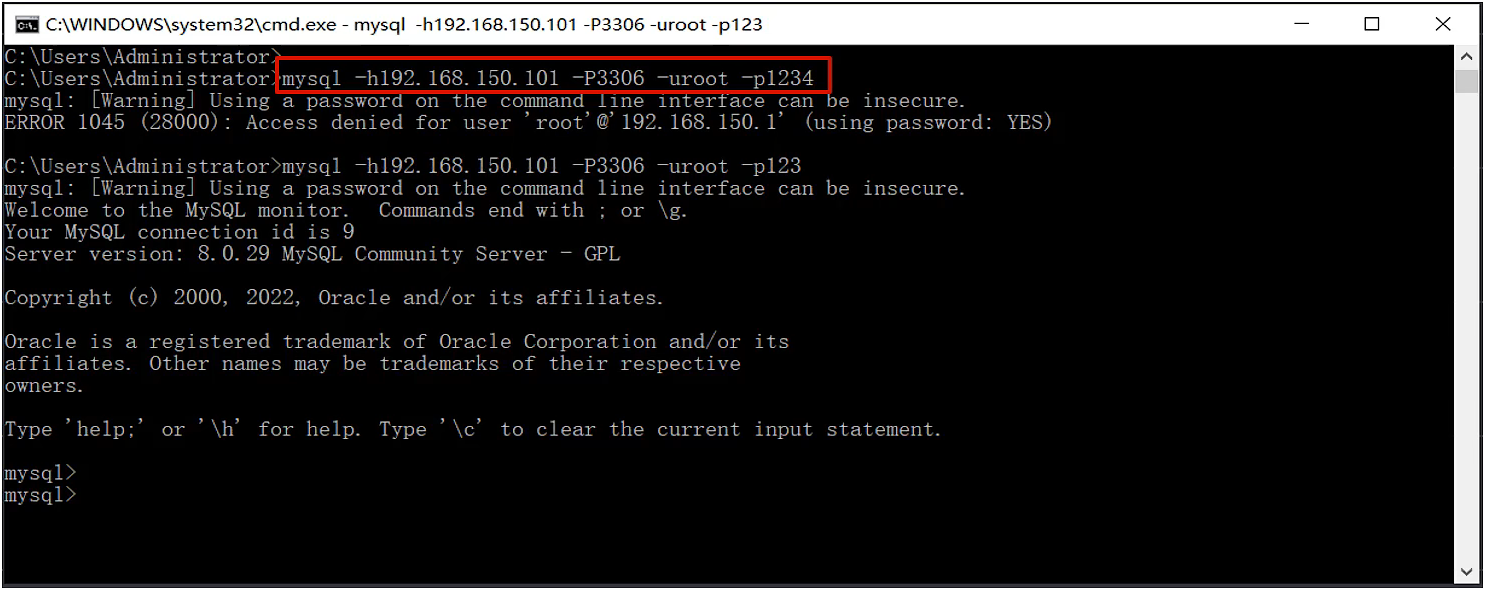
MySQL-企业开发使用方式
mysql -u用户名 -p密码 [-h数据库服务器IP地址 -p端口号]
数据模型
- 关系型数据库(RDBMS):建立在关系模型基础上,由多张相互连接的二维表组成的数据库
特点
- 使用表存储数据,格式统一,易于维护
- 使用SQL语言操作,标准统一,使用方便,可用于复杂查询
SQL简介
- SQL:一门操作关系型数据库的编程语言,定义操作所有关系型数据库的统一标准。
通用语法
- SQL语句可以单行或多行书写,以分号结尾。
- SQL语句可以使用空格/缩进来增强语句的可读性。
- MySQL数据库的SQL语句不区分大小写。
- 注释:
- 单行注释:
--注释内容或#注释内容(MySQL特有) - 多行注释:
/*注释内容*/
- 单行注释:

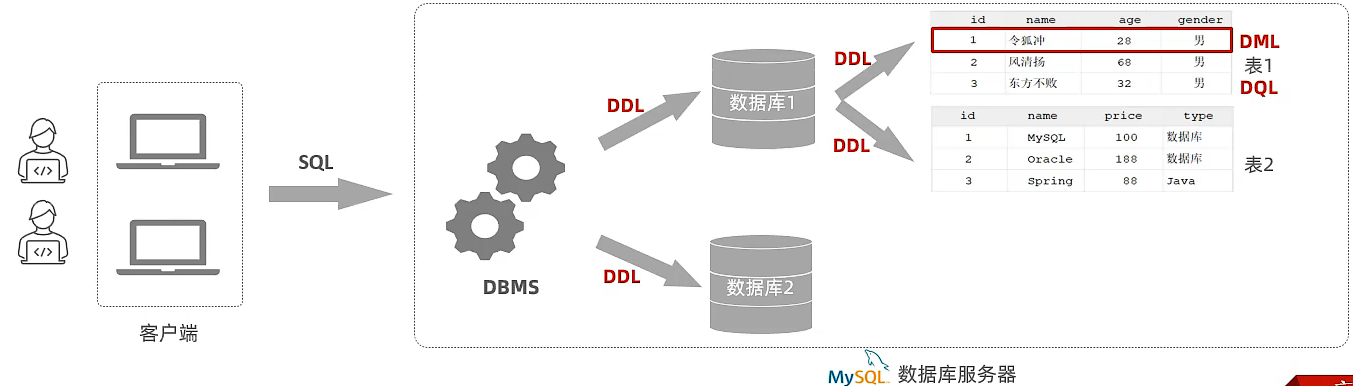
SQL分类
SQL语句通常被分为四大类:

开发的三个阶段
数据库设计-DDL
DDL英文全称是Data Definition Language,数据定义语言,用来定义数据库对象(数据库、表)。
数据库
查询
查询所有数据库
show databases;
查询当前数据库
select database();
查询表结构
desc 表名;
查询当前数据库中的所有表名
show tables;
查询指定表的建表语句
show create table 表名;
创建
create database [if not exists] 数据库名 [default charset 字符集] [collate 排序规则];
删除
drop database [if exists] 数据库名;
使用
use 数据库名;
注意事项:
- 上述语法中的database,也可以替换成schema。如:
create schema db01;
代码示例:
#查询所有数据库
SHOW DATABASES;
#创建数据库
create database db01;
#创建数据库db01,如果没有在创建
create database if not exists db01;
#创建数据库db02,如果没有在创建
create database if not exists db02;
#创建数据库db03,如果没有在创建
create database if not exists db03;
#使用数据库db01
use db01;
#查看当前正在使用的数据库
select database();
#查询所有数据库
show databases;
#删除数据库
drop database db03;
#该数据库存在时删除,不存在时也不报错
drop database if exists db02;
#查询所有数据库
show schemas;
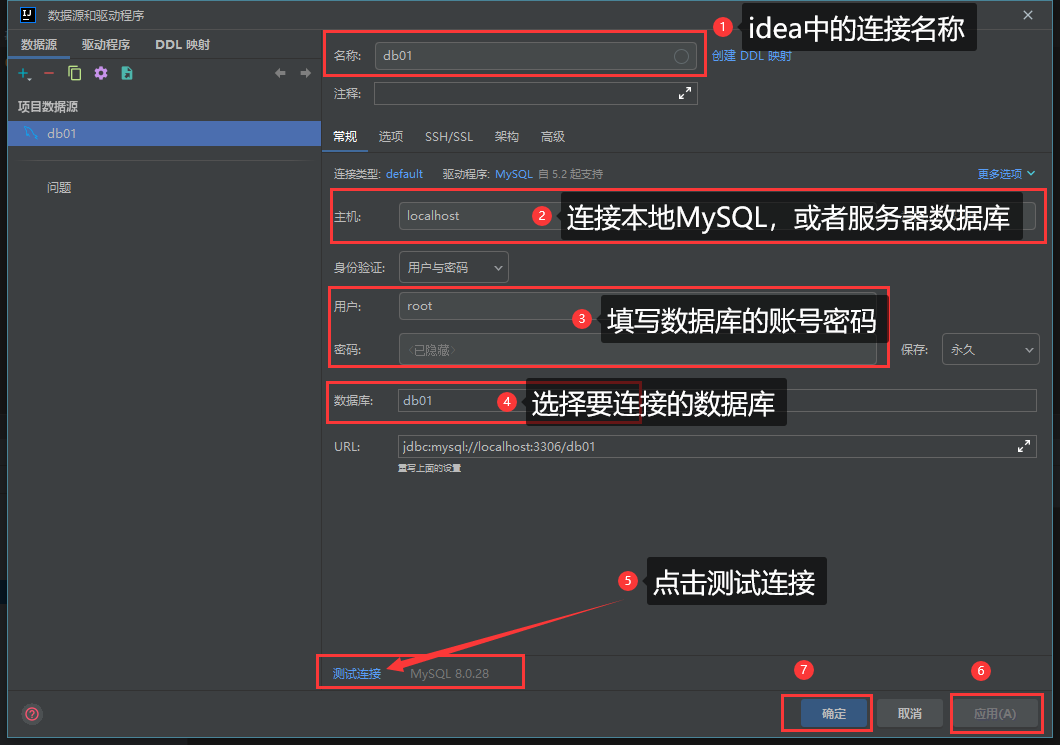
MySQL客户端工具-图像化工具
DataGrip:
- 介绍:DataGrip是JetBrains旗下的一款数据库管理工具,是管理和开发MySQL、Oracle、PostgreSQL的理想解决方案。
- 官网:https://www.jetbrains.com/zh-cn/datagrip/
- 安装:黑马参考资料中提供的《DataGrip安装手册》
IDEA中内嵌的有数据库管理工具
IDEA中的控制台
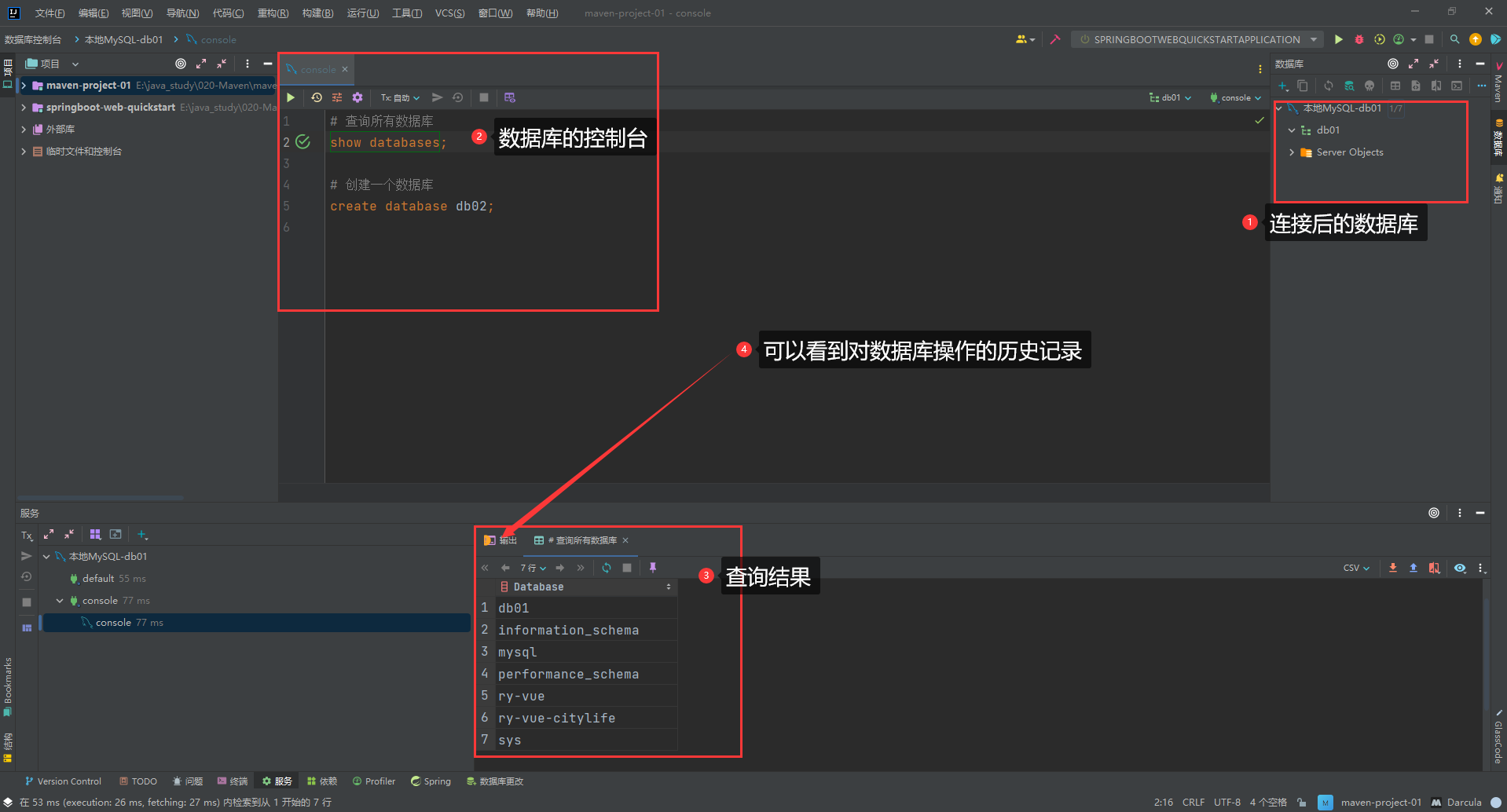
表(创建、查询、修改、删除)
DDL-表操作-创建
create table 表名(
字段1 字段1类型[ comment 字段1注释 ],
字段2 字段2类型[ comment 字段2注释 ],
字段3 字段3类型[ comment 字段3注释 ]
)[ comment 表注释];
DDL-表操作-查询
查询当前数据库所有表
show tables;
查询表结构
desc 表名;
举例:
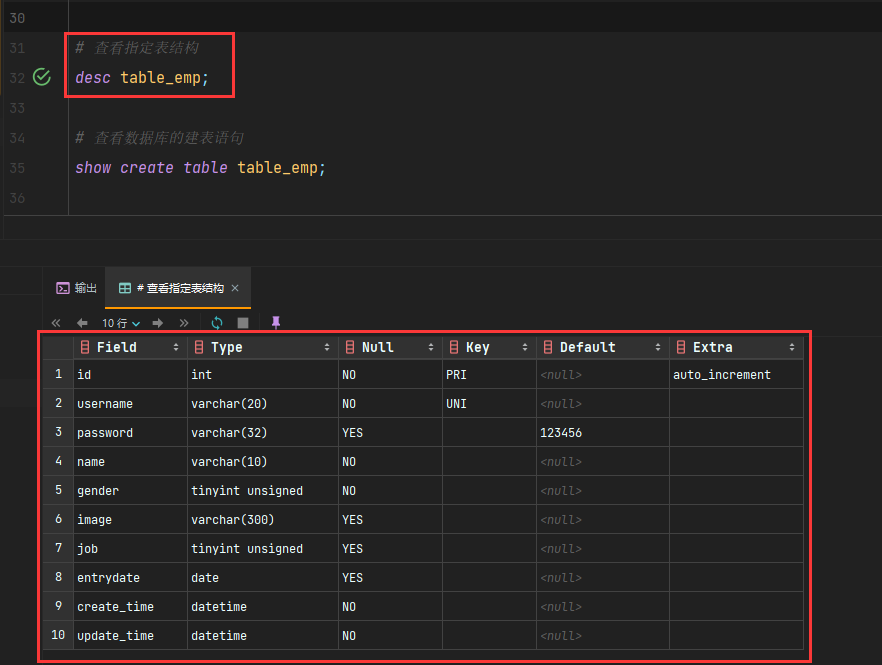
查询建表语句
show create table 表名;
DDL-表操作-修改
添加字段
alter table 表名 add 字段名 类型(长度) [comment 注释] [约束];
修改数据类型
alter table 表名 modify 字段名 新数据类型(长度);
修改字段名和字段类型
alter table 表名 change 旧字段名 新字段名 类型(长度) [comment 注释] [约束];
删除字段
alter table 表名 drop 字段名;
删除表=》新建表=》迁移表数据,最终完成修改表名(如果原表有任何依赖(如视图、索引、触发器等),这些依赖都需要手动重新创建。)
alter table 表名 rename to 新表名;
修改表名(所有与原表相关的对象(如视图、索引、触发器等)都将自动更新以引用新表名)
rename table 表名 to 新表名;
- 使用图形化界面进行操作
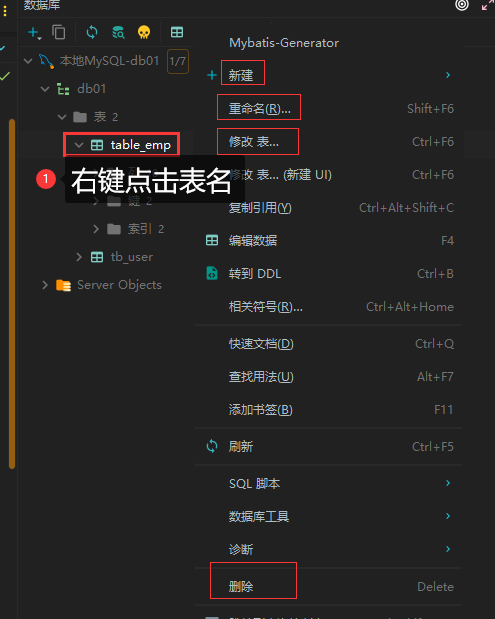
- 转到DDL:自动生成建表语句
DDL-表操作-删除
删除表
drop table [if exists] 表名;
删除指定表(数据),并重新创建该表(结构)
truncate table 表名;
注意事项:
- 在删除表时,表中的全部数据也会被删除
约束:
- 概念:约束是作用于表中字段上的规则,用于限制存储在数据表中的数据。
- 目的:保证数据库中数据的正确性、有效性、完整性

设计对应的表
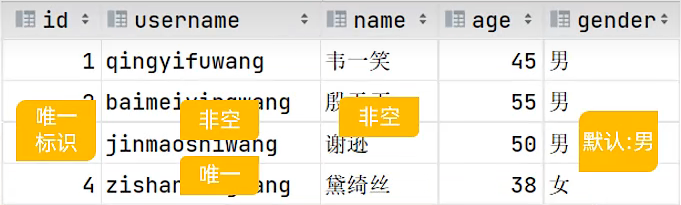
对应的SQL语句
#创建 基本语法(约束)
create table tb_user
(
id int primary key auto_increment comment 'ID,唯一标识',
username varchar(20) not null unique comment '用户名',
name varchar(10) not null comment '姓名',
age int comment '年龄',
gender char(1) default '男' comment '性别'
) comment '用户表';
创建成功,测试插入数据。
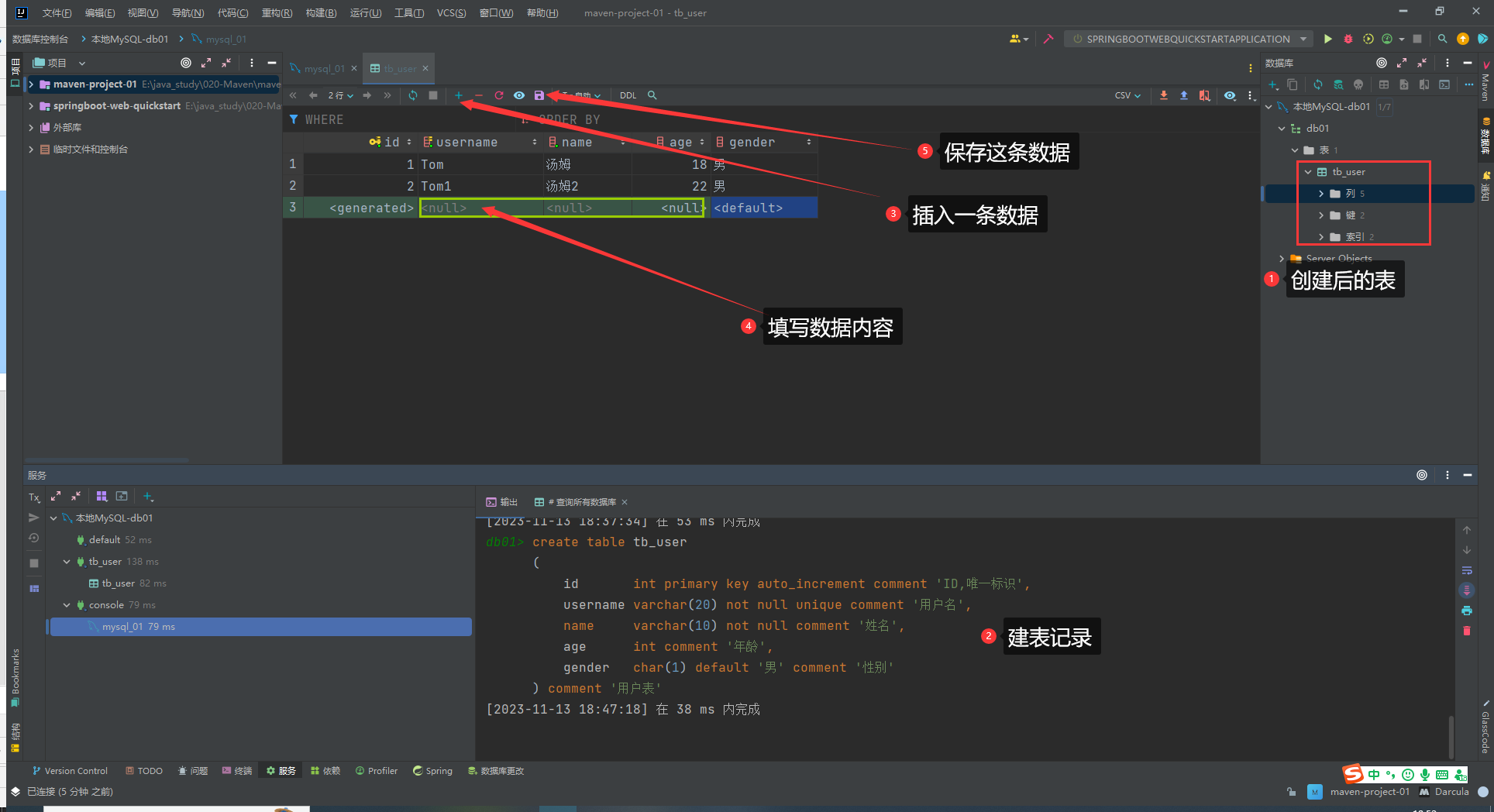
数据类型:
MySQL中的数据类型有很多,主要分为三类:数值类型、字符串类型、日期时间类型
数值类型
| 类型 | 大小(byte) | 有符号(SIGNED)范围 | 无符号(UNSIGNED)范围 | 描述 |
|---|---|---|---|---|
tinyint | 1 | (-128,127) | (0,255) | 小整数值 |
smallint | 2 | (-32768,32767) | (0,65535) | 大整数值 |
mediumint | 3 | (-8388608,8388607) | (0,16777215) | 大整数值 |
int | 4 | (-2147483648,2147483647) | (0,4294967295) | 大整数值 |
bigint | 8 | (-263,263-1) | (0,2^64-1) | 极大整数值 |
float | 4 | (-3.402823466 E+38,3.402823466351 E+38) | 0 和 (1.175494351 E-38,3.402823466 E+38) | 单精度浮点数值 |
double | 8 | (-1.7976931348623157 E+308,1.7976931348623157 E+308) | 0 和 (2.2250738585072014 E-308,1.7976931348623157 E+308) | 双精度浮点数值 |
decimal | 小数值(精度更高) |
tinyint unsigned:表示无符号的tinyint类型,例如:用户的年龄 age tinyint unsigned
float(5,2):5表示整个数字长度,2 表示小数位个数
double(5,2):5表示整个数字长度,2 表示小数位个数,例如:成绩(分值为999.9~0) score double(4,1)
decimal(5,2):5表示整个数字长度,2 表示小数位个数
字符串类型
| 类型 | 大小 | 描述 |
|---|---|---|
char | 0-255 bytes | 定长字符串 |
varchar | 0-65535 bytes | 变长字符串 |
tinyblob | 0-255 bytes | 不超过255个字符的二进制数据 |
tinytext | 0-255 bytes | 短文本字符串 |
blob | 0-65 535 bytes | 二进制形式的长文本数据 |
text | 0-65 535 bytes | 长文本数据 |
mediumblob | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
mediumtext | 0-16 777 215 bytes | 中等长度文本数据 |
longblob | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
longtext | 0-4 294 967 295 bytes | 极大文本数据 |
char(10):最多只能存10个字符,不足10个字符,占用10个字符空间,例如存储AB占用十个字符空间,性能高,浪费空间
varchar(10):最多只能存10个字符,不足10个字符,按照实际长度存储,例如存储ABC占用三个字符空间,性能低,节省空间
手机号:phone char(11)
用户名:username varchar(20)
日期时间类型
| 类型 | 大小(byte) | 范围 | 格式 | 描述 |
|---|---|---|---|---|
date | 3 | 1000-01-01 至 9999-12-31 | YYYY-MM-DD | 日期值 |
time | 3 | -838:59:59 至 838:59:59 | HH:MM:SS | 时间值或持续时间 |
year | 1 | 1901 至 2155 | YYYY | 年份值 |
datetime | 8 | 1000-01-01 00:00:00 至 9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
timestamp | 4 | 1970-01-01 00:00:01 至 2038-01-19 03:14:07 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值,时间戳 |
用户生日:birthday data
操作时间:updata_time datatime
案例
根据页面原型/需求创建表(设计合理的数据类型、长度、约束)
- 字段限制说明
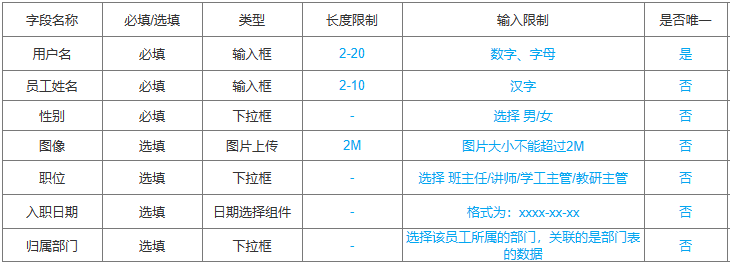
- 根据需求文档使用IDEA创建员工表
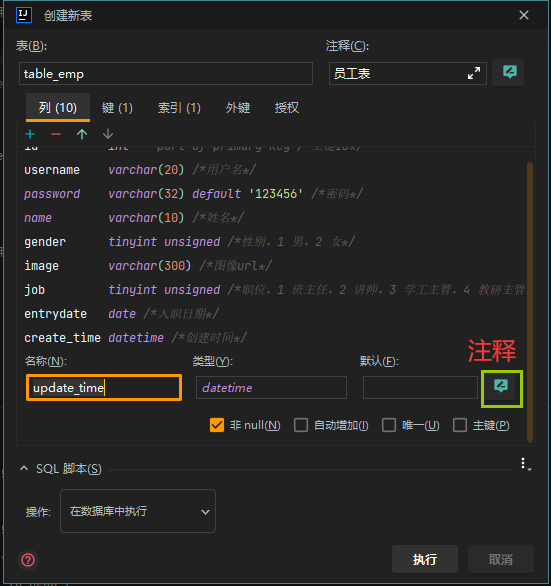
- 设计表结构的基本流程
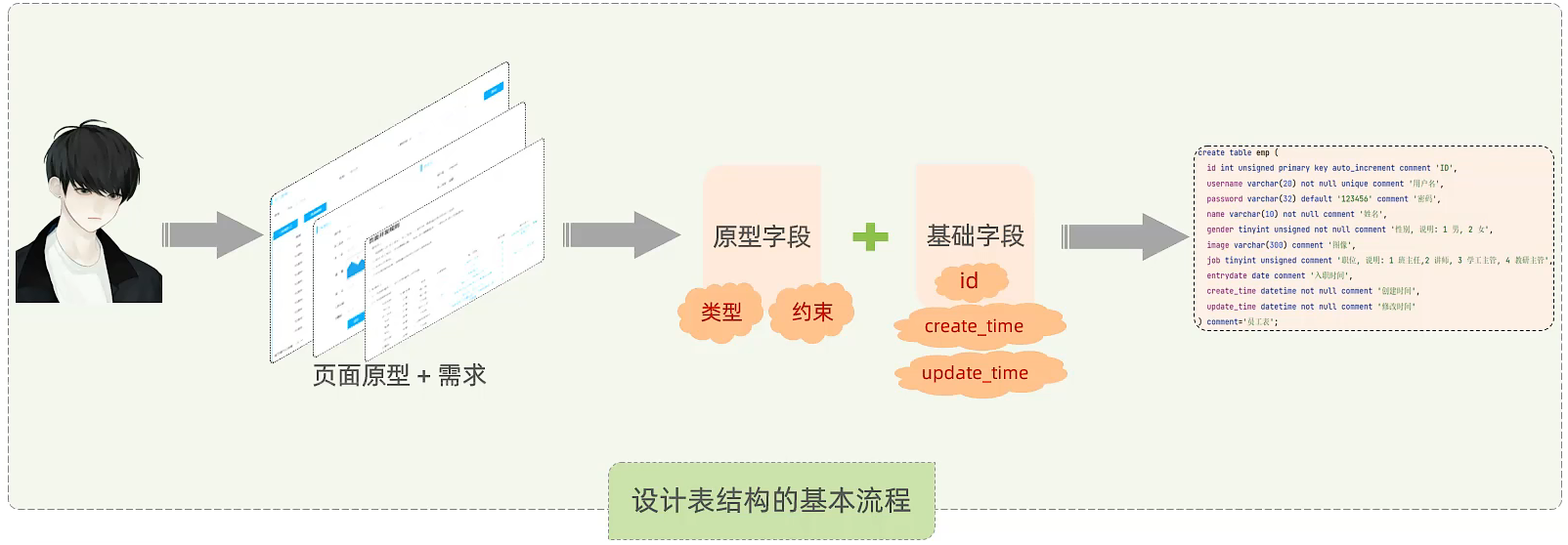
注意事项:
- create_time:记录的是当前这条数据插入的时间。
- update_time:记录当前这条数据最后更新的时间。
多表设计
暂时略
数据库操作
数据库操作-DML
DML英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录进行增、删、改操作。
添加数据(INSERT)
- 指定字段添加数据
insert into 表名(字段名1,字段名2,...) values(值1,值2,....);
- 全部字段添加数据
insert into 表 values(值1,值2,值3......);
- 批量添加数据(指定字段)
insert into 表名(字段名1,字段名2) values(值1,值2),(值1,值2);
- 批量添加数据(全部字段)
insert into 表名 values(值1,值2,...),(值1,值2,...);
示例:
# DML:插入数据-insert
# 1.为table_emp表的username,name,gender 字段插入值
insert into table_emp(username, name, gender, create_time, update_time)
values ('paidaxing', '派大星', 1, now(), now());
# 2.为table_emp表的 所有字段插入值
insert into table_emp(id, username, password, name, gender, image, job, entry_date, create_time, update_time)
values (null, 'haimian', '123', '海绵宝宝', 1, '1.jpg', 1, '2000-02-12', now(), now());
insert into table_emp
values (null, 'pilaoban', '321', '痞老板', '1', '3.jpg', 4, '2020-03-23', now(), now());
insert into table_emp
values (null, 'pilaoban3', default, '痞老板3', '3', '4.jpg', 2, '2020-01-13', now(), now());
# 3.批量为 为table_emp表的username,name,gender字段插入数据
insert into table_emp(username, name, gender, create_time, update_time)
VALUES ('xielaoban2', '蟹老板2', 1, now(), now()),
('paofu', '泡芙阿姨', 2, now(), now());
注意事项:
- 插入数据时,指定的字段顺序需要与值的顺序是一一对应的。
- 字符串和日期型数据应该包含在引号中。
- 插入的数据大小,应该在字段的规定范围内。
- 插入数据时,若数据库已经选择了默认值,values对应值为default
- 插入数据时,自增主键values对应的值为null
修改数据(UPDATE)
语法格式:
update 表名 set 字段名1=值1,字段名2=值2,....;
update 表名 set 字段名1=值1,字段名2=值2,.... where 条件;
示例:
#更新数据
# 1.将table_emp表中的ID为1的员工 姓名name字段更新为'张三'
update table_emp
set name='张四',
update_time=now()
where id = 1;
# 2.将table_emp表中所有员工的入职日期,更新为'2010-01-01'
update table_emp
set entry_date = '2010-01-01',
update_time=now();
注意事项:
- 修改语句的条件可以有,也可以没有,如果没有条件,则会修改整张表的所有数据。
删除数据(DELETE)
语法格式:
delete from 表名 [where 条件];
truncate table 表名 或者truncate 表名;
示例:
#DML 删除数据
# 1.删除table_emp表中ID为1的员工
delete
from table_emp
where id = 1;
# 2.删除table_emp表中的所有员工
delete
from table_emp;
truncate table table_emp;
注意事项:
- delete语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数据。
- delete语句不能删除某个字段的值(如果要操作,可以使用update,将该字段的值设置为null)。
truncate table 表名 或者truncate 表名;直接删除表中的所有数据,且IDEA中没有警告提示。
数据库操作-DQL
- DQL英文全称是Data Query Language(数据库查询语言),用来查询数据库表中的记录。
- 关键字:SELECT

#语法格式:
select
[all|distinct]
<目标列的表达式1> [别名],
<目标列的表达式2> [别名].......
from <表名或视图名> [别名] ,<表名或视图名> [别名]......
[where <条件表达式>]
[group by <列名>
[having <条件表达式>]]
[order by <列名> [asc|desc]]
[limit <数字或者列表>];
#简化版语法:
select *| 列名 from 表 where 条件
DQL-基本查询
- DQL-数据准备
-- 员工管理(带约束)
create table tb_emp
(
id int unsigned primary key auto_increment comment 'ID',
username varchar(20) not null unique comment '用户名',
password varchar(32) default '123456' comment '密码',
name varchar(10) not null comment '姓名',
gender tinyint unsigned not null comment '性别, 说明: 1 男, 2 女',
image varchar(300) comment '图像',
job tinyint unsigned comment '职位, 说明: 1 班主任,2 讲师, 3 学工主管, 4 教研主管',
entrydate date comment '入职时间',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间'
) comment '员工表';
-- 准备测试数据
INSERT INTO tb_emp (id, username, password, name, gender, image, job, entrydate, create_time, update_time)
VALUES (1, 'jinyong', '123456', '金庸', 1, '1.jpg', 4, '2000-01-01', '2022-10-27 16:35:33', '2022-10-27 16:35:35'),
(2, 'zhangwuji', '123456', '张无忌', 1, '2.jpg', 2, '2015-01-01', '2022-10-27 16:35:33', '2022-10-27 16:35:37'),
(3, 'yangxiao', '123456', '杨逍', 1, '3.jpg', 2, '2008-05-01', '2022-10-27 16:35:33', '2022-10-27 16:35:39'),
(4, 'weiyixiao', '123456', '韦一笑', 1, '4.jpg', 2, '2007-01-01', '2022-10-27 16:35:33', '2022-10-27 16:35:41'),
(5, 'changyuchun', '123456', '常遇春', 1, '5.jpg', 2, '2012-12-05', '2022-10-27 16:35:33', '2022-10-27 16:35:43'),
(6, 'xiaozhao', '123456', '小昭', 2, '6.jpg', 3, '2013-09-05', '2022-10-27 16:35:33', '2022-10-27 16:35:45'),
(7, 'jixiaofu', '123456', '纪晓芙', 2, '7.jpg', 1, '2005-08-01', '2022-10-27 16:35:33', '2022-10-27 16:35:47'),
(8, 'zhouzhiruo', '123456', '周芷若', 2, '8.jpg', 1, '2014-11-09', '2022-10-27 16:35:33', '2022-10-27 16:35:49'),
(9, 'dingminjun', '123456', '丁敏君', 2, '9.jpg', 1, '2011-03-11', '2022-10-27 16:35:33', '2022-10-27 16:35:51'),
(10, 'zhaomin', '123456', '赵敏', 2, '10.jpg', 1, '2013-09-05', '2022-10-27 16:35:33', '2022-10-27 16:35:53'),
(11, 'luzhangke', '123456', '鹿杖客', 1, '11.jpg', 2, '2007-02-01', '2022-10-27 16:35:33', '2022-10-27 16:35:55'),
(12, 'hebiweng', '123456', '鹤笔翁', 1, '12.jpg', 2, '2008-08-18', '2022-10-27 16:35:33', '2022-10-27 16:35:57'),
(13, 'fangdongbai', '123456', '方东白', 1, '13.jpg', 1, '2012-11-01', '2022-10-27 16:35:33', '2022-10-27 16:35:59'),
(14, 'zhangsanfeng', '123456', '张三丰', 1, '14.jpg', 2, '2002-08-01', '2022-10-27 16:35:33',
'2022-10-27 16:36:01'),
(15, 'yulianzhou', '123456', '俞莲舟', 1, '15.jpg', 2, '2011-05-01', '2022-10-27 16:35:33', '2022-10-27 16:36:03'),
(16, 'songyuanqiao', '123456', '宋远桥', 1, '16.jpg', 2, '2010-01-01', '2022-10-27 16:35:33',
'2022-10-27 16:36:05'),
(17, 'chenyouliang', '12345678', '陈友谅', 1, '17.jpg', null, '2015-03-21', '2022-10-27 16:35:33',
'2022-10-27 16:36:07'),
(18, 'zhang1', '123456', '张一', 1, '2.jpg', 2, '2015-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:09'),
(19, 'zhang2', '123456', '张二', 1, '2.jpg', 2, '2012-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:11'),
(20, 'zhang3', '123456', '张三', 1, '2.jpg', 2, '2018-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:13'),
(21, 'zhang4', '123456', '张四', 1, '2.jpg', 2, '2015-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:15'),
(22, 'zhang5', '123456', '张五', 1, '2.jpg', 2, '2016-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:17'),
(23, 'zhang6', '123456', '张六', 1, '2.jpg', 2, '2012-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:19'),
(24, 'zhang7', '123456', '张七', 1, '2.jpg', 2, '2006-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:21'),
(25, 'zhang8', '123456', '张八', 1, '2.jpg', 2, '2002-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:23'),
(26, 'zhang9', '123456', '张九', 1, '2.jpg', 2, '2011-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:25'),
(27, 'zhang10', '123456', '张十', 1, '2.jpg', 2, '2004-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:27'),
(28, 'zhang11', '123456', '张十一', 1, '2.jpg', 2, '2007-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:29'),
(29, 'zhang12', '123456', '张十二', 1, '2.jpg', 2, '2020-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:31');
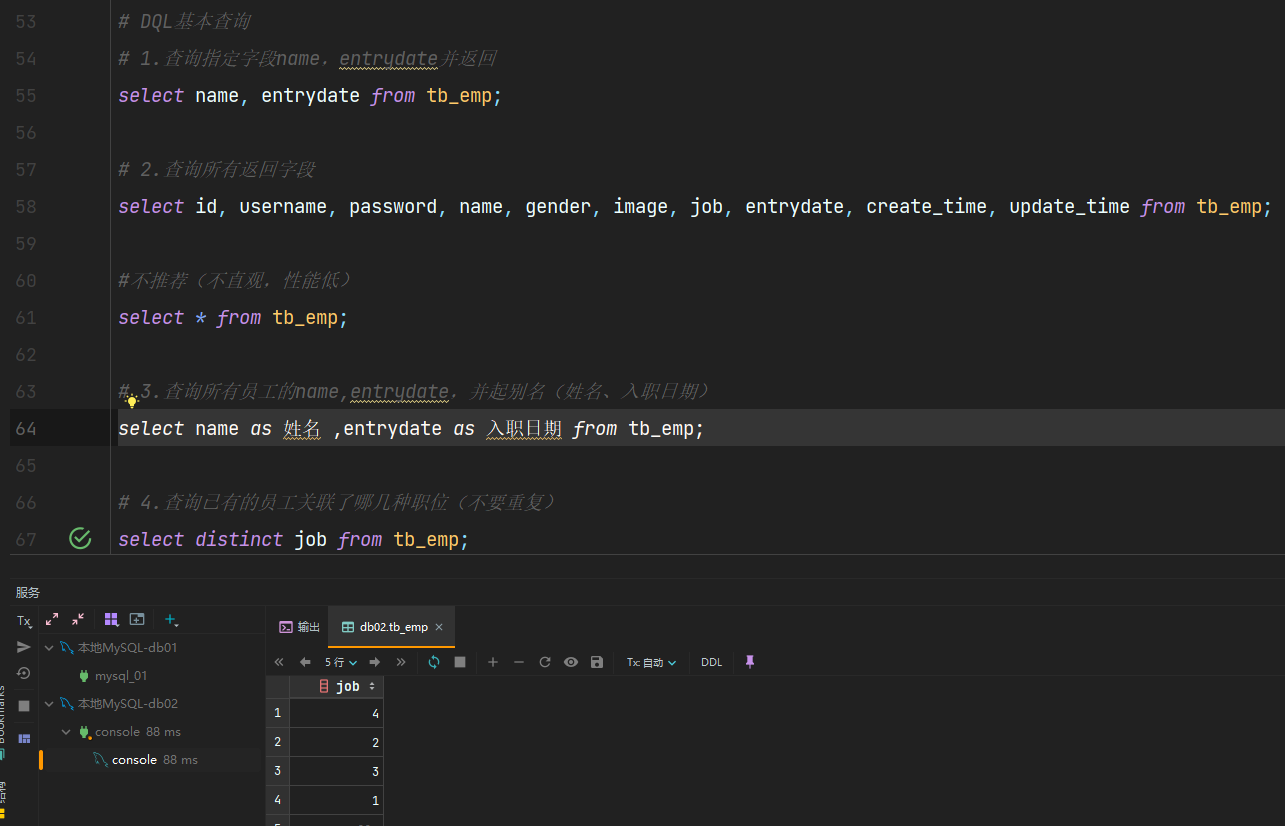
语法:
- 查询多个字段:
select 字段1,字段2,字段3 from 表名;
- 查询所有字段(通配符):
select * from 表名;
- 设置别名:
select 字段1 [as 别名1], 字段2[as 别名2] from 表名;
- 去除重复记录:
select distinct 字段列表 from 表名;
示例:
DQL-条件查询
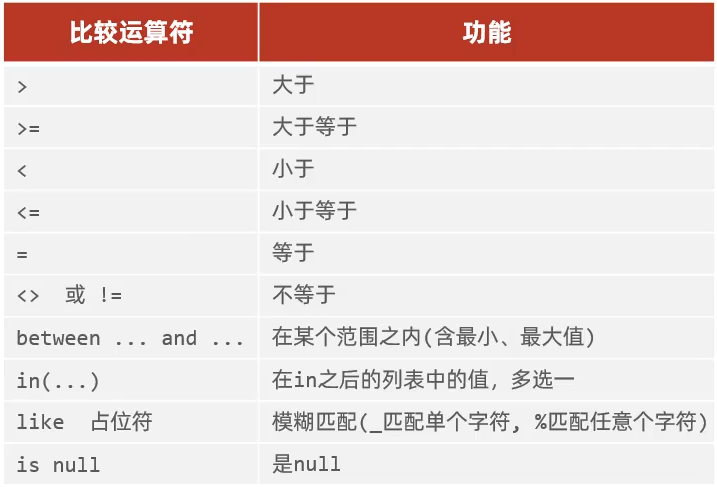
语法:
- 条件查询
select 字段列表 from 表名 where 条件查询;
- 比较运算符
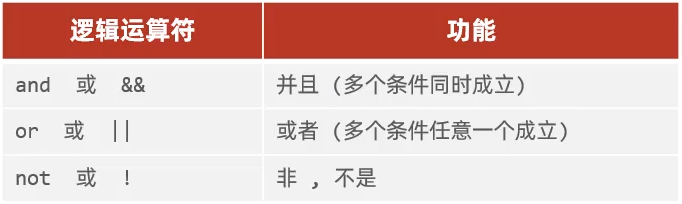
- 逻辑运算符
示例:
-- =================== 条件查询 ======================
-- 1. 查询 姓名 为 杨逍 的员工
select * from tb_emp where name='杨逍';
-- 2. 查询在 id小于等于5 的员工信息
select * from tb_emp where id <= 5;
-- 3. 查询 没有分配职位 的员工信息 -- 判断 null , 用 is null
select * from tb_emp where job is null;
-- 4. 查询 有职位 的员工信息 -- 判断 不是null , 用 is not null
select * from tb_emp where job is not null ;
-- 5. 查询 密码不等于 '123456' 的员工信息
select * from tb_emp where password != '123456';
select * from tb_emp where password <> '123456';
-- 6. 查询入职日期 在 '2000-01-01' (包含) 到 '2010-01-01'(包含) 之间的员工信息
select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01' order by entrydate;
-- 7. 查询 入职时间 在 '2000-01-01' (包含) 到 '2010-01-01'(包含) 之间 且 性别为女 的员工信息
select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01' and gender = 2;
select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01' && gender = 2;
-- 8. 查询 职位是 2 (讲师), 3 (学工主管), 4 (教研主管) 的员工信息
select * from tb_emp where job in (2, 3, 4) order by job desc ;
-- 9. 查询姓名为两个字的员工信息
select * from tb_emp where name like '__';
-- 10. 查询姓 '张' 的员工信息 ---------> 张%
select * from tb_emp where name like '张%';
-- 11. 查询姓名中包含 '三' 的员工信息
select * from tb_emp where name like '%三%';
DQL-分组查询
-
聚合函数
-
介绍:将一列数据作为一个整体,进行纵向计算,不对
null值进行运算 -
语法:
select 聚合函数(字段列表) from 表名;
-
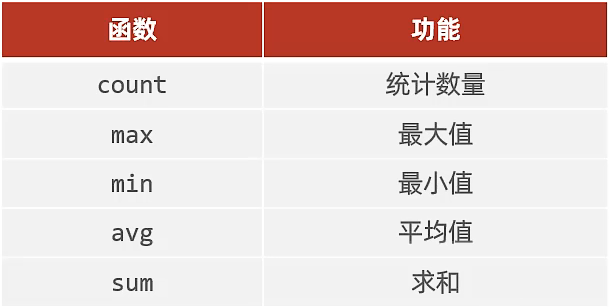
注意事项:
- null值不参与所有聚合函数运算
- 统计数量可以使用:
count(*)count(字段)count(常量),推荐使用count(*)
-
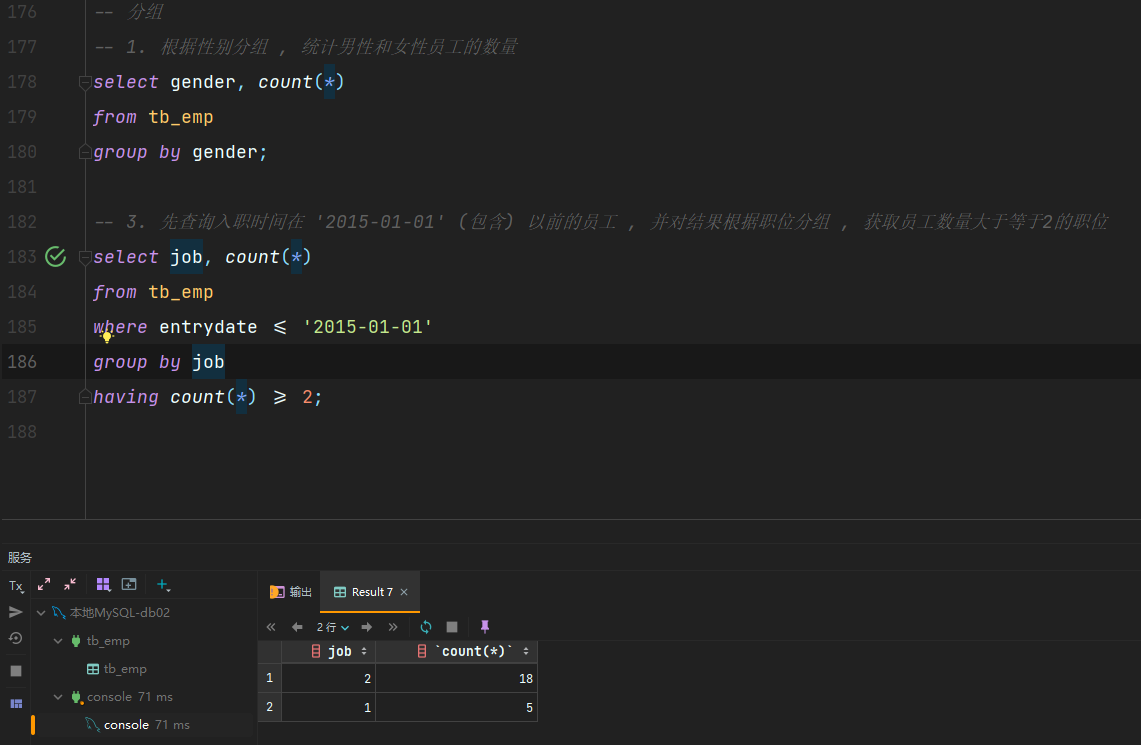
分组查询
语法:
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件]; -
where与having区别
- 执行时机不同:where是分组之前进行过滤,不满足于where条件,不参与分组;而having是分组之后对结果进行过滤。
- 判断条件不同:where不能对聚合函数进行判断,而having可以。
注意事项:
- 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义
- 执行顺序:where > 聚合函数 > having
示例:
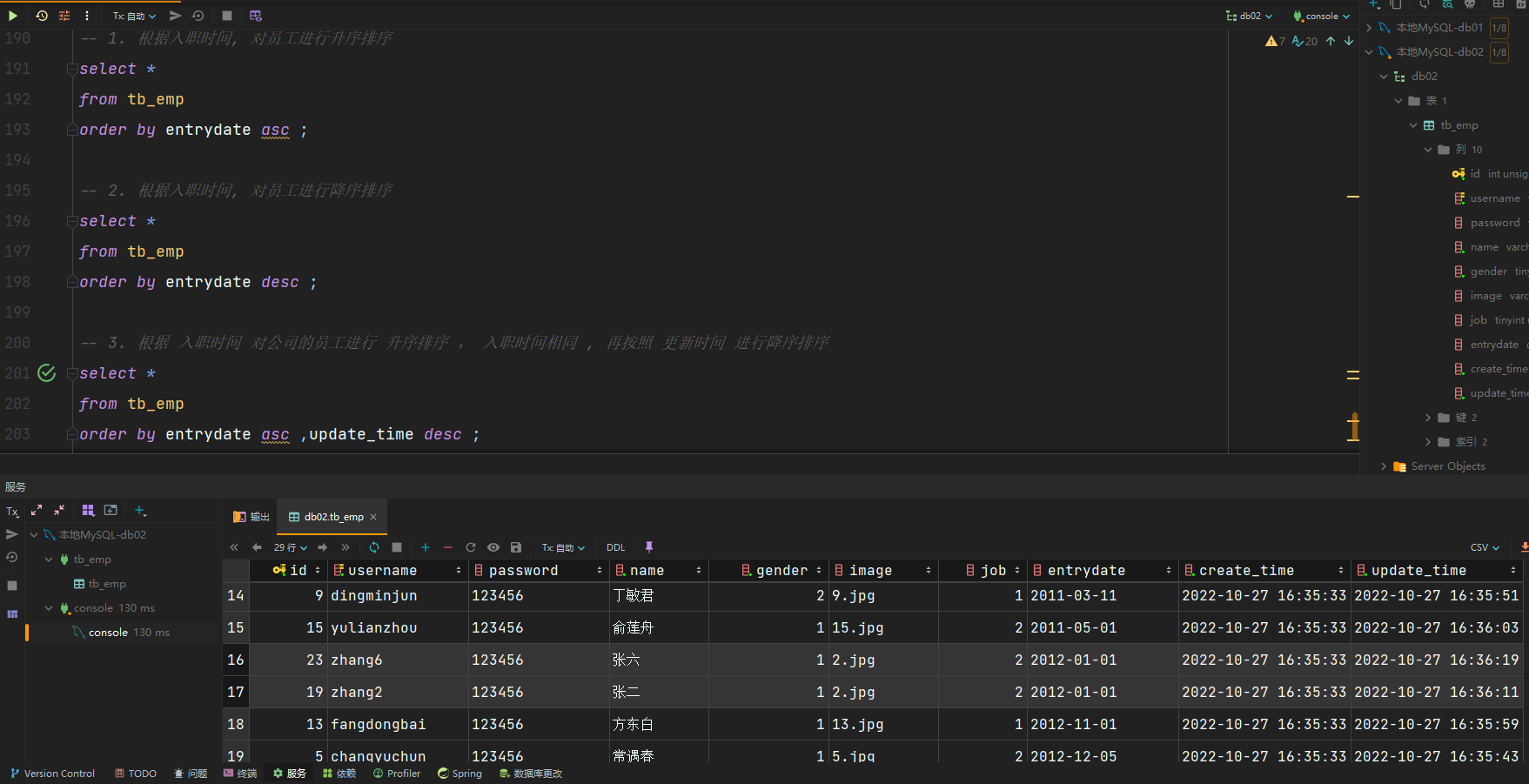
DQL-排序查询
语法:
条件查询
select 字段列表 from 表名 [where 条件列表] [group by 分组字段] order by 字段1 排序方式1, 字段2 排序方式2... ;
排序方式
ASC:升序(默认值)DESC:降序
注意事项:
- 如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序
示例:
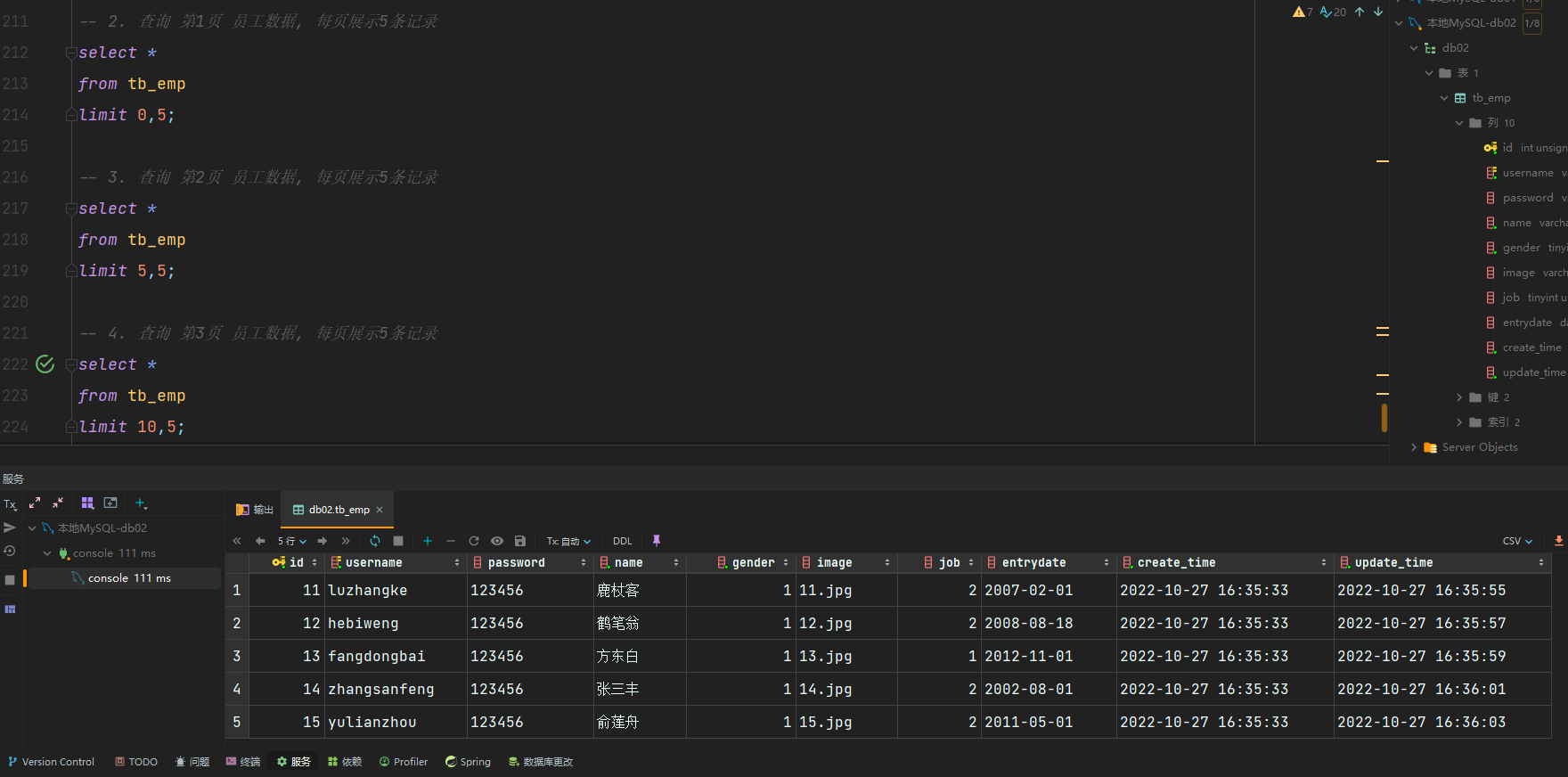
DQL-分页查询

语法:
分页查询
select 字段列表 from 表名 limit 起始索引, 查询记录数;
注意事项:
起始索引从0开始,
起始索引 = (查询页码 − 1 ) ∗ 每页显示记录数 起始索引 =(查询页码 - 1)* 每页显示记录数 起始索引=(查询页码−1)∗每页显示记录数分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中是
limit如果查询的是第一页数据,起始索引可以省略,直接简写为
limit 10
示例:
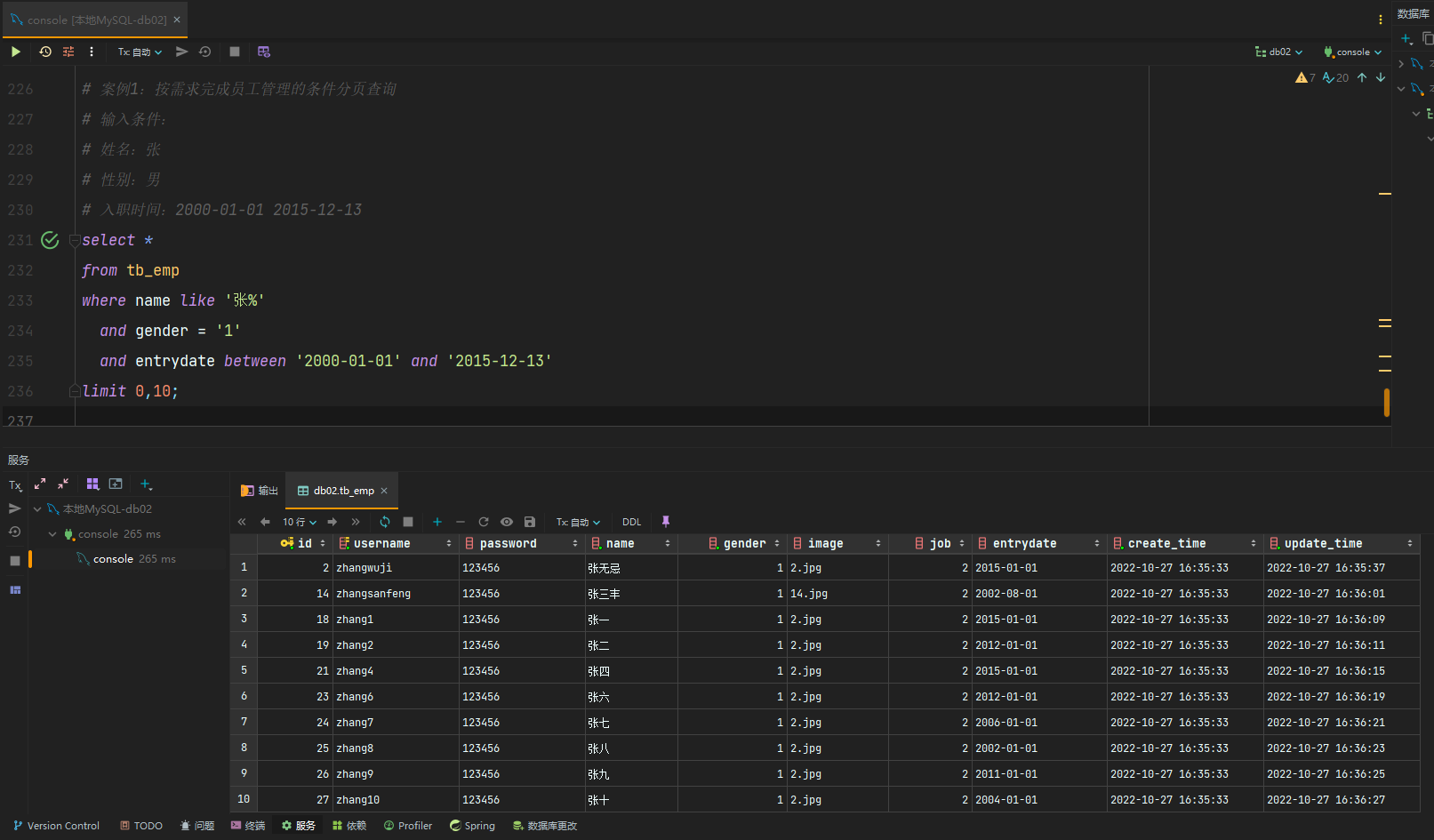
DQL-案例1
根据需求完成员工管理的条件分页查询

页面开发规则
- 查询员工
1.1 根据输入的 员工姓名、员工性别、入职时间 搜索满足条件的员工信息。
1.2 其中 员工姓名,支持模糊匹配; 性别 进行精确查询 ;入职时间 进行范围查询。
1.3 支持分页查询。
1.4 并对查询的结果,根据最后修改时间进行倒序排序。
示例:
小结:
基本查询
条件查询
分组查询
分页查询

多表设计-概述
项目开发中,在进行数据库表结构设计时,会根据也无需求以及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表之间也存在着各种联系,基本上分为三种:
- 一对多(多对一)
- 多对多
- 一对一
一对多
需求
根据 页面原型 及 需求文档,完成部门及员工模块的表结构设计。
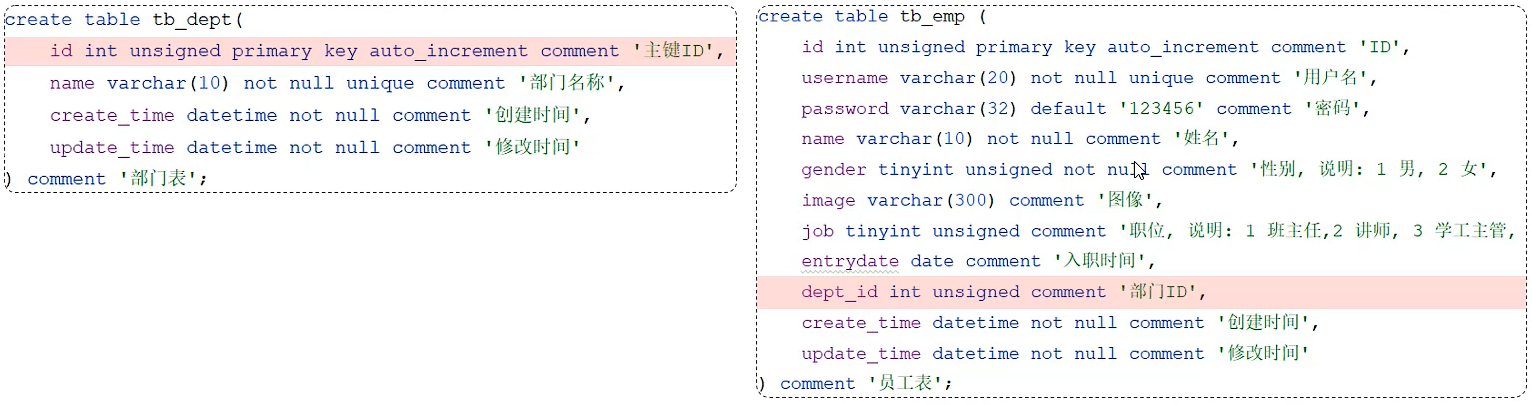
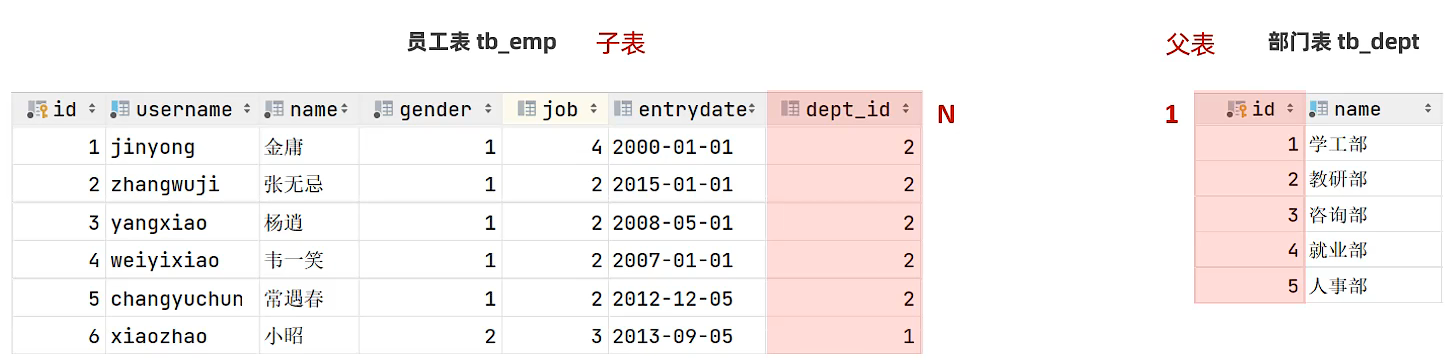
一对多关系实现:在数据表中多的一方,添加字段,来关联1的一方的主键
多表问题分析
现象
- 部门数据可以直接删除,然而还有部分员工归属于该部门下,此时就出现了数据的不完整性、不一致问题
问题分析
- 目前上述的两张表,在数据库层面,并未建立关联,所以是无法保证数据的一致性和完整性。
外键约束
- 外键语法
-- 创建表时指定
create table 表名(
字段名 数据类型;
...
[constraint] [外键名称] foreign key(外键字段名) references 主表(字段名)
);
-- 建完表后,添加外键
alter table 表名 add constraint 外键名称 foreign key(外键字段名) references 主表(字段名);
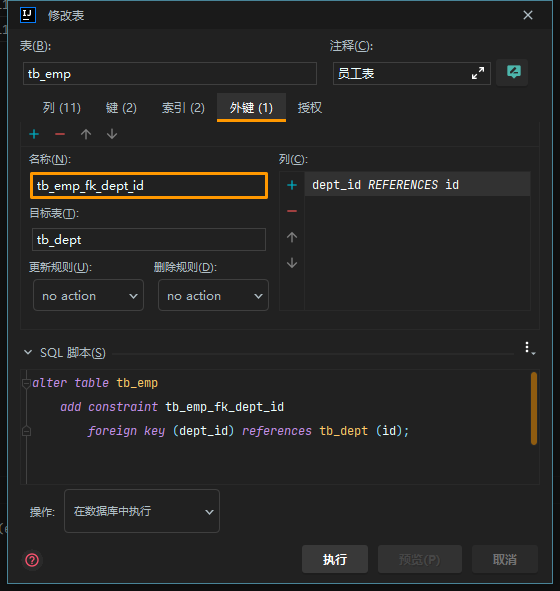
禁止使用物理外键
物理外键
- 概念:使用foreign key定义外键关联另外一张表
- 缺点:
- 影响增、删、改的效率(需要检查外键关系)
- 仅用于单点数据库,不适用于分布式、集群场景
- 容易引发数据库的死锁问题,消耗性能
推荐使用逻辑外键
逻辑外键
- 概念:在业务逻辑中,解决外键关联
- 通过逻辑外键,就可以很方便的解决上述问题
一对一
一对一
- 案例:用户与身份信息的关系
- 关系:一对一关系,多用于单表拆分,将一表的基础字段放在一张表中,其他字段放在另一个表中,以提升操作效率
- 实现:在任意一方加入外键,关联另外一方的主键,并且设置外键为位于的(UNIQUE)
单表

拆分

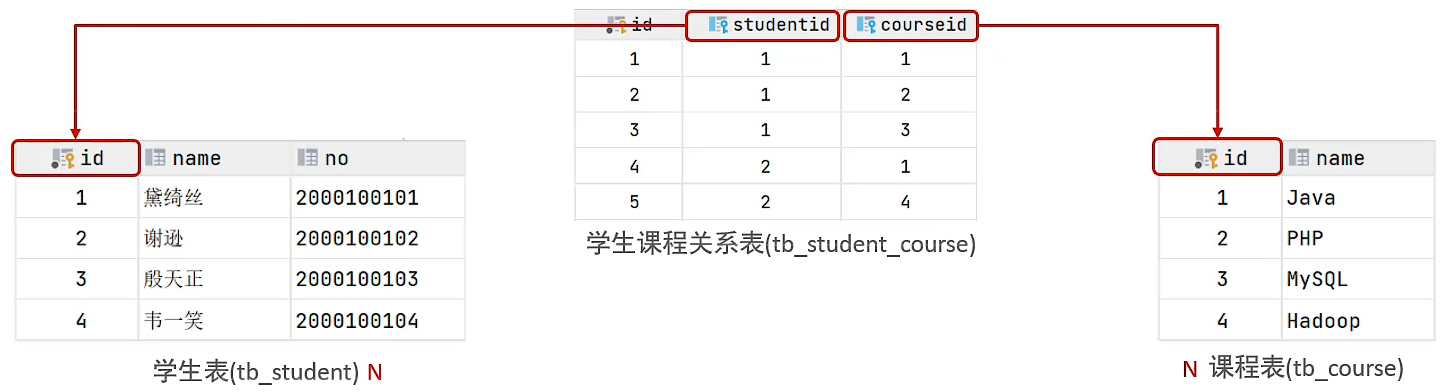
多对多
多对多
- 案例:学生与课程的关系
- 关系:一个学生可以选修多门课程,一门课程也可以供多个学生选择
- 实现:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
案例
需求
- 参考资料中提供的《苍穹外卖_管理后台》页面原型,设计分类管理、菜单管理、套餐管理模块的表结构。
步骤
- 阅读页面原型及需求文档,分析各个模块涉及到的表结构,及表结构之间的关系
- 根据页面原型及需求文档,分析各个表结构中具体的字段及约束
- 阅读页面原型及需求文档,分析各个模块涉及到的表结构,及表结构之间的关系
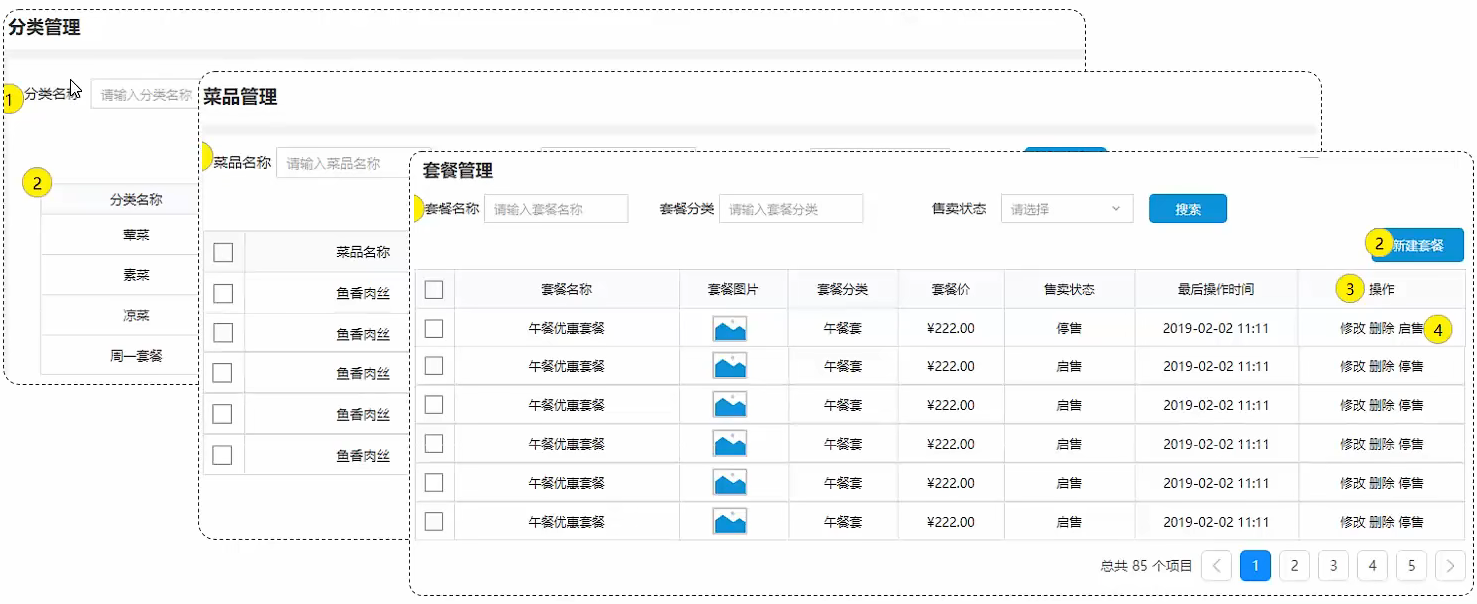
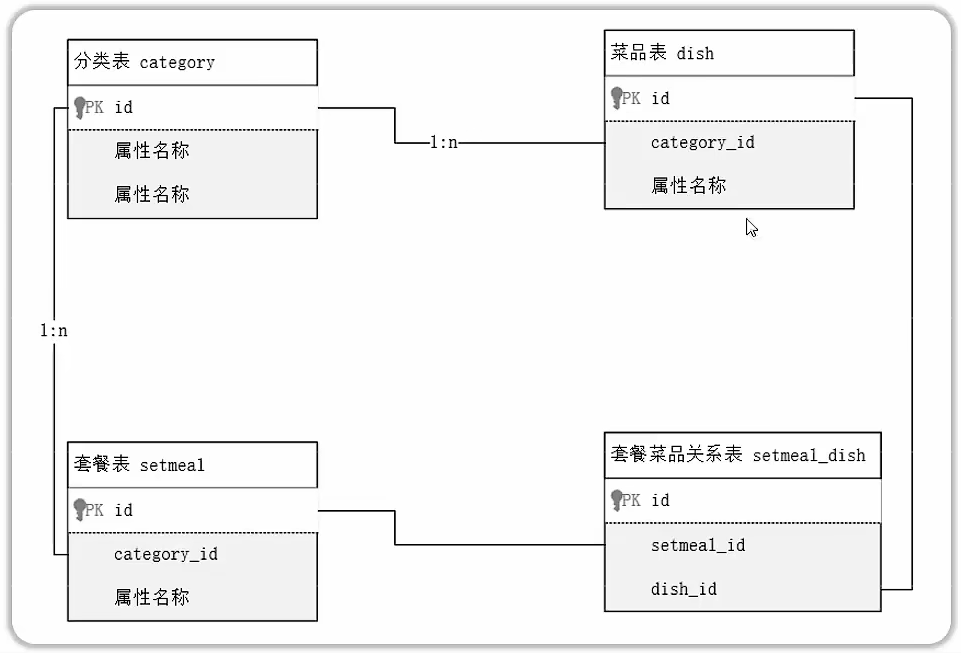
- 根据页面原型及需求文档,分析各个表结构中具体的字段及约束

小结
1、一对多
在多的一方添加外键,关联另一方的外键
2、一对一
任意一方,添加外键,关联另一方的主键
3、多对多
通过中间表来维护,中间表的两个外键,分别关联另外两张表的主键
多表查询
数据准备
- 将资料中准备好的多表查询数据准备的SQL脚本导入数据库中
-- 部门管理
create table tb_dept
(
id int unsigned primary key auto_increment comment '主键ID',
name varchar(10) not null unique comment '部门名称',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间'
) comment '部门表';
-- 员工管理(带约束)
create table tb_emp
(
id int unsigned primary key auto_increment comment 'ID',
username varchar(20) not null unique comment '用户名',
password varchar(32) default '123456' comment '密码',
name varchar(10) not null comment '姓名',
gender tinyint unsigned not null comment '性别, 说明: 1 男, 2 女',
image varchar(300) comment '图像',
job tinyint unsigned comment '职位, 说明: 1 班主任,2 讲师, 3 学工主管, 4 教研主管',
entrydate date comment '入职时间',
dept_id int unsigned comment '部门ID',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间'
) comment '员工表';
insert into tb_dept (id, name, create_time, update_time)
values (1, '学工部', now(), now()),
(2, '教研部', now(), now()),
(3, '咨询部', now(), now()),
(4, '就业部', now(), now()),
(5, '人事部', now(), now());
INSERT INTO tb_emp
(id, username, password, name, gender, image, job, entrydate, dept_id, create_time, update_time)
VALUES (1, 'jinyong', '123456', '金庸', 1, '1.jpg', 4, '2000-01-01', 2, now(), now()),
(2, 'zhangwuji', '123456', '张无忌', 1, '2.jpg', 2, '2015-01-01', 2, now(), now()),
(3, 'yangxiao', '123456', '杨逍', 1, '3.jpg', 2, '2008-05-01', 2, now(), now()),
(4, 'weiyixiao', '123456', '韦一笑', 1, '4.jpg', 2, '2007-01-01', 2, now(), now()),
(5, 'changyuchun', '123456', '常遇春', 1, '5.jpg', 2, '2012-12-05', 2, now(), now()),
(6, 'xiaozhao', '123456', '小昭', 2, '6.jpg', 3, '2013-09-05', 1, now(), now()),
(7, 'jixiaofu', '123456', '纪晓芙', 2, '7.jpg', 1, '2005-08-01', 1, now(), now()),
(8, 'zhouzhiruo', '123456', '周芷若', 2, '8.jpg', 1, '2014-11-09', 1, now(), now()),
(9, 'dingminjun', '123456', '丁敏君', 2, '9.jpg', 1, '2011-03-11', 1, now(), now()),
(10, 'zhaomin', '123456', '赵敏', 2, '10.jpg', 1, '2013-09-05', 1, now(), now()),
(11, 'luzhangke', '123456', '鹿杖客', 1, '11.jpg', 1, '2007-02-01', 1, now(), now()),
(12, 'hebiweng', '123456', '鹤笔翁', 1, '12.jpg', 1, '2008-08-18', 1, now(), now()),
(13, 'fangdongbai', '123456', '方东白', 1, '13.jpg', 2, '2012-11-01', 2, now(), now()),
(14, 'zhangsanfeng', '123456', '张三丰', 1, '14.jpg', 2, '2002-08-01', 2, now(), now()),
(15, 'yulianzhou', '123456', '俞莲舟', 1, '15.jpg', 2, '2011-05-01', 2, now(), now()),
(16, 'songyuanqiao', '123456', '宋远桥', 1, '16.jpg', 2, '2010-01-01', 2, now(), now()),
(17, 'chenyouliang', '123456', '陈友谅', 1, '17.jpg', NULL, '2015-03-21', NULL, now(), now());
概述
介绍
- 多表查询:指从多张表中查询数据
- 笛卡尔积:笛卡尔乘积是指在数学中,两个集合(A集合和B集合)的所有组合情况。(在多表查询时,需要消除无效的笛卡尔积)
笛卡尔积
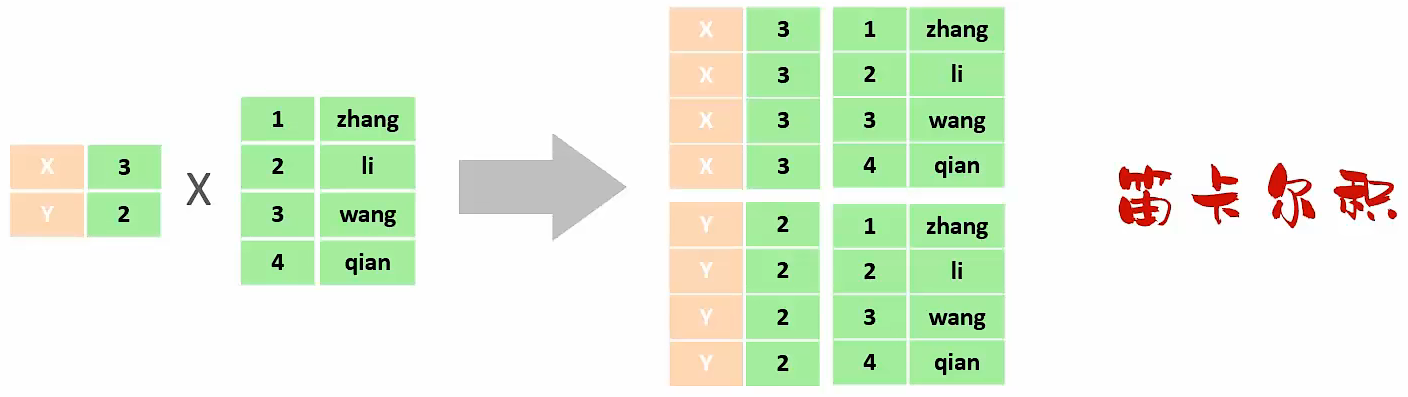
消除无效的笛卡尔积

分类
- 连接查询
- 内连接:相当于查询A、B交集部分数据
- 外连接
- 左外连接:查询左表所有数据(包括两张表交集部分数据)
- 右外连接:查询右表所有数据(包括两张表交集部分数据)
- 子查询
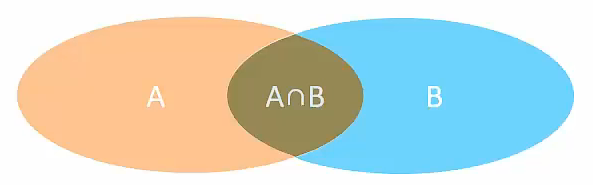
内连接(A∩B)
语法
- 隐式内连接:
select 字段列表 from 表1, 表2 where 条件...- 显式内连接:
select 字段列表 from 表1 [inner] join 表2 on 连接条件...
示例
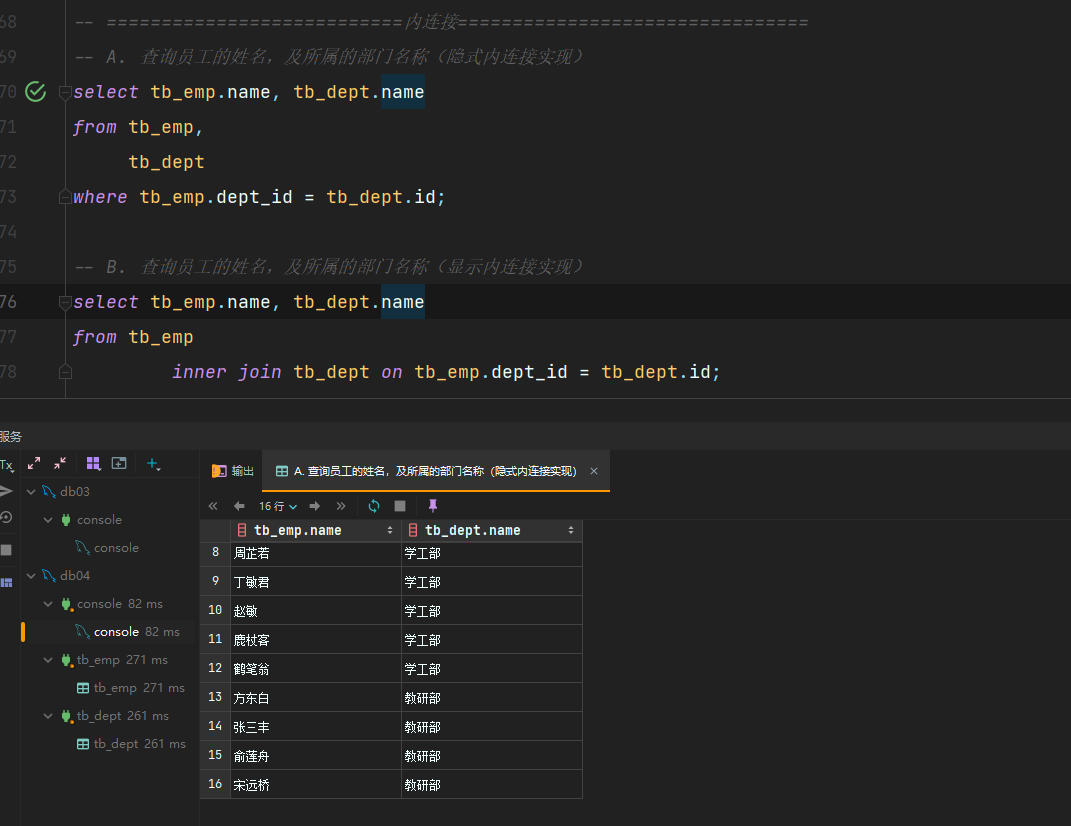
起别名
-- 起别名
select e.name, d.name
from tb_emp e,
tb_dept d
where e.dept_id = d.id;
外连接
语法
- 左外连接:
select 字段列表 from 表1 left [outer] join 表2 on 连接条件...;- 右外连接:
select 字段列表 from 表1 right [outer] join 表2 on 连接条件...;
示例
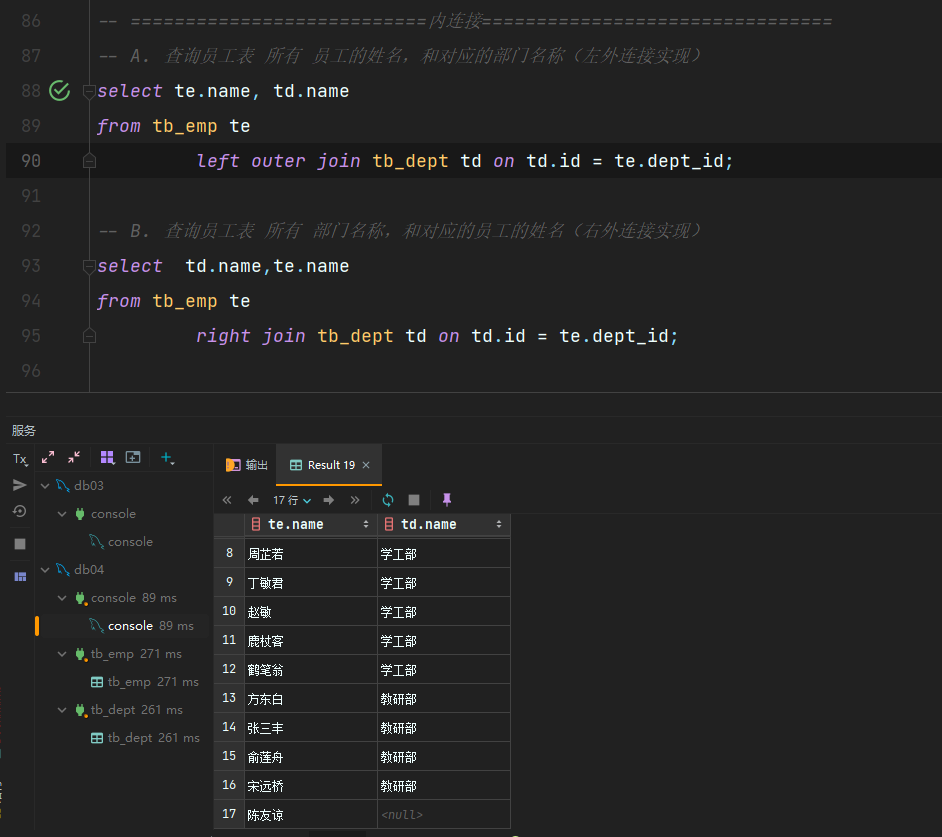
开发中常用左外连接,右外连接可以用左外连接来替换
子查询
概述
- 介绍:SQL语句中嵌套select语句,称为嵌套查询,又称为子查询。
- 形式:
select * from t1 where column1 = (select column1 from t2 ...);- 子查询外部的语句可以是insert、update、delete、select的任何一个,最常见的是select。
分类
- 标量子查询:子查询返回的结果为单个值
- 列子查询:子查询返回的结果为一列
- 行子查询:子查询返回的结果为一行
- 表子查询:子查询返回的结果为多行多列
标量子查询
标量子查询
- 子查询的结果是单个值(数字、字符串、日期等),最简单的形式
- 常用操作符:=、<>、>、>=、<、<=
示例
-- 标量子查询
-- A. 查询“教研部”的所有员工信息
-- a. 查询 教研部 的部门ID - tb_dept
select id
from tb_dept
where name = '教研部';
-- b. 再查询该部门ID下的员工信息 - tb_emp
select *
from tb_emp
where dept_id = 2;
-- 将a. b. 合并为一条SQL
select *
from tb_emp
where dept_id = (select id
from tb_dept
where name = '教研部');
-- B. 查询在"东方白"入职后的员工信息
-- a. 查询 方东白 的入职时间
select entrydate
from tb_emp
where name = '方东白';
-- b. 查询 方东白 入职之后的员工信息
select *
from tb_emp
where entrydate > '2012-11-01';
-- 将a. b. 合并为一条SQL
select *
from tb_emp
where entrydate > (select entrydate
from tb_emp
where name = '方东白');
列子查询
列子查询
- 子查询返回的结果是一列(可以是多行)
- 常用的操作符:
in、not in等
示例
-- 列子查询
-- A. 查询 教研部 和 咨询部 的所有员工信息
-- a. 查询 教研部 和 咨询部 的部门ID - tb_dept
select id
from tb_dept
where name = '教研部'
or name = '咨询部';
-- b. 根据部门ID查询该部门下的员工信息 - tb_emp
select *
from tb_emp
where dept_id in (2, 3);
select *
from tb_emp
where dept_id in (select id
from tb_dept
where name = '教研部'
or name = '咨询部');
行子查询
行子查询
- 子查询的结果可以是一行(可以是多列)
- 常用操作符:
=、<>、in、not in
示例
-- 行子查询
-- A. 查询与“韦一笑”的入职日期 及 职位都相同的员工信息
-- a. 查询与“韦一笑”的入职日期 及 职位
select entrydate, job
from tb_emp
where name = '韦一笑';
-- b. 查询与其入职日期 及 职位都相同的员工信息
select *
from tb_emp
where entrydate = '2007-01-01'
and job = 2;
-- 合并为一条SQL
select *
from tb_emp
where entrydate = (select entrydate
from tb_emp
where name = '韦一笑')
and job = (select job
from tb_emp
where name = '韦一笑');
-- 提高SQL效率
select *
from tb_emp
where (entrydate, job) = ('2007-01-01', 2);
select *
from tb_emp
where (entrydate, job) = (select entrydate, job
from tb_emp
where name = '韦一笑');
表子查询
表子查询
- 子查询返回的结果是多行多列,常作为临时表
- 常用的操作符:in
示例
-- 表子查询
-- A. 查询入职日期是"2006-01-01"之后的员工信息,及其部门名称
-- a. 查询入职日期是"2006-01-01"之后的员工信息
select *
from tb_emp
where entrydate >= '2006-01-01';
-- b. 查询这部分员工信息及其部门名称
select e.*, d.name
from (select *from tb_emp where entrydate >= '2006-01-01') e,
tb_dept d
where e.dept_id = d.id;
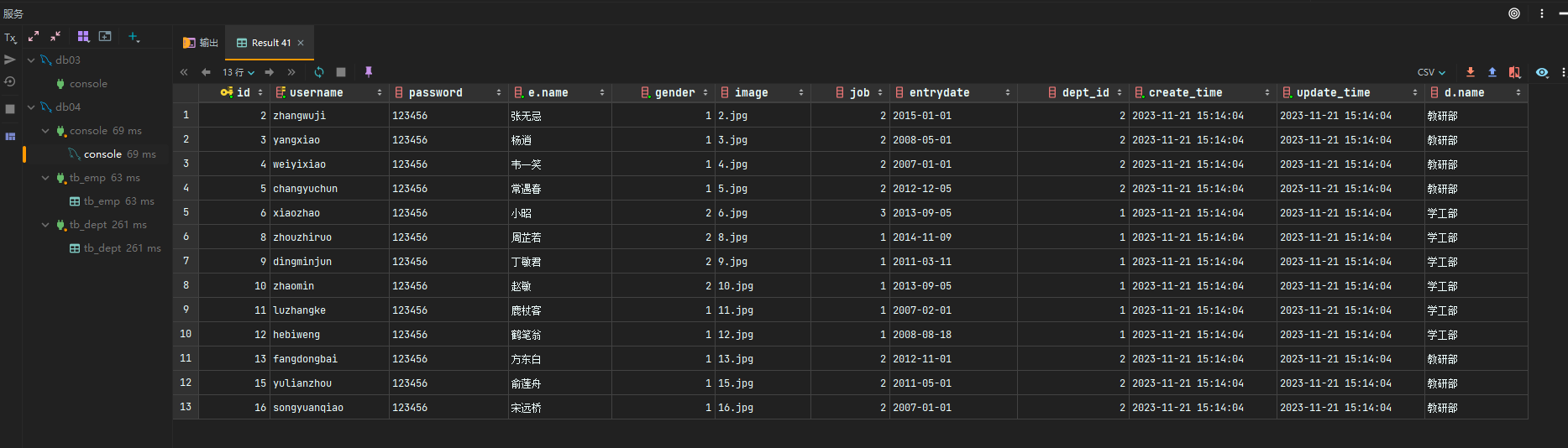
案例
根据需求,完成多表查询的SQL语句的编写
- 将资料中准备好的多表查询的数据准备的SQL脚本导入数据库中。
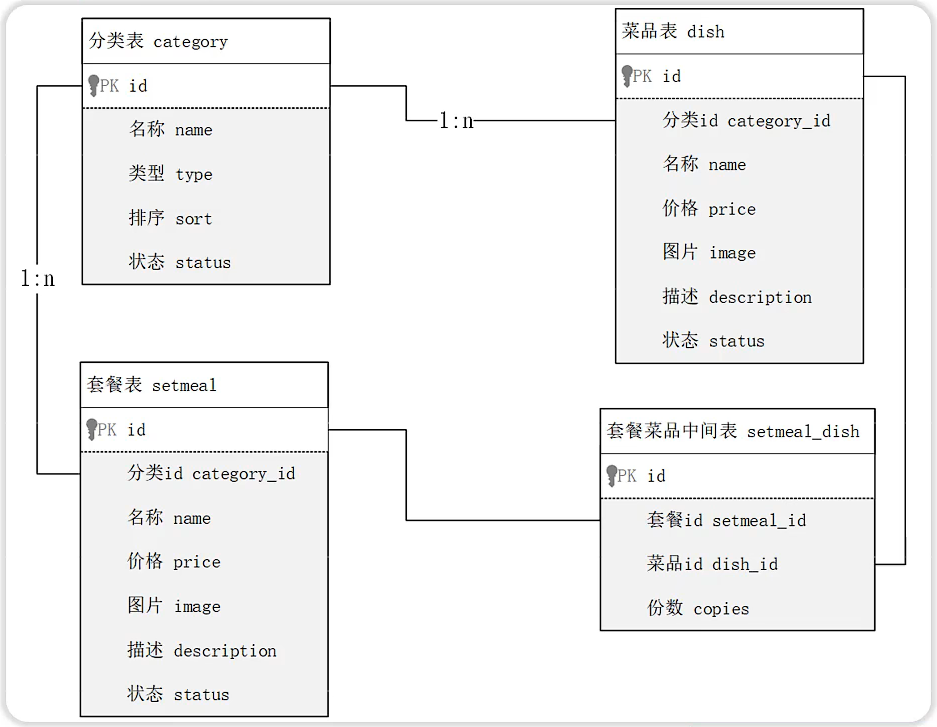
数据准备
-- 分类表
create table category(
id int unsigned primary key auto_increment comment '主键ID',
name varchar(20) not null unique comment '分类名称',
type tinyint unsigned not null comment '类型 1 菜品分类 2 套餐分类',
sort tinyint unsigned not null comment '顺序',
status tinyint unsigned not null default 0 comment '状态 0 禁用,1 启用',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '更新时间'
) comment '分类' ;
-- 菜品表
create table dish(
id int unsigned primary key auto_increment comment '主键ID',
name varchar(20) not null unique comment '菜品名称',
category_id int unsigned not null comment '菜品分类ID',
price decimal(8, 2) not null comment '菜品价格',
image varchar(300) not null comment '菜品图片',
description varchar(200) comment '描述信息',
status tinyint unsigned not null default 0 comment '状态, 0 停售 1 起售',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '更新时间'
) comment '菜品';
-- 套餐表
create table setmeal(
id int unsigned primary key auto_increment comment '主键ID',
name varchar(20) not null unique comment '套餐名称',
category_id int unsigned not null comment '分类id',
price decimal(8, 2) not null comment '套餐价格',
image varchar(300) not null comment '图片',
description varchar(200) comment '描述信息',
status tinyint unsigned not null default 0 comment '状态 0:停用 1:启用',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '更新时间'
)comment '套餐' ;
-- 套餐菜品关联表
create table setmeal_dish(
id int unsigned primary key auto_increment comment '主键ID',
setmeal_id int unsigned not null comment '套餐id ',
dish_id int unsigned not null comment '菜品id',
copies tinyint unsigned not null comment '份数'
)comment '套餐菜品中间表';
-- ================================== 导入测试数据 ====================================
-- category
insert into category (id, type, name, sort, status, create_time, update_time) values (1, 1, '酒水饮料', 10, 1, '2022-08-09 22:09:18', '2022-08-09 22:09:18');
insert into category (id, type, name, sort, status, create_time, update_time) values (2, 1, '传统主食', 9, 1, '2022-08-09 22:09:32', '2022-08-09 22:18:53');
insert into category (id, type, name, sort, status, create_time, update_time) values (3, 2, '人气套餐', 12, 1, '2022-08-09 22:11:38', '2022-08-10 11:04:40');
insert into category (id, type, name, sort, status, create_time, update_time) values (4, 2, '商务套餐', 13, 1, '2022-08-09 22:14:10', '2022-08-10 11:04:48');
insert into category (id, type, name, sort, status, create_time, update_time) values (5, 1, '经典川菜', 6, 1, '2022-08-09 22:17:42', '2022-08-09 22:17:42');
insert into category (id, type, name, sort, status, create_time, update_time) values (6, 1, '新鲜时蔬', 7, 1, '2022-08-09 22:18:12', '2022-08-09 22:18:28');
insert into category (id, type, name, sort, status, create_time, update_time) values (7, 1, '汤类', 11, 1, '2022-08-10 10:51:47', '2022-08-10 10:51:47');
-- dish
insert into dish (id, name, category_id, price, image, description, status, create_time, update_time) values (1,'王老吉', 1, 6.00, 'https://reggie-itcast.oss-cn-beijing.aliyuncs.com/41bfcacf-7ad4-4927-8b26-df366553a94c.png', '', 1, '2022-06-09 22:40:47', '2022-06-09 22:40:47');
insert into dish (id, name, category_id, price, image, description, status, create_time, update_time) values (2,'北冰洋', 1, 4.00, 'https://reggie-itcast.oss-cn-beijing.aliyuncs.com/4451d4be-89a2-4939-9c69-3a87151cb979.png', '还是小时候的味道', 1, '2022-06-10 09:18:49', '2022-06-10 09:18:49');
insert into dish (id, name, category_id, price, image, description, status, create_time, update_time) values (3,'雪花啤酒', 1, 4.00, 'https://reggie-itcast.oss-cn-beijing.aliyuncs.com/bf8cbfc1-04d2-40e8-9826-061ee41ab87c.png', '', 1, '2022-06-10 09:22:54', '2022-06-10 09:22:54');
insert into dish (id, name, category_id, price, image, description, status, create_time, update_time) values (4,'米饭', 2, 2.00, 'https://reggie-itcast.oss-cn-beijing.aliyuncs.com/76752350-2121-44d2-b477-10791c23a8ec.png', '精选五常大米', 1, '2022-06-10 09:30:17', '2022-06-10 09:30:17');
insert into dish (id, name, category_id, price, image, description, status, create_time, update_time) values (5,'馒头', 2, 1.00, 'https://reggie-itcast.oss-cn-beijing.aliyuncs.com/475cc599-8661-4899-8f9e-121dd8ef7d02.png', '优质面粉', 1, '2022-06-10 09:34:28', '2022-06-10 09:34:28');
insert into dish (id, name, category_id, price, image, description, status, create_time, update_time) values (6,'老坛酸菜鱼', 5, 56.00, 'https://reggie-itcast.oss-cn-beijing.aliyuncs.com/4a9cefba-6a74-467e-9fde-6e687ea725d7.png', '原料:汤,草鱼,酸菜', 1, '2022-06-10 09:40:51', '2022-06-10 09:40:51');
insert into dish (id, name, category_id, price, image, description, status, create_time, update_time) values (7,'经典酸菜鮰鱼', 5, 66.00, 'https://reggie-itcast.oss-cn-beijing.aliyuncs.com/5260ff39-986c-4a97-8850-2ec8c7583efc.png', '原料:酸菜,江团,鮰鱼', 1, '2022-06-10 09:46:02', '2022-06-10 09:46:02');
insert into dish (id, name, category_id, price, image, description, status, create_time, update_time) values (8,'蜀味水煮草鱼', 5, 38.00, 'https://reggie-itcast.oss-cn-beijing.aliyuncs.com/a6953d5a-4c18-4b30-9319-4926ee77261f.png', '原料:草鱼,汤', 1, '2022-06-10 09:48:37', '2022-06-10 09:48:37');
insert into dish (id, name, category_id, price, image, description, status, create_time, update_time) values (9,'清炒小油菜', 6, 18.00, 'https://reggie-itcast.oss-cn-beijing.aliyuncs.com/3613d38e-5614-41c2-90ed-ff175bf50716.png', '原料:小油菜', 1, '2022-06-10 09:51:46', '2022-06-10 09:51:46');
insert into dish (id, name, category_id, price, image, description, status, create_time, update_time) values (10,'蒜蓉娃娃菜', 6, 18.00, 'https://reggie-itcast.oss-cn-beijing.aliyuncs.com/4879ed66-3860-4b28-ba14-306ac025fdec.png', '原料:蒜,娃娃菜', 1, '2022-06-10 09:53:37', '2022-06-10 09:53:37');
insert into dish (id, name, category_id, price, image, description, status, create_time, update_time) values (11,'清炒西兰花', 6, 18.00, 'https://reggie-itcast.oss-cn-beijing.aliyuncs.com/e9ec4ba4-4b22-4fc8-9be0-4946e6aeb937.png', '原料:西兰花', 1, '2022-06-10 09:55:44', '2022-06-10 09:55:44');
insert into dish (id, name, category_id, price, image, description, status, create_time, update_time) values (12,'炝炒圆白菜', 6, 18.00, 'https://reggie-itcast.oss-cn-beijing.aliyuncs.com/22f59feb-0d44-430e-a6cd-6a49f27453ca.png', '原料:圆白菜', 1, '2022-06-10 09:58:35', '2022-06-10 09:58:35');
insert into dish (id, name, category_id, price, image, description, status, create_time, update_time) values (13,'清蒸鲈鱼', 5, 98.00, 'https://reggie-itcast.oss-cn-beijing.aliyuncs.com/c18b5c67-3b71-466c-a75a-e63c6449f21c.png', '原料:鲈鱼', 1, '2022-06-10 10:12:28', '2022-06-10 10:12:28');
insert into dish (id, name, category_id, price, image, description, status, create_time, update_time) values (14,'东坡肘子', 5, 138.00, 'https://reggie-itcast.oss-cn-beijing.aliyuncs.com/a80a4b8c-c93e-4f43-ac8a-856b0d5cc451.png', '原料:猪肘棒', 1, '2022-06-10 10:24:03', '2022-06-10 10:24:03');
insert into dish (id, name, category_id, price, image, description, status, create_time, update_time) values (15,'梅菜扣肉', 5, 58.00, 'https://reggie-itcast.oss-cn-beijing.aliyuncs.com/6080b118-e30a-4577-aab4-45042e3f88be.png', '原料:猪肉,梅菜', 1, '2022-06-10 10:26:03', '2022-06-10 10:26:03');
insert into dish (id, name, category_id, price, image, description, status, create_time, update_time) values (16,'剁椒鱼头', 5, 66.00, 'https://reggie-itcast.oss-cn-beijing.aliyuncs.com/13da832f-ef2c-484d-8370-5934a1045a06.png', '原料:鲢鱼,剁椒', 1, '2022-06-10 10:28:54', '2022-06-10 10:28:54');
insert into dish (id, name, category_id, price, image, description, status, create_time, update_time) values (17,'馋嘴牛蛙', 5, 98.00, 'https://reggie-itcast.oss-cn-beijing.aliyuncs.com/7a55b845-1f2b-41fa-9486-76d187ee9ee1.png', '配料:鲜活牛蛙,丝瓜,黄豆芽', 1, '2022-06-10 10:37:52', '2022-06-10 10:37:52');
insert into dish (id, name, category_id, price, image, description, status, create_time, update_time) values (18,'鸡蛋汤', 7, 4.00, 'https://reggie-itcast.oss-cn-beijing.aliyuncs.com/c09a0ee8-9d19-428d-81b9-746221824113.png', '配料:鸡蛋,紫菜', 1, '2022-06-10 10:54:25', '2022-06-10 10:54:25');
insert into dish (id, name, category_id, price, image, description, status, create_time, update_time) values (19,'平菇豆腐汤', 7, 6.00, 'https://reggie-itcast.oss-cn-beijing.aliyuncs.com/16d0a3d6-2253-4cfc-9b49-bf7bd9eb2ad2.png', '配料:豆腐,平菇', 1, '2022-06-10 10:55:02', '2022-06-10 10:55:02');
-- setmeal
insert into setmeal (id, category_id, name, price, status, description, image, create_time, update_time) values (1, 4, '商务套餐A', 20.00, 1, '', 'https://reggie-itcast.oss-cn-beijing.aliyuncs.com/21a5ed3a-97f6-447a-af9d-53deabfb5661.png', '2022-06-10 10:58:09', '2022-06-10 10:58:09');
insert into setmeal (id, category_id, name, price, status, description, image, create_time, update_time) values (2, 4, '商务套餐B', 22.00, 1, '', 'https://reggie-itcast.oss-cn-beijing.aliyuncs.com/8d0075f8-9008-4390-94ca-2ca631440304.png', '2022-06-10 11:00:13', '2022-06-10 11:11:37');
insert into setmeal (id, category_id, name, price, status, description, image, create_time, update_time) values (3, 3, '人气套餐A', 49.00, 1, '', 'https://reggie-itcast.oss-cn-beijing.aliyuncs.com/8979566b-0e17-462b-81d8-8dbace4138f4.png', '2022-06-10 11:11:23', '2022-06-10 11:11:23');
-- setmeal_dish
insert into setmeal_dish (id, setmeal_id, dish_id, copies) values (1, 1, 1, 1);
insert into setmeal_dish (id, setmeal_id, dish_id, copies) values (2, 1, 4, 1);
insert into setmeal_dish (id, setmeal_id, dish_id, copies) values (3, 1, 11, 1);
insert into setmeal_dish (id, setmeal_id, dish_id, copies) values (4, 2, 2, 1);
insert into setmeal_dish (id, setmeal_id, dish_id, copies) values (5, 2, 4, 1);
insert into setmeal_dish (id, setmeal_id, dish_id, copies) values (6, 2, 9, 1);
insert into setmeal_dish (id, setmeal_id, dish_id, copies) values (7, 3, 2, 1);
insert into setmeal_dish (id, setmeal_id, dish_id, copies) values (8, 3, 6, 1);
insert into setmeal_dish (id, setmeal_id, dish_id, copies) values (9, 3, 5, 1);
案例需求
-
– 1. 查询价格低于 10元 的菜品的名称 、价格 及其 菜品的分类名称 .
-
– 2. 查询所有价格在 10元(含)到50元(含)之间 且 状态为’起售’的菜品名称、价格 及其 菜品的分类名称 (即使菜品没有分类 , 也需要将菜品查询出来).
-
– 3. 查询每个分类下最贵的菜品, 展示出分类的名称、最贵的菜品的价格 .
-
– 4. 查询各个分类下 状态为 ‘起售’ , 并且 该分类下菜品总数量大于等于3 的 分类名称 .
-
– 5. 查询出 “商务套餐A” 中包含了哪些菜品 (展示出套餐名称、价格, 包含的菜品名称、价格、份数).
-
– 6. 查询出低于菜品平均价格的菜品信息 (展示出菜品名称、菜品价格).
案例解决示例
-- 1. 查询价格低于 10元 的菜品的名称 、价格 及其 菜品的分类名称 .
select d.name, price, c.name
from dish d,
category c
where d.category_id = c.id
and price < 10;
-- 2. 查询所有价格在 10元(含)到50元(含)之间 且 状态为'起售'的菜品名称、价格 及其 菜品的分类名称 (即使菜品没有分类 , 也需要将菜品查询出来).
select d.name, price, c.name
from dish d
left join
category c on d.category_id = c.id
where price between 10 and 50
and d.status = 1;
-- 3. 查询每个分类下最贵的菜品, 展示出分类的名称、最贵的菜品的价格 .
select c.name, d.name, max(price)
from dish d,
category c
where d.category_id = c.id
group by c.name;
-- 4. 查询各个分类下 状态为 '起售' , 并且 该分类下菜品总数量大于等于3 的 分类名称 .
select c.name, count(*)
from dish d,
category c
where d.category_id = c.id
and c.status = 1
group by c.name
having count(*) >= 3;
-- 5. 查询出 "商务套餐A" 中包含了哪些菜品 (展示出套餐名称、价格, 包含的菜品名称、价格、份数).
select s.name, s.price, d.name, d.price, copies
from setmeal s,
setmeal_dish sd,
dish d
where s.id = sd.setmeal_id
and sd.dish_id = d.id
and s.name = '商务套餐A';
-- 6. 查询出低于菜品平均价格的菜品信息 (展示出菜品名称、菜品价格).
-- 表:dish
-- SQL:
-- a.计算 菜品的平均价格
select avg(price)
from dish;
-- b. 查询出低于菜品平均价格的菜品信息
select *
from dish
where price < 37.736842;
-- c.合并SQL
select *
from dish
where price < (select avg(price) from dish);
小结
-
内连接
隐式:
select 字段列表 from 表1, 表2 where 条件...;显示:
select 字段列表 from 表1 [inner] join 表2 on 条件...; -
外连接
左外:
select 字段列表 from 表1 left join 表2 on 条件...;右外:
select 字段列表 from 表1 right join 表2 on 条件...; -
子查询
- 标量子查询
- 列子查询
- 行子查询
- 表子查询
事务
思考
场景
- 学工部整个部门解散了,该部门及部门下的员工都需要删除了。
操作
-- 删除学工部 delete from tb_dept where id = 1; -- 删除学工部的员工 delete from tb_emp where dept_id = 1;问题
- 如果删除部门成功了,而删除该部门的员工时失败了,就造成了数据的不一致
介绍&操作
介绍
概念
事物是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败
注意事项
默认MySQL的事务是自动提交的,也就是说,当执行一条DML语句,MySQL会立即隐式的提交事务
操作
事务控制
- 开启事务:
start transaction; / begin;- 提交事务:
commit- 回滚事务:
rollback;
四大特性(ACID)

小结
-
事务介绍
一组操作的集合,这组操作要么全部成功,要么全部失败
-
事务操作
start transaction / begin; commit; rollback; -
事务四大特性
- 原子性
- 一致性
- 隔离性
- 持久性
数据库优化
索引
介绍
概念
索引(index)是帮助数据库高效获取数据的数据结构
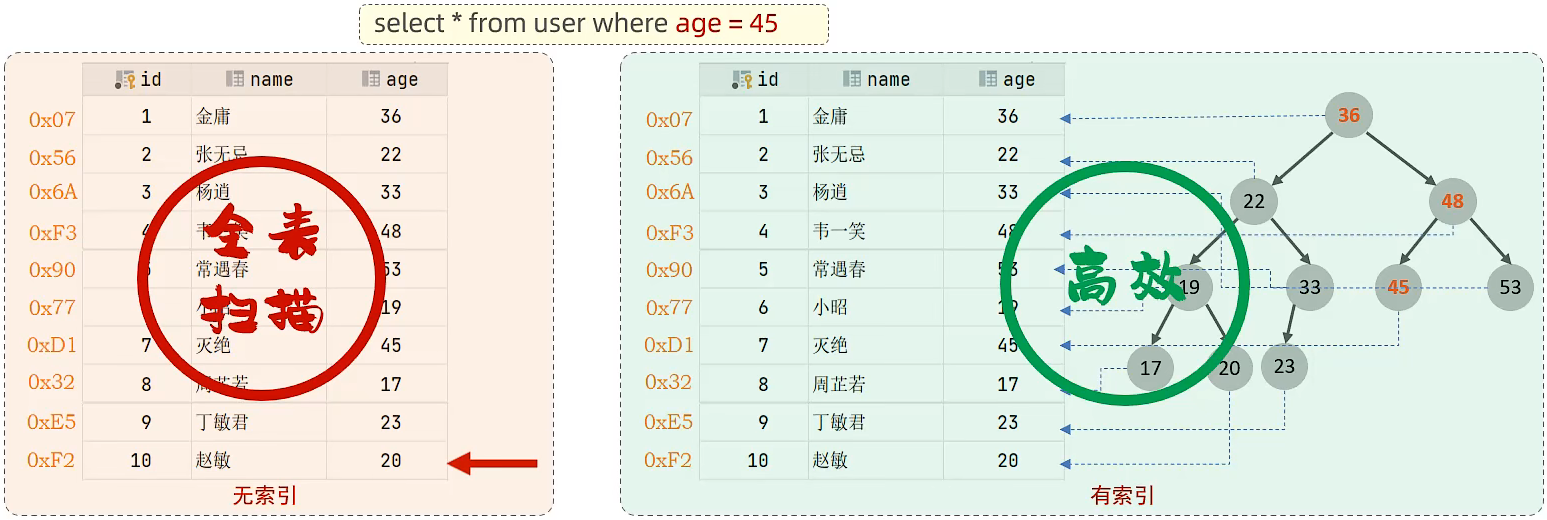
优缺点
优点
- 提高数据的查询效率,降低数据库的IO成本
- 通过索引列对数据进行排序,降低数据排序的成本,降低CPU消耗
缺点
- 索引会占用存储空间
- 索引会大大提高了查询效率,同时也降低了insert、update、delete的效率
结构
MySQL数据库支持的索引结构有很多,如:Hash索引、B+Tree索引、Full-Text索引等。我们平时说的索引,如果没有特别指明,都是默认的B+Tree结构组织的索引。
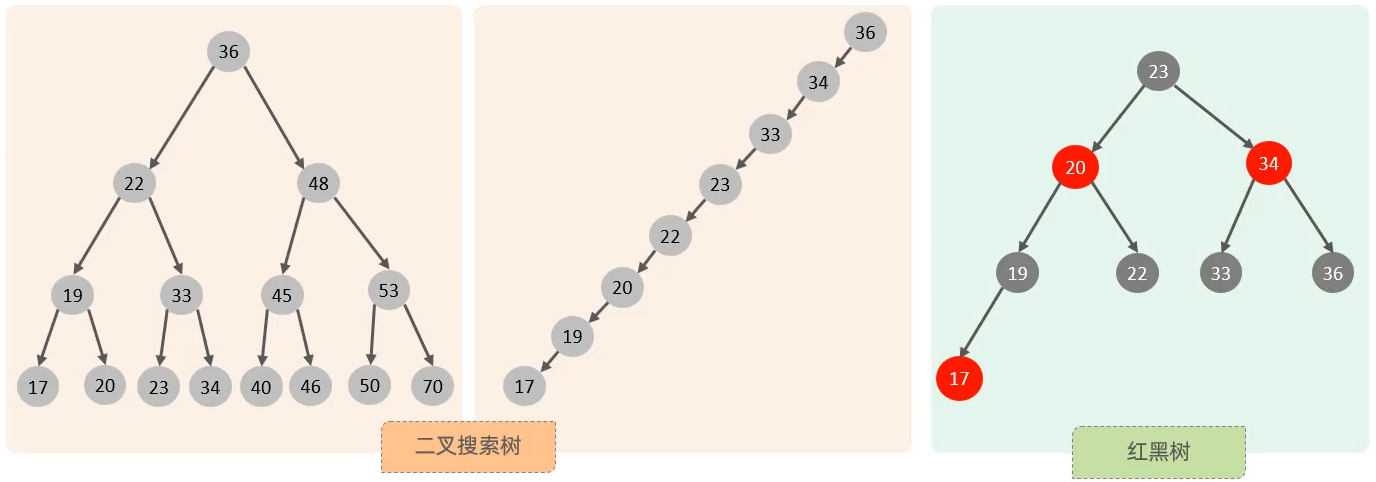
思考:存在什么问题?
大数据量情况下,层级深,检索速度慢
- B+Tree(多路平衡搜索树)
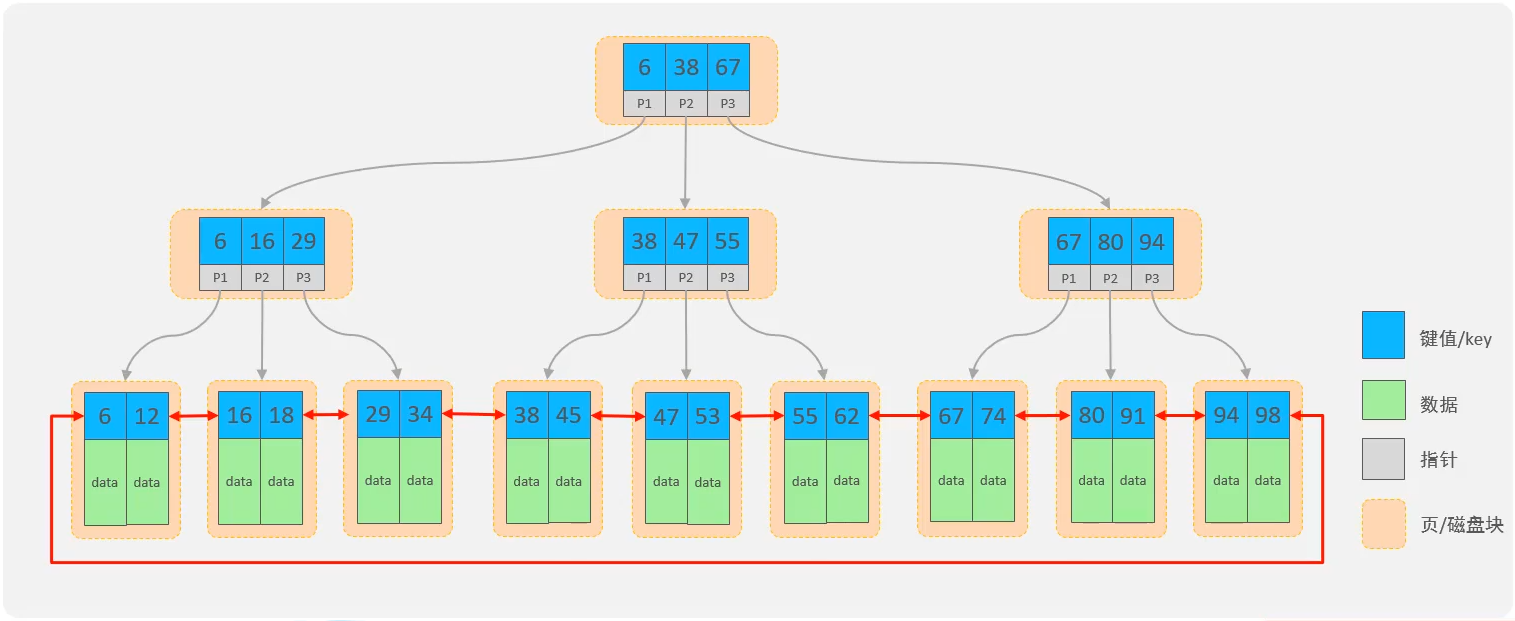
- 每一个节点,可以存储多个key(有n个key,就有n个指针)。
- 所有的数据都存储在子叶节点,非子叶节点仅用于索引数据。
- 子叶节点形成了一颗双向链表,便于数据的排序及区间范围查询。
语法
-
创建索引
create [unique] index 索引名 on 表名(字段名,...); -
查看索引
show index from 表名; -
删除索引
drop index 索引名 on 表名;
示例
-- 创建:为tb_emp表的name字段建立一个索引
create index idx_emp_name on tb_emp(name);
-- 查询:查询tb_emp表的索引信息
show index from tb_emp;
-- 删除:删除tb_emp表中name字段的索引
drop index idx_emp_name on tb_emp;
注意事项
- 主键字段,在建表时,会自动创建主键索引。
- 添加唯一约束,时数据库实际上会添加唯一索引。
小结
-
介绍
索引是帮助数据库高效获取数据的数据结构
-
结构
MySQL数据库中默认的索引结构是B+Tree
-
语法
-- 创建 create [unique] index 索引名 on 表名(字段名,...); -- 查询 show index from 表名; -- 删除 drop index 索引名 on 表名;
[外链图片转存中…(img-ISDCQVyK-1700729341869)]
小结
-
事务介绍
一组操作的集合,这组操作要么全部成功,要么全部失败
-
事务操作
start transaction / begin; commit; rollback; -
事务四大特性
- 原子性
- 一致性
- 隔离性
- 持久性
数据库优化
索引
介绍
概念
索引(index)是帮助数据库高效获取数据的数据结构
[外链图片转存中…(img-6jYDMBfT-1700729341870)]
优缺点
优点
- 提高数据的查询效率,降低数据库的IO成本
- 通过索引列对数据进行排序,降低数据排序的成本,降低CPU消耗
缺点
- 索引会占用存储空间
- 索引会大大提高了查询效率,同时也降低了insert、update、delete的效率
结构
MySQL数据库支持的索引结构有很多,如:Hash索引、B+Tree索引、Full-Text索引等。我们平时说的索引,如果没有特别指明,都是默认的B+Tree结构组织的索引。
[外链图片转存中…(img-biITHPma-1700729341870)]
思考:存在什么问题?
大数据量情况下,层级深,检索速度慢
- B+Tree(多路平衡搜索树)
[外链图片转存中…(img-gS4x8a7D-1700729341871)]
- 每一个节点,可以存储多个key(有n个key,就有n个指针)。
- 所有的数据都存储在子叶节点,非子叶节点仅用于索引数据。
- 子叶节点形成了一颗双向链表,便于数据的排序及区间范围查询。
语法
-
创建索引
create [unique] index 索引名 on 表名(字段名,...); -
查看索引
show index from 表名; -
删除索引
drop index 索引名 on 表名;
示例
-- 创建:为tb_emp表的name字段建立一个索引
create index idx_emp_name on tb_emp(name);
-- 查询:查询tb_emp表的索引信息
show index from tb_emp;
-- 删除:删除tb_emp表中name字段的索引
drop index idx_emp_name on tb_emp;
注意事项
- 主键字段,在建表时,会自动创建主键索引。
- 添加唯一约束,时数据库实际上会添加唯一索引。
小结
-
介绍
索引是帮助数据库高效获取数据的数据结构
-
结构
MySQL数据库中默认的索引结构是B+Tree
-
语法
-- 创建 create [unique] index 索引名 on 表名(字段名,...); -- 查询 show index from 表名; -- 删除 drop index 索引名 on 表名;