作者简介
九号,携程数据技术专家,关注数据仓库架构、数据湖、流式计算、数据治理。
一、背景
元数据MetaData狭义的解释是用来描述数据的数据,广义的来看,除了业务逻辑直接读写处理的那些业务数据,所有其它用来维持整个系统运转所需的信息/数据都可以叫作元数据。比如数据表格的Schema信息,任务的血缘关系,用户和脚本/任务的权限映射关系信息等等。
在数据仓库的建设质量的评估中,一个必不可少的评价指标就是数据产出的及时性,特别是对于P0级别的流程,及时性指标的好坏一方面决定了下游应用方能否准时地获取所需的业务指标,直接影响到业务的工作效率;另一方面也反映了相应指标的数据架构的合理程度。
数据及时性,顾名思义就是测试数据需要按时产出。及时性重点关注的三个要素是:定时调度时间、数据任务优先级以及数据产出deadline。其中任务的优先级决定了它获取数据计算资源的多少,影响了任务执行时长。数据deadline则是数据最晚产出时间的统一标准,需要严格遵守。这三要素中,属于业内统一认知且在质量保障阶段需要重点关注的是:数据deadline,这也是我们优化数据流程产出的最终评判标准。
二、问题
上述部分已经阐述了数据及时性的重要性和评判标准,在通常情况下,为了提升数据及时性,需要投入人力对重点数据流程进行优化。
但针对数据仓库业界来讲,对于一个重要的数据结果,其上游可能存在几十个层级,数百个不同的数据处理任务,从最初的数据到最终的结果,数据流转过程极其复杂,传统的通过人工逐个排查的方式去定位影响数据流程产出的问题节点,存在如下的三项缺点:
1)覆盖的任务范围有限;
2)效率低下,判断标准不统一,判定准确率不高;
3)无法形成知识沉淀,依赖于个人能力;
如果数据流程未能充分优化,一方面会存在数据结果产出时间不稳定,影响数据的及时性;另一方面也会造成计算资源和存储资源的浪费,并且也不易于后续维护。
三、方案
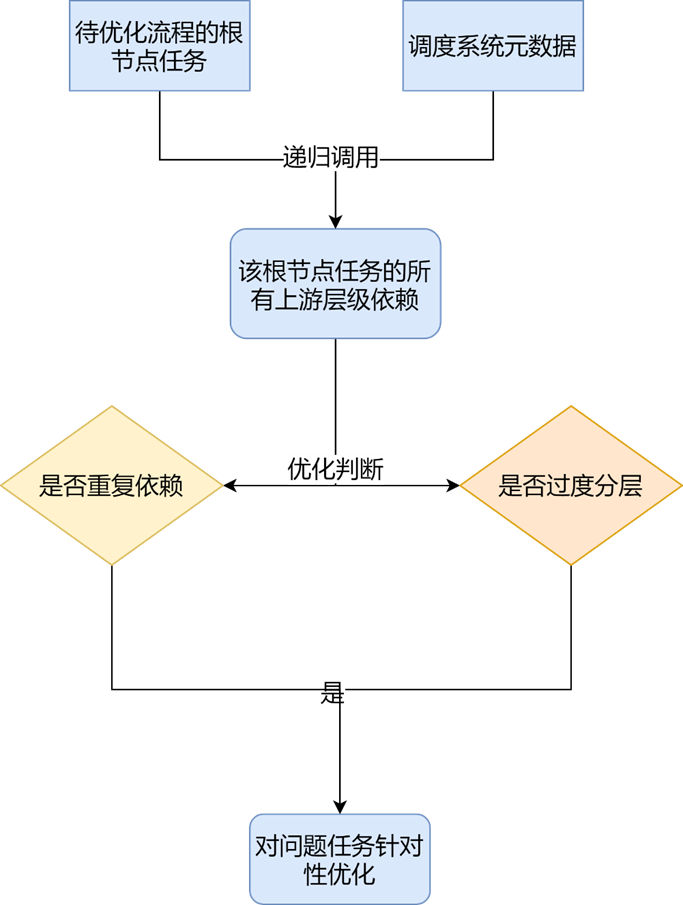
为了避免上述的问题,提升数据流程优化的效率和质量,我们采用了从血缘元数据出发的方案。在数仓任务的执行中,都会依赖于一个调度系统组件,目前业内通用的是以DAG为核心的工作流系统,数据流程中的每个任务都会设置定时执行或者配置上游依赖,这些设置的上游依赖就是我们方案中需要的调度血缘的元数据。
基于上述的血缘数据,我们的方案中需要实现以下两个功能:
基于任务之间的血缘关系生成所有上游任务的层级依赖数据
以调度系统本身的元数据作为出发点,调度系统自身的元数据就包含了一个任务的上游和下游依赖,基于这个数据,通过层级递归的扫描,就可以得到指定根节点任务的所有上游任务的层级依赖结果。
设计合理的算法定位到有问题的任务
在上一步骤得到指定根节点任务的所有上游任务的层级依赖结果后,通过如下三种逻辑定位有问题的任务:
1)定位过度分层:JobA的下游只有JobA1在使用,且JobA是JobA1产出的关键路径,也即JobA1的产出时间由JobA决定,那么此种情形下,我们可以把JobA的逻辑合并到JobA1,这样一方面可以减少大数据任务的启动消耗时间和获取资源的时间;另一方面也可以减少依赖层级,方便后续维护。
2)定位重复依赖:在较复杂的数据流程中,会出现如下的情况:JobB2依赖JobB1和JobB,而JobB1也同时依赖JobB,简化后的情况如下图:
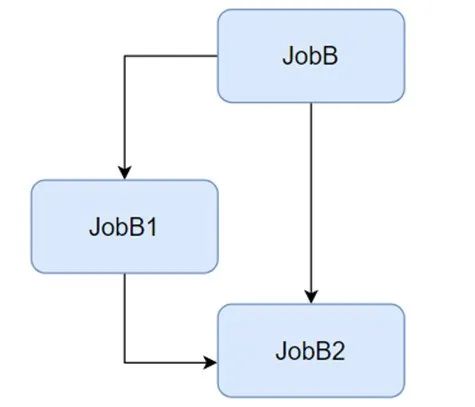
此时我们就可以检查JobB2的逻辑,考虑任务内容中涉及到JobB的逻辑合并到JobB1,从而可以实现流程依赖和代码逻辑的合并优化,降低维护成本,提升整体产出时间。
3)定位关键路径:在完成上述两个步骤后,整个流程从结构上已经基本没问题,如果要进一步优化产出时间,需要针对特定任务进行调优,此时可以基于已有的上游层级依赖数据,计算得到每个层级的最晚产出的任务Id,这些任务Id串联在一起就是影响整个流程产出的关键路径,然后对关键路径上的任务进行调优。
上述方案的整体设计图如下:
四、案例
在对酒店订单明细宽表的优化过程中,基于前期的元数据建设,主要的工作内容分为以下三个步骤:
1)调度优化。调度优化的出发点是合理分配同步任务的优先级,将非核心任务的数据同步延后。从而降低0到2点,酒店订单宽表核心流程执行期间的集群资源压力。
2)模型优化。在这一步骤中,我主要是从两个方向出发:
减少跨层级重复依赖,避免相似逻辑代码的出现,提升数据结果的复用能力。
避免滥用分层,对冗余的分层、中间表进行合并,减少任务调度链路的层级,减少Job数量,节省Job的启动时间。
3)任务优化。通过调整参数设置、SQL逻辑优化的方式对具体任务进行优化需要优化的任务。这一步骤的工作也就是传统认知中的任务优化。
其中第二步和第三步就是基于本文中的方案快速定位到问题任务,整体优化后的效果如下:
酒店订单明细宽表的7日平均产出时间由2:51提前到1:36,提升45%
全流程任务总数量从211个降到145个,减少32%
可控上游依赖任务(非外BU任务)总数量由180降到117,减少35%
关键链路调度层级由11层减少到6层,且其中两层是外部BU任务
五、展望
基于元数据和血缘建设,本方案后续有如下三点可以深入优化:
跨多层判断重复依赖。由于上述实际案例中的酒店订单流程相对不复杂,在仅进行一层的重复依赖判断后,就已经达到了比较满意的优化效果,所以为继续进行多层重复依赖的判断,但从血缘结构上是可以支持多层判断的。
定位多Job中重复/相似逻辑。多个任务依赖同一个上游任务,可以人工进行判断是否存在可合并的重复/相似逻辑;这一点如果要提升效率,需要再结合表的血缘关系一起判断。
多数据流程的优化。在数仓的工作中,一个主题域产出的结果表,通常会存在多张,在进行整个主题域流程的优化或者重构中,也可以利用本案的思想,结构化进行优化工作,提升效率。
【推荐阅读】