Ma M, Ren J, Zhao L, et al. Smil: Multimodal learning with severely missing modality[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(3): 2302-2310.[开源]
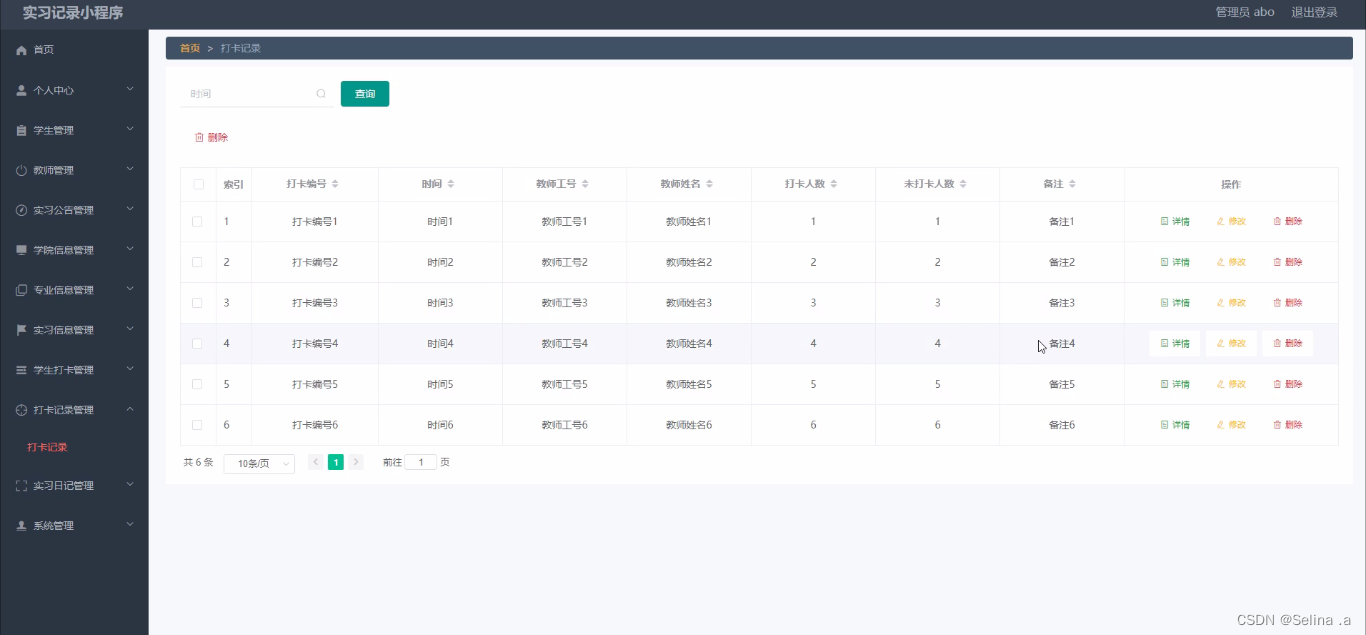
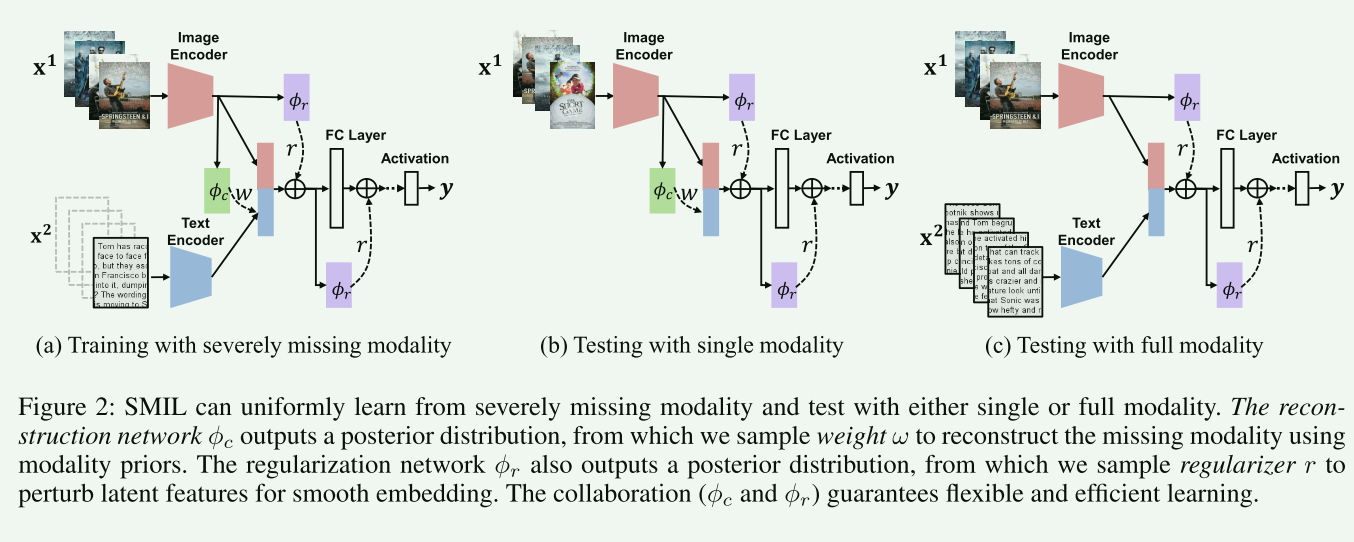
本文的核心思想是探讨和解决多模态学习中的一个重要问题:在训练和测试数据中严重缺失某些模态时,如何有效进行学习。具体来说,这里的“严重缺失”指的是在多达90%的训练样本中缺少一些模态信息。在过去的研究中,大多关注于如何处理测试数据的模态不完整性,而对于训练数据的模态不完整性,尤其是严重缺失的情况,探讨较少。文章提出了一种新的方法——SMIL(Severely Missing Modality in Multimodal Learning),使用贝叶斯元学习来同时实现两个目标:灵活性(在训练、测试或两者中处理缺失模态)和效率(从不完整的模态中高效学习)。核心思想是通过扰动潜在特征空间,使单一模态的嵌入能够近似全模态的嵌入。为了验证这一方法的有效性,作者在三个流行的基准数据集(MM-IMDb, CMU-MOSI 和 avMNIST)上进行了一系列实验。结果表明,SMIL在处理严重模态缺失的多模态学习问题方面,相比现有方法和生成型基准(如自编码器和生成对抗网络)具有更好的性能。
- 模态重建
模态重建是通过使用重建网络来实现的。该网络利用可用的模态信息来生成缺失模态的近似值,从而在潜在特征空间中生成完整的数据,并促进两个方面的灵活性。一方面,该模型可以通过使用完整和不完整的数据进行联合训练来挖掘混合数据的全部潜力。另一方面,在测试时,通过打开或关闭特征重建网络,该模型可以以统一的方式处理不完整或完整的输入。具体来说,重建网络被训练来预测先验权重的权重,而不是直接生成缺失模态。这是通过学习一组可以使用 K-means 或 PCA 在所有模态完整样本之间聚类的模态先验 M 来实现的。然后,通过计算模态先验的加权和来重建缺失模态。这种方法可以有效地处理缺失模态问题,并在实验中取得了良好的结果。
- 不确定性引导特征正则化
该网络通过对特征进行扰动来评估数据的不确定性,并将不确定性评估用作特征正则化,以克服模型和数据偏差。具体来说,该网络使用一组随机噪声向量来扰动输入特征,并计算每个扰动的输出的方差。然后,将方差用作特征正则化的权重,以减少特征之间的差异。这种方法可以有效地处理低质量和不完整的特征,并提高多模态模型的鲁棒性和泛化能力。与之前的确定性正则化方法相比,不确定性引导特征正则化可以显著提高模型的容量和性能。
- 贝叶斯元学习框架
通过利用贝叶斯元学习框架来联合优化所有网络实现的。具体来说,主网络 f θ f_{\theta} fθ在重构 f ϕ ϕ f_{\phi_{\phi}} fϕϕ网络和正则化 f ϕ r f_{\phi_{r}} fϕr网络的帮助下在 D m D_m Dm上进行元训练。然后,在 D f D_f Df上对更新后的主网络 f θ ∗ f_{\theta^{*}} fθ∗进行元测试。最后,通过梯度下降元更新网络参数 { θ , ϕ c , ϕ r } \left\{\boldsymbol{\theta}, \boldsymbol{\phi}_{c}, \boldsymbol{\phi}_{r}\right\} {θ,ϕc,ϕr}。该框架旨在优化目标函数,即最小化 L ( D f ; θ ∗ , ψ ) \mathcal{L}\left(\mathcal{D}^{f} ; \boldsymbol{\theta}^{*}, \boldsymbol{\psi}\right) L(Df;θ∗,ψ),其中 θ ∗ = θ − α ∇ θ L ( D m ; ψ ) \boldsymbol{\theta}^{*}=\boldsymbol{\theta}-\alpha \nabla_{\boldsymbol{\theta}} \mathcal{L}\left(\mathcal{D}^{m} ; \boldsymbol{\psi}\right) θ∗=θ−α∇θL(Dm;ψ), ψ = { ϕ c , ϕ r } \psi=\left\{\phi_{c}, \phi_{r}\right\} ψ={ϕc,ϕr}表示重构和正则化网络参数的组合。贝叶斯元学习的目标是最大化条件似然: log p ( Y ∣ X ; θ ) \log p(\mathbf{Y} \mid \mathbf{X} ; \boldsymbol{\theta}) logp(Y∣X;θ)。然而,解决它涉及到不可行的真后验 p ( z ∣ X ) p(z|X) p(z∣X)。因此,通过一种分摊分布 q ( z ∣ X ; ψ ) q(z|X;ψ) q(z∣X;ψ)来近似真后验分布,并且近似的下限形式可以定义为 L θ , ψ = E q ( z ∣ X ; θ , ψ ) [ log p ( Y ∣ X , z ; θ ) ] − KL [ q ( z ∣ X ; ψ ) ∥ p ( z ∣ X ) ] . \begin{aligned} \mathcal{L}_{\boldsymbol{\theta}, \boldsymbol{\psi}}=\boldsymbol{E}_{q(\mathbf{z} \mid \mathbf{X} ; \boldsymbol{\theta}, \boldsymbol{\psi})}[\log p(\mathbf{Y} \mid \mathbf{X}, \mathbf{z} ; \boldsymbol{\theta})]- & \operatorname{KL}[q(\mathbf{z} \mid \mathbf{X} ; \boldsymbol{\psi}) \| p(\mathbf{z} \mid \mathbf{X})] . \end{aligned} Lθ,ψ=Eq(z∣X;θ,ψ)[logp(Y∣X,z;θ)]−KL[q(z∣X;ψ)∥p(z∣X)].
我们通过蒙特卡罗(MC)抽样来最大化这个下界