目录
引言
一、导入包
二、dropout网络定义
三、创建模型,定义损失函数和优化器
四、加载数据
五、训练train
六、测试
引言
dropout正则化的原理相对简单但非常有效。它在训练神经网络时,以一定的概率(通常是在0.2到0.5之间)随机地将某些神经元的输出设置为零,即“关闭”这些神经元。这些“关闭”的神经元在整个训练过程中都不参与前向传播和反向传播。
这一过程有点类似于在每次训练迭代中从网络中删除一些神经元,然后在下一次迭代中再将它们添加回去。这种随机的“删除”和“添加”过程迫使网络不依赖于特定的神经元,从而提高了模型的泛化能力。
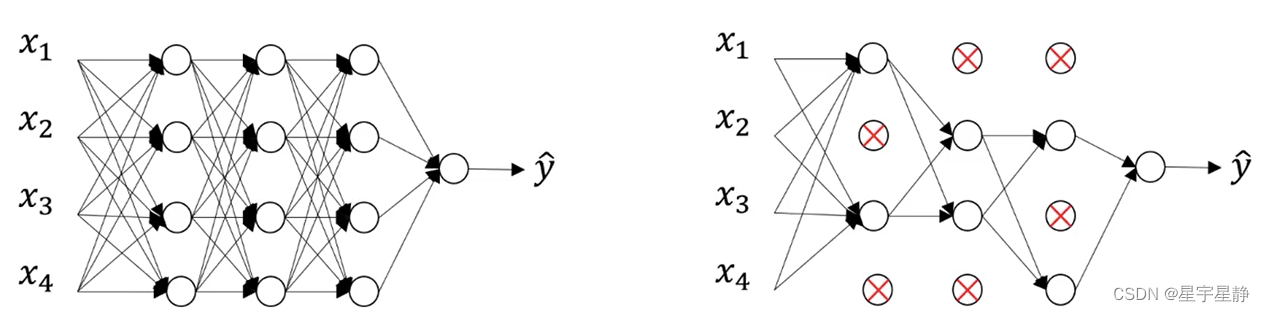
具体来说,dropout正则化有以下几个效果:
-
减少过拟合: 通过随机地关闭一些神经元,dropout可以减少神经网络对训练数据的过度拟合,使其更好地适应未见过的数据。
-
增加网络的鲁棒性: 由于每个神经元都有可能在任何时候被关闭,网络被迫学习对于任何输入都要保持稳健,而不是过于依赖某些特定的神经元。
-
防止协同适应: 在训练过程中,dropout可以防止神经元之间形成过于强烈的依赖关系,防止它们过分协同适应训练数据。
这一方法的关键在于,通过在训练期间随机地关闭一些神经元,模型不再依赖于任何一个特定的神经元,从而减少了过拟合的风险。在测试阶段,所有的神经元都被保留,但其输出值要按照训练时的概率进行缩放,以保持平衡。
一、导入包
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
二、dropout网络定义
# 定义一个带有 dropout 正则化的简单神经网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(10, 128)
self.relu = nn.ReLU()
self.dropout1 = nn.Dropout(0.5) # 添加50%的dropout
self.fc2 = nn.Linear(128, 64)
self.dropout2 = nn.Dropout(0.3) # 添加30%的dropout
self.fc3 = nn.Linear(64, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.dropout1(x)
x = self.fc2(x)
x = self.relu(x)
x = self.dropout2(x)
x = self.fc3(x)
x = self.sigmoid(x)
return x
三、创建模型,定义损失函数和优化器
# 创建模型,定义损失函数和优化器
model = Net()
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)四、加载数据
# 生成虚拟数据
torch.manual_seed(42)
X_train = torch.rand((1000, 10))
y_train = torch.randint(0, 2, (1000, 1)).float()
X_test = torch.rand((200, 10))
y_test = torch.randint(0, 2, (200, 1)).float()
# 创建数据加载器
train_dataset = TensorDataset(X_train, y_train)
test_dataset = TensorDataset(X_test, y_test)
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=32, shuffle=False)
五、训练train
# 训练循环
for epoch in range(10):
for inputs, labels in train_dataloader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
六、测试
# 测试循环
model.eval()
with torch.no_grad():
correct = 0
total = 0
for inputs, labels in test_dataloader:
outputs = model(inputs)
predicted = (outputs > 0.5).float()
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total
print(f"测试准确率:{accuracy * 100:.2f}%")
然后我们就可以模仿上述的案例自己修改一些其中的参数进行网络训练和调整了。