Author:rab
目录
- 前言
- 一、通配符
- 1.1 *
- 1.2 ?
- 1.3 []
- 1.4 {}
- 二、正则表达元字符
- 2.1 *
- 2.2 .
- 2.3 ^
- 2.4 $
- 2.5 []
- 2.6 \
- 2.7 \<\>
- 2.8 \{\}
- 总结
前言
不管是学任何语言,几乎都会涉及到通配符与正则的使用。有时候对于 Linux 初学者来说,往往会将通配符和正则表达搞混了。今天,我们来仔细研究一下 Linux 中通配符与正则元字符之间的细微区别。
一、通配符
在 Shell 中,通配符常用于文件名或路径名匹配的特殊字符,以下是一些常见的 Shell 通配符。
1.1 *
1、功能
匹配任意字符零次或多次。
2、案例
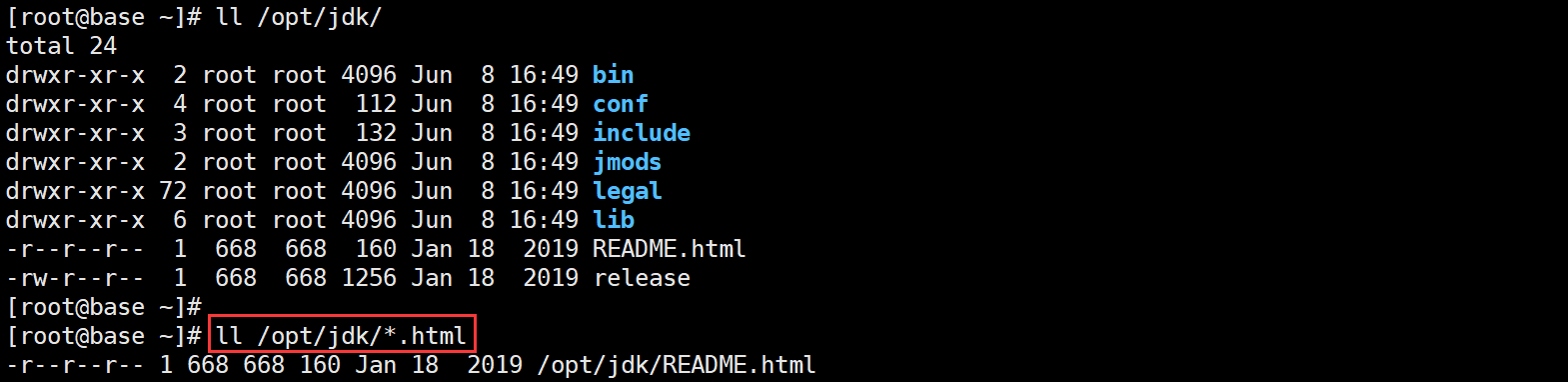
# 列出/opt/jdk目录下所有以.html结尾的所有文件
[root@base ~]# ll /opt/jdk/*.html
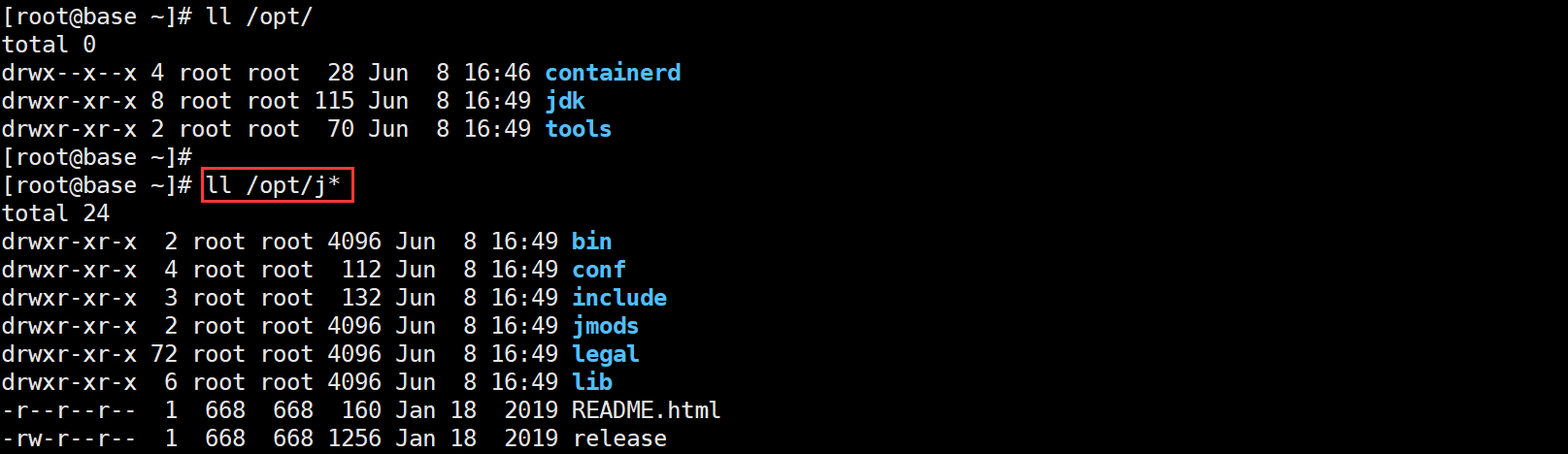
# 列出/opt目录下所有以j字母开头的目录名下的所有内容
[root@base ~]# ll /opt/j*
1.2 ?
1、功能
匹配任意单个字符,即只能匹配单个字符,且必须要匹配一个。
2、案例
# 列出/opt/jdk/目录下开头是READM结尾是.html,且在这开头和结尾之间只有任意一个字符的文件
# 比如下面案例就能匹配到:README.html、READMq.html、READMH.html等满足要求的文件
[root@base ~]# ll /opt/jdk/READM?.html

1.3 []
1、功能
匹配指定范围内的字符,如 [0-9] 匹配任意数字。
2、案例
# 创建两个测试文件
[root@base opt]# touch 1.txt 22.txt
# 匹配数字开头的文件
[root@base opt]# ll [0-9]*

# 匹配数字开头的文件(此时只能是单个数字开头的才能被匹配到)
[root@base opt]# ll [0-9].txt

1.4 {}
1、功能
用于生成花括号内的字符串模式的所有可能组合,用逗号隔开。如:{1,22}.txt 匹配 1.txt 或 22.txt 文件。要注意的是 {} 中至少有两个匹配对象,否则会报错,具体看下图。
2、案例
# 查看(匹配)1.txt与22.txt文件
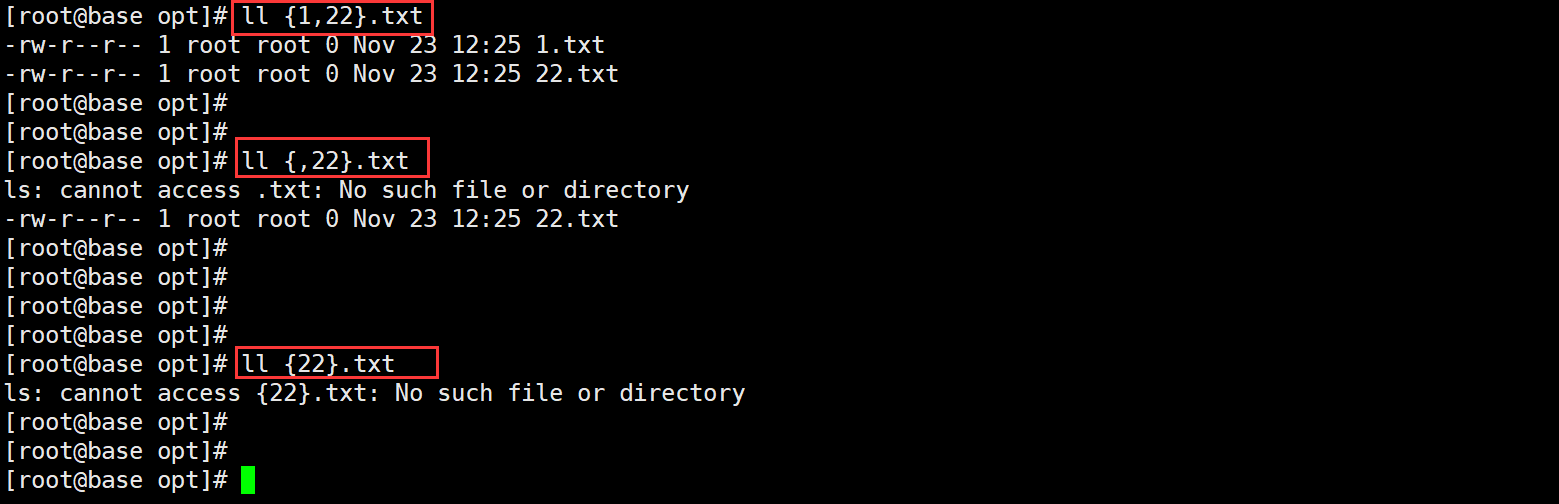
# 其他案例
1.复制多个文件
cp file{1,2,3}.txt destdir/ # 该命令会复制 file1.txt、file2.txt 和 file3.txt 到目标目录destdir下
2.重命名文件
mv oldfile{,.bak} # 该命令会将 oldfile 重命名为 oldfile.bak
3. 创建多个目录
mkdir {dir1,dir2,dir3} # 该命令会创建 dir1、dir2 和 dir3 三个目录
4.数字范围
touch file{1..5}.txt # 该命令将会创建 file1.txt 到 file5.txt 五个文件
5.生成组合文件
echo {aa,bb}_{cc,dd}.txt # 该命令将会生成aa_cc、aa_dd、bb_cc、bb_dd四种组合文件(注意下划线不是非必须的)

二、正则表达元字符
正则表达用于更通用的文本模式匹配,可以在文本中查找、匹配和提取特定的模式。
2.1 *
1、功能
匹配 * 前一个字符 0 次或多次,如:she*ll,就表示匹配 e 字符 0 次或多次重复,如 shll、shell、sheel、sheeeel 等。
2、案例
# 匹配字符a零次或重复多次
b # 它能匹配是因为满足了匹配字符a零次
ab # 它能匹配是因为满足了匹配字符a一次
aab # 它能匹配是因为满足了匹配字符a重复两次

那正则中的 * 如何像通配符中的 * 匹配任意呢?采用 .* 即可,. 接下来会讲到。
ls | grep 'file.*\.txt'
# 该命令会列出当前目录中所有以 "file" 开头,后面跟着任意字符,然后是 ".txt" 结尾的文件。
# 如file.txt、filexsd.txt、fileodcfrgop.txt等文件均会被匹配
# 为什么会这样呢?因为.表示匹配任意单个字符,然后*又表示匹配其前面字符(即.)0次或重复多次
# 所以在正则中.*就相当于,没有()、一个点(.)、两个点(..)、三个点(...)、以此类推。
2.2 .
1、功能
用于匹配任意单个字符,如:..6. 表示前面两个字符可为任意单个字符,第四个字符也为单个任意字符,如 aa6k、So68 等均能匹配。
2、案例
# 匹配文件中满足的所有内容,如下图,被匹配的部分会被标红

2.3 ^
1、功能
用于匹配行首,表示行首的字符是 ^ 后面的那些字符,如:^rab 表示匹配以 rab 字符开头的所有行。
2、案例
# 匹配file.txt文件中内容所有以ab开头的行(说白了被匹配到的都会被标红)

2.4 $
1、功能
用于匹配行尾,表示行尾的字符是 $ 前面的那些字符,如:rab$ 表示匹配以 rab 字符结尾的所有行。
2、案例
grep 'ab$' file.txt
常用:匹配空白行
grep '^$' file.txt # ^$表示匹配file.txt文件的所有空白行
grep -v '^$' file.txt # -v选项表示取反,即过滤掉file.txt文件中的空白行
2.5 []
1、功能
用于匹配字符合集,即匹配中括号中的某个字符。如:
[xyz]:将会匹配字符 x、y 或 z 单个字符。[a-z]:将会匹配字符 a~z 之间的任意单个字符(包括 a 和 z)。[a-zA-Z]:将会匹配小写字符 a~z 之间或大写字符 A~Z 之间的任意单个字符(包括 a/A 和 z/Z)。[a-z0-9]:将会匹配小写字符 a~z 之间或数字0~9之间的任意单个字符。[^a-z]:在 [] 中的 ^ 符号表示取反,即匹配除了小写字符 a~z 之外的任意单个字符。[][][]:多个 [] 组合能够匹配一般的单词或数字,如:[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]就可以匹配我们的手机号(即任意 11 位纯数字的组合)。
2、案例
这种正则匹配的组合与我们通配符的 {} 组合功能相似。
2.6 \
1、功能
实现转义,什么是转义,顾名思义:即改变原本内容的含义。比如,\^、\$ 等,原本在正则中 ^ 表示匹配以 xxx 开头的行,$ 表示以 xxx 结尾的行。那如果被我们使用 \ 进行转义后,就不再具备正则中以xxx开头、以xxx结尾的原本含义了,而仅仅就是字面上所见的原生符号(而不具备任何意义,仅作为一个单纯的占位字符),当我们对某些没有意义的特殊符号进行转义时,也会使这些没有意义的特殊符号具备一定的意义。
2、案例
# 即使具备有意义的字符转义为无意义的字符

注意:转义符 \ 仅转义与它相邻的那个原字符。
2.7 <>
1、功能
该正则表达使用转义符号 \ 来表示,将没有任何意义的 < 符号进行转义后, < 符号就具备了一定意义了。因此 \<rab\> 就表示完整匹配整个单词 rab。
2、案例
# 仅仅匹配有rab单词的行,即使其他行也有rab关键字,但也不会被匹配,因为其他行的rab与其他字符相邻了

# 继续看下面案例,当我的rab关键字与其他字符不相邻时就可以被匹配

2.8 {}
1、功能
同样是通过转义字符 \ 来转义,用于表示前一个字符的重复此时,此时有以下几种情况:
-
\{n\}匹配 {} 前面的字符 n 次,如:
ra\{3\}b匹配raaab。 -
\{n,\}匹配 {} 前面的字符至少 n 次,如:
ra\{3,\}b匹配raaab、raaaaaab等。 -
\{n,m\}匹配 {} 前面的字符 n 次与 m 次之间,如:
ra\{3,6\}b匹配raaab、raaaaaab等。
2、案例
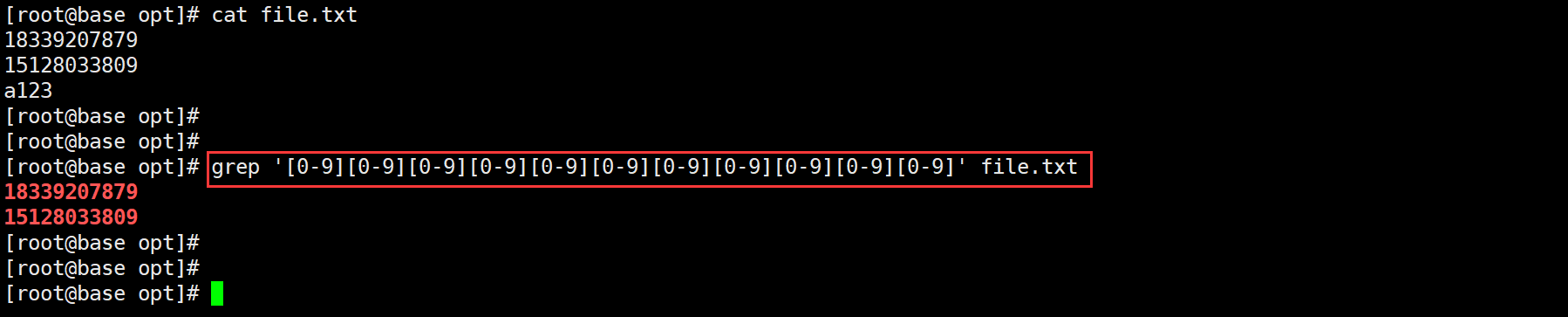
# 比如匹配文件中的手机号(如下图)
# 为什么会匹配到手机号呢?因为{}会先匹配其前面的字符[]11次,而每次都是[0-9]
# 相当于:[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]的效果

注意:你会发现,通配符和正则表达元字符都有 * 号,那这两个符号怎么区分呢?其实这两个是相辅相成的,如果满足通配符表达则匹配,如果满足正则表达则匹配,如果同时满足通配和正则表达则均匹配,如下案例。

总结
在使用时,需要根据具体的需求选择合适的匹配方法。在 Shell 脚本中,通常会使用通配符,而在需要更复杂模式匹配的文本处理场景中,则会使用正则表达式。
—END