参考文献:
[1] Vocoder (由助教許博竣同學講授)哔哩哔哩bilibili
[2] Oord A, Dieleman S, Zen H, et al. Wavenet: A generative model for raw audio[J]. arXiv preprint arXiv:1609.03499, 2016.
[3] https://deepmind.com/blog/article/wavenet-generative-model-raw-audio
[4] Review: DilatedNet — Dilated Convolution (Semantic Segmentation) | by Sik-Ho Tsang | Towards Data Science
[5] Jin Z, Finkelstein A, Mysore G J, et al. FFTNet: A real-time speaker-dependent neural vocoder[C]//2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2018: 2251-2255.
[6] Kalchbrenner N, Elsen E, Simonyan K, et al. Efficient neural audio synthesis[C]//International Conference on Machine Learning. PMLR, 2018: 2410-2419.
[7] Prenger R, Valle R, Catanzaro B. Waveglow: A flow-based generative network for speech synthesis[C]//ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019: 3617-3621.
[8] Flow-based Deep Generative Models | Lil'Log (lilianweng.github.io)
[9] 细水长flow之NICE:流模型的基本概念与实现 - 科学空间|Scientific Spaces (kexue.fm)
目录
一、Introduction
Spectrogram 与 phase
Waveform Synthesis Methods
Vocoder 为什么独立研究
二、Neural Vocoder——WaveNet
WaveNet 思路
WaveNet 架构
WaveNet Softmax Distribution
WaveNet Dilated Causal Convolution
WaveNet Residual and Skip Connections
Conditional WaveNet
WaveNet 总结
三、Neural Vocoder——FFTNet
FFTNet 架构
FFTNet 小技巧
FFTNet 总结
四、Neural Vocoder——WaveRNN
WaveRNN Dual Softmax Layer
WaveRNN 架构
WaveRNN 加速小技巧
WaveRNN 总结
五、Neural Vocoder——WaveGlow
Flow-Based Model
WaveGlow 架构
WaveGlow 总结
六、Vocoder Conclusion
一、Introduction
Vocoder:当涉及语音合成时,vocoder是一个重要的组成部分,它负责将数字化的语音信号转换回可听的声音。Vocoder是“Voice Coder”的缩写,它是一种处理语音信号的算法或设备,用于分析和合成声音。它接收数字信号(通常是通过语音识别等手段得到的),并对其进行处理,使之变成人耳能够理解的声音信号。
-
首先我们大概讲一下 Vocoder 是干什么的。之前说过,一般在模型中操作的都是声谱 spectrogram,而 Vocoder 就是将 spectrogram 转为我们可以听的声音信号的。
Spectrogram 与 phase
-
要搞懂 Vocoder,首先我们需要知道 Spectrogram 是怎么来的。已知我们有一段声音信号 x,则有以下过程
-
STFT:“Short-Time Fourier Transform”(短时傅立叶变换)。它是一种信号处理技术,用于将信号从时域转换到频域。STFT 通过在时域上应用傅里叶变换的窗口,将信号分解为时间上局部化的频谱信息。
-
t:时间
-
f:频率
-
-
首先对声音信号进行 STFT,得到一个关于时间和频率的函数 X,由于完成傅里叶变换后得到的结果通常都是复数,因此可以表示为 Ae^iθ 的形式,其中 A 就是振幅(amplitude),θ 就是相位(phase)。不同时间,不同频率都有自己的振幅和相位。而这里的 A 就是 Spectrogram。
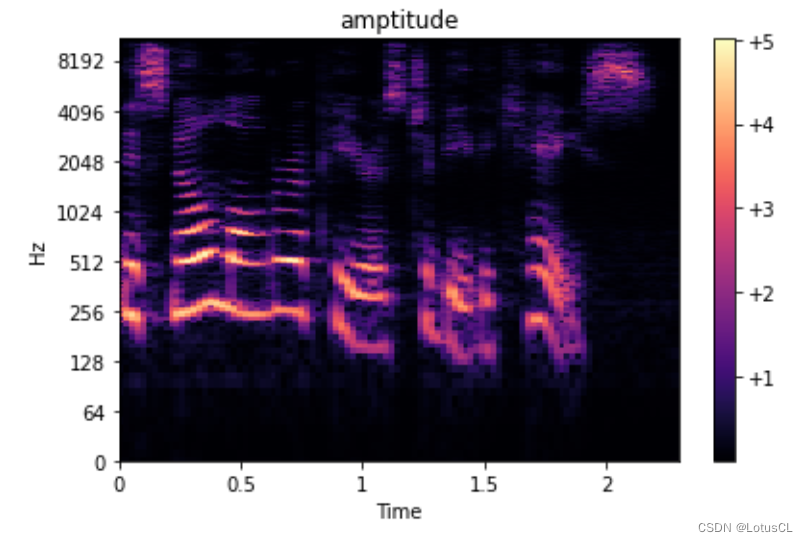
-
也就是说,Spectrogram 距离声音信号还缺少相位的信息。奇怪了,那我们之前生成的时候为什么抛弃掉了相位的信息呢?我们将相位画出,如图,可以看出来,相位信息几乎就相当于杂讯一般的存在。也就是说,无论是生成这个 phase,还是从 Spectrogram 中还原出 phase,都是非常困难的。
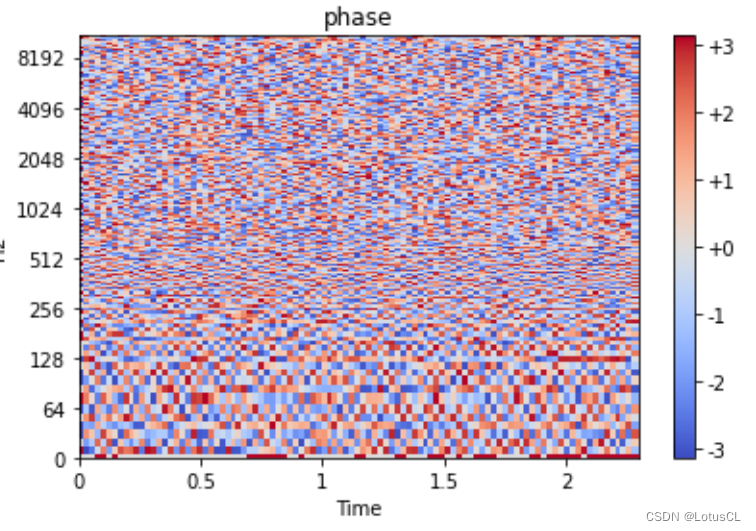
-
那问题就来了,phase 真的有这么重要吗,是不是随便给给就能合出比较好的声音了呢?在视频课程中,在随便给了 phase 后,声音就会变得非常奇怪,因此这个还是有点重要的,然而,phase 生成还是太难了。
Waveform Synthesis Methods
-
那不生成 phase,我们怎么合成出人类能听的声音信号,也就是波形(waveform)呢?我们决定使用模型生成出的声音特征(acoustic features),由它通过 Vocoder 直接生成波形。
-
Traditional Methods:
-
Heuristic methods:Griffin-Lim algorithm
Griffin-Lim算法是一种启发式方法,用于估计音频信号的相位信息,从而实现从幅度谱(amplitude)重建时域波形(waveform)。这个算法特别适用于声音合成或音频重建的场景。这个算法的基本思想是:通过对幅度谱的估计和随机初始化重建频谱的相位,然后反转这些估计的频谱,再次应用STFT来获得新的时域波形。然后重复这个过程,迭代多次,希望最终获得合理的相位估计。不过它生成的语音听起来还是不太自然。
-
-
Neural Vocoder:
-
Generative neural networks
遇事不决用神经网络是这样的(×),但是它生成出来的语音质量确实很好。
-
Directly generate waveform from acoustic features
-
Vocoder 为什么独立研究
-
我们可能很好奇,为什么 Vocoder 要单独拿来研究,而不是接在 TTS、VC 等模型后面直接做 End2End 训练呢?因为 Vocoder 是将频谱图转为波形的方式,只要生成的是频谱图,就可以使用 Vocoder,这使得其泛用性很高,而其他模型的生成目标就变成了生成频谱图,这会降低整个任务难度,使得它们能够更加专注于声音信号的处理。
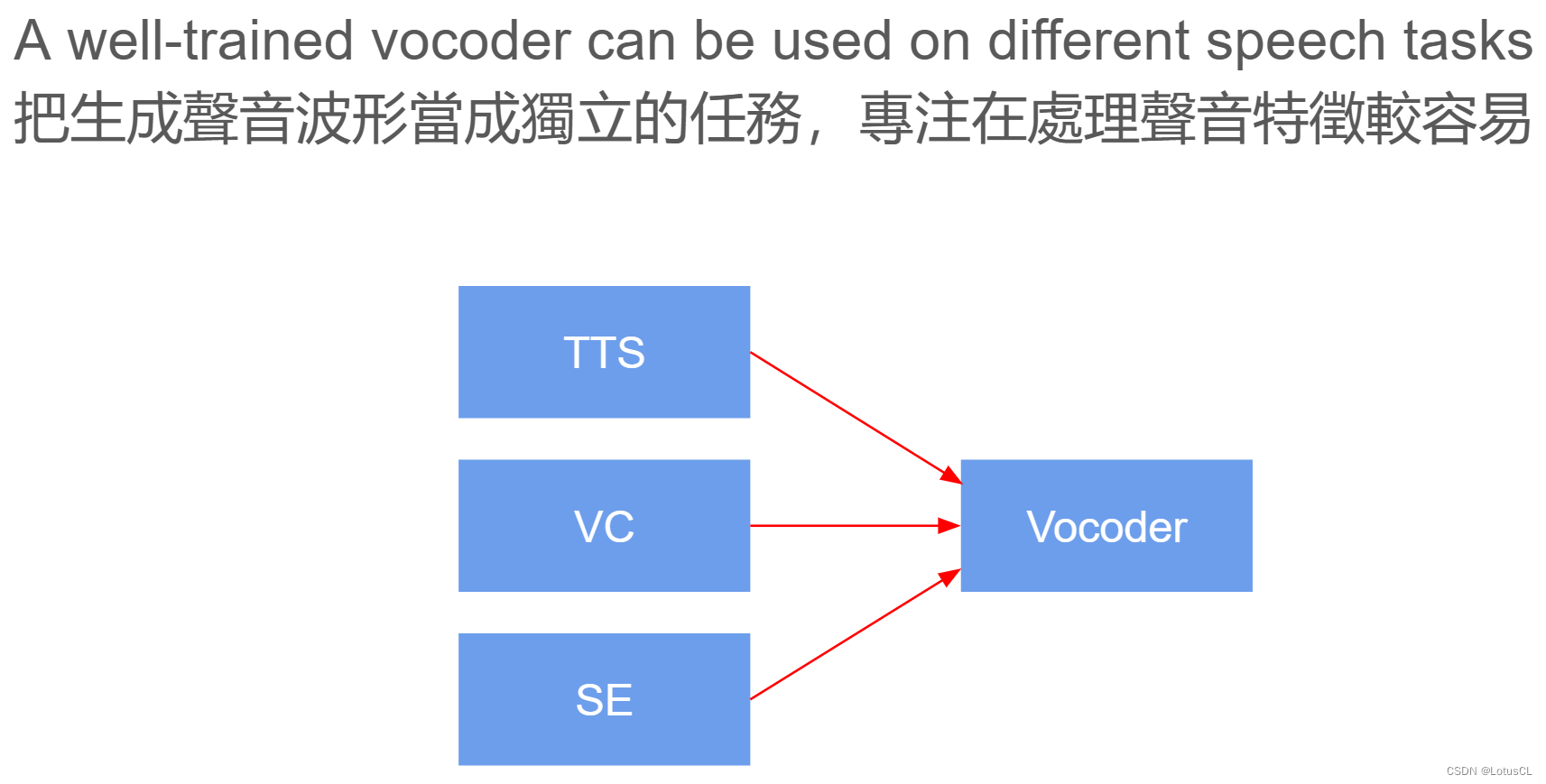
二、Neural Vocoder——WaveNet
WaveNet 思路
-
最早被提出生成波形的模型。其本质上就是一个自回归模型(autoregressive model)。这是怎么来的?
-
我们可以把波形放大,其实我们发现其本质上就是一个个数值连接起来的。
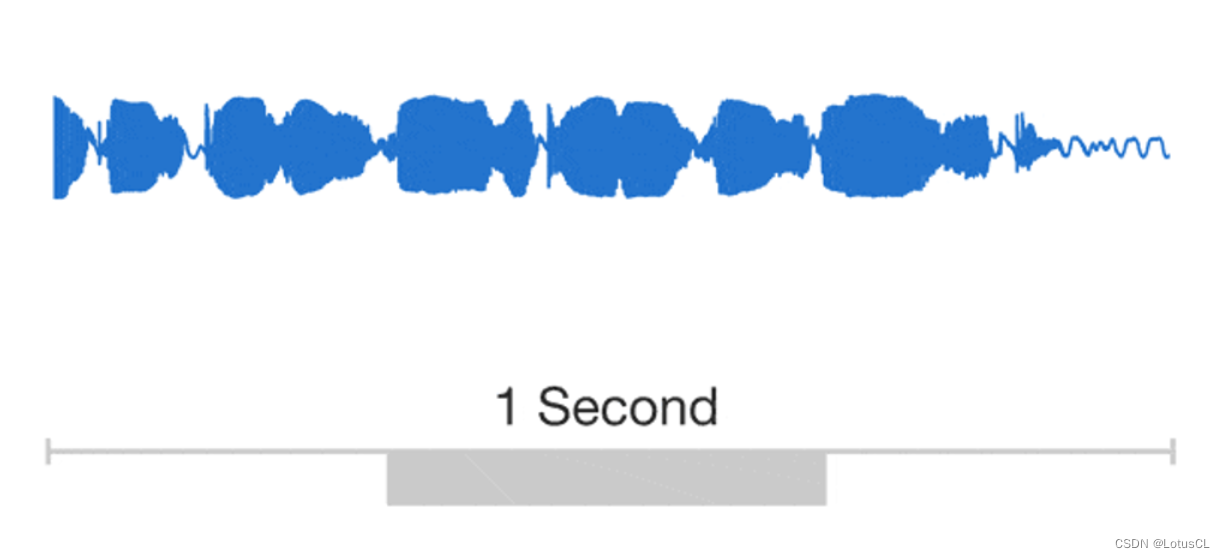
-
所以我们很自然的就能想到自回归模型。想要知道 xt 的值,就需要将 x1~xt-1 的值拿出来当成输入。而 WaveNet 就是这么做的。

-
一个值基于前面的值进行扩张卷积(Dilated Convolution),最终生成下一个值,然后生成的值又作为输出,去生成下下个值。
-
而 WaveNet 的主要构成成分就是因果卷积网络(Causal Convolution Network)。马上我们就细讲。这里可以简单了解一下。
Causal Convolution(因果卷积):是卷积神经网络中的一种卷积操作,它具有一种“因果性”约束,即输出中的每个元素只能依赖于输入序列中其之前的元素。这种约束在处理时间序列数据时非常有用,因为它确保模型不会“未来”依赖于当前时间步之后的信息。
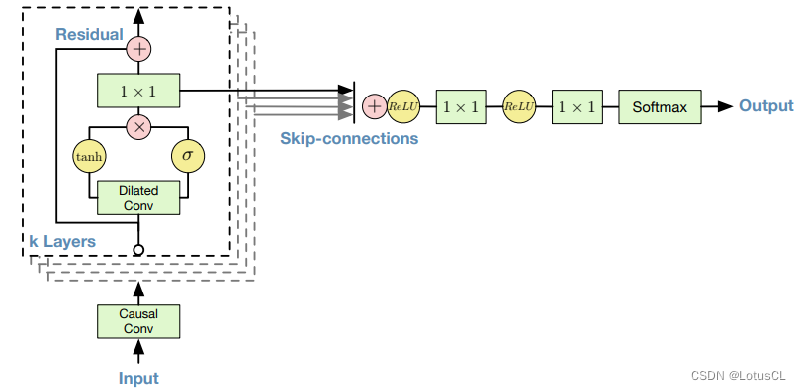
WaveNet 架构
Skip connections(跳跃连接):是指在神经网络中将某一层的输出直接连接到后续层的非相邻层或更深层的输入的技术。这种技术的主要目的是改善神经网络的训练效果、提高梯度传播和模型学习能力。
-
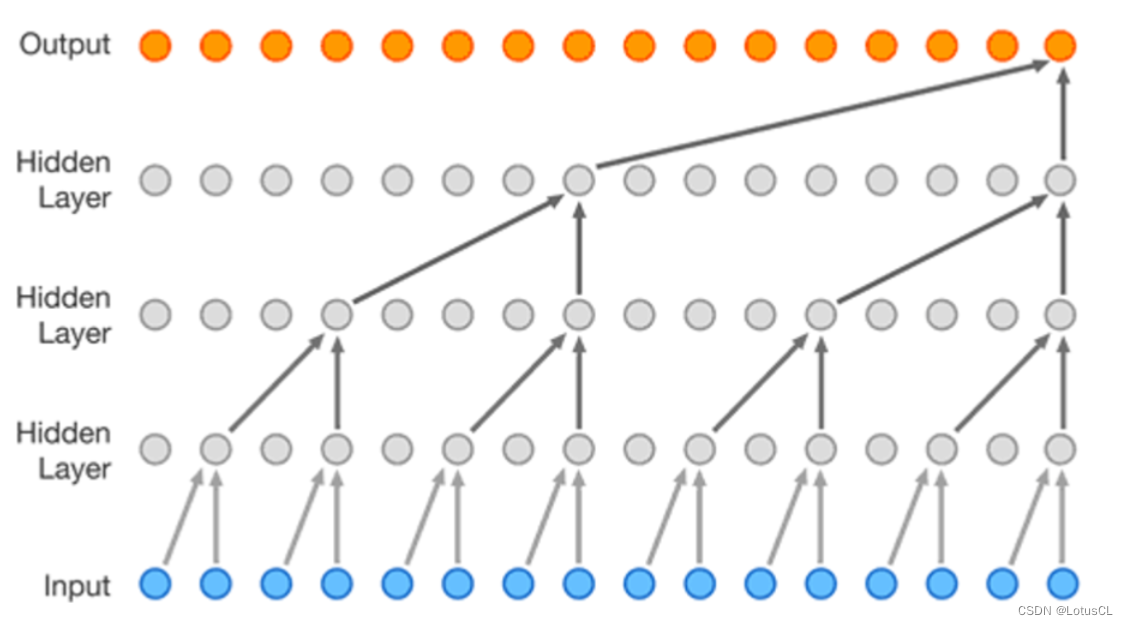
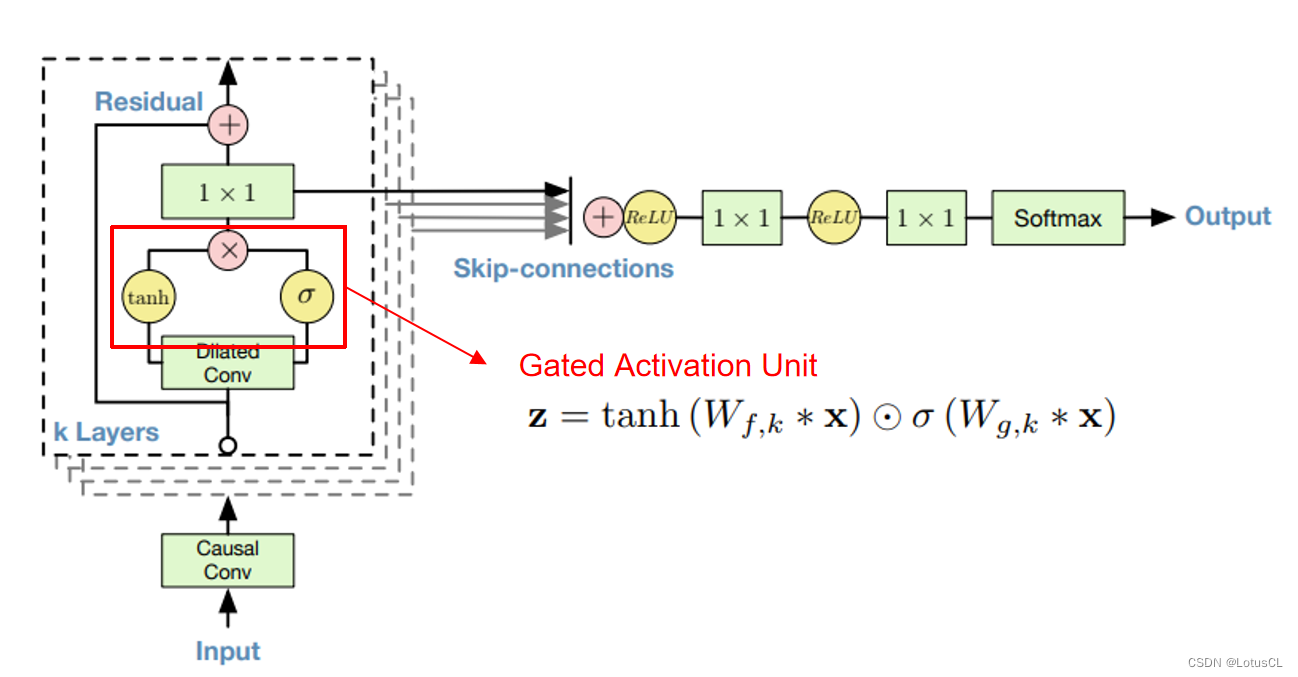
我们可以简单了解一下 WaveNet 的主要架构。Input 就是所谓的 x1~xt-1,Output 就是 xt。输入会率先进入因果卷积层(Casual Conv),然后进入扩张卷积层(Dilated Conv),经过不同的激活函数(activate function),将结果进行点乘,然后通过 1×1 的 CNN,之后和原来的结果相加(残差学习,residual learning),这样我们算作“一层”,这一层的输出会传到下一层中作为输入,一共会有 k 层。
-
而每一层的 CNN 输出又会被单独拉出来相加(这样的操作叫 Skip-connections),经过 ReLU、1×1 CNN、ReLU、1×1 CNN、Softmax,最终产生输出。
WaveNet Softmax Distribution
μ-law 编码算法:主要用于音频数据的压缩和量化。μ-law(mu-law)是一种非线性编码方式,通常用于将音频信号进行压缩,使其更适合于数字信号处理。它会将音频信号进行非线性变换,将输入信号的动态范围缩小,并且使较小幅度的信号更容易表示,减少了对噪音的敏感程度。这种编码方式能够在保留音频信号主要特征的同时,通过压缩和量化来减小数据量。
-
对于 WaveNet,原来声音信号是一系列数字的排列,这里会将其转为独热向量(one-hot vector)后再作为输入传入网络中。包括其输出也将为 one-hot vector sequence。
-
而我们也可以将产生声音信号的问题转为以下式子:
也即:给定 x1 到 xt-1,求取 xt 的概率分布。
-
而这也会导致一个问题。实际上,声音信号在电脑中都是使用 16-bit 的整数来存储的,这就意味着其范围是 [-32768, 32767],如果使用这种格式来对模型进行训练,那么问题就变成了一个有 65536 种类别的分类问题。类别太多,对模型来讲学习过于困难,所以我们希望把这 65536 个类别压缩成 256 个类别,也就是使用 8-bit 整数来表示声音信号的数据。那我们可以直接使用 Linear Mapping 进行转换吗?
-
不,我们不这么做。我们会先将 [-32768, 32767] 的范围线性压缩成 [-1, 1],然后再通过一个名为 μ-law 的算法,算法公式如下:
-
通过 μ-law 后范围还是 [-1, 1],然后再将其拉回 [0, 255] 范围中。整体的过程如下:
[-32768, 32767] (16-bit int) -> [-1, 1] -> [-1, 1] (μ-law) -> [0, 255] (8-bit int)
WaveNet Dilated Causal Convolution
-
我们之前说,WaveNet 主要组成成分是因果卷积网络(Causal Convolution),具体是一个值基于前面的值进行扩张卷积(Dilated Convolution)。那么这些网络名词是什么意思呢?
-
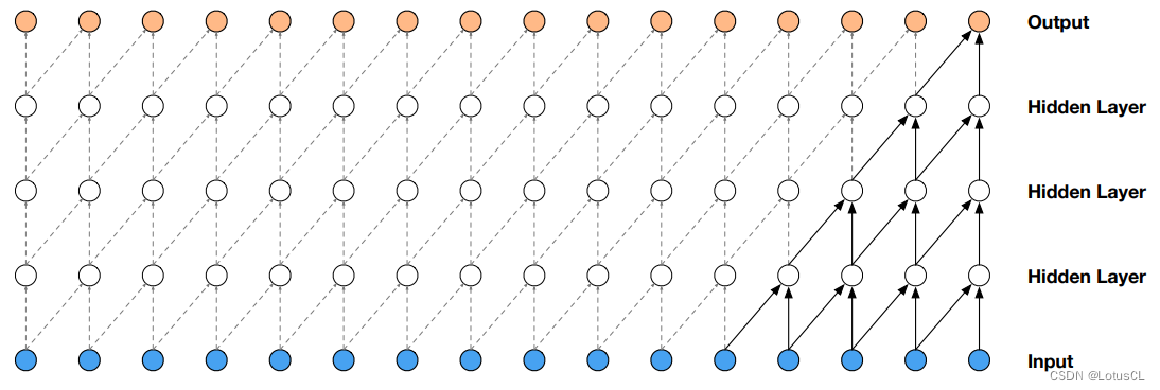
因果卷积网络,即具有一种“因果性”约束的卷积网络,它的输出 yt 只会看到输入序列 xt 及之前的信息,而不会看到未来的信息。我们将其画出,其最典型的特征就如下面的“直角三角形”图案。
-
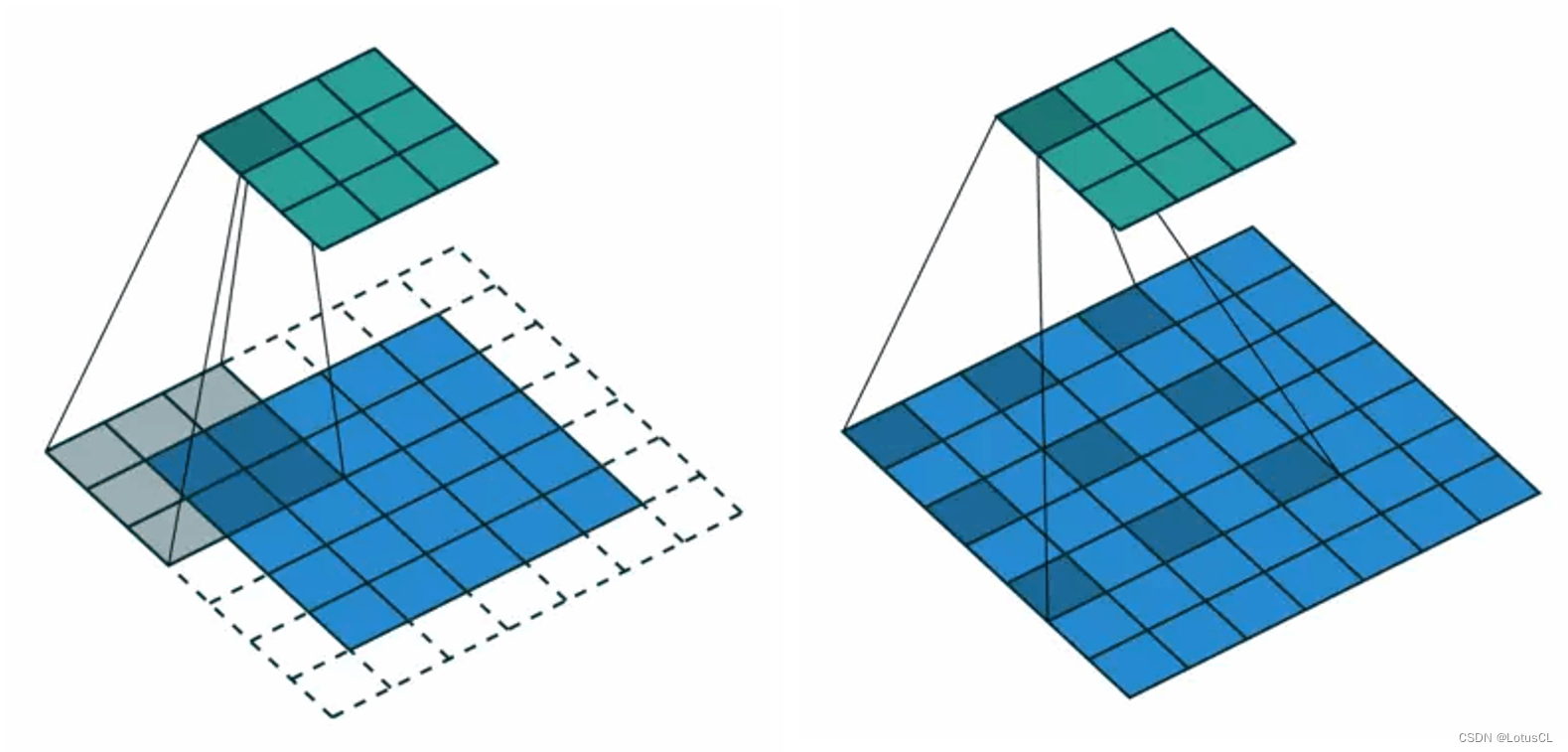
扩张卷积,它相对于普通的卷积有所不同。如下图,普通卷积的卷积核是紧挨在一起的,而 Dilated Convolution 的卷积核则是分开布置的,因此做到了卷积视野的 “dilate”。
-
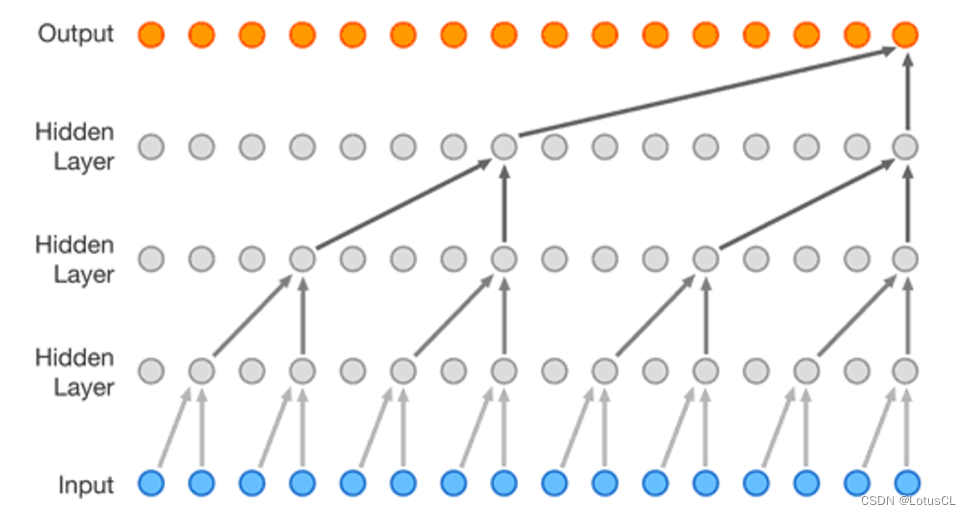
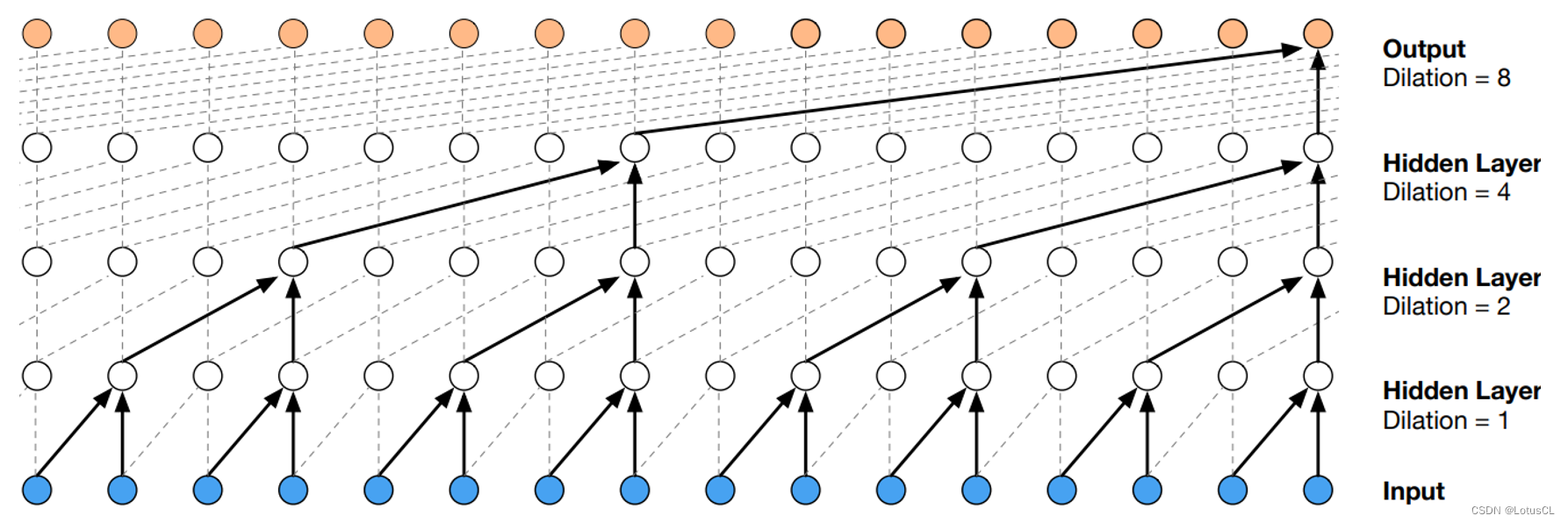
将这两者的特性结合,我们就得到了 WaveNet 的 Dilated Causal Convolution。
-
而扩张卷积最大的好处就是能够指数级增加输出的每一个值所能看到的视野。图如下,如果采用的是普通的因果卷积,经过4层卷积后,输出的一个值所能看到的只有输入的5个值。但如果采用的是扩张因果卷积,同样的深度下,输出的一个值就能看到足足16个值,这极大提高了视野范围。

WaveNet Residual and Skip Connections
-
刚刚我们讲完了 WaveNet Softmax 操作以及 Dilated Causal Convolution,剩下还有一个结构,它是在每层中,将卷积后的结果通过不同的激活函数,然后再将各自的结果进行点乘。这样的操作我们叫做 Gated Activation Unit。
-
其可以表达为以下公式:
意思是通过了卷积后,经过 tanh 和 sigmoid 两个激活函数,两个结果再做点乘,变成最终的结果。
Conditional WaveNet
-
讲到这里,我们好像还是没有说到 Spectrogram?毕竟刚刚讲述的 WaveNet 的输入是前几个 timesteps 的 输出(x1, ... , xt-1),输出则是 xt,那么 Spectrogram 是什么时候使用呢?其实就是放在了 Gated Activation Unit 那里。
-
我们将塞进来的随时间变化的 Spectrogram 称为 Local Condition,公式如下,使用 y 来表示 Spectrogram。还是和 x 一样通过一个 CNN,和 x 加起来,再通过两个激活函数,最终结果点乘。
-
有 “Local Condition” 自然也就有 Global Condition。 这里指的就是我们对声音添加的额外条件,比如使用谁的声音,带有怎样的情绪,用什么样子的说话方式等。这些条件将会作用于整个语音生成。条件可能是一个值,也可能是一个独热向量。不管怎样,它们添加的方式都和上面是一样的。公式表示如下:
WaveNet 总结
-
WaveNet 合成出来的音质还是非常好的,但由于是自回归模型,而声音信号中,一秒就有16000个值,也就是说使用 WaveNet 产生一秒的声音就需要运算 16000 次,因此在生成时就会非常慢。而下面提到的模型其主要目的就是为了解决生成速度很慢的问题。
三、Neural Vocoder——FFTNet
FFTNet 和 WaveNet 一样也是自回归模型。不一样的是,它将其中的深度 CNN 改成比较简单的计算方式,这样每次计算时的耗时就会少一些。此外,FFTNet 中还有一些训练和合成上的技巧,只要是使用自回归模型来生成语音的,这些技巧都可以加以应用来提高生成的语音质量。
FFTNet 架构
-
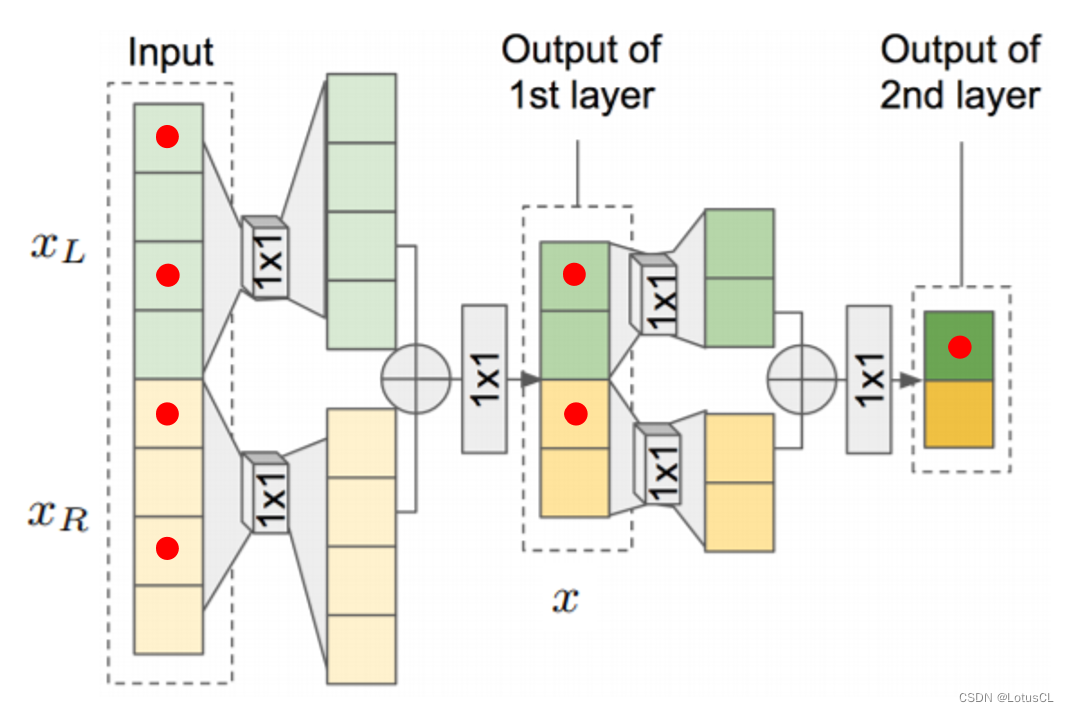
FFTNet 的输入和输出与 WaveNet 一样,输入就是所谓的 x1~xt-1,输出就是 xt。输入的数据首先会被切成两段,分别为 xl 和 xr,通过不同的 CNN 再加起来得到 z,然后通过一个 ReLU,一个1×1 CNN,一个ReLU,得到新的 x,然后再进行和上面一样的操作。因为相加的操作,每通过一层,输入的数据大小就会减半,最后大小变成1的时候,这就是最终的输出。

-
使用公式表达上面的过程就是:
-
而 Spectrogram 加入也是和 WaveNet 类似的方式,是在生成 z 的步骤中加入的,我们用 h 代表 Spectrogram,使用公式表示加入的方式如下:
-
这就是 FFTNet,架构非常简单,而效果却和 WaveNet 效果相似。为什么能达到如此优秀的效果?我们可以看下面的示意图,生成最右边的1个红点,是需要往左推,知道上一层的2个红点,再上一层是需要知道4个红点,通过多层叠加,我们不难得知,最终输出的视野将会非常大。
FFTNet 小技巧
-
Zero padding:
-
在输入的声音信号前加上一些0,会让训练变得更稳定。
-
-
Conditional sampling:
-
我们说过,WaveNet 的最终输出实际上是一个分类问题,也就是说是从最后的分布(distribution)中选取概率最大的类别作为最终的输出。而根据不同的情况,有时我们并不需要找概率最大的那个,而是根据分布去进行随机采样出最终的输出。
-
-
Injected noise:
-
WaveNet 和 FFTNet 都是自回归模型(autoregressive model),在训练时都采用了 teacher forcing,使用真实的 x1-xt-1,希望输出和答案的 xt 越接近越好。然而,在实际使用中,我们是使用模型上一步的输出当成输入的,也就意味着,如果上一步产生的答案并不是很好,这样的误差就会传递到下一步,最终导致整个模型垮掉。
-
所以我们可以在训练的过程中,给输入 x 增加一些高斯噪声。这样训练出来的模型在推理生成声音时会更加稳定。
-
-
Post-synthesis denoising
-
使用上面添加噪声的方法进行训练,最终生成的模型在投入使用时,产生的声音信号会有点噪音,所以就采用了信号处理的方式来对生成的声音信号进行去噪(后合成去噪)
-
FFTNet 总结
-
FFTNet 采用了更简单的架构,可以以更快的速度生成和 WaveNet 几乎一样好的声音信号。作者甚至在论文里说模型可以做到使用 CPU 的实时转换(real time using CPU),也就是产生 1s 的声音信号花不到 1s。
-
然而,大家实际上在使用的时候速度没有办法达到如作者所说的那么快的速度,但是还是比 WaveNet 快上不少。并且,在 FFTNet 中采用的那些小技巧对于自回归模型来说都是非常有用的。
-
最后我们来看看各个模型的效果。这里采用的 MOS 就是我们之前提到的 mean opinion score,即通过找一群人,让他们听声音,给分数一个 1-5 的分数,最终计算平均得分。带 ”+“ 的就是训练时采用小技巧的模型。可以看到 FFT 的评分还是没有 WaveNet 高,不过两个模型在采用小技巧后其频分都突飞猛进了。

四、Neural Vocoder——WaveRNN
还是由谷歌提出的,一句话总结这个模型就是,之前都是使用 CNN 来处理时间序列的,这回我们使用 RNN。
WaveRNN Dual Softmax Layer
门控循环单元(Gated Recurrent Unit,GRU):GRU 是一种循环神经网络(RNN)的变体,用于处理和建模时间序列数据,如语音信号。GRU 包含更新门(Update Gate)和重置门(Reset Gate),这两个门的作用类似于 LSTM 中的输入门和遗忘门,用于控制信息的流动和传递。
-
在谈 WaveRNN 架构前,我们先了解一下 WaveRNN 的 Softmax 层。之前我们说,WaveNet 的 Softmax 层将 16-bit 的数据压缩成 8-bit 数据再进行处理。而在 WaveRNN 中, Softmax 是将 16-bit 的数据拆成两个 8-bit 的数据,两个数据做两次预测来达到 16-bit 的效果。
-
分成的两个数据一个叫 Coarse,写作 c_t,还有一个叫 Fine,写作 f_t。

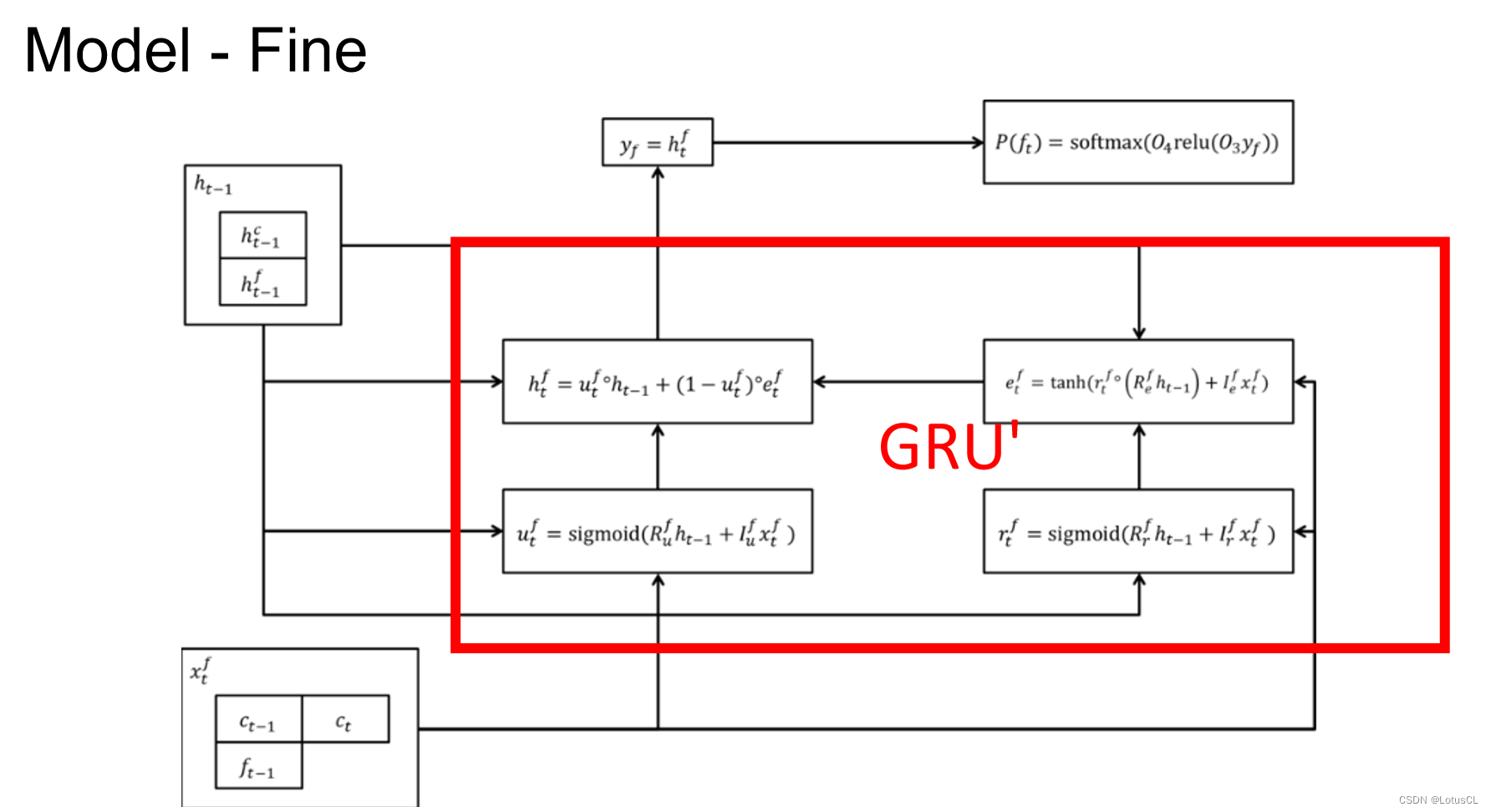
WaveRNN 架构
-
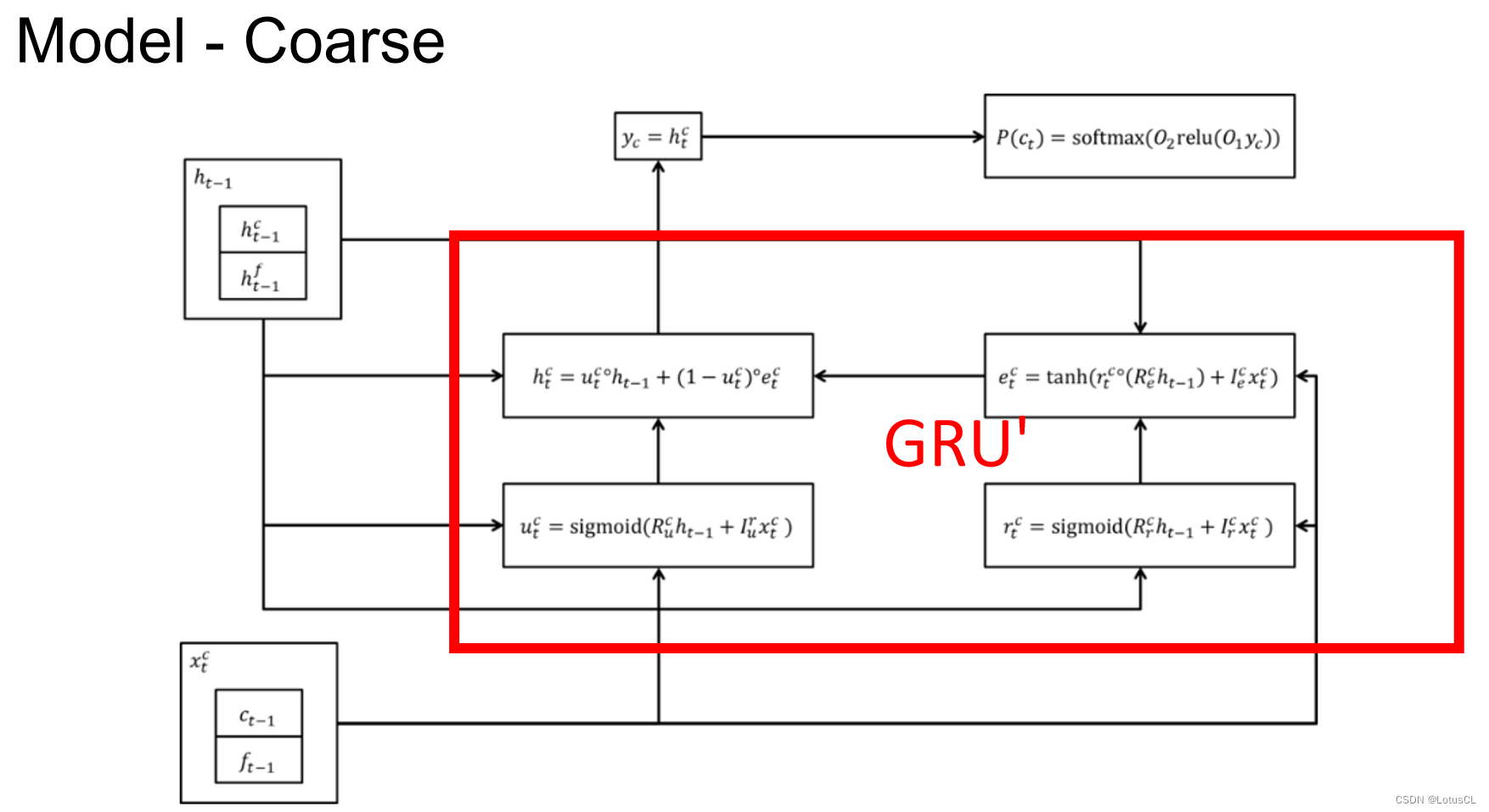
对于 Coarse 8-bit 的运算的结构图如下,红色方框里的四个单元可以理解为 GRU 运算。左下角 x_t^c 表示上一个时间的 16-bit 数据,即 x_t-1 的结果,左上角则是上一个时间的 hidden stat,输出则是当前时间的 hidden state y_c,通过两层的 linear transform,然后再进行 softmax 就可以得到 Coarse 8-bit,也就是最终的结果。
-
Fine 8-bit 和 Coarse 8-bit 其实差不多,用了另一个 GRU 来处理,唯一不同的就是我们不仅会将上一个 16-bit 数据拿来做 Input,同时也会将这一次产生的 Coarse 8-bit c_t 拿来做 Input。
-
遗憾的是,原论文中也只有上面这些图,没有详细说明模型部署方式。网上关于 WaveRNN 的部署方式有很多,可以自己查询了解,这里不再赘述。
WaveRNN 加速小技巧
在 WaveRNN 中还提到了一些能够让模型再加速的方法。论文中说,采用了下面技巧的 WaveRNN,就可以在手机的 CPU 上实现 Real-time 的运算。
-
Sparse WaveRNN
-
即 Weight Pruning(权重修剪),将一些比较小的权重值设为0,减少运算时候的消耗。
-
-
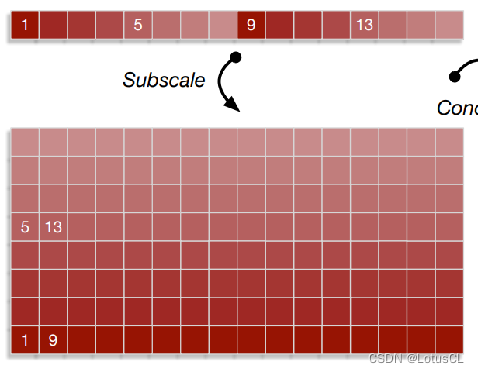
Subscale WaveRNN
-
原来我们是从1、2、3、……这样生成下去的,而在此变种中,我们将生成的序列进行折叠,依次生成 1、9、17、……,其他部分也是如此,如依次生成5、13、21、……,这样8个部分可以同时进行运算,那么整体速度就可以快8倍。
-
WaveRNN 总结
-
很简单,但是很强大。
五、Neural Vocoder——WaveGlow
实际上,语音生成速度之所以慢,本质上还是因为采用的是自回归模型。有人就想,如果不用自回归模型来生成语音信号会怎么样?WaveGlow 随之诞生。
Flow-Based Model
-
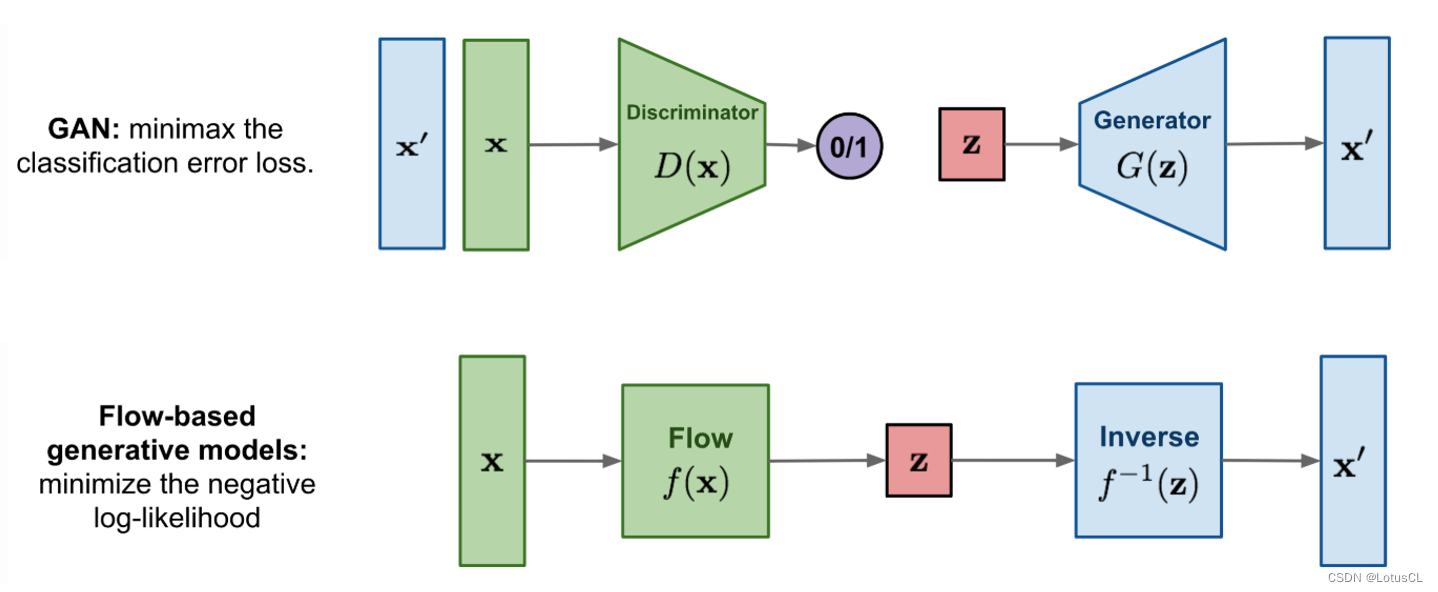
在了解 WaveGlow 模型前,我们先来了解一下 Flow-Based Model。相比于 GAN 中有两个模型,生成器需要去骗过判别器,Flow-Based Model 只有一个模型 Flow,也就是图中的 f(x)。模型将会接收真实数据的输入,将数据映射到高纬度类噪声 z 中,这相当于一个概率分布。与此同时,作为 transform 的 f(x) 还是可逆的,也就是可以使用 z 作为输入,从中采样出我们所需要的声音信号。
-
从数学的角度来解释就是下面这样:
-
这里的 z 就是平均值为 0,标准差为 1 的高斯分布。 因此我们可以写出它的概率密度函数(Probability Density Function,PDF)q。其实就是高斯分布的 PDF,将某一个 z 丢到其中,就可以告诉我们其出现的概率有多大。公式如下:
-
在训练中,因为是将 x 映射到高斯分布上,所以如果变换函数 f 训练得很好的话,那么它就可以将原始数据 x 映射到一个空间,在这个空间中数据点更符合高斯分布的特性。放到数学中就是 x 丢到高斯分布 PDF 中,得到的数值应该会很大。那么 q(x) 应该如何计算呢?我们将上面两个公式结合起来,就得到了下面的式子:
-
这里对 z 进行了一次变量替换,在概率中我们学过(悲,没学过),变量替换不能简单换了就行了,后面还需要加上雅可比行列式(Jacobian Determinant)的绝对值。
弹幕解释:一个是以z的元素为坐标的空间,一个是在以x的元素为坐标的空间,所以要有jacobian
-
对 q(x) 取 log,这就是我们训练的目标函数:数值越大越好。公式如下。此外,我们设计的变换函数 f 需要满足两个条件:很容易可逆、其雅可比行列式很容易计算。
-
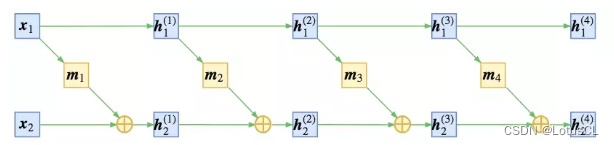
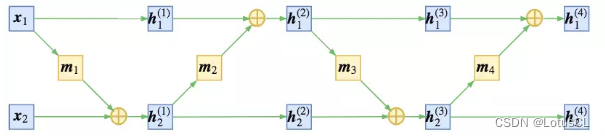
那么我们应该如何设计函数 f 呢?我们可以将 x 拆成 x_1 和 x_2,中间结果我们定义为 h,同时我们也将 h 拆成两类结果,为 h_1 和 h_2,则第一层的两个结果我们就写作 h_1^(1) 和 h_2^(1),则有:
-
其中,m 表示某种运算。所以以第一层举例,当我们有中间结果h_1^(1) 和 h_2^(1) 时,如果想进行反推,则有:
-
所以原始数据 x 经过上面这些变换后,最终生成的数据就是 z。而中间所有的变换加起来,就是我们的 f。

-
将上述过程绘制成图更方便理解,大概是下面这个样子:
-
当然,你也可以稍微改一下顺序,变成这样:
-
无论是上面的,还是下面的,整体运算都是可逆的。
WaveGlow 架构
-
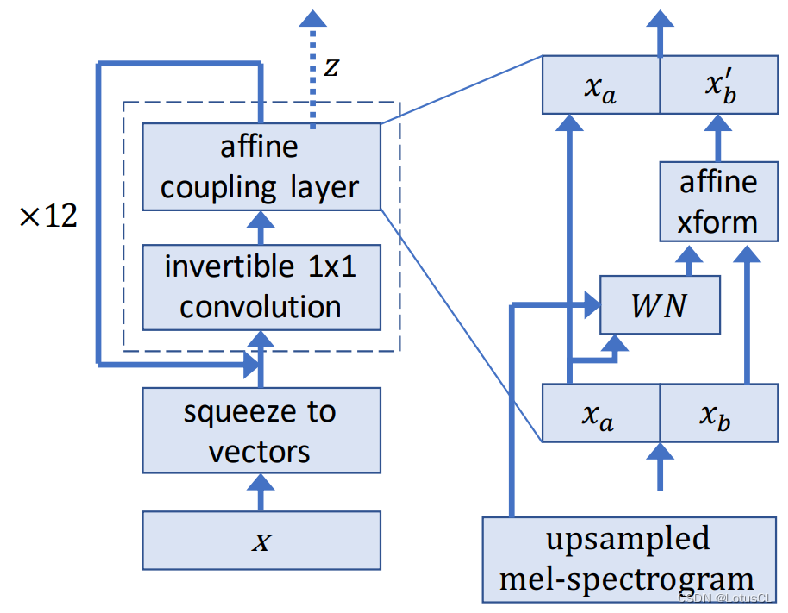
下图是 WaveGlow 的架构图。中间使用虚线框起来的模块就是变换函数 f。我们可以给定 x 输出结果 z,我们也可以提供 z 来生成语音 x。
-
从输入开始讲,x 首先通过 squeeze to vectors 变为向量,然后再进入一个 1×1 Conv,然后再进入 affine coupling layer,这就是我们之前提过的那一堆运算,这样的操作在 WaveGlow 中一共会进行12次,每次都被视为一层。
-
我们将 affine coupling layer 放大来看(图在右侧),输入首先被切割为 x_a 和 x_b,左边的会直接保留作为输出,并且还会丢给一个模块 WN 做运算,算出来的结果会和 x_b 相加变成输出 x_b‘。 值得一提的是,对 x_a 进行运算的模块就是 WaveNet(WN),这也是 WaveGlow 的名字来源。所以同样的,Spectrogram 自然也可以通过 WN 来接入模型中。
-
而对于 squeeze to vectors 操作,假设我们输入的是 1s 的数据,也就是 16000 个点,我们会将其变换成形状为 (8, 2000) 的向量。其中原因是如果我们不进行形状的变换,在拆分输入数据时,我们就会拆成两个 8000 的,这样对于运算来说很不方便,左右两边的计算时间会相差非常大。而在变换后,我们就可以将其拆分为两个 (4, 2000) 的。

WaveGlow 总结
-
在使用 WaveGlow 时,我们的输入是一整段声音,所以它的生成速度要比自回归模型要快得很多很多。
-
然而,这样的模型也有一个很大的缺点,那就是非常难训练。当初论文中说用了 8 张 Nvidia GV100 GPU 来进行训练,这个在当时一张要卖 35w。
六、Vocoder Conclusion
-
质量方面:WaveNet > others
-
训练时间方面:WaveRNN >= WaveNet >= FFTNet >> WaveGlow
-
生成速度方面:
-
实时标准:16kHz,即每秒需能运算 16000 次。
-
WaveGlow (520kHz) >> Real-time > WaveRNN >= FFTNet >> WaveNet (0.11kHz)
-
传统高度优化的 Griffin-Lim 算法:507kHz
-
-
而 Neural Vocoders 的现状就是要么生成速度很慢,要么很难训练。而且还需要高度的优化才能有非常好的结果。
-
因此目前的研究目标就是做一个生成速度快、质量高,并且容易训练的 Vocoder。