3. 基于zookeeper实现分布式锁
实现分布式锁目前有三种流行方案,分别为基于数据库、Redis、Zookeeper的方案。这里主要介绍基于zk怎么实现分布式锁。在实现分布式锁之前,先回顾zookeeper的相关知识点
3.1. 知识点回顾
3.1.1. 安装启动
安装:把zk安装包上传到/opt目录下,并切换到/opt目录下,执行以下指令
# 解压
tar -zxvf zookeeper-3.7.0-bin.tar.gz
# 重命名
mv apache-zookeeper-3.7.0-bin/ zookeeper
# 打开zookeeper根目录
cd /opt/zookeeper
# 创建一个数据目录,备用
mkdir data
# 打开zk的配置目录
cd /opt/zookeeper/conf
# copy配置文件,zk启动时会加载zoo.cfg文件
cp zoo_sample.cfg zoo.cfg
# 编辑配置文件
vim zoo.cfg
# 修改dataDir参数为之前创建的数据目录:/opt/zookeeper/data
# 切换到bin目录
cd /opt/zookeeper/bin
# 启动
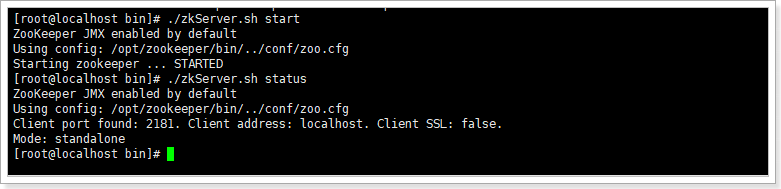
./zkServer.sh start
./zkServer.sh status # 查看启动状态
./zkServer.sh stop # 停止
./zkServer.sh restart # 重启
./zkCli.sh # 查看zk客户端如下,说明启动成功:
3.1.2. 相关概念
Zookeeper提供一个多层级的节点命名空间(节点称为znode),每个节点都用一个以斜杠(/)分隔的路径表示,而且每个节点都有父节点(根节点除外),非常类似于文件系统。并且每个节点都是唯一的。
znode节点有四种类型:
-
PERSISTENT:永久节点。客户端与zookeeper断开连接后,该节点依旧存在
-
EPHEMERAL:临时节点。客户端与zookeeper断开连接后,该节点被删除
-
PERSISTENT_SEQUENTIAL:永久节点、序列化。客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
-
EPHEMERAL_SEQUENTIAL:临时节点、序列化。客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
创建这四种节点:
[zk: localhost:2181(CONNECTED) 0] create /aa test # 创建持久化节点
Created /aa
[zk: localhost:2181(CONNECTED) 1] create -s /bb test # 创建持久序列化节点
Created /bb0000000001
[zk: localhost:2181(CONNECTED) 2] create -e /cc test # 创建临时节点
Created /cc
[zk: localhost:2181(CONNECTED) 3] create -e -s /dd test # 创建临时序列化节点
Created /dd0000000003
[zk: localhost:2181(CONNECTED) 4] ls / # 查看某个节点下的子节点
[aa, bb0000000001, cc, dd0000000003, zookeeper]
[zk: localhost:2181(CONNECTED) 5] stat / # 查看某个节点的状态
cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x5
cversion = 3
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 5
[zk: localhost:2181(CONNECTED) 6] get /aa # 查看某个节点的内容
test
[zk: localhost:2181(CONNECTED) 11] delete /aa # 删除某个节点
[zk: localhost:2181(CONNECTED) 7] ls / # 再次查看
[bb0000000001, cc, dd0000000003, zookeeper]事件监听:在读取数据时,我们可以同时对节点设置事件监听,当节点数据或结构变化时,zookeeper会通知客户端。当前zookeeper针对节点的监听有如下四种事件:
-
节点创建:stat -w /xx
当/xx节点创建时:NodeCreated
-
节点删除:stat -w /xx
当/xx节点删除时:NodeDeleted
-
节点数据修改:get -w /xx
当/xx节点数据发生变化时:NodeDataChanged
-
子节点变更:ls -w /xx
当/xx节点的子节点创建或者删除时:NodeChildChanged
3.1.3. java客户端
ZooKeeper的java客户端有:原生客户端、ZkClient、Curator框架(类似于redisson,有很多功能性封装)。
-
引入依赖
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.7.0</version>
</dependency>-
常用api及其方法
public class ZkTest {
public static void main(String[] args) throws KeeperException, InterruptedException {
// 获取zookeeper链接
CountDownLatch countDownLatch = new CountDownLatch(1);
ZooKeeper zooKeeper = null;
try {
zooKeeper = new ZooKeeper("172.16.116.100:2181", 30000, new Watcher() {
@Override
public void process(WatchedEvent event) {
if (Event.KeeperState.SyncConnected.equals(event.getState())
&& Event.EventType.None.equals(event.getType())) {
System.out.println("获取链接成功。。。。。。" + event);
countDownLatch.countDown();
}
}
});
countDownLatch.await();
} catch (Exception e) {
e.printStackTrace();
}
// 创建一个节点,1-节点路径 2-节点内容 3-节点的访问权限 4-节点类型
// OPEN_ACL_UNSAFE:任何人可以操作该节点
// CREATOR_ALL_ACL:创建者拥有所有访问权限
// READ_ACL_UNSAFE: 任何人都可以读取该节点
// zooKeeper.create("/atguigu/aa", "haha~~".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
zooKeeper.create("/test", "haha~~".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
// zooKeeper.create("/atguigu/cc", "haha~~".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT_SEQUENTIAL);
// zooKeeper.create("/atguigu/dd", "haha~~".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
// zooKeeper.create("/atguigu/dd", "haha~~".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
// zooKeeper.create("/atguigu/dd", "haha~~".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
// 判断节点是否存在
Stat stat = zooKeeper.exists("/test", true);
if (stat != null){
System.out.println("当前节点存在!" + stat.getVersion());
} else {
System.out.println("当前节点不存在!");
}
// 判断节点是否存在,同时添加监听
zooKeeper.exists("/test", event -> {
});
// 获取一个节点的数据
byte[] data = zooKeeper.getData("/atguigu/ss0000000001", false, null);
System.out.println(new String(data));
// 查询一个节点的所有子节点
List<String> children = zooKeeper.getChildren("/test", false);
System.out.println(children);
// 更新
zooKeeper.setData("/test", "wawa...".getBytes(), stat.getVersion());
// 删除一个节点
//zooKeeper.delete("/test", -1);
if (zooKeeper != null){
zooKeeper.close();
}
}
}3.2. 思路分析
分布式锁的步骤:
-
获取锁:create一个节点
-
删除锁:delete一个节点
-
重试:没有获取到锁的请求重试
参照redis分布式锁的特点:
-
互斥 排他
-
防死锁:
-
可自动释放锁(临时节点) :获得锁之后客户端所在机器宕机了,客户端没有主动删除子节点;如果创建的是永久的节点,那么这个锁永远不会释放,导致死锁;由于创建的是临时节点,客户端宕机后,过了一定时间zookeeper没有收到客户端的心跳包判断会话失效,将临时节点删除从而释放锁。
-
可重入锁:借助于ThreadLocal
-
-
防误删:宕机自动释放临时节点,不需要设置过期时间,也就不存在误删问题。
-
加锁/解锁要具备原子性
-
单点问题:使用Zookeeper可以有效的解决单点问题,ZK一般是集群部署的。
-
集群问题:zookeeper集群是强一致性的,只要集群中有半数以上的机器存活,就可以对外提供服务。
3.3. 基本实现
实现思路:
-
多个请求同时添加一个相同的临时节点,只有一个可以添加成功。添加成功的获取到锁
-
执行业务逻辑
-
完成业务流程后,删除节点释放锁。
由于zookeeper获取链接是一个耗时过程,这里可以在项目启动时,初始化链接,并且只初始化一次。借助于spring特性,代码实现如下:
@Component
public class ZkClient {
private static final String connectString = "172.16.116.100:2181";
private static final String ROOT_PATH = "/distributed";
private ZooKeeper zooKeeper;
@PostConstruct
public void init(){
try {
// 连接zookeeper服务器
this.zooKeeper = new ZooKeeper(connectString, 30000, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("获取链接成功!!");
}
});
// 创建分布式锁根节点
if (this.zooKeeper.exists(ROOT_PATH, false) == null){
this.zooKeeper.create(ROOT_PATH, null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
} catch (Exception e) {
System.out.println("获取链接失败!");
e.printStackTrace();
}
}
@PreDestroy
public void destroy(){
try {
if (zooKeeper != null){
zooKeeper.close();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/**
* 初始化zk分布式锁对象方法
* @param lockName
* @return
*/
public ZkDistributedLock getZkDistributedLock(String lockName){
return new ZkDistributedLock(zooKeeper, lockName);
}
}zk分布式锁具体实现:
public class ZkDistributedLock {
private static final String ROOT_PATH = "/distributed";
private String path;
private ZooKeeper zooKeeper;
public ZkDistributedLock(ZooKeeper zooKeeper, String lockName){
this.zooKeeper = zooKeeper;
this.path = ROOT_PATH + "/" + lockName;
}
public void lock(){
try {
zooKeeper.create(path, null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
} catch (Exception e) {
// 重试
try {
Thread.sleep(200);
lock();
} catch (InterruptedException ex) {
ex.printStackTrace();
}
}
}
public void unlock(){
try {
this.zooKeeper.delete(path, 0);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
}
}改造StockService的checkAndLock方法:
@Autowired
private ZkClient client;
public void checkAndLock() {
// 加锁,获取锁失败重试
ZkDistributedLock lock = this.client.getZkDistributedLock("lock");
lock.lock();
// 先查询库存是否充足
Stock stock = this.stockMapper.selectById(1L);
// 再减库存
if (stock != null && stock.getCount() > 0){
stock.setCount(stock.getCount() - 1);
this.stockMapper.updateById(stock);
}
// 释放锁
lock.unlock();
}Jmeter压力测试:

性能一般,mysql数据库的库存余量为0(注意:所有测试之前都要先修改库存量为5000)
基本实现存在的问题:
-
性能一般(比mysql分布式锁略好)
-
不可重入
接下来首先来提高性能
3.4. 优化:性能优化
基本实现中由于无限自旋影响性能:
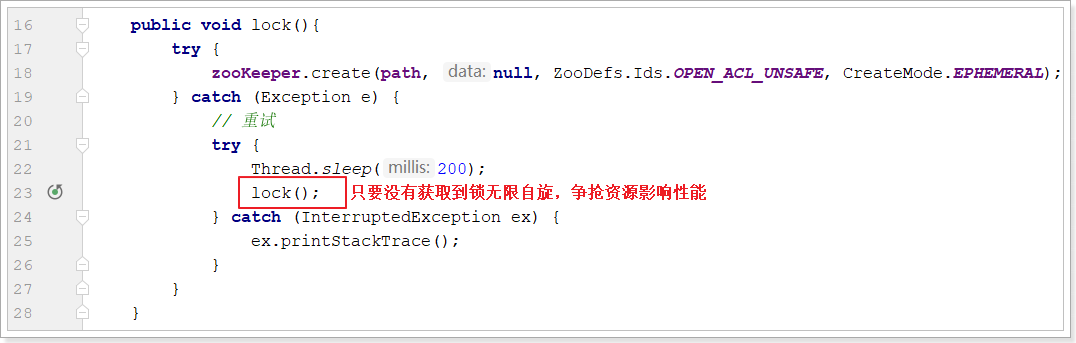
试想:每个请求要想正常的执行完成,最终都是要创建节点,如果能够避免争抢必然可以提高性能。
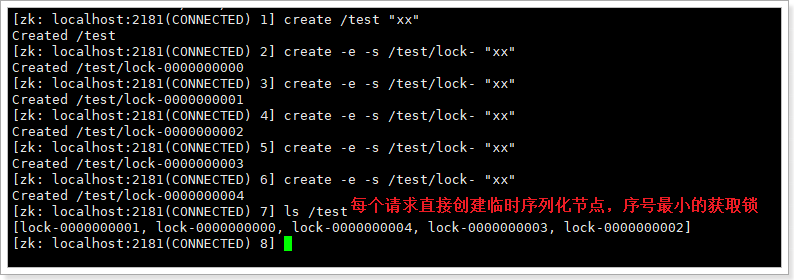
这里借助于zk的临时序列化节点,实现分布式锁:
3.4.1. 实现阻塞锁
代码实现:
public class ZkDistributedLock {
private static final String ROOT_PATH = "/distributed";
private String path;
private ZooKeeper zooKeeper;
public ZkDistributedLock(ZooKeeper zooKeeper, String lockName){
try {
this.zooKeeper = zooKeeper;
this.path = zooKeeper.create(ROOT_PATH + "/" + lockName + "-", null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void lock(){
String preNode = getPreNode(path);
// 如果该节点没有前一个节点,说明该节点时最小节点,放行执行业务逻辑
if (StringUtils.isEmpty(preNode)){
return ;
}
// 重新检查。是否获取到锁
try {
Thread.sleep(20);
} catch (InterruptedException ex) {
ex.printStackTrace();
}
lock();
}
public void unlock(){
try {
this.zooKeeper.delete(path, 0);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
}
/**
* 获取指定节点的前节点
* @param path
* @return
*/
private String getPreNode(String path){
try {
// 获取当前节点的序列化号
Long curSerial = Long.valueOf(StringUtils.substringAfterLast(path, "-"));
// 获取根路径下的所有序列化子节点
List<String> nodes = this.zooKeeper.getChildren(ROOT_PATH, false);
// 判空
if (CollectionUtils.isEmpty(nodes)){
return null;
}
// 获取前一个节点
Long flag = 0L;
String preNode = null;
for (String node : nodes) {
// 获取每个节点的序列化号
Long serial = Long.valueOf(StringUtils.substringAfterLast(node, "-"));
if (serial < curSerial && serial > flag){
flag = serial;
preNode = node;
}
}
return preNode;
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
return null;
}
}主要修改了构造方法和lock方法:
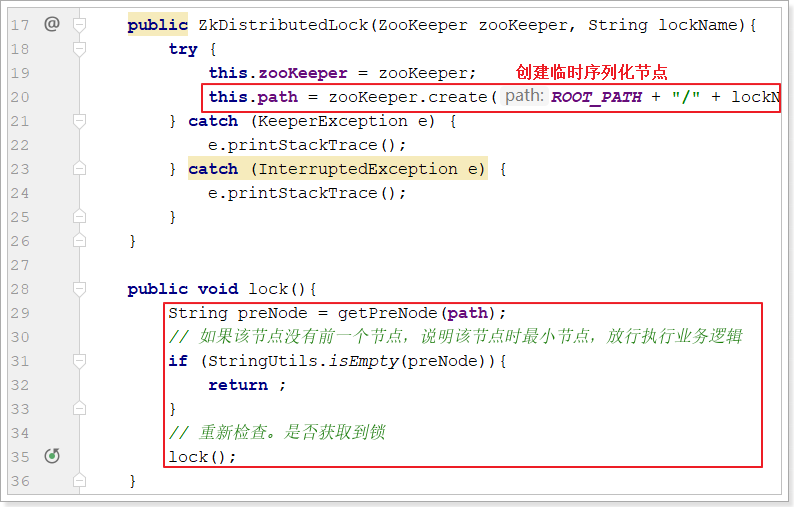
并添加了getPreNode获取前置节点的方法。
测试结果如下:

性能反而更弱了。
原因:虽然不用反复争抢创建节点了,但是会自旋判断自己是最小的节点,这个判断逻辑反而更复杂更耗时。
解决方案:监听。
3.4.2. 监听实现阻塞锁
对于这个算法有个极大的优化点:假如当前有1000个节点在等待锁,如果获得锁的客户端释放锁时,这1000个客户端都会被唤醒,这种情况称为“羊群效应”;在这种羊群效应中,zookeeper需要通知1000个客户端,这会阻塞其他的操作,最好的情况应该只唤醒新的最小节点对应的客户端。应该怎么做呢?在设置事件监听时,每个客户端应该对刚好在它之前的子节点设置事件监听,例如子节点列表为/locks/lock-0000000000、/locks/lock-0000000001、/locks/lock-0000000002,序号为1的客户端监听序号为0的子节点删除消息,序号为2的监听序号为1的子节点删除消息。
所以调整后的分布式锁算法流程如下:
-
客户端连接zookeeper,并在/lock下创建临时的且有序的子节点,第一个客户端对应的子节点为/locks/lock-0000000000,第二个为/locks/lock-0000000001,以此类推;
-
客户端获取/lock下的子节点列表,判断自己创建的子节点是否为当前子节点列表中序号最小的子节点,如果是则认为获得锁,否则监听刚好在自己之前一位的子节点删除消息,获得子节点变更通知后重复此步骤直至获得锁;
-
执行业务代码;
-
完成业务流程后,删除对应的子节点释放锁。
改造ZkDistributedLock的lock方法:
public void lock(){
try {
String preNode = getPreNode(path);
// 如果该节点没有前一个节点,说明该节点时最小节点,放行执行业务逻辑
if (StringUtils.isEmpty(preNode)){
return ;
} else {
CountDownLatch countDownLatch = new CountDownLatch(1);
if (this.zooKeeper.exists(ROOT_PATH + "/" + preNode, new Watcher(){
@Override
public void process(WatchedEvent event) {
countDownLatch.countDown();
}
}) == null) {
return;
}
// 阻塞。。。。
countDownLatch.await();
return;
}
} catch (Exception e) {
e.printStackTrace();
// 重新检查。是否获取到锁
try {
Thread.sleep(200);
} catch (InterruptedException ex) {
ex.printStackTrace();
}
lock();
}
}压力测试效果如下:

由此可见性能提高不少,接近于redis的分布式锁
3.5. 优化:可重入锁
引入ThreadLocal线程局部变量保证zk分布式锁的可重入性。
public class ZkDistributedLock {
private static final String ROOT_PATH = "/distributed";
private static final ThreadLocal<Integer> THREAD_LOCAL = new ThreadLocal<>();
private String path;
private ZooKeeper zooKeeper;
public ZkDistributedLock(ZooKeeper zooKeeper, String lockName){
try {
this.zooKeeper = zooKeeper;
if (THREAD_LOCAL.get() == null || THREAD_LOCAL.get() == 0){
this.path = zooKeeper.create(ROOT_PATH + "/" + lockName + "-", null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
}
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void lock(){
Integer flag = THREAD_LOCAL.get();
if (flag != null && flag > 0) {
THREAD_LOCAL.set(flag + 1);
return;
}
try {
String preNode = getPreNode(path);
// 如果该节点没有前一个节点,说明该节点时最小节点,放行执行业务逻辑
if (StringUtils.isEmpty(preNode)){
THREAD_LOCAL.set(1);
return ;
} else {
CountDownLatch countDownLatch = new CountDownLatch(1);
if (this.zooKeeper.exists(ROOT_PATH + "/" + preNode, new Watcher(){
@Override
public void process(WatchedEvent event) {
countDownLatch.countDown();
}
}) == null) {
THREAD_LOCAL.set(1);
return;
}
// 阻塞。。。。
countDownLatch.await();
THREAD_LOCAL.set(1);
return;
}
} catch (Exception e) {
e.printStackTrace();
// 重新检查。是否获取到锁
try {
Thread.sleep(200);
} catch (InterruptedException ex) {
ex.printStackTrace();
}
lock();
}
}
public void unlock(){
try {
THREAD_LOCAL.set(THREAD_LOCAL.get() - 1);
if (THREAD_LOCAL.get() == 0) {
this.zooKeeper.delete(path, 0);
THREAD_LOCAL.remove();
}
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
}
/**
* 获取指定节点的前节点
* @param path
* @return
*/
private String getPreNode(String path){
try {
// 获取当前节点的序列化号
Long curSerial = Long.valueOf(StringUtils.substringAfterLast(path, "-"));
// 获取根路径下的所有序列化子节点
List<String> nodes = this.zooKeeper.getChildren(ROOT_PATH, false);
// 判空
if (CollectionUtils.isEmpty(nodes)){
return null;
}
// 获取前一个节点
Long flag = 0L;
String preNode = null;
for (String node : nodes) {
// 获取每个节点的序列化号
Long serial = Long.valueOf(StringUtils.substringAfterLast(node, "-"));
if (serial < curSerial && serial > flag){
flag = serial;
preNode = node;
}
}
return preNode;
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
return null;
}
}3.6. zk分布式锁小结
参照redis分布式锁的特点:
-
互斥 排他:zk节点的不可重复性,以及序列化节点的有序性
-
防死锁:
-
可自动释放锁:临时节点
-
可重入锁:借助于ThreadLocal
-
-
防误删:临时节点
-
加锁/解锁要具备原子性
-
单点问题:使用Zookeeper可以有效的解决单点问题,ZK一般是集群部署的。
-
集群问题:zookeeper集群是强一致性的,只要集群中有半数以上的机器存活,就可以对外提供服务。
-
公平锁:有序性节点
3.7. Curator中的分布式锁
Curator是netflix公司开源的一套zookeeper客户端,目前是Apache的顶级项目。与Zookeeper提供的原生客户端相比,Curator的抽象层次更高,简化了Zookeeper客户端的开发量。Curator解决了很多zookeeper客户端非常底层的细节开发工作,包括连接重连、反复注册wathcer和NodeExistsException 异常等。
通过查看官方文档,可以发现Curator主要解决了三类问题:
-
封装ZooKeeper client与ZooKeeper server之间的连接处理
-
提供了一套Fluent风格的操作API
-
提供ZooKeeper各种应用场景(recipe, 比如:分布式锁服务、集群领导选举、共享计数器、缓存机制、分布式队列等)的抽象封装,这些实现都遵循了zk的最佳实践,并考虑了各种极端情况
Curator由一系列的模块构成,对于一般开发者而言,常用的是curator-framework和curator-recipes:
-
curator-framework:提供了常见的zk相关的底层操作
-
curator-recipes:提供了一些zk的典型使用场景的参考。本节重点关注的分布式锁就是该包提供的
引入依赖:
最新版本的curator 4.3.0支持zookeeper 3.4.x和3.5,但是需要注意curator传递进来的依赖,需要和实际服务器端使用的版本相符,以我们目前使用的zookeeper 3.4.14为例。
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.3.0</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.3.0</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.14</version>
</dependency>添加curator客户端配置:
@Configuration
public class CuratorConfig {
@Bean
public CuratorFramework curatorFramework(){
// 重试策略,这里使用的是指数补偿重试策略,重试3次,初始重试间隔1000ms,每次重试之后重试间隔递增。
RetryPolicy retry = new ExponentialBackoffRetry(1000, 3);
// 初始化Curator客户端:指定链接信息 及 重试策略
CuratorFramework client = CuratorFrameworkFactory.newClient("172.16.116.100:2181", retry);
client.start(); // 开始链接,如果不调用该方法,很多方法无法工作
return client;
}
}3.7.1. 可重入锁InterProcessMutex
Reentrant和JDK的ReentrantLock类似, 意味着同一个客户端在拥有锁的同时,可以多次获取,不会被阻塞。它是由类InterProcessMutex来实现。
// 常用构造方法
public InterProcessMutex(CuratorFramework client, String path)
// 获取锁
public void acquire();
// 带超时时间的可重入锁
public boolean acquire(long time, TimeUnit unit);
// 释放锁
public void release();3.7.1.1. 使用案例
改造service测试方法:
@Autowired
private CuratorFramework curatorFramework;
public void checkAndLock() {
InterProcessMutex mutex = new InterProcessMutex(curatorFramework, "/curator/lock");
try {
// 加锁
mutex.acquire();
// 先查询库存是否充足
Stock stock = this.stockMapper.selectById(1L);
// 再减库存
if (stock != null && stock.getCount() > 0){
stock.setCount(stock.getCount() - 1);
this.stockMapper.updateById(stock);
}
// this.testSub(mutex);
// 释放锁
mutex.release();
} catch (Exception e) {
e.printStackTrace();
}
}
public void testSub(InterProcessMutex mutex) {
try {
mutex.acquire();
System.out.println("测试可重入锁。。。。");
mutex.release();
} catch (Exception e) {
e.printStackTrace();
}
}注意:如想重入,则需要使用同一个InterProcessMutex对象。
压力测试结果:

3.7.1.2. 底层原理
3.7.2. 不可重入锁InterProcessSemaphoreMutex
具体实现:InterProcessSemaphoreMutex。与InterProcessMutex调用方法类似,区别在于该锁是不可重入的,在同一个线程中不可重入。
public InterProcessSemaphoreMutex(CuratorFramework client, String path);
public void acquire();
public boolean acquire(long time, TimeUnit unit);
public void release();案例:
@Autowired
private CuratorFramework curatorFramework;
public void deduct() {
InterProcessSemaphoreMutex mutex = new InterProcessSemaphoreMutex(curatorFramework, "/curator/lock");
try {
mutex.acquire();
// 1. 查询库存信息
String stock = redisTemplate.opsForValue().get("stock").toString();
// 2. 判断库存是否充足
if (stock != null && stock.length() != 0) {
Integer st = Integer.valueOf(stock);
if (st > 0) {
// 3.扣减库存
redisTemplate.opsForValue().set("stock", String.valueOf(--st));
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
mutex.release();
} catch (Exception e) {
e.printStackTrace();
}
}
}3.7.3. 可重入读写锁InterProcessReadWriteLock
类似JDK的ReentrantReadWriteLock。一个拥有写锁的线程可重入读锁,但是读锁却不能进入写锁。这也意味着写锁可以降级成读锁。从读锁升级成写锁是不成的。主要实现类InterProcessReadWriteLock:
// 构造方法
public InterProcessReadWriteLock(CuratorFramework client, String basePath);
// 获取读锁对象
InterProcessMutex readLock();
// 获取写锁对象
InterProcessMutex writeLock();注意:写锁在释放之前会一直阻塞请求线程,而读锁不会
public void testZkReadLock() {
try {
InterProcessReadWriteLock rwlock = new InterProcessReadWriteLock(curatorFramework, "/curator/rwlock");
rwlock.readLock().acquire(10, TimeUnit.SECONDS);
// TODO:一顿读的操作。。。。
//rwlock.readLock().unlock();
} catch (Exception e) {
e.printStackTrace();
}
}
public void testZkWriteLock() {
try {
InterProcessReadWriteLock rwlock = new InterProcessReadWriteLock(curatorFramework, "/curator/rwlock");
rwlock.writeLock().acquire(10, TimeUnit.SECONDS);
// TODO:一顿写的操作。。。。
//rwlock.writeLock().unlock();
} catch (Exception e) {
e.printStackTrace();
}
}3.7.4. 联锁InterProcessMultiLock
Multi Shared Lock是一个锁的容器。当调用acquire, 所有的锁都会被acquire,如果请求失败,所有的锁都会被release。同样调用release时所有的锁都被release(失败被忽略)。基本上,它就是组锁的代表,在它上面的请求释放操作都会传递给它包含的所有的锁。实现类InterProcessMultiLock:
// 构造函数需要包含的锁的集合,或者一组ZooKeeper的path
public InterProcessMultiLock(List<InterProcessLock> locks);
public InterProcessMultiLock(CuratorFramework client, List<String> paths);
// 获取锁
public void acquire();
public boolean acquire(long time, TimeUnit unit);
// 释放锁
public synchronized void release();3.7.5. 信号量InterProcessSemaphoreV2
一个计数的信号量类似JDK的Semaphore。JDK中Semaphore维护的一组许可(permits),而Cubator中称之为租约(Lease)。注意,所有的实例必须使用相同的numberOfLeases值。调用acquire会返回一个租约对象。客户端必须在finally中close这些租约对象,否则这些租约会丢失掉。但是,如果客户端session由于某种原因比如crash丢掉, 那么这些客户端持有的租约会自动close, 这样其它客户端可以继续使用这些租约。主要实现类InterProcessSemaphoreV2:
// 构造方法
public InterProcessSemaphoreV2(CuratorFramework client, String path, int maxLeases);
// 注意一次你可以请求多个租约,如果Semaphore当前的租约不够,则请求线程会被阻塞。
// 同时还提供了超时的重载方法
public Lease acquire();
public Collection<Lease> acquire(int qty);
public Lease acquire(long time, TimeUnit unit);
public Collection<Lease> acquire(int qty, long time, TimeUnit unit)
// 租约还可以通过下面的方式返还
public void returnAll(Collection<Lease> leases);
public void returnLease(Lease lease);案例代码:
StockController中添加方法:
@GetMapping("test/semaphore")
public String testSemaphore(){
this.stockService.testSemaphore();
return "hello Semaphore";
}StockService中添加方法:
public void testSemaphore() {
// 设置资源量 限流的线程数
InterProcessSemaphoreV2 semaphoreV2 = new InterProcessSemaphoreV2(curatorFramework, "/locks/semaphore", 5);
try {
Lease acquire = semaphoreV2.acquire();// 获取资源,获取资源成功的线程可以继续处理业务操作。否则会被阻塞住
this.redisTemplate.opsForList().rightPush("log", "10010获取了资源,开始处理业务逻辑。" + Thread.currentThread().getName());
TimeUnit.SECONDS.sleep(10 + new Random().nextInt(10));
this.redisTemplate.opsForList().rightPush("log", "10010处理完业务逻辑,释放资源=====================" + Thread.currentThread().getName());
semaphoreV2.returnLease(acquire); // 手动释放资源,后续请求线程就可以获取该资源
} catch (Exception e) {
e.printStackTrace();
}
}3.7.6. 栅栏barrier
-
DistributedBarrier构造函数中barrierPath参数用来确定一个栅栏,只要barrierPath参数相同(路径相同)就是同一个栅栏。通常情况下栅栏的使用如下:
-
主client设置一个栅栏
-
其他客户端就会调用waitOnBarrier()等待栅栏移除,程序处理线程阻塞
-
主client移除栅栏,其他客户端的处理程序就会同时继续运行。
DistributedBarrier类的主要方法如下:
setBarrier() - 设置栅栏 waitOnBarrier() - 等待栅栏移除 removeBarrier() - 移除栅栏 -
-
DistributedDoubleBarrier双栅栏,允许客户端在计算的开始和结束时同步。当足够的进程加入到双栅栏时,进程开始计算,当计算完成时,离开栅栏。DistributedDoubleBarrier实现了双栅栏的功能。构造函数如下:
// client - the client // barrierPath - path to use // memberQty - the number of members in the barrier public DistributedDoubleBarrier(CuratorFramework client, String barrierPath, int memberQty); enter()、enter(long maxWait, TimeUnit unit) - 等待同时进入栅栏 leave()、leave(long maxWait, TimeUnit unit) - 等待同时离开栅栏memberQty是成员数量,当enter方法被调用时,成员被阻塞,直到所有的成员都调用了enter。当leave方法被调用时,它也阻塞调用线程,直到所有的成员都调用了leave。
注意:参数memberQty的值只是一个阈值,而不是一个限制值。当等待栅栏的数量大于或等于这个值栅栏就会打开!
与栅栏(DistributedBarrier)一样,双栅栏的barrierPath参数也是用来确定是否是同一个栅栏的,双栅栏的使用情况如下:
-
从多个客户端在同一个路径上创建双栅栏(DistributedDoubleBarrier),然后调用enter()方法,等待栅栏数量达到memberQty时就可以进入栅栏。
-
栅栏数量达到memberQty,多个客户端同时停止阻塞继续运行,直到执行leave()方法,等待memberQty个数量的栅栏同时阻塞到leave()方法中。
-
memberQty个数量的栅栏同时阻塞到leave()方法中,多个客户端的leave()方法停止阻塞,继续运行。
-
3.7.7. 共享计数器
利用ZooKeeper可以实现一个集群共享的计数器。只要使用相同的path就可以得到最新的计数器值, 这是由ZooKeeper的一致性保证的。Curator有两个计数器, 一个是用int来计数,一个用long来计数。
3.7.7.1. SharedCount
共享计数器SharedCount相关方法如下:
// 构造方法
public SharedCount(CuratorFramework client, String path, int seedValue);
// 获取共享计数的值
public int getCount();
// 设置共享计数的值
public void setCount(int newCount) throws Exception;
// 当版本号没有变化时,才会更新共享变量的值
public boolean trySetCount(VersionedValue<Integer> previous, int newCount);
// 通过监听器监听共享计数的变化
public void addListener(SharedCountListener listener);
public void addListener(final SharedCountListener listener, Executor executor);
// 共享计数在使用之前必须开启
public void start() throws Exception;
// 关闭共享计数
public void close() throws IOException;使用案例:
StockController:
@GetMapping("test/zk/share/count")
public String testZkShareCount(){
this.stockService.testZkShareCount();
return "hello shareData";
}StockService:
public void testZkShareCount() {
try {
// 第三个参数是共享计数的初始值
SharedCount sharedCount = new SharedCount(curatorFramework, "/curator/count", 0);
// 启动共享计数器
sharedCount.start();
// 获取共享计数的值
int count = sharedCount.getCount();
// 修改共享计数的值
int random = new Random().nextInt(1000);
sharedCount.setCount(random);
System.out.println("我获取了共享计数的初始值:" + count + ",并把计数器的值改为:" + random);
sharedCount.close();
} catch (Exception e) {
e.printStackTrace();
}
}3.7.7.2. DistributedAtomicNumber
DistributedAtomicNumber接口是分布式原子数值类型的抽象,定义了分布式原子数值类型需要提供的方法。
DistributedAtomicNumber接口有两个实现:DistributedAtomicLong 和 DistributedAtomicInteger

这两个实现将各种原子操作的执行委托给了DistributedAtomicValue,所以这两种实现是类似的,只不过表示的数值类型不同而已。这里以DistributedAtomicLong 为例进行演示
DistributedAtomicLong除了计数的范围比SharedCount大了之外,比SharedCount更简单易用。它首先尝试使用乐观锁的方式设置计数器, 如果不成功(比如期间计数器已经被其它client更新了), 它使用InterProcessMutex方式来更新计数值。此计数器有一系列的操作:
-
get(): 获取当前值
-
increment():加一
-
decrement(): 减一
-
add():增加特定的值
-
subtract(): 减去特定的值
-
trySet(): 尝试设置计数值
-
forceSet(): 强制设置计数值
你必须检查返回结果的succeeded(), 它代表此操作是否成功。如果操作成功, preValue()代表操作前的值, postValue()代表操作后的值。