前言
Pytest框架可以使用两种测试报告,其中一种就是使用pytest-html插件生成的测试报告,但是报告中有一些信息没有什么用途或者显示的不太好看,还有一些我们想要在报告中展示的信息却没有,最近又有人问我pytest-html生成的报告,能不能汉化?答案是肯定的,那么今天就教大家如何优化和汉化pytest-html测试报告解决上述问题
同时,在这我也准备了一份软件测试视频教程(含接口、自动化、性能等),需要的可以直接在下方观看,或者直接关注VX公众号:互联网杂货铺,免费领取
软件测试视频教程观看处:
软件测试工程师大忌!盲目自学软件测试真的会毁终生,能救一个是一个......
生成报告
我们先编写一个简单的测试代码,生成一份原始的测试报告,来看看哪些需要修改
测试代码
test_pytest_html.py
"""
------------------------------------
@Time : 2019/8/28 19:45
@Auth : linux超
@File : test_pytest_html.py
@IDE : PyCharm
@Motto: Real warriors,dare to face the bleak warning,dare to face the incisive error!
@QQ : 28174043@qq.com
@GROUP: 878565760
------------------------------------
"""
import pytest
def login(username, password):
"""模拟登录"""
user = "linux静"
pwd = "linux静静"
if user == username and pwd == password:
return {"code": 1001, "msg": "登录成功", "data": None}
else:
return {"code": 1000, "msg": "用户名或密码错误", "data": None}
test_data = [
# 测试数据
{
"case": "用户名正确, 密码正确",
"user": "linux静",
"pwd": "linux静静",
"expected": {"code": 1001, "msg": "登录成功", "data": None}
},
{
"case": "用户名正确, 密码为空",
"user": "linux静",
"pwd": "",
"expected": {"code": 1000, "msg": "用户名或密码错误", "data": None}
},
{
"case": "用户名为空, 密码正确",
"user": "",
"pwd": "linux静静",
"expected": {"code": 1000, "msg": "用户名或密码错误", "data": None}
},
{
"case": "用户名错误, 密码错误",
"user": "linux",
"pwd": "linux",
"expected": {"code": 1000, "msg": "用户名或密码错误", "data": None}
}
]
class TestLogin(object):
@pytest.mark.parametrize("data", test_data)
def test_login(self, data):
result = login(data["user"], data["pwd"])
assert result == data["expected"]
if __name__ == '__main__':
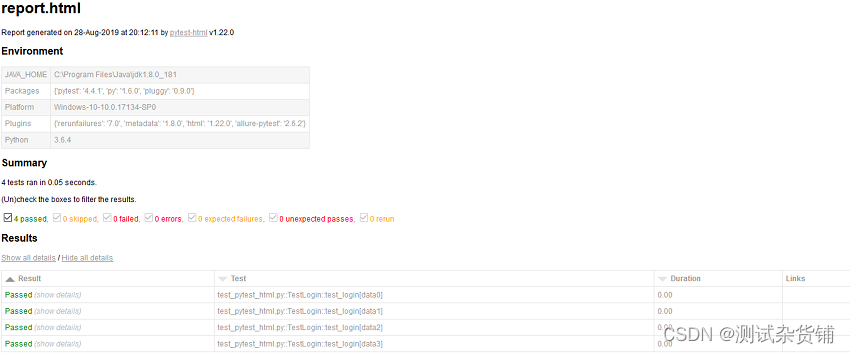
pytest.main(['-sv', "D:\PythonTest\MyPytestHtml\pytest_html_optimization", "--html", "report.html"])原始报告
修改Environment
可以看到原始的测试报告里面的Environment中所有的信息和我们的被测系统的环境关系不是很大,主要的信息其实是一些开发环境,那么如果我想添加或者删除一些信息,比如删除Java_Home,添加测试接口地址该如何添加讷?
我们需要在项目的根目录新键contest.py文件,文件中添加如下代码
def pytest_configure(config):
# 添加接口地址与项目名称
config._metadata["项目名称"] = "Linux超博客园自动化测试项目v1.0"
config._metadata['接口地址'] = 'https://www.cnblogs.com/linuxchao/'
# 删除Java_Home
config._metadata.pop("JAVA_HOME")修改后的效果

修改Summary
原始的Summary部分只显示了测试用例数及用例执行时间,那么如果我们想在这个位置添加测试人员等一些信息该如何实现?同样在conftest.py文件中添加如下代码:
@pytest.mark.optionalhook
def pytest_html_results_summary(prefix):
prefix.extend([html.p("所属部门: xx测试中心")])
prefix.extend([html.p("测试人员: Linux静")])修改后的效果

修改Results
Results主要展示的是测试结果信息,而且这里也有一些不符合我们实际需求的信息,比如Test列显示的内容很长,它主要是测试用例所在的路径及测试类,测试用例及测试数据拼接而成的,可读性很差,从这个描述根本看不出来我们的测试用例测试的是什么,所以我们希望它能这样显示:测试+用例名称[user:用户名-pwd:密码] ,如:测试用户名正确,密码正确[user:Linux超-pwd:Linux超哥],下面我们就来实现这样的效果
优化Test
先手我们分析一波源码,看一下原始的测试报告的Test列表的信息是怎么生成的。找到我们pytest-html插件的安装位置,打开plugin.py文件,你会发现这样一块代码
1 class TestResult:
2 def __init__(self, outcome, report, logfile, config):
3 self.test_id = report.nodeid
4 if getattr(report, "when", "call") != "call":
5 self.test_id = "::".join([report.nodeid, report.when])
6 self.time = getattr(report, "duration", 0.0)
7 self.outcome = outcome第3行,5行,就是报告中Test信息的来源了,test_pytest_html.py::TestLogin::test_login[data0] 这样一条信息,实际是用例的nodeid,而【data0】是测试用例参数化时的每个参数,ids的作用主要就是用来标记测试用例(不知道的可以去看一下那篇文章),增加测试用例执行后输出信息的可读性,因此我们可以使用这个参数来改变【data0】,让它显示我们的测试数据,ok,在我们的测试代码中添加并修改如下代码:
# 改变输出结果
ids = [
"测试:{}->[用户名:{}-密码:{}-预期:{}]".
format(data["case"], data["user"], data["pwd"], data["expected"]) for data in test_data
]
class TestLogin(object):
# 添加ids参数
@pytest.mark.parametrize("data", test_data, ids=ids)
def test_login(self, data):
result = login(data["user"], data["pwd"])
assert result == data["expected"]修改完之后再次执行我们的测试代码,生成测试报告
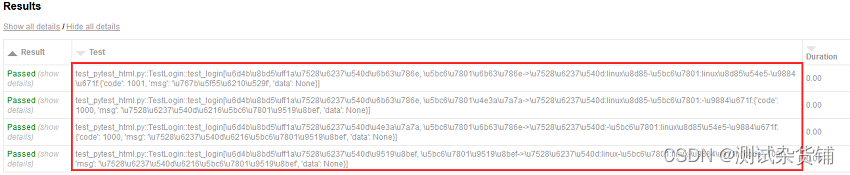
很遗憾,中文部分显示的都是乱码,还得继续修改
解决中文乱码
在conftest.py文件中继续添加如下代码:
import pytest
from py._xmlgen import html
@pytest.mark.hookwrapper
def pytest_runtest_makereport(item):
outcome = yield
report = outcome.get_result()
getattr(report, 'extra', [])
report.nodeid = report.nodeid.encode("utf-8").decode("unicode_escape") # 解决乱码再次执行测试代码,查看报告输出

中文已经可以正常显示了,很开心,但是前面还是有一堆的目录及测试类,我仍然不想要,那么我们继续修改
删除多余部分
要删除前面多余的部分,接下来只能通过修改报告的html了,因为源码中我实在没找到在哪里能够修改这个显示,我们查看一下html报告的页面元素属性
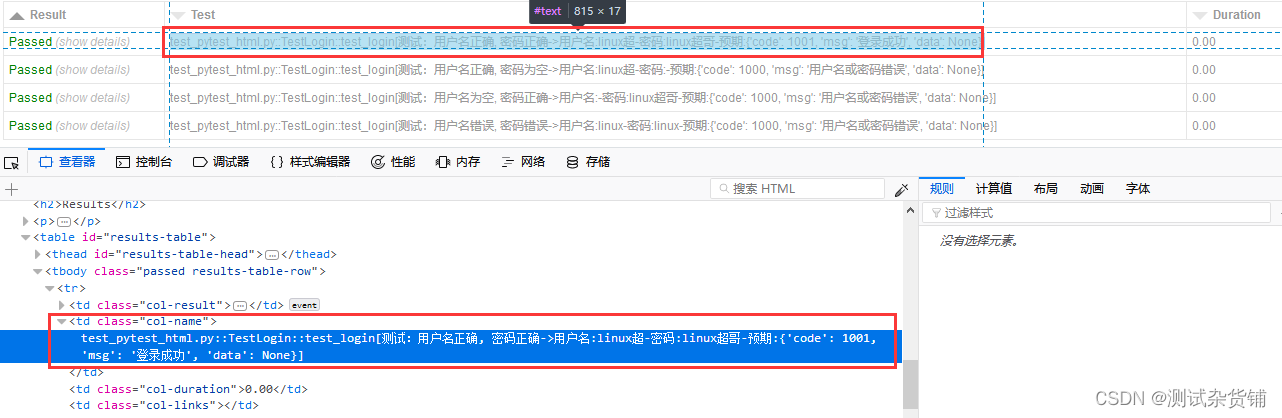
看到这里,你想到用什么方法来修改了嘛?我想到的是使用js代码改变这个元素的innerText, 我们先实验一下,切换到【控制台】依次执行如下代码
// 找到Test列中所有的表格元素
var test_name = document.getElementBysClassName("col-name");
// 修改第1个表格的innerText属性
test_name[0].innerText = test_name[0].innerText.split("\[")[1].split(["\]")[0]; // 以[符号分割一次,再以]分割一次,得到目标字符串
以上带代码只能修改一个表格,所以要修改多个表格只能使用循环了,再次重写js代码
var case_name_td = document.getElementsByClassName("col-name")
for(var i = 0; i < case_name_td.length; i++)
try{
case_name_td[i].innerText = case_name_td[i].innerText.split("\[")[1].split("\]")[0];
}
catch(err){
// 如果表格中没有[]会抛异常,如果抛异常我就显示null,如果你想显示别的东西自己改吧,因为通常只要我们使用参数化就有[]显示
case_name_td[i].innerText = "null";
}js代码我们已经写好了, 但是我们要放在哪里讷,又是个问题?通过查看报告的html源码我发现在html代码的开头引入了这样一些代码

在pytest-html插件的源码中,发现插件的resource目录下有一个main.js文件,里面的代码就是上述html代码中的js脚本,一模一样的

而且在main.js中确实存在一个init()方法,通过以上分析,应该不难猜测生成测试报告时,会自动把main.js文件加载到html中,而且是从init()方法开始的,因此我们尝试一下把我们编写的js代码放到init()方法内部实验一下
function init () {
reset_sort_headers();
add_collapse();
show_filters();
toggle_sort_states(find('.initial-sort'));
find_all('.sortable').forEach(function(elem) {
elem.addEventListener("click",
function(event) {
sort_column(elem);
}, false)
});
// 修改用例报告显示的用例名称 add by linux静
var case_name_td = document.getElementsByClassName("col-name")
for(var i = 0; i < case_name_td.length; i++)
try{
case_name_td[i].innerText = case_name_td[i].innerText.split("\[")[1].split("\]")[0];
}
catch(err){
// 如果表格中没有[]会抛异常,如果抛异常我就显示null,如果你想显示别的东西自己改吧,因为通常只要我们使用参数化就有[]显示
case_name_td[i].innerText = "null";
}
};添加完之后记得保存,再次执行测试代码,查看测试报告
修改后的效果

你没有看错,确实成功了,小小成就感还是有的,哈哈!
删除Links
报告中的links从来没看见有内容过,所以我打算把这一列删除,在contest.py文件中添加如下代码
@pytest.mark.optionalhook
def pytest_html_results_table_header(cells):
cells.pop(-1) # 删除link列
@pytest.mark.optionalhook
def pytest_html_results_table_row(report, cells):
cells.pop(-1) # 删除link列修改后的效果

增加失败截图与用例描述
用例添加失败截图和添加一列用例的描述信息,在之前文章中已经说过了,所以你可以通过以下链接去看我之前的文章,错误截图只有web自动化测试才会有哦
完整的conftest.py代码
"""
------------------------------------
@Time : 2019/8/28 19:50
@Auth : linux超
@File : conftest.py
@IDE : PyCharm
@Motto: Real warriors,dare to face the bleak warning,dare to face the incisive error!
@QQ : 28174043@qq.com
@GROUP: 878565760
------------------------------------
"""
import pytest
from selenium import webdriver
from py._xmlgen import html
driver = None
@pytest.mark.hookwrapper
def pytest_runtest_makereport(item):
"""当测试失败的时候,自动截图,展示到html报告中"""
outcome = yield
pytest_html = item.config.pluginmanager.getplugin('html')
report = outcome.get_result()
extra = getattr(report, 'extra', [])
# 如果你生成的是web ui自动化测试,请把下面的代码注释打开,否则无法生成错误截图
# if report.when == 'call' or report.when == "setup":
# xfail = hasattr(report, 'wasxfail')
# if (report.skipped and xfail) or (report.failed and not xfail): # 失败截图
# file_name = report.nodeid.replace("::", "_") + ".png"
# screen_img = capture_screenshot()
# if file_name:
# html = '<div><img src="data:image/png;base64,%s" alt="screenshot" style="width:600px;height:300px;" ' \
# 'onclick="window.open(this.src)" align="right"/></div>' % screen_img
# extra.append(pytest_html.extras.html(html))
# report.extra = extra
extra.append(pytest_html.extras.text('some string', name='Different title'))
report.description = str(item.function.__doc__)
report.nodeid = report.nodeid.encode("utf-8").decode("unicode_escape") # 解决乱码
def capture_screenshot():
'''截图保存为base64'''
return driver.get_screenshot_as_base64()
def pytest_configure(config):
# 添加接口地址与项目名称
config._metadata["项目名称"] = "Linux超博客园自动化测试项目v1.0"
config._metadata['接口地址'] = 'https://www.cnblogs.com/linuxchao/'
# 删除Java_Home
config._metadata.pop("JAVA_HOME")
@pytest.mark.optionalhook
def pytest_html_results_summary(prefix):
prefix.extend([html.p("所属部门: xx测试中心")])
prefix.extend([html.p("测试人员: Linux静")])
@pytest.mark.optionalhook
def pytest_html_results_table_header(cells):
cells.insert(1, html.th('Description'))
cells.pop(-1) # 删除link列
@pytest.mark.optionalhook
def pytest_html_results_table_row(report, cells):
cells.insert(1, html.td(report.description))
cells.pop(-1) # 删除link列
@pytest.fixture(scope='session')
def driver():
global driver
print('------------open browser------------')
driver = webdriver.Firefox()
yield driver
print('------------close browser------------')
driver.quit()汉化报告
最后一步,汉化我们的测试报告,因为都是英文的,可能有的同学不太喜欢或者说领导不太喜欢,接下来就开始我们的汉化之路,汉化还是比较简单的, 只要小心谨慎即可
声明:以下修改的所有文件均存在pytest-html插件的源码目录下
修改plugin.py
plugin.py文件主要用来生成测试报告的html代码的,因此汉化肯定离不开修改这个文件了,接下来一步一步按照我的步骤修改吧(注释部分是源码,紧接着的是我修改后的代码)
# if len(log) == 0:
# log = html.div(class_='empty log')
# log.append('No log output captured.')
if len(log) == 0: # modify by linux超
log = html.div(class_='empty log')
log.append('未捕获到日志')
additional_html.append(log)
# head = html.head(
# html.meta(charset='utf-8'),
# html.title('Test Report'),
# html_css)
head = html.head( # modify by linux超
html.meta(charset='utf-8'),
html.title('测试报告'),
html_css)
# outcomes = [Outcome('passed', self.passed),
# Outcome('skipped', self.skipped),
# Outcome('failed', self.failed),
# Outcome('error', self.errors, label='errors'),
# Outcome('xfailed', self.xfailed,
# label='expected failures'),
# Outcome('xpassed', self.xpassed,
# label='unexpected passes')]
outcomes = [Outcome('passed', self.passed, label="通过"),
Outcome('skipped', self.skipped, label="跳过"),
Outcome('failed', self.failed, label="失败"),
Outcome('error', self.errors, label='错误'),
Outcome('xfailed', self.xfailed,
label='预期失败'),
Outcome('xpassed', self.xpassed,
label='预期通过')]
# if self.rerun is not None:
# outcomes.append(Outcome('rerun', self.rerun))
if self.rerun is not None:
outcomes.append(Outcome('重跑', self.rerun))
# summary = [html.p(
# '{0} tests ran in {1:.2f} seconds. '.format(
# numtests, suite_time_delta)),
# html.p('sfsf',
# class_='filter',
# hidden='true')]
summary = [html.p( # modify by linux超
'执行了{0}个测试用例, 历时:{1:.2f}秒 . '.format(
numtests, suite_time_delta)),
html.p('(取消)勾选复选框, 以便筛选测试结果',
class_='filter',
hidden='true')]
# cells = [
# html.th('Result',
# class_='sortable result initial-sort',
# col='result'),
# html.th('Test', class_='sortable', col='name'),
# html.th('Duration', class_='sortable numeric', col='duration'),
# html.th('Links')]# modify by linux超
cells = [
html.th('通过/失败',
class_='sortable result initial-sort',
col='result'),
html.th('用例', class_='sortable', col='name'),
html.th('耗时', class_='sortable numeric', col='duration'),
html.th('链接')]
# results = [html.h2('Results'), html.table([html.thead(
# html.tr(cells),
# html.tr([
# html.th('No results found. Try to check the filters',
# colspan=len(cells))],
# id='not-found-message', hidden='true'),
# id='results-table-head'),
# self.test_logs], id='results-table')]
results = [html.h2('测试结果'), html.table([html.thead( # modify by linux超
html.tr(cells),
html.tr([
html.th('无测试结果, 试着选择其他测试结果条件',
colspan=len(cells))],
id='not-found-message', hidden='true'),
id='results-table-head'),
self.test_logs], id='results-table')]
#html.p('Report generated on {0} at {1} by '.format(
html.p('生成报告时间{0} {1} Pytest-Html版本:'.format( # modify by linux超
# body.extend([html.h2('Summary')] + summary_prefix
# + summary + summary_postfix)
body.extend([html.h2('用例统计')] + summary_prefix # modify by linux超
+ summary + summary_postfix)
# environment = [html.h2('Environment')]
environment = [html.h2('测试环境')] # modify by linux超plugin.py文件到这就修改完了,你可以生成报告查看以下效果,接下来修改main.js
修改main.js
/*
function add_collapse() {
// Add links for show/hide all
var resulttable = find('table#results-table');
var showhideall = document.createElement("p");
showhideall.innerHTML = '<a href="javascript:show_all_extras()">Show all details</a> / ' +
'<a href="javascript:hide_all_extras()">Hide all details</a>';
resulttable.parentElement.insertBefore(showhideall, resulttable);
*/
function add_collapse() { // modify by linux超
// Add links for show/hide all
var resulttable = find('table#results-table');
var showhideall = document.createElement("p");
showhideall.innerHTML = '<a href="javascript:show_all_extras()">显示详情</a> / ' +
'<a href="javascript:hide_all_extras()">隐藏详情</a>';
resulttable.parentElement.insertBefore(showhideall, resulttable);
修改style.css最后修改style.css,这个文件主要用来美化测试报告的,如果你对css比较熟悉,可以自定义报告样式
.expander::after {
content: " (展开详情)";
color: #BBB;
font-style: italic;
cursor: pointer;
}
.collapser::after {
content: " (隐藏详情)";
color: #BBB;
font-style: italic;
cursor: pointer;
}到目前为止,所有的汉化都已经完成了,接下来我们执行一下测试代码,查看一下报告的效果
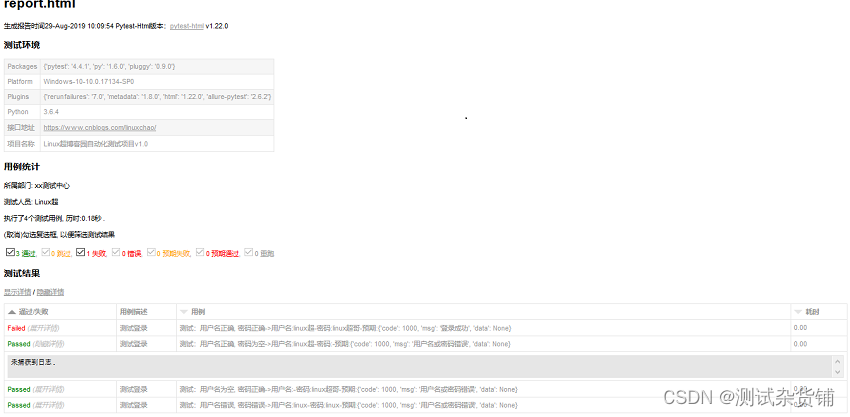
最后报告效果
安装汉化版插件
为了方便大家使用,跳过修改源码过程,我已经把汉化版的pytest-html插件源码上传到了我的GitHub ,下面说一下使用方法
方法1
1.如果你已经安装过了pytest-html,请先卸载 pip uninstall pytest-html
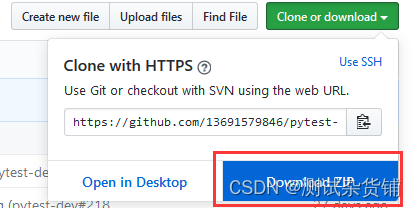
2.下载插件源码到本地,git clone https://github.com/13691579846/pytest-html 或者按照下图方法下载
3.打开CMD切换到插件中setup.py文件所在目录,执行如下命令
python setup.py install
方法2
1.如果你未安装过pytest-html插件,请先执行如下命令安装
pip install pytest-html
2.按照方法1的方式下载汉化后的插件,把下载后的插件中的部分分件覆盖到python第三方库目录下pytest-html下的部分文件

方法3
直接下载汉化后的源码,把源码中的pytest_html直接丢到python第三方库存放目录也可
方法4
最后一个方法就是按照我的文章步骤,一步一步修改自己的源码
方法5
下载pytest源码后使用pip install ./pytest-html 安装
总结
PS:这里分享一套软件测试的自学教程合集。对于在测试行业发展的小伙伴们来说应该会很有帮助。除了基础入门的资源,博主也收集不少进阶自动化的资源,从理论到实战,知行合一才能真正的掌握。全套内容已经打包到网盘,内容总量接近500个G。如需要软件测试学习资料,关注公众号(互联网杂货铺),后台回复1,整理不易,给个关注点个赞吧,谢谢各位大佬!

这些资料,对于做【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!凡事要趁早,特别是技术行业,一定要提升技术功底。




![[ChatGPT]ChatGPT免费,不用翻墙!?——你需要的装备](https://img-blog.csdnimg.cn/d70072bc422845e6934a54ef767d470b.png)