在机器学习和深度学习中,前向传播和损失函数是两个关键概念。它们在神经网络的训练过程中起着重要的作用,帮助模型学习和优化参数。
一、前向传播
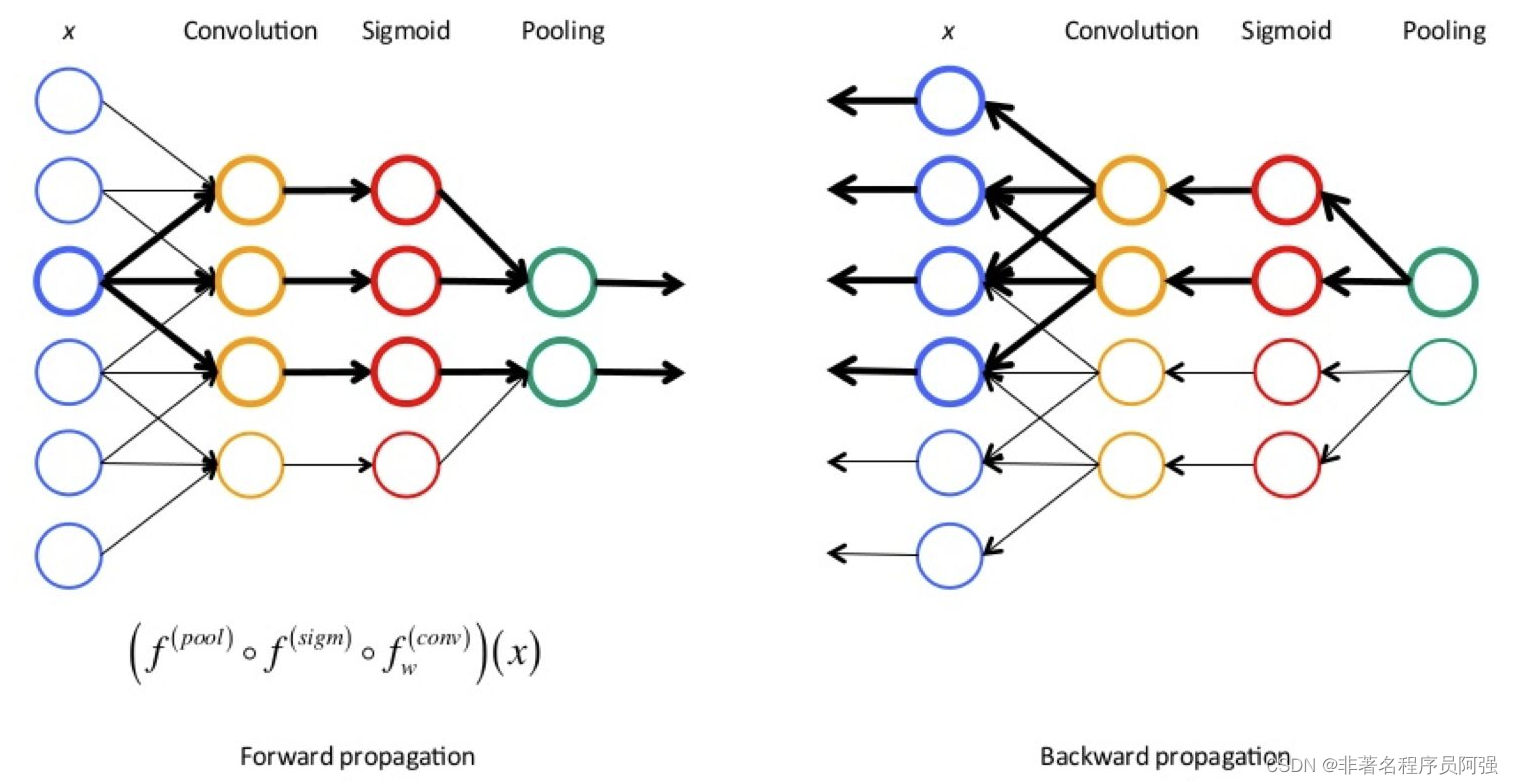
前向传播是机器学习和深度学习中一种信息传递的过程。在神经网络中,前向传播指的是将输入数据通过网络的各个层,依次传递到输出层的过程。
在前向传播中,每一层的神经元会根据输入数据和对应的权重进行计算,产生一个输出。这个输出又会作为下一层的输入,参与到下一层的计算中。通过这种方式,数据会在网络中不断传递,直到达到输出层。
在传统的神经网络中,前向传播的计算可以用矩阵乘法和非线性激活函数来表示。首先,将输入数据表示为一个向量,然后和对应的权重矩阵进行乘法运算,得到一个中间层的输出。接着,对这个输出应用非线性激活函数,以引入非线性变换。最后,将这个结果作为下一层的输入,依次进行计算,直到达到输出层。
通过前向传播,神经网络可以通过学习输入数据和对应标签之间的模式,实现对未知数据的预测和分类。前向传播过程中的参数即网络的权重和偏置,最终会被用于计算损失函数。
二、损失函数
损失函数是衡量模型预测结果与实际标签之间差异的指标。在机器学习和深度学习中,通常使用损失函数来衡量模型的性能。
损失函数的选择通常取决于具体的任务和数据类型。对于分类问题,常用的损失函数包括交叉熵损失函数、对数损失函数等;对于回归问题,常用的损失函数包括均方误差损失函数、平均绝对误差损失函数等。
在训练神经网络时,我们的目标是最小化损失函数。通过反向传播算法,我们可以根据损失函数的导数来调整网络中的权重和偏置,从而使得模型能够更好地拟合训练数据。
损失函数的选择和优化对于模型的性能和泛化能力有重要影响。一个合适的损失函数可以帮助模型更好地学习数据之间的模式,并且在实际应用中能够得到良好的结果。
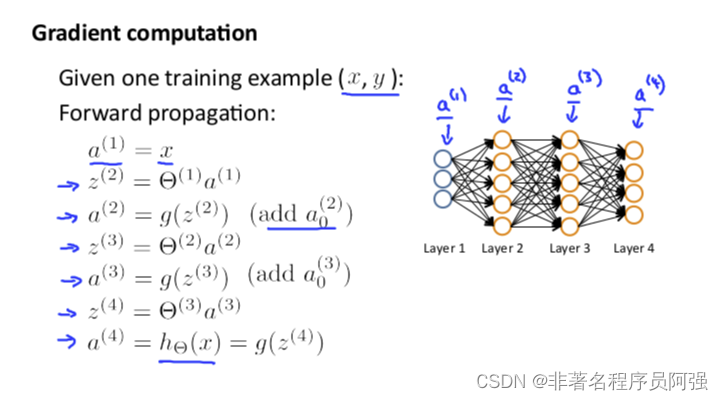
三、前向传播与损失函数的关系
前向传播和损失函数是紧密相关的。在前向传播过程中,数据会通过网络的各个层,最终到达输出层。在这个过程中,每一层的神经元会根据输入数据和权重进行计算,产生一个输出。
而损失函数衡量了模型的预测结果与实际标签之间的差异。通过比较预测结果和实际标签,损失函数可以量化模型的性能,评估其预测的准确性和误差大小。
在训练过程中,我们通过最小化损失函数来优化模型。通过反向传播算法,我们可以根据损失函数关于网络参数的导数,来调整参数的取值,从而使得模型的预测结果更接近真实标签。
通过不断迭代前向传播和损失函数的计算,我们可以逐渐优化模型的性能。最终,我们可以得到一个在训练数据上表现良好的模型,能够在新数据上做出准确的预测。
总结:
前向传播和损失函数是机器学习和深度学习中非常重要的概念。前向传播是将输入数据通过网络的各个层,传递到输出层的过程,帮助模型学习输入数据和对应标签之间的模式。损失函数衡量了模型的预测结果与实际标签之间的差异,帮助我们评估和优化模型的性能。
在神经网络的训练过程中,我们通过最小化损失函数来优化模型。通过反向传播算法,我们可以根据损失函数关于网络参数的导数,来调整参数的取值,从而使得模型的预测结果更接近真实标签。
人工智能的学习之路非常漫长,不少人因为学习路线不对或者学习内容不够专业而举步难行。不过别担心,我为大家整理了一份600多G的学习资源,基本上涵盖了人工智能学习的所有内容。点击下方链接,0元进群领取学习资源,让你的学习之路更加顺畅!记得点赞、关注、收藏、转发哦!扫码进群领资料


![P8599 [蓝桥杯 2013 省 B] 带分数(dfs+全排列+断点判断)](https://img-blog.csdnimg.cn/a340ed91cf984ee79e92afbfe35ac004.png)