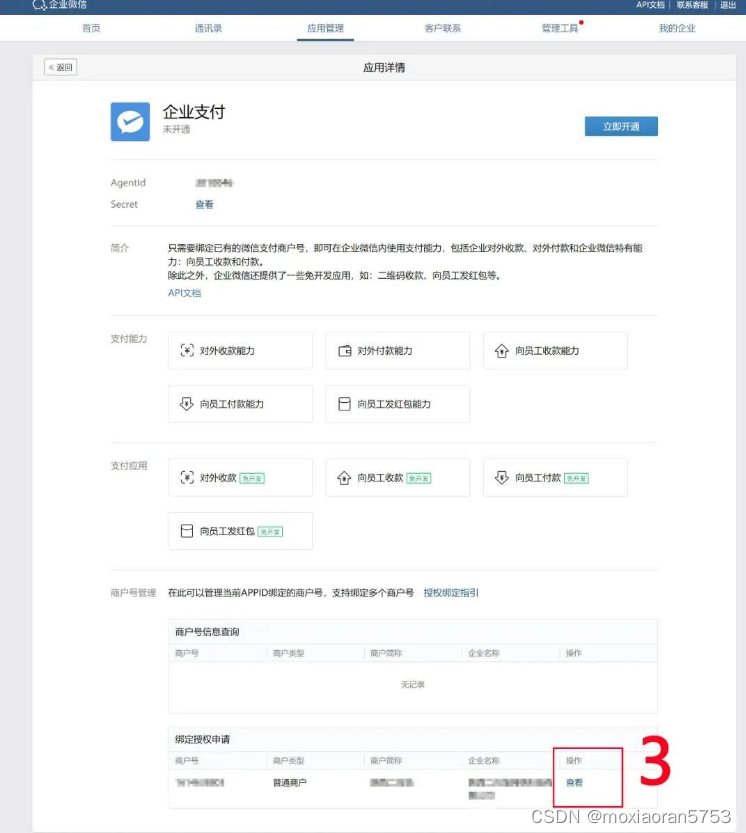
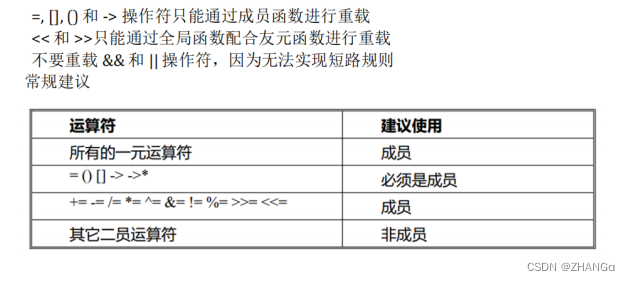
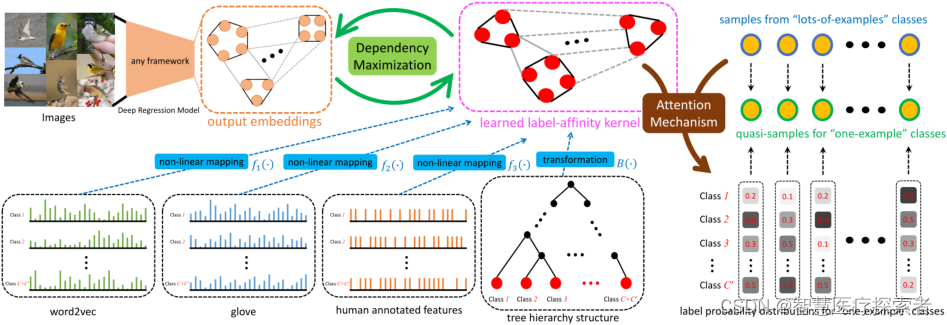
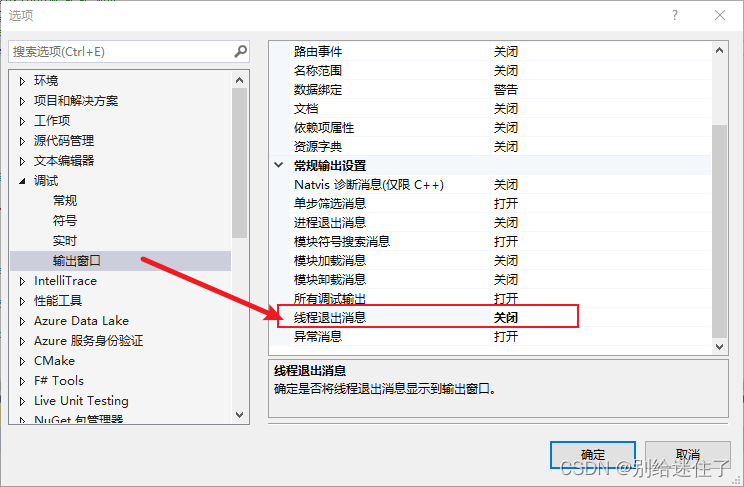
最近在看时间序列的文章,回顾下经典
论文地址
项目地址
Forecasting at Scale
- 3.2、季节性
- 3.3、假日和活动事件
- 3.4、模型拟合
- 3.5、分析师参与的循环建模
- 4、自动化预测评估
- 4.1、使用基线预测
- 4.2、建模预测准确性
- 4.3、模拟历史预测
- 4.4、识别大的预测误差
- 5、结论
- 6、致谢
3.2、季节性
企业时间序列通常由于它们所代表的人类行为而具有多期季节性。例如,5天的工作周可以在时间序列上产生每周重复的效应,而假期安排和学校放假可以产生每年重复的效应。为了拟合和预测这些效应,我们必须指定季节性模型,这些模型是关于 t 的周期函数。
我们依靠傅立叶级数提供周期效应的灵活模型(Harvey & Shephard 1993)。让 P 表示我们期望时间序列具有的常规周期(例如,对于年度数据,P = 365.25;对于每周数据,当我们将时间变量按天计算时,P = 7)。我们可以用傅立叶级数来近似任意平滑的季节效应
s ( t ) = ∑ n = 1 N ( a n c o s ( 2 π n t P ) + b n s i n ( 2 π n t P ) ) s(t)= \sum_{n=1}^{N}(a_ncos(\frac{ 2πnt}{P})+b_nsin(\frac{ 2πnt}{P})) s(t)=∑n=1N(ancos(P2πnt)+bnsin(P2πnt))
标准傅立叶级数。拟合季节性需要估计2N个参数 β = [ a 1 , b 1 , . . . , a N , b N ] T β=[a_1,b_1,...,a_N,b_N]^{\texttt{T}} β=[a1,b1,...,aN,bN]T。这是通过为历史和未来数据中的每个 t 值构建一个季节性向量矩阵来完成的,例如,对于每年的季节性和 N = 10。
X ( t ) = [ c o s ( 2 π ( 1 ) t 356.25 ) , . . . , s i n ( 2 π ( 10 ) t 356.25 ) ] X(t)=\begin{bmatrix} cos(\frac{ 2π(1)t}{356.25}), ...,sin(\frac{ 2π(10)t}{356.25}) \end{bmatrix} X(t)=[cos(356.252π(1)t),...,sin(356.252π(10)t)] (5)
季节性成分是
s ( t ) = X ( t ) β s(t)=X(t)β s(t)=X(t)β (6)
在我们的生成模型中,我们采用 β N o r m a l ( 0 , σ 2 ) β~Normal(0, σ^2) β Normal(0,σ2)对季节性施加平滑先验。
将序列截断到 N,对季节性施加了低通滤波器,因此增加 N 可以适应更快变化的季节模式,尽管存在过度拟合的风险。对于年度和每周季节性,我们发现分别使用 N = 10 和 N = 3 对大多数问题效果良好。选择这些参数可以使用诸如 AIC 的模型选择过程进行自动化。
3.3、假日和活动事件
假期和事件对许多企业时间序列提供了大而有些可预测的冲击,通常不遵循周期模式,因此它们的影响无法很好地通过平滑周期来建模。例如,美国的感恩节是在11月的第四个星期四举行的。美国最大的电视节目之一——超级碗则在1月或2月的某个星期日举行,难以编程声明。世界上许多国家有根据农历计算的重要节日。特定假期对时间序列的影响通常每年相似,因此将其纳入预测非常重要。
我们允许分析师提供一个自定义的过去和未来事件列表,由该事件或假期的唯一名称识别,如表1所示。我们包括一个国家列,以便除全球节日外,保留特定于国家的节日列表。对于给定的预测问题,我们使用全球节日集合和特定国家节日集合的并集。
将这个假期列表纳入模型中是基于假设假期效应是独立的。对于每个假期 i,设 D i D_i Di 为该假期的过去和未来日期集合。我们添加一个指示函数,表示时间 t 是否在假期 i 期间,并为每个假期分配一个参数 κ i κ_i κi,该参数是相应预测变化。这与季节性类似,通过生成回归器矩阵来完成。
Z ( t ) = [ 1 ( t ∈ D 1 ) , . . . , 1 ( t ∈ D L ) ] Z(t) = [1(t \in D_1),..., 1(t \in D_L)] Z(t)=[1(t∈D1),...,1(t∈DL)]
并采用
h ( t ) = Z ( t ) κ h(t)=Z(t)κ h(t)=Z(t)κ (7)
与季节性一样,我们使用先验 κ ∼ N o r m a l ( 0 , v 2 ) κ \sim Normal(0,v^2) κ∼Normal(0,v2)。
通常,包括特定假期前后一段时间窗口的效应非常重要,比如感恩节周末。为了解决这个问题,我们为假期周围的日期添加额外的参数,本质上将假期周围的每一天都视为一个假期。
3.4、模型拟合
当将每个观测的季节性和假期特征结合到矩阵X中,并将变化点指示符a(t)结合到矩阵A中时,模型(1)可以在几行Stan代码(Carpenter et al. 2017)中表示,如下所示。对于模型拟合,我们使用Stan的L-BFGS算法找到最大后验估计,但也可以进行完整的后验推断,将模型参数的不确定性包括在预测的不确定性中。

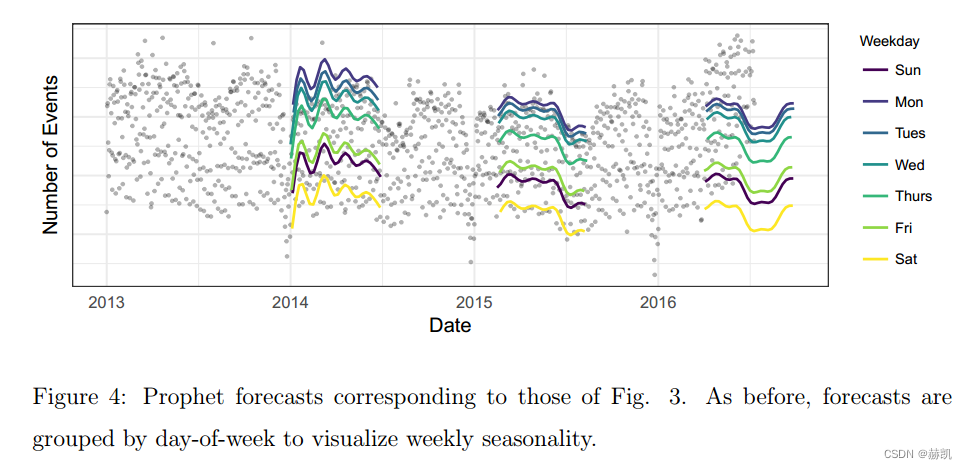
图4显示了Prophet模型对图3中Facebook事件时间序列的预测。这些预测与图3中相同的三个日期一样,仅使用该日期之前的数据进行预测。Prophet模型能够预测每周和每年的季节性,与图3中的基准模型不同,它不会对第一年的假期下降作出过度反应。在第一个预测中,Prophet模型在只有一年数据的情况下稍微过拟合了每年的季节性。在第三个预测中,模型还没有学习到趋势已经发生变化。图5显示了一个包含最近三个月数据的预测展示了趋势的变化(虚线)。
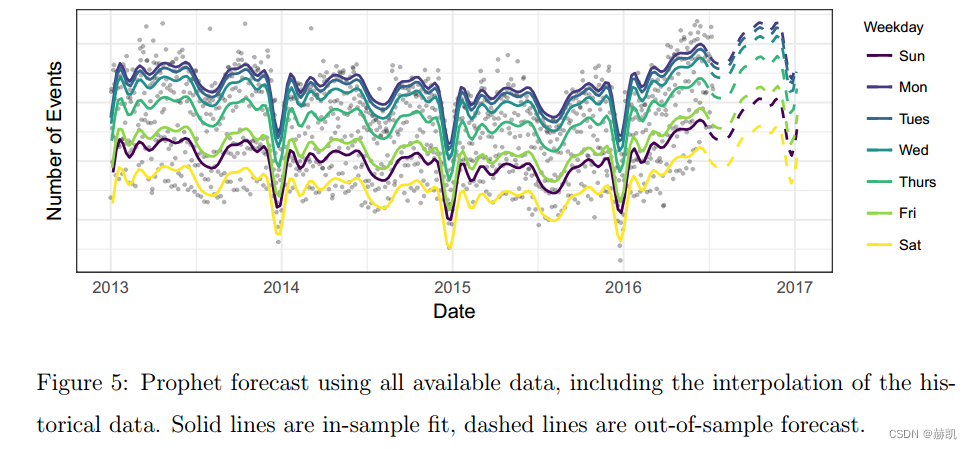
可分解模型的一个重要优势是它允许我们分别观察预测的每个组成部分。图6显示了与图4中最后一个预测相对应的趋势、每周季节性和每年季节性组件。除了产生预测之外,这为分析师提供了洞察他们的预测问题的有用工具。
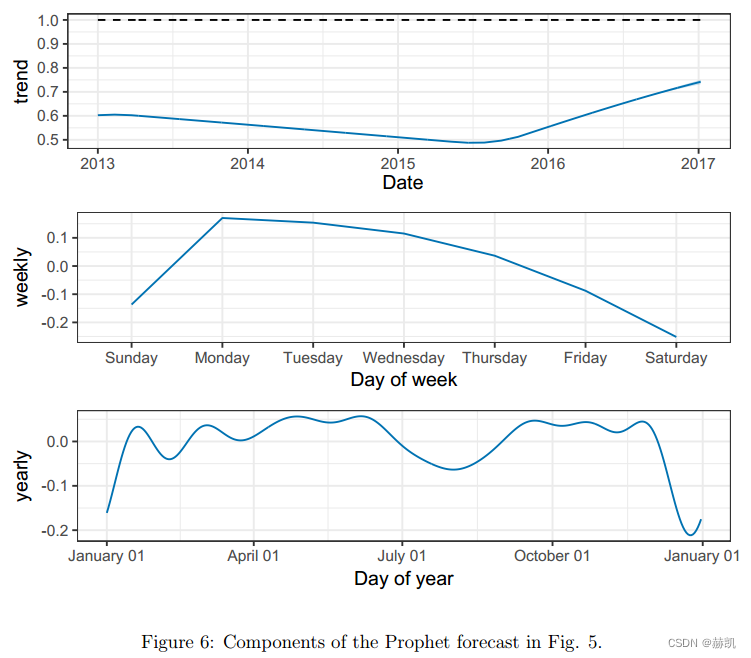
清单1中的参数tau和sigma是对模型变化点和季节性正则化程度的控制参数。正则化对于避免过拟合是重要的,然而,很可能没有足够的历史数据通过交叉验证来选择最佳的正则化参数。我们设置了适用于大多数预测问题的默认值,并且当需要优化这些参数时,会与分析师进行协商。
3.5、分析师参与的循环建模
经常进行预测的分析师通常对其所预测的数量具有丰富的领域知识,但在统计知识方面却知之甚少。在Prophet模型规范中,有几个地方可以让分析师调整模型以应用他们的专业知识和外部知识,而无需理解底层统计学。
-
能力:分析师可能拥有关于总市场规模的外部数据,并可以直接通过指定容量来应用这些知识。
-
变化点:已知的变化点日期,如产品变更日期,可以直接指定。
-
假期和季节性:我们合作的分析师具有哪些假期影响哪些地区增长的经验,他们可以直接输入相关的假期日期和适用的季节性时间尺度。
-
平滑参数:通过调整 τ τ τ,分析师可以从更全局或局部平滑的模型范围内进行选择。季节性和假期平滑参数 ( σ , ν ) (σ,ν) (σ,ν)允许分析师告诉模型未来预期的历史季节变化有多少。
借助良好的可视化工具,分析师可以使用这些参数来改进模型拟合。当将模型拟合绘制在历史数据上时,很快就能发现自动变化点选择中遗漏了哪些变化点。τ参数是一个单一的旋钮,可以调整趋势的灵活性,σ是调整季节性分量强度的旋钮。可视化提供了许多其他有益的人为干预机会:线性趋势或逻辑增长、确定季节性的时间尺度以及确定应该从拟合中剔除的异常时间段等。所有这些干预都可以在没有统计专业知识的情况下进行,是分析师应用其见解或领域知识的重要途径。
预测文献通常区分基于历史数据拟合的统计预测和人为判断的预测(也称为管理预测),后者由人类专家使用已经学到对特定时间序列有效的任何过程产生。这两种方法各有其优势。统计预测需要较少的领域知识和人类预测者的努力,并且可以轻松扩展到许多预测。人为判断的预测可以包含更多信息,并且对变化的条件更具响应性,但可能需要分析师进行大量工作。
我们的分析师参与的循环建模方法是一种替代方法,试图通过使分析师的努力集中于在必要时改进模型而不是通过某种未经说明的程序直接产生预测,从而融合了统计和人为判断预测的优势。我们发现我们的方法与Wickham和Grolemund(2016)提出的“转换-可视化-建模”循环非常相似,其中人类领域知识在一些迭代之后被编码到改进的模型中。
典型的预测扩展依赖于完全自动化的程序,但已经在许多应用中显示,人为判断的预测在准确性上表现出色。我们提出的方法让分析师可以通过一小组直观的模型参数和选项对预测进行判断,同时保留在必要时回归到完全自动化的统计预测的能力。截至目前,我们只有零星的实证证据表明可能会改进准确性,但我们期待未来的研究可以评估分析师在模型辅助设置中的改进效果。
在规模化的情况下,让分析师参与其中的能力至关重要,这在很大程度上依赖于预测质量的自动评估和良好的可视化工具。我们现在描述如何自动化预测评估,以确定最相关的预测以供分析师输入。
4、自动化预测评估
在本节中,我们概述了一种通过比较各种方法并确定需要手动干预的预测的流程来自动化预测绩效评估的方法。这个部分与所使用的预测方法无关,并包含我们在多种应用中进行生产业务预测时制定的一些最佳实践。
4.1、使用基线预测
在评估任何预测过程时,比较一组基线方法非常重要。我们喜欢使用简单的预测方法,对底层过程进行强烈的假设,但在实践中可以产生合理的预测。我们发现比较简单的模型(最后一个值和样本均值)以及第2节中描述的自动预测程序非常有用。
4.2、建模预测准确性
预测是在一定的时间范围内进行的,我们用H表示这个范围。这个范围是我们关心预测未来多少天的数量,通常是30、90、180或365天。因此,对于任何具有每日观察的预测,我们会产生高达H个未来状态的估计,每个状态都会与一些误差相关联。我们需要声明一个预测目标来比较方法和跟踪绩效。此外,了解我们的预测过程有多容易出错可以让企业预测的使用者决定是否信任它。
设 y ^ ( t ∣ T ) \widehat{y}(t|T) y (t∣T)表示用直到时间t的历史信息对时间T进行的预测,并且 d ( y , y ′ ) d(y,{y}') d(y,y′)是距离度量,例如平均绝对误差, d ( y , y ′ ) = ∣ y − y ′ ∣ d(y,{y}')=|y- {y}'| d(y,y′)=∣y−y′∣。距离函数的选择应该是特定于问题的。De Gooijer和Hyndman(2006)回顾了几种这样的误差度量{在实践中,我们更喜欢平均绝对百分比误差(MAPE)的可解释性。我们将时间T之前 h ∈ ( 0 , H ] h \in(0,H] h∈(0,H]时段的预测的经验准确性定义为:
ϕ ( T , h ) = d ( y ^ ( T + h ∣ T ) , y ( T + h ) ) \phi (T,h)=d(\widehat{y}(T+h|T),y(T+h)) ϕ(T,h)=d(y (T+h∣T),y(T+h))
为了对准确性及其随h的变化进行估计,通常会指定误差项的参数模型,并从数据中估计其参数。例如,如果我们使用AR(1)模型 y ( t ) = α + β y ( t − 1 ) + ν ( t ) y(t) = α + βy(t − 1) + ν(t) y(t)=α+βy(t−1)+ν(t),我们会假设 ν ( t ) ∼ N o r m a l ( 0 , σ v 2 ) ν(t) ∼ Normal(0,σ_{v}^{2}) ν(t)∼Normal(0,σv2),并专注于从数据中估计方差项 σ v 2 σ_{v}^{2} σv2。然后,我们可以通过模拟或使用错误总和的期望的解析表达式来使用任何距离函数形成期望。不幸的是,这些方法只在已经针对过程指定了正确模型的条件下给出正确的误差估计,而这在实践中不太可能发生。
我们更倾向于采用适用于各种模型的非参数方法来估计预期误差。这种方法类似于在独立同分布数据上对进行预测的模型估计外样本误差的交叉验证。给定一组历史预测,我们拟合一个关于不同预测时域h的预期误差模型。
ξ ( h ) = E [ ϕ ( T , h ) ] ξ(h)=E[\phi (T, h)] ξ(h)=E[ϕ(T,h)] (8)
该模型应该是灵活的,但也可以提出一些简单的假设。首先,函数在h上应该是局部平滑的,因为我们预计连续几天犯的错误相对类似。其次,我们可能会假设该函数在h上应该是微弱递增的,尽管这并不适用于所有预测模型。在实践中,我们使用局部回归(Cleveland和Devlin 1988)或同位素回归(Dykstra 1981)作为误差曲线的灵活非参数模型。
为了生成历史预测误差以拟合该模型,我们使用一种称为模拟历史预测的过程。
4.3、模拟历史预测
我们希望通过拟合(8)式中的预期误差模型来进行模型选择和评估。遗憾的是,使用类似交叉验证的方法比较困难,因为观测数据不可互换 - 我们不能简单地随机划分数据。我们使用模拟历史预测(SHFs)在历史的不同截断点处产生K个预测,这些截断点被选择为使预测时间段位于历史之内,并且可以评估总体误差。这个过程基于传统的“滚动起源”预测评估程序(Tashman,2000),但只使用了一小组截断日期,而不是每个历史日期都进行一次预测。使用较少的模拟日期的主要优点是节约计算资源,同时提供更少相关性的准确度测量。
SHFs模拟了我们在过去的那些时间点上使用该预测方法所犯的误差。图3和图4中的预测就是SHFs的例子。这种方法的优点是简单易懂,容易向分析师和决策者解释,而且用于生成对预测误差的洞察相对无争议。在使用SHF方法评估和比较预测方法时,需要注意两个主要问题。
首先,我们进行的模拟预测越多,它们对误差的估计就越相关。在极端情况下,如果在历史的每一天进行一次模拟预测,考虑到额外的一天信息,预测不太可能发生太大变化,并且从一天到下一天的误差几乎相同。另一方面,如果我们只进行很少的模拟预测,那么我们就只有很少的历史预测误差观测值可供我们基于其选择模型。作为一种经验法则,对于预测时间段为H,我们通常每隔H=2个周期进行一次模拟预测。尽管相关的估计不会引入模型准确度的偏差,但它们会产生较少有用的信息并减慢预测评估的速度。
其次,更多的数据可能导致预测方法的表现更好或更差。当模型规范错误且过度拟合过去时,更长的历史可能会导致更糟糕的预测,例如使用样本均值来预测具有趋势的时间序列。图7显示了LOESS方法在图3和图4的时间序列上使用的预测期间的预期平均绝对百分比误差函数ξ(h)的估计值。该估计是使用九个模拟预测日期进行的,每个季度开始后选择一个日期。Prophet在所有预测时间段上都具有较低的预测误差。Prophet的预测是使用默认设置进行的,调整参数可能进一步提高性能。
在可视化预测时,我们更喜欢使用点而不是线来表示历史数据,因为这些点代表精确的测量结果,永远不会进行插值。然后,我们通过预测叠加线条。对于SHFs,将模型在不同预测时间段上的误差可视化是有用的,既可以作为时间序列(如图3),也可以作为SHFs的汇总(如图7)。
即使对于单个时间序列,SHFs也需要计算许多预测,而且在规模上,我们可能希望对许多不同的指标以及多个不同的聚合级别进行预测。只要这些机器可以写入相同的数据存储,SHFs可以在独立的机器上进行计算。我们将预测和相关误差存储在Hive或MySQL中,具体取决于它们的预期使用方式。
4.4、识别大的预测误差
当有太多的预测需要分析师手动检查时,能够自动识别可能存在问题的预测就变得非常重要。自动识别不良预测可以让分析师更有效地利用有限的时间,并利用他们的专业知识来纠正任何问题。以下是使用SHFs来识别预测可能存在问题的几种方法:
-
当相对于基准线而言,预测误差较大时,可能是因为模型规范错误。分析师可以根据需要调整趋势模型或季节性模型。
-
对于特定日期,所有方法都存在较大的误差,这可能是异常值的表现。分析师可以识别并排除异常值。
-
当某个方法的SHF误差从一个截断点急剧增加到下一个截断点时,这可能表明数据生成过程发生了变化。添加变点或将不同阶段分开建模可能会解决这个问题。
虽然有些问题无法轻易纠正,但我们遇到的大多数问题都可以通过指定变点和排除异常值来纠正。一旦预测被标记为需要审核并可视化,这些问题就很容易被识别和纠正。
5、结论
规模化预测的一个重要主题是,具有不同背景的分析师必须进行比他们能够手动完成的更多的预测。我们预测系统的第一个组成部分是我们在Facebook上对各种数据进行多次迭代预测后开发的新模型。我们使用简单、模块化的回归模型,通常使用默认参数效果良好,并允许分析师选择与他们的预测问题相关的组件,并根据需要轻松进行调整。第二个组成部分是用于测量和跟踪预测准确性,并标记应该手动检查的预测的系统,以帮助分析师进行增量改进。这是一个关键的组成部分,它可以让分析师识别何时需要对模型进行调整,或者何时可能需要完全不同的模型。简单、可调整的模型和可扩展的性能监控结合起来,使大量分析师能够对大量和多样的时间序列进行预测,这就是我们所认为的规模化预测。
6、致谢
我们感谢Dan Merl让Prophet的开发成为可能,并在开发过程中提供建议和见解。我们还感谢Dirk Eddelbuettel、Daniel Kaplan、Rob Hyndman、Alex Gilgur和Lada Adamic对本文的有益审阅。我们特别感谢Rob Hyndman将我们的工作与主观预测联系起来的见解。
至此结束,主要是作者能把公式列出来就比较厉害。

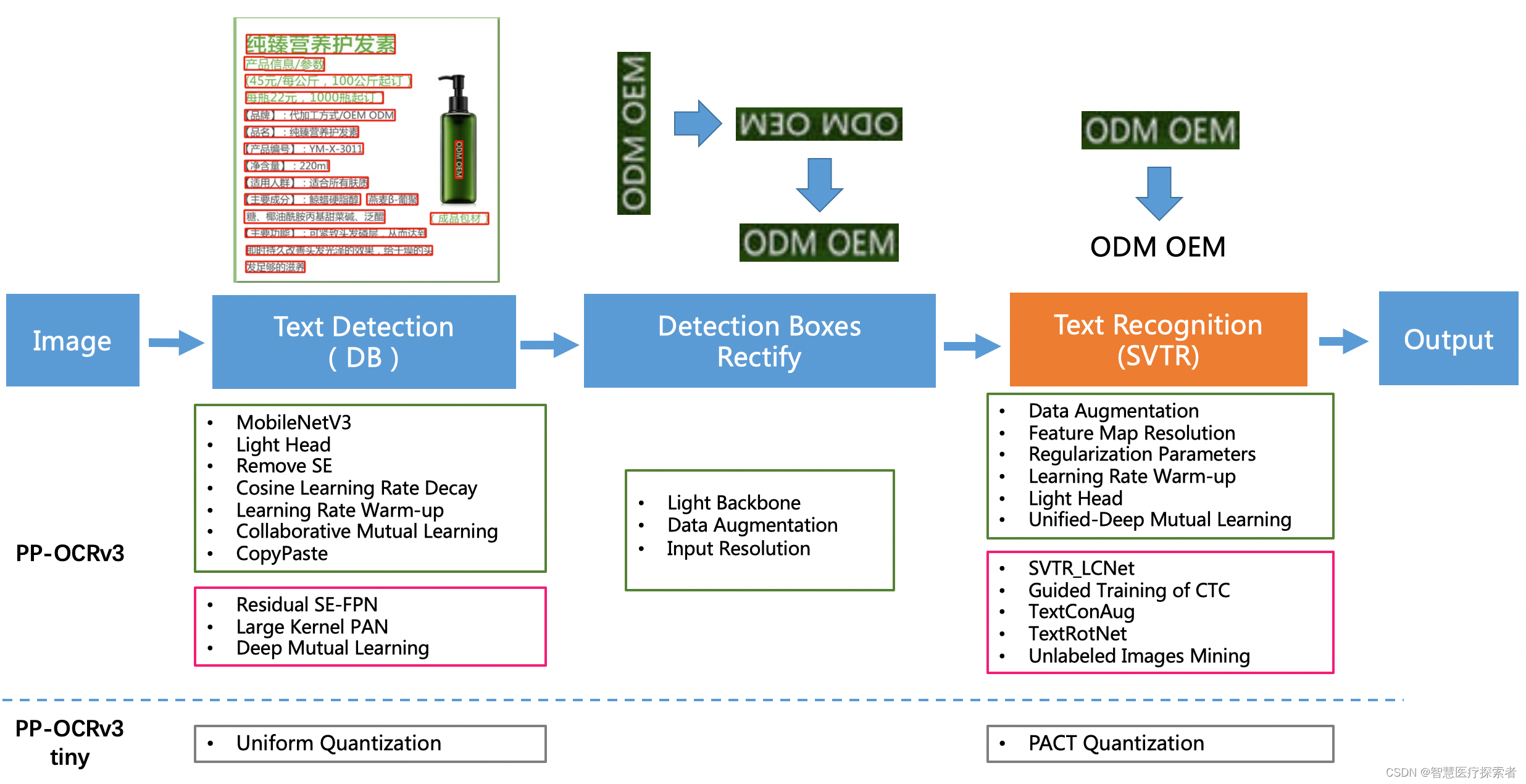




![[点云分割] 条件欧氏聚类分割](https://img-blog.csdnimg.cn/e9ca0fe1d5824918a7b508ee5621ccc4.png)