官方地址:openSMILE 3.0 - audEERING
使用指导:openSMILE — openSMILE Documentation (audeering.github.io)
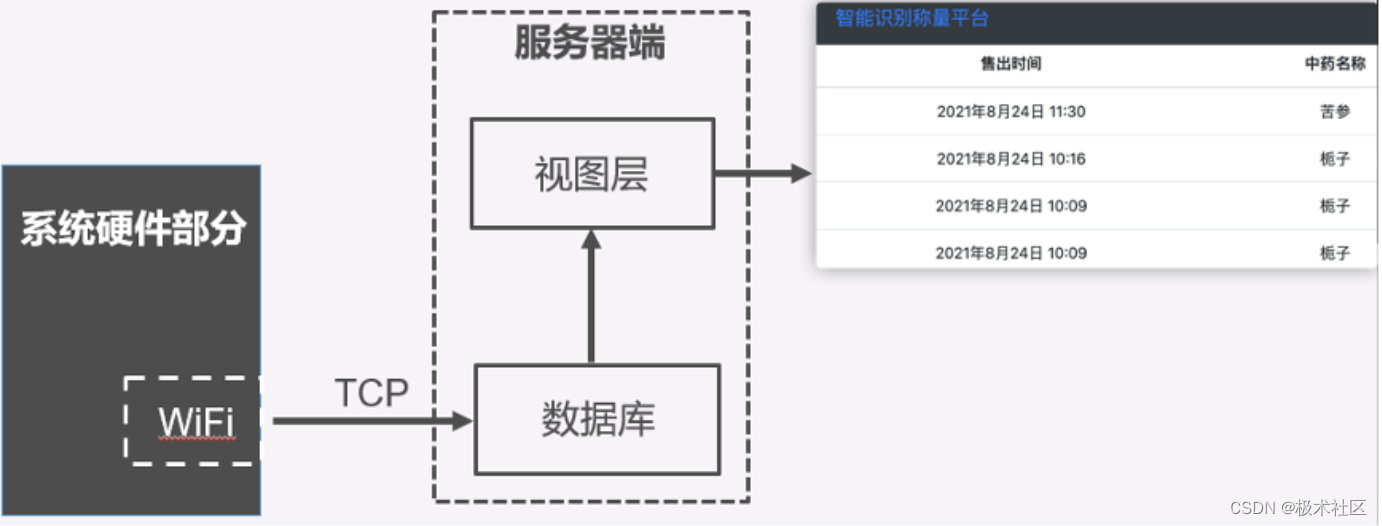
openSMILE 简介
openSMILE是一款以命令行形式运行的工具,通过配置config文件来提取音频特征。主要应用于语音识别、情感计算、音乐信息获取。2.0版本之后的openSMILE包括了openCV库,可以用于视频处理和视频特征提取。
官网有linux和windows版本提供下载,windows可以不编译直接用,建议在命令行里指明 openSMILE 绝对路径。
openSMILE的输入输出格式
文件输入格式
- RIFF-WAVE (PCM) (for MP3, MP4, OGG, etc. a converter needs to be used)
- Comma Separated Value (CSV)
- HTK parameter files
- WEKA’s ARFF format.(由htk工具产生)
- Video streams via openCV.(opencv产生的视频流数据)
文件输出格式
- RIFF-WAVE (PCM uncompressed audio)
- Comma Separated Value (CSV)
- HTK parameter file
- WEKA ARFF file
- LibSVM feature file format
- Binary float matrix format
分类器和其他组件
openSMILE还提供了许多VAD算法,用于判断各时间点有没有说话。
- Voice Activity Detection based on Fuzzy Logic
- Voice Activity Detection based on LSTM-RNN with pre-trained models
- Turn-/Speech-segment detector
- LibSVM (on-line)
- LSTM-RNN (Neural Network) classifier which can load RNNLIB and CURRENNT nets
- GMM (experimental implementation from eNTERFACE’12 project, to be release soon)
- SVM sink (for loading linear kernel WEKA SMO models)
- Speech Emotion recognition pre-trained models (openEAR)
0.openSMILE的安装
0.1.Ubuntu20.04安装openSMILE
其他系统安装
# 要求必须要有以下包git make gccg++ cmake perl5 gnuplot
#没有的话直接安装包名sudo apt-get install package-name
git clone https://github.com/audeering/opensmile.git
cd opensmile
bash build.sh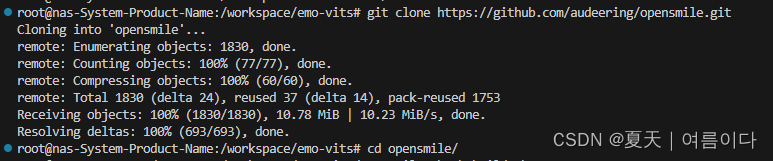
添加环境路径
#每个人的不同 ,查看路径pwd
#export PATH="自己的路径/opensmile/build/progsrc/smilextract:$PATH"
#我的
export PATH="/workspace/emo-vits/opensmile/build/progsrc/smilextract:$PATH"
# 更新
source /etc/profile
#查看版本
SMILExtract -h 
0.2.openSMILE在Windows上的安装
打开Release openSMILE 3.0 · audeering/opensmile · GitHub
拉到页面最下面
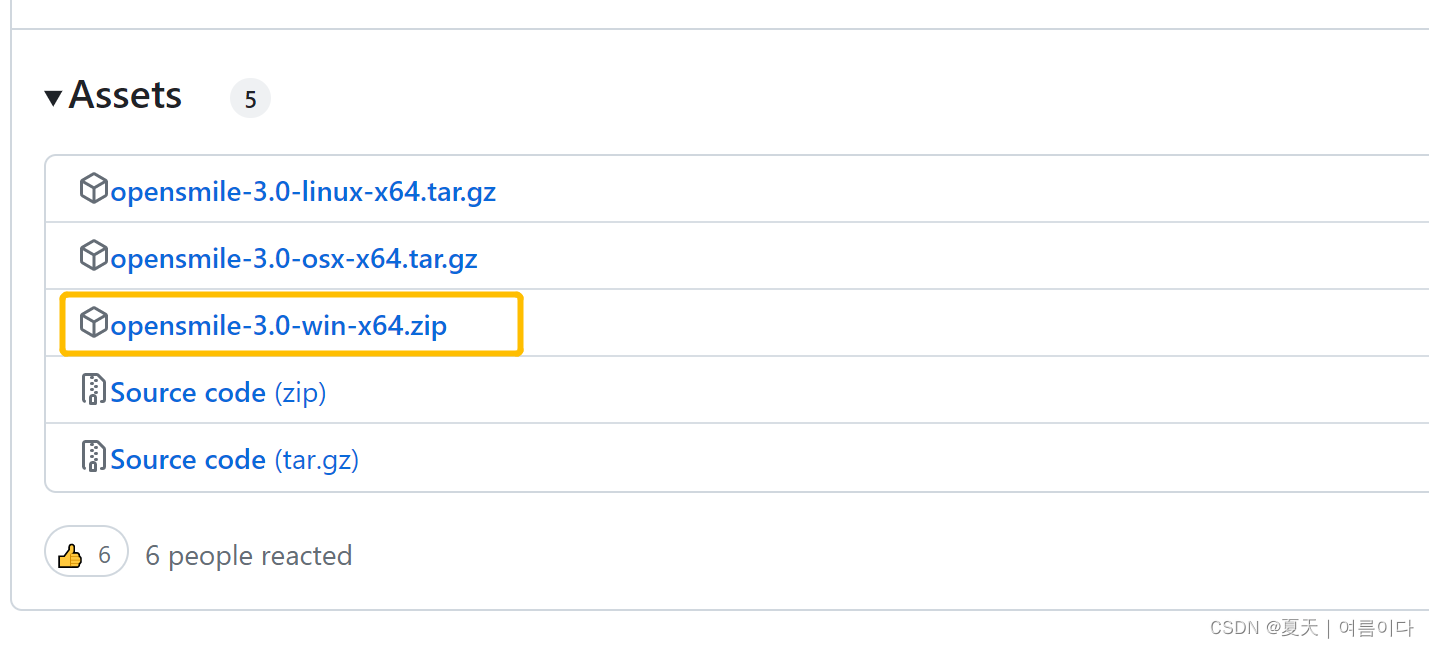
点击下载安装包后,进行解压然后配置
0.3. pip方式安装
GitHub - audeering/opensmile-python: Python package for openSMILE
pip install opensmile
相关库
pip install ffmpegpip方式安装简单,但是只提供几种特征设置
ComParE_2016 = 'compare/ComParE_2016'
GeMAPS = 'gemaps/v01a/GeMAPSv01a' # legacy
GeMAPSv01a = 'gemaps/v01a/GeMAPSv01a'
GeMAPSv01b = 'gemaps/v01b/GeMAPSv01b'
eGeMAPS = 'egemaps/v01a/eGeMAPSv01a' # legacy
eGeMAPSv01a = 'egemaps/v01a/eGeMAPSv01a'
eGeMAPSv01b = 'egemaps/v01b/eGeMAPSv01b'
eGeMAPSv02 = 'egemaps/v02/eGeMAPSv02'
emobase = 'emobase/emobase'1.openSMILE使用
在使用时,根据安装方法不同,使用时稍有不同,pip安装的都有import opensmile,如果git安装的,配置好环境后直接使用SMILExtract命令就可以,在bash或python文件中一样使用~
1.1.提取单个语音特征
pip 安装
import opensmile
smile = opensmile.Smile(
feature_set=opensmile.FeatureSet.ComParE_2016,
feature_level=opensmile.FeatureLevel.Functionals,
)
y = smile.process_file('')
print(y)结果

1行6373列,代表所使用的特征opensmile.FeatureSet.ComParE_2016包含了6373种特征,例如mfcc等
1.2.读取指定文件中所有的语音文件
Windows处理时需要添加路径
依次处理,将生成的特征文件保存到另一个指定文件中,
import os
audio_path = 'C:/Users/Administrator/Desktop/download/wav' # 音频文件所在目录
output_path='C:/Users/Administrator/Desktop/download/rebuild' # 特征文件输出目录
audio_list=os.listdir(audio_path) # 生成所有音频文件文件名的列表
features_list=[]
for audio in audio_list: # 遍历指定文件夹下的所有文件
if audio[-4:]=='.wav':
this_path_input=os.path.join(audio_path, audio) # 打开一个具体的文件,audio_path+audio
this_path_output=os.path.join(output_path,audio[:-4]+'.txt')
# &&连续执行;C: 进入C盘内;进入opensmile中要执行的文件的目录下;执行文件 -C 配置文件 -I 语音文件 -O 输出到指定文件
cmd = 'C: && cd C:/Program/opensmile-2.3.0/bin/Win32 && SMILExtract_Release -C C:/Program/opensmile-2.3.0/config/IS09_emotion.conf -I ' + this_path_input + ' -O ' + this_path_output
os.system(cmd)
print('over~')
1.3.批量处理生成特征的文本文件
提取组合出可以用来学习处理的矩阵文件。代码如下
import os
import pandas as pd
txt_path = 'C:/Users/Administrator/Desktop/download/rebuild' # 特征文本文件所在目录
txt_list = os.listdir(txt_path)
features_list = []
for file in txt_list: # 遍历指定文件夹下的所有文件
if file[-4:] == '.txt':
file_path = os.path.join(txt_path, file)
# 打开输出文件
f = open(file_path)
# 最后一行是特征向量,取最后一行
last_line = f.readlines()[-1]
f.close()
features = last_line.split(',')
# 最后一行特征行的第一个元素为‘unknown’,最后一个为‘?’,都不是对应的特征,要去掉
features = features[1:-1]
features_list.append(features)
data_m = pd.DataFrame(features_list)
data_m.to_csv(os.path.join('C:/Users/Administrator/Desktop/download', 'test_data.csv'), sep = ',', header=False, index=False)
print('over')
1.4.Linux中提取单个语音特征的bash命令
SMILExtract -C thisconfig.conf -I input.wav -O output.arff
#SMILExtract -C config/emobase/emobase2010.conf -I /workspace/emo-vits/dataset/p225v0.1/p225_001_mic1.wav -O output.arff - thisconfig.conf :指定的配置文件,也就是所需要的特征
- input.wav :输入的语音文件
- output .arff : 输出文件
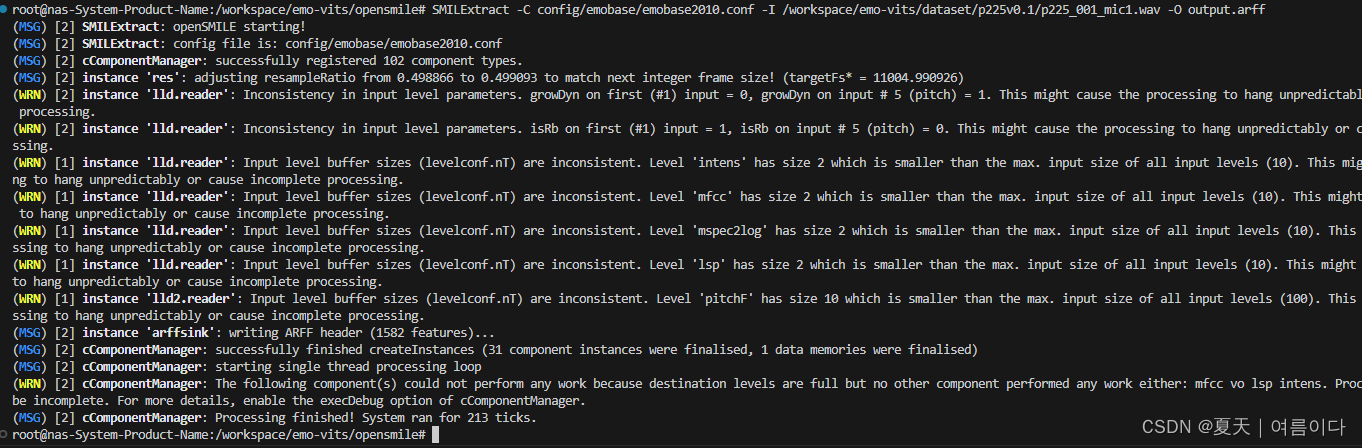
输出arff文件如图
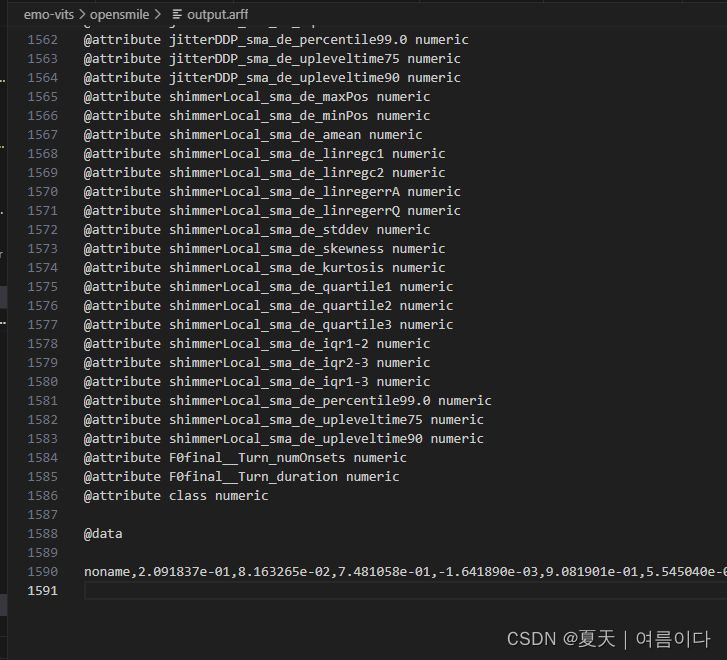
在训练时,主要使用最后一行向量特征。
1.5.Linux中批量提取语音数据集特征的python文件
import os
audio_path = '/workspace/emo-vits/dataset/p225v0.1' # .wav file path
output_path='/workspace/emo-vits/dataset/p225emo' # feature file path
audio_list=os.listdir(audio_path)
features_list=[]
for audio in audio_list: # 遍历指定文件夹下的所有文件
if audio[-4:]=='.wav':
this_path_input=os.path.join(audio_path, audio) # 打开一个具体的文件,audio_path+audio
this_path_output=os.path.join(output_path,audio[:-4]+'.csv') # .txt/.csv
# 进入opensmile中要执行的文件的目录下;执行文件 -C 配置文件 -I 语音文件 -O 输出到指定文件
os.system( 'SMILExtract -C /workspace/tts/opensmile/config/emobase/emobase2010.conf -I ' + this_path_input + ' -O ' + this_path_output)
print('over~')
就会在指定文件夹生成音频对应的csv文件,
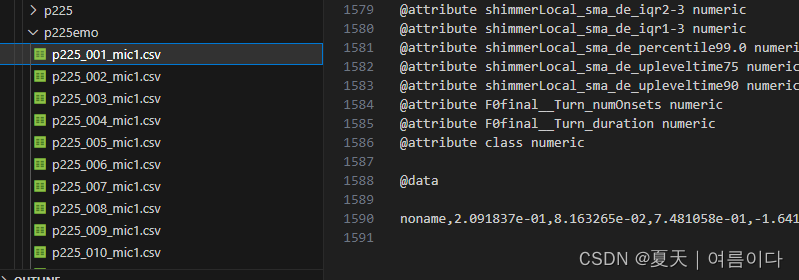
提取文件后,对csv文件进行处理,提取数据特征向量部分
批量处理生成特征的文本文件,提取组合出可以用来学习处理的矩阵文件。
文件分俩步骤运行,一个是批量提取数据集语音的情感特征,第二步骤是将语音特征保存为一个npy文件,以便于数据的读取及使用。
# 步骤一 :
import os
audio_path = '/workspace/emo-vits/dataset/p225v0.1' # .wav file path
output_path='/workspace/emo-vits/dataset/p225emo' # feature file path
audio_list=os.listdir(audio_path)
features_list=[]
for audio in audio_list: # 遍历指定文件夹下的所有文件
if audio[-4:]=='.wav':
this_path_input=os.path.join(audio_path, audio) # 打开一个具体的文件,audio_path+audio
this_path_output=os.path.join(output_path,audio[:-4]+'.csv') # .txt/.csv
# 进入opensmile中要执行的文件的目录下;执行文件 -C 配置文件 -I 语音文件 -O 输出到指定文件
os.system( 'SMILExtract -C /workspace/tts/opensmile/config/emobase/emobase2010.conf -I ' + this_path_input + ' -O ' + this_path_output)
print('over 1 ~')
# 步骤二 :
# 读取csv文件
import os
import numpy as np
txt_path='/workspace/emo-vits/dataset/p225emo'
txt_list=os.listdir(txt_path)
features_list=[]
for txt in txt_list:
if txt[-4:]=='.csv':
this_path=os.path.join(txt_path,txt)
f=open(this_path)
last_line=f.readlines()[-1]
print("last_line:",last_line)
f.close()
features=last_line.split(',')
features=features[1:-1]
features_list.append(features)
features_array=np.array(features_list)
np.save('p225_opensmile_features.npy',features_array)
print('over 2 ~')
更多语音处理工具请参考
Speech | 提取语音(数据集)的语音特征合集_夏天|여름이다的博客-CSDN博客
参考文献
【1】【音频特征】opensmile 工具的使用和批处理_weiquan fan的博客-CSDN博客
【2】openSMILE简介及使用 - 知乎






![[汇编实操]DOSBox工具: unable to open input file: 文件名.asm问题解决](https://img-blog.csdnimg.cn/a458a99559ba45658d6594d20539826a.png)