文章目录
- 并行与分布式 第7章 体系结构 下
- 7.3 互连结构
- 7.3.1 网络拓扑的基本概念
- 7.3.2 互连网络分类
- 7.3.3 典型静态网络
- 7.3.4典型动态互连网络
- 7.4 性能评测
- 7.4.1 工作负载
- 7.4.2 峰值速度
- 7.4.3 并行执行时间
- 7.4.4 性能价格比
- 7.4.5多处理器性能定律
并行与分布式 第7章 体系结构 下
7.3 互连结构
7.3.1 网络拓扑的基本概念
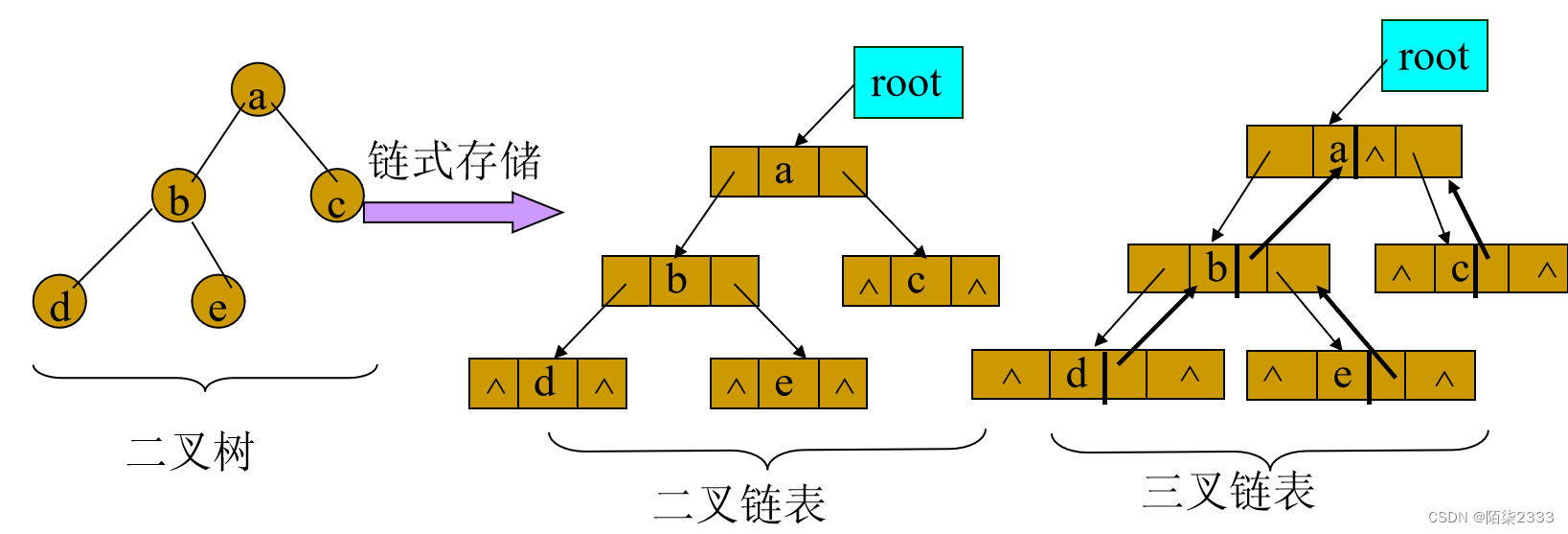
互连结构是由开关元件按照一定拓扑结构连接并按照一定控制方式工作而形成的结构,用以实现计算机系统内多个功能部件间的相互连接。
三要素
• 互连拓扑:描述连接通路的拓扑结构
• 开关元件:描述连接通路的开关状态
• 控制方式:描述连接通路的操作规则
分类
• 静态互连(一维,环网,带弦环,树形,网格型,超立方)
• 动态互连(总线,交叉开关,多级互连)
协议
• PCIE,InfiniBand,以太网协议,FDDI光纤网络
• 网络规模(Size)网络中节点的个数
• 链路数(Link)网络中所有节点间链路的个数;
• 链路冗余度(Link Redundancy)网络中连接两个特定节点的所有链路个数;
• 节点度(Node Degree)射入或射出每个节点的边数称为该节点的度,度=射入边数+射出边数;
• 直径(Diameter)网络中任何两个节点之间的最长距离,及最大路径长度;
• 对剖宽度(Bisection Width)对分网络各半所必须移去的最少边数;
• 对称性(Symmetric)从任一节点视角看整个网络是否都保持一 致;
7.3.2 互连网络分类
• 根据互连网络中连接通路是否能够被共享,可以分为静态互连网络和动态互连网络。
• 静态互连网络,网络节点固定地与开关单元相连,以建立节点与节点之间的被动连接通路。
• 动态互连网络,网络节点只与位于互连网络边界上的开关单元相连,开关单元之间可以按照应用需求动态的改变连接组态,以建立节点与节点之间的主动可控连接通路
静态互连网络的设计要求
• 网络中每个节点的度要小,最好各个节点的度都相等
且与网络规模无关;
• 网络直径要小,随节点数目增多而缓慢增加;
• 尽量对称,信息流量分布较为均匀;
• 对节点合理编址,能实现高效路径算法;
• 有较高路径冗余度,满足鲁棒性要求;
• 扩展代价低,且扩展后仍能保持原有互连拓扑特性
7.3.3 典型静态网络
一维线性阵列
• N个节点排列成1xN一维阵列,每个节点只与左右近邻
节点相连,故也称为二近邻连接
• 节点度为2,网络直径为N-1,对剖度为1
一维环形阵列
• 用一条附加链路将线性阵列的两个端点连接起来而构成的
• 首尾连接时构成环,环可以为单向或双向,其节点度为2,对剖宽度为2,
• 单向环直径为N,双向环直径为N/2;
带弦环
增加的链路愈多,结点度愈高,网络直径就愈小。
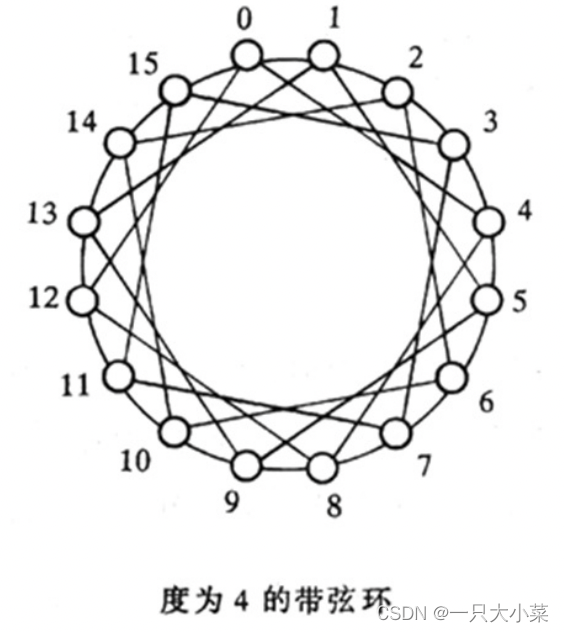
全连接带弦环
• 结点度: N-1
• 直径最短,为1
循环移数网络
• 通过在环上每个结点到所有与其距离为2的整数幂的结点之间都增加一条附加链而构成的。
• 网络规模N=2^n
• 如果|j-i|=2^r,r=0,1,2,…,n-1,则结点i与结点j连接。
• 结点度为d=2n-1,直径D=n/2。
树形连接
• 星形连接,N个节点的网络,如果尽量增大一个节点度使其变为N-1,则形成星形连接,此时网络直径为2;
• 二叉树连接,N个节点的网络,除了根节点和叶节点外,每个内节点只与其父节点和两个子节点相连,故也称为三近邻连接;此时,节点的度为3,对剖宽度为1,直径为2logN;
• 二叉胖树(Fat Tree),为解决二叉树连接中根节点的瓶颈效应,增加根节点附近的链路冗余度,距离根节点越近,链路冗余度越大。
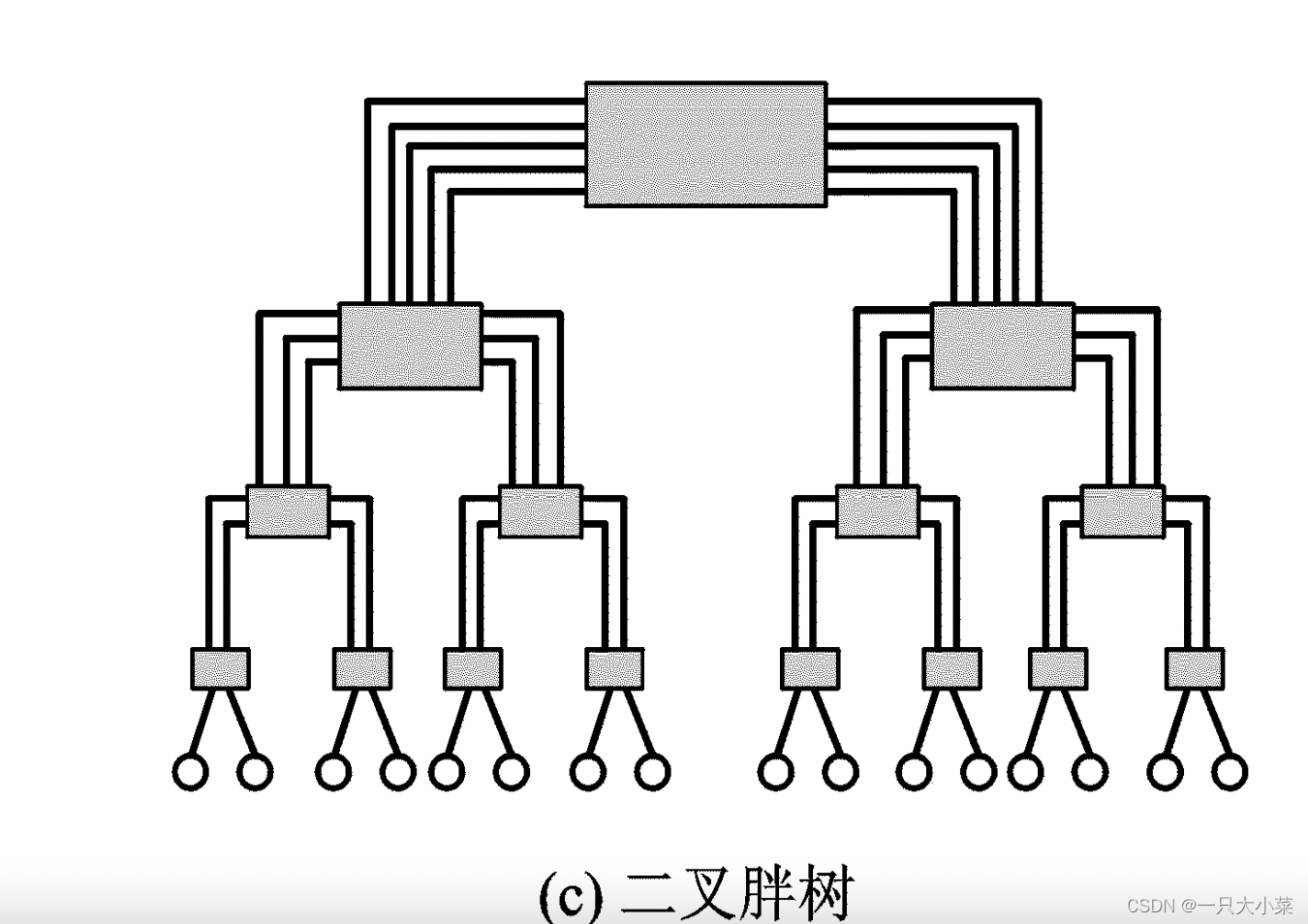
多维网格
• N=n^k 个结点的k维网格
• 网络直径为k(n-1)
• 内部结点度为2k , • 边结点和角结点的结点度分别为3或2。
多维环形网格
• N=n^k 个结点的k维环形网格
• 内部结点度为2k ,
• 边结点和角结点的结点度分别为3或2
Illiac网孔
• kxk的二维网格,如果在垂直方向上采用带状环形连接,水平方向上采用跨行蛇形连接,称为Illiac网格
• 节点度为4
• 网络直径为(k-1),
• 对剖宽度为2k;
Torus网孔
• kxk的二维网格,如果在垂直方向上采用带状环形连接,水平方向上也采用带状环形连接,称为Torus网格
• 节点度为4,
• 网络直径为k,
• 对剖宽度为2k;
超立方体(CUBE)
• 一个2元n立方体结构,由N=2^n 个结点组成,它们分布在n维上,每维有2个节点,每个节点都是立方的顶点;
• 一个2元n立方的节点度为n,网络直径为n,对剖宽度为2^(n-1);
超立方环
• 如果将3-立方的每个顶点代之以一个环,则构成了3-立方环;
• 超立方体和超立方环缺乏可扩放性和应用价值,但是由于其拓扑数学特性,具备学术价值。
7.3.4典型动态互连网络
总线(Bus)是连接计算机系统各个部件的一组导线和插座,用于主设备和从设备之间的数据传输,公共总线以分时工作为基础,因此每条总线要配一个总线控制器才能使用。
总线设计要考虑的问题包含:
总线仲裁、中断处理、协议转换、路障同步、缓存一致性、总线桥接、层次扩展等
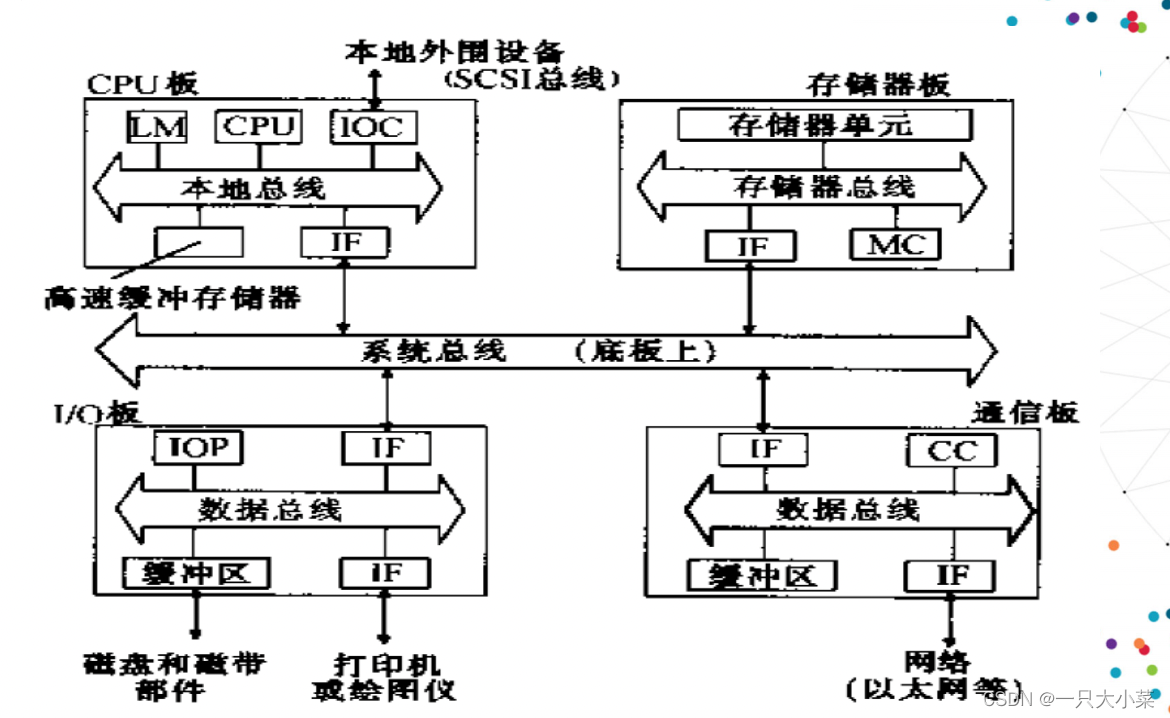
总线层次
• 局部总线,印刷电路板上实现的总线
• 处理器总线,CPU板级上的总线
• 存储器总线,存储器板级上的总线
• 数据总线,I/O板级和通信板级的总线
• 系统总线,底板上(主板上)为所有插入板间通信提供的通路
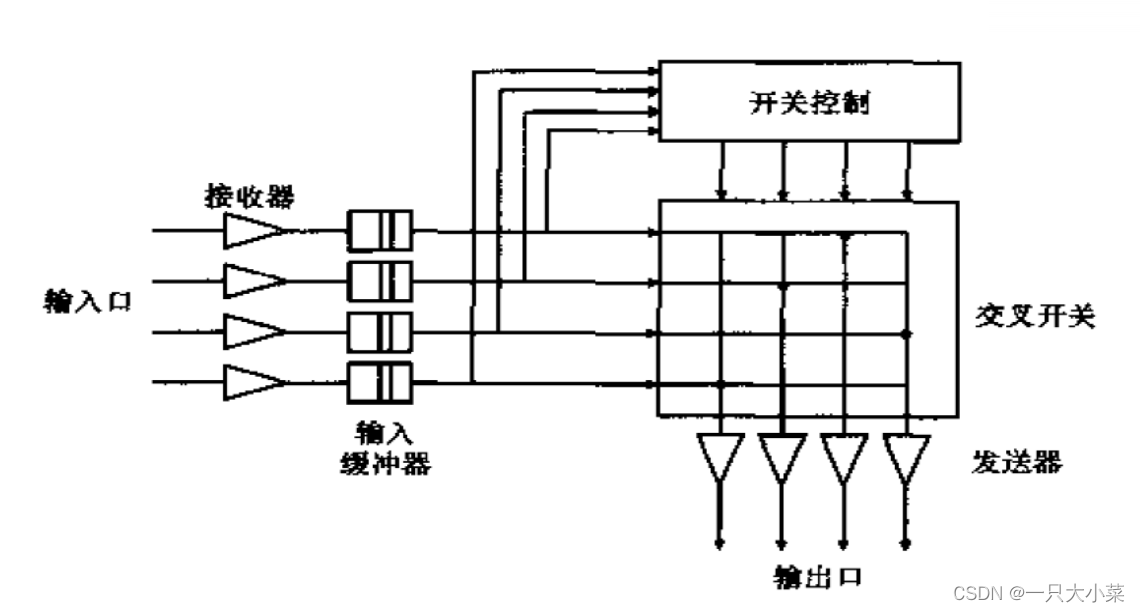
交叉开关
交叉开关(CrossBar Switcher),通过一个单级交叉开关阵列实现的交互网络,每个开关上的状态可由程序动态的控制,可在源目对之间动态提供一条专用连接通路。
• 当端口数为N时,其开关量(复杂度)为N^2
• 在并行处理中,交叉开关的使用通常有两种方式:用于实现处理器间的1v1通信,用于实现处理器和多体交叉存储体间的1vN通信
多级互连网络
多级互连网络(Multistage Interconnection Network,MIN)为了构筑大型开关网络,不能无限制增大单个交叉开关,而是可以将多级交叉开关级联起来,构成交叉开关网络来实现输入到输出之间的动态切换。
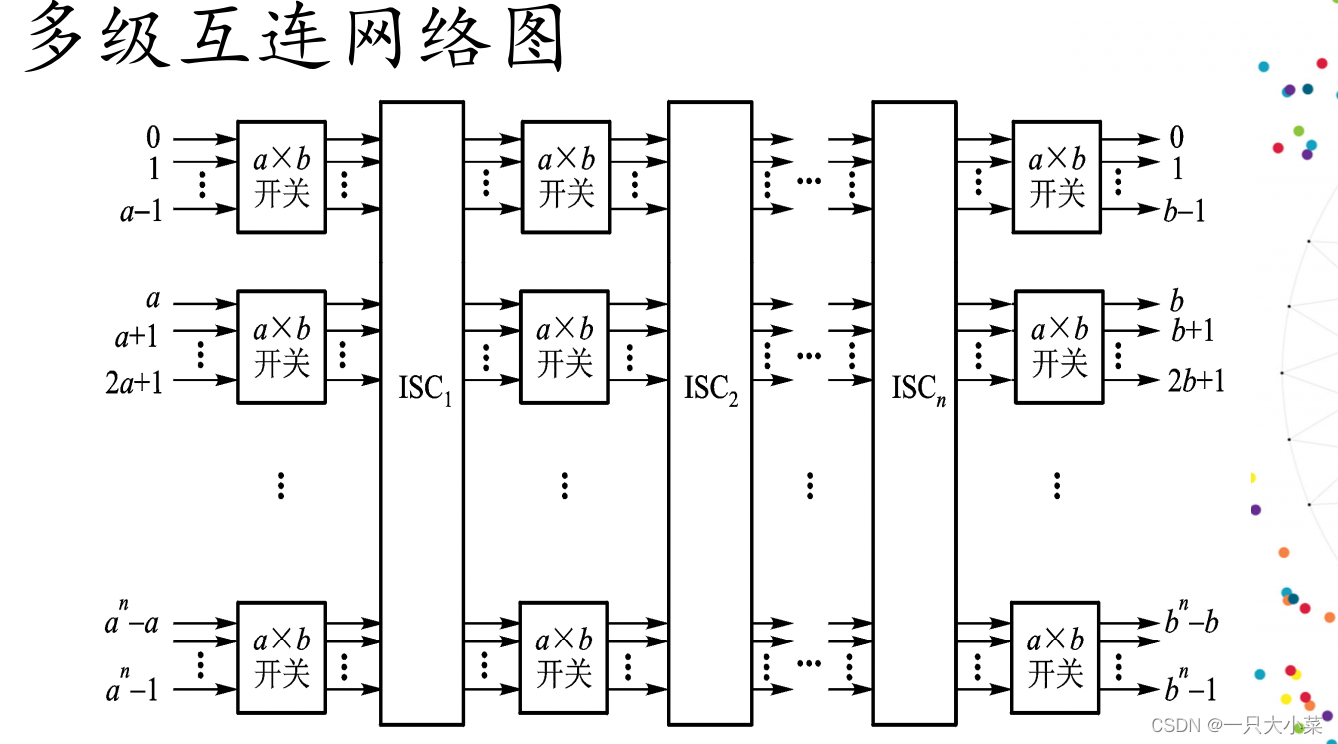
互连规模
• 总线/交叉开关,实现节点内部印刷电路板上的元件间的连接, 距离最短,带宽最高,如SCSI协议;
• SAN,System Area Network,系统网,将短距离(3-25m内的 节点连接起来形成紧密耦合单一系统,带宽较高InfiniBand;
• LAN,Local Area Network,局域网,在一个建筑物内或一个单位的地理区域内的节点连接起来形成松散耦合多机系统,网距25-500m,如千兆以太网;
• MAN,Metropolitan Area Network,城域网,覆盖整个城市的计算机网络,网距<=25km,如FDDI光纤网络;
• WAN,Wide Area Network,广域网,实现城市-城市间互联的国家级网络,通常是逻辑链路而非物理链路,如中国教育网。
互连协议
PCI总线标准协议、InfiniBand、以太网、FDDI光纤网络、VPN、SDN
7.4 性能评测
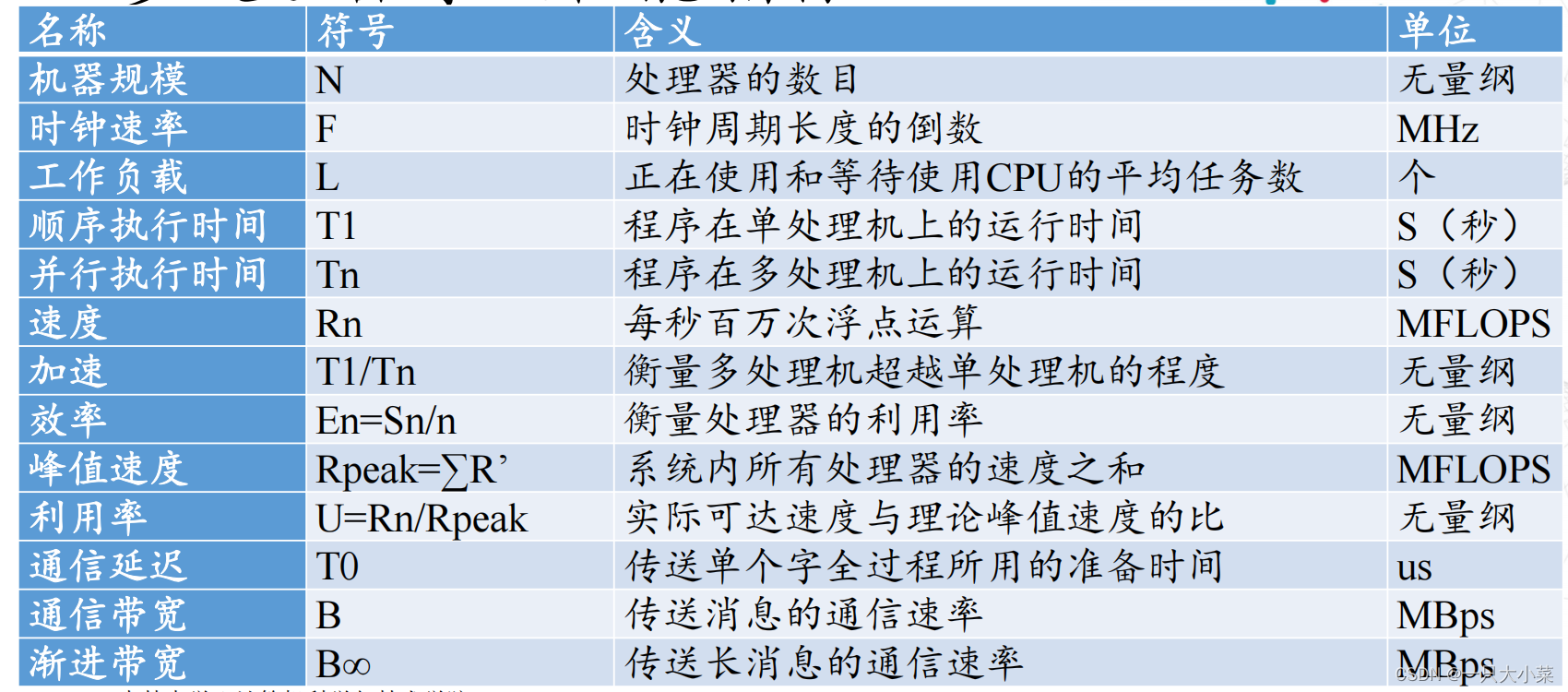
7.4.1 工作负载
工作负载:一段时间内正在使用和等待使用CPU的平均任务数。CPU使用率高,并不意味着负载就一定大。举例:
• 有一个程序需要一直使用CPU的运算功能,那么此时CPU的使用率可能达到100%,但是CPU的工作负载则是趋近于"1",因为CPU仅负责一个工作。
• 如果同时执行这样的程序两个呢?CPU的使用率还是100%,但是工作负载则变成2了。
• 当CPU的工作负载越大,代表CPU必须要在不同的工作之间进行频繁的上下文切换
7.4.2 峰值速度
• 衡量计算机系统性能的一个重要指标就是计算峰值或者浮点计算峰值,它是指计算机每秒钟能完成的浮点计算最大次数。包括理论浮点峰值和实测浮点峰值。理论浮点峰值是该计算机理论上能达到的每秒钟能完成浮点计算最大次数,它主要是由CPU的主频决定的。
• 理论浮点峰值=CPU主频×CPU每个时钟周期执行浮点运算的次数×系统中CPU数
• CPU每个时钟周期执行浮点运算的次数是由处理器中浮点运算单元的个数及每个浮点运算单元在每个时钟周期能处理几条浮点运算来决定的。
7.4.3 并行执行时间
• T n = Tcomput + Tparo+ Tcomm
- Tcomput :计算时间,
- Tparo 并行开销
• 进程管理时间:进程生成、进程结束、进程切换
• 组操作时间:进程组生成、进程组消亡
• 进程查询时间:查询进程标识和等级、查询进程组的标识和大小 - Tcomm通信时间,
• 同步时间:路障与事件、锁与临界区
• 通信时间:点到点消息传递、共享变量读写
• 聚合操作时间:规约操作、前缀运算
存储器性能
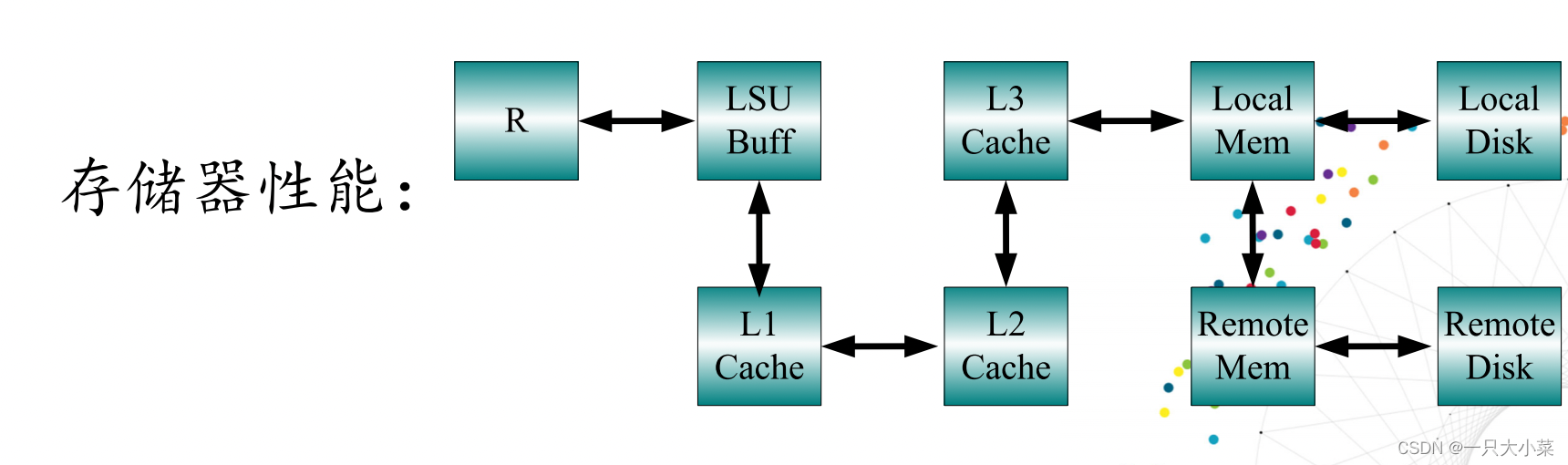
层次化存储结构,每一层都有三个参数表征
• 容量C:存储字节总量,B(字节)
• 延迟D:读取一个字所需的全部时间,s(秒)
• 带宽B:不同层次的存储器件间传输数据的速度,Bps(Bytes Per Second)
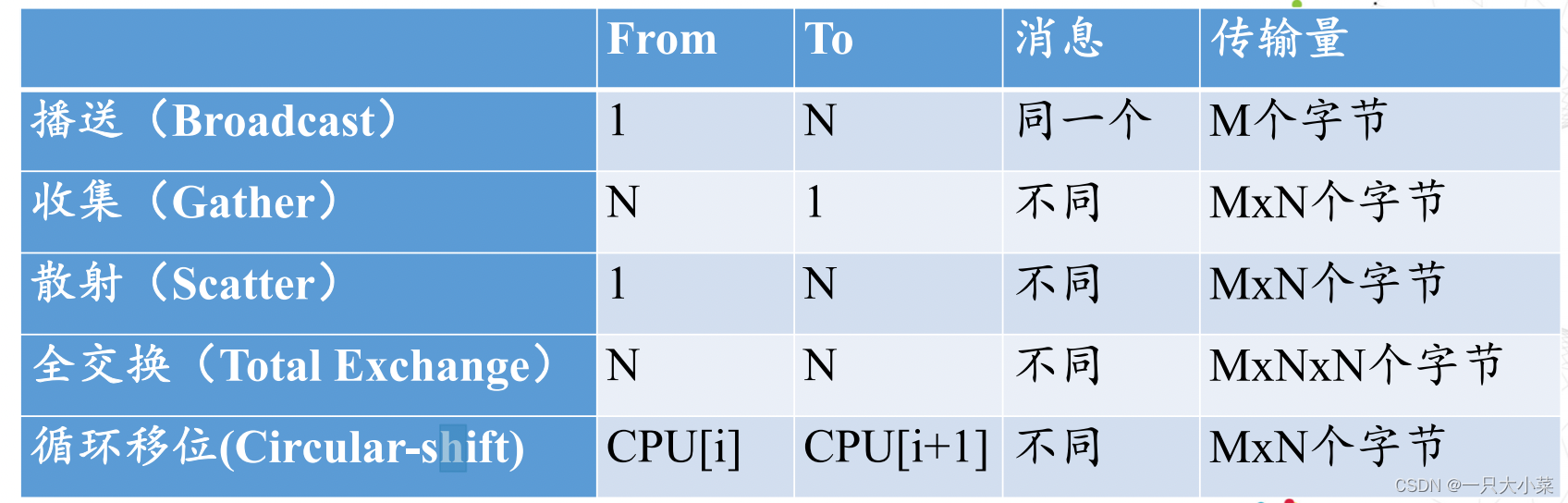
通信开销:测量法(ping-pong scheme)
• K个节点,用M[KxK]={Mij,i=1…K,j=1.

通信开销(2)解析法
- 发送一个长度为m个Byte的通信开销T(m)=T0+m/ R∞
• R∞为渐近带宽,单位MBps. - T0为通信延迟,又称为启动时间,T0时间内都是在打通数据通路,第一个Byte还没有到达,T0时间后每隔周期时间有一个Byte到达。
通信开销(3)整体通信开销的测量
7.4.4 性能价格比
• 价格=原料成本+直接成本+毛利+折扣
• 机器的性能价格比(Performance/Cost Ratio):系指用单位代价(通
常以百万美元表示)所获取的性能(通常以MIPS或MFLOPS表示)
• 高性能价格比意味着成本是有效的,成本的有效性可用利用率来衡
量。机器的利用率(Utilization):可达到的速度与峰值速度之比。
• 性价比决定技术选型:超算 v.s. 工作站集群
7.4.5多处理器性能定律
多处理器系统的加速比:对于一个给定的应用,并行算法(或并行程序)的执行速度相对于串行算法(或串行程序)的执行速度加快了多少倍。
不同条件下使用不同的加速比定律
• Amdahl定律:当计算负载固定时适用
• Gustafson定律(1988):当问题具备可扩放性时适用
• Sun&Ni定律:当存储器受限时适用
参数的约定
• P并行系统中处理器数;
• W问题规模,计算负载总量;
• Ws应用程序中的可串行分量;
• Wp应用程序中的可并行分量;
• f可串行分量的比例;1-f可并行分量的比例;
• Ts串行执行时间;Tp并行执行时间;
• S加速比,E效率
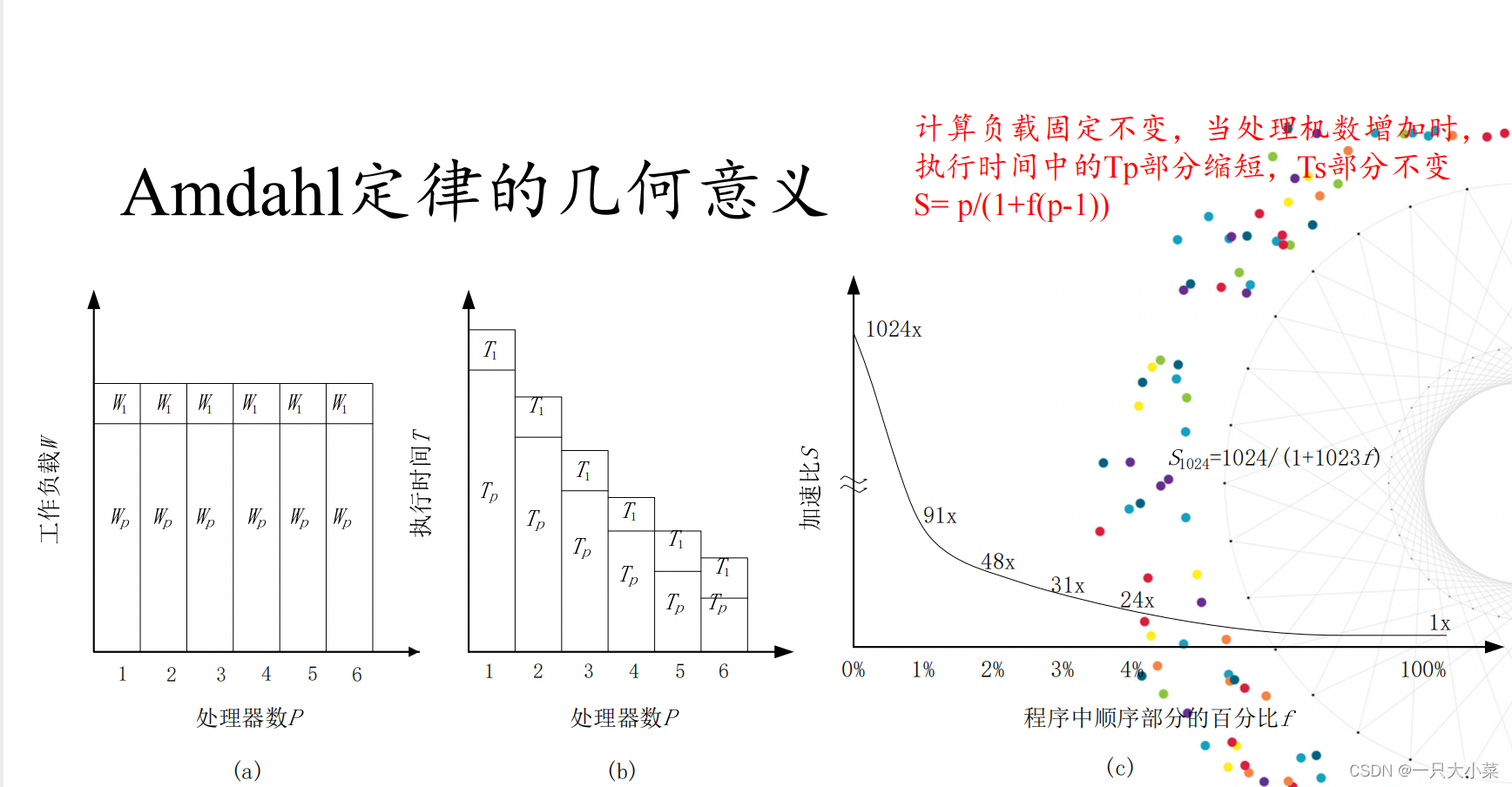
Amdahl定律
• 出发点:在实时性要求很高的应用类型中,计算负载固定不变,将这些计算负载分布在多个处理器上,增加处理器可以加快执行速度。
• 阿姆达尔定律侧重于减少给定的固定大小问题的时间。 阿姆达尔定律指出,问题(算法)的顺序部分限制了随着系统资源的增加可以实现的总加速。
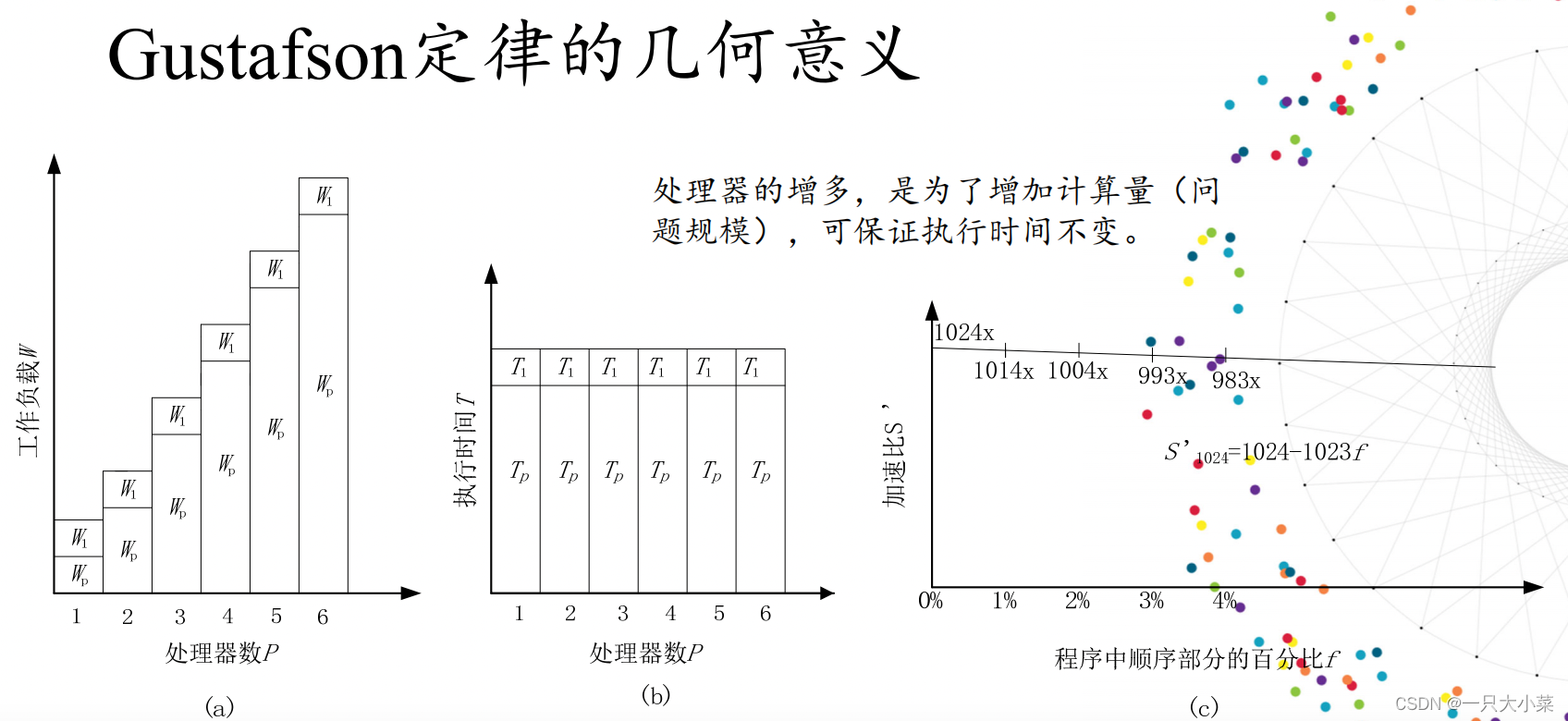
Gustafson定律
•出发点:在对精度要求很高的应用类型中,为了提高精度必须加大计算量,相应的须增多处理器的个数才能维持计算时间不变。
•对于这类应用,通常是先在小规模计算资源上运行粗粒度处理作为调试测试,然后在大规模计算资源上运行细粒度作为正式运行。
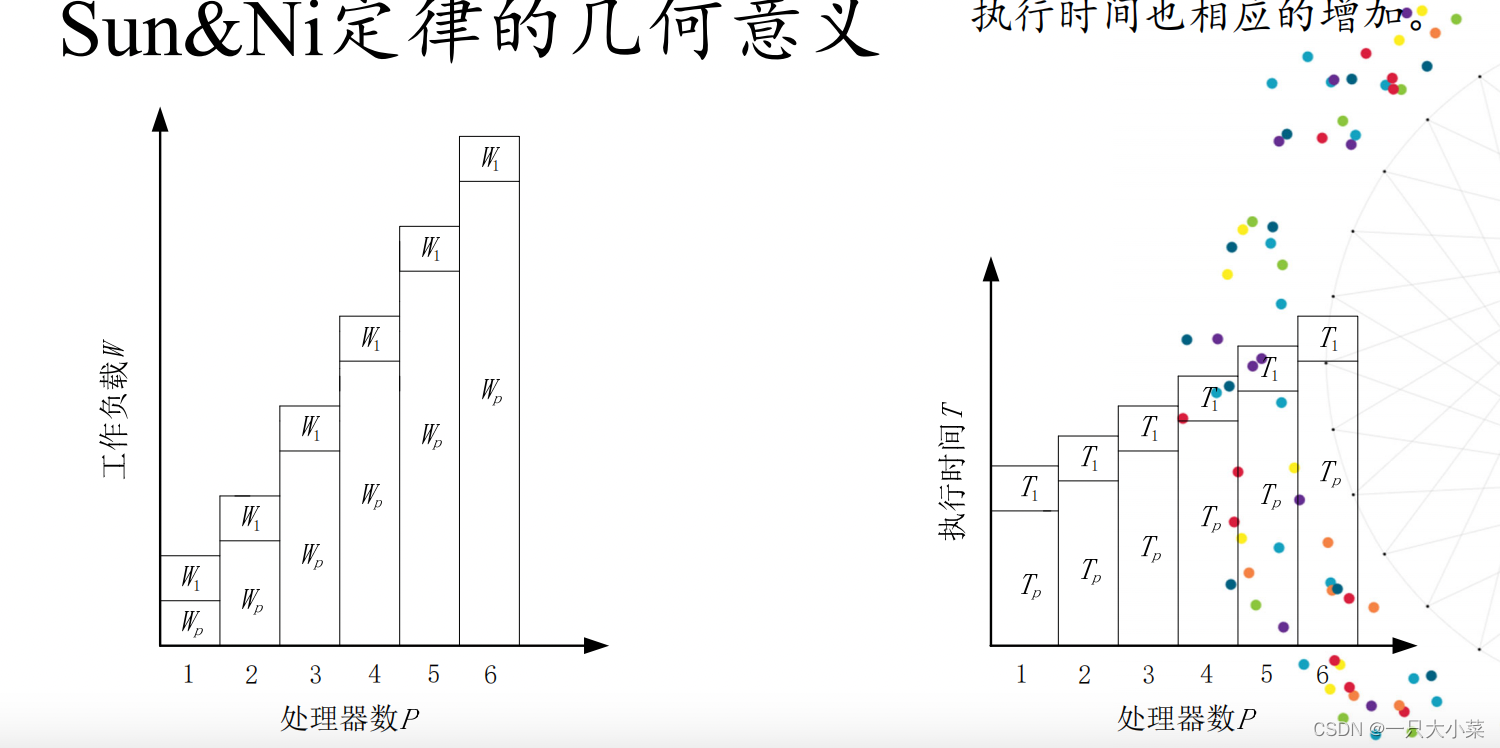
Sun&Ni定律
出发点:Amdahl定律和Gustafson定律各代表两种极端情况, 为了将两者统一实现一般化(generalization),Xian-He Sun (孙贤和,美国伊利诺伊理工学院计算机科学系教授)和Lionel Ni(倪明选)于1993年提出了Sun&Ni定律。
• Amdahl定律和Gustafson定律都没有对处理器个数和存储容量做任何限制,而实际上在多个节点组成的并行系统中, 可求解问题的规模是受到存储容量限制的。
• 基本思想是,只要存储空间许可,应尽量增大问题规模以 产生更好和更精确的解(此时可能使得执行时间略有增 加),目标是更大的加速比、更高的求解精度、更好的资 源利用率
参数的约定
• P个节点的并行系统,每个节点的存储容量为M,则全部存储容量为pM。
• 问题规模从一个节点扩大到p个节点,对存储的需求增加p倍,并行工作负载计算量增大G§倍,则扩大前W=fW+(1-f)W,扩大后W=fW+(1-f)WG§