文章目录
- 将开发环境和生产环境区分开
- 环境变量
- vite处理环境变量
- loadEnv
- 业务代码需要使用环境变量
- `.env`
- `.env.development`
- `.env.test`
- 修改`VITE_`前缀

将开发环境和生产环境区分开
分别创建三个vite 的配置文件,并将它们引入vite.config.js
vite.base.config.js
import { defineConfig } from "vite"
export default defineConfig ({})
vite.dev.config.js
import { defineConfig } from "vite"
export default defineConfig ({})
vite.prd.config.js
import { defineConfig } from "vite"
export default defineConfig ({})
引入vite.config.js
import { defineConfig } from "vite";
import viteBaseConfig from "./vite.base.config";
import viteDevConfig from "./vite.dev.config";
import vitePrdConfig from "./vite.prd.config";
const EnvMap = {
build: () => {
return Object.assign({}, viteBaseConfig, vitePrdConfig);
},
serve: () => {
return Object.assign({}, viteBaseConfig, viteDevConfig);
},
};
export default defineConfig(({ command }) => {
console.log("command:", command);
return EnvMap[command]();
});
在package.json中配置vite的开发命令和打包命令
{
"name": "vite",
"version": "1.0.0",
"main": "index.js",
"license": "MIT",
"scripts": {
"dev": "vite",
"build": "vite build"
},
"dependencies": {
"lodash": "^4.17.21",
},
"devDependencies": {
"vite": "^5.0.0"
}
}
分别执行一下以下两行命令
yarn dev
yarn build
可以看到,确实能够根据command这个变量,来区分开发还是生产。
环境变量
会根据当前当前代码所在环境而发生变化的变量。
代码环境通常包括
开发环境、测试环境、预发布环境、灰度环境、生产环境
比如百度地图的sdk,某些第三方请求特定的密钥或者token,以及小程序的APP_KEY,不同环境请求的后端接口地址也有可能不同。
以上这些举例的变量,都会因为开发周期的变化,用不同的变量值,这个时候,如果这些变量能够根据环境的变化自动变化,就比较完美,减少人工干预,才可能不出错。
vite处理环境变量
vite内置第三方库dotenv来处理环境变量的获取和注入。
dotenv会自动读取.env文件,并解析这个文件的环境变量,并将其挂到process对象(nodejs的process)上。
创建.env文件,vite默认在.env创建全局环境变量,
NAME = "dengxi"
POSITION = "CEO"
更改vite.config.js配置,这里引入了vite自带的方法loadEnv
import { defineConfig, loadEnv } from "vite";
import viteBaseConfig from "./vite.base.config";
import viteDevConfig from "./vite.dev.config";
import vitePrdConfig from "./vite.prd.config";
const EnvMap = {
build: () => {
return Object.assign({}, viteBaseConfig, vitePrdConfig);
},
serve: () => {
return Object.assign({}, viteBaseConfig, viteDevConfig);
},
};
export default defineConfig(({ command, mode }) => {
console.log("command:", command);
console.log("mode:", mode)
const env = loadEnv(mode, process.cwd(),"");
console.log("env:", env.NAME)
return EnvMap[command]();
});
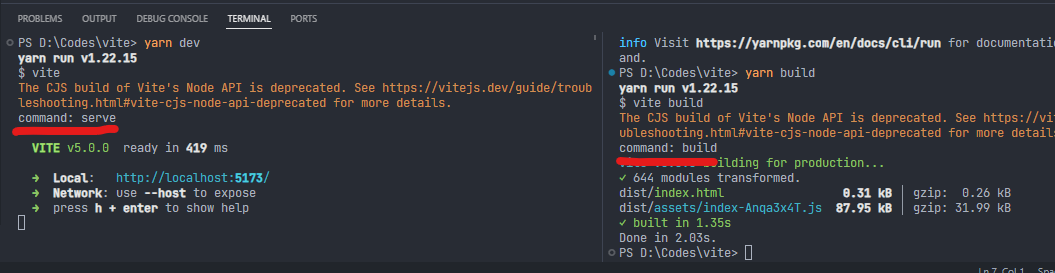
无论是通过vite创建服务器,还是通过vite打包,我们都能获取到。
yarn dev
yarn build
左侧是vite启动开发服务器,右侧是vite打包到生茶环境,它们都能获取到.env配置的环境变量

loadEnv
这个方法非常重要,通过它我们可以自由配置环境变量的存储文件,vite虽然提供了默认的.env,但这显然是不够用的,实际项目中,可能会有很多环境,需要将不同的环境变量放到不同的文件中。
loadEnv接收三个参数,第一个参数来自我们的启动命令,如果是vite自带的启动服务命令yarn vite 本文中配置的是yarn dev, mode === 'development' // true ,如果vite自带的打包命令 yarn vite build,本文中配置的是yarn build, mode === 'production' // true
左边是启动服务器,右边是打包
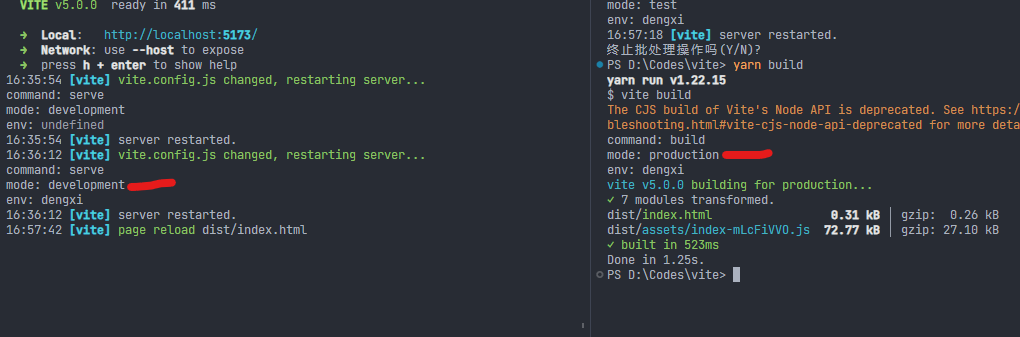
如果你想自由配置这个mode的值怎么办呢?
yarn vite --mode 'test'
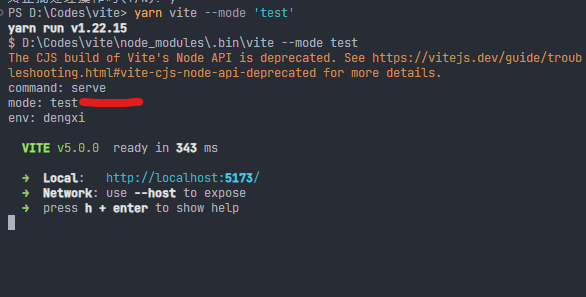
这样就可以通过不同的命令,来控制mode变量了。
loadEnv的第二个参数,其实是用来存放环境变量文件所在的路径,一般这种配置文件,都是放到项目根目录下的,通过process.cwd()方法,可以获取当前node进程所在的位置,也就是vite.config.js文件所在的位置,而vite.config.js也在项目根目录下,所以可以这么直接用。但本质上第二个参数就是一个路径,理论上,通过配置这第二个参数,我们能够将存储变量的文件放到任意路径下。
loadEnv的第三个参数,是用来配置存储环境变量文件的文件名前缀,默认是.env,通过配置它,我们就能有多个不同环境的配置环境变量的文件了。
如果第三个参数传入 ENV,那默认的存储全局环境变量的文件就得改名为ENV
生产环境存储环境变量的文件,就得改名为ENV.production
开发环境存储环境变量的文件,就得改名为 ENV.development
创建 .env.development 文件 ,文件名称由上文提到的loadEnv方法的第三个参数 和 上文提到的 mode 组合而成,默认开发环境loadEnv方法的第三个参数是.env,默认开发环境mode是development
NAME = "yangxi"
AGE = 20
创建 .env.production 文件 ,文件名称由上文提到的loadEnv方法的第三个参数 和 上文提到的 mode 组合而成,默认生产环境loadEnv方法的第三个参数是.env,默认生产环境mode是production
NAME = "yangxianddengxi"
AGE = 38
再自定义一个test环境
创建 .env.test 文件
NAME = "firstname lastname"
AGE = "number"
此时的vite.config.js
import { defineConfig, loadEnv } from "vite";
import viteBaseConfig from "./vite.base.config.js";
import viteDevConfig from "./vite.dev.config.js";
import vitePrdConfig from "./vite.prd.config.js";
const EnvMap = {
build: () => {
return Object.assign({}, viteBaseConfig, vitePrdConfig);
},
serve: () => {
return Object.assign({}, viteBaseConfig, viteDevConfig);
},
};
export default defineConfig(({ command, mode }) => {
const env = loadEnv(mode, process.cwd(),"");
console.log("env", env.NAME); // 获取当前的环境变量
return EnvMap[command]();
});
分别执行以下命令
yarn dev // 或者yarn vite
yarn build // 或者yarn vite build
yarn dev --mode 'test' // 或者 yarn vite --mode 'test'
左边是development ,中间是production,右边是test
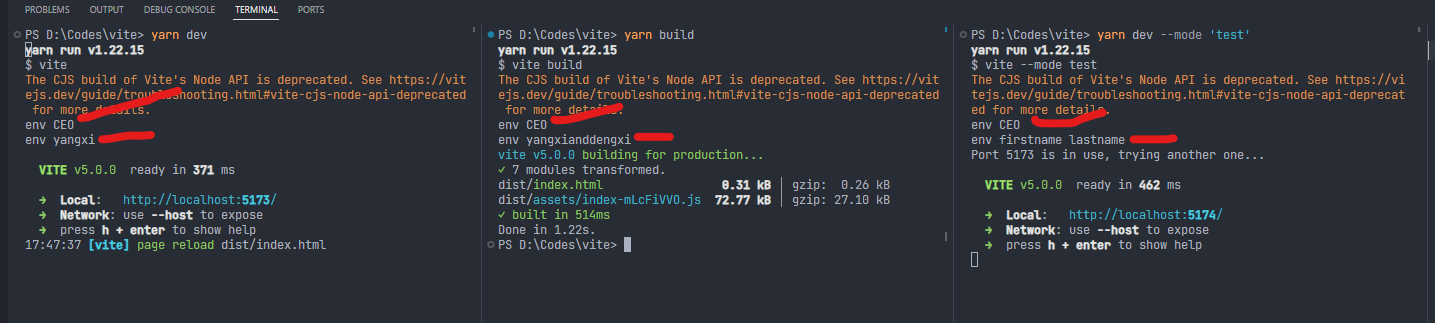
env.POSITION 只有.env文件配置了,所以三个环境都能拿到,没有被覆盖。
env.NAME 每个环境都配置了,.env配置的变量被覆盖了,三个环境拿到的值都不一样。
业务代码需要使用环境变量
上面介绍了在vite中如何配置和使用环境变量,实际开发中,我们在业务中,也常常要使用环境变量。
环境变量,会被vite注入到import.meta.env这个变量中
我们重新配置一下 .env 、.env.development、.env.test
.env
# 上面是服务器所需的环境变量
NAME = "dengxi"
POSITION = "CEO"
# 下面是业务中所需的环境变量,业务中的环境变量默认必须带有前缀VITE_,这样的变量才会被vite注入到import.meta.env
VITE_CAN = "全栈开发"
VITE_DO = "全栈开发"
.env.development
# 上面是服务器所需的环境变量
NAME = "yangxi"
AGE = 20
# 下面是业务中所需的环境变量,业务中的环境变量默认必须带有前缀VITE_,这样的变量才会被vite注入到import.meta.env
VITE_CAN = "前端开发"
.env.test
# 上面是服务器所需的环境变量
NAME = "firstname lastname"
AGE = "number"
# 下面是业务中所需的环境变量,业务中的环境变量默认必须带有前缀VITE_,这样的变量才会被vite注入到import.meta.env
VITE_CAN = "啥也不会"
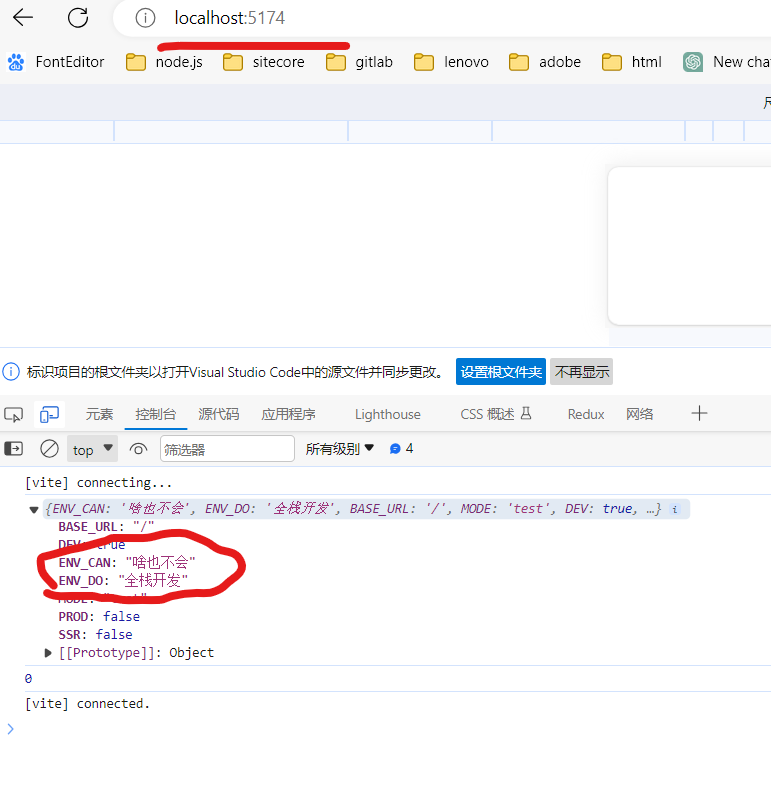
我们在main.js中尝试打印 import.meta.env
import { count } from "./counter.js";
console.log(import.meta.env)
console.log(count);
分别启动development环境的服务器和test环境的服务器
yarn build // 或者yarn vite build
yarn dev --mode 'test' // 或者 yarn vite --mode 'test'
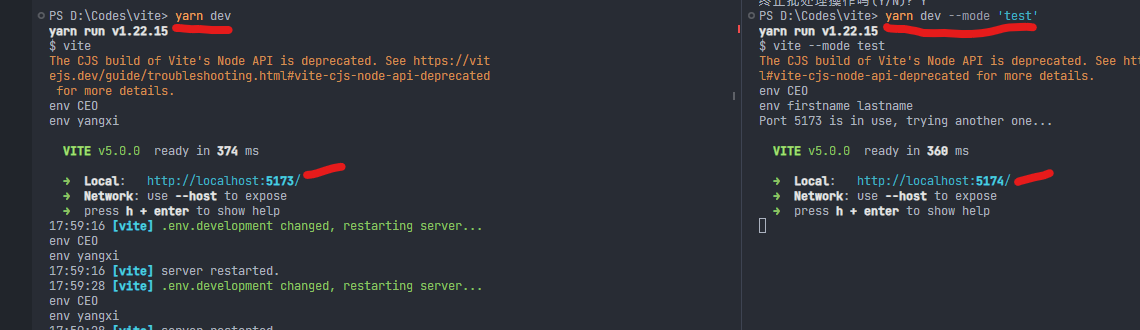
分别打开浏览器查看
development环境
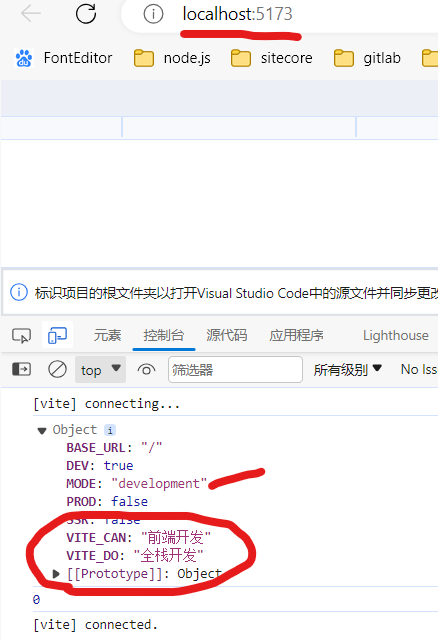
test环境
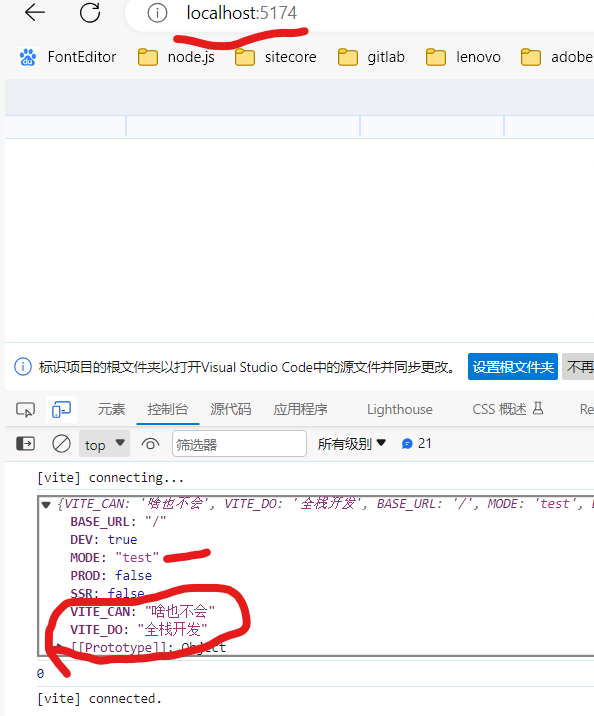
环境变量中,只有VITE_前缀的环境变量才被成功注入到import.meta.env中,供业务端使用
.env的全局配置变量VITE_DO也被注入了,但如果对应的环境变量中,有同名的变量,它VITE_CAN将会被覆盖
修改VITE_前缀
默认强制加一个VITE_才能注入到业务中,也挺恶心的,但必须得有一个前缀,不然如何区分注入服务器的环境变量和业务中使用的环境变量呢
通过配置envPrefix来改变使用的前缀,一般来说不同环境使用的环境变量名称都是相同,不然你就得在不同的环境配置不同名称的环境变量,而且在使用的时候也要用不同的名字,太麻烦了。所以这个envPrefix配置在vite.base.config.js即可。
vite.base.config.js
import { defineConfig } from "vite";
export default defineConfig({
optimizeDeps: {
exclude: [], // 将指定数组中的依赖不进行预构建
},
envPrefix: "ENV", // 更改环境变量注入到业务代码中,所需的前缀名
});
修改完对应的环境变量名称后,一样能拿到环境变量