2021秋招-目录
知识点总结
- 预训练语言模型: Bert家族
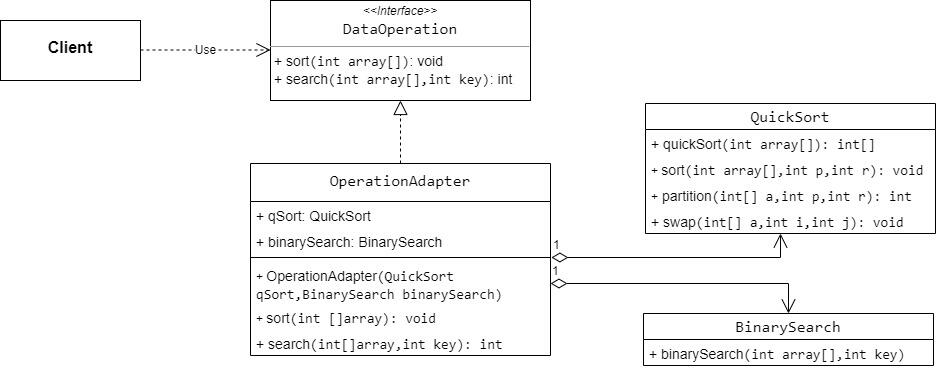
1.1 BERT、attention、transformer理解部分
- B站讲解–强烈推荐
- 可视化
- 推倒
- 结合代码理解
- 代码部分
- 常见面试考点以及问题:
- word2vec 、 fasttext 、elmo;
- BN 、LN、CN、WN
- NLP中的loss与评价总结
4.1 loss_function:
- 深度学习-Loss函数
- L1、L2正则化总结: L1,L2正则所有问题-视频-PPT截图⭐⭐⭐⭐
5.1 知乎-L1正则化与L2正则化⭐⭐⭐
5.2 贝叶斯眼里的正则化⭐⭐
5.1 L1正则化与L2正则化
5.2 深入理解L1、L2正则化
5.3 L1和L2正则化的概率解释🎃
5.4 机器学习中的范数规则化之(一)L0、L1与L2范数
5.5 L1正则化和L2正则化的详细直观解释
5.6 机器学习——正则化不理解的地方 - 过拟合、欠拟合 原因、现象、解决办法。
6.1 深度学习中的过拟合问题和解决办法(转载)
6.2
面经
刷题
深度学习汇总
0. 数学公式整理
机器学习之常用矩阵/向量运算-待整理
- 矩阵乘法
- Hadamard product
- 向量点积
- 向量叉积
- CNN中点积求和
- 矩阵乘法中: 可以看作 向量点积;
(转载)数学-矩阵计算 矩阵和向量的求导法则-待整理
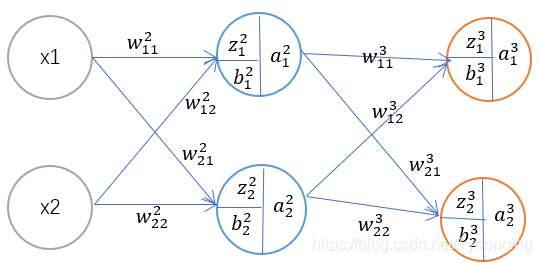
1. 前馈网络、反向传播公式推导
反向传播算法(过程及公式推导)⭐⭐⭐
反向传播算法—从四个基本公式说起
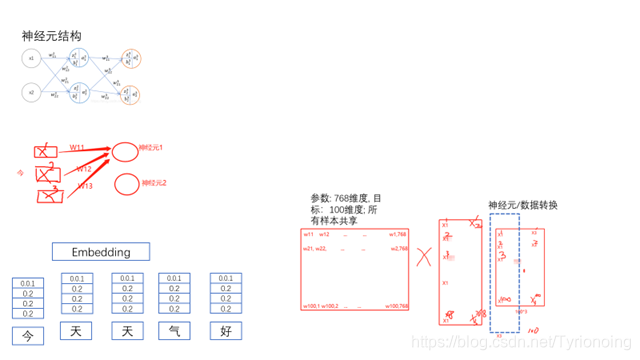
- 神经元结构神经网络入门——神经元算法
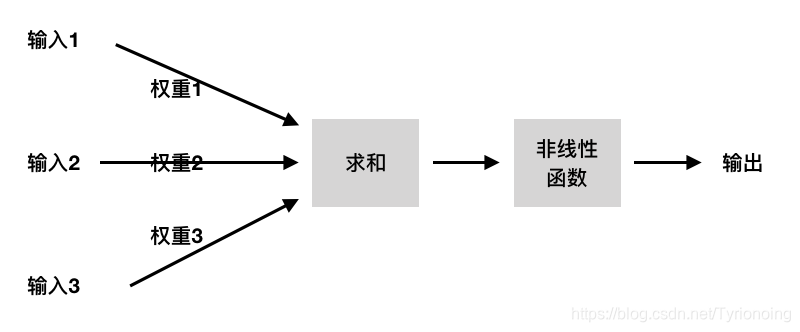
- 神经元/数据/参数 计算; 神经元指的一个结构。
2. SGD推倒
3. 优化器总结
4. 激活函数总结
5. pooling、dropout、
6. 参数 &超参数、batch_size、学习率
6.损失函数专题
7.过拟合、欠拟合
8.BN、LN
8.1 Internal Covariate Shift
- 如何理解 Internal Covariate Shift?
深度神经网络模型的训练为什么会很困难?其中一个重要的原因是,深度神经网络涉及到很多层的叠加,而每一层的参数更新会导致上层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新。为了训好模型,我们需要非常谨慎地去设定学习率、初始化权重、以及尽可能细致的参数更新策略。
Google 将这一现象总结为 Internal Covariate Shift,简称 ICS。 什么是 ICS 呢?
大家都知道在统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如 transfer learning / domain adaptation 等。而 covariate shift 就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同。
大家细想便会发现,的确,对于神经网络的各层输出,由于它们经过了层内操作作用,其分布显然与各层对应的输入信号分布不同,而且差异会随着网络深度增大而增大,可是它们所能“指示”的样本标记(label)仍然是不变的,这便符合了covariate shift的定义。由于是对层间信号的分析,也即是“internal”的来由。
那么ICS会导致什么问题?
简而言之,每个神经元的输入数据不再是“独立同分布”。
其一,上层参数需要不断适应新的输入数据分布,降低学习速度。
其二,下层输入的变化可能趋向于变大或者变小,导致上层落入饱和区,使得学习过早停止。
其三,每层的更新都会影响到其它层,因此每层的参数更新策略需要尽可能的谨慎。