目录
1、什么是索引
2、索引分类
3、索引的基本操作
3.1、主键索引
3.2、单列索引
3.3、唯一索引
3.4、复合索引
4、索引的底层原理
为什么使用B+Tree而不是B-Tree?
如果数据量特别大的情况下,B+Tree会不会深度太深影响查询效率?
5、聚簇索引和非聚簇索引
5.1、概念:
5.2、使用聚簇索引的优势
5.3、聚簇索引需要注意什么
5.4、为什么通常建议使用自增id
6、索引失效的常见场景
1、什么是索引
1.1、索引定义
索引是一种帮助MySQL提高查询效率的数据结构
1.2、索引的优点
加快数据查询的速度
1.3、索引的缺点
- 维护索引需要耗费数据库资源
- 索引需要占用磁盘空间
- 当对表的数据进行增删改时,因为要维护索引,速度会受到影响
2、索引分类
- 主键索引:设定为主键后数据库会自动建立索引,innodb为聚簇索引
- 单值索引:一个索引只包含一个列,一个表可以有多个单列索引
- 唯一索引:索引列的值必须唯一,但允许有空值
- 复合索引:一个索引包含多个列
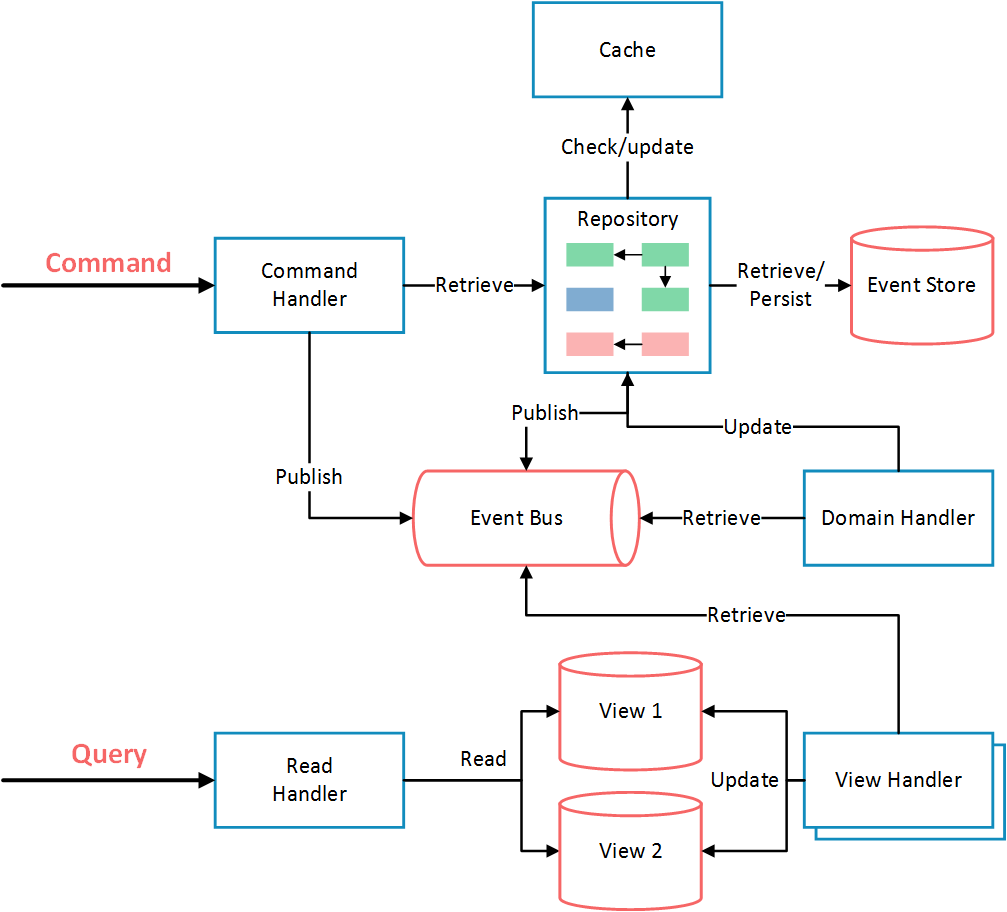
3、索引的基本操作
3.1、主键索引
建表,把id设置为主键:

查看索引:

可以看到,我们没有设置索引,但数据库已经自动帮我们把主键设置为索引了~
3.2、单列索引
建表,把age设置为单列索引:

通过上述,我们可以观察到,主键被数据库自动设置为索引,单列索引可以和主键索引同时存在~
3.3、唯一索引
建表,把name设置为唯一索引:

唯一索引和主键索引的区别:

主键索引的值不能为空,而唯一索引的值可以为空(我在MySQL5.7版本上是支持多个数据为空的的)~
3.4、复合索引
建表,把name和age设置为复合索引:

复合索引底层如何存储的,我们先来看看索引的底层原理:
4、索引的底层原理
在MySQL中,实际存储数据,是如何存储的呢?
如下:
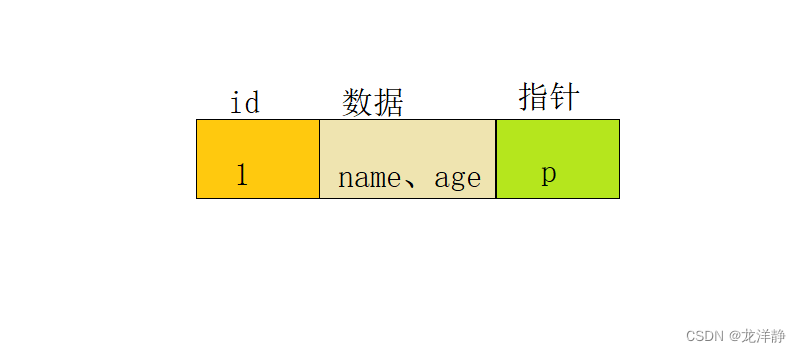
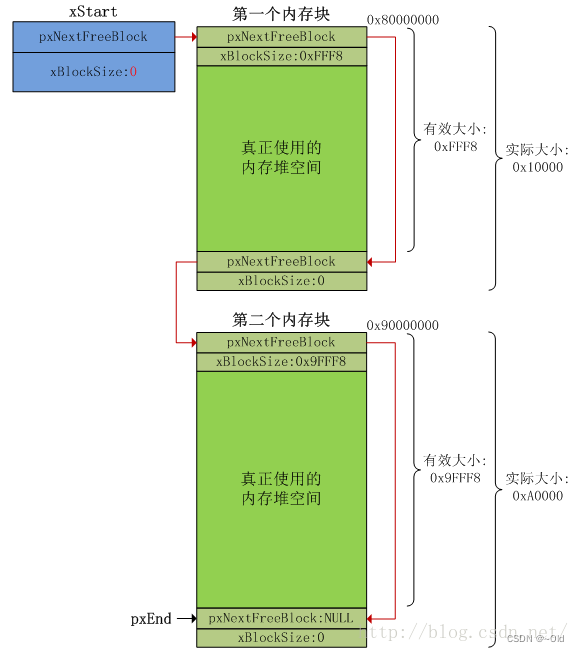
看上图,我们会知道存储数据时,是按照三部分存储的,一个是主键索引,一个是数据部分,一个是指针。那么指针指向哪里呢?指针是指向下一个节点的:
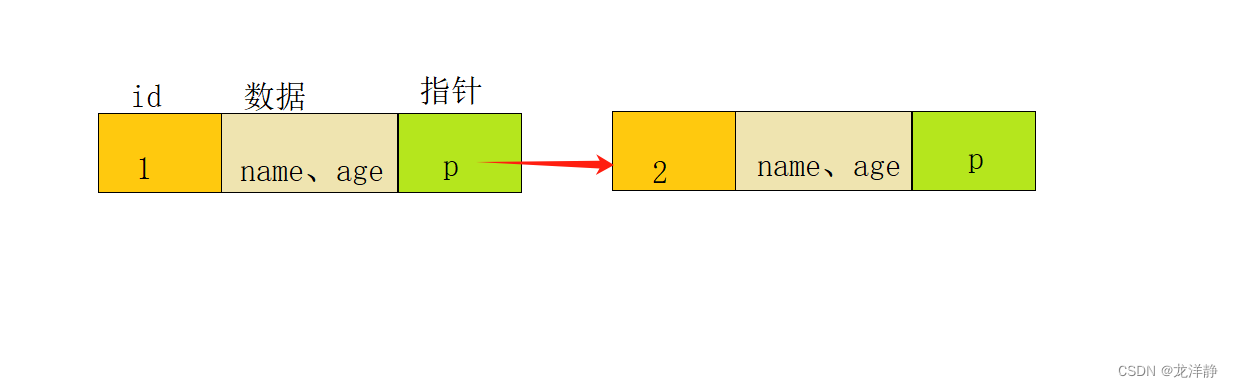
数据就是这样组织起来的。有一个点需要注意的是,MySQL索引底层的数据是按照主键进行有序放置的,也就是说,数据是按照主键索引进行有序存储的。那么问题来了,当我们存入的数据特多时,我们是需要把数据全部遍历一遍吗?这样的话,时间复杂度是不是有点太大了,如果有一万个数据,运气不好的话,找数据不是得找一万次?
那根据我们上述所说的数据是按照主键有序存储的,那我们就可以对底层数据存储进行优化,把数据划分成一个个的区域,例如下面的3个数据一划分:

划分后,我们就可以把每个区域看成是一页页的数据(MySQL中,每一页默认是规定存储16KB的数据),我们就可以给每一页数据一个目录,如下:
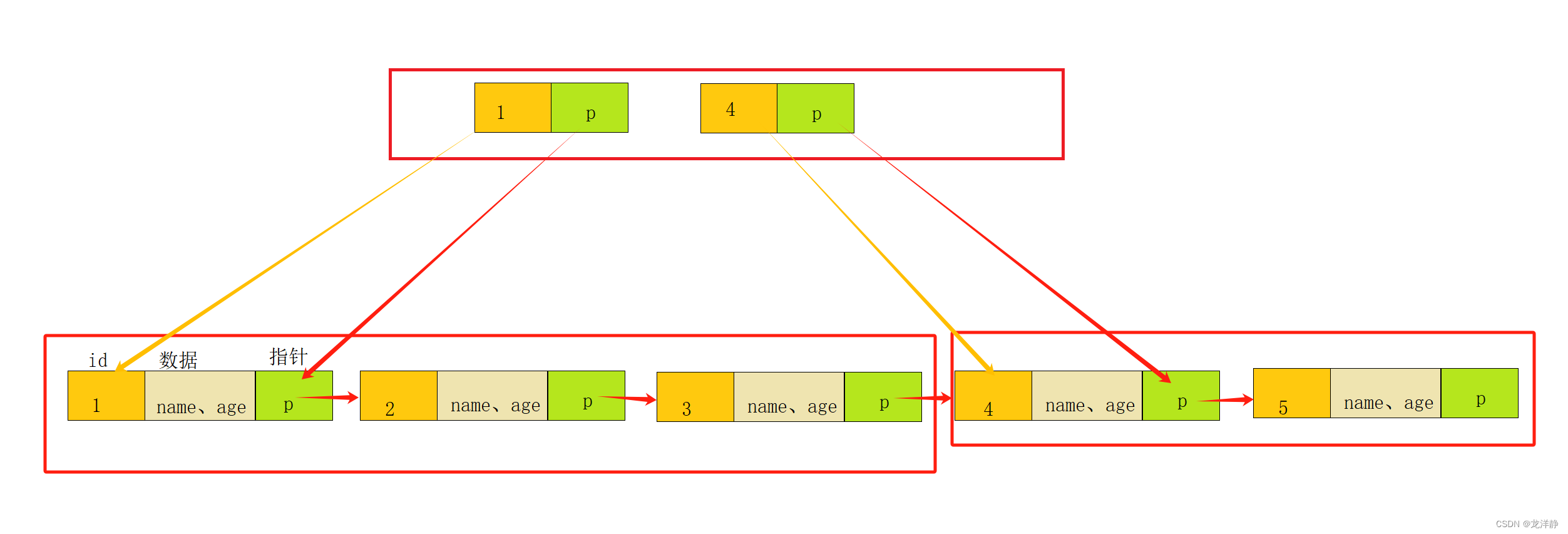
观察上图,我们就可以得知,目录中的数据其实就是每一页的数据的第一个数据~
细心的小伙伴会发现,目录中存储的数据,并不是完整的数据,而是只存放了一个数据的主键和指针~
如果说,如果数据量非常非常大,目录这个区域也已经超过了16KB的数据怎么办,是不是需要我们再给目录再提一层目录呢~如下:
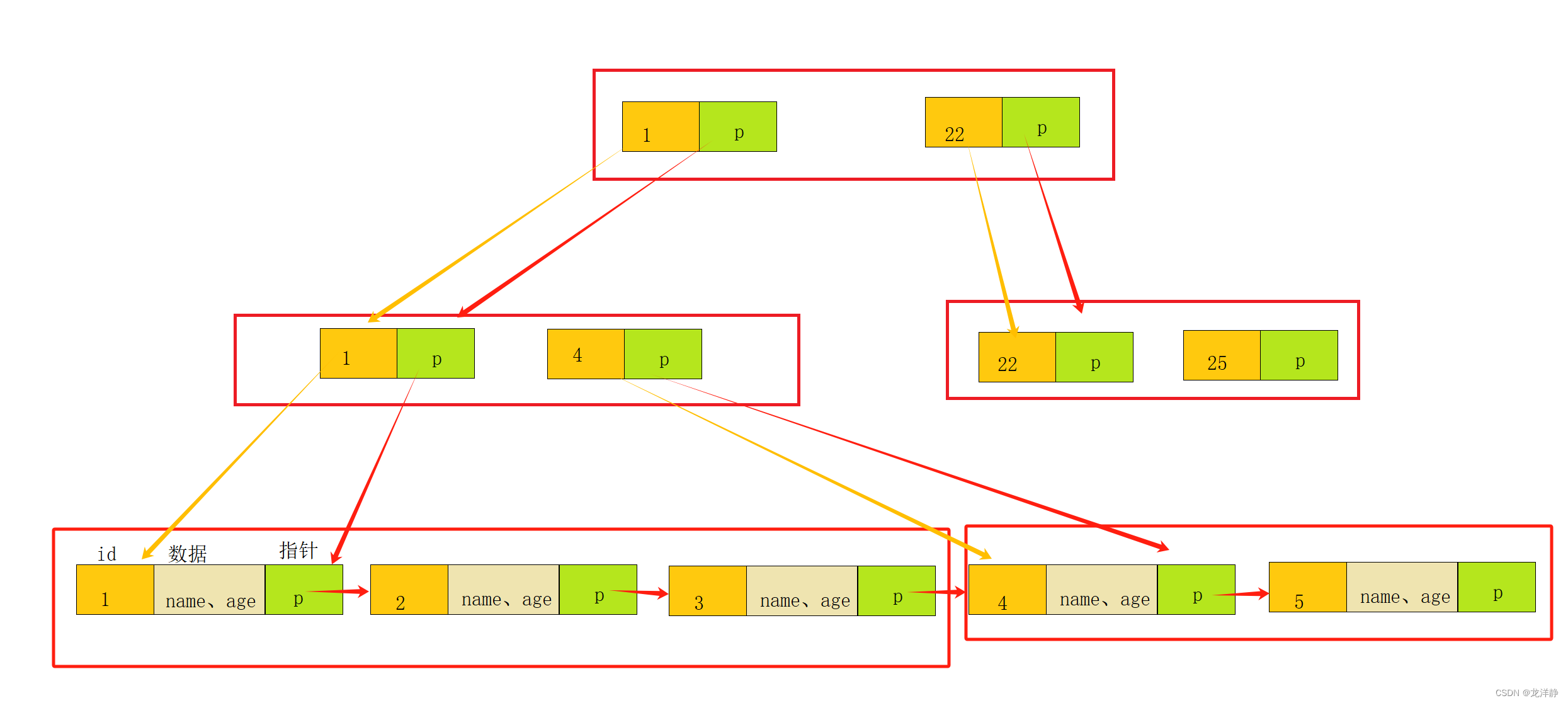
此时,看到这里学习过数据结构的小伙伴就会知道,这个不就是B+树吗?对的,MySQL索引就是采用了B+的数据结构。
B+Tree是在B-Tree基础上的一种优化,使其更适合实现外存储索引结构,InnoDB存储引擎(Mysql的默认引擎就是InnoDB)就是用B+Tree实现其索引结构。
为什么使用B+Tree而不是B-Tree?
- B+Tree的非叶子节点只存储键值信息,而B-Tree是存储所有数据(每一页的存储空间是有限的,如果非叶子节点也存储数据,会导致每个节点能存储的key的数量变少;当存储的数据量很大时,会导致T-Tree的深度变大,增加查询时的磁盘I/O次数,进而影响查询效率;而B+Tree就能很好的解决这些问题)
- B+Tree所有叶子结点之间都有一个链指针,B-Tree没有
- B+Tree数据记录都存放在叶子结点中
如果数据量特别大的情况下,B+Tree会不会深度太深影响查询效率?
不会哦~B+Tree的高度一般都是在2~4层,而MySQL的InnoDB存储引擎在设计时,是将根节点常驻内存的,也就是说,查找某一键值的行记录时最多只需要1~3次磁盘I/O操作~
为什么B+Tree的高度一般都是在2~4层?
我们可以来算一算一页能存放多少数据:
假设是我们刚才的数据的表,有一个id,一个name,一个age。id是int类型,4个字节(数据量大时,需要使用bigInt,8个字节);name假设是设置20字节;age为int类型,4个字节;一个指针,8个字节;一共一条数据36字节。
1KB=1024字节;一页可以存16KB,16*1024/28约等于455条数据。
当我们的B+Tree的高度为2时,也就是说有一层目录,我们来算算能存多少数据:
目录中,只存放id和指针,一共12个字节,一页能存放数据个数:16*1024/12约等于1365个数据。那么1365的数据就对应1365页叶子节点的数据,约等于对应621226条数据。
当B+Tree的高度为3时,大家可以自己算算,能存的数据量其实是非常大的,因此一般B+Tree的高度都是在2~4层的~
5、聚簇索引和非聚簇索引
5.1、概念:
- 聚簇索引:将数据存储与索引放到一块,索引结构的叶子结点保存了行数据
- 非聚簇索引:将数据与索引分开存储,索引结构的叶子结点指向了数据对应的位置。
聚簇索引:
也就是说,数据库中的所有数据都是放在聚簇索引的叶子结点中的,而其他索引都属于辅助索引(例如:复合索引、前缀索引、唯一索引等),辅助索引叶子结点中存储的不是数据的物理位置,而是主键值,因此,辅助索引访问数据时总是需要二次查找的:
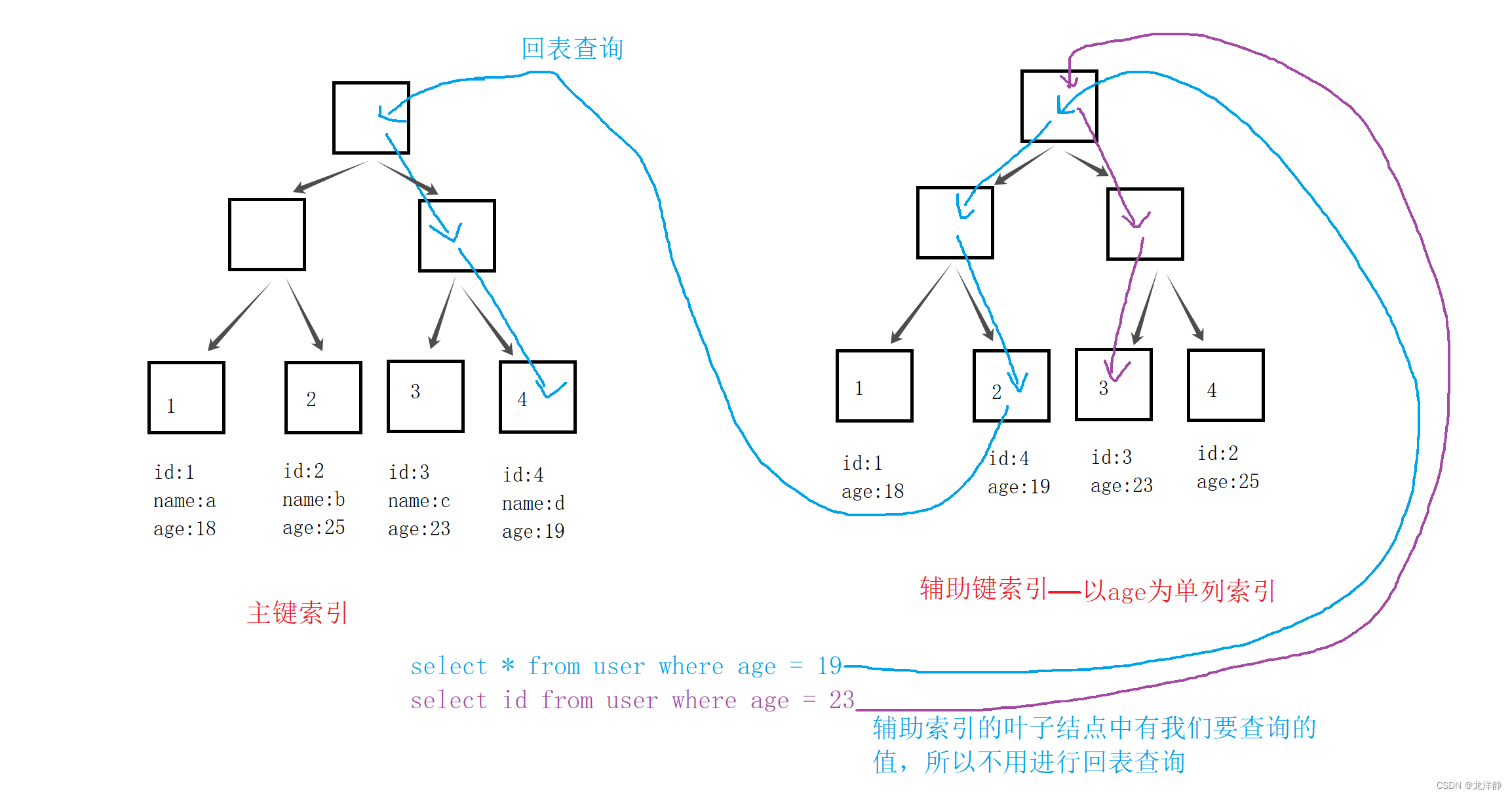
说明:
- 我们会看到辅助索引,是以age作为单列索引的,索引这个索引树就是以age大小排序的~
- InnoDB使用的是聚簇索引,将主键组织到一B+树中,而行数据就储存在叶子节点上,若使用 where d =4"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。
- 若对Name列进行条件搜索,则需要两个步: 第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键,第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。 (重点在于通过其他键需要建立辅助索引)
- 聚簇索引默认是主键,如果表中没有定义主键,InnoDB 会选择一个唯一且非空的索代,如果没有这样的索引,InnoDB 会隐式定义一个主键(举似oracle中的Rowld)来作为聚索引,如果已经设置了主键为聚索引又希望再单独设置聚索引,必须先别除主键,然后添加我们想要的聚能索引,最后恢复设置主键即可。
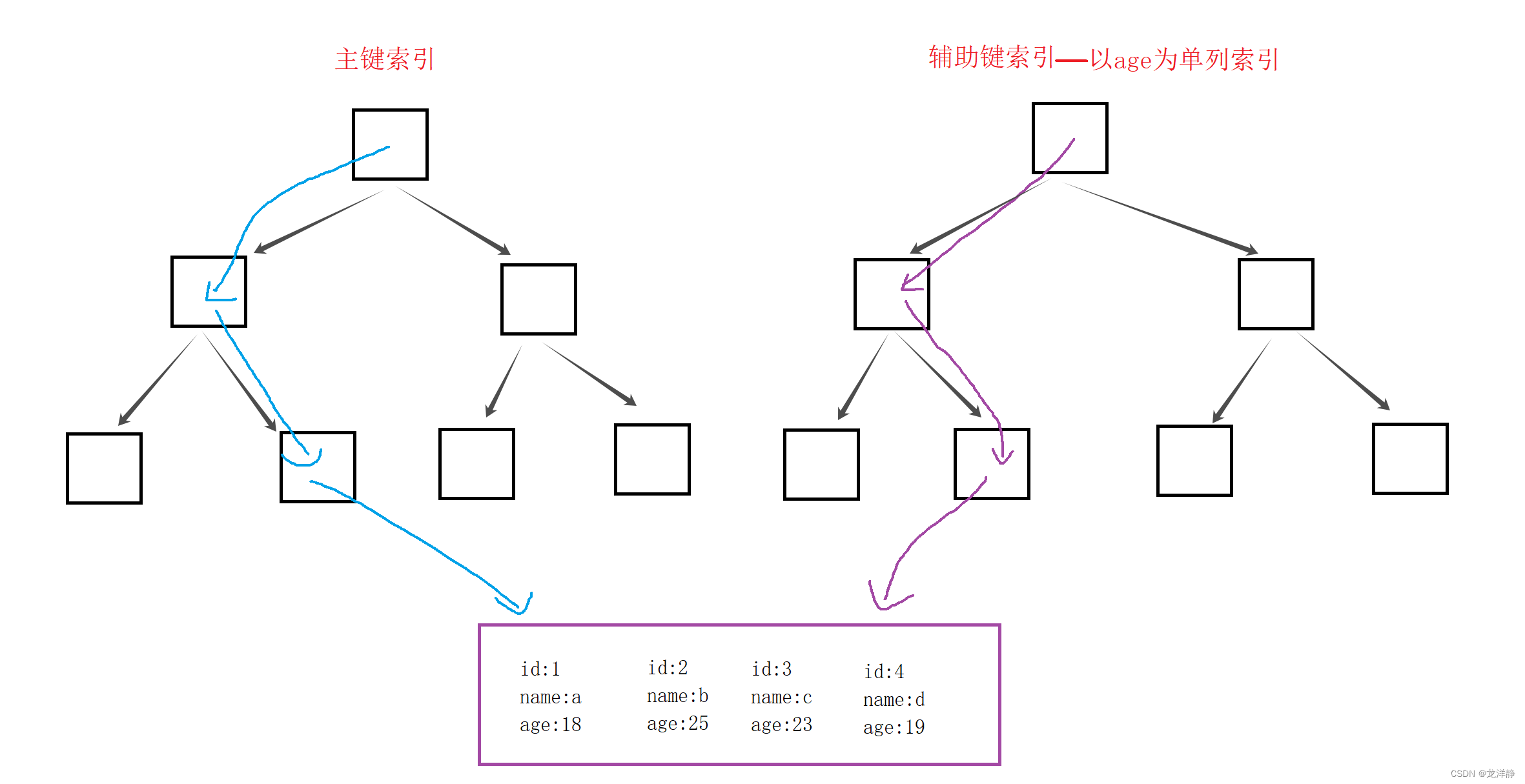
非聚簇索引:
MYISAM就是使用的非聚簇索引,非聚簇索引的两颗B+树看上去没有什么不同,节点的结构完全一致,只是存储的内容不同。主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子结点都使用一个地址指向真正的表数据,对于表数据来说,这两个建没有任何差别,由于索引树是独立的,通过辅助建索引无需访问主键的索引树:
5.2、使用聚簇索引的优势
每次使用辅助索引检索都要经过两次B+树查找,看上去聚簇索引的效率明显要低于非聚簇索引,这不是多此一举吗?聚簇索引的优势在哪?
- 由于行数据和聚簇索引的叶子节点存储在一起,同一页中会有多条行数据,访问同一数据页不同行记录时,已经把页加载到了Buffer中(缓存器),再次访问时,会在内存中完成访问,不必访问磁盘。这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键Id来组织数据,获得数据更快。
- 辅助索引的叶子节点,存储主键值,而不是数据的存放地址。好处是当行数据放生变化时,索引树的节点也需要分裂变化;或者是我们需要查找的数据,在上一次IO读写的缓存中没有,需要发生一次新的IO操作时,可以避免对辅助索引的维护工作,只需要维护聚簇索引树就好了。另一个好处是,因为辅助索引存放的是主键值,减少了辅助索引占用的存储空间大小。
5.3、聚簇索引需要注意什么
当使用主键为聚簇索引时,主键最好不要使用UUID,因为UUID的值太过于离散,不适合排序且可能出现新增记录的UUID,会插入在索引树中间的位置,导致索引树调整复杂度变大,消耗更多的时间和资源。
建议使用int类型的自增,方便排序并且默认会在索引树的末尾增加主键值,对索引树的结构影响最小。而且,逐渐值占用的存储空间越大,辅助索引中保存的主键值也会跟着变大,占用存储空间,也会影响到IO操作读取到的数据量~
5.4、为什么通常建议使用自增id
聚簇索引的数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻的存放在磁盘上的。如果主键不是自增id,那么可以想象,例如使用UUID,每次都是随机值,就会导致每次添加数据时,都不要不断地调整数据的物理地址、重新分页等。当然也有其他措施来减少这些操作,但是这是无法减少这些操作的,但却无法彻底避免。那如果说使用自增,那就简单了,他只需要一页一页的写,索引结构相对紧凑,磁盘碎片少,效率也高~
6、索引失效的常见场景
- 复合索引(联合索引),要使用最左前缀(也就是说,联合索引,索引的叶子结点在排序时其实是按照创建索引时,最左边这个值排序的,因此要使用最左前缀),否则会失效
- 查询时使用like关键字,并且以%开头时,索引会失效
- 在列上进行函数运算时,索引会失效
- 使用in不会造成索引失效,而not in会
- 使用or关键字时,如果or的前后的列都是索引则会使用索引,如果其中一个列不是索引,索引就会失效~
好啦,本期就到这里咯,下期见~~~