✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。
🍎个人主页:小嗷犬的个人主页
🍊个人网站:小嗷犬的技术小站
🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。
本文目录
- 数据集与 Notebook
- 环境准备
- 数据集
- 可视化
- 模型
- 预测
- Loss 与评价指标
数据集与 Notebook
数据集:70 Dog Breeds-Image Data Set
Notebook:「MobileNet V3」70 Dog Breeds-Image Classification
环境准备
import warnings
warnings.filterwarnings('ignore')
禁用警告,防止干扰。
!pip install lightning --quiet
安装 PyTorch Lightning。
import random
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="darkgrid", font_scale=1.5, font="SimHei", rc={"axes.unicode_minus":False})
导入常用的库,设置绘图风格。
import torch
import torchmetrics
from torch import nn, optim
from torch.nn import functional as F
from torch.utils.data import DataLoader
from torchvision import transforms, datasets, models
导入 PyTorch 相关的库。
import lightning.pytorch as pl
from lightning.pytorch.loggers import CSVLogger
from lightning.pytorch.callbacks.early_stopping import EarlyStopping
导入 PyTorch Lightning 相关的库。
seed = 1
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
pl.seed_everything(seed, workers=True)
设置随机种子。
数据集
batch_size = 64
设置批次大小。
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
])
test_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
设置数据集的预处理。
train_dataset = datasets.ImageFolder(root="/kaggle/input/70-dog-breedsimage-data-set/train", transform=train_transform)
val_dataset = datasets.ImageFolder(root="/kaggle/input/70-dog-breedsimage-data-set/valid", transform=test_transform)
test_dataset = datasets.ImageFolder(root="/kaggle/input/70-dog-breedsimage-data-set/test", transform=test_transform)
读取数据集。
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
加载数据集。
可视化
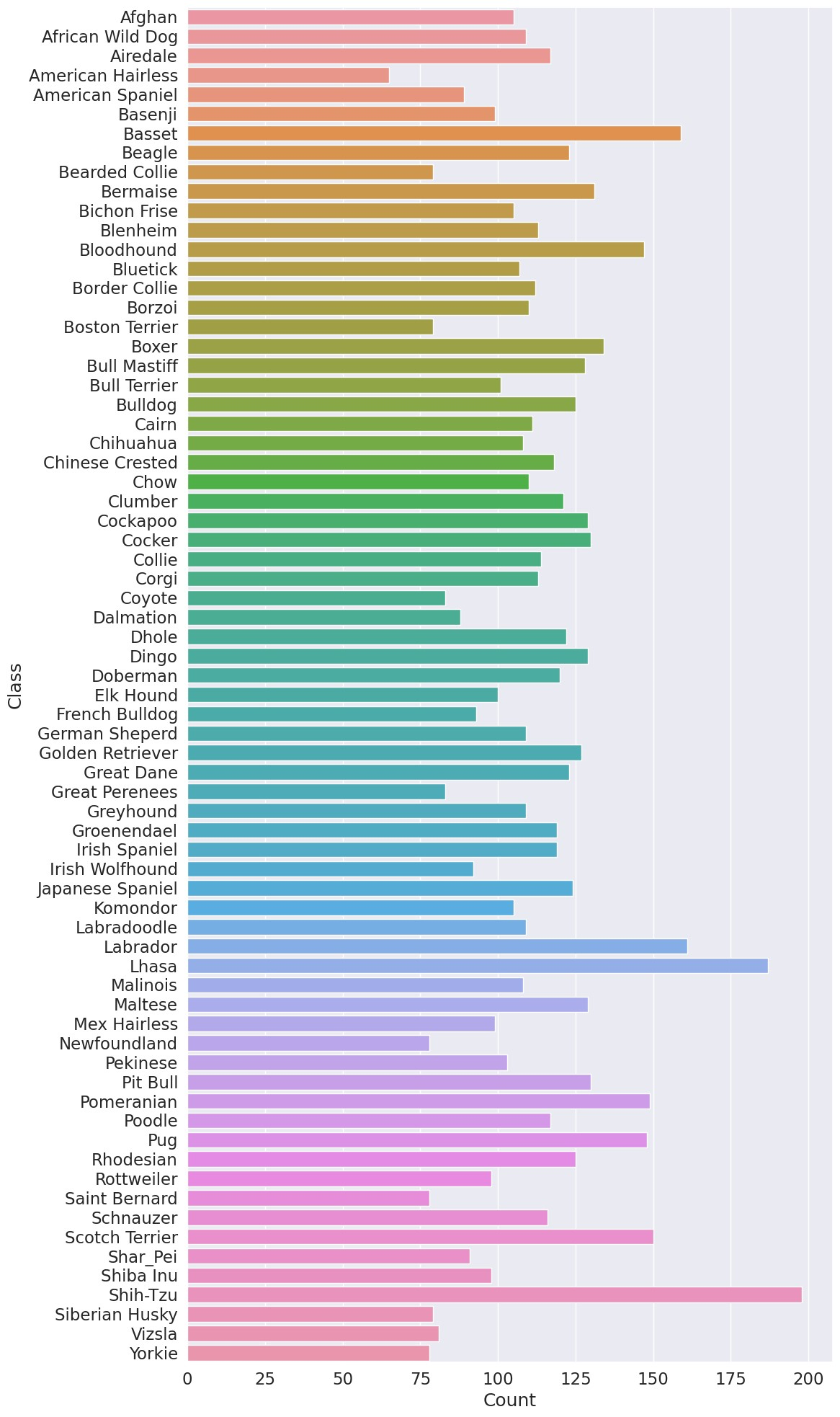
class_names = train_dataset.classes
class_count = [train_dataset.targets.count(i) for i in range(len(class_names))]
df = pd.DataFrame({"Class": class_names, "Count": class_count})
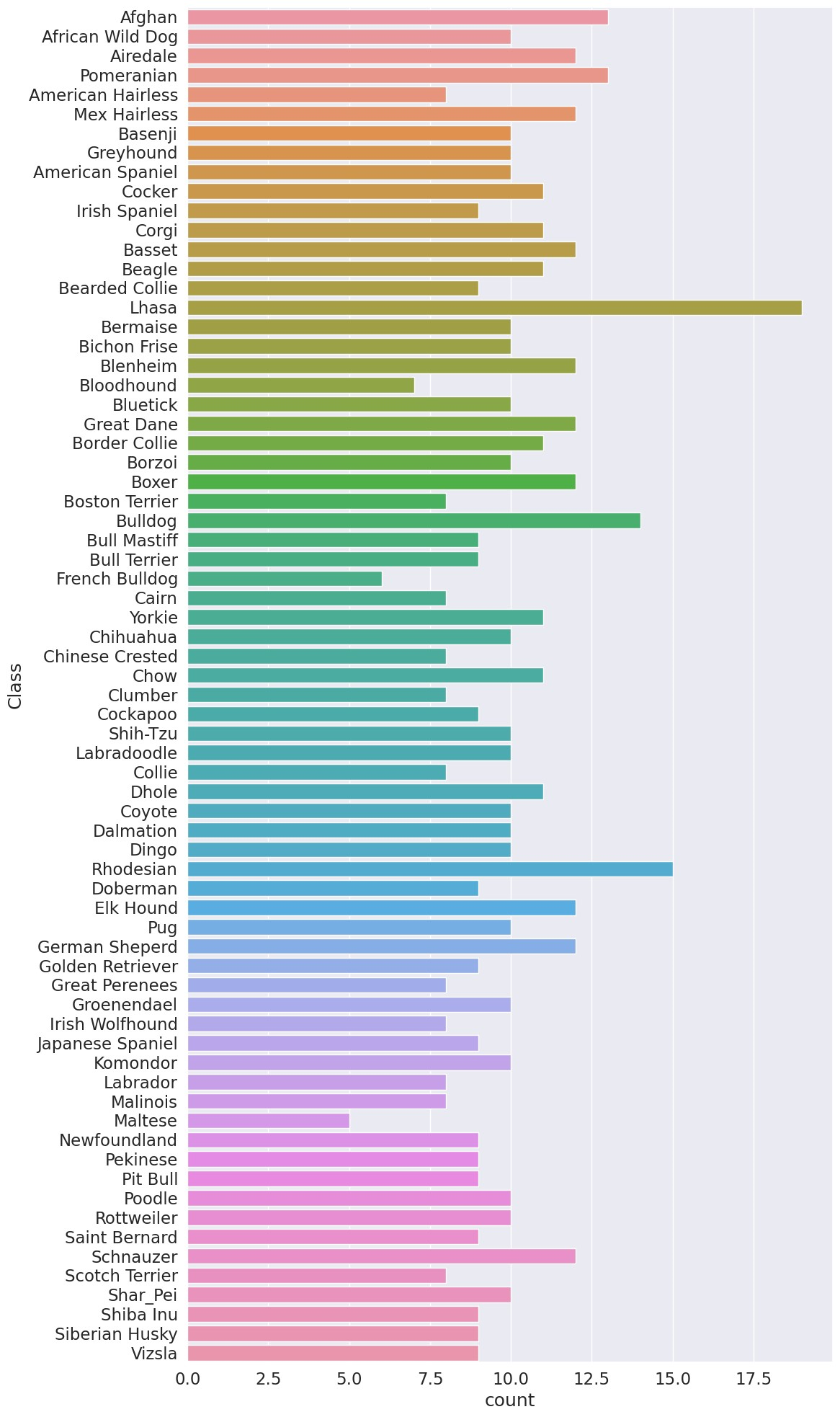
plt.figure(figsize=(12, 20), dpi=100)
sns.barplot(x="Count", y="Class", data=df)
plt.tight_layout()
plt.show()
绘制训练集的类别分布。
plt.figure(figsize=(12, 20), dpi=100)
images, labels = next(iter(val_loader))
for i in range(8):
ax = plt.subplot(8, 4, i + 1)
plt.imshow(images[i].permute(1, 2, 0).numpy())
plt.title(class_names[labels[i]])
plt.axis("off")
plt.tight_layout()
plt.show()
绘制训练集的样本。

模型
class LitModel(pl.LightningModule):
def __init__(self, num_classes=1000):
super().__init__()
self.model = models.mobilenet_v3_large(weights="IMAGENET1K_V2")
# for param in self.model.parameters():
# param.requires_grad = False
self.model.classifier[3] = nn.Linear(self.model.classifier[3].in_features, num_classes)
self.accuracy = torchmetrics.Accuracy(task="multiclass", num_classes=num_classes)
self.precision = torchmetrics.Precision(task="multiclass", average="macro", num_classes=num_classes)
self.recall = torchmetrics.Recall(task="multiclass", average="macro", num_classes=num_classes)
self.f1score = torchmetrics.F1Score(task="multiclass", num_classes=num_classes)
def forward(self, x):
x = self.model(x)
return x
def configure_optimizers(self):
optimizer = optim.Adam(
self.parameters(), lr=0.001, betas=(0.9, 0.99), eps=1e-08, weight_decay=1e-5
)
return optimizer
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.cross_entropy(y_hat, y)
self.log("train_loss", loss, on_step=True, on_epoch=False, prog_bar=True, logger=True)
self.log_dict(
{
"train_acc": self.accuracy(y_hat, y),
"train_prec": self.precision(y_hat, y),
"train_recall": self.recall(y_hat, y),
"train_f1score": self.f1score(y_hat, y),
},
on_step=True,
on_epoch=False,
logger=True,
)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.cross_entropy(y_hat, y)
self.log("val_loss", loss, on_step=False, on_epoch=True, logger=True)
self.log_dict(
{
"val_acc": self.accuracy(y_hat, y),
"val_prec": self.precision(y_hat, y),
"val_recall": self.recall(y_hat, y),
"val_f1score": self.f1score(y_hat, y),
},
on_step=False,
on_epoch=True,
logger=True,
)
def test_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
self.log_dict(
{
"test_acc": self.accuracy(y_hat, y),
"test_prec": self.precision(y_hat, y),
"test_recall": self.recall(y_hat, y),
"test_f1score": self.f1score(y_hat, y),
}
)
def predict_step(self, batch, batch_idx, dataloader_idx=None):
x, y = batch
y_hat = self(x)
preds = torch.argmax(y_hat, dim=1)
return preds
定义模型。
num_classes = len(class_names)
model = LitModel(num_classes=num_classes)
logger = CSVLogger("./")
early_stop_callback = EarlyStopping(
monitor="val_loss", min_delta=0.00, patience=5, verbose=False, mode="min"
)
trainer = pl.Trainer(
max_epochs=20,
enable_progress_bar=True,
logger=logger,
callbacks=[early_stop_callback],
deterministic=True,
)
trainer.fit(model, train_loader, val_loader)
训练模型。
trainer.test(model, val_loader)
测试模型。
预测
pred = trainer.predict(model, test_loader)
pred = torch.cat(pred, dim=0)
pred = pd.DataFrame(pred.numpy(), columns=["Class"])
pred["Class"] = pred["Class"].apply(lambda x: class_names[x])
plt.figure(figsize=(12, 20), dpi=100)
sns.countplot(y="Class", data=pred)
plt.tight_layout()
plt.show()
绘制预测结果的类别分布。
Loss 与评价指标
log_path = logger.log_dir + "/metrics.csv"
metrics = pd.read_csv(log_path)
x_name = "epoch"
plt.figure(figsize=(8, 6), dpi=100)
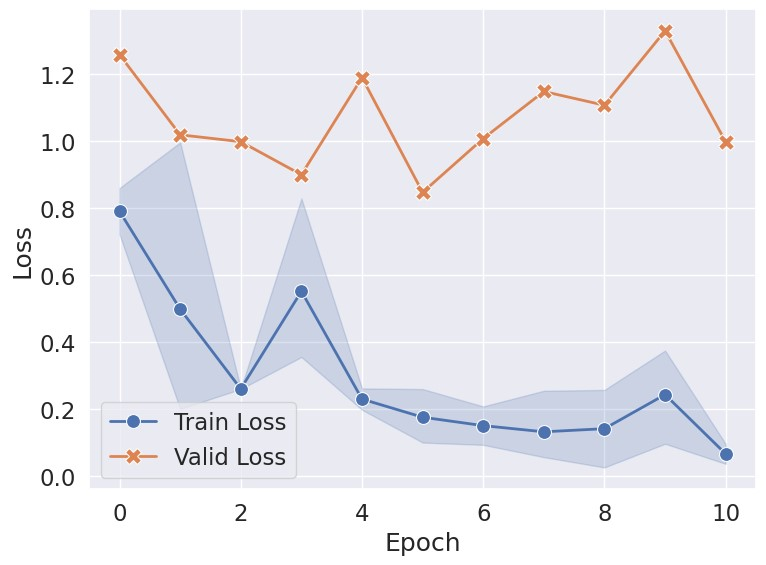
sns.lineplot(x=x_name, y="train_loss", data=metrics, label="Train Loss", linewidth=2, marker="o", markersize=10)
sns.lineplot(x=x_name, y="val_loss", data=metrics, label="Valid Loss", linewidth=2, marker="X", markersize=12)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.tight_layout()
plt.show()
plt.figure(figsize=(14, 12), dpi=100)
plt.subplot(2,2,1)
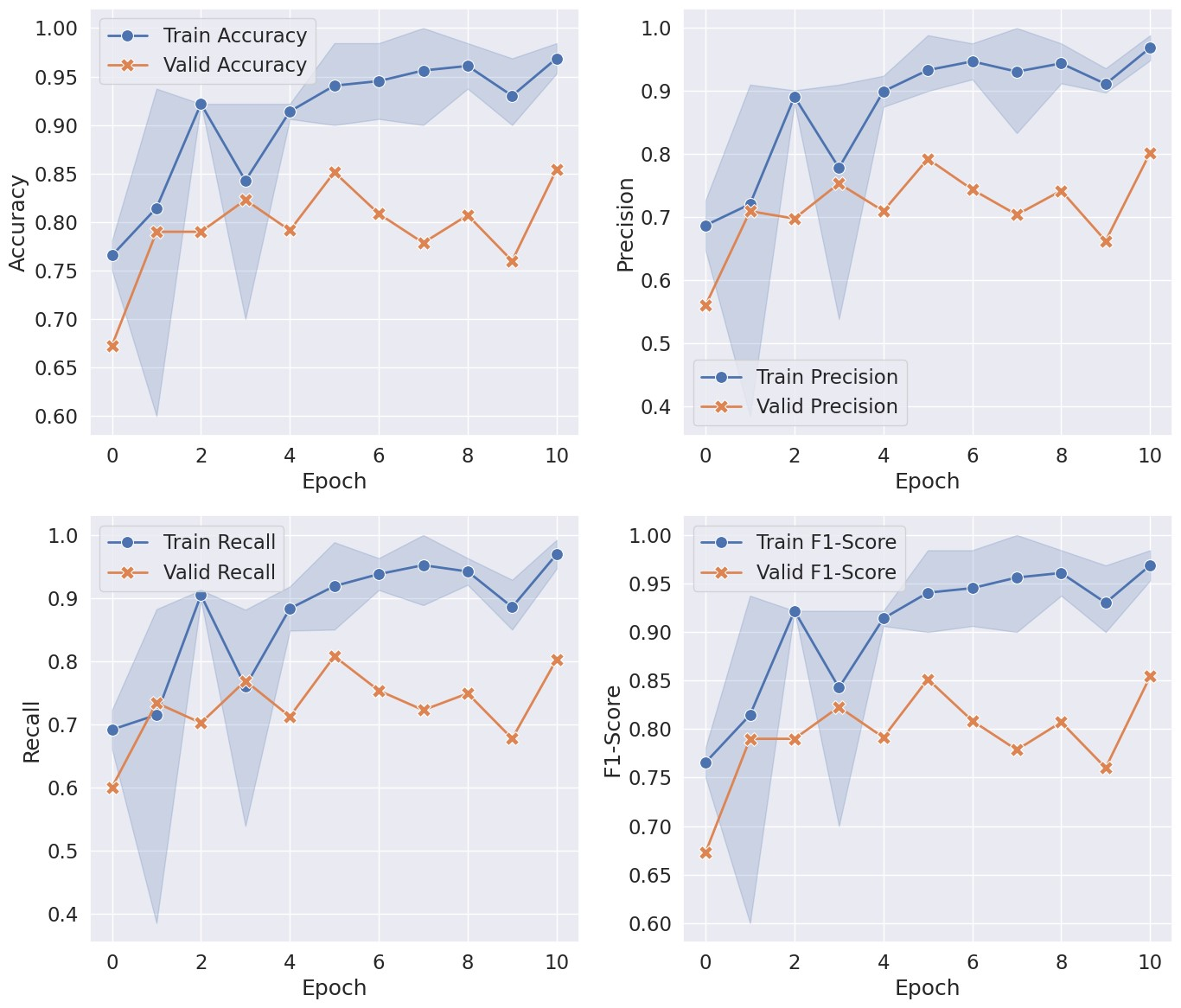
sns.lineplot(x=x_name, y="train_acc", data=metrics, label="Train Accuracy", linewidth=2, marker="o", markersize=10)
sns.lineplot(x=x_name, y="val_acc", data=metrics, label="Valid Accuracy", linewidth=2, marker="X", markersize=12)
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.subplot(2,2,2)
sns.lineplot(x=x_name, y="train_prec", data=metrics, label="Train Precision", linewidth=2, marker="o", markersize=10)
sns.lineplot(x=x_name, y="val_prec", data=metrics, label="Valid Precision", linewidth=2, marker="X", markersize=12)
plt.xlabel("Epoch")
plt.ylabel("Precision")
plt.subplot(2,2,3)
sns.lineplot(x=x_name, y="train_recall", data=metrics, label="Train Recall", linewidth=2, marker="o", markersize=10)
sns.lineplot(x=x_name, y="val_recall", data=metrics, label="Valid Recall", linewidth=2, marker="X", markersize=12)
plt.xlabel("Epoch")
plt.ylabel("Recall")
plt.subplot(2,2,4)
sns.lineplot(x=x_name, y="train_f1score", data=metrics, label="Train F1-Score", linewidth=2, marker="o", markersize=10)
sns.lineplot(x=x_name, y="val_f1score", data=metrics, label="Valid F1-Score", linewidth=2, marker="X", markersize=12)
plt.xlabel("Epoch")
plt.ylabel("F1-Score")
plt.tight_layout()
plt.show()
绘制 Loss 与评价指标的变化。