个人简介:Java领域新星创作者;阿里云技术博主、星级博主、专家博主;正在Java学习的路上摸爬滚打,记录学习的过程~
个人主页:.29.的博客
学习社区:进去逛一逛~

InnoDB存储引擎
- ⑩⑧【MySQL】详解InnoDB存储引擎
- 1. InnoDB逻辑存储结构
- 2. InnoDB架构
- 🗜内存架构
- 🗜磁盘架构
- 🗜后台线程
- 3. 事务的原理
- ⚪redo log
- ⚪undo log
- 4. MVCC
- 🐟MVCC基本概念
- 🐟MVCC实现原理
⑩⑧【MySQL】详解InnoDB存储引擎
1. InnoDB逻辑存储结构
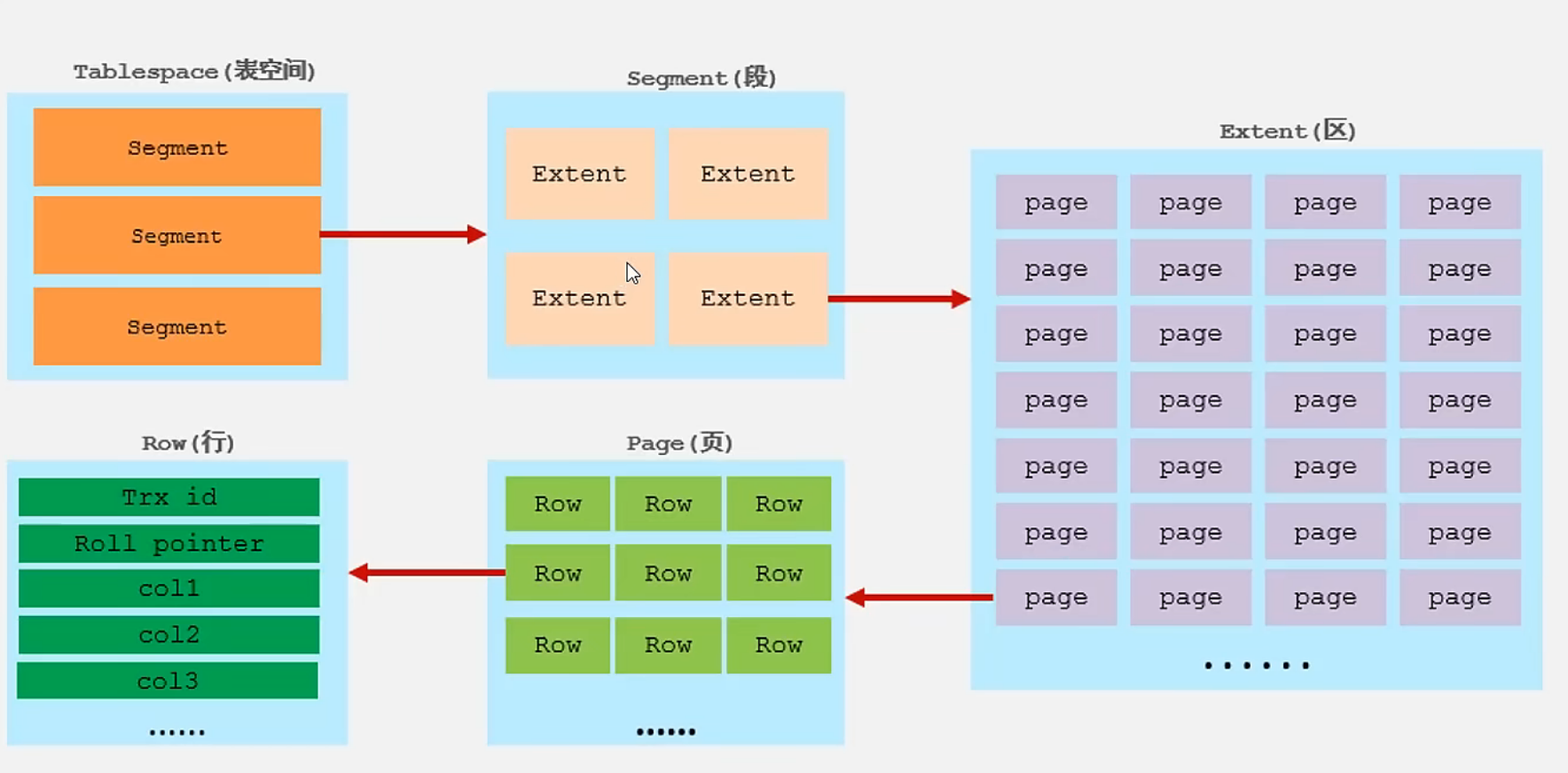
InnoDB逻辑存储结构:
-
🚀
表空间(idb文件):一个MySQL实例可以对应多个表空间,用于存储记录、索引等数据。 -
🚀
段:分为数据段(Leaf node segment) 、索引段(Non-leaf node segment) 、回滚段(Rollback segment) ,InnoDB是索引组织表,数据段就是B+树的叶子节点,索引段即为B+树的非叶子节点。段用来管理多个Extent(区) 。 -
🚀
区:表空间的单元结构,每个区的大小为1M。默认情况下,InnoDB存储引擎页大小为16K,即一个区中一共有64个连续的页。 -
🚀
页:是InnoDB存储引擎磁盘管理的最小单元,每个页的大小默认为16KB。为了保证页的连续性,InnoDB存储引擎每次从磁盘申请4-5个区。 -
🚀
行:InnoDB存储引擎数据是按行进行存放的。 -
- ⚪
Trx_id:每次对某条记录进行改动时,都会把对应的事务id赋值给Trx_id隐藏列。 - ⚪
Roll pointer:每次对某条引记录进行改动时,都会把旧的版本写入到undo日志中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。
- ⚪
2. InnoDB架构
架构:
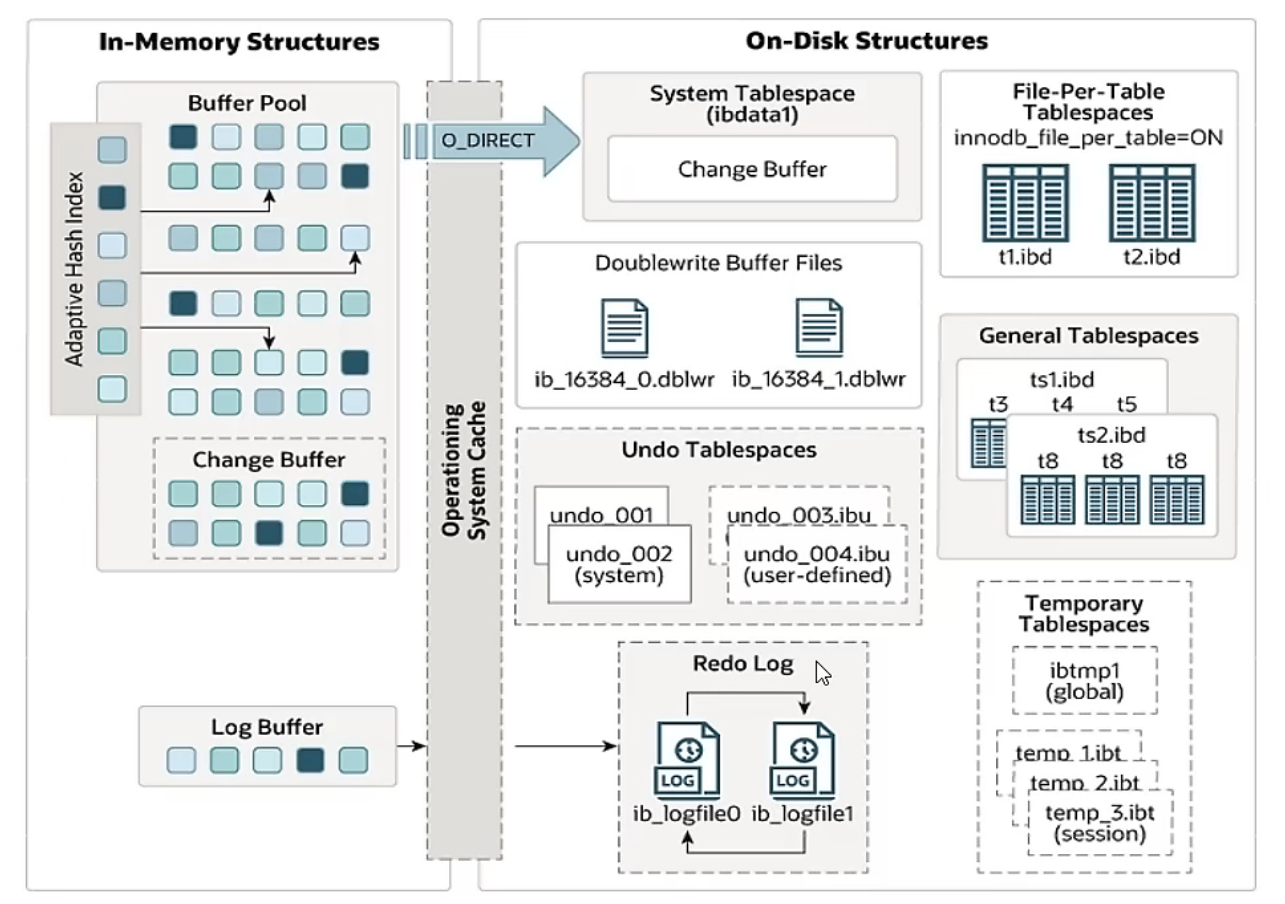
MySQL5.5版本开始,默认使用InnoDB存储引擎,它擅长事务处理,具有崩溃恢复特性,在日常开发中使用非常广泛。下面是InnoDB架构图,左侧为内存结构,右侧为磁盘结构。
🗜内存架构
内存结构 - In-Memory Structures:
- 🚀
Buffer Poll:缓冲池 是主内存中的一个区域,里面可以缓存磁盘上经常操作的真实数据,在执行增删改查操作时,先操作缓冲池中的数据(若缓冲池没有数据,则从磁盘加载并缓存),然后再以一定频率刷新到磁盘,从而减少磁盘IO,加快处理速度。 -
- 缓冲池以Page页 为单位,底层采用链表数据结构管理Page 。根据状态,将Page分为三种类型:
-
- ⚪
free page—— 空闲page,未被使用。 - ⚪
clean page—— 被使用page,数据没有被修改过。 - ⚪
dirty page—— 脏页,被使用page,数据被修改过,页中数据与磁盘的数据产生了不一致。
- ⚪
- 🚀
Change Buffer:更改缓冲区(针对于非唯一二级索引页) ,在执行DML语句时,如果这些数据Page
没有在Buffer Pool中,不会直接操作磁盘,而会将数据变更存放在更改缓冲区Change Buffer中,在未
来数据被读取时,再将数据合并恢复到Buffer Pool中,再将合并后的数据刷新到磁盘中。 - 更改缓冲区Change Buffer的意义是什么?
-
- 与聚集索引不同,二级索引通常是非唯一的,并且以相对随机的顺序插入二级索引。同样,删除和更新可能会影响索引树中不相邻的二级索引页,如果每一次都操作磁盘,会造成大量的磁盘IO。有了ChangeBuffer之后,我们可以在缓冲池中进行合并处理,减少磁盘IO。
-
🚀
Adaptive Hash Index:自适应hash索引 ,用于优化对Buffer Pool数据的查询。InnoDB存储引擎会监控对表上各索引页的查询,如果观察到hash索引可以提升速度,则建立hash索引,称之为自适应hash索引。自适应哈希索引,无需人工干预,是系统根据情况自动完成。 -
-
-- innodb中,自适应hash索引的参数:innodb_adaptive_hash_index -- 查看是否开启了 自适应hash SHOW VARIABLES LIKE 'innodb_adaptive_hash_index';
-
-
🚀
Log Buffer:日志缓冲区,用来保存要写入到磁盘中的log日志数据(redo log、undo log),默认大小为16MB ,日志缓冲区的日志会定期刷新到磁盘中。如果需要更新、插入或删除许多行的事务,增加日志缓冲区的大小可以节省磁盘I/O。 -
-
#参数 -- 缓冲区大小:innodb_log_buffer_size -- 日志刷新到磁盘时机:innodb_flush_log_at_trx_commit -- 查看: SHOW VARIABLES LIKE 'innodb_log_buffer_size'; SHOW VARIABLES LIKE 'innodb_flush_log_at_trx_commit'; #或 SELECT @@innodb_log_buffer_size; SELECT @@innodb_flush_log_at_trx_commit; -
日志刷新到磁盘时机:innodb_flush_log_at_trx_commit(值:0/1/2)

-
🗜磁盘架构
磁盘结构 On-Disk Structures:
-
🚀
System Tablespace:系统表空间 是更改缓冲区的存储区域。如果表是在系统表空间创建,而不是每个表文件或通用表空间中创建的,它也可能包含表和索引数据。(在MySQL5.x版本中还包含InnoDB数据字典、undologs等)。 -
-
#参数 : innodb_data_file_path -- 查看相关信息 SHOW VARIABLES LIKE '%data_file_path%';
-
-
🚀
File-Per-Table Tablespaces:每个表的文件表空间 包含单个InnoDB表的数据和索引,并存储在文件系统上的单个数据文件中。 -
-
#参数 : innodb_file_per_table SHOW VARIABLES LIKE '%file_per_table%';
-
-
🚀
General Tablespaces:通用表空间 ,需要通过CREATE TABLESPACE语法创建通用表空间,在创建表时,可以指定通用表空间。 -
-
-- 创建通用表空间 CREATE TABLESPACE 通用表空间名称 ADD DATAFILE '表空间文件名' ENGINE = 存储引擎名; -- 创建表时指定关联的通用表空间 CREATE TABLE 表名( 字段1 字段1类型 [COMMENT 字段1注释], 字段2 字段2类型 [COMMENT 字段2注释], 字段3 字段3类型 [COMMENT 字段3注释], ... 字段n 字段n类型 [COMMENT 字段n注释] )[COMMENT 表注释] TABLESPACE 通用表空间名称;
-
- 🚀
Undo Tablespaces:撤销表空间,MySQL实例在初始化时会自动创建两个默认的undo表空间(初始大小16M),用于存储undo log日志。
- 🚀
Temporary Tablespaces:InnoDB使用会话临时表空间 和全局临时表空间 。存储用户创建的临时表等数据。
- 🚀
Doublewrite Buffer Files:双写缓冲区 ,innoDB引擎将数据页从Buffer Pool刷新到磁盘前,先将数据页写入双写缓冲区文件中,便于系统异常时恢复数据。 (双写缓冲区文件:xxx.dblwr文件)
- 🚀
Redo Log:重做日志 ,是用来实现事务的持久性。该日志文件由两部分组成:重做日志缓冲(redo log buffer) 以及 重做日志文件(redo log file) ,前者是在内存中,后者在磁盘中。当事务提交之后会把所有修改信息都会存到该日志中,用于在刷新脏页到磁盘时,发生错误时,进行数据恢复使用。
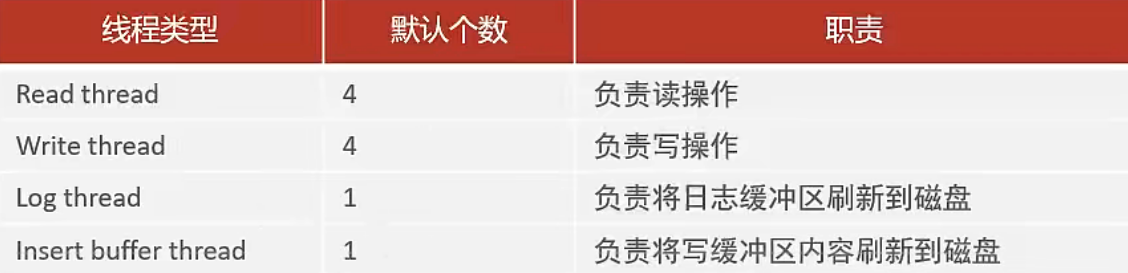
🗜后台线程
后台线程:
- 🚀
Master Thread: -
- 核心后台线程,负责调度其他线程,还负责将缓冲池中的数据异步刷新到磁盘中,保持数据的一致性,还包括脏页的刷新、合并插入缓存、undo页的回收。
- 🚀
IO Thread: -
- 在InnoDB存储引擎中大量使用了AIO(异步非阻塞IO)来处理IO请求,这样可以极大地提高数据库的性能,而IO Thread主要负责这些IO请求的回调。
- 🚀
Purge Thread: -
- 主要用于回收事务已经提交了的undo log,在事务提交之后,undo log可能不用了,就用它来回收。
-
🚀
Page Cleaner Thread: -
- 协助Master Thread刷新脏页到磁盘的线程,它可以减轻Master Thread的工作压力,减少阻塞。
3. 事务的原理
事务:
事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
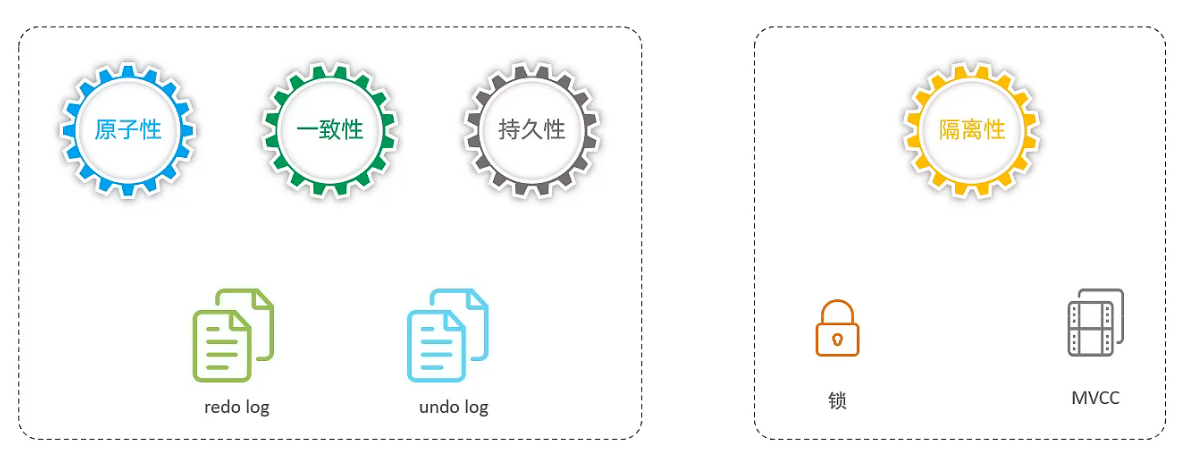
事务四大特性:
- 原子性(Atomicity) 事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性(Consistency) 事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(Isolation) 数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性(Durability) 事务一旦提交或回滚,它对数据库数据的改变就是永久的。
⚪redo log
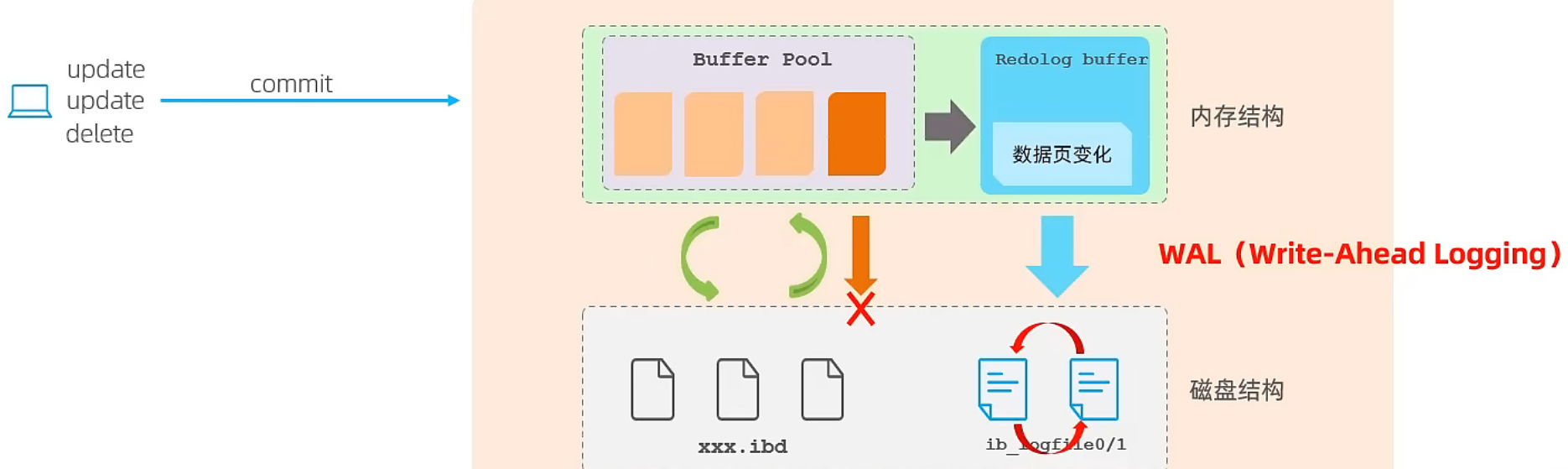
重做日志 - redo log:
重做日志 ,记录的是事务提交时数据页的物理修改,是用来实现事务的持久性 。该日志文件由两部分组成:重做日志缓冲(redo log buffer) 以及 重做日志文件(redo log file) ,前者是在内存中,后者在磁盘中。当事务提交之后会把所有修改信息都会存到该日志中,用于在刷新脏页到磁盘时,发生错误时,进行数据恢复使用。
⚪undo log
回滚日志 - undo log:
回滚日志 ,用于记录数据被修改前的信息,作用包含两个:提供回滚 和 MVCC(多版本并发控制) 。
undo log 和redo log 记录物理日志不一样,undo log 是逻辑日志。可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update 一条记录时,它记录一条对应相反的update记录。当执行rollback时,就可以从undo log中的逻辑记录读取到相应的内容并进行回滚。
Undo log销毁:-
- undo log在事务执行时产生,事务提交时,并不会立即删除undo log,因为这些日志可能还用于MVCC。
Undo log存储:-
- undo log采用段的方式进行管理和记录,存放在前面介绍的rollback segment回滚段中,内部包含1024个undo log segment。
4. MVCC
🐟MVCC基本概念
当前读:
读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。对于我们日常的操作 ,如:
select..lock in share mode(共享锁),select\update\insert\delete..for update(排他锁)都是一种当前读 。
快照读:
简单的select(不加锁)就是快照读,快照读,读取的是记录数据的可见版本,有可能是历史数据,不加锁,是非阻塞读。
- 事务隔离级别:
-
- Read Committed :每次select,都生成一个快照读。
- Repeatable Read :开启事务后第一个select语句才是快照读的地方。
- Serializable :快照读会退化为当前读。
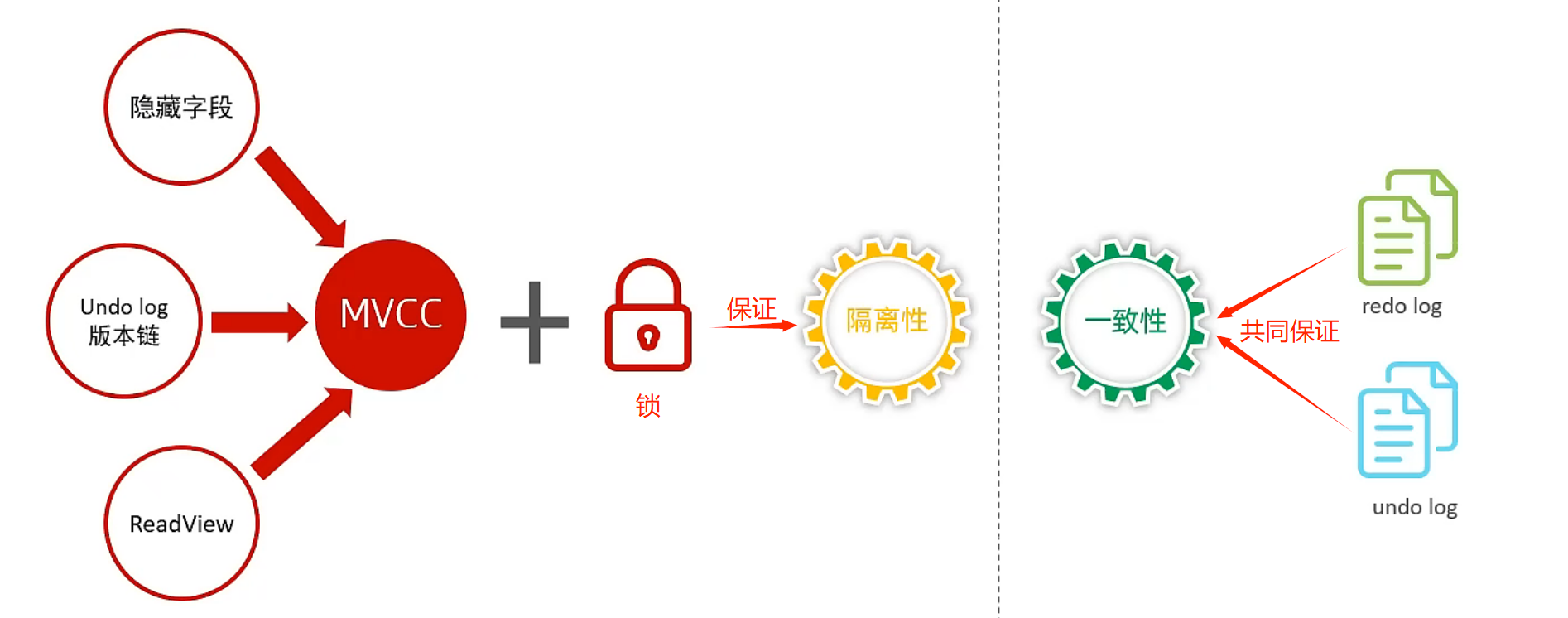
多版本并发控制 - MVCC:
全称Multi--Version Concurrency Control,多版本并发控制 。指维护一个数据的多个版本,使得读写操作没有冲突 ,快照读为MySQL实现MVCC提供了一个非阻塞读功能。MVCC的具体实现,还需要依赖于数据库记录中的:三个隐式字段、undo log日志、readView。
🐟MVCC实现原理
表的隐藏字段:

undo log - 回滚日志:
- 回滚日志 ,在insert、update、delete的时候产生的便于数据回滚的日志 。
- 当insert的时候,产生的undo log日志只在回滚时需要,在事务提交后,可被立即删除 。
- 而update、delete的时候,产生的undo log日志不仅在回滚时需要,在快照读时也需要,不会立即被删除 。
undo log 版本链:-
- 不同事务或相同事务对同一条记录进行修改,会导致该记录的undolog生成一条记录版本链表,链表的头部是最新的旧记录,链表尾部是最早的旧记录。
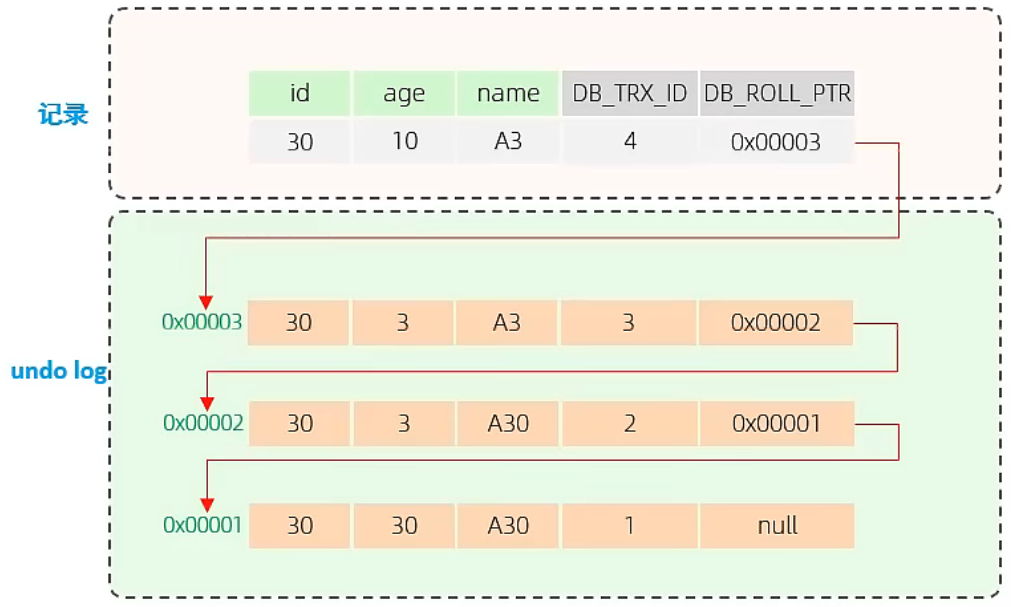
readView - 读视图:
ReadView(读视图)是快照读SQL执行时MVCC提取数据的依据,记录并维护系统当前活跃的事务(未提交的)id。
不同的隔离级别,生成ReadViewl的时机不同:
READ COMMITTED:在事务中每一次执行快照读时生成ReadView。
REPEATABLE READ:仅在事务中第一次执行快照读时生成ReadView,后续复用该ReadView。
- ReadView的4个核心字段:
-










![Ubuntu18.04运行gazebo的launch文件[model-4] process has died报错](https://img-blog.csdnimg.cn/df0c83b7b8284e0286172b8b7147c970.png)