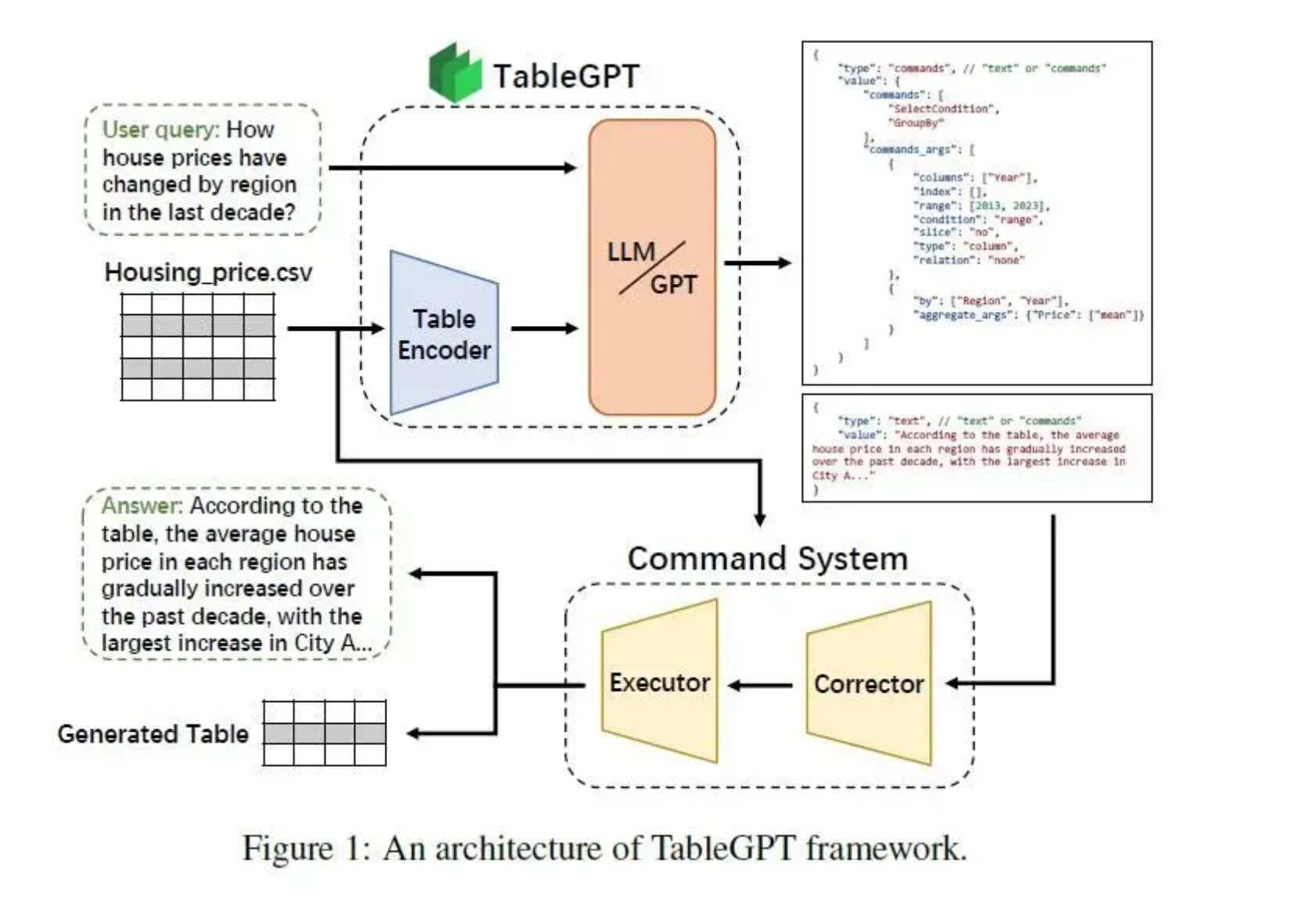
本文根据 2023 云栖大会演讲实录整理而成,演讲信息如下:
演讲人:陈守元 | 阿里云计算平台事业部开源大数据产品总监
演讲主题:阿里云开源大数据产品年度发布
随着云计算的不断发展,未来数据处理和应用的趋势将围绕Cloud Native、Severless和Data+AI展开。其中,云原生架构已成为主流趋势,因为它可以提高数据处理和应用程序的可伸缩性和灵活性,支持大规模部署和更快的响应时间。同时,Serverless作为一种新型计算模式,可以提高处理效率、降低运营成本并减少资源浪费,其独特的特点使得其成为处理大规模数据的理想选择。此外,Data与AI融合正在快速发展,不断提高智能化和自动化程度,同时需要高质量的数据来支撑算法的准确性和有效性。

EMR:面向下一代湖仓和全面Serverless化
下面进入产品发布环节,我们将围绕上面三个点 做哪些事情、有哪些发布更好地服务用户上云 来讲述我们产品的重点发布。

首先,我们来看EMR。EMR 是一个云原生开源大数据平台系统。对于 EMR 而言,线下IDC 大量基于开源 Hadoop生态构建的线下用户搬站上云第一站就会选择EMR,因为改造代价特别地小,几乎可以无缝平迁上云。这对用户来说是具有巨大的人力资本和机器资本的节省。 我们将阿里云EMR 定位为 用户搬站上云的第一站。
今年我们的产品矩阵做了升级,我们希望在云上基于更多样化的 IaaS 提供多样化的 EMR 产品形态。EMR 通用版,核心解决的用户问题就是帮助用户的大数据系统平迁上云,这也是和用户线下部署兼容度最高的方案。第二个是 EMR 容器版,即 EMR ACK 版。现在 IT 基础设施的云原生容器化基本上都深入人心,我们大量客户在云上基于 IT 系统的构建都会选择容器化的平台,例如阿里云的 ACK。用户自然而然会联想到如何把Data 和 AI 的 workload 迁移到IT 基础设施的同一个集群里,完成Data&AI 的负载 与 IT 设施负载混用,EMR 容器版,或者说 EMR onACK 就是帮用户解决这类问题的产品。
最后也是我们今天想强调的重点就是 EMR Serverless 版。对于 EMR Serverless 子产品线而言,内部有些feature 或者功能 在之前云栖中已做了发布。今天对于 EMR Serverless 产品线是一个更加完整的矩阵呈现,今天会重点讲一下 Serverless Spark、Serverless StrarRocks 两大主流 EMR 计算引擎的 Serverless 化,今天也是我们正式对外提出一个完整的 EMR Serverless化的产品线矩阵。
EMR Serverless 版是 EMR 产品线形态中诞生最晚、发布最新的一代产品和技术,其实 EMR 围绕 Serverless 的布局在一年前、两年前都在紧锣密鼓地进行。前面 OSS-HDFS、Serverless HDFS 这一块其实在去年、前年已有发布,但是今年我们做了更多的尝试努力,我们希望把 EMR 上面主流的大数据计算引擎、存储引擎、开发平台、元数据管理全都 Serverless 化,只有这样方才能够更好地满足云原生用户更好地利用大数据。Serverless Spark,更好地解决了湖仓场景下 Data ETL 的处理能力,Serverless StrarRocks 更好地解决了湖仓场景下 Data analytic 能力,Serverless HDFS 更好解决了湖仓场景下数据存储能力,最后 EMR Stutio 帮助用户线下可以平迁体验上云,让用户能够更好使用云上大数据基础设施,同时还能免运维。所以EMR 今年从计算,到存储,到开发环境 几乎全部实现了 EMR 主力引擎和平台都能够做到 Serverless 化,我们希望能够把整个大数据开发运维闭环,从而进一步帮助云原生上的开发者更好地把大数据用起来。

下面仍然回到 EMR 主力场景, EMR通用版,围绕湖仓场景做了大量更新。EMR 主力场景仍然围绕着湖仓处理,围绕在湖仓计算、存储、运维、开发做了大量的更新。在计算层面,我们核心还是降本提效,IaaS 层适配了新的倚天 CPU,PaaS 层做了 Native Spark RunTime,这些都是从 IaaS 层和 PaaS 层更好地帮助用户降本提效。存储部分,Serverless HDFS (同时也称之为 OSS-HDFS) 很早已有发布,但是在这一年希望让Serverless HDFS 和 本地 HDFS 在使用层面给用户体验完全一致,包括 在 文件性能、数据访问、源数据获取等方案 做到几乎完全一致。为上述目标,我们因此做了大量有关系统性能优化 以及 系统安全性优化。我们的 Open 文件性能的提升、DU 访问源数据的提升,这些都是今年的成果。

EMR 运维,这主要体现在两个方面。在云上来说 EMR 能结合到云原生上面给用户创造比较大的平台价值就在于弹性,今年我们做到大量的弹性优化。我们大量客户给我们反馈说 EMR 的平台弹性越来越稳定;另外一个运维重点,即 EMR Doctor,我们希望通过 AI 的方式、自动化、智能化的运维平台方式帮助用户去解决开源大数据运维的问题。从社区开源大数据用户反馈来看,开源大数据使用最大的、最痛的点就是系统运维。如何长期有效地保证我们的业务在云上健康地运行,这是很多用户上云和云下使用开源大数据非常大的痛点,EMR Doctor 就是解决这个问题。EMR 开发,即 EMR Studio,我们希望云原生 Serverless 化托管了我们的开发平台、调度平台,帮助用户从线下的体验完全平迁到云上的一套体验。以上均是 EMR 围绕湖仓场景的重大更新。
最后仍然回到 EMR For AI,我们每个产品都在拥抱积极的变化,这里分为三部分:EMR DataScience、EMR Doctor、EMR+DataWorks 的 Code Pilot。EMR DataScience 是在 EMR 的容器版里面,我们提供了一个新的集群叫 EMR DataScience,里面内置了不少 AI 最流行的组件,包括 Pytorch、TF。我们希望用户在一个平台上既能够处理大数据,同时还能够云原生地处理 AI 的工具,这是 EMR DataScience 帮助用户做的相关工作。EMR Doctor,这个工作前面提到希望用 AI 化、智能化的方式帮助用户实现 AIOps,能够用自动化的手段定位问题、诊断问题、及早发现问题。EMR+Dataworks,今年DataWorks重磅的发布就是 code pilot 的发布,但是那上面作为一个平台实际上底下也对接了 EMR 等等,正好实际上 code pilot 也是平台引擎无关的Feature,可以生成 EMR 里面的 HIVE 代码,用户就可以用 DataWorks 上面开发平台能够通过自然语言生成 MaxCompute 的 SQL,能够操作业务,这样能够极大地减少用户开发代码的成本,这在 DataWorks 对外提供公测的时候欢迎去试用一下。
Flink Streaming Lakehouse:新一代的流式湖仓新方案
下面我们看一下 Flink Streaming Lakehouse。Lakehouse 这个概念其实在前几年很火,原因就是对于一个 Lakehouse 的系统来说,既兼具了 Data Warehouse 的严谨,包括ACID、版本的管理、数据格式的校验等等;同时它还有 Data Lake 的灵活性,能够放很多大量非结构化的文本,包括图片、视频、音频、图像等等。而 Lakehouse 同时能够承载结构化的数据和非结构化的数据,这对用户来说是非常好的 AI 和大数据融合的底层存储方案。但是我们看 Lakehouse 的过程中发现 Lakehouse 在时效性方面有非常大的问题,Flink 核心使命和价值就在帮助我们的客户解决大数据实时化转型和升级。所以Flink 社区 和 我们 一起发布了 Streaming Lakehouse 方案。

回到Streaming Lakehouse 我主要从产品方向 讲三个场景要点。前面已经提到Lakehouse 在 AI 时代下 Lakehouse 的方案会越来越重要,因为它既能存储结构化的数据又能存储非阶段的数据,这个是大数据和 AI 一体化存储的重要承载点。但是 Lakehouse 在实践的过程中仍然遇到时效性的问题,整个 Lakehouse 的 Data Pipeline 串联起来可能达到小时级别的延迟,从最开始的数据进入到数据价值的发挥,比如 BI、AI,能够看到整个数据链路到小时级别,这其实对于用户来说要构建一个实时湖仓面临很大的延迟。所以 Flink 希望一起帮助用户做到 Lakehouse 的实时化,通过流式、实时帮助用户做很大的提升。
最后是 Unified,其实 Flink 社区在前几年一直主打 Unified Batch & Streaming。我们希望在计算层面做到融合,就是流批一体。我们在开源社区推广流批一体的方案时,发现如果用户只是计算层面的融合对于用户只能解决一半的问题。还有一半问题在于存储,存储仍然是两套的存储方案,两套存储和两套数据因此会导致的离线和实时的数据不一致性对于用户来说是非常大的问题,所以 Flink 团队和社区一起构建了 Paimon。Paimon 基于底层的分布式文件系统,比如说 OSS 会构建一个 Unified 的 storage,既可以做流,也可以做批,我们称之为批流一体的存储。所以 Flink+Paimon 构成 Lakehouse 的方案,既具备 Unified 的 process,也可以具备 Unified 的 Storage,这一层合并在一起能够真正完整地帮助用户实现流批一体的解决方案。这是我们 Streaming Lakehouse 的价值点,最终我们希望帮助用户在 Data+AI 时代下提供实时化、流式化和 Serverless 化的湖仓方案。
回到 Flink 主线,我们一直以来的使命就是希望帮助用户做到大数据的升级和转型,所以追求实时场景下的性价比一直是 Flink 团队一直以来努力的方向。追求实时化的性价比今年有两个重要的点,一个是Flink全面拥抱了倚天,结合到倚天 整个实时计算 Flink 综合的性价比有 50%的提升,这是Flink 团队结合IaaS 层面做了大量优化。同时在 PaaS 层 Flink 企业级内核 我们仍然在做大量优化,这其中包括算子的优化,以及未来我们会公布 native runtime 的优化。这部分优化相比于开源Flink引擎,我们实时计算 Flink 版 会有两倍的提升,特别是在吞吐部分可以解决很多用户高吞吐量或者大流量的实时计算场景。

Elasticsearch:Serverless 和 Search for Data & AI
接下来讲一下 Elasticsearch,这也是开源大数据很重要的组成部分。说到 Elasticsearch 可能大家更多仍然停留在比较早期 for data 的 search,就是全文的检索,类似于搜索引擎要做全文的检索。但今天我想告诉大家这个思想需要刷新一下,Elasticsearch 不仅是 for data 的 search,也是 for AI 的 search。我今天给大家重点会讲一下 ES 如何从 Data 转变成 Data+AI 的 search 系统。
第一个是我们的 Elasticsearch 的版本发布。坦白地说,当前产品形态,即 ES on PaaS 的独立集群版本已经非常好地满足我们中国公有云和专有云客户很多的市场需求,不少中大型公司都非常认可阿里云的 ES产品形态,产品客户受众无论在基数以及未来增长都很不错。但实际上随着最近这一两年客户在降本提效上提上了日程之后,发现有一批非常大的潜在客户以及中长尾的客户其实仍然对云上的独立集群版本所带来的成本仍然认为是比较大的上云入门门槛。他们非常希望以低门槛甚至零门槛的方式开启云上的 ES,这就是我们 ES Serverless 要做的初衷,我们希望以一个零门槛的方式能够帮助用户开启云上 Elasticsearch 的使用。

同时 Elasticsearch Serverless 也是我们国内首家支持通用场景的 ES 版本。去年我们也发布了一个 Elasticsearch Serverless版本,但更多解决日志 ELK 场景的需求。但是该版本在数据一致性上会存在问题,所以今年我们进行大量的产品技术架构重构。本次 ES Serverless 的发布是一个面向通用场景的升级发布,这里面不仅支持包括日志场景,还支持订单、金融等等场景,这里面的数据一致性都可以得到很好的保障。这是我们今年发布相比于去年发布升级很不一样的点。针对 ES Serverless 可以真正按量付费、秒级弹性、简单运维,同时可以完全兼容开源的 ES,这是很多其他的厂商不一定能做到的。
下面重点强调 ES for AI 和 Data 的部分,标志着 ES 真正从 Data 面向 Data&AI 的搜索引擎。云栖会场外面有很大的广告栏,主打的是 ESRE 的发布,这是 ES 公司重大的发布。发布的核心简单跟大家说一下,就是支持 AI 相关检索,包括向量检索,包括多路并规的查询优化,这些东西都是在 ES 内核重点打的点,帮助用户做 AI 检索。阿里云ES 围绕着 ES 最新的 AI 能力进行了大量方案集成,就是右边的增强方案。我们跟达摩院 AI 方案做联合,和 PAI—EAS 方案联合,甚至会和社区一起做更多的联合方案,这些方案能够帮助我们的用户更好地在云上用上阿里云、达摩院 AI 的技术,和社区的 ES 更好地结合起来。所以我们希望通过 ES8.9 这个版本能够帮助用户构建下一代面向 Data+AI 的检索系统。

围绕 ES 自研能力的升级,阿里云 ES 是和 ES 公司一起合作,也是基于开源的 ES 做更多的优化孵化,其实是完全基于开源,也是完全兼容开源的,我们做了大量的增强。而这里面做了三个升级,包括场景的升级,也就是日志场景向通用场景的升级和改造。去年 ES 更多是做日志场景、ELK 场景,今年的 ES Serverless 面向通用场景进行完全开放。另外就是有关搜索内核引擎的优化,包括读写分离、存算分离,这些更好地解决集群稳定性问题、成本流控问题、资源弹性的问题。最后我们在购买链路和相关控制台上做了比较大的体验升级,我们非常推荐大家去用一用阿里云 ES Serverless 版本,感受一下完全 Serverless 化的 ES。
Milvus:AI时代的搜索引擎
今天最后一个,也是今年完全新的产品。前面全部是我们现有的功能、现有产品线的叠加,Milvus 这部分是我们今年要发布的 AI 时代新的搜索引擎。目前,在向量检索部分Milvus几乎是全球最火、最亮眼的技术。我们会在12月份开启向量检索 Milvus 版本对外测试,相比于开源的 Milvus 来说会做相应产品企业级的增强。同时在兼容开源的 Milvus 之上,我们还会去结合达摩院的技术能够提供更好的企业级向量检索能力。同时在云上肯定会做大量的产品联合工作,包括和我们的存储上有大量非结构化的数据可供用户检索查询。同时我们会跟 PAI 平台、达摩院 AI 模型做更多的深度集成,做 AI 向量检索能力、做大模型向量支撑,这些方案未来都会在我们的产品之上构建。所以我们最终是希望能够帮助云上使用 Milvus 的用户更快、更方便、更低门槛构建 AI 时代下的搜索系统。

回顾一下我们讲了大数据的三个趋势。Cloud Native,整个 IT 投资都在往云上加速转型。Serverless 化,我们认为未来的 PaaS 平台最终全部都会归到 Serverless 化,所有 AI 产品、大数据产品和其他 PaaS 产品都会归到 Serverless 化。最后是 Data+AI,未来 AI 和大数据会做彻底的融合打通,这也是我们整个开源大数据一直以来在积极围绕这三个点做布局。
最后希望大家多多关注阿里云,关注阿里云的开源大数据,谢谢大家!