目录
- 引言
- 一、链表的介绍
- 二、链表的几种分类
- 三、不带头单链表的一些常用接口
- 3.1 动态申请一个节点
- 3.2 尾插数据
- 3.3 头插数据
- 3.4 尾删数据
- 3.5 头删数据
- 3.6 查找数据
- 3.7 pos位置后插入数据
- 3.8 删除pos位置数据
- 3.9 释放空间
- 四、带头双向链表的常见接口
- 4.1创建头节点(初始化)
- 4.2pos位置前插入
- 4.3删除pos位置数据
- 4.4其他
- 五、总结
引言
上篇博客已经介绍了顺序表的实现:【数据结构】详解顺序表。最后在里面也谈及了顺序表结构的缺陷,即效率低,空间浪费等等问题,那么为了解决这些问题,于是乎我们引入了链表的概念,下面将对链表结构进行讲解
一、链表的介绍
首先肯定会问,到底什么是链表?链表的概念:链表是一种物理存储结构上非连续,非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
在结构上其与火车的结构相似,分为一个个节点,再将每个节点连接起来,就形成了一个链表,其大致结构如下:
但还要几点需要注意:
- 链式结构在逻辑上是连续的,但在物理空间上不一定是连续的;
- 这些节点一般是在堆上申请出来的,即使用
malloc函数来动态申请空间;- 每当需要增加一个数据时,便可申请一段空间,空间可能连续也可能不连续。

二、链表的几种分类
链表的结构大致可以分为8类,即:带头/不带头单向链表,带头/不带头双向链表,带头/不带头单向循环链表,带头/不带头双向循环链表。 今天我所介绍的是其中最简单的结构和最复杂的结构:
- 单向不带头不循环链表:
单向不带头不循环链表结构简单,但实现起来并不简单且复杂度高,所以一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。- 双向带头循环链表:
带头双向循环链表结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。表面上看这结构十分的复杂,但在后面实现函数时会发现这种结构会带来很多优势,实现起来反而更简单了,复杂度也大大降低。


三、不带头单链表的一些常用接口
定义如下结构体,表示链表的一个节点:
typedef int SLDataType;
typedef struct SlistNode
{
SLDataType val;//所需保存的数据
struct SListNode* next;//结构体指针,指向下一个节点的地址
}SLNode;
3.1 动态申请一个节点
为了使链表在各个函数中都可以使用,所以我们需要动态开辟内存来创建节点,再通过指针将他们相连接。在
CreatNode()函数中我们创建节点并将他们初始化:
//动态申请节点
SLNode* CreatNode(SLTDateType x)
{
SLNode* newnode = (SLNode*)malloc(sizeof(SLNode));
//检测
if(newnode == NULL)
{
perror("CreatNode()::malloc");
return;
}
newnode->val = x;
newnode->next = NULL;
return newnode;
}
3.2 尾插数据
根据一般逻辑,我们想要尾插那就要先创建新节点并找到尾节点。那么我们定义指针
tail,然后利用循环找尾节点再链接新节点tail->next = newnode,另外还要额外判断链表为空的情况,此情况直接尾插即可,具体如下:
//尾插
void SLPushBack(SLNode** pplist, SLDateType x)
{
SLNode* newnode = CreatNode(x);
if (*pplist == NULL)
{
*pplist = newnode;
}
else
{
//找尾
SLNode* tail = *pplist;
while (tail->next != NULL)
{
tail = tail->next;
}
//链接
tail->next = newnode;
}
}
3.3 头插数据
头插就比较简单了,只需要注意一点:不额外定义变量时,要先将新节点链到链表,即
newnode->next = *pplist,然后再改头节点,即*pplist = newnode,如下:
void SLPushFront(SLNode** pplist, SLDateType x)
{
assert(pplist);
SLNode* newnode = CreatNode(x);
newnode->next = *pplist;
*pplist = newnode;
}
3.4 尾删数据
同样想要尾删,那就必须先找到尾节点,然后释放空间。但释放完空间后,上一个节点的
next仍然指向释放空间的地址,这就可能造成越界访问,野指针问题。所以我们还需要记录尾节点的上一个节点tailPrev,然后通过这个指针将此节点next置为NULL。此外还需用assert()检测链表不为NULL,分类讨论链表只有一个节点和有多个节点的情况。如下:
//尾删
void SLPopBack(SLNode** pplist)
{
assert(pplist && *pplist);
SLNode* tailPrev = NULL;
SLNode* tail = *pplist;
// 1.只有一个节点
if (tail->next == NULL)
{
free(tail);
*pplist = NULL;
}
// 2.两个及以上的节点
else
{
//找尾及上一个节点
while (tail->next)
{
tailPrev = tail;
tail = tail->next;
}
free(tail);
tail = NULL;
tailPrev->next = NULL;
}
}
3.5 头删数据
头删数据时,链表同样不能为空,另外头删无需判断链表节点数问题,这就比较容易实现了:
void SLPopFront(SLNode** pplist)
{
//不为空
assert(pplist && *pplist);
//记录第一个节点
SLNode* first= *pplist;
*pplist = (*pplist)->next;
free(first);
}
3.6 查找数据
给定一个
val,再链表中向后寻找,找到时返回此节点地址pos,未找到返回NULL。我们只需定义一个结构体指针SLNode* cur = plist;,让他向后走,找到val时返回cur,直到cur = NULL时循环结束并返回NULL。因为这里无需改变链表指向,所以可以直接传一级指针。
SLNode* SLFind(SLNode* plist, SLDateType x)
{
SLNode* cur = plist;
while (cur)
{
//寻找val
if (cur->val == x)
return cur;
cur = cur->next;
}
return NULL;
}
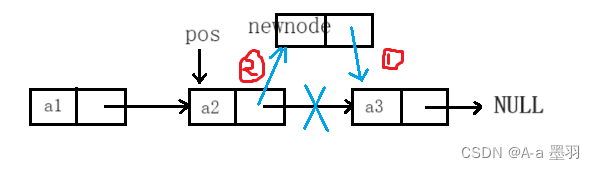
3.7 pos位置后插入数据
如下图,先创建一个节点
newnode,然后将newnode->next指向pos位置的下一个节点,最后将pos->next指向新节点。
当然pos != NULL。
//指定位置插入
void SLInsertAfter(SLNode* pos, SLDataType x)
{
assert(pos);
SLNode* newnode = CreatNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
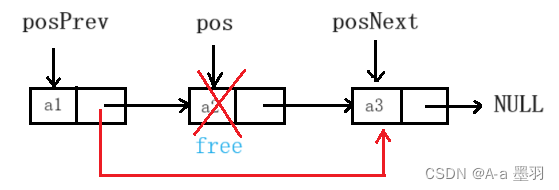
3.8 删除pos位置数据
先通过循环找到
pos前一个节点地址posPrev,和后一个节点地址posNext,然后释放pos节点,链接posPrev和posNext。
同样pos != NULL,还有一点是当pos为头节点,就相当于头删,但无需判断,同样适用。
void SLErase(SLNode* pos, SLNode** pplist)
{
assert(pos && pplist);
SLNode* posPrev = *pplist, *posNext = pos->next, *cur = *pplist;
//找pos前一个节点
while(cur != pos)
{
posPrev = cur;
cur = cur->next;
}
//链接
posPrev->next = posNext;
free(pos);
}
3.9 释放空间
因为这是一个链式结构,且每个节点是
malloc动态开辟的,所以最后要将所以节点释放,否则会造成内存泄漏问题。只需定义一个结构体指针SLNode* cur = *pplist,让他向后依次释放节点,直到cur = NULL。
void SLDestroy(SLNode** pplist)
{
assert(pplist);
SLNode* cur = *pplist;
while(cur)
{
//记录下一个节点
SLNode* next = cur->next;
free(cur);
cur = next;
}
}
四、带头双向链表的常见接口
通过上面对单向不循环链表的介绍,我们不难发现其实单链表的尾插,尾删和指定位置删除其实效率是不高的,时间复杂度为
O(n)。而双向带头循环链表是不存在这个问题的,且因为链表带头节点的原因,在函数传参是无需用到二级指针,在实现函数时也会发现很多时候也不需要单独判断链表没节点的情况,因为头节点本身就是一个节点,这也大大降低了代码的难度。
双向带头循环链表的每个节点都包含两个指针:一个指向上一个节点,一个指向下一个节点。那么便可这样设计节点:
typedef int DataType;
//节点设计
typedef struct DListNode
{
DataType val;
struct DListNode* _prev;//指向上一个节点的指针
struct DListNode* _next;//指向下一个节点的指针
}DLNode;
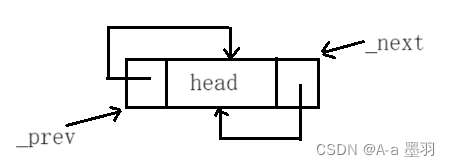
4.1创建头节点(初始化)
头节点和其他节点的结构是相同的,就相当于链表自带一个节点,并将此节点初始化成以下格式:
DLNode* InitDLNode(DLNode* phead)
{
//创建
DLNode* head = (DLNode*)malloc(sizeof(DLNode));
if (head == NULL)
{
perror("InitDLNode()::malloc");
return;
}
//形成循环结构
head->_prev = head;
head->_next = head;
head->val = -1;
return head;
}
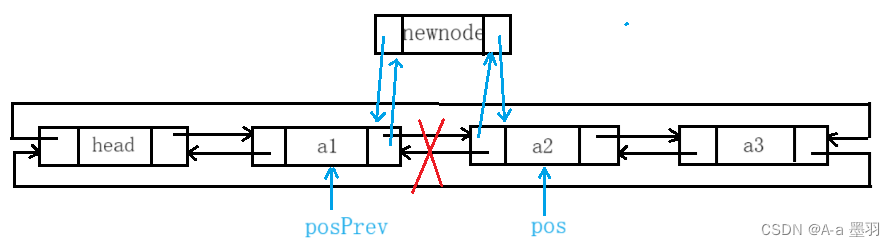
4.2pos位置前插入
对于
pos位置之前插入,可以先通过pos->_prev找到前一个节点的地址,然后再进行插入操作。因为是双向循环链表的原因,找pos前一个节点也不需要循环,时间复杂度只有O(1)。
事实上当链表无有效节点(即只有头节点)也不需要单独判断,这样降低了代码难度,具体实现代码如下:
//指定位置插入
void DLNodeInsert(DLNode* pos, DataType x)
{
assert(pos);
DLNode* posPrev = pos->_prev;//pos前一个节点
DLNode* newnode = CreatNode(x);//创建新节点
//链接
posPrev->_next = newnode;
newnode->_prev = posPrev;
pos->_prev = newnode;
newnode->_next = pos;
}
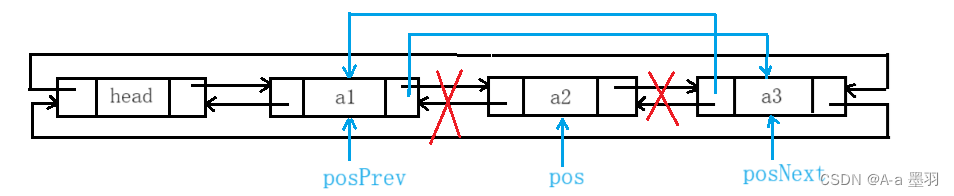
4.3删除pos位置数据
删除
pos位置的数据,我们可以通过pos->_prev找到上一个节点的地址,再通过pos->_next找到下一个节点的地址。然后将这两个节点链接起来,并释放pos节点,如下:
当只有一个头节点时我们还需额外判断一下,代码如下:
void DLNodeErase(DLNode* pos)
{
assert(pos);
assert(pos->_next != pos);//不能为头节点
DLNode* posPrev = pos->_prev, * posNext = pos->_next;
//链接
posPrev->_next = posNext;
posNext->_prev = posPrev;
free(pos);
}
4.4其他
还有头删/插,尾删/插这四个函数,但这四个函数并不需要额外实现,因为:
头插/删可以当作pos = phead->_next的指定位置插入/删除,尾删也可以当作pos = phead->_prev的指定位置删除,尾插则是pos = phead的位置。头/尾删这两个pos分别代表头节点的后一个和前一个,且判断assert(phead != phead->_next)也是必要的,这里就不代码实现了。
五、总结
对比于顺序表我们发现链表有很多优点,也有一些缺点:
优点:
- 链表的空间浪费较小,按需开辟空间;
- 任意位置插入和删除数据效率更高,实现了
O(1)时间复杂度;缺点:
- 不支持随机访问数据(致命缺陷);
- 每个节点还要存储链接下一个节点的指针,这也会造成一点空间浪费;