文章目录
- 循环神经网络的从零开始实现
- 1. 独热编码
- 2. 初始化模型参数
- 3. 循环神经网络模型
- 4. 预测
- 5. 梯度裁剪
- 6. 训练
循环神经网络的从零开始实现
从头开始基于循环神经网络实现字符级语言模型。
# 读取数据集
%matplotlib inline
import math
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
1. 独热编码
每个词元都有一个对应的索引,表示为特征向量,即每个索引映射为相互不同的单位向量。
词元表不同词元个数为N,词元索引范围为0到N-1。词元的索引为整数,那么将创建一个长度为N的全0向量,并将第i处元素设置为1。则此向量是原始词元的一个独热编码。
假如有2个词元"cat"和"dog"
- "cat"对应:[1, 0]
- "dog"对应:[0, 1]
索引为0和2的独热向量
# 索引为0和2的独热向量
F.one_hot(torch.tensor([0, 2]), len(vocab))
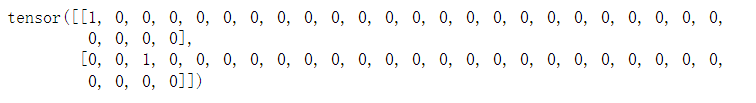
采样的小批量数据形状为二维张量:(批量大小,时间步数),one_hot函数将其转换为三维张量:(时间步数,批量大小,词表大小)
# 采样的小批量数据形状为二维张量:(批量大小,时间步数)
# one_hot函数将其转换为三维张量:(时间步数,批量大小,词表大小)
# 方便我们通过最外层维度,一步一步更新小批量数据的隐状态
X = torch.arange(10).reshape((2, 5))
print(F.one_hot(X.T, 28).shape)
# 显示第一行
F.one_hot(X.T, 28)[0,:,:]

2. 初始化模型参数
隐藏单元数num_hiddens是一个可调的超参数
训练语言模型时,输入和输出来自相同的词表,具有相同的维度即词表大小
"""
初始化模型参数:
1、隐藏层参数
2、输出层参数
3、附加梯度
"""
# (词表大小,隐藏层数,设备)
def get_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
# 定义函数normal(),初始化模型的参数
def normal(shape):
return torch.randn(size=shape, device=device) * 0.01
# 隐藏层参数
W_xh = normal((num_inputs, num_hiddens))
W_hh = normal((num_hiddens, num_hiddens))
b_h = torch.zeros(num_hiddens, device=device)
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
3. 循环神经网络模型
定义init_rnn_state函数在初始化时返回隐状态,该函数的返回是一个张量,张量全用0填充,形状为(批量大小,隐藏单元数)。
# 定义init_rnn_state函数在初始化时返回隐状态
# 该函数的返回是一个张量,张量全用0填充,形状为(批量大小,隐藏单元数)
def init_rnn_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), )

循环神经网络通过最外层的维度实现循环,以便时间步更新小批量数据的隐状态H
# 循环神经网络通过最外层的维度实现循环,以便时间步更新小批量数据的隐状态H
def rnn(inputs, state, params):
# inputs的形状:(时间步数量,批量大小,词表大小)
W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
# X的形状:(批量大小,词表大小)
for X in inputs:
# 激活函数tanh,更新隐状态H
H = torch.tanh(torch.mm(X, W_xh) + torch.mm(H, W_hh) + b_h)
Y = torch.mm(H, W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
创建一个类来包装这些函数, 并存储从零开始实现的循环神经网络模型的参数
"""
从零开始实现的循环神经网络模型:
1、定义网络模型的参数
2、对词表进行独热编码
3、初始化模型参数并返回隐状态
"""
class RNNModelScratch: #@save
"""从零开始实现的循环神经网络模型"""
# 定义类的初始化,将传入的参数赋值给对象的属性,以便后续使用
def __init__(self, vocab_size, num_hiddens, device,
get_params, init_state, forward_fn):
self.vocab_size, self.num_hiddens = vocab_size, num_hiddens
self.params = get_params(vocab_size, num_hiddens, device)
self.init_state, self.forward_fn = init_state, forward_fn
def __call__(self, X, state):
# 对输入进行独热编码,返回状态及参数
X = F.one_hot(X.T, self.vocab_size).type(torch.float32)
return self.forward_fn(X, state, self.params)
def begin_state(self, batch_size, device):
# 初始化参数
return self.init_state(batch_size, self.num_hiddens, device)
检查输出是否具有正确的形状。 例如,隐状态的维数是否保持不变。
num_hiddens = 512
# 网络模型
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,
init_rnn_state, rnn)
# 获得网络初始状态
state = net.begin_state(X.shape[0], d2l.try_gpu())
# 将X移到GPU上,并且返回输出Y和状态
Y, new_state = net(X.to(d2l.try_gpu()), state)
Y.shape, len(new_state), new_state[0].shape
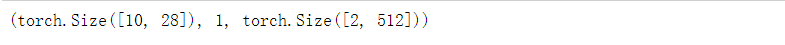
可以看到输出形状是(时间步数x批量大小,词表大小), 而隐状态形状保持不变,即(批量大小,隐藏单元数)。
4. 预测
定义预测函数
"""
定义预测函数:
1、prefix是用户提供的字符串;
2、循环遍历prefix的开始字符时不输出,不断将隐状态传递给下一个时间步;
3、在此期间模型进行自我更新(隐状态),不进行预测;
4、2和3步骤称为预热期,预热期过后隐状态的值更适合预测,从而预测字符并输出。
"""
# prefix:前缀字符串
def predict_ch8(prefix, num_preds, net, vocab, device): #@save
"""在prefix后面生成新字符"""
state = net.begin_state(batch_size=1, device=device)
outputs = [vocab[prefix[0]]]
# 匿名函数:改变输出的形状
get_input = lambda: torch.tensor([outputs[-1]], device=device).reshape((1, 1))
# 预热期:不进行输出
for y in prefix[1:]: # 预热期
_, state = net(get_input(), state)
outputs.append(vocab[y])
# 预热期过了之后,进行预测
for _ in range(num_preds): # 预测num_preds步
y, state = net(get_input(), state)
outputs.append(int(y.argmax(dim=1).reshape(1)))
return ''.join([vocab.idx_to_token[i] for i in outputs])
测试predict_ch8函数。 我们将前缀指定为time traveller, 并基于这个前缀生成10个后续字符
# 测试predict_ch8函数。 我们将前缀指定为time traveller, 并基于这个前缀生成10个后续字符。
# 未训练模型,输出预测结果没有联系
predict_ch8('time traveller ', 10, net, vocab, d2l.try_gpu())

5. 梯度裁剪
为什么要梯度裁剪:
1、对于长度为T的序列,我们在迭代中计算T个时间步上的梯度,在反向传播过程中产生长度为T的矩阵乘法链;
2、T较大时,会导致数值不稳定,例如梯度消失或者梯度爆炸。
一个流行的替代方案是通过将梯度g投影回给定半径 (例如θ)的球来裁剪梯度g。

def grad_clipping(net, theta): #@save
"""裁剪梯度"""
if isinstance(net, nn.Module):
# 附加梯度的参数
params = [p for p in net.parameters() if p.requires_grad]
else:
# 梯度的范数:对应图里作为分母的"||g||"
params = net.params
norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))
# 如果梯度过大,将其限制到θ
if norm > theta:
for param in params:
param.grad[:] *= theta / norm
6. 训练
在一个迭代周期内训练模型:
1、序列数据的不同采样方法(随机采样和顺序分区)将导致状态初始化的差异;
2、在更新模型参数之前裁剪梯度,这样可以保证训练过程中如果某点发生梯度爆炸,模型也不会发散;
3、用困惑度评价模型,使得不同长度的序列也有了可比性。
- 顺序分区:只在每个迭代周期的开始位置初始化隐状态。
- 随机抽样:每个样本都是在一个随机位置抽样的,因此需要在每个迭代周期重新初始化隐状态。
#@save
"""
训练网络一个迭代周期:
1、初始化状态,将数据传到GPU上
2、计算损失,进行梯度裁剪并更新模型参数
"""
def train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter):
"""训练网络一个迭代周期(定义见第8章)"""
# 状态,时间
state, timer = None, d2l.Timer()
metric = d2l.Accumulator(2) # 训练损失之和,词元数量
for X, Y in train_iter:
if state is None or use_random_iter:
# 在第一次迭代或使用随机抽样时初始化state
state = net.begin_state(batch_size=X.shape[0], device=device)
else:
if isinstance(net, nn.Module) and not isinstance(state, tuple):
# state对于nn.GRU是个张量
# detach_()将张量从计算图中分离出来,不会影响到原始张量
state.detach_()
else:
# state对于nn.LSTM或对于我们从零开始实现的模型是个张量
for s in state:
s.detach_()
# 将Y 进行转置并展平成一维向量
y = Y.T.reshape(-1)
# 将X,y移动到设备上,并且输入到模型中
X, y = X.to(device), y.to(device)
y_hat, state = net(X, state)
l = loss(y_hat, y.long()).mean()
# 如果更新器 updater 是 torch.optim.Optimizer 类型,则调用 updater.step() 方法进行参数更新;
# 否则调用 updater(batch_size=1) 进行参数更新。
if isinstance(updater, torch.optim.Optimizer):
updater.zero_grad() # 梯度置零
l.backward() # 反向传播,知道如何调整参数以最小化损失函数
grad_clipping(net, 1) # 梯度裁剪
updater.step() # 使用优化器来更新参数
else:
l.backward()
grad_clipping(net, 1)
# 因为已经调用了mean函数
updater(batch_size=1)
# y.numel()计算y中元素数量
metric.add(l * y.numel(), y.numel())
# 使用指数损失函数计算累积平均困惑度 math.exp(metric[0] / metric[1]) 和训练速度 metric[1] / timer.stop()。
return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()
- updater.zero_grad(): 这一行代码将模型参数的梯度置零,以便在每次迭代中计算新的梯度。
- l.backward(): 这一行代码使用反向传播算法计算损失函数对模型参数的梯度。通过计算梯度,我们可以知道如何调整模型参数以最小化损失函数。
- grad_clipping(net, 1): 这一行代码对模型的梯度进行裁剪,以防止梯度爆炸的问题。梯度爆炸可能会导致训练不稳定,裁剪梯度可以限制梯度的范围。
- updater.step(): 这一行代码使用优化器(如SGD、Adam等)来更新模型的参数。优化器根据计算得到的梯度和预定义的学习率来更新模型参数,以使模型更好地拟合训练数据。
循环神经网络的训练函数也支持高级API实现
# 循环神经网络的训练函数也支持高级API实现
#@save
def train_ch8(net, train_iter, vocab, lr, num_epochs, device,
use_random_iter=False):
"""训练模型(定义见第8章)"""
loss = nn.CrossEntropyLoss()
# 动画窗口:窗口显示一个图例,图例名称为 "train",x 轴的范围从 10 到 num_epochs
animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',
legend=['train'], xlim=[10, num_epochs])
# 初始化
if isinstance(net, nn.Module):
updater = torch.optim.SGD(net.parameters(), lr)
else:
updater = lambda batch_size: d2l.sgd(net.params, lr, batch_size)
predict = lambda prefix: predict_ch8(prefix, 50, net, vocab, device)
# 训练和预测
for epoch in range(num_epochs):
ppl, speed = train_epoch_ch8(
net, train_iter, loss, updater, device, use_random_iter)
# 每10个epoch,对输入字符串进行预测,并将预测结果添加到动画中
if (epoch + 1) % 10 == 0:
print(predict('time traveller'))
animator.add(epoch + 1, [ppl])
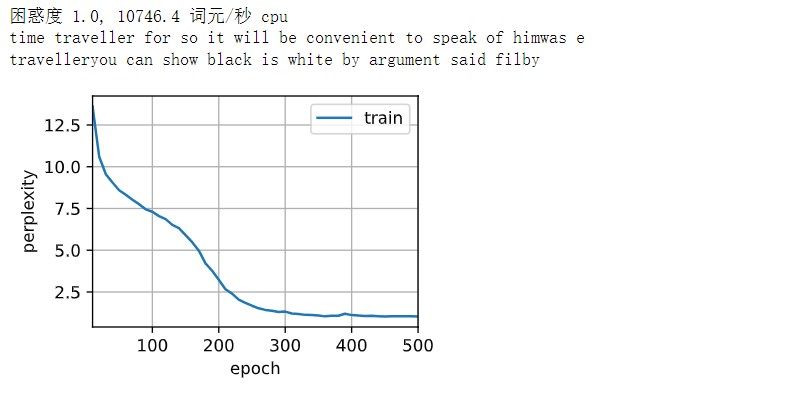
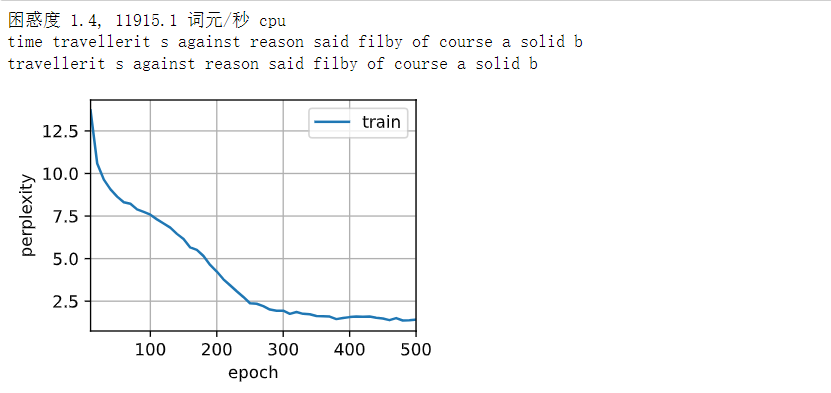
print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')
print(predict('time traveller'))
print(predict('traveller'))
在数据集中只使用了10000个词元, 所以模型需要更多的迭代周期来更好地收敛
# 在数据集中只使用了10000个词元, 所以模型需要更多的迭代周期来更好地收敛
num_epochs, lr = 500, 1
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu())
检查一下随机抽样方法的结果
# 检查一下随机抽样方法的结果
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,
init_rnn_state, rnn)
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu(),
use_random_iter=True)





![[C国演义] 第二十一章](https://img-blog.csdnimg.cn/890cbfc2fc244fe8afd95745dca4f7b3.png)