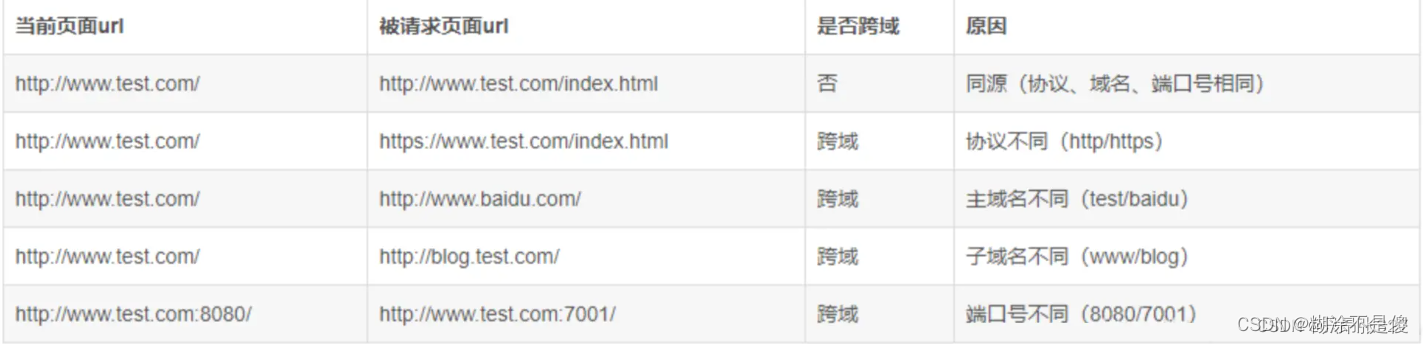
hello everybody,本期是安卓逆向so层魔改md5教学,干货满满,可以细细品味,重点介绍的是so层魔改md5的处理.
常见的魔改md5有:
1:明文加密前处理 2:改初始化魔数 3:改k表中的值 4:改循环左移的次数 本期遇到的是124.且循环左移的次数是动态的,需要前面的加密结果处理生成
目录
首先介绍md5的实现
说明:
登陆抓包:
sign的加密
总结:
首先介绍md5的实现
1首先对明文16进制编码,比如我的名字 杨如画 会被编码成 e6 9d a8 e5 a6 82 e7 94 bb
2把明文填充到448bit(比如e6是两个16进制字符,也就是一个字节,8bit),填充方式是先填充一个80,接着一直填充00 00 00直到448bit,
填充成这样e6 9d a8 e5 a6 82 e7 94 bb 80 00 00 00...(56个字节,448bit)
3附加消息长度,需要填充8个字节,也就是e6 9d a8 e5 a6 82 e7 94 bb的长度9个字节,72位,长度就是72,转成16进制就是48,理论上填充的长度为48 也就是
00 00 00 00 00 00 00 48,但是md5处理的时候需要把这8个字节转为小端序,什么是小端续呢?你可以上网查,我简单说一下这里的小端序就是把这8个字节,注意是以字节为单位把最后一个放到第一个,倒数第二个放到第二个,以此类推,最终结果是48 00 00 00 00 00 00 00. md5的输入长度是无限长的,如果64bit位放不下,也就是长度大于2的64次方的话,会取低64bit,也是按照小端序来取的. 此外sha3算法也是明文无限长,其他hash算法不是.
4最终明文处理成e6 9d a8 e5 a6 82 e7 94 bb 80 00 00 00...48 00 00 00 00 00 00 00,一共512bit,如果输入的数据刚好为448bit,那么就需要填充512bit,再加上附加消息长度64bit,一共1024bit,因为md5的分组长度为512bit,所以需要进行分组处理
至于k表和初始化魔数和循环左移我们待会再说,先对md5的明文处理有一个概念,注意这很重要,后续需要用到.
概念介绍完了,我们来实战吧
说明:
设备: pixel4 XL android10
抓包:charles配合socksdroid
下载地址:aHR0cHM6Ly93d3cud2FuZG91amlhLmNvbS9hcHBzLzMwNjM5OS9oaXN0b3J5X3YzNjA=
frida版本:16.0.1
此版本是旧版本,新版本算法并没有改,流程也大致差不多,复杂的话可以frida trace,后续也会介绍到,事实上这也是我为了逆这个算法现学的,介绍一下背景,我是学了frida rpc接触到了这个app,当时逆登陆的时候有个sign,当时用的是rpc,因为rpc需要开着手机,我想着能不能逆向出完整的算法呢?这期间遇到了非常大的挑战,因为很多frida的api我也不太熟悉,我也是现学现用,后续会一一介绍,整个魔改md5耗时3天.
登陆抓包:
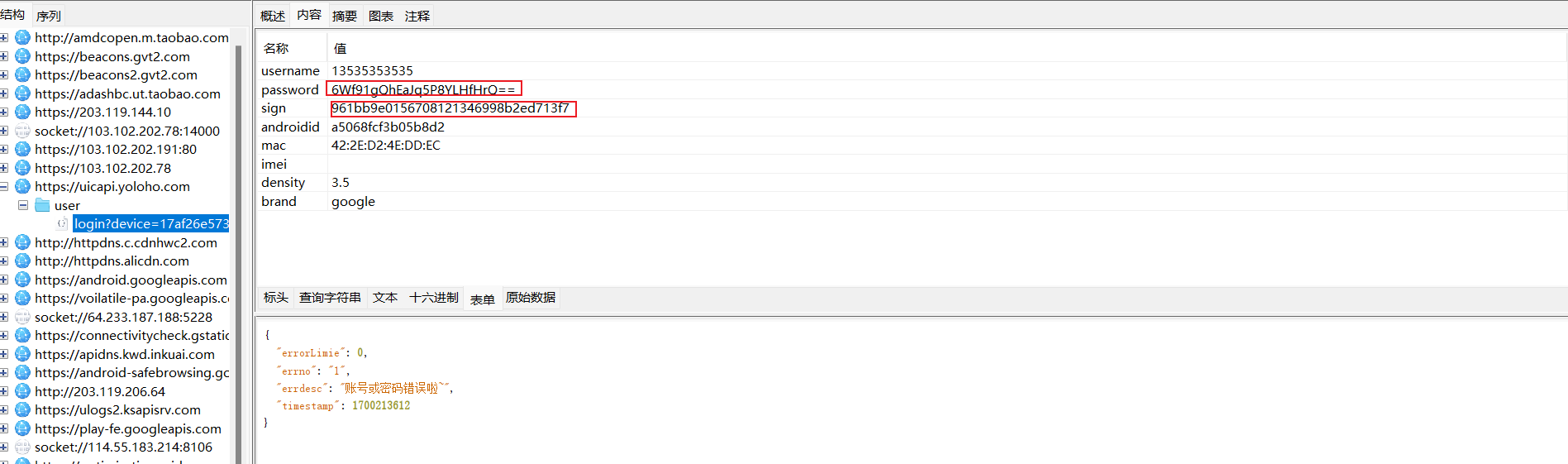
1 查询参数没什么特别的,重点看表单,username是手机号,密码加密了,还有一个用作验签的sign,这个sign的作用我之前说过很多次了,他是用来验签的,通常是把查询参数或者表单中的参数除sign之外的其他值拼接起来加密,防止数据包被恶意篡改,当然也不是不能篡改,把这个sign逆了不就行了吗
2 password的我就不说了,在java层,我直接给出代码吧 定位可以搜字符串,hook java层系统函数等等
# 128位密钥
_str = hashlib.md5('16751641924'.encode('utf-8')).hexdigest()
key = _str[0:16].encode('utf-8')
# 128位IV(Initialization Vector)
iv = 'yoloho_dayima!%_'.encode('utf-8')
# 明文
plaintext = "1472580369Xx" # 不能超过31个字符
# 加密
cipher = AES.new(key, AES.MODE_CBC, iv)
padded_data = pad(plaintext.encode(), AES.block_size)
ciphertext = cipher.encrypt(padded_data)
# 将密文以Base64格式输出
password = base64.b64encode(ciphertext).decode()
print(password)sign的加密
3 定位我也不说了,搜字符串,hook什么hashmap,hashset,stringbuilder之类的你都试试吧,总能找到的,我就贴下面了

4 hook encrypt_data这个native函数,返回的就是sign,直接右键复制为frida片段
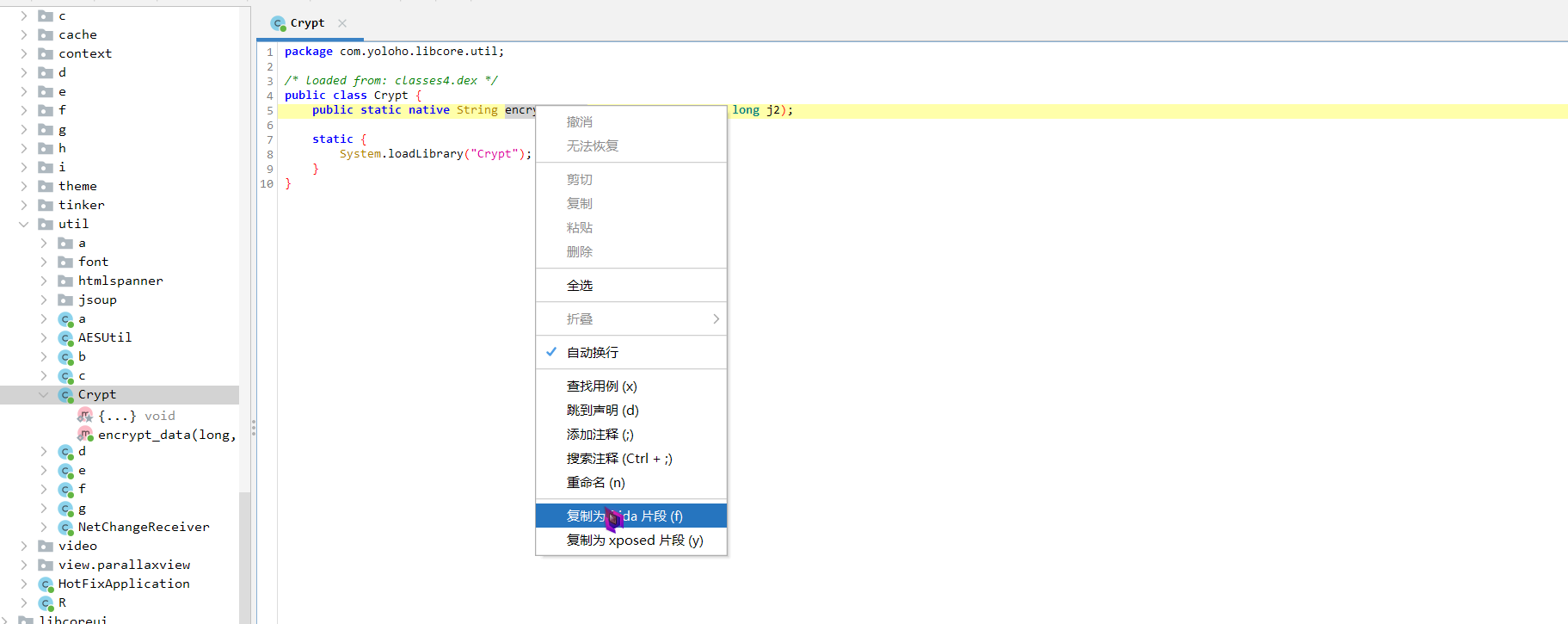
5 有java的api 要包在Java.perform里
Java.perform(function (){
let Crypt = Java.use("com.yoloho.libcore.util.Crypt");
Crypt["encrypt_data"].implementation = function (j, str, j2) {
console.log(`Crypt.encrypt_data is called: j=${j}, str=${str}, j2=${j2}`);
let result = this["encrypt_data"](j, str, j2);
console.log(`Crypt.encrypt_data result=${result}`);
return result;
};
})6 配合着抓包,点击一下登陆,发现加密的结果与抓包中一样,那铁定是这里了

7 接下来为了避免一直手点登陆,可以进行java层主动调用
function call(){
Java.perform(function (){
let Crypt = Java.use("com.yoloho.libcore.util.Crypt");
var res = Crypt["encrypt_data"](0, '23eedd78b2b95ef16b82da4fe2177bdcb1920dd6user/login16751641924oKc0ZztEbNCIcDKL3hoF/A==', 85)
console.log(res);
})
}8 我建议你采用我这个主动调用,这样最终加密出来的结果会和我的一样,方便你调试

9 接下来我们把libCrypt.so拖到ida32中反编译,Crypt名字在上面的java代码中出现了,只有32位的所以拖到ida32中
10 反编译后搜一下java发现是静态注册,这里名字叫encrypt_1data是因为进行了符号修饰
 11 这里直接点进去看内部逻辑
11 这里直接点进去看内部逻辑
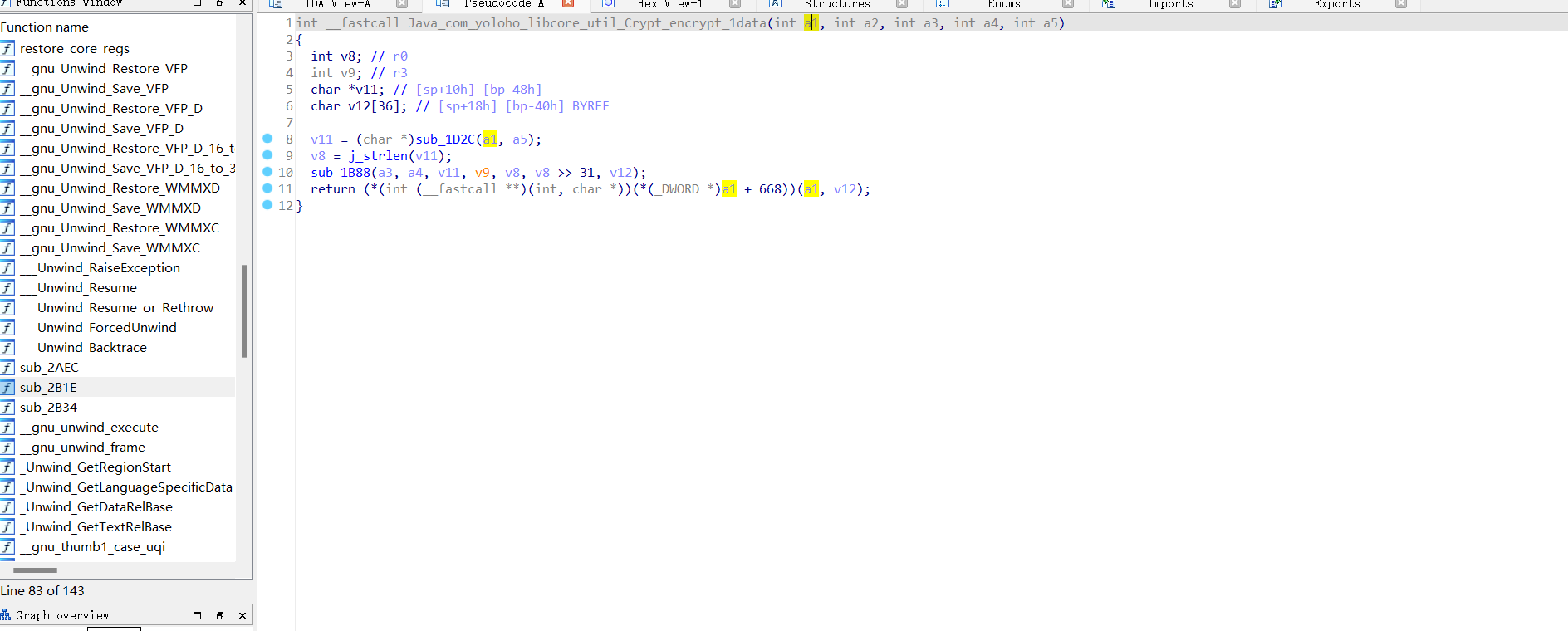
12 转换一下JNIEnv对象,ida7.5以后可以不用导头文件,直接改类型
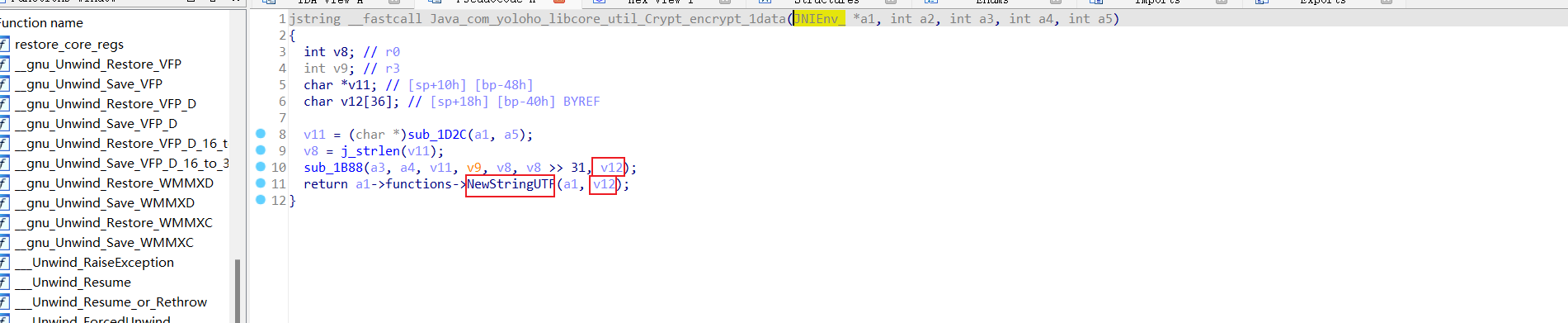
13 看到NewStringUTF,第一个参数是JNIEnv,第二个参数是CString,这里是把CString转为JString再返回给java层,所以最终加密的结果就是v12
14 这里可以hook 1B88这个函数,这种没有名字的通常后面就是偏移量,不放心的话可以点进去看看,加上so基值就可以得到函数内存地址了,这是arm指令的,如果是thubm指令的就得+1,如果你不会看arm还是thumb指令就看so是32还是64,32的一般是thumb,64的一般是arm指令
15 接下来hook sub_1B88这个函数,这是修改过后的,一开始你不知道哪些是地址就把所有参数打印一遍,是地址再dump,因为你dump数字的话是会报错的
var soAddr = Module.findBaseAddress("libCrypt.so");
var funcAddr = soAddr.add(0x1B88+1) //32位+1
Interceptor.attach(funcAddr,{
onEnter: function(args){
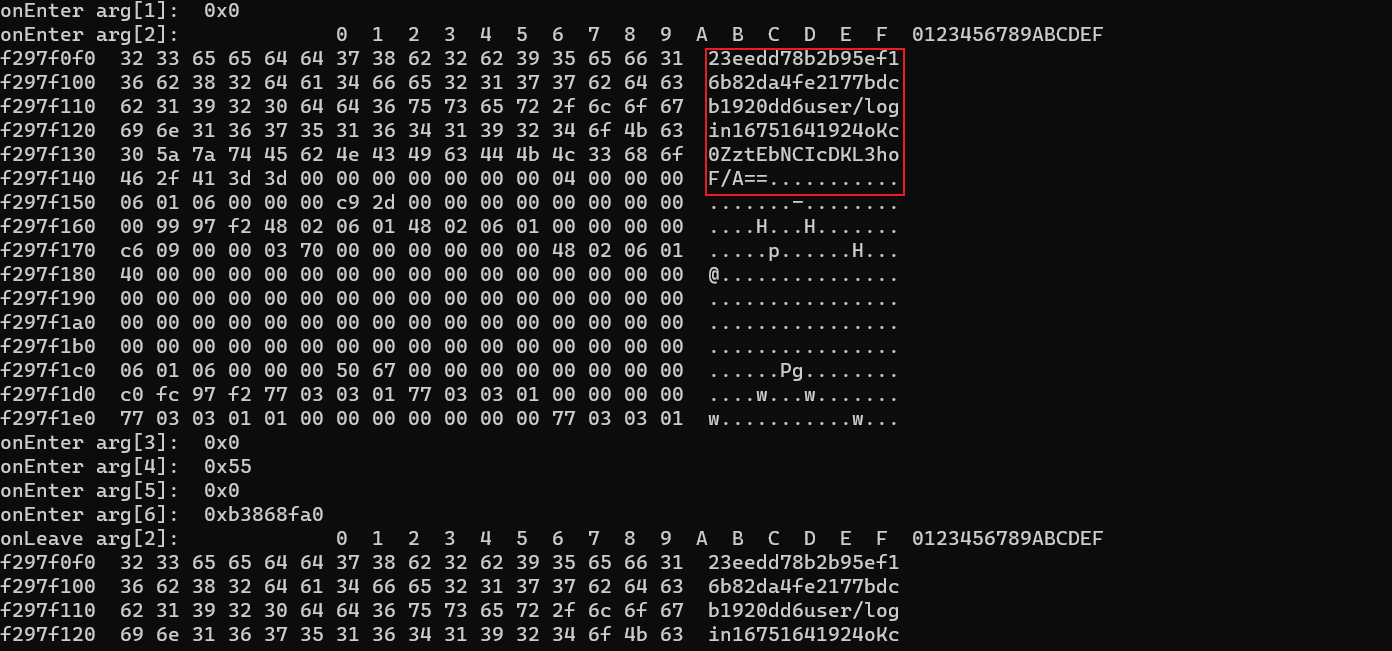
console.log('onEnter arg[0]: ',args[0])
console.log('onEnter arg[1]: ',args[1])
console.log('onEnter arg[2]: ',hexdump(args[2]))
console.log('onEnter arg[3]: ',args[3])
console.log('onEnter arg[4]: ',args[4])
console.log('onEnter arg[5]: ',args[5])
console.log('onEnter arg[6]: ',args[6])
this.arg2 = args[2]
this.arg6 = args[6]
},
onLeave: function(retval){
console.log('onLeave arg[2]: ',hexdump(this.arg2))
console.log('onLeave arg[6]: ',hexdump(this.arg6))
console.log('onLeave result: ',retval)
}
});16这里开着两个hook脚本,java层主动调用,分析so的结果,后面这张图我就不贴了,就是java层的主动调用
17 我们可以看到结果在arg6中,也就是第7个参数,证明结果确实来自v12
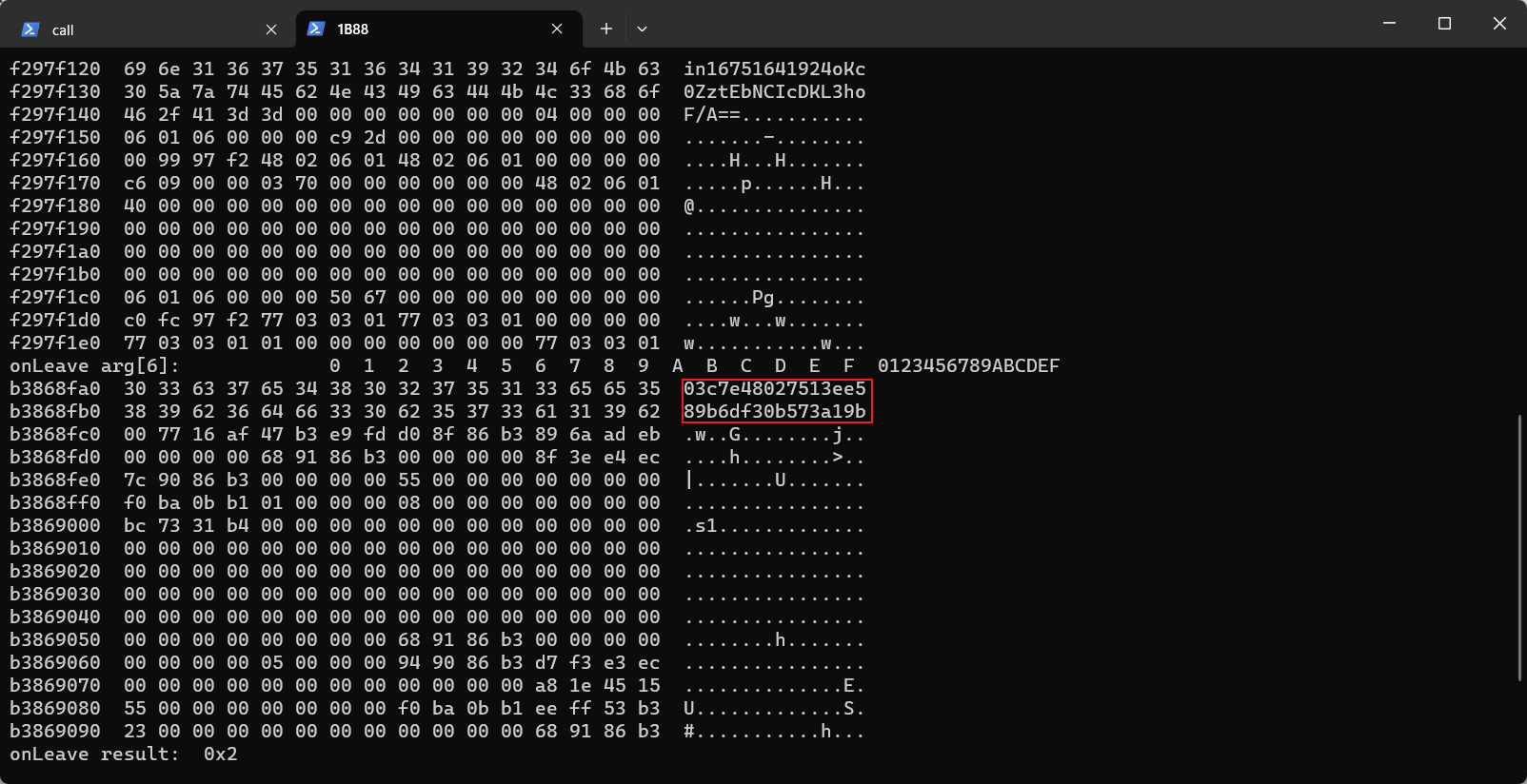
18 而arg2就是我们从java层传进的第二个明文参数,只有这个是重要的,其他不重要的就不要输出,影响判断
19 接下来我们从1B88点进去看看,点进去后发现这里面调用了很多函数,我是把这些函数都hook了一般,但是感觉很乱,有好几个函数被调用了好几次,有的函数内部有if判断还有嵌套函数,极大影响我们的思路,这里可以使用frida trace工具来帮我们分析调用流程

20 frida trace是github上的一个工具,可以自行去下载解压后放到ida的plugis目录下,重启ida
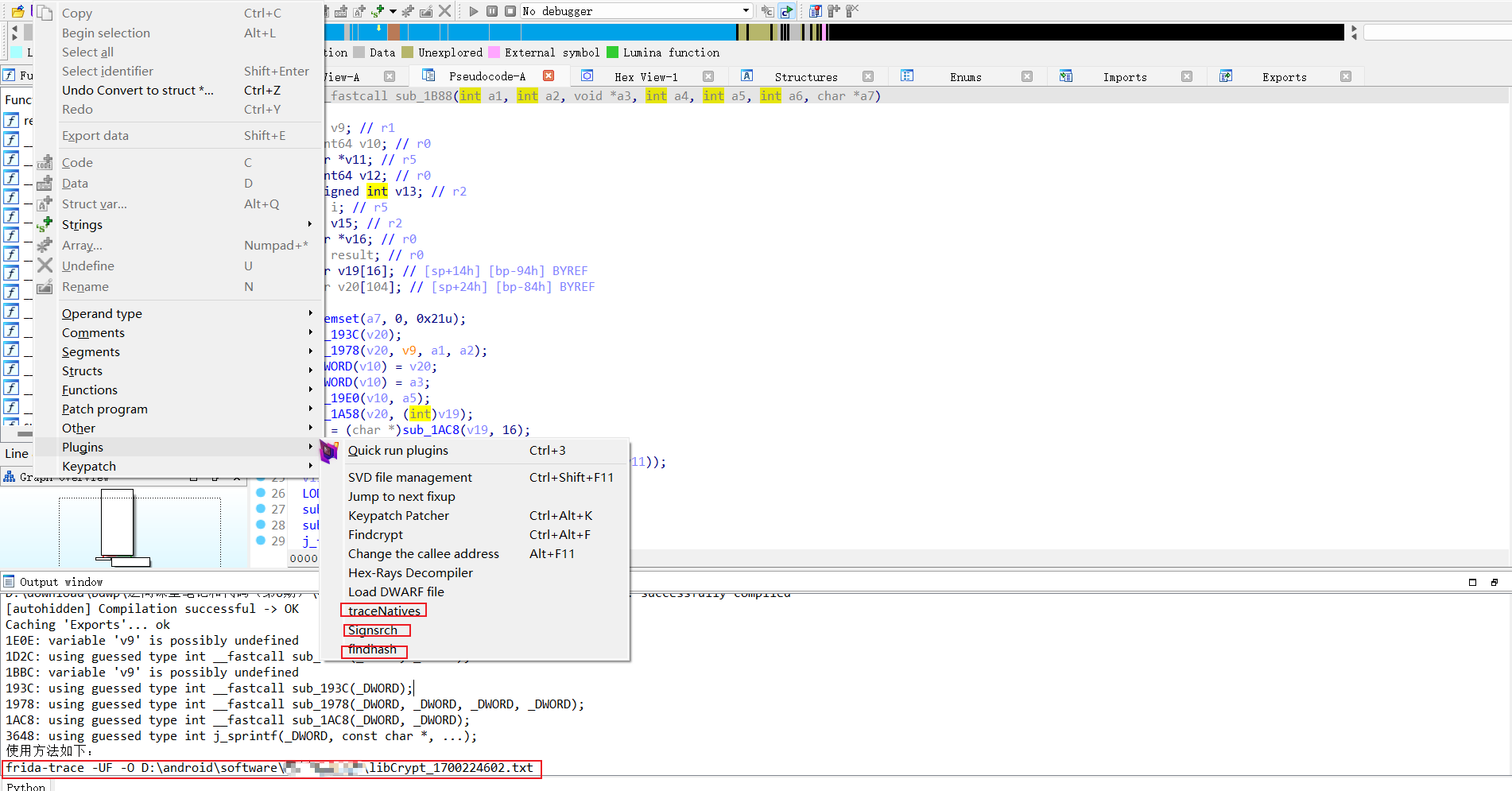
21 这里还有几个好用的ida插件signsrch,findhash,可以识别一些加密特征来判断是什么加密. 这里直接点一下traceNatives会生成一条命令,终端执行一下

22 接下来主动调用一下java层的函数,它会给我们打印函数调用流程,这样就清晰多了,这里的函数地址默认都加了1,因为这个so是thumb指令的

23 我们上面分析到1B88,后面的函数你可以一一hook,到这里我感觉写的内容有点多了,我怕你们没耐心看完,所以就不带你们一个一个函数hook了![]()

24 这个sub1105就是魔改的md5算法
25 最终会加密3次md5,每一次md5都是魔改的,共同的魔改是这里传进去的都是md5 update的字节,而且这个字节你实现的话必须要魔改原本的md5算法.除此以外,第一次还魔改了循环左移,第二次还魔改了初始化魔数和循环左移,并且初始化魔数并不是固定的,而是由第一次加密的md5结果处理生成的,第三次加密的字节需要由第二次加密的结果提供,也就是说,最终的加密结果需要依靠前两次加密的
26 说完了这些我们直接开始hook,下面的代码是简化后的,略去了无效的输出,方便阅读
var soAddr = Module.findBaseAddress("libCrypt.so");
var funcAddr = soAddr.add(0x1104+1) //32位+1
var num = 0
Interceptor.attach(funcAddr,{
onEnter: function(args){
num+=1
console.log(`===============${num}============================`)
console.log('onEnter arg[0]: ',hexdump(args[0]))
console.log('onEnter arg[1]: ',hexdump(args[1]))
console.log('onEnter arg[2]: ',hexdump(args[2]))
this.arg1 = args[1]
},
onLeave: function(retval){
console.log('onLeave arg[1]: ',hexdump(this.arg1))
}
});
27 这里我结合ida中的代码分析a1和a2,a3是什么
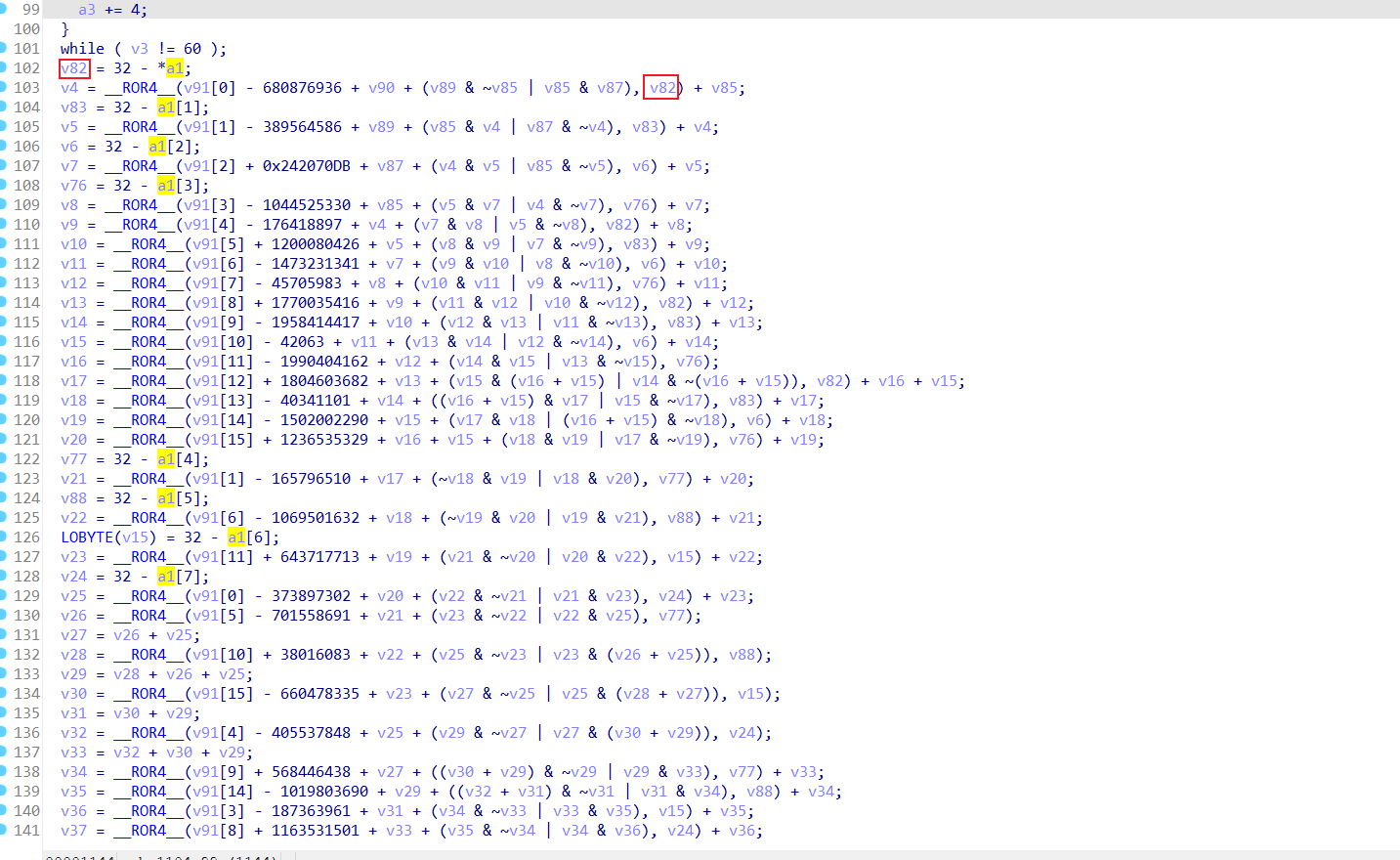
28 选中a1,发现它一直在被32减去它的一个值并赋值给另一个值,而复制的值参与了64轮加密

29 这里我们把减号改成加号再转hex,接着对比着c++中的md5可以发现k值并没有被魔改,7,12,17,22是循环左移的次数,并且他是交替着的,我们发现下图中的v82 v83 v6 v76也是交替着的,这也就意味着a1就是循环左移的次数,循环左移你们可以上网搜索了解一下, 4个字节32位,它一直要被32减去的原因可能是他在循环右移,因为32字节的数左移一个数相当于右移32减去这个数
30我们来看看传进去的3个a1参数长啥样
31 第一组
32 第二组
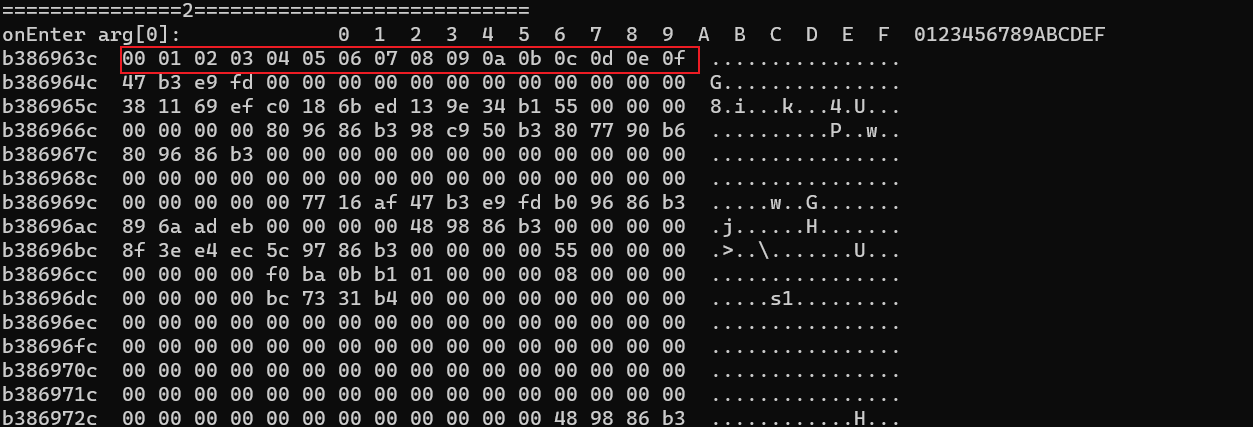 33 第三组,07 0c 11 16十进制也就是07 12 17 22,这不就是循环左移的次数吗,对比了下剩下的,发现第三个加密循环左移是标准的
33 第三组,07 0c 11 16十进制也就是07 12 17 22,这不就是循环左移的次数吗,对比了下剩下的,发现第三个加密循环左移是标准的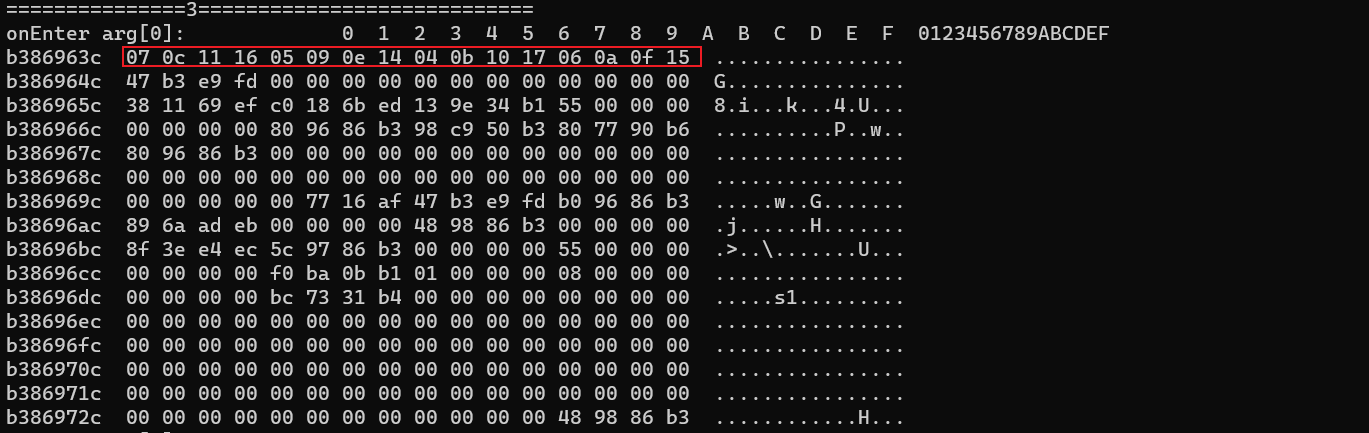
34 如果你分不清是so层是循环左移还是右移那你可以拿这16个字节和被32减去的数值分别进行加密,如果其他地方没有被魔改,那么一定有一个是对的
好了,接下来看a2参数,看到01 23 45 67 89 ab cd ef fe dc ba 98 76 54 32 10 这组数据你就应该想到md5加密的4组初始化魔数
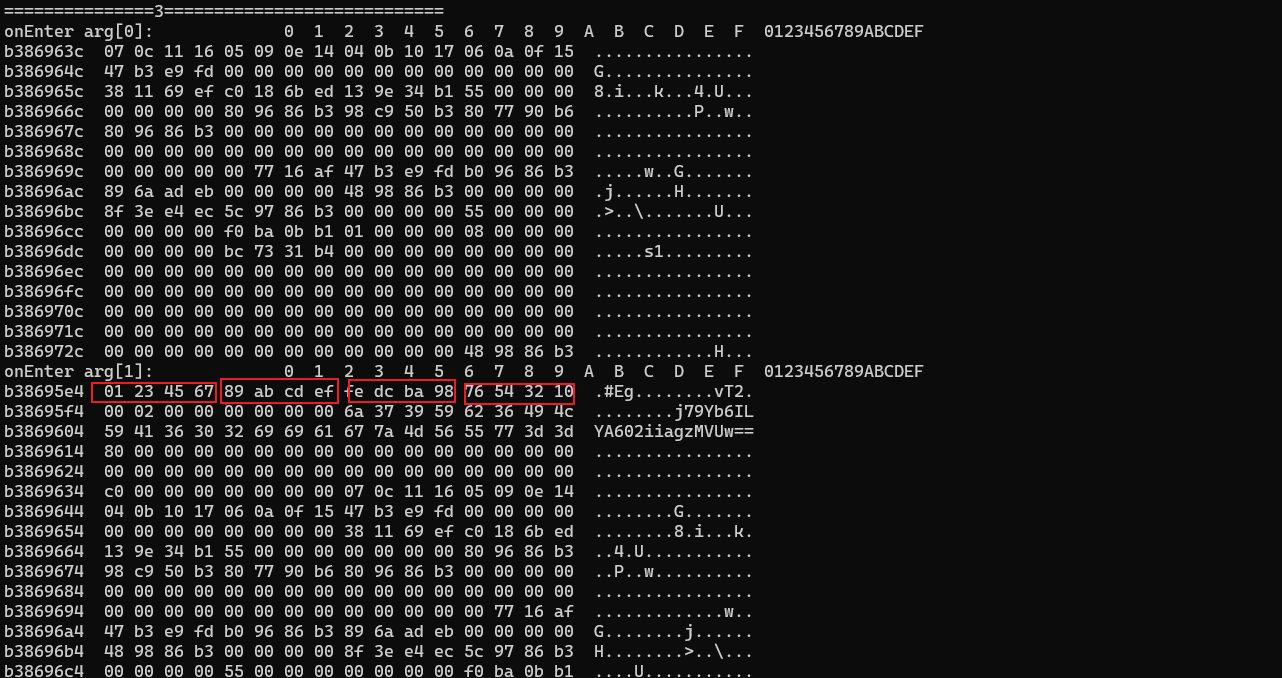
35 对比着C++中的md5,注意这里同样是以4个字节进行小端序排列

36 从so中的取值中也能判断出来

37 参数3是md5明文updata后的字节,注意这是被填充过的,从终端可以看出
38 接下来分析3个魔改加密的实现,我喜欢从后往前推

39 把看似明文的东西md5以下,发现结果是正确的,但你千万不要觉得传进去的是明文,我上面圈了80 00 ...和c0 00 00 00 00 00 00 00,还记得前面介绍的填充和附加消息长度吗,就是这两个,所以传进去的是updata的字节!我前后强调很多遍了!!!

40 那么接下来就应该分析j79Yb6ILYA602iiagzMVUw==是哪来的 你不用想也知道这肯定是第二次的加密结果某种形式变化的
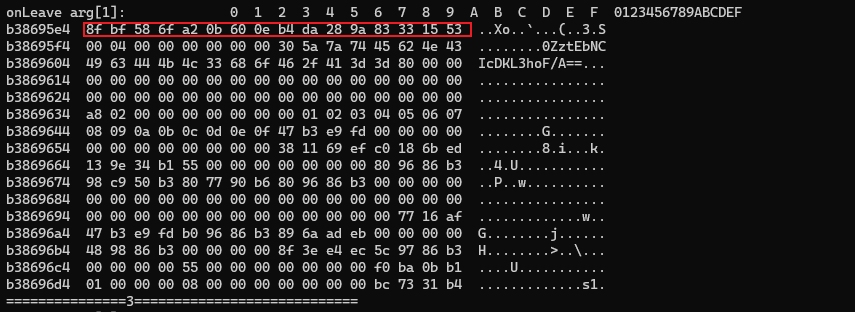
41 也就是说8f bf 58 6f a2 0b 60 0e b4 da 28 9a 83 33 15 53怎么变成j79Yb6ILYA602iiagzMVUw==的
42 大胆猜测一下,第二次加密和第三次加密前不是进行了一堆函数操作吗,当然只有部分函数做了处理,还有一些加密的准备工作

43 这里我就大胆猜测
44 j79Yb6ILYA602iiagzMVUw==看着像base64,把它from base64一下看看
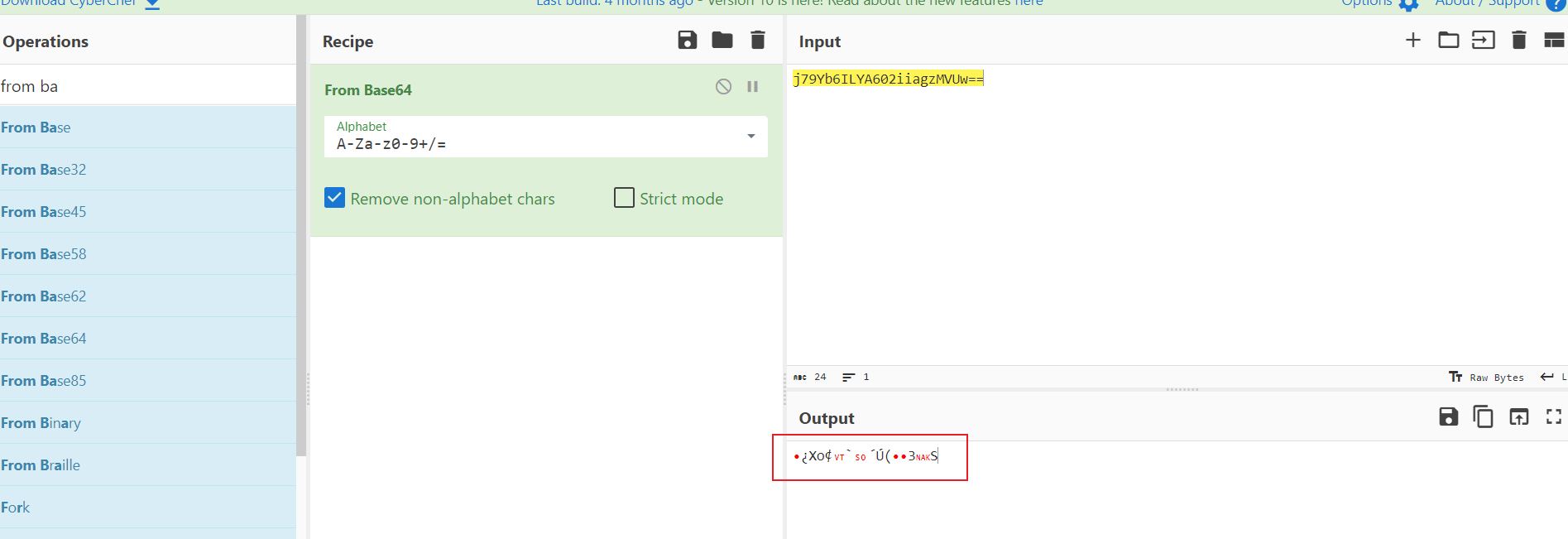
45 啥,乱码?别急,转16进制看看,上面的 8f bf 58 6f a2 0b 60 0e b4 da 28 9a 83 33 15 53不就是16进制的吗,你猜怎么着?
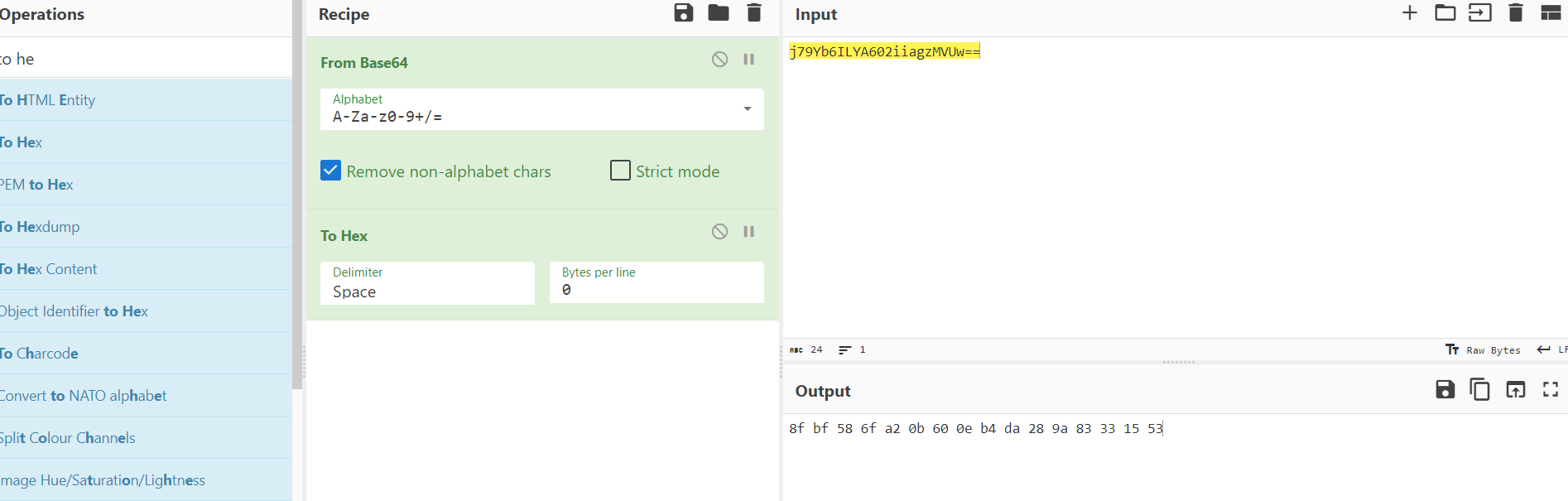
46 结果很显然了, 8f bf 58 6f a2 0b 60 0e b4 da 28 9a 83 33 15 53from hex 后to base64就是j79Yb6ILYA602iiagzMVUw==
47 所以接下来就清晰了,分析第二次加密
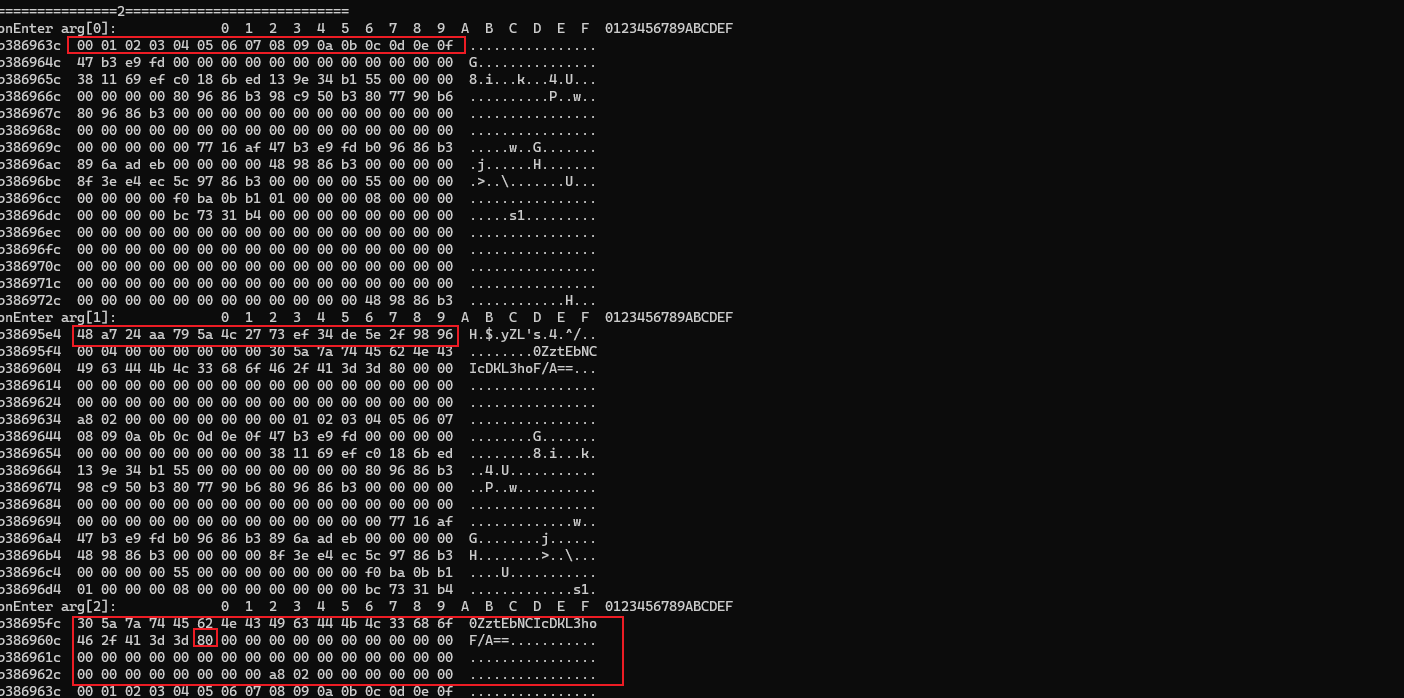
48 明文是0ZztEbNCIcDKL3hoF/A==,这是我们主动调用的加密字符串的一部分,那另一部分呢,等等,另一部分是64字节,512bit,这不就是md5的分组长度吗

49 我们再来看看第一次加密的参数,正是我们所说的前512bit
50 也就是说so把23eedd78b2b95ef16b82da4fe2177bdcb1920dd6user/login16751641924oKc0ZztEbNCIcDKL3hoF/A==,这整个字符串进行updata和填充到1024bit,因为md5处理的字节必须是512的整数倍,并分了两组,第一组由第一次加密得到,得到的结果做为第二次加密的初始化魔数传入,并加密第二组的512bit得到第三次加密的16进制参数
51好像是这样,那怎么验证呢,因为这两次md5传入的字节都不是完整的,相当于让我把一个字符串update得到的两组512bit拆开加密,这该如何是好啊?
52 所以这就需要你对md5的加密流程足够了解,你才能去改md5的源代码来达到上面所说的效果,那我们先来看第一组加密的吧
53 这两次加密的循环左移都需要改,这里我提前改了
/* Round 1 */
FF(a, b, c, d, x[0], 0, 0xd76aa478); /* 1 */
FF(d, a, b, c, x[1], 1, 0xe8c7b756); /* 2 */
FF(c, d, a, b, x[2], 2, 0x242070db); /* 3 */
FF(b, c, d, a, x[3], 3, 0xc1bdceee); /* 4 */
FF(a, b, c, d, x[4], 0, 0xf57c0faf); /* 5 */
FF(d, a, b, c, x[5], 1, 0x4787c62a); /* 6 */
FF(c, d, a, b, x[6], 2, 0xa8304613); /* 7 */
FF(b, c, d, a, x[7], 3, 0xfd469501); /* 8 */
FF(a, b, c, d, x[8], 0, 0x698098d8); /* 9 */
FF(d, a, b, c, x[9], 1, 0x8b44f7af); /* 10 */
FF(c, d, a, b, x[10], 2, 0xffff5bb1); /* 11 */
FF(b, c, d, a, x[11], 3, 0x895cd7be); /* 12 */
FF(a, b, c, d, x[12], 0, 0x6b901122); /* 13 */
FF(d, a, b, c, x[13], 1, 0xfd987193); /* 14 */
FF(c, d, a, b, x[14], 2, 0xa679438e); /* 15 */
FF(b, c, d, a, x[15], 3, 0x49b40821); /* 16 */
/* Round 2 */
GG(a, b, c, d, x[1], 4, 0xf61e2562); /* 17 */
GG(d, a, b, c, x[6], 5, 0xc040b340); /* 18 */
GG(c, d, a, b, x[11], 6, 0x265e5a51); /* 19 */
GG(b, c, d, a, x[0], 7, 0xe9b6c7aa); /* 20 */
GG(a, b, c, d, x[5], 4, 0xd62f105d); /* 21 */
GG(d, a, b, c, x[10], 5, 0x2441453); /* 22 */
GG(c, d, a, b, x[15], 6, 0xd8a1e681); /* 23 */
GG(b, c, d, a, x[4], 7, 0xe7d3fbc8); /* 24 */
GG(a, b, c, d, x[9], 4, 0x21e1cde6); /* 25 */
GG(d, a, b, c, x[14], 5, 0xc33707d6); /* 26 */
GG(c, d, a, b, x[3], 6, 0xf4d50d87); /* 27 */
GG(b, c, d, a, x[8], 7, 0x455a14ed); /* 28 */
GG(a, b, c, d, x[13], 4, 0xa9e3e905); /* 29 */
GG(d, a, b, c, x[2], 5, 0xfcefa3f8); /* 30 */
GG(c, d, a, b, x[7], 6, 0x676f02d9); /* 31 */
GG(b, c, d, a, x[12], 7, 0x8d2a4c8a); /* 32 */
/* Round 3 */
HH(a, b, c, d, x[5], 8, 0xfffa3942); /* 33 */
HH(d, a, b, c, x[8], 9, 0x8771f681); /* 34 */
HH(c, d, a, b, x[11], 10, 0x6d9d6122); /* 35 */
HH(b, c, d, a, x[14], 11, 0xfde5380c); /* 36 */
HH(a, b, c, d, x[1], 8, 0xa4beea44); /* 37 */
HH(d, a, b, c, x[4], 9, 0x4bdecfa9); /* 38 */
HH(c, d, a, b, x[7], 10, 0xf6bb4b60); /* 39 */
HH(b, c, d, a, x[10], 11, 0xbebfbc70); /* 40 */
HH(a, b, c, d, x[13], 8, 0x289b7ec6); /* 41 */
HH(d, a, b, c, x[0], 9, 0xeaa127fa); /* 42 */
HH(c, d, a, b, x[3], 10, 0xd4ef3085); /* 43 */
HH(b, c, d, a, x[6], 11, 0x4881d05); /* 44 */
HH(a, b, c, d, x[9], 8, 0xd9d4d039); /* 45 */
HH(d, a, b, c, x[12], 9, 0xe6db99e5); /* 46 */
HH(c, d, a, b, x[15], 10, 0x1fa27cf8); /* 47 */
HH(b, c, d, a, x[2], 11, 0xc4ac5665); /* 48 */
/* Round 4 */
II(a, b, c, d, x[0], 12, 0xf4292244); /* 49 */
II(d, a, b, c, x[7], 13, 0x432aff97); /* 50 */
II(c, d, a, b, x[14], 14, 0xab9423a7); /* 51 */
II(b, c, d, a, x[5], 15, 0xfc93a039); /* 52 */
II(a, b, c, d, x[12], 12, 0x655b59c3); /* 53 */
II(d, a, b, c, x[3], 13, 0x8f0ccc92); /* 54 */
II(c, d, a, b, x[10], 14, 0xffeff47d); /* 55 */
II(b, c, d, a, x[1], 15, 0x85845dd1); /* 56 */
II(a, b, c, d, x[8], 12, 0x6fa87e4f); /* 57 */
II(d, a, b, c, x[15], 13, 0xfe2ce6e0); /* 58 */
II(c, d, a, b, x[6], 14, 0xa3014314); /* 59 */
II(b, c, d, a, x[13], 15, 0x4e0811a1); /* 60 */
II(a, b, c, d, x[4], 12, 0xf7537e82); /* 61 */
II(d, a, b, c, x[11], 13, 0xbd3af235); /* 62 */
II(c, d, a, b, x[2], 14, 0x2ad7d2bb); /* 63 */
II(b, c, d, a, x[9], 15, 0xeb86d391); /* 64 */
54 接下来我们需要做的事是把明文传的23eedd78b2b95ef16b82da4fe2177bdcb1920dd6user/login16751641924oKc,最终MD5Encode的时候压入的字节和下图一样即可

55 怎么操作呢,我直接说结论了,由于传参刚好是512bit,所以只需要把填充和附加消息长度的地方注释即可
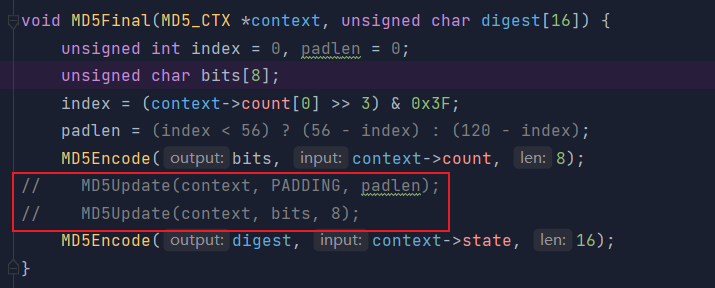
56 最终结果也是成功得到了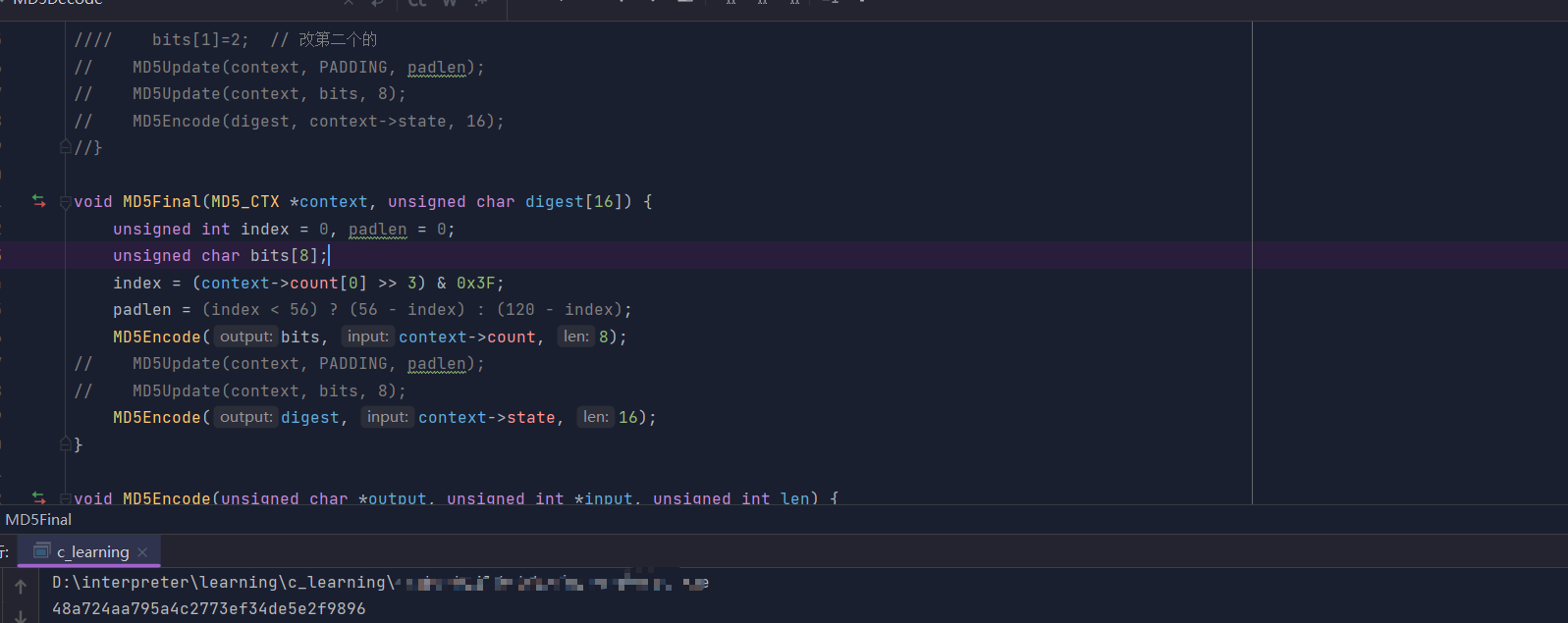
57 接一下就是改第二次加密的初始化魔数,可以仿照着01 23 45 67 89 ab cd ef fe dc ba 98 76 54 32 10 按小端字节序排列

58 接下来改updata的字节

59 这里主要改小端字节序,为什么呢,因为填充的80是直接跟着明文的字节,而小端字节序是有明文的长度决定的,注意这里的长度是整个长度,之前说过了,
60 00 00 00 00 00 00 02 a8 a8代表的是168bit,21字节,正是0ZztEbNCIcDKL3hoF/A==的字符个数,02代表的是512bit,64字节,也就是前面的那串

61 c++md5中由于只有168字符,所以我们需要手动改消息长度的内容,怎么改呢,很简单 a8 00 00 00 00 00 00 00 改a8 02 00 00 00 00 00 00怎么改?
62 很简单中间改bits的值就好了,加上一句bits[1]=2;
 63 结果也就验证成功了,那么怎么写活呢,结尾我会附上完整python代码
63 结果也就验证成功了,那么怎么写活呢,结尾我会附上完整python代码

总结:
本次教学干货很多,由于考虑单篇文章的阅读时间,我省略了部分无关紧要的流程,核心流程都在里面了.
说实话写这个sign算法的人水平很高,他对md5算法肯定是有充分了解和把握的,一般改改初始化魔数,改改k值都很少见,他一个算法里连着改那么多算是比较少见了.
提一点,关于那个魔改的md5函数,你可以结合着so层主动调用,不过你需要传3个指针参数,但是不太好构造,我这里采取的是直接修改so层传的第3个参数的值来验证的(本文并未提及),如果没有我上面说的前提,你自己摸索需要不断进行验证推翻再验证的过程,逆向就是这个样子的.
本人写作水平有限,如有讲解不到位或者讲解错误的地方,还请各位大佬在评论区多多指教,共同进步,也可加本人微信lyaoyao__i(两个_)
python代码:
import struct
import base64
from loguru import logger
class sign():
def __init__(self):
pass
def md5_1(self,message):
def left_rotate(x, amount):
return ((x << amount) | (x >> (32 - amount))) & 0xFFFFFFFF
def F(x, y, z):
return (x & y) | (~x & z)
def G(x, y, z):
return (x & z) | (y & ~z)
def H(x, y, z):
return x ^ y ^ z
def I(x, y, z):
return y ^ (x | ~z)
def FF(a, b, c, d, x, s, ac):
a = (a + F(b, c, d) + x + ac) & 0xFFFFFFFF
return left_rotate(a, s) + b & 0xFFFFFFFF
def GG(a, b, c, d, x, s, ac):
a = (a + G(b, c, d) + x + ac) & 0xFFFFFFFF
return left_rotate(a, s) + b & 0xFFFFFFFF
def HH(a, b, c, d, x, s, ac):
a = (a + H(b, c, d) + x + ac) & 0xFFFFFFFF
return left_rotate(a, s) + b & 0xFFFFFFFF
def II(a, b, c, d, x, s, ac):
a = (a + I(b, c, d) + x + ac) & 0xFFFFFFFF
return left_rotate(a, s) + b & 0xFFFFFFFF
def pad_message(message):
# original_length_bits = len(message) * 8
# message += b'\x80'
# while (len(message) + 8) % 64 != 0:
# message += b'\x00'
# message += struct.pack('<Q', original_length_bits) # 填充
return message
a0 = 0x67452301
b0 = 0xEFCDAB89
c0 = 0x98BADCFE
d0 = 0x10325476
message = pad_message(message)
chunks = [message[i:i+64] for i in range(0, len(message), 64)]
for chunk in chunks:
words = struct.unpack('<16I', chunk)
A, B, C, D = a0, b0, c0, d0
# Round 1
A = FF(A, B, C, D, words[0], 0, 0xD76AA478)
D = FF(D, A, B, C, words[1], 1, 0xE8C7B756)
C = FF(C, D, A, B, words[2], 2, 0x242070DB)
B = FF(B, C, D, A, words[3], 3, 0xC1BDCEEE)
A = FF(A, B, C, D, words[4], 0, 0xF57C0FAF)
D = FF(D, A, B, C, words[5], 1, 0x4787C62A)
C = FF(C, D, A, B, words[6], 2, 0xA8304613)
B = FF(B, C, D, A, words[7], 3, 0xFD469501)
A = FF(A, B, C, D, words[8], 0, 0x698098D8)
D = FF(D, A, B, C, words[9], 1, 0x8B44F7AF)
C = FF(C, D, A, B, words[10], 2, 0xFFFF5BB1)
B = FF(B, C, D, A, words[11], 3, 0x895CD7BE)
A = FF(A, B, C, D, words[12], 0, 0x6B901122)
D = FF(D, A, B, C, words[13], 1, 0xFD987193)
C = FF(C, D, A, B, words[14], 2, 0xA679438E)
B = FF(B, C, D, A, words[15], 3, 0x49B40821)
# Round 2
A = GG(A, B, C, D, words[1], 4, 0xF61E2562)
D = GG(D, A, B, C, words[6], 5, 0xC040B340)
C = GG(C, D, A, B, words[11], 6, 0x265E5A51)
B = GG(B, C, D, A, words[0], 7, 0xE9B6C7AA)
A = GG(A, B, C, D, words[5], 4, 0xD62F105D)
D = GG(D, A, B, C, words[10], 5, 0x02441453)
C = GG(C, D, A, B, words[15], 6, 0xD8A1E681)
B = GG(B, C, D, A, words[4], 7, 0xE7D3FBC8)
A = GG(A, B, C, D, words[9], 4, 0x21E1CDE6)
D = GG(D, A, B, C, words[14], 5, 0xC33707D6)
C = GG(C, D, A, B, words[3], 6, 0xF4D50D87)
B = GG(B, C, D, A, words[8], 7, 0x455A14ED)
A = GG(A, B, C, D, words[13], 4, 0xA9E3E905)
D = GG(D, A, B, C, words[2], 5, 0xFCEFA3F8)
C = GG(C, D, A, B, words[7], 6, 0x676F02D9)
B = GG(B, C, D, A, words[12], 7, 0x8D2A4C8A)
# Round 3
A = HH(A, B, C, D, words[5], 8, 0xFFFA3942)
D = HH(D, A, B, C, words[8], 9, 0x8771F681)
C = HH(C, D, A, B, words[11], 10, 0x6D9D6122)
B = HH(B, C, D, A, words[14], 11, 0xFDE5380C)
A = HH(A, B, C, D, words[1], 8, 0xA4BEEA44)
D = HH(D, A, B, C, words[4], 9, 0x4BDECFA9)
C = HH(C, D, A, B, words[7], 10, 0xF6BB4B60)
B = HH(B, C, D, A, words[10], 11, 0xBEBFBC70)
A = HH(A, B, C, D, words[13], 8, 0x289B7EC6)
D = HH(D, A, B, C, words[0], 9, 0xEAA127FA)
C = HH(C, D, A, B, words[3], 10, 0xD4EF3085)
B = HH(B, C, D, A, words[6], 11, 0x04881D05)
A = HH(A, B, C, D, words[9], 8, 0xD9D4D039)
D = HH(D, A, B, C, words[12], 9, 0xE6DB99E5)
C = HH(C, D, A, B, words[15], 10, 0x1FA27CF8)
B = HH(B, C, D, A, words[2], 11, 0xC4AC5665)
# Round 4
A = II(A, B, C, D, words[0], 12, 0xF4292244)
D = II(D, A, B, C, words[7], 13, 0x432AFF97)
C = II(C, D, A, B, words[14], 14, 0xAB9423A7)
B = II(B, C, D, A, words[5], 15, 0xFC93A039)
A = II(A, B, C, D, words[12], 12, 0x655B59C3)
D = II(D, A, B, C, words[3], 13, 0x8F0CCC92)
C = II(C, D, A, B, words[10], 14, 0xFFEFF47D)
B = II(B, C, D, A, words[1], 15, 0x85845DD1)
A = II(A, B, C, D, words[8], 12, 0x6FA87E4F)
D = II(D, A, B, C, words[15], 13, 0xFE2CE6E0)
C = II(C, D, A, B, words[6], 14, 0xA3014314)
B = II(B, C, D, A, words[13], 15, 0x4E0811A1)
A = II(A, B, C, D, words[4], 12, 0xF7537E82)
D = II(D, A, B, C, words[11], 13, 0xBD3AF235)
C = II(C, D, A, B, words[2], 14, 0x2AD7D2BB)
B = II(B, C, D, A, words[9], 15, 0xEB86D391)
a0 = (a0 + A) & 0xFFFFFFFF
b0 = (b0 + B) & 0xFFFFFFFF
c0 = (c0 + C) & 0xFFFFFFFF
d0 = (d0 + D) & 0xFFFFFFFF
result = struct.pack('<4I', a0, b0, c0, d0)
return result.hex()
def md5_2(self,message,_result,length):
def left_rotate(x, amount):
return ((x << amount) | (x >> (32 - amount))) & 0xFFFFFFFF
def F(x, y, z):
return (x & y) | (~x & z)
def G(x, y, z):
return (x & z) | (y & ~z)
def H(x, y, z):
return x ^ y ^ z
def I(x, y, z):
return y ^ (x | ~z)
def FF(a, b, c, d, x, s, ac):
a = (a + F(b, c, d) + x + ac) & 0xFFFFFFFF
return left_rotate(a, s) + b & 0xFFFFFFFF
def GG(a, b, c, d, x, s, ac):
a = (a + G(b, c, d) + x + ac) & 0xFFFFFFFF
return left_rotate(a, s) + b & 0xFFFFFFFF
def HH(a, b, c, d, x, s, ac):
a = (a + H(b, c, d) + x + ac) & 0xFFFFFFFF
return left_rotate(a, s) + b & 0xFFFFFFFF
def II(a, b, c, d, x, s, ac):
a = (a + I(b, c, d) + x + ac) & 0xFFFFFFFF
return left_rotate(a, s) + b & 0xFFFFFFFF
def pad_message(message):
original_length_bits = len(message) * 8
message += b'\x80'
while (len(message) + 8) % 64 != 0:
message += b'\x00'
message += struct.pack('<Q', original_length_bits)
return message
a0 = int(hex(_result[0]), 16)
b0 = int(hex(_result[1]), 16)
c0 = int(hex(_result[2]), 16)
d0 = int(hex(_result[3]), 16)
message = pad_message(message) #448 255
if(length<256):
# 1组就一个
_hex= hex(length)
index_to_replace = message.rindex(bytes.fromhex(_hex[2:]))
# 将目标位置替换为 0x02
message = message[:index_to_replace + 1] + b'\x02' + message[index_to_replace + 2:]
else:
_hex = hex(length-256)
index_to_replace = message.rindex(bytes.fromhex(_hex[2:]))
# 将目标位置替换为 0x03
message = message[:index_to_replace + 1] + b'\x03' + message[index_to_replace + 2:]
chunks = [message[i:i+64] for i in range(0, len(message), 64)]
for chunk in chunks:
words = struct.unpack('<16I', chunk)
A, B, C, D = a0, b0, c0, d0
# Round 1
A = FF(A, B, C, D, words[0], 0, 0xD76AA478)
D = FF(D, A, B, C, words[1], 1, 0xE8C7B756)
C = FF(C, D, A, B, words[2], 2, 0x242070DB)
B = FF(B, C, D, A, words[3], 3, 0xC1BDCEEE)
A = FF(A, B, C, D, words[4], 0, 0xF57C0FAF)
D = FF(D, A, B, C, words[5], 1, 0x4787C62A)
C = FF(C, D, A, B, words[6], 2, 0xA8304613)
B = FF(B, C, D, A, words[7], 3, 0xFD469501)
A = FF(A, B, C, D, words[8], 0, 0x698098D8)
D = FF(D, A, B, C, words[9], 1, 0x8B44F7AF)
C = FF(C, D, A, B, words[10], 2, 0xFFFF5BB1)
B = FF(B, C, D, A, words[11], 3, 0x895CD7BE)
A = FF(A, B, C, D, words[12], 0, 0x6B901122)
D = FF(D, A, B, C, words[13], 1, 0xFD987193)
C = FF(C, D, A, B, words[14], 2, 0xA679438E)
B = FF(B, C, D, A, words[15], 3, 0x49B40821)
# Round 2
A = GG(A, B, C, D, words[1], 4, 0xF61E2562)
D = GG(D, A, B, C, words[6], 5, 0xC040B340)
C = GG(C, D, A, B, words[11], 6, 0x265E5A51)
B = GG(B, C, D, A, words[0], 7, 0xE9B6C7AA)
A = GG(A, B, C, D, words[5], 4, 0xD62F105D)
D = GG(D, A, B, C, words[10], 5, 0x02441453)
C = GG(C, D, A, B, words[15], 6, 0xD8A1E681)
B = GG(B, C, D, A, words[4], 7, 0xE7D3FBC8)
A = GG(A, B, C, D, words[9], 4, 0x21E1CDE6)
D = GG(D, A, B, C, words[14], 5, 0xC33707D6)
C = GG(C, D, A, B, words[3], 6, 0xF4D50D87)
B = GG(B, C, D, A, words[8], 7, 0x455A14ED)
A = GG(A, B, C, D, words[13], 4, 0xA9E3E905)
D = GG(D, A, B, C, words[2], 5, 0xFCEFA3F8)
C = GG(C, D, A, B, words[7], 6, 0x676F02D9)
B = GG(B, C, D, A, words[12], 7, 0x8D2A4C8A)
# Round 3
A = HH(A, B, C, D, words[5], 8, 0xFFFA3942)
D = HH(D, A, B, C, words[8], 9, 0x8771F681)
C = HH(C, D, A, B, words[11], 10, 0x6D9D6122)
B = HH(B, C, D, A, words[14], 11, 0xFDE5380C)
A = HH(A, B, C, D, words[1], 8, 0xA4BEEA44)
D = HH(D, A, B, C, words[4], 9, 0x4BDECFA9)
C = HH(C, D, A, B, words[7], 10, 0xF6BB4B60)
B = HH(B, C, D, A, words[10], 11, 0xBEBFBC70)
A = HH(A, B, C, D, words[13], 8, 0x289B7EC6)
D = HH(D, A, B, C, words[0], 9, 0xEAA127FA)
C = HH(C, D, A, B, words[3], 10, 0xD4EF3085)
B = HH(B, C, D, A, words[6], 11, 0x04881D05)
A = HH(A, B, C, D, words[9], 8, 0xD9D4D039)
D = HH(D, A, B, C, words[12], 9, 0xE6DB99E5)
C = HH(C, D, A, B, words[15], 10, 0x1FA27CF8)
B = HH(B, C, D, A, words[2], 11, 0xC4AC5665)
# Round 4
A = II(A, B, C, D, words[0], 12, 0xF4292244)
D = II(D, A, B, C, words[7], 13, 0x432AFF97)
C = II(C, D, A, B, words[14], 14, 0xAB9423A7)
B = II(B, C, D, A, words[5], 15, 0xFC93A039)
A = II(A, B, C, D, words[12], 12, 0x655B59C3)
D = II(D, A, B, C, words[3], 13, 0x8F0CCC92)
C = II(C, D, A, B, words[10], 14, 0xFFEFF47D)
B = II(B, C, D, A, words[1], 15, 0x85845DD1)
A = II(A, B, C, D, words[8], 12, 0x6FA87E4F)
D = II(D, A, B, C, words[15], 13, 0xFE2CE6E0)
C = II(C, D, A, B, words[6], 14, 0xA3014314)
B = II(B, C, D, A, words[13], 15, 0x4E0811A1)
A = II(A, B, C, D, words[4], 12, 0xF7537E82)
D = II(D, A, B, C, words[11], 13, 0xBD3AF235)
C = II(C, D, A, B, words[2], 14, 0x2AD7D2BB)
B = II(B, C, D, A, words[9], 15, 0xEB86D391)
a0 = (a0 + A) & 0xFFFFFFFF
b0 = (b0 + B) & 0xFFFFFFFF
c0 = (c0 + C) & 0xFFFFFFFF
d0 = (d0 + D) & 0xFFFFFFFF
result = struct.pack('<4I', a0, b0, c0, d0)
return result.hex()
def md5_3(self,message):
def left_rotate(x, amount):
return ((x << amount) | (x >> (32 - amount))) & 0xFFFFFFFF
def F(x, y, z):
return (x & y) | (~x & z)
def G(x, y, z):
return (x & z) | (y & ~z)
def H(x, y, z):
return x ^ y ^ z
def I(x, y, z):
return y ^ (x | ~z)
def FF(a, b, c, d, x, s, ac):
a = (a + F(b, c, d) + x + ac) & 0xFFFFFFFF
return left_rotate(a, s) + b & 0xFFFFFFFF
def GG(a, b, c, d, x, s, ac):
a = (a + G(b, c, d) + x + ac) & 0xFFFFFFFF
return left_rotate(a, s) + b & 0xFFFFFFFF
def HH(a, b, c, d, x, s, ac):
a = (a + H(b, c, d) + x + ac) & 0xFFFFFFFF
return left_rotate(a, s) + b & 0xFFFFFFFF
def II(a, b, c, d, x, s, ac):
a = (a + I(b, c, d) + x + ac) & 0xFFFFFFFF
return left_rotate(a, s) + b & 0xFFFFFFFF
def pad_message(message):
original_length_bits = len(message) * 8
message += b'\x80'
while (len(message) + 8) % 64 != 0:
message += b'\x00'
message += struct.pack('<Q', original_length_bits)
return message
a0 = 0x67452301
b0 = 0xEFCDAB89
c0 = 0x98BADCFE
d0 = 0x10325476
message = pad_message(message)
chunks = [message[i:i+64] for i in range(0, len(message), 64)]
for chunk in chunks:
words = struct.unpack('<16I', chunk)
A, B, C, D = a0, b0, c0, d0
# Round 1
A = FF(A, B, C, D, words[0], 7, 0xD76AA478)
D = FF(D, A, B, C, words[1], 12, 0xE8C7B756)
C = FF(C, D, A, B, words[2], 17, 0x242070DB)
B = FF(B, C, D, A, words[3], 22, 0xC1BDCEEE)
A = FF(A, B, C, D, words[4], 7, 0xF57C0FAF)
D = FF(D, A, B, C, words[5], 12, 0x4787C62A)
C = FF(C, D, A, B, words[6], 17, 0xA8304613)
B = FF(B, C, D, A, words[7], 22, 0xFD469501)
A = FF(A, B, C, D, words[8], 7, 0x698098D8)
D = FF(D, A, B, C, words[9], 12, 0x8B44F7AF)
C = FF(C, D, A, B, words[10], 17, 0xFFFF5BB1)
B = FF(B, C, D, A, words[11], 22, 0x895CD7BE)
A = FF(A, B, C, D, words[12], 7, 0x6B901122)
D = FF(D, A, B, C, words[13], 12, 0xFD987193)
C = FF(C, D, A, B, words[14], 17, 0xA679438E)
B = FF(B, C, D, A, words[15], 22, 0x49B40821)
# Round 2
A = GG(A, B, C, D, words[1], 5, 0xF61E2562)
D = GG(D, A, B, C, words[6], 9, 0xC040B340)
C = GG(C, D, A, B, words[11], 14, 0x265E5A51)
B = GG(B, C, D, A, words[0], 20, 0xE9B6C7AA)
A = GG(A, B, C, D, words[5], 5, 0xD62F105D)
D = GG(D, A, B, C, words[10], 9, 0x02441453)
C = GG(C, D, A, B, words[15], 14, 0xD8A1E681)
B = GG(B, C, D, A, words[4], 20, 0xE7D3FBC8)
A = GG(A, B, C, D, words[9], 5, 0x21E1CDE6)
D = GG(D, A, B, C, words[14], 9, 0xC33707D6)
C = GG(C, D, A, B, words[3], 14, 0xF4D50D87)
B = GG(B, C, D, A, words[8], 20, 0x455A14ED)
A = GG(A, B, C, D, words[13], 5, 0xA9E3E905)
D = GG(D, A, B, C, words[2], 9, 0xFCEFA3F8)
C = GG(C, D, A, B, words[7], 14, 0x676F02D9)
B = GG(B, C, D, A, words[12], 20, 0x8D2A4C8A)
# Round 3
A = HH(A, B, C, D, words[5], 4, 0xFFFA3942)
D = HH(D, A, B, C, words[8], 11, 0x8771F681)
C = HH(C, D, A, B, words[11], 16, 0x6D9D6122)
B = HH(B, C, D, A, words[14], 23, 0xFDE5380C)
A = HH(A, B, C, D, words[1], 4, 0xA4BEEA44)
D = HH(D, A, B, C, words[4], 11, 0x4BDECFA9)
C = HH(C, D, A, B, words[7], 16, 0xF6BB4B60)
B = HH(B, C, D, A, words[10], 23, 0xBEBFBC70)
A = HH(A, B, C, D, words[13], 4, 0x289B7EC6)
D = HH(D, A, B, C, words[0], 11, 0xEAA127FA)
C = HH(C, D, A, B, words[3], 16, 0xD4EF3085)
B = HH(B, C, D, A, words[6], 23, 0x04881D05)
A = HH(A, B, C, D, words[9], 4, 0xD9D4D039)
D = HH(D, A, B, C, words[12], 11, 0xE6DB99E5)
C = HH(C, D, A, B, words[15], 16, 0x1FA27CF8)
B = HH(B, C, D, A, words[2], 23, 0xC4AC5665)
# Round 4
A = II(A, B, C, D, words[0], 6, 0xF4292244)
D = II(D, A, B, C, words[7], 10, 0x432AFF97)
C = II(C, D, A, B, words[14], 15, 0xAB9423A7)
B = II(B, C, D, A, words[5], 21, 0xFC93A039)
A = II(A, B, C, D, words[12], 6, 0x655B59C3)
D = II(D, A, B, C, words[3], 10, 0x8F0CCC92)
C = II(C, D, A, B, words[10], 15, 0xFFEFF47D)
B = II(B, C, D, A, words[1], 21, 0x85845DD1)
A = II(A, B, C, D, words[8], 6, 0x6FA87E4F)
D = II(D, A, B, C, words[15], 10, 0xFE2CE6E0)
C = II(C, D, A, B, words[6], 15, 0xA3014314)
B = II(B, C, D, A, words[13], 21, 0x4E0811A1)
A = II(A, B, C, D, words[4], 6, 0xF7537E82)
D = II(D, A, B, C, words[11], 10, 0xBD3AF235)
C = II(C, D, A, B, words[2], 15, 0x2AD7D2BB)
B = II(B, C, D, A, words[9], 21, 0xEB86D391)
a0 = (a0 + A) & 0xFFFFFFFF
b0 = (b0 + B) & 0xFFFFFFFF
c0 = (c0 + C) & 0xFFFFFFFF
d0 = (d0 + D) & 0xFFFFFFFF
result = struct.pack('<4I', a0, b0, c0, d0)
return result.hex()
def main(self,_str):
str1 = _str[:64]
str2 = _str[64:]
# 示例用法
res1 = self.md5_1(str1.encode('utf-8'))
logger.info(f'第一次md5初始化魔数分割前的加密结果==>{res1}')
# 将原始哈希字符串转换为字节对象
original_bytes = bytes.fromhex(res1)
# 使用 struct 模块按照规律解析字节对象并生成新的四组
_result = [struct.unpack('<I', original_bytes[i:i + 4])[0] for i in range(0, len(original_bytes), 4)]
logger.info(f'初始化魔数==>a1={hex(_result[0])} a2={hex(_result[1])} a3={hex(_result[2])} a4={hex(_result[3])}')
res2 = self.md5_2(str2.encode('utf-8'),_result,len(str2)*8)
res_2 = base64.b64encode(bytes.fromhex(res2)).decode('utf-8')
logger.info(f'第二次md5结果==>{res2},是最终加密结果的明文')
sign = self.md5_3(res_2.encode('utf-8'))
logger.info(f'第三次md5最终sign结果==>{sign}')
obj = sign()
obj.main('23eedd78b2b95ef16b82da4fe2177bdcb1920dd6user/login16751641924oKc0ZztEbNCIcDKL3hoF/A==')