分布式 id 需要处理的问题主要是同一时间在多台机器中保证生成的 id 唯一,为了这么做我们可以这么做:
分布式 id 生成策略
先说几个已经被淘汰的策略引出分布式 id 的问题
1,UUID:UUID 随机并且唯一,在单一的数据库中就不适合作为主键,因为生成的字符串太长不符合索引优化规则
2,自增 ID:不管是数据库自增还是MP自增,分布式数据库中总是要存放一定范围的数据,使用自增策略可能会导致不同数据库存放同一id的问题
以下的方法比较靠谱
3,redis 生成:利用 redis 的 incr 命令生成 id,设置起始值和步长,步长值是配置了多少台 redis,这种方法同样适应与数据库多主模式
4,雪花算法:生成一个64bit的id,也就是long类型的数字,长度适中并且方便快捷
雪花算法
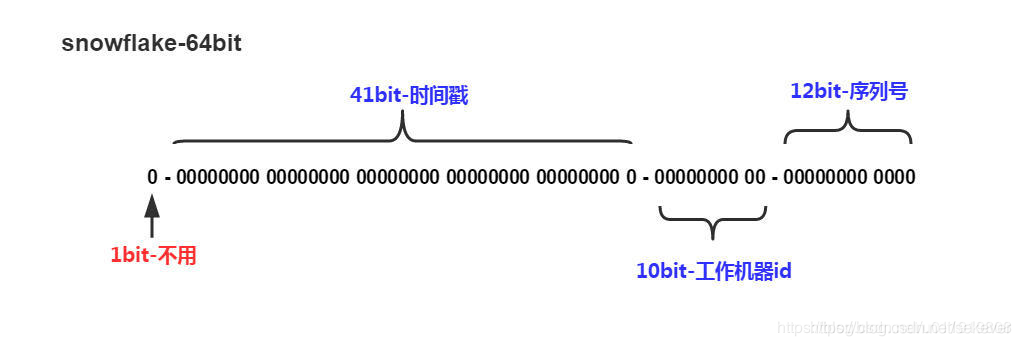
雪花算法是一个比较常见的生成分布式 id 的方式,它会生成一个 8 字节的数据,通过确保每段数据在空间与时间上唯一来确定最终数据的唯一
64bit 中,起始 1bit 为0,闲置不用
接下来 41bit 代表时间戳,这个是毫秒级的时间,存放时间戳的差值(当前时间-固定的开始时间),41位的时间戳可以使用69年
10bit 存放机器 id,前 5bit 代表机器位置(配置在不同地区的机器有不同 id),后 5bit 代表机器 id (一个地区会配置集群)
最后的 12bit 代表流水号,一个毫秒时间内最多可以处理4096个 id