首先,部署Redis数据库:
先下载包:
wget http://download.redis.io/releases/redis-5.0.7.tar.gz
解压redis包:
tar -xvf redis-5.0.7.tar.gz
编译:
make
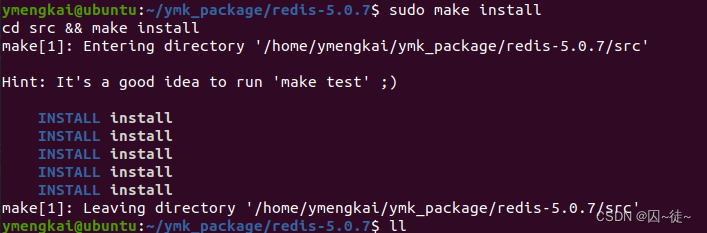
sudo make install (这样没有指定安装目录)
# 注意,redis默认安装路径:/usr/local/bin,这样其实挺好的,并不需要折腾,其实准确
# 的来说,当执行完两个make之后,就会在redis包下的src目录下生成所有必要文件,同
# 时,将一些可执行文件扔一份到 /usr/local/bin 当然,如果不想将这些可执行二进制文件
# 扔到 /usr/local/bin,可以自行指定位置,安下面命令执行即可
sudo make PREFIX=/usr/local/redis install (指定redis的安装目录)
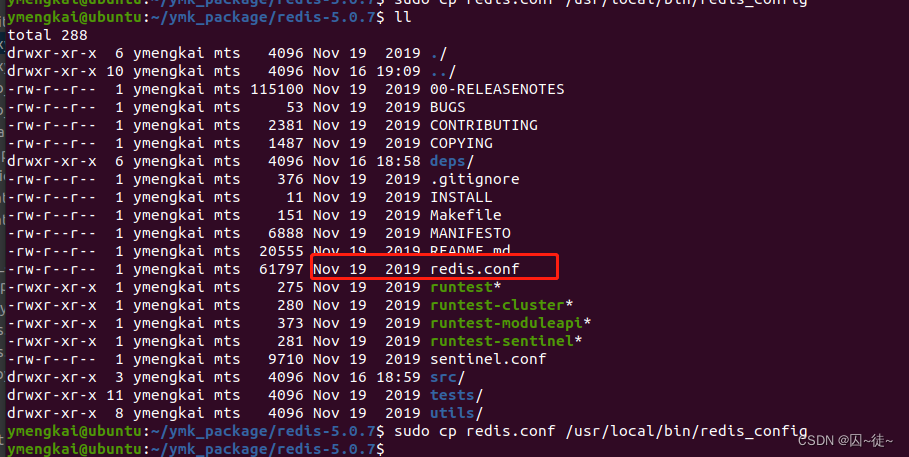
安装完成后长这样:
将redis配置文件复制到bin目录下(先新建文件夹然后再将redis配置文件coyp进去)
我们要将配置文件复制一份,我们以后就是用这个配置文件来启动。
cd /usr/local/bin
sudo mkdir redis_config
# 回到安装redis目录,因为redis.conf文件在这里
sudo cp redis.conf /usr/local/bin/redis_config
接下来修改配置文件:
vi /usr/local/bin/redis_config/redis.conf
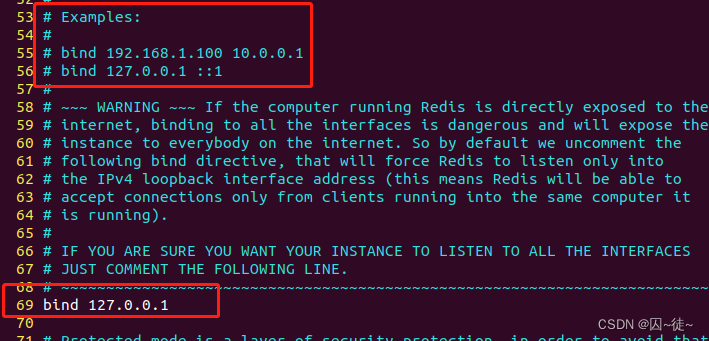
这里有几个地方需要注意:
第一个地方,绑定地址,允许访问的地址,默认是127.0.0.1,会导致只能在本地访问。修改为0.0.0.0则可以在任意IP访问,生产环境不要设置为0.0.0.0
第二个地方,设置守护,守护进程,修改为yes后即可后台运行
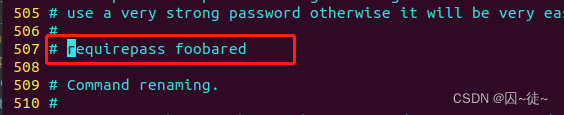
第三个地方,设置密码,设置后访问Redis必须输入密码。这里注意,redis没有用户名一说,只有服务地址和密码,密码还可以不给,不像postgres等数据库,需要严格的身份验证。
其他的,基本不太动...
# 监听的端口 port 6379 # 工作目录,默认是当前目录,也就是运行redis-server时的命令,日志、持久化等文件会保存在这个目录 dir . # 数据库数量,设置为1,代表只使用1个库,默认有16个库,编号0~15 databases 1 # 设置redis能够使用的最大内存 maxmemory 512mb # 日志文件,默认为空,不记录日志,可以指定日志文件名 logfile "redis.log"

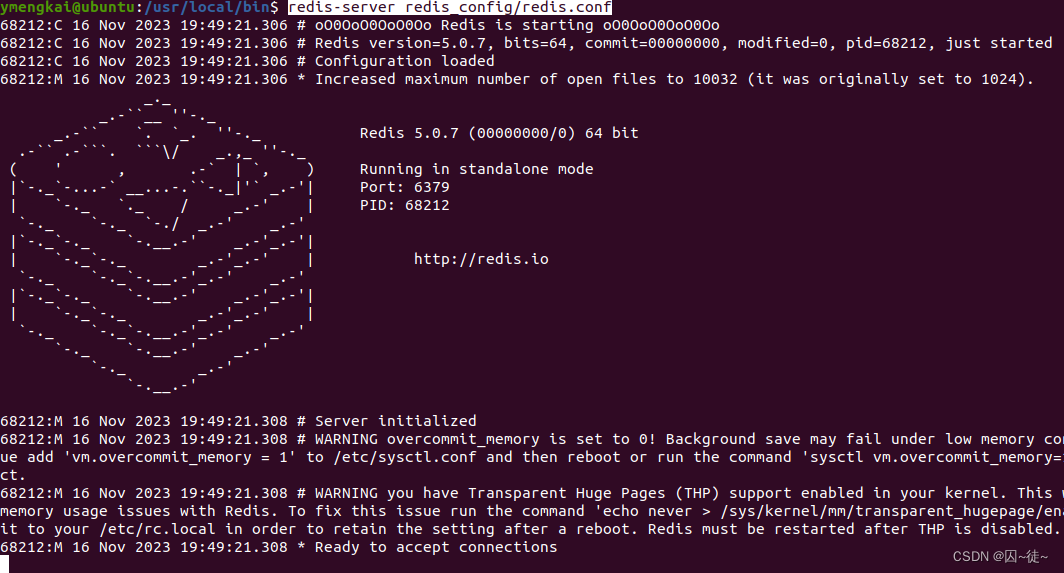
接下来,启动redis:
cd /usr/local/bin
redis-server redis_config/redis.conf
启动客户端:
cd /usr/local/bin redis-cli -h 127.0.0.1 -p 6379
设置Redis开机自启动
首先,新建一个系统服务文件:
vi /etc/systemd/system/redis.service文件内容为:
[Unit]
Description=redis-server
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/bin/redis-server /usr/local/bin/redis_config/redis.conf
PrivateTmp=true
[Install]
WantedBy=multi-user.target
这里其他的没啥,注意这个参数 ExecStart,填对就行。
systemctl daemon-reload 现在,我们可以用下面这组命令来操作redis了:
# 启动
systemctl start redis
# 停止
systemctl stop redis
# 重启
systemctl restart redis
# 查看状态
systemctl status redis执行下面的命令,可以让redis开机自启:
systemctl enable redis
好了,接下来,开始扯 celery
Celery 是一款简单灵活可靠的分布式任务执行框架,支持大量任务的并发执行。
Celery 采用典型生产者和消费者模型。生产者提交任务到任务队列,众多消费者从任务队列中取任务执行。
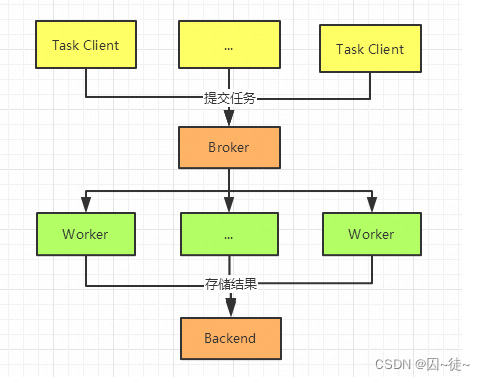
- 提交任务给 Broker 队列
- 如果是异步任务,Worker 会立即从队列中取出任务并执行,执行结果保存在 Backend 中
- 如果是定时任务,任务由 Celery Beat 进程周期性地将任务发往 Broker 队列,Worker 实时监视消息队列获取队列中的任务执行
应用场景
- 长时间任务的异步执行, 如上传大文件
- 实时任务执行,支持集群部署,如支持高并发的机器学习推理
- 定时任务执行,如定时发送邮件
节点总结:
到这里,我先记录一些理解。
首先,celery它是一个典型的生产者消费者模型。也就是说,这个模型里,可以没有生产者,但是必须得有消费者。
其次,这里先了解2个命令:
celery -A tasks worker --loglevel=info --pool=solo
celery -A proj.period_task beat -l info
这里面出现了一个 worker, 一个 beat。worker 就是消费者的意思,beat 是指周期任务。
2个命令很像,但是意思完全不一样。celery beat -A ... 是说,周期的向队列里放入任务。而celery worker -A ... 是说,一旦队列里有任务,就立刻去执行任务。所以,beat 就属于生产者,而 worker 属于消费者。如果没有 worker 那么任务只会堆积,没人处理。因此,使用celery 一定得启动 worker。
第三,selery跟我们django服务里面自定义的app一样,它本身也是一个app。
安装
本文使用 Redis 作为 Broker 即消息队列
pip install celery
pip install redis需要持久化任务的话,Broker 使用 RabbitMQ 并设置持久化队列。
官方建议生产环境首选 RabbitMQ ,突然停止或断电 Redis 可能会数据丢失。
Celery 的开发主要有四个步骤:
- 实例化 Celery
- 定义任务
- 启动任务 Worker
- 调用任务
先看一个简单的celery实现:
from celery import Celery
# broker 是用于存储任务的队列,backend 是用于存储任务执行结果的队列
test_celery = Celery('test', broker='redis://127.0.0.1:6379/0',
backend='redis://127.0.0.1:6379/1')
# 也可以以这种方式,导入任务模块,当然,这里作为最简单的例子,是不需要的
app.conf.imports = ['tasks']
@test_celery.task
def my_add(a, b):
return a + b这样,一个最简单的最基本的 celery 就已经完成了。现在已经构建了一个 celery 的异步任务。但是光有任务是没有用的,首先得有消费者,就是我之前写的小结里记录的,celery 必须得有worker,然后,在搞一个生产者,将任务放到队列里,然后,自然会有worker去执行任务,代码也就会被执行了。
启动任务 Worker
celery -A my_celery worker -l info -c 4这里千万注意,worker 的位置:
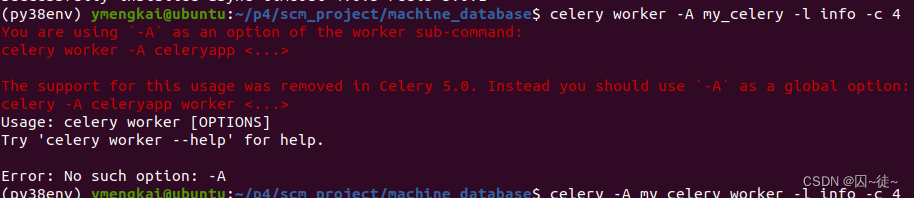
新版本,worker不让写前面了。
连接成功后,长这样子...
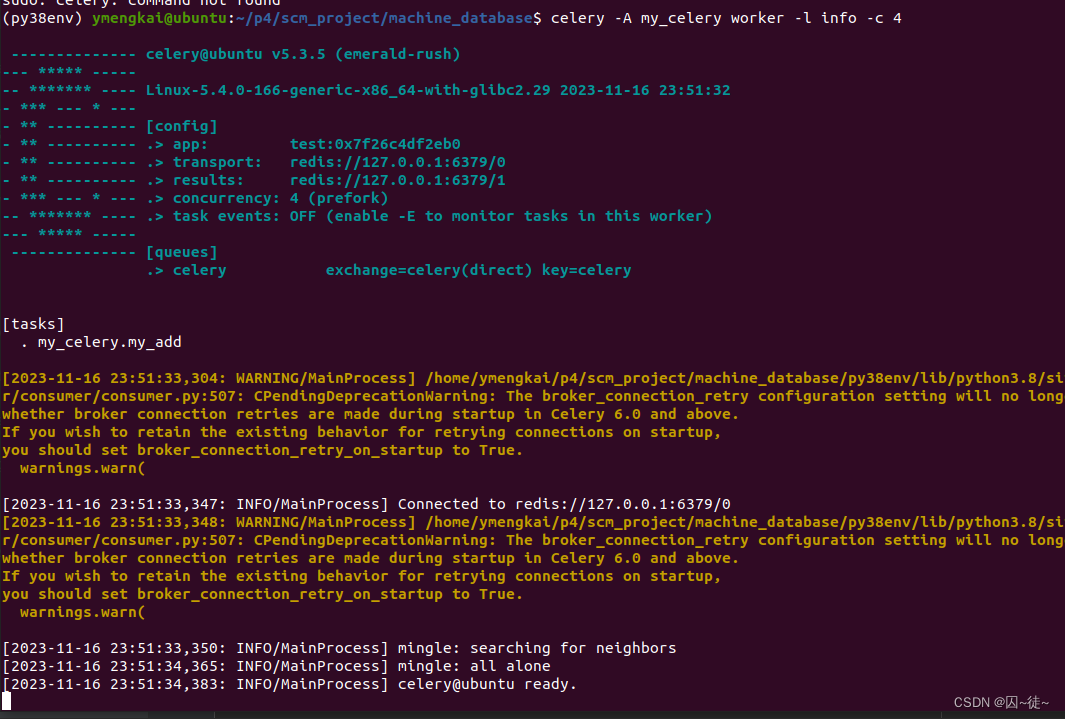
到这里,celery 的消费者就搞定了,然后是生产者...其实生产者无非就2种,一次性的,循环性的。但是其本质又都是一样的,就是给 task 到任务队列完事。一次性的就是只触发一次将 task 压入队列,周期性的就是间隔的将 task 压入队列。
现在构建生产者,最简单的,就是这样,直接弄一个,然后,执行这个文件即可。
from my_celery import my_add
my_add.delay(1, 2)看下结果:
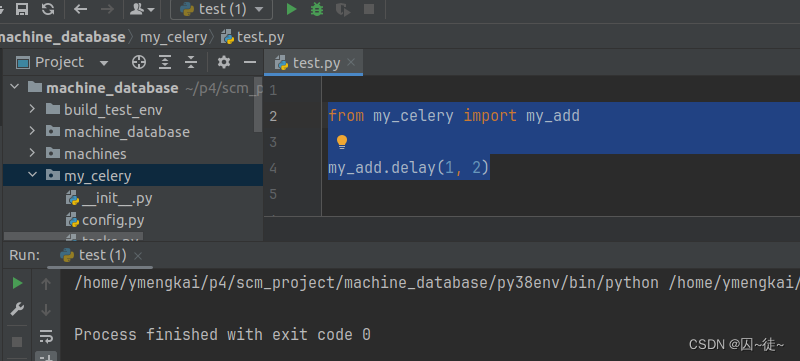
这是刚起的 celery 的 worker 的执行结果...

换一种写法:
from my_celery import my_add
my_add.delay(1, 2)
# 使用签名模式,得到的是一个新的 task, 这种 task 可以跨越进程被调用
new_task = my_add.s(1, 2)
new_task.delay()结果就成了:

这是两种写法,先不做,讨论,一会在说。
就现在为止,基本上,我们就已经可以使用selery做事情了。尤其是在django服务中,完全可以搞一个 url 配合视图函数做任务触发,就可以利用celery做异步任务。
上面是个简单的实现,通常情况,都是写出配置文件来用的,会显得规范一些。目录结构通常是这样的。构建一个celery app的文件夹,让它和 manage.py 在同一级目录。
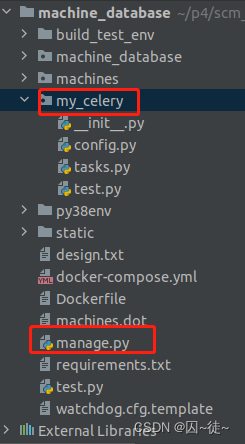
所有的 task 都可以放到 tasks.py 中,celery 的实例化对象可以放到 __init__.py 中,相关的配置可以放到 config.py 中。
__init__.py
from celery import Celery
from celery.schedules import crontab
test_celery = Celery('test')
# 加载配置文件
test_celery.config_from_object('my_celery.config')
# 添加周期任务,在没有调度的时候,周期任务是不会执行的,只有通过周期调度命令启动的时候
# 它们才会被执行
test_celery.conf.beat_schedule = {
'test001': {
'task': 'my_celery.tasks.my_add',
# 每周一07:30执行my_add任务
'schedule': crontab(minute='30', hour='7', day_of_week='1'),
'args': (1, 3)
},
'test002': {
'task': 'my_celery.tasks.my_add',
# 每分钟执行一次 my_add 任务
'schedule': crontab(minute='*/1'),
'args': (1, 3)
},
}
config.py
注意:这里一定得记着导入模块,因为如果这里没写导入任务模块,那么就会导致任务模块里的任务统统没被注册,那就无法使用。
BROKER_URL = 'redis://127.0.0.1:6379/0' # Broker,中间件,进行消息传输,使用Redis
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/1' # Backend,结果后端,使用Redis
CELERY_RESULT_SERIALIZER = 'json' # 结果序列化方案
CELERY_TASK_RESULT_EXPIRES = 60 * 60 * 24 # 任务过期时间
CELERY_TIMEZONE = 'Asia/Shanghai' # 时区配置
CELERY_IMPORTS = ( # 导入的任务模块
'my_celery.tasks',
)tasks.py
from my_celery import test_celery
@test_celery.task
def my_add(a, b):
return a + btest.py
from my_celery.tasks import my_add
my_add.delay(1, 2)
# 定时任务,延时3秒执行
my_add.apply_async((3, 4), countdown=3)
new_task = my_add.s(5, 6)
new_task.delay()普通的调用和之前的简单模式一样,这次看下周期调用:
celery -A my_celery beat -l info这里有第二种写法,其意义在于,周期模式是需要记录时间的,因此,可以指定一个地方让其记录时间。
celery -A proj beat -s /home/celery/var/run/celerybeat-schedule结果:
每隔1分钟将task压入队列
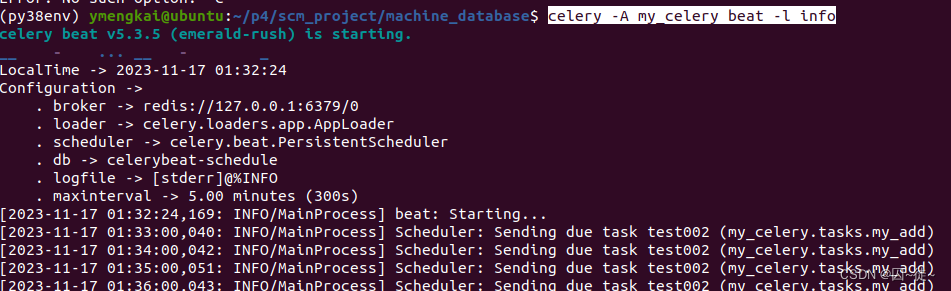
每隔1分钟,worker就能获取到task,并执行它

到这里,基本的celery,就搞定了,可以使用了....
另外的一些花哨的用法,记录下:
调用任务
常规任务
- delay():直接调用任务,是
apply_async()的封装 - apply_async():通过发送异步消息调用任务,可指定倒计时 countdown ,执行时间 eta ,过期时间 expires 等参数
- signature():创建签名,可传递任务签名给别的进程使用,或作为其他函数的参数
- s():创建签名的快捷方式
from my_celery.tasks import my_add
result = my_add.delay(1, 2) # 直接调用
print(result.get())
result = my_add.apply_async((1, 2), countdown=2) # 2s后执行
print(result.get())
t1 = my_add.signature((1, 2), countdown=2) # 签名Signatures,可传递任务签名给别的进程使用,或作为其他函数的参数
result = t1.delay()
print(result.get())
t1 = my_add.s(1, 2).set(countdown=2) # 创建签名的快捷方式
result = t1.delay()
print(result.get())组合任务
- group():组合,接受一个可并行调用的任务列表
- chain():串联,将签名连接在一起,一个接一个调用(前一个签名的结果作为下一个签名的第一个参数)
- chord():和弦,类似
group()但包含回调,在所有任务执行完后再调用任务 - map():将参数列表应用于该任务
- starmap():将复合参数列表应用于该任务
- chunks():将一个很长的参数列表分块成若干部分
任务状态跟踪
这种情况,需要对 __init__.py 做出一定的修改,添加一些内容即可
from celery import Celery, Task
from celery.schedules import crontab
from celery.utils.log import get_task_logger
logger = get_task_logger(__name__) # 日志
test_celery = Celery('test')
test_celery.config_from_object('my_celery.config')
test_celery.conf.beat_schedule = {
'test001': {
'task': 'my_celery.tasks.my_add',
'schedule': crontab(minute='30', hour='7', day_of_week='1'),
'args': (1, 3)
},
'test002': {
'task': 'my_celery.tasks.my_add',
'schedule': crontab(minute='*/1'),
'args': (1, 3)
},
}
class TaskMonitor(Task):
def on_success(self, retval, task_id, args, kwargs):
"""success时回调"""
logger.info('task id:{} , arg:{} , successful !'.format(task_id, args))
def on_retry(self, exc, task_id, args, kwargs, einfo):
"""retry时回调"""
logger.info('task id:{} , arg:{} , retry ! einfo: {}'.format(task_id, args, exc))
def on_failure(self, exc, task_id, args, kwargs, einfo):
"""failure时回调"""
logger.info('task id: {0!r} failed: {1!r}'.format(task_id, exc))
然后,再修改下 tasks.py
from my_celery import test_celery, TaskMonitor
@test_celery.task
def my_add(a, b):
return a + b
@test_celery.task(base=TaskMonitor)
def my_add_1(a, b):
return a + b命令行参数:
关于 celery 命令行的启动等参数,都在这了
| 参数 | 含义 | 全称 |
|---|---|---|
| -A | 指定模块 | |
| -l | 日志level | –loglevel |
| -c | 进程数 | –concurrency |
| -Q | 指定队列 | –queue |
| -B | 周期性任务 | –beat |
| -P | 池的实现 | –pool |
搭建redis:
Redis基础——1、Linux下安装Redis(超详细)_linux安装redis_原首的博客-CSDN博客
使用redis:
https://www.cnblogs.com/fuminer/p/17254164.html
celery的使用:
Python定时任务库Celery——分布式任务队列_python celery_XerCis的博客-CSDN博客
其他参考,总之,看到的帖子,都有错误之处,往往不能让我通达,故写此贴:
https://www.cnblogs.com/clark1990/p/17174251.html
Periodic Tasks — Celery 5.3.5 documentation
https://docs.celeryq.dev/en/stable/reference/cli.html
Python定时任务库Celery——分布式任务队列_python 使用分布式消息系统celery实现定时任务 自动执行python 脚本_XerCis的博客-CSDN博客
Python-Celery定时任务、延时任务、周期任务、crontab表达式及清除任务的基本使用与踩坑 - 知乎




![23111707[含文档+PPT+源码等]计算机毕业设计基于javawebmysql的旅游网址前后台-全新项目](https://img-blog.csdnimg.cn/img_convert/e1a49b4802b87123878d034ab4d10f0f.png)