目录
Test.c
DList.h
DList.c
SLInsert
SLErase
DList.c总代码
顺序表和链表的对比
今天继续再双向循环链表的基础上做修改。
❓提问:请你在10分钟内写一个带头双向循环链表。
其实我们只要把SLInsert 和 SLErase 写好就大功告成了!🆗
Test.c
#include"Dlist.h"
int main()
{
SL* phead = SLInit();
//头插
SLPushFront(phead, 7);
SLPushFront(phead, 77);
SLPushFront(phead, 9);
SLPushFront(phead, 99);
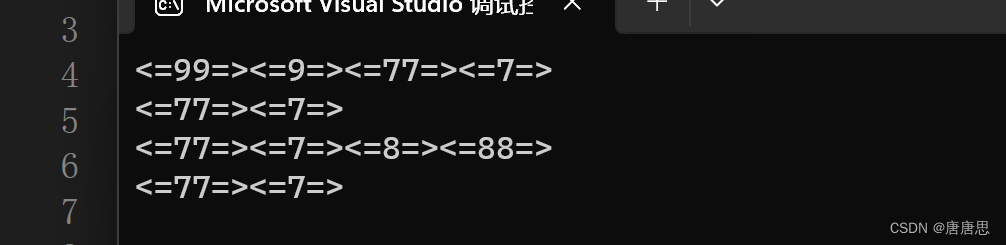
SLPrint(phead);
//头删
SLPopFront(phead);
SLPopFront(phead);
SLPrint(phead);
//尾插
SLPushBack(phead,8);
SLPushBack(phead, 88);
SLPrint(phead);
//尾删
SLPopBack(phead);
SLPopBack(phead);
SLPrint(phead);
//
SLDestory(phead);
phead = NULL;
return 0;
}DList.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int SLDataType;
typedef struct SListNode
{
SLDataType val;
struct SListNode* prev;
struct SListNode* next;
}SL;
//初始化
SL* SLInit();
//打印数据
SL* SLPrint(SL* phead);
//查询
SL* SLFind(SL* phead, SLDataType x);
//头插
void SLPushFront(SL* phead, SLDataType x);
//头删
void SLPopFront(SL* phead);
//尾插
void SLPushBack(SL* phead, SLDataType x);
//尾删
void SLPopBack(SL* phead);
//在pos的前面插入
void SLInsert(SL* pos, SLDataType x);
//删除pos位置
void SLErase(SL* pos);
//销毁
void SLDestory(SL* phead);DList.c
SLInsert
//在pos的前面插入
void SLInsert(SL* pos, SLDataType x)
{
assert(pos);
SL* cur = pos->prev;
SL* newnode = Createnewnode(x);
newnode->next = pos;
pos->prev = newnode;
cur->next = newnode;
newnode->prev = cur;
}SLErase
//删除pos位置
void SLErase(SL* pos)
{
assert(pos);
SL* cur = pos->prev;
SL* tail = pos->next;
cur->next = tail;
tail->prev = cur;
free(pos);
pos = NULL;
}DList.c总代码
#include"Dlist.h"
//创建新的节点
SL* Createnewnode(SLDataType x)
{
SL* newnode = (SL*)malloc(sizeof(SL));
newnode->val = x;
newnode->prev = NULL;
newnode->next = NULL;
return newnode;
}
//初始化
SL* SLInit()
{
SL* phead = Createnewnode(-1);
phead->prev = phead;
phead->next = phead;
return phead;
}
//打印
SL* SLPrint(SL* phead)
{
assert(phead);
assert(phead->next != phead);//不打印头节点
SL* cur = phead->next;
while (cur != phead)
{
printf("<=%d=>", cur->val);
cur = cur->next;
}
printf("\n");
}
//查询
SL* SLFind(SL* phead, SLDataType x)
{
assert(phead);
SL* cur = phead->next;
while (cur != phead)
{
if (cur->val == x)
{
return cur;
}
}
return NULL;
}
//在pos的前面插入
void SLInsert(SL* pos, SLDataType x)
{
assert(pos);
SL* cur = pos->prev;
SL* newnode = Createnewnode(x);
newnode->next = pos;
pos->prev = newnode;
cur->next = newnode;
newnode->prev = cur;
}
//删除pos位置
void SLErase(SL* pos)
{
assert(pos);
SL* cur = pos->prev;
SL* tail = pos->next;
cur->next = tail;
tail->prev = cur;
free(pos);
pos = NULL;
}
//头插
void SLPushFront(SL* phead, SLDataType x)
{
SLInsert(phead->next, x);
}
//头删
void SLPopFront(SL* phead)
{
assert(phead->next != phead);//不删除头节点
SLErase(phead->next);
}
//尾插
void SLPushBack(SL* phead, SLDataType x)
{
SLInsert(phead, x);
}
//尾删
void SLPopBack(SL* phead)
{
assert(phead->next != phead);//不删除头节点
SLErase(phead->prev);
}
//销毁
void SLDestory(SL* phead)
{
assert(phead);
SL* cur = phead->next;
while (cur != phead)
{
SL* tmp = cur->next;
free(cur);
cur = tmp;
}
free(phead);
cur = NULL;
} 
🙂🙂是不是很简单,动手快速写一写吧!!
顺序表和链表的对比
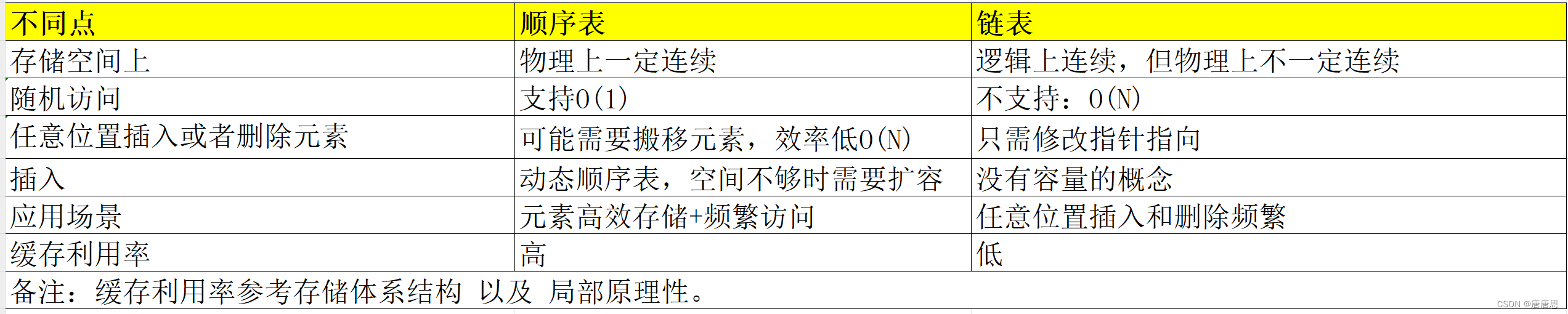
链表(双向)的优势:
- 任意位置插入删除都是O(1)
- 知道pos位置并且插入和删除,都是O(N) //后期学习哈希可以达到O(1)
- 按需求申请释放,合理利用空间,不存在浪费
链表(双向)劣势:
- 下标随机访问不方便O(N) //不支持高效排序
顺序表优势:
- 支持下标随机访问O(1)
- CPU高速缓存命中率比较高
顺序表劣势:
- 头部或者中间插入删除效率低,要挪动数据。O(N)
- 空间不够需要扩容,扩容有一定的消耗,且可能存在一定的空间浪费
- 只适合尾插尾删
有人可能问CPU高速缓存命中率比较高是什么?
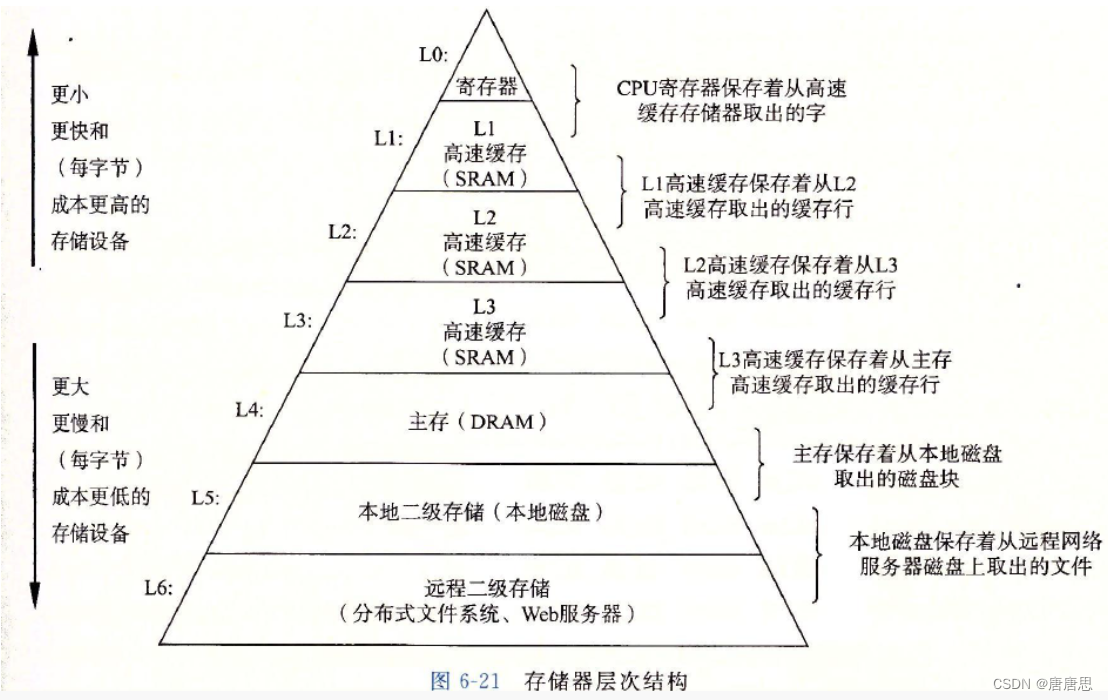
电脑中负责运算就是 CPU 和 GPU(显卡等)。负责存储就是内存和硬盘(磁盘/固态)。内存是带电暂时存储,速度相对较快。硬盘是不带电,永久存储,读写速度相对慢。
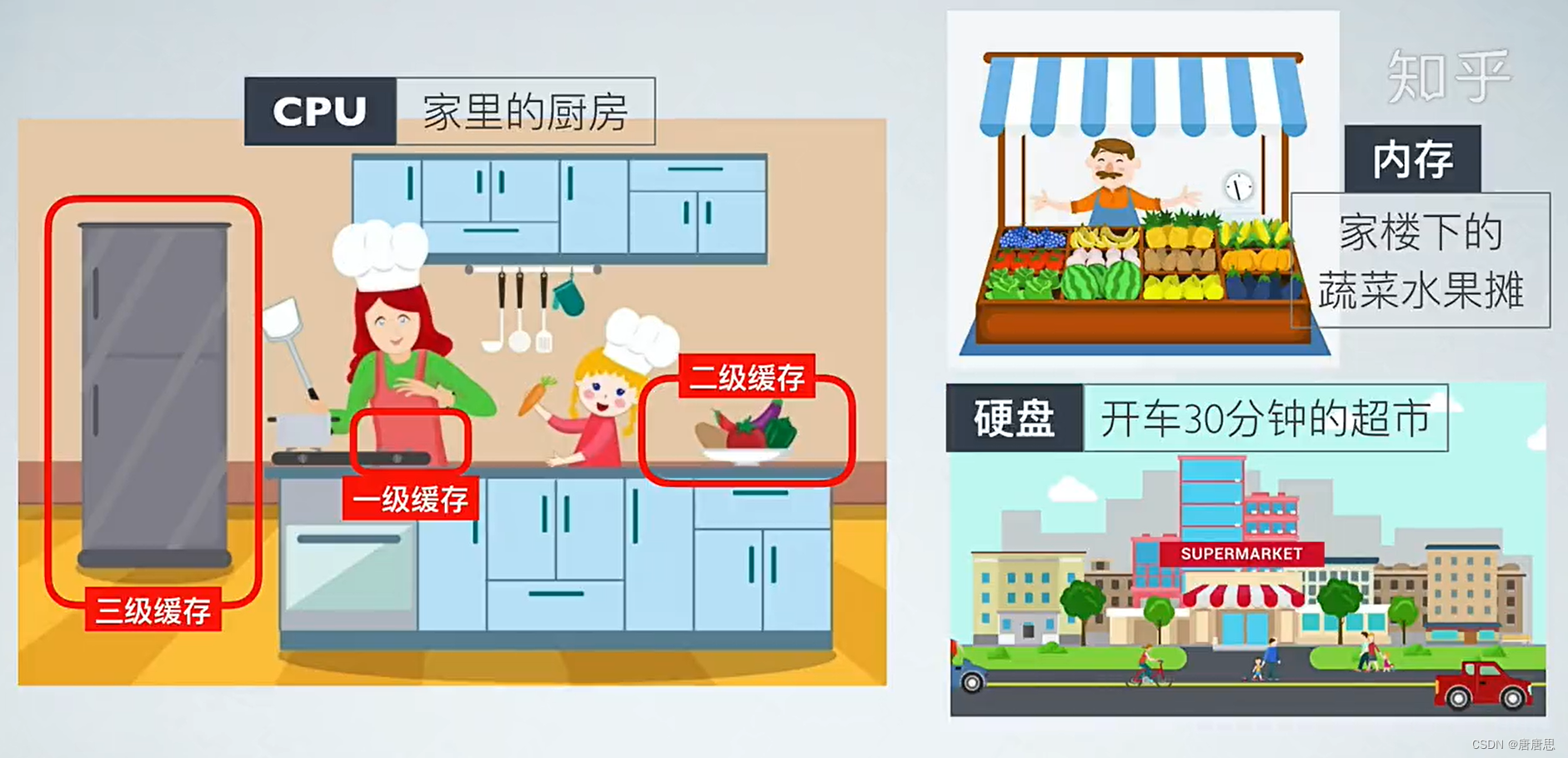
当然除了内存和硬盘这两个存储介质,还有其他的存储介质。就是缓存 虽然内存速度相较于硬盘快,但是对于CPU来说还是慢了,于是就有围绕在CPU附近的缓存。
缓存中,缓存的存储数据越少,速度越快。所以,小的数据会放到寄存器。大的数据会放到高速缓存中去。像顺序表/链表/数组这样的数据存储,当然是放到高速缓存中。
那么数据是怎样放入缓存,CPU怎样去访问高速缓存中的数据呢?
- 首先CPU会到高速缓存中去查看需要访问的数据是否在缓存中
- 如果在就访问成功(命中)
- 如果不在(没命中)就把数据 加载 高速缓存中(不是一个一个加载,而是一段一段的加载)
- 加载之后再去访问
对于顺序表来说,物理结构上的连续,加载和访问时的命中率更高
对于链表来说,只是逻辑上的连续,物理空间可能相隔很远,所以命中率相对没有那么高,而且很容易造成缓存污染(空间存储都是一些无用的数据)
这个也叫:局部性原理
 想要更加深入的了解【戳一戳】:与程序员相关的CPU缓存知识 | 酷 壳 - CoolShell
想要更加深入的了解【戳一戳】:与程序员相关的CPU缓存知识 | 酷 壳 - CoolShell
✔✔✔✔✔最后感谢大家的阅读,若有错误和不足,欢迎指正!乖乖敲代码哦!
代码---------→【唐棣棣 (TSQXG) - Gitee.com】
联系---------→【邮箱:2784139418@qq.com】






![洛谷 P3131 [USACO16JAN] Subsequences Summing to Sevens S](https://img-blog.csdnimg.cn/78158e597f684631b659eb8c4c7b32cf.png)

![Taro编译警告解决方案:Error: chunk common [mini-css-extract-plugin]](https://img-blog.csdnimg.cn/d7565cfc032647bfb69e7971731a06a2.gif#pic_center)
