1、什么是冷启动问题?
在缺乏有价值数据的时候,如何有效地满足业务需求的问题,就是“冷启动问题”。为了沟通方便,下面统一从推荐系统的角度来讲“冷启动问题”,其他业务场景同理。
冷启动问题是机器学习系统中十分常见、无法回避的问题,因为任何机器学习系统都要经历从无到有的过程。试想,你作为一个新用户,在没有用户数据的情况下,淘宝如何给你个性化推荐商品,抖音如何给你个性化推荐视频呢?
具体地讲,根据数据匮乏情况的不同,冷启动问题主要分为 3 类:
- 用户冷启动:新用户注册后,没有历史行为数据。
- 物品冷启动:新物品上架后,没有用户对该物品的交互数据。
- 系统冷启动:新系统上线时,缺乏所有历史相关数据。
2、如何解决冷启动问题?
说“解决”可能是过于绝对和自信了,但面对没有数据的情况,我们并不是完全没有办法。
在讲具体的解决方法之前,我还是希望站在更高维度,帮助大家构建一个数据分析师/算法工程师该有的思维模型——可以从哪些角度来解构数据/算法相关的问题,那么以后无论遇到什么问题,都可以做到考虑全面。抓到要害。
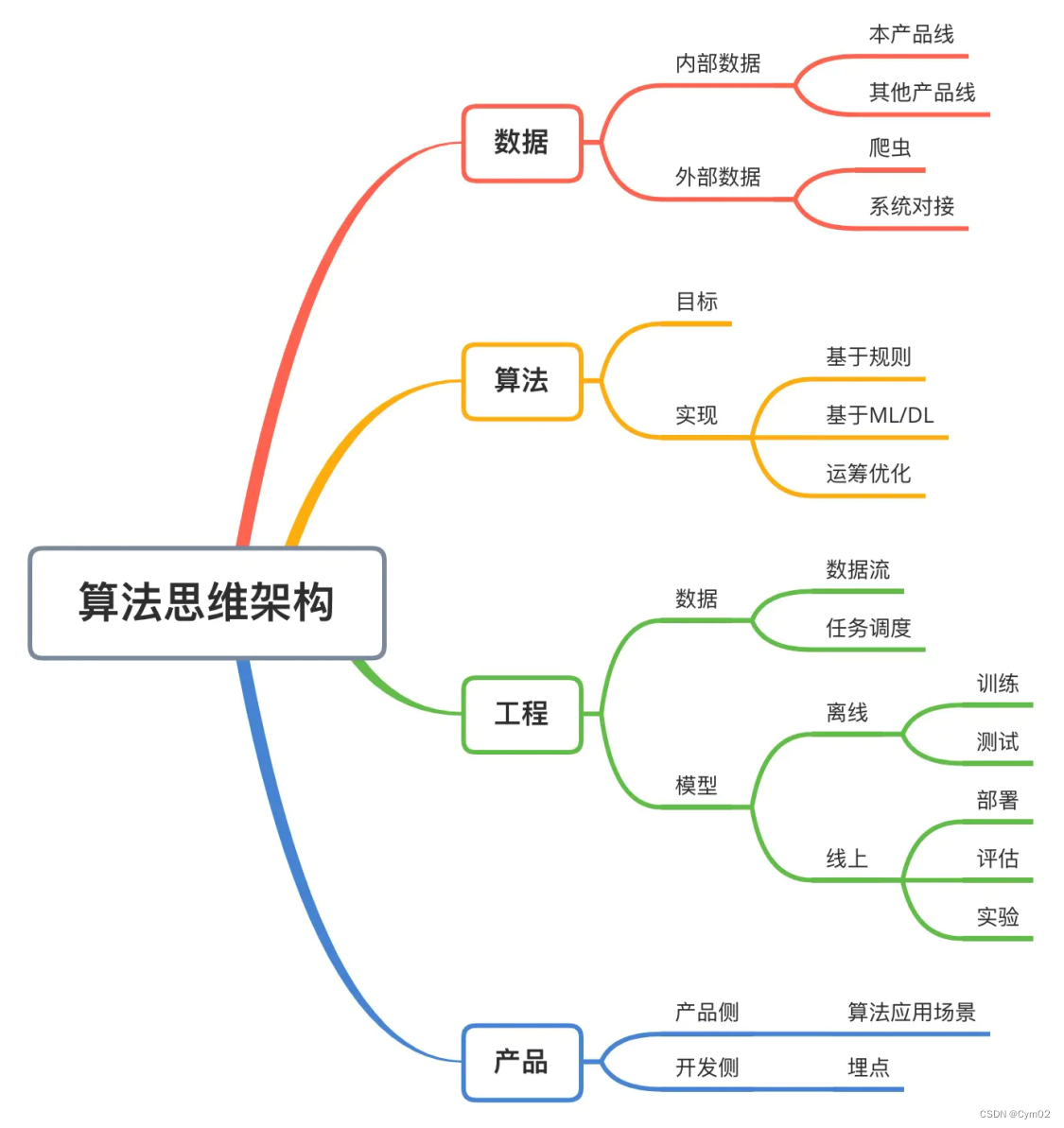
冷启动问题是因为数据缺乏导致的,与工程实现无关。根据上面的思维导图,我们来从数据、算法和产品三个角度来思考。
3、数据
首先思考数据,能够帮助我们了解现状,知道手上有哪些底牌。数据一般包括用户数据和物品数据。
按数据来源的不同,考虑:内部数据、外部数据。
3.1、内部数据
内部数据包括:本产品线的数据、其他产品线的数据。
注意,在冷启动问题中,对于数据是“缺乏”而非“没有”。这意味着我们手上可能还是有一些数据的。
● 对于用户冷启动问题,用户在注册时填写的信息(手机号、地址、性别、年龄等)和注册时的环境信息(IP地址、GPS),可以帮助我们做出粗粒度的推荐。例如可以根据专家意见或决策树模型建立一些针对于不同年龄段、不同性别的用户的个性化榜单,然后在用户完成注册后,根据注册时填写的信息进行推荐。
● 对于物品冷启动问题,物品的一些属性信息也同样可以起到作用。在酒店推荐的场景下,可以根据新上线酒店的位置、价格、面积等信息,为酒店指定聚类,找到相似酒店,利用相似酒店的推荐逻辑完成冷启动过程。
另外,如果公司还有其他业务线,那么其他业务线的数据也可以拿过来使用。例如用户在美团已经积累了外卖数据,可以根据消费金额、家庭地址等分析得出用户的消费水平,那么在用户第一次使用美团的酒店服务时,也可以推荐出符合消费习惯的酒店。
3.2、外部数据
常见获取数据的手段包括:爬虫、平台对接。
● 爬虫是近乎于零成本的方案,但是可能会有一些法律风险。平台之间互相告对方非法爬取数据的新闻屡见不鲜。
● 有些第三方 DMP(Data Management Platform,数据管理平台)也会提供用户信息。像国外的 BlueKai、Nielsen,国内的 Talking Data 等公司都提供匹配率非常高的数据服务,可以极大地丰富用户的属性特征。像腾讯、百度、网易、Google等企业都与这些 DMP 平台有合作。
那 DMP 的数据是哪里来的呢?数据交换。通过合作的方式,企业给 DMP 提供用户的一些基本数据,DMP 对数据进行分析、挖掘,给企业提供更加全方位的用户信息。这样一来,企业就能获取到本来完全得不到的用户兴趣、收入水平、广告倾向等一系列高阶特征。
4、算法
在梳理完数据现状之后,接下来考虑算法的问题。
推荐系统的目标就是推荐给用户正确的商品,评价方式可以是点击率、在线观看时长等。在解决冷启动问题的过程中,无论用什么算法,算法的优化目标都要与总体目标一致。
算法可以从实现方式的不同,分为 3 类:基于规则、基于ML/DL、探索与利用。
4.1、基于规则的算法
基于规则的算法,一般给出的都是榜单类型的推荐结果。
在用户冷启动场景下,可以使用“热门排行榜”、“最新流行趋势榜”、“最高评分榜”等作为默认的推荐列表,实现非个性化推荐。可以根据专家意见建立一些针对于不同年龄段、不同性别的用户的个性化榜单,然后在用户完成注册后,根据注册时填写的信息进行粗粒度的个性化推荐。另外,在 LBS(Location Based Services,基于位置的服务)场景下,可以根据用户在注册时填写的地址信息、GPS 信息,按一定规则推荐周围的店家/商品。
在物品冷启动场景下,可以按一定规则寻找相似商品进行绑定,完成推荐。
需要注意的是,基于规则的算法更多依赖的是专家对业务的洞察。因此在制定规则时,需要充分了解业务,充分利用已有数据,才能让冷启动规则合理且高效。
4.2、基于ML/DL
基于 ML/DL 的算法要解决的是用户冷启动或物品冷启动问题,而非系统冷启动问题。因此前提是,系统已经上线,同时也已经有了一定的数据积累。
机器学习(ML)的思路是,将基于规则的算法改造为机器学习模型,按学习方式的不同,又可以分为有监督学习和无监督学习(当然还有半监督学习,此处不展开)。
● 有监督学习:在前面的例子中,可以利用点击率目标构造一个用户属性的决策树,在每个决策树的叶节点建立冷启动榜单,然后新用户在注册后,根据其有限的属性信息,寻找到决策树上对应的叶节点榜单,完成冷启动过程。
● 无监督学习:例如使用聚类算法,来寻找相似物品,但要注意维度灾难问题。
需要注意的是,由于数据的缺乏,不能选用复杂的机器学习模型,否则容易造成过拟合问题。
而对于新用户,由于其特征非常的稀疏,使用基于深度学习(DL)的推荐系统效果会比较差,那有什么方法呢?可以考虑迁移学习和强化学习。
● 迁移学习如果有其他业务线的数据,也可以拿过来使用。冷启动问题本质上是某领域的数据或知识不足导致的,如果能够将其他领域的知识用于当前领域,那么冷启动问题自然迎刃而解。我们称这种做法为“迁移学习”,常见的做法是共享特征(在深度学习模型中就是共享 Embedding)或共享模型参数。例如将 CTR 模型中的用户 Embedding 和物品 Embedding 应用到 CVR 模型中,直接用于训练。Embedding 是一种高维特征到低维特征的映射,训练好的 Embedding 可以反映用于与隐变量、商品与隐变量之间的内在联系。
● 强化学习:所谓强化学习,就是指智能体(即模型)根据环境(即用户、物品等)的反馈(即点击或不点击)来采取行动(即推荐商品列表)并改变自身状态(更新模型参数),然后再获得反馈再采取行动再改变状态的循环过程。在一次次的迭代过程中,让推荐系统尽快度过冷启动状态。
4.3、运筹优化
运筹优化在推荐系统中的应用场景是多样的,而在冷启动问题里,主要是用于解决物品冷启动问题。当然,同样也可以用来解决系统冷启动的问题。
具体而言,就是是在“探索新数据”和“利用旧数据”之间进行平衡,使系统既能够利用旧数据进行推荐,达到推荐系统的商业目标,又能高效地探索冷启动的物品是否是“优质物品”,使冷启动物品获得曝光的倾向,快速收集冷启动数据。我们又称这个过程为“探索与利用”。
显然,这是一个多目标优化问题。
一个经典的解决办法是 UCB(Upper Confidence Bound,置信区间上界)。公式如下。其中 为观测到的第 个物品的平均回报(这里的平均回报可以是点击率、转化率等), 是目前为止向该用户曝光第 个物品的次数, 是到目前为止曝光所有物品的次数之和。
在新物品刚上架的时候, 比较低,但是因为曝光次数 也比较小,所以 会比较大,最后 值会比较大,新物品的曝光机会较大。随着曝光次数的增加, 在公式中的相对值逐渐减小,最后 就主要取决于 了。也就是说,使用 UCB 方法进行推荐,推荐系统会倾向于推荐“效果好”或“冷启动”的物品。随着冷启动物品被有倾向性的推荐,能够快速收集反馈数据,最后快速通过冷启动阶段。
5、产品
最后讨论一下从产品的角度,要怎么帮助解决冷启动问题。
冷启动问题之所以出现,就是因为缺乏有价值的数据,那么在产品功能方面,就要尽量帮助收集数据。
● 用户冷启动:有些应用会在用户第一次登录时,引导用户输入一些冷启动特征。例如,一些音乐类产品会引导用于选择“音乐风格”;一些视频类产品会引导用户选择几部自己喜欢的电影。
● 物品冷启动:有些应用会以积分奖励的方式引导用户输入一些物品特征。像大众点评上的评论体系,淘宝上的评价系统,都是帮助商家、商品快速度过冷启动解决的利器。