文章目录
- 一、关于SQL必须要知道的一切
- (1)SQL是什么?
- (2)你为什么要学SQL?
- (3)SQL到底要学什么?
- 二、 SQL学习的三个阶段
- (1)理解运行原理,串联核心语句
- (2)积累函数用法,刷题巩固提升
- (3)拆解企业需求,复杂库表实战
- 强调一点:一定要学会自己看报错Debug!!!
- 三、数据架构基础知识
- (1)服务器
- (2)架构
- (3)表格
- (4)字段
- (5)值得参考的代码规范
- (6)SQL代码全局规则补充总结
- (7)解题思路
- 系列文章
一、关于SQL必须要知道的一切
(1)SQL是什么?
- 一大能力
- 可以对数据库发号施令,建立数据库并对其中的数据进行查询
- 两大属性
- 结构化
- 全称Structured Query Language,也就是结构化查询语言。
- 1、只能针对结构化数据进行处理,无法处理乱糟糟非结构化数据
- 非结构化数据

- 结构化数据
- 非结构化数据
- 2、语言有严格的语法结构和运行顺序(所以学起来非常简单)
- 语法结构: select–from–where–group by–having–order by–limit
- 运行顺序: from–where–group by–having–select–order by–limit
- 标准化
- 语法标准由ANSI美国国家标准化组织统一制定
- 所有主流数据库都与ANSI标准相兼容,它们的关键语法都是相同的
- 比如 SELECT、UPDATE、DELETE、INSERT、WHERE 等等
- 比如 SELECT、UPDATE、DELETE、INSERT、WHERE 等等
- 结构化
(2)你为什么要学SQL?
- 普遍的职场要求
- 数据化运营岗位有要求
- 高级的产品岗位有要求
- 更是数据分析师的必备技能
- 总结
- SQL作为你跟数据库对话的语言,想要直接从数据库取数,就绝对绕不开它
- 而掌握SOL就意味着直接掌握企业数据库里的一手无限商机,是人才走向数据化并进行高效信息处理的分水岭
- 提升效率的神器
- 自己取数,省去需求排期
- 在权限内,想看什么数据就看什么数据
- 一键运行,代码处理数据
- 将数据的处理过程标准化为代码,一键轻松运行,方便随意修改
- 连接工具,自动产出报表
- 直接连接数据库
- 轻松获取任意数据
- 自定义各种数据查询
- 自动刷新各类报表
- 进行各种高级分析
- 自己取数,省去需求排期
(3)SQL到底要学什么?
-
HiveSQL/Mysql/PostgreSQL等SQL语言,到底要学哪个?
- HiveSQL/Mysql/PostgreSQL到底是个啥?
他们本质上都是各有神通的数据库- 最经典的四个基础数据库
- Mysql【万金油】
- 采用最常用的标准SQL语言,同时体积小、速度快、开发和运维成本低,并且源码开放,一般中小型网站的开发都选择 MySQL 作为网站数据库。是最最常见的数据库,个人都可以轻松安装使用。
- 但是它缺乏安全系统,同时不支持热备份,不适合作为大型商业公司的专业数据库。
- Sql Server【微软生态内的王】
- 性价比和易用性高,方便拓展,速度还快
- 但是 SQL Server只能Windows系统上运行,兼容性差,并且由于微软完全重 写了SQL Server的代码,安全性还需要长期的测试
- Oracle【高端专业】
- 能在所有主流平台上运行(包括Windows),并且采用完全开放策略,完全支持所有工业标准,安全性极高,拓展、并行和速度性能都很好
- 但是对硬件的要求高,价格贵,管理维护麻烦,操作比较复杂,需要的技术含量较高
- PostgreSql【空数据上yyds】
- 有最先进的开放源码的数据库系统,稳定性极强,能很好地应对崩溃、断电之类的灾难场景。同时性能高速度快,在GIS等地理类型数据的空间处理上首屈一指。
- 但是需要定期维护和清理mvcc的多版本控制,分布式集群bug很多。并发上pg采用抢占资源的方式,如果有一个大的SOL在跑,可能就会阻塞其他的进程。扩容花费的时间很长(非常致命)。
- 总结
Mysql、Sql Server、Oracle、PostgreSql作为四大金刚在中小型公司较
为常见,是判断一家企业数据实力的好方法。
- Mysql【万金油】
- 各家都会有的Hive
- Hive是基于Hadoop (分布式系统框架,可以理解为Hive是APP,Hadoop是底层系统)的一个数据仓库工具。能将结构化的数据文件映射为一张数据库表,并提供SOL查询功能,实现【存储即查询】
- 优点是学习成本低,可以通过SQL语句实现查询,可伸缩、可扩展、容错性能极高,可以轻松存储和处理PB以上的海量数据,是大数据存储的首选数据库
- 缺点是不提供实时查询功能,只适合基于大量不可变数据的处理和分析,并且不优化的话查询速度极慢
- 总结
Hive是大多数企业走向大数据的毕竟之路,可以高性价比地存储和处理海量数据。
- 大厂主流的Cloudera Impala和PrestoDB
- Presto
- FaceBook、美团、哈罗等大厂都在用
- 优点是轻量快速,支持近乎实时的查询,扩展性(甚至能够跨数据源连表查询)和稳定性庸置疑,完全开源发展潜力大,并且文档完善。
- 缺点是才刚发展十几年,实力还需要验证 (速度比Impala慢一点),非常吃
内存和服务器资源
- Impala
- 金融等海量实时交易场景的主力数据库,阿里、百度等一线大厂都在用
- 优点是轻量快速,支持近乎实时的查询,计算都在内存中完成,减少延迟和磁盘IO开销,性能极高(基于C++实现,是最快的数据库)
- 缺点是零容忍查询失误,一错全错,同样非常吃内存和服务器资源
- 总结
Presto和Impala都是敏捷分析场景下的高级数据库,速度快,适合直接连接各类分析工具,并且进行实时监控与分析。但是很吃资源,小公司用不起,大公司也要省着用。
- Presto
- 最经典的四个基础数据库
- SQL语言为什么会有很多种?
- 1、不同的数据库的技术原理不同
- 2、为了适应各种特定场景,各家的数据库需要开发和定义一些特殊用法
- 3、各家的部分语法在易用性上进行了升级和"优化”
- 总结
- 虽然各家开发的数据库为了适应各种特定场景,都有一些自己定义的特定用法
- 但是,SQL有统一标准,各家的主要语法都完全相同,我们在初学阶段只要学习最为通用和标准的Mysql
- 等到入职前或入职后再补充学习公司所用数据库的特定用法即可
- 毕竟有这么多数据库,超人才能全部学完

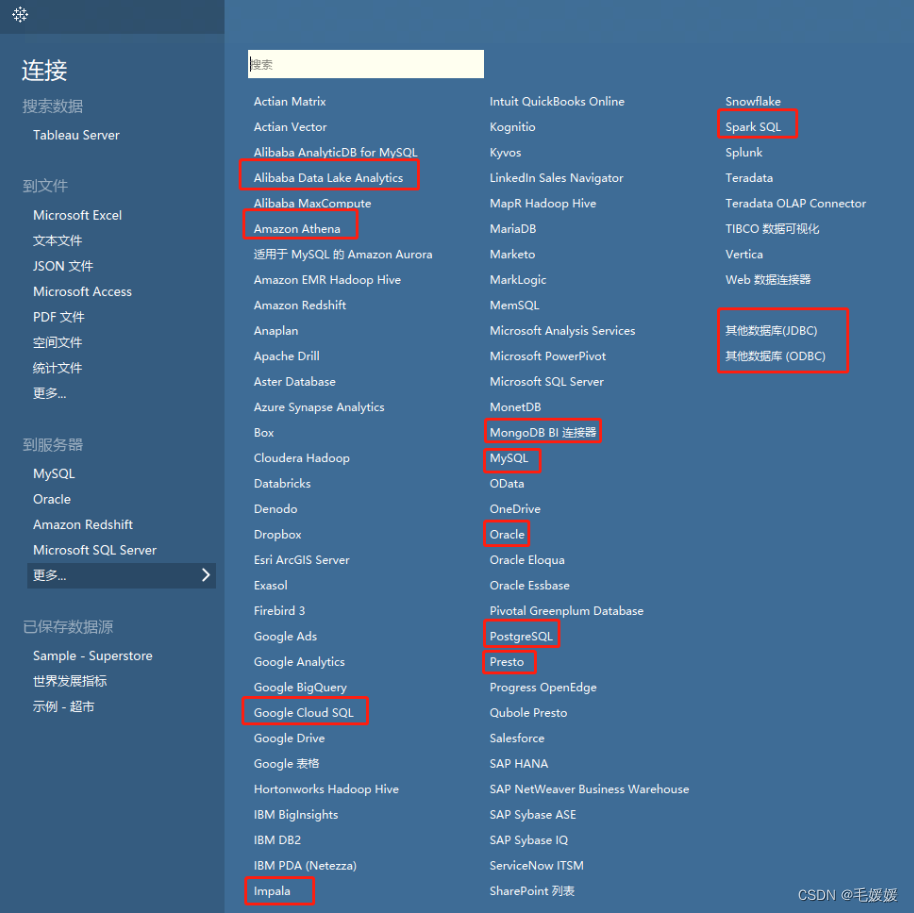
- 毕竟有这么多数据库,超人才能全部学完
- HiveSQL/Mysql/PostgreSQL到底是个啥?
-
我要不要学习如何搭建数据库?
- 数据分析师是数据的消费者,而不是创造者
- 图书馆
- 数据库
- 书
- 数据
- 出版社
- 埋点数据的开发
- 图书管理员
- 运行和维护数据库的数据工程师/数仓
- 研究员和读者
- 数据分析师
- 图书馆
- 因此,SQL6个部分的语言,分析师只需要掌握数据查询语言,其他了解即可
- 数据查询语言 (DQL:Data Query Language)
- 其语句,也称为“数据检索语句”,用以从表中获得数据,确定数据怎样在应用程序给出。保留字SELECT是DOL (也是所有SQL) 用得最多的动词,其他DOL常用的保留字有WHERE,ORDER BY,GROUP BY和HAVING。这些DOL保留字常与其它类型的SOL语句一起使用。
- select–from–where–group by–having–order by–limit
- 数据操作语言(DML: Data Manipulation Language)
- 其语句包括动词INSERT、UPDATE和DELETE。它们分别用于添加、修改和删除。
- 事务控制语言(TCL)
- 它的语句能确保被DML语句影响的表的所有行及时得以更新。包括COMMIT (提交)命令、SAVEPOINT (保存点) 命令、ROLLBACK (回滚)命令
- 数据控制语言(DCL)
- 它的语句通过GRANT或REVOKE实现权限控制,确定单个用户和用户组对数据库对象的访问。某些RDBMS可用GRANT或REVOKE控制对表单个列的访问。
- 数据定义语言 (DDL)
- 其语句包括动词CREATE,ALTER和DROP。在数据库中创建新表或修改、删除表(CREAT TABLE 或DROP TABLE);为表加入索引等。
- 指针控制语言(CCL)
- 它的语句,像DECLARE CURSOR,FETCH INTO和UPDATE WHERE CURRENT用于对一个或多个表单独行的操作。
- 数据查询语言 (DQL:Data Query Language)
- 但是,多懂一些数据库的知识(但不要求会做),会让你更有竞争力
- 能让你知道怎么更好地提数据需求
- 生产库
- 数据湖 (Hive)
- 数据中心(Presto/Impala/中间库)
- BI或报表系统
- 能让你知道问题出在哪
- 埋点
- 入库
- 提取
- 分析
- 能让你能优化查询的速度
- 从整体合理分配运算资源
- 能让你知道怎么更好地提数据需求
- 数据分析师是数据的消费者,而不是创造者
-
SQL语句要掌握到什么程度?
- 基础语法
- select–from–where–group by–having–order by–limit
- 表链接
- 子查询
- 重点是搞懂基础语法背后的SOL运行原理,知道数据库是如何对表格做操作的
- 各类函数
- 聚合函数、case when、窗口函数、substr()、replace()nullif()等等等等
- 重点是不断地学习和积累,尝试新的函数用法
- 经典组合
- 日期偏移或窗口函数求同环比、case when做数据转置与透视表、使用数值做复杂的逻辑判断
- 重点是理解分析需求,熟练掌握表格结构
- 代码规范
- 注意规范,多写注释,真的能救你一命
- 注意规范,多写注释,真的能救你一命
- 基础语法
二、 SQL学习的三个阶段
(1)理解运行原理,串联核心语句
- 学习目标
- 熟练掌握核心语句的运行原理
- 知道有哪些语句
- 语句各自的功能和限制
- 语句执行时的运行步骤
- 哪怕多层嵌套也能应对明确的取数需求
- 熟练掌握核心语句的运行原理
- 提升方法
- 只学核心语句的运行原理
- 先用Excel分步处理数据,再用SQL实现
- 尽可能地在一次查询中练习多个核心语句
- 尽可能做复杂的子查询嵌套、表连接、窗口函数
(2)积累函数用法,刷题巩固提升
- 学习目标
- 知道常用SOL常用函数的语法和功能
- 数值处理函数
- round(数值型字段,n) :对数值型字段取小数点后n位小数
- n为正整数时,取小数点后n位小数
- round(3141.592,2) = 3141.59
- n为负整数时,取小数点前n位小数
- round(3141.592,-2) = 3100
- round(3151.592,-2) = 3200
- 注意: round()是四舍五入,不是直接截取,截取用left
- n为正整数时,取小数点后n位小数
- abs(数值型字段):取数值型字段的绝对值
- abs(-666) = 666
- coalesce(字段,数值):将字段中的null填充为默认数值
- coalesce(expression1, expression2, … expression-n)
- 表示如果第一个不为空取第一个,否则判断下一个,以此类推,如果全部为空,则返回null值
- coalesce(expression1, expression2, … expression-n)
- isnull(exper)
- 判断exper是否为空,是则返回1,否则返回0
- ifnull(exper1,exper2)
- 判断exper1是否为空,是则用exper2代替
- nullif(exper1,exper2)
- 如果exprl=expr2成立,那么返回值为null,否则返回值为expr1
- round(数值型字段,n) :对数值型字段取小数点后n位小数
- 数据类型转化
- cast(字段 as 要转换成的数据类型)
- cast(日期 as date)
- 常用转化类型:date、text、int
- Mysql所有数据类型:https://www.runoob.com/mysql/mysql-data-types.html
- cast(字段 as 要转换成的数据类型)
- 字符处理函数
- substring(字段,从第n位开始取,往后取m位)=mid()
- 可以直接处理时间类型的数据
- substring(‘MySQL LEFT’,7,4) = mid(‘MySQL LEFT’,7,4) = LEFT
- left(字段,从左边一位开始往后取几位)、right()
- left(‘MySQL LEFT’,5) = MYSQL
- right(‘MySQL LEFT’,4) = LEFT
- concat()
- 连接括号内任意的字符串
- 也可以直接处理时间类型的数据,因为时间类型的数据本质就是字符串
- replace(字段,需要替换的字符,替换后的结果)
- replace(abbc,‘bb’,‘cc’) = accc
- substring_index()
- substring_index(‘https://help.codingce.com’, ‘.’, -2) = codingce.com
- ucase(需要大写的字段)
- ucase(‘mysql’) = MYSQL
- lcase(需要小写的字段)
- lcase(‘MYSQL’) = mysql
- len():返回某个文本字段的长度
- length(‘Hello World’) = 11
- position()可以获取某一字符在字符串中的位置
- position(‘world’ in ‘Hello world’) = 7
- substring(字段,从第n位开始取,往后取m位)=mid()
- 时间函数
- 时间格式date_format
- date_format() - 格式化某个字段的显示方式
- MySQL时间数据的默认格式
- https://www.w3school.com.cn/sql/func_date_format.asp
- DATE - 格式:YYYY-MM-DD
- DATETIME - 格式:YYYY-MMDD HH:MM:SS
- TIMESTAMP - 格式:YYYYMM-DD HH:MM:SS
- YEAR - 格式:YYYY或YY
- date()month()year()
- date():提取日期或日期/时间表达式的日期部分
- month():取月份返回一个数字
- year():取年份返回一个数字
- now()curdate()curtime()
- now():返回当前的日期和时间
- curdate():返回当前的日期
- curtime():返回当前的时间
- 时间偏移date_add
- date_add():在日期中添加或减去指定的时间间隔
- date_add(date,interval n 时间单位):在日期往后偏移n个时间单位(可以为负数)
- date_sub(date,interval n 时间单位):在日期往前偏移n个时间单位(可以为负数)
- 时间差值datediff
- datediff(date1,date2):函数返回两个日期之间的天数
- SELECT DATEDIFF(‘2008-12-30’,‘2008-12-29’) AS DiffDate
- 返回1
- datediff取时间间隔 (秒、日、月、天)
- timestampdiff(时间单位,开始时间,结束时间):返回结束时间和开始时间之间有多少个时间单位
- timestampdiff(month,date1,date2):日期2和日期1之间相差几个月
- timestampdiff(second,date1,date2):日期2和日期1之间相差多少秒
- datediff(date1,date2):函数返回两个日期之间的天数
- 时间格式date_format
- 逻辑函数
- if(condition, value if true, value if false):单一条件判断
- case when 条件1 then 数值1 when 条件2 then 数值2 else 数值3 end:多个条件判断
- 逻辑函数的经典用法
- 数值替换
- 条件计算
- 任意多选
- 行列转置
- 数值处理函数
- 会搜索并学习和使用新函数
- 能灵活使用函数进行各种数据处理
- 可以脱离数据库,手撕代码
- 知道常用SOL常用函数的语法和功能
- 提升方法
- 把常用函数的写法都写3-5遍
- 多刷题!多刷题!多刷题!有的题都刷一遍
(3)拆解企业需求,复杂库表实战
- 学习目标
- 能将需求转化为明确数据字段
- 能独立梳理出数据字典
- describe 数据库
- 然后整理到自己的Excel字段中
- 不断完善字段的定义和计算口径
- 能独立完成宽表的制作
- 将最常见的数据需求写成几段常用的SOL代码
- 使用【with 临时表名as(查询语句)】创建临时表
- 临时表相当于一段被提前运行的子查询
- 运行结果可以通过临时表名,被用于后续的查询语句中
- 使用【create view 视图名 as (查询语)】创建视图
- 视图相当于一张永久的临时表,每次被查询时都会运行对应的查询语句
- 视图本身是一张虚拟表,通过视图看到的数据存储在相应的数据库表中,视图本身不存储数据
- 经常被使用的查询可以被定义为视图,可以简单地理解视图表就是一段查询代码的输出结果
- 视图表显示的数据可以来自多个表,也可以来自视图
- 可以对视图进行查询、修改和删除(select、insert、update、delete),同时相应的数据库表的数据也会发生变化
- 通过视图,被授予该视图权限的用户只能查询和修改他们所见到的数据,用户可以被限制在数据的不同子集上,提升安全性
- 积累复杂库表关系下的处理经验
- 积累复杂场景下函数和语句的组合用法
- 提升方法
- 在企业级数据库中处理真实的数据需求
- 快速复现同事的SQL代码
- 最快速度围绕核心字段整理出数据字典
- 制作几张宽表,解决最高频的取数需求
- 随着业务发展,逐步补充关键字段
- 自己主动发现数据需求,推进数据建设
- 能输出价值后,提最少的数据需求
- 最后,梳理指标体系推进数据建设
- 在企业级数据库中处理真实的数据需求
强调一点:一定要学会自己看报错Debug!!!
- 不会Debug,不是懒,就是基本功不扎实
- 不要害怕报错
- 先检查基础语法、大小写、空格、书写错误
- 先定位报错的位置linex
- 认真翻译报错信息
- 思考可能的报错原因(80%的报错都是因为语句用法不熟和粗心),排除粗心原因
- 百度寻找对应解决方法
- 加强积累,把你报错的过程和思路记录下来,巩固报错部分较为生疏的语法,很快你就能一眼知道报错原因,报错会越来越少
三、数据架构基础知识
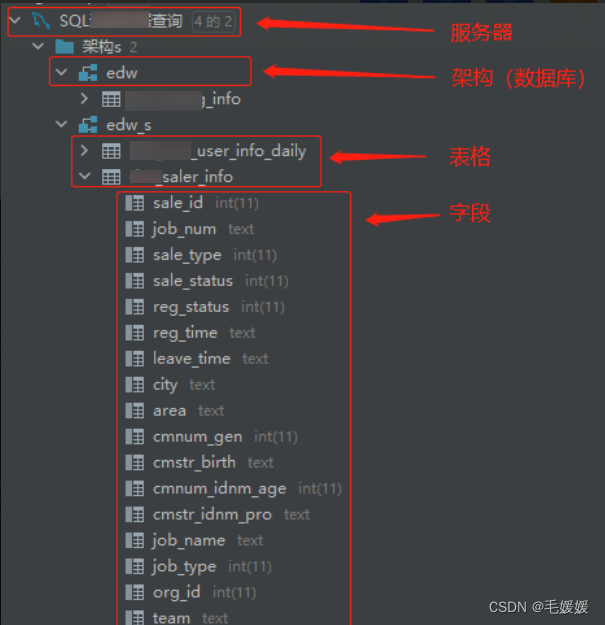
(1)服务器
- 数据库中一切数据和信息所存储的地方,可以理解为你的电脑硬盘
- 服务器往往有对应的物理主机和访问地址,连接数据库时主机后面所填的就是访问地址
(2)架构
- 服务器中具体的数据库,用于存储不同用途的表格,可以理解为电脑中的文件夹
- 常见的架构有ods/edw/edw_s/ddm,他们各自有不同的储存特点。
- ods (Operational Data Store):操作型数据仓库
- 同步业务生产过程中的所有数据,比edw更加详细,冗余和复杂度也更高
- edw (Enterprise Data Warehouse):企业数据库
- 已处理完成并进行过汇总的,可供业务直接使用的企业数据库
- edw_s:安全级别更高的企业数据库
- 存储安全级别较高的敏感或机密数据,例如用户的身份证号、手机号、真实姓名
- 加密性更高,一般需要独立授权
- ddm (Distributed Database Middleware):局部数据库
- 专门针对某个具体的应用或需求建设的局部数据库,只关心自己需要的数据。不会全盘考虑企业整体的数据架构和应用,每个应用都有自己的DM。所以DM可以基于仓库建设也可以独立建设。
- 专门针对某个具体的应用或需求建设的局部数据库,只关心自己需要的数据。不会全盘考虑企业整体的数据架构和应用,每个应用都有自己的DM。所以DM可以基于仓库建设也可以独立建设。
- ods (Operational Data Store):操作型数据仓库
(3)表格
- 存在于不同架构中具体的数据表格,可以理解为文件夹中的Exce
- 真实场景中“架构.表格”的形式存储表名更加方便跨数据库取数
- 对表格使用默认统一的别名,更方便后续的代码移植 (用a b c的话还需要修改select后的字段前缀)
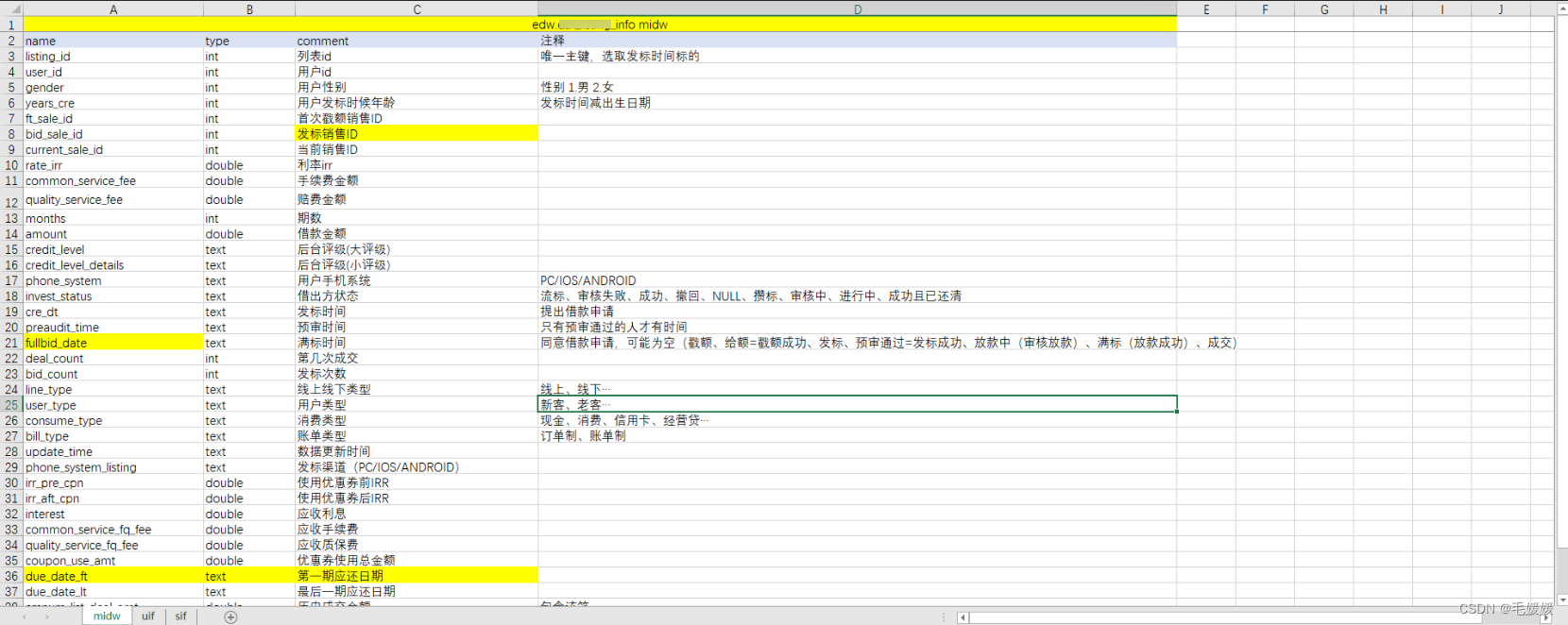
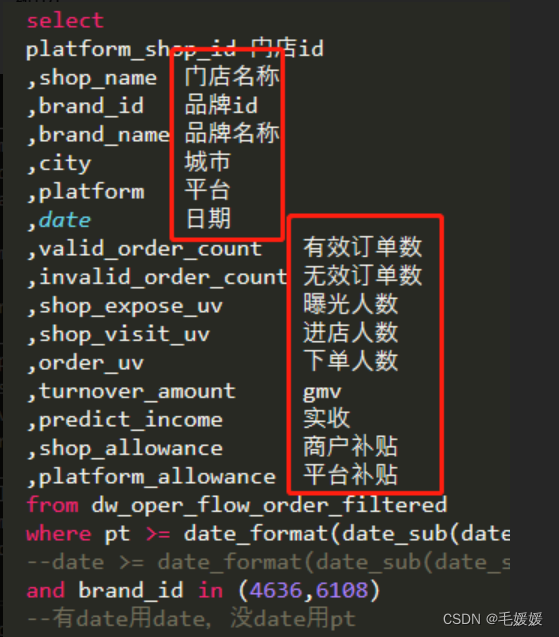
(4)字段
- 表格中不同列,可以理解为Excel中的列
- 拿到数据库权限后的第一件事就是整理自己的Dictionary,梳理常用的表格和字段含义
(5)值得参考的代码规范
-
只有select和from不换行,直接写成一行

-
核心语句换行,join 连接表换行,on 连接键换行,多连接键也换行
-
where/having 多条件and/or 换行,单条件语句不换行,例如: between and、sif.branch in(‘上海分行’,‘北京分行’)
-
group by 后字段不换行,order by 后字段不换行
-
括号内不加空格,函数的括号前不加空格,括号内不加空格,例如:(‘上海分行’,‘北京分行’)、sum(amount)
-
运算符前后加空格: = 、>= 、<= 、> 、< 、!= 、- 、+
-
含乘除的运算符前后不加空格:*、/、%
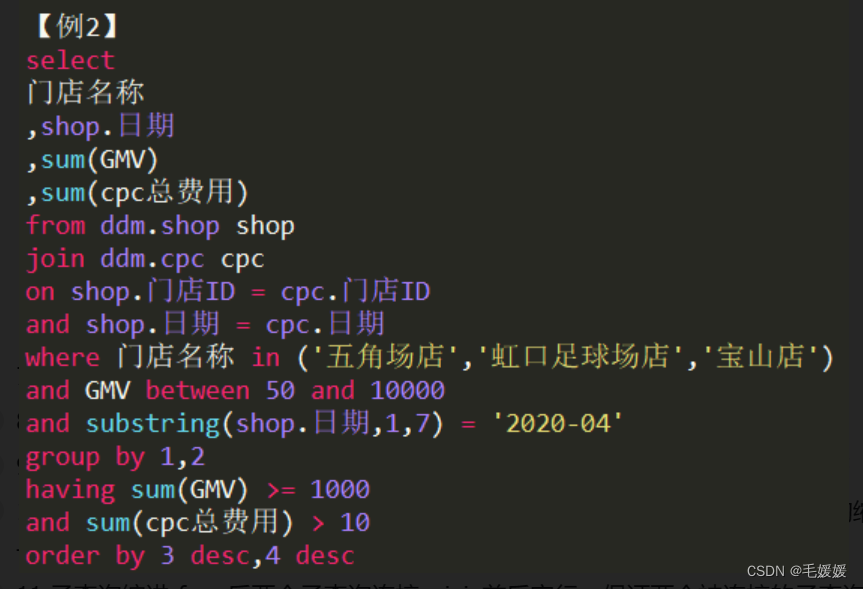
-
select 后只有一个字段不换行,select 后的 * 算作一个字段来看
-
distinct 不换行,后面的字段大于一个,字段换行
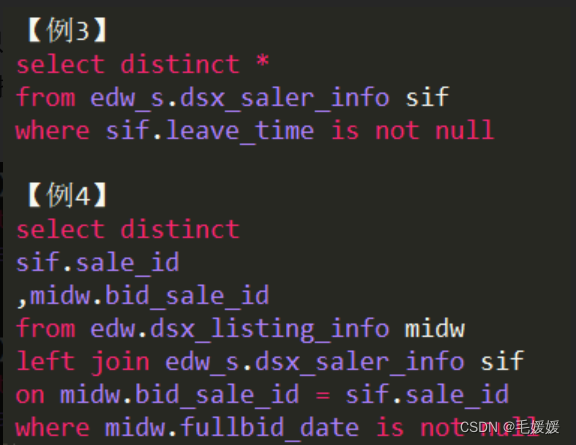
-
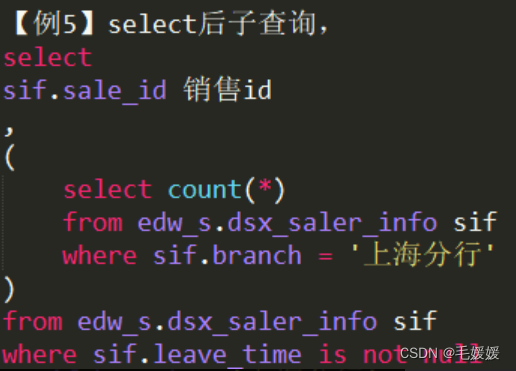
子查询缩进-select后子查询,括号换行,子查询缩进在括号后,括号上下对齐
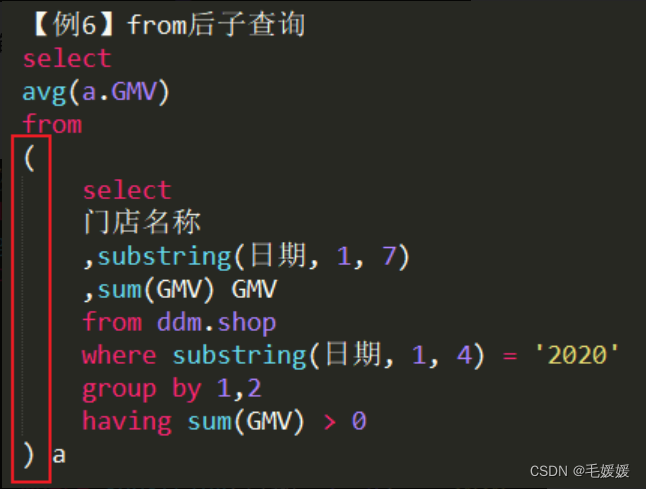
-
子查询缩进-from后子查询,括号换行,括号与from同一缩进,括号中的查询缩进在括号后
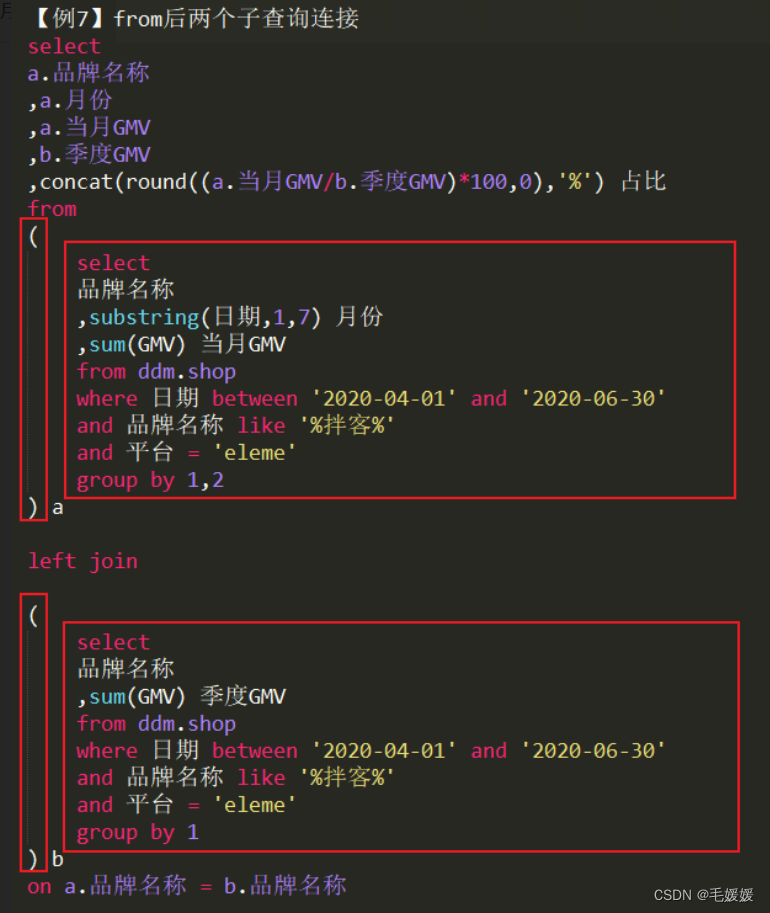
-
子查询缩进-from后两个子查询连接,join前后空行,保证两个被连接的子查询与 from和join 在同一缩进,括号上下对齐
-
子查询缩进-where后子查询,括号不换行,括号在in/运算符后,子查询缩进在括号
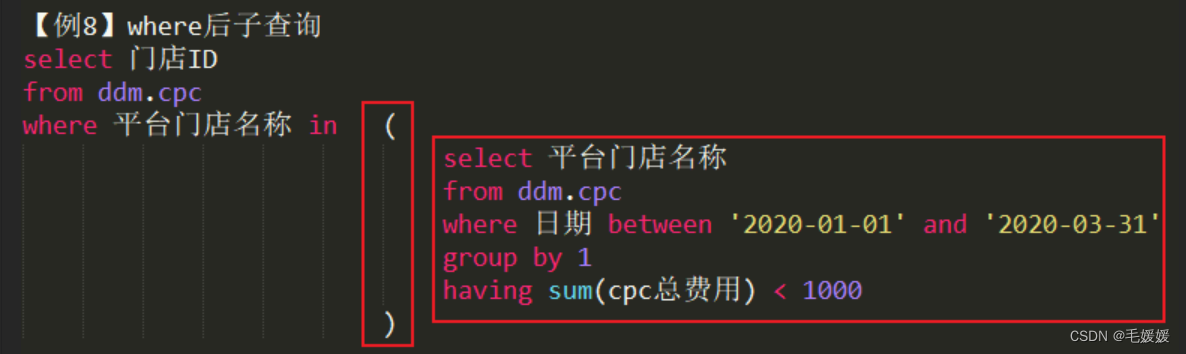
-
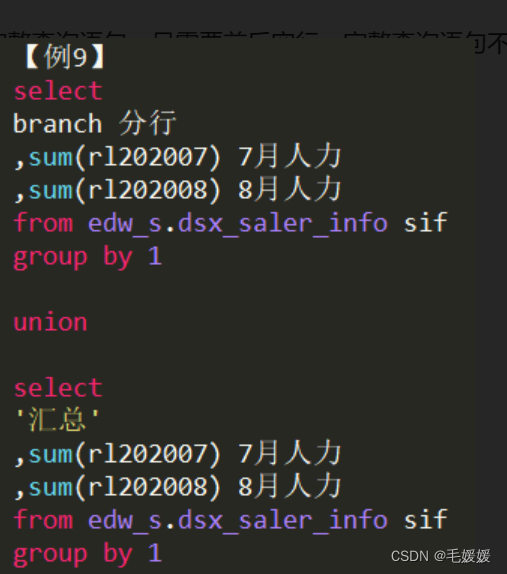
union前后为完整查询语句,且需要前后空行,完整查询语句不需要括号
-
窗口函数不换行

-
函数嵌套,函数除了 case when 其余函数和函数的多重嵌套都写一行

-
case when 函数,仅有一对when和then时,全部写一行

-
case when 函数,when 后仅一个条件时,when 和 then 在同一行,若 when 后有多个条件时 then 换行,且前后的 then 都换行,保持代码块内格式统一
-
case when 函数,else 和 end 在同一行,case when 函数在本身有换行时,外面嵌套的函数,后半个括号要换行与前半个括号上下对齐
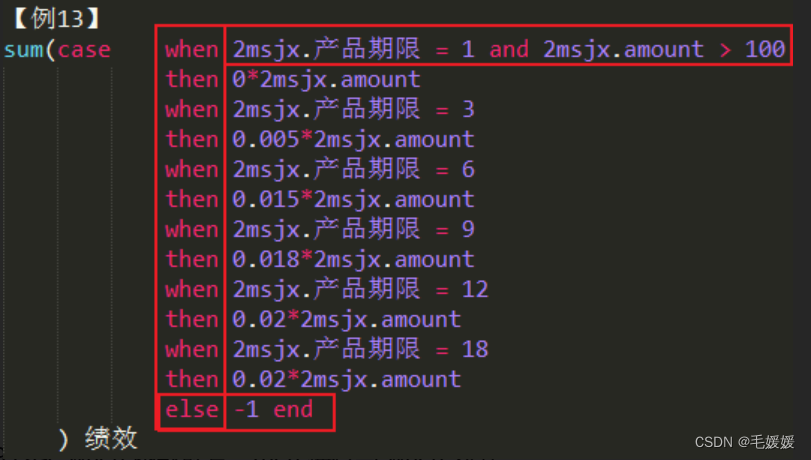
-
case when 函数嵌套,then 换行与 when 对产
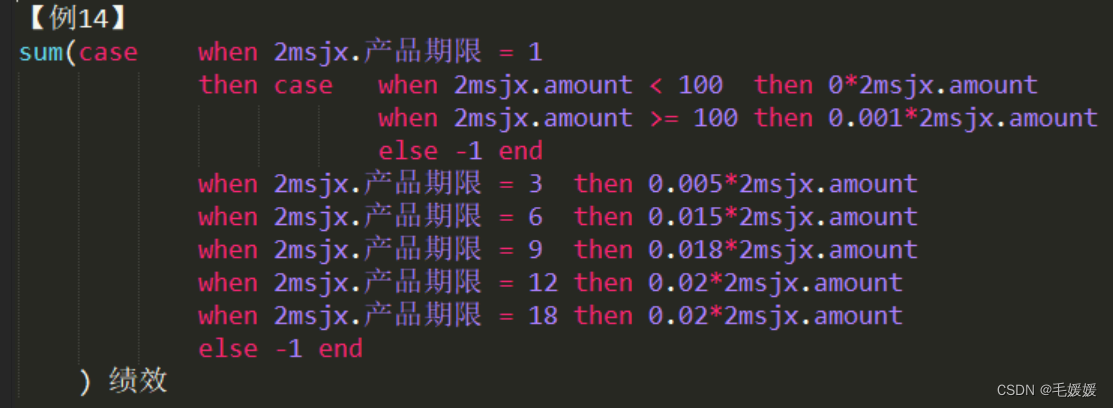
-
with as 中间表,表名换行,括号换行,代码缩进在括号后,多个中间表时加空行区分
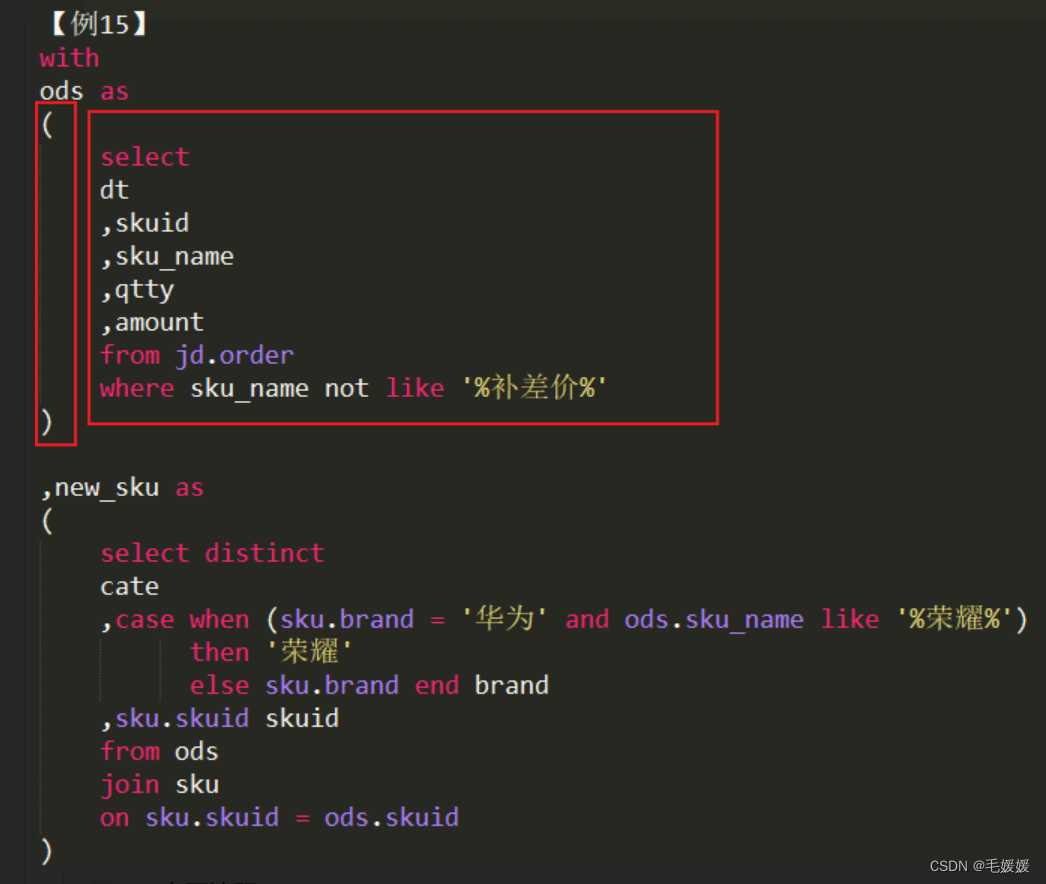
-
别名尽量统一缩进
-
代码结束处加;
- 不同公司要求不一样,数据建设好的都不用,因为可以直接识别select
-
多写注释
- 单行注释:# 注释内容
- 多行注释:/*注释内容*/
- crtl+/:可以快捷注释整行
记住:多换行,多缩进
(6)SQL代码全局规则补充总结
- 在阅读SQL代码和书写时,可以先从from和join语句看起,明确用了哪些表,然后看select查询和创建了哪些字段,接下来细致研究代码细节,最后看where的筛选逻辑
- 在各个库中,表和字段别名尽量统一,方便代码移植,减少使用a,b来别名,别名要有含义
- 命令和变量名称冲突时需要在变量两侧加``(在左上角~那)做区分,’ ’ (单引号在区分字符串时使用)," ”(已有单引号时用双引号包含单引号)
- 表和变量名中不要出现空格,可使用下划线_替代
(7)解题思路
- 尽可能使用分步实现法,顺着题目一步步写
- 写SQL代码时应该尽量脱离数据库,在脑海里完成代码的组合和调试
- 遇到特别复杂的逻辑,一次查询无法解决,可以直接上子查询,然后再慢慢优化
- 遇到暂时想不清楚的地方,可以先搁置,最后基于其他步骤已成型的代码进行推导
- 实在不行就画图,或者用Excel表格先处理出来,再一步步用SQL实现
- 完成代码后一定要尽量优化自己的代码,这样逻辑才能越来越好
- 不断反复练习,最终能在读题时就在脑海里理清代码逻辑
系列文章
SQL自学三部曲_Part1:云端数据库配置&Excel/Tableau连接数据库
SQL自学三部曲_Part2:十大必学语法(一)
SQL自学三部曲_Part2:十大必学语法(二)
SQL自学三部曲_Part3:关于SQL必须要知道的一切